一种被推荐对象的过滤方法及系统与流程
本申请涉及数据处理技术,尤其涉及一种被推荐对象的过滤方法及系统。
背景技术:
在电子商务网站中,一般需要对电子商务产品进行过滤,以便从中选择出高质量的优质产品来向用户进行推荐,例如将被推荐的产品的对应信息放置于电子商务网站的首页等等,从而使得用户能够不通过搜索和过多的产品浏览操作即可获得优质产品的信息,更为便捷的进行购物。现有技术中,一般通过人工肉眼选择需要向用户推荐的产品,或者直接根据电子商务产品的成交量等来选择需要向用户推荐的产品,但是通过上述方式选择出来的被推荐的产品往往由于人工选择的倾向性或者选择依据的单一而造成选择结果与用户预期之间的偏差,导致产品推荐的不准确。也即是说,当将这些选择出来的产品向用户进行推荐时,往往并不能获得客户的认同,从而用户仍然需要通过搜索并对搜索到的产品进行浏览而最终实现购物,这样,电子商务网站所属的第一服务器需要进行优质产品的选择和推荐处理,然而这种选择和推荐处理并未减少用户购物中的操作,反而由于需要进行优质产品的选择和推荐处理,从而增加了第一服务器的数据处理压力,降低了第一服务器的数据处理速度;而且,第一服务器需要将对于产品的推荐数据发送到各个用户所在的客户端,以便向用户进行展现,第一服务器和客户端之间的推荐数据传输也占用了两者之间的传输带宽,浪费了网络传输资源。
技术实现要素:
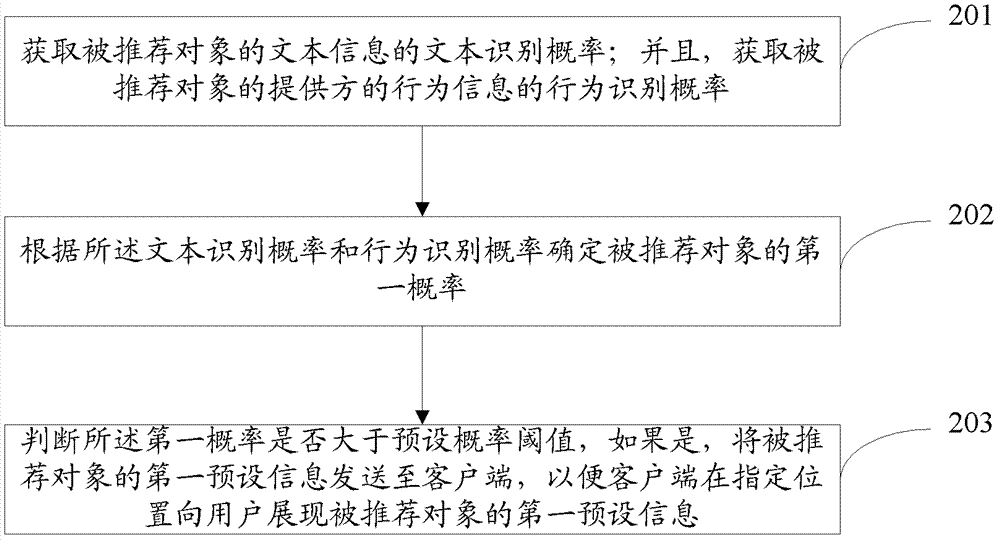
有鉴于此,本申请要解决的技术问题是,提供一种被推荐对象的过滤方法及系统,能够提高第一服务器的数据处理速度,且减少第一服务器与客户端之间的传输带宽占用。为此,本申请实施例采用如下技术方案:一种被推荐对象的过滤方法,包括:获取被推荐对象的文本信息的文本识别概率;并且,获取被推荐对象的提供方的行为信息的行为识别概率;根据所述文本识别概率和行为识别概率确定被推荐对象的第一概率;判断所述第一概率是否大于预设概率阈值,如果是,将被推荐对象的第一预设信息发送至客户端,以便客户端在指定位置向用户展现被推荐对象的第一预设信息。一种被推荐对象的过滤系统,包括:第一获取单元,用于获取被推荐对象的文本信息的文本识别概率;第二获取单元,用于获取被推荐对象的提供方的行为信息的行为识别概率;确定单元,用于根据所述文本识别概率和行为识别概率确定被推荐对象的第一概率;判断单元,用于判断所述第一概率是否大于预设概率阈值;发送单元,用于判断单元的判断结果为是时,将被推荐对象的第一预设信息发送至客户端,以便客户端在指定位置向用户展现被推荐对象的第一预设信息。对于上述技术方案的技术效果分析如下:根据被推荐对象的文本识别概率和被推荐对象提供方的行为识别概率确定被推荐对象的第一概率,进而判断第一概率大于预设概率阈值时,将被推荐对象的第一预设信息发送至客户端,以便客户端在指定位置向用户展现被推荐对象的第一预设信息;从而,在进行被推荐对象的过滤时,不仅仅依靠人工方式或者依据被推荐对象的成交量,而是结合被推荐对象以及被推荐对象的提供方两方面的因素,相应的进行被推荐对象的过滤,从而使得被推荐对象的选择准确,减少了用户进行搜索和浏览的操作,从而第一服务器的数据处理压力降低,提高了第一服务器的数据处理速度;而且,由于用户搜索和产品浏览操作的减少,客户端与第一服务器之间传输的搜索结果数据以及产品浏览对应的产品数据减少,从而减少了客户端与第一服务器之间的传输带宽占用,减少了对于网络传输资源的浪费。附图说明图1为本申请实施例所应用的网络环境;图2为本申请实施例一种被推荐对象的过滤方法流程示意图;图3为本申请实施例一个步骤的实现方法流程示意图;图4为本申请实施例另一个步骤的实现方法流程示意图;图5为本申请实施例被推荐数据的过滤系统结构示意图。具体实施方式以下,结合附图详细说明本申请实施例被推荐数据的过滤方法及系统的实现。为了更好的对本申请实施例过滤方法进行理解,首先对本申请实施例被推荐对象的过滤方法及系统可以适用的网络环境进行举例,如图1所示,可以包括:客户端110,用于向第一服务器发送被推荐对象的文本信息;第一服务器120,用于获取被推荐对象的文本信息以及被推荐对象的提供方的相关行为信息,并且将被推荐对象的预设信息发送给客户端,以便客户端将预设信息在指定位置进行展现。