数据库集群单点故障的监控系统及方法与流程
本申请涉及网络通信系统,具体地,涉及一种数据库集群单点故障的监控系统及方法。
背景技术:
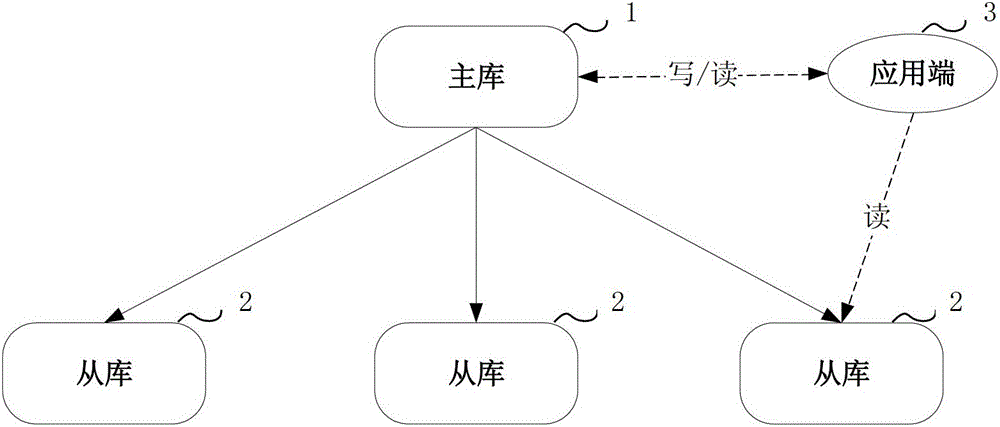
目前,互联网公司通常采用数据库集群来存储网站的海量数据。数据库集群的结构如图1所示,主库(Master)1提供对外的读写服务,若干个从库(Slave)2只对外提供读服务,以MySQL数据库为例,主库1和从库2均为MySQL实例,从而图1所示的数据库集群构成一个MySQL集群,每一个MySQL数据库(包括主库和从库)都是一个单点。各个MySQL数据库之间的关系包括:通过复制机制,从库2根据主库1定期发送的日志,不断地从主库1中读取更新的数据,从而使得从库2尽量与主库1的数据保持一致,使得应用端3(Client)从从库2中读取的数据与主库一致。在实际运行中,互联网公司使用的服务器大部分都是普通的个人电脑(PC,PersonalComputer)服务器(Server),PCServer存在一定的故障率,如通常会发生内存异常、主板异常、或者直接宕机,发生故障的PCServer就无法向外提供服务,这就是MySQL数据库的单点故障,如果正好是主库1的机器出现问题,那么应用端3(Client)对主库1写入数据的操作就会受影响,影响到数据库集群对外提供的写服务。目前,针对MySQL数据库的单点故障主要有以下两种解决方案:第一种方案,采用人工干预的解决办法。该方法包括:人工确认主库1是否存活(即正常向外提供读写服务),若存活,则将主库1直接启动,以确定从库2是否能够正常同步,若主库1中的数据损坏或者主库1不存活(即不能正常向外提供读写服务),则选择一台数据较新的从库2作为新主库。具体地,将该新主库设置为可读写的状态,将原主库1的读写状态设置为只读状态,然后通知前端应用或者中间层将数据写入新的主库,从而完成主从数据库的切换。上述过程均需要人工干预。如果主库和从库在同一个网段的话,采用虚拟IP的方式,主备切换不会影响到前端应用或者中间层的切换,影响到数据写入的时间几乎为零;但是,对于主库和从库跨机房部署、不属于同一个网段的情况,主备切换则会影响到前端应用或者中间层的切换,也即对数据的写入造成影响。第二种方案,设置一个单点监控端,打通该单点监控端与所有MySQL数据库之间的信任关系(例如,打通ssh信任关系),从该单点监控端定时与当前的MySQL主库进行通信,以ssh判断方式来判断识别主库是否存活(即可提供写服务),在判断发生单点故障时,调用程序控制实现新的主库的选举,新库的选举过程与上述第一种方案中的主从数据库的切换处理方式类似,在切换完成后,基于ssh信任关系使新主库中的数据与旧主库中的数据保持同步,该方案通过增设单点监控端作为探测源,用它判断主库的故障,从而替代原来的人工判断。上述的方案一中存在人工切换处理效率低、切换时间长、容易丢失写入的数据的问题。而上述方案二中单点监控端必须首先打通与其他MySQL数据库之间的ssh信任关系,这一处理过程仍需人工进行处理、处理过程复杂繁琐、效率较低,对于ssh信任关系的维护也同样复杂繁琐;单点监控端需要基于ssh判断方式对单点故障进行识别,处理过程复杂、低效;并且打通了ssh信任关系后,通过单点监控端就能够访问到其他MySQL数据库的数据,这样对数据安全性造成威胁,并且如果单点监控端与MySQL主库同时发生故障,就无法通过单点监控端来实现主从数据库的切换,从而降低了系统的稳定性。可见,在现有技术中,MySQL数据库集群单点故障的解决方案中存在效率低下、数据安全性差、系统稳定性差的问题。
技术实现要素:
针对现有技术中分布式MySQL数据库单点故障的解决方案中存在的效率低下、数据安全性差、系统稳定性差的问题,本申请实施例提供了一种数据库集群单点故障的监控系统,用以解决至少一个上述问题。相应地,本申请实施例还提供了一种数据库集群单点故障的监控方法。本申请实施例技术方案如下:一种数据库集群单点故障的监控系统,应用于包括若干个数据库的数据库集群中,数据库包括主库或从库,监控系统包括:若干个数据库代理,至少三个基于分布式协调机制相互通信的协调终端,其中至少三个协调终端中包括一个领导协调终端;一个数据库代理与数据库集群中的一个数据库对应设置在一台服务器上,每个数据库代理中均保存各个协调终端的地址;数据库代理,用于定时检测对应数据库的读写状态,并将检测得到的数据库读写状态信息发送给领导协调终端;领导协调终端,用于接收来自各个数据库代理的数据库读写状态信息,在超过预定时限未接收到任意一个数据库读写状态信息,或接收到的任意一个数据库读写状态信息为异常时,确定数据库集群中存在单点故障。