一种对网页进行版式分类的方法和装置与流程
本发明涉及互联网技术,特别涉及一种对网页进行版式分类的方法和装置。
背景技术:
目前,针对Web网页,主要存在两种分类方式,一种是内容分类,另一种是版式分类。其中,内容分类是以页面正文内容的不同作为分类角度,可分为新闻页和问答页等;版式分类是以页面主体结构框架的不同作为分类角度,可分为博客页和论坛页等。对于内容分类,目前的研究已经比较成熟,但对于版式分类的研究则稍显不足。在实际应用中,版式分类的结果可用于建立网页模型,并可为页面信息抽取提供参考信息,还可用于搜索引擎结果的类别区分等,具有重要意义。现有技术中,主要通过名单加典型的统一资源定位符(URL,UniformResourceLocator)特征的方式来实现版式分类,具体实现包括:针对任一Web网页X,首先利用名单来对其URL进行匹配,所述名单中可包括一系列不同的域名以及分别对应的版式类别等,如名单中的一个域名为hi.baidu.com,对应的版式类别为博客页,那么,如果Web网页X的URL中包括“hi.baidu.com”,则可确定出Web网页X所属的版式类别为博客页;如果利用名单无法确定出Web网页X所属的版式类别,则可进一步利用一些典型的URL特征来进行确定,如Web网页X的URL中包括“bbs”,则可确定出Web网页X所属的版式类别为论坛页。但是,上述方式在实际应用中会存在一定的问题:由于名单中能够覆盖的域名非常有限,而且很多Web网页的URL中不会存在如“bbs”等典型的URL特征,因此将会导致很多的Web网页无法被正确分类。
技术实现要素:
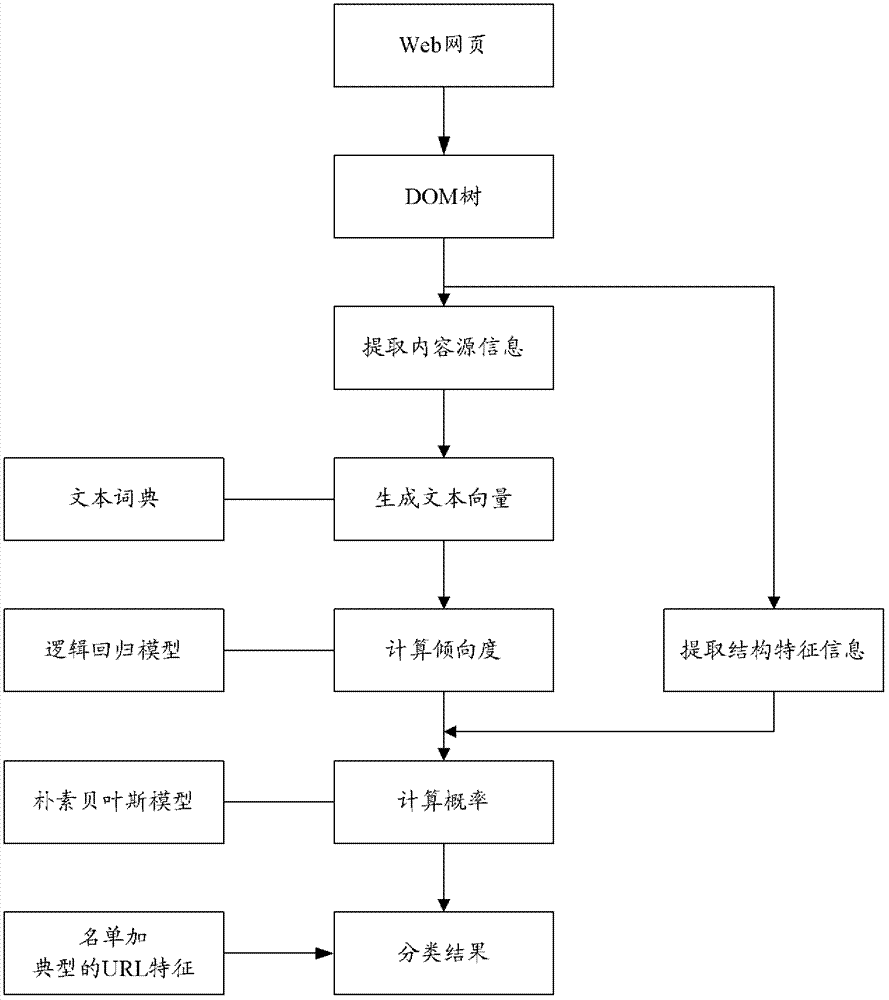
有鉴于此,本发明提供了一种对网页进行版式分类的方法和装置,能够提高分类结果的准确性。为达到上述目的,本发明的技术方案是这样实现的:一种对网页进行版式分类的方法,当需要对任一Web网页进行分类时,进行以下处理:获取所述Web网页中能够体现页面版式特征的信息;根据获取到的信息确定所述Web网页分别属于预先设定的N个不同版式类别的概率,N为大于1的正整数;将取值最大的概率对应的版式类别作为所述Web网页所属的版式类别。一种对网页进行版式分类的装置,包括:第一处理模块,用于当需要对任一Web网页进行分类时,进行以下处理:获取所述Web网页中能够体现页面版式特征的信息,并发送给第二处理模块;所述第二处理模块,用于根据获取到的信息确定所述Web网页分别属于预先设定的N个不同版式类别的概率,N为大于1的正整数;将取值最大的概率对应的版式类别作为所述Web网页所属的版式类别。可见,采用本发明所述方案,对于任一Web网页,可根据获取到的体现该Web网页的页面版式特征的信息确定该Web网页分别属于不同的版式类别的概率,并将取值最大的概率对应的版式类别作为该Web网页所属的版式类别。相比于现有技术,本发明所述方案无需依赖于名单和典型的URL特征,对任意的Web网页均适用,从而可较好地提高分类结果的准确性。而且,本发明所述方案实现起来简单方便,便于普及和推广。附图说明图1为本发明对网页进行版式分类的方法实施例的流程图。图2为本发明对网页进行版式分类的过程示意图。图3为本发明所述两级版式分类方式示意图。图4为本发明对网页进行版式分类的装置实施例的组成结构示意图。具体实施方式针对现有技术中存在的问题,本发明中提出一种改进后的对网页进行版式分类的方案。为使本发明的技术方案更加清楚、明白,以下参照附图并举实施例,对本发明所述方案作进一步地详细说明。图1为本发明对网页进行版式分类的方法实施例的流程图。当需要对任一Web网页进行分类时,分别按照图1所示流程进行处理。步骤11:获取Web网页X中能够体现页面版式特征的信息。为便于表述,用Web网页X来代表任一Web网页。本步骤中,可首先建立Web网页X的文本对象模型(DOM,DocumentObjectModel)树;之后,根据所建立的DOM树提取出Web网页X中的内容源信息以及结构特征信息。其中,内容源信息可包括:标签和短文本;结构特征信息可包括:URL、二级导航和标题。通常来说,页面版式特征不会体现在长文本,如正文和句子中,因此,可只提取Web网页X中的短文本和标签等,将其作为内容源信息,并提取Web网页X的URL、Web网页X中的二级导航以及标题等作为结构特征信息,标题即指Web网页X的网页标题,短文本是指网页超文本标记语言(HTML,HypertextMarkupLanguage)源文件中不包含标点且文本长度有限的字符串,一般用于描述网页的若干提示信息。如何建立DOM树以及如何提取内容源信息和结构特征信息可以参考现有技术,在此不赘述...
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1