其中,所述被推荐对象例如可以为:产品,而文本信息可以为产品的描述信息、标题、关键字等产品相关的文字信息;而被推荐对象的提供方可以为商家,所述行为信息可以为被推荐对象被购买、被点击、被二次点击等用户在网页上的操作动作信息等,所述预设信息可以为被推荐对象的除文字信息之外的其他信息,例如图片信息、图片的描述等。图2为本申请实施例一种被推荐数据的过滤方法流程示意图,如图2所示,该方法包括:步骤201:获取被推荐对象的文本信息的文本识别概率;并且,获取被推荐对象的提供方的行为信息的行为识别概率;步骤202:根据所述文本识别概率和行为识别概率确定被推荐对象的第一概率;其中,第一概率的计算公式可以为:第一概率=文本识别概率*文本识别概率权重+行为识别概率*行为识别概率权重。步骤203:判断所述第一概率是否大于预设概率阈值,如果是,将被推荐对象的第一预设信息发送至客户端,以便客户端在指定位置向用户展现被推荐对象的第一预设信息。在图2所示的被推荐产品的过滤方法中,根据被推荐对象的文本识别概率和被推荐对象提供方的行为识别概率确定被推荐对象的第一概率,进而判断第一概率大于预设概率阈值时,将将被推荐对象的第一预设信息发送至客户端,以便客户端在指定位置向用户展现被推荐对象的第一预设信息;从而,在进行被推荐对象的过滤时,不仅仅依靠人工方式或者依据被推荐对象的成交量,而是结合被推荐对象以及被推荐对象的提供方的相关行为信息两方面的因素,相应的进行被推荐对象的过滤,从而使得被推荐对象的选择可以准确,减少了用户进行搜索和浏览的操作,从而第一服务器的数据处理压力降低,提高了第一服务器的数据处理速度;而且,由于用户搜索和产品浏览操作的减少,客户端与第一服务器之间传输的搜索结果数据以及产品浏览对应的产品数据减少,从而减少了客户端与第一服务器之间的传输带宽占用,减少了对于网络传输资源的浪费。在图2的基础上对本申请实施例被推荐数据的过滤方法的实现进行更为详细的说明。其中,步骤201中所述获取被推荐对象的文本信息的文本识别概率可以包括:根据被推荐对象的样本,确定样本的各种文本参数对应的概率值在文本识别概率中的权重值;根据被推荐对象的文本信息计算被推荐对象在每一种文本参数下的概率值;根据被推荐对象在每一种文本参数下的概率值以及各种文本参数对应的概率值在文本识别概率中的权重值,计算被推荐对象的文本信息的文本识别概率。具体的,如图3所示,步骤201中的所述获取被推荐对象的文本信息的文本识别概率可以通过以下步骤实现。其中,步骤301~步骤308是所述根据被推荐对象的样本,确定样本的各种文本参数对应的概率值在文本识别概率中的权重值的一种具体实现,步骤309~步骤312是所述根据被推荐对象的文本信息计算被推荐对象在每一种文本参数下的概率值的一种具体实现;步骤313对应所述计算被推荐对象的文本信息的文本识别概率。步骤301:获取被推荐对象的样本,将所述样本划分为第一样本库和第二样本库。其中,当所述被推荐对象为产品时,可以按照样本的产品质量高低来进行第一样本库和第二样本库的划分,例如第一样本库中所包含的样本的产品质量相对第二样本库中样本的产品质量更高;而第二样本库中样本的产品质量相对较低。一般的,将描述信息全面、图片好、价格数据真实、产品细节属性描述充分、交易量好、评价高的产品认为是高质量产品,高质量产品之外的产品为低质量产品,本申请实施例中也可以按照上述标准类似的标准进行所述产品质量高低的判断。步骤302:对于每个样本,从样本的各种文本参数中分别提取各种文本参数所包含的词条。其中,当所述被推荐对象为产品时,所述文本参数可以包括:标题、关键字、描述信息等。当所述文本参数为描述信息时,在进行样本的文本参数中的词条提取时,可以通过以下步骤实现:1.1对于每一样本的描述信息,去除描述信息中的html标签;1.2从描述信息中去除包含在停用词列表中的词组;1.3对于进行上述去除处理后的描述信息,将相邻的预设个数的词组作为一个词条。这里,所述预设个数可以自主设定,例如可以设为1个和/或2个和/或3个等,这里不限制。优选地,为了防止后续英文字符的大小写对词条的出现次数统计结果构成影响,这里还可以将所有词条中的英文字符全部转换成小写的英文字符。