一种数据库集群单点故障的监控方法,包括:基于分布式协调机制的领导协调终端,接收与数据库集群中的数据库对应设置的数据库代理发送的数据库读写状态信息;领导协调终端在超过预定时限未接收到任意一个数据库读写状态信息、或接收到的任意一个数据库读写状态信息为异常时,确定数据库集群中存在单点故障。根据本申请实施例提供的技术方案,通过数据库代理定时检测数据库集群中对应数据库的读写状态,基于分布式协调机制的领导协调终端根据来自数据库代理的数据库读写状态信息,对数据库集群中的单点故障进行识别,能够高效、可靠地识别数据库集群中的单点故障,从而能够解决现有技术中,分布式MySQL数据库单点故障的解决方案中存在的效率低下的问题。相比于现有技术,本申请实施例提供的技术方案操作简便、监控结果有效可靠。本申请的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本申请而了解。本申请的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。附图说明图1为现有技术中数据库集群的结构示意图;图2为本申请实施例提供的数据库集群单点故障的监控系统的结构框图;图3为本申请实施例提供的数据库集群单点故障的监控方法的流程图;图4为图2中基于分布式协调机制的领导协调终端的工作流程图;图5为本申请实施例具体实施的场景示意图。具体实施方式以下结合附图对本申请的实施例进行说明,应当理解,此处所描述的实施例仅用于说明和解释本申请,并不用于限定本申请。针对现有技术中MySQL数据集群库单点故障的解决方案中存在的效率低下、数据安全性差、系统稳定性差的问题,本申请实施例提供了一种对数据库集群中的单点故障进行监控的方案,以解决至少一个上述问题。在本申请实施例提供的方案中,设置与数据库集群中的数据库相对应的数据库代理,对应设置的数据库和数据库代理位于同一服务器上,设置至少三个基于分布式协调机制的协调终端,其中包括一个领导协调终端、其余为从属协调终端,每个数据库代理中都保存各个协调终端的IP地址和端口。数据库代理定期检测对应数据库的读写状态,并将检测结果上报给领导协调终端,领导协调终端在超过预定时限未接收到任意一个数据库的读写状态、或接收到的任意一个数据库读写状态信息为异常时,确定数据库集群中存在单点故障,能够通过由若干个数据库代理和至少三个协调终端构成的分布式结构,根据各数据库的读写状态信息来识别单点故障,从而能够简便、高效、可靠地识别数据库集群中的单点故障。在本申请实施例的优选实施例中,还能够通过领导协调终端根据各数据库的数据更新状况,指示数据库代理完成主从数据库的切换操作、以及主从数据库之间的数据同步操作,在该分布式结构中,数据库代理仅对数据库的读写状态进行设置,不对数据库中的其他数据进行操作,能够保障数据安全性;基于分布式协调机制的协调终端,能够在领导协调终端发生故障时,自动选举出新的领导协调终端,能够保障系统的稳定性和可靠性;从而能够解决现有技术中,MySQL数据库集群单点故障的解决方案中存在的效率低下、数据安全性差、系统稳定性差的问题。下面对本申请实施例进行详细说明。图2中示出了本申请实施例提供的数据库集群单点故障的监控系统的结构框图,数据库集群(X1、X2、…、Xt)中包括若干个数据库,数据库包括主库XM或从库XS,如图2所示,该系统包括:多个数据库代理221、222、…、22t,由至少三个基于分布式协调机制的协调终端211、212、…、21n构成的协调集群21,协调集群21中包括一个领导协调终端21L、其余为从属协调终端21F,其中n为奇数;一个数据库代理22i与数据库集群中的一个数据库Xi对应设置在一台服务器上,每个数据库代理22i中均保存各个协调终端的地址。图3中示出了图2所示系统的工作流程图,如图3所示,图2所示系统的工作原理包括如下处理步骤:步骤31、数据库代理22i定时检测对应数据库的读写状态,并将检测得到的数据库读写状态信息发送给领导协调终端21L;步骤32、领导协调终端21L接收来自各个数据库代理的数据库读写状态信息,在超过预定时限未接收到任意一个数据库读写状态信息,或接收到的任意一个数据库读写状态信息为异常时,确定数据库集群中存在单点故障。