另外,在进行词条的提取之前,还可以先对两个样本库中的样本进行防噪处理,具体的,该防噪处理过程可以包括:2.1按照样本的生成时间,将生成时间处于预设时间之前的样本去除;2.2将样本的预设第一文本参数的关键词处于黑白名单中的样本去除;2.3将样本的提供方处于黑白名单中的样本去除;2.4将样本的预设第一文本参数的关键词包含被禁止关键词的样本去除。通过以上对于样本的防噪处理,可以进一步选择出合适的样本,否则,可能对后续的过滤结果的准确性构成影响。步骤303:建立每一种文本参数的词条库,每一种文本参数的词条库中包括:该种文本参数所包含的各个词条在第一样本库样本的该种文本参数中的数量和第二样本库样本的该种文本参数中的数量。也即是说,对于提取出的每个词条,分别统计该词条在第一样本库样本的对应文本参数中出现的次数和第二样本库样本的对应文本参数中出现的次数。例如,对于描述信息(对应文本参数)中提取出的词条W1,统计出其在第一样本库各个样本的描述信息(对应文本参数)中出现的次数HC1,并且,统计出该词条W1在第二样本库中各个样本的描述信息(对应文本参数)中出现的次数LC1;对于标题中的词条W2,统计出其在第一样本库中各个样本的标题中出现的次数HC2,在第二样本库中各个样本的标题中出现的次数LC2;等等。以下,通过步骤304~步骤307详细描述如何实现根据每一种文本参数的词条库计算每一样本在该种文本参数下的概率值。步骤304:建立每一种文本参数的词条库,计算词条库中每个词条在该种文本参数下的出现概率。所述词条库中包括:该种文本参数所包含的各个词条在第一样本库样本的该种文本参数中的数量和第二样本库样本的该种文本参数中的数量。具体的,在某一种文本参数下,词条W在该种文本参数下的出现概率P(W)的计算公式可以为:P(W)=(HCW*LT)/(HCW*LT+LCW*HT);其中,HCW为词条W在第一样本库中样本的该种文本参数中出现的次数;LCW为词条W在第二样本库中样本的该种文本参数中出现的次数;LT为第一样本库中样本的总数;HT为第二样本库中样本总数。其中,当步骤302中进行了样本库中样本的防噪处理时,LT和HT应该为样本库进行防噪处理后样本库中样本总数。步骤305:对每一词条在对应文本参数下的出现概率进行修正处理,得到每一词条的出现概率的修正值。当步骤304中概率计算在HCW为0时,P(W)会趋近于0,在LCW为0时,P(W)等于1,为了避免这种极端情况的出现,可以使用一个修正函数f(W)=(s*X+n*P(W))/(s+n)对步骤304中计算得到的出现概率进行修正处理,其中n为词条W在第一样本库中各个样本的对应文本参数中出现的次数HCW和词条W在第二样本库中各个样本的对应文本参数中出现的次数LCW之和;X,s为常量,X,s一般为预设的值,作用为避免出现P(W)为1或0的极端情况,在实际应用中可以自主设置,X和s一般取具有参考价值的经验数据值,例如可以根据另外一个已有词条的计算结果,将s取值为该词条出现在该词条对应的第一样本库和第二样本库中的次数之和;X取值为该词条在对应的第一样本库中出现的概率。步骤306:对于每一样本的每一种文本参数,根据该样本的该种文本参数所包含的所有词条在该种文本参数下的出现概率的修正值,计算该样本在该种文本参数下的第一概率值和第二概率值。其中,第一概率值P1=1-(1-f(1))(1-f(2))...(1-f(m))^(1/m),第二概率值P2=1-(f(1)*f(2)...f(m))^(1/m),m为对应文本参数所包含的词条的总数量。例如,某一样本A的文本参数B,则根据该样本A的文本参数B中所包含的所有词条在该文本参数B下的出现概率的修正值,计算该样本A在该文本参数B下的第一概率值和第二概率值。步骤307:根据该样本在该种文本参数下的第一概率值和第二概率值计算该样本在该种文本参数下的概率值S=(P1-P2)/(P1+P2)。同样的,本步骤中,根据样本A在文本参数B下的第一概率值和第二概率值计算样本A在该文本参数B下的...
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1