根据图2所示系统及其工作原理,通过数据库代理定时检测数据库集群中对应数据库的读写状态,基于分布式协调机制的领导协调终端根据来自数据库代理的数据库读写状态信息,对数据库集群中的单点故障进行识别,能够高效、可靠地识别数据库集群中的单点故障,从而能够解决现有技术中,分布式MySQL数据库单点故障的解决方案中存在的效率低下的问题。以下处理过程为图2所示系统的优选实施方式的工作流程,具体包括:步骤一、与主库XM对应的数据库代理在主库中创建主库测试表,在定时能够向主库测试表中写入一条记录、并从中读取一条记录,并且能够与主库XM的端口ping通时,确定主库XM的读写状态正常;与从库XS相对应的数据库代理在从库XS中创建测试表,在定时能够从从库测试表中读取一条记录,并且能够与从库XS的端口ping通时,确定从库XS的读写状态正常;步骤二、各数据库代理在预定的通信时刻到来时,将检测到的对应数据库的读写状态信息上报给领导协调终端21L;步骤三、领导协调终端21L判断是否超过预定时限未接收到任意一个所述数据库读写状态信息,或接收到的任意一个数据库读写状态信息为异常,在判断超过预定期限未收到主库XM读写状态信息,或者主库XM的读写状态信息为异常的情况下,处理进行到步骤四,在判断接收到的从库XS的读写状态信息为异常的情况下,处理进行到步骤十四;步骤四、领导协调终端21L确定主库XM发生单点故障,将发生单点故障的主库XM标记为旧主库X’M,通知与读写状态信息为正常的从库XS相连接的数据库代理上报所述从库XS的数据更新状况;步骤五、与从库XS对应的数据库代理根据来自领导协调终端21L的通知,获取对应从库XS的数据更新状况信息,将获取到的从库XS数据更新状况信息发送给领导协调终端21L;步骤六、领导协调终端21L根据各数据库代理上报的从库XS的数据更新状况信息,将数据更新数量最多的从库XS确定为新主库XM,指示与新主库XM对应的数据库代理将新主库XM的数据读写状态设置为可读可写;步骤七、与新主库XM对应的数据库代理根据领导协调终端21L的指示,将对应新主库XM的数据读写状态设置为可读可写;步骤八、领导协调终端21L将新主库XM的数据更新状况信息发送给与其它从库XS相连接的数据库代理;步骤九、与从库XS相连接的数据库代理根据来自领导协调终端21L的新主库XM的数据更新状况信息、以及对应从库XS的数据更新状况信息,确定对应从库XS中缺乏的数据,从新主库XM中读取所确定缺乏的数据、并将读取的数据存入到对应从库XS中;步骤十、领导协调终端21L在能够与旧主库X’M对应的数据库代理通信的情况下,指示与旧主库X’M对应的数据库代理将旧主库X’M的读写状态设置为只读,并上报旧主库X’M中的数据更新状况信息;步骤十一、与旧主库X’M对应的数据库代理根据来自领导协调终端21L的指示,将对应旧主库X’M的读写状态设置为只读,获取对应旧主库X’M的数据更新状况信息,将获取到的旧主库X’M数据更新状况信息发送给领导协调终端21L;步骤十二、领导协调终端21L将接收到的旧主库X’M的数据更新状况信息发送给其它各数据库代理;步骤十三、与新主库XM对应的数据库代理根据来自领导协调终端21L的旧主库X’M的数据更新状况信息、以及对应的新主库XM的数据更新状况信息,确定对应的新主库XM中缺乏的数据,从旧主库X’M中读取所确定缺乏的数据、并将读取的数据存入到对应新主库XM中;与从库XS对应的数据库代理根据来自领导协调终端21L的旧主库X’M的数据更新状况信息、以及对应从库XS的数据更新状况信息,确定对应从库XS中缺乏的数据,从旧主库X’M中读取所确定缺乏的数据、并将读取的数据存入到对应从库XS中,处理结束。步骤十四、领导协调终端21L在接收收到上报的从库XS读写状态信息为异常的情况下,确定从库XS发生单点故障,指示与发生单点故障的从库XS对应的数据库代理将该从库XS的读写状态设置为不可用;步骤十五、与发生单点故障的从库XS相对应的数据库代理根据来自领导协调终端21L的指示将相对应的从库XS的读写状态设置为不可用,处理结束。通过上述处理过程,领导协调终端21L能够实时高效地识别出主库XM或从库XS发生的单点故障,在主库XM发生单点故障的情况下,将从库XS中数据更新数量最多的从库XS确定为新的主库XM,指示与新主库XM对应的数据库代理完成从库XS切换为主库XM的操作;并通知与从库XS对应的各个数据库代理,根据新主库XM的数据更新状况补齐对应从库XS中缺乏的数据,在旧主库XM能够通信的情况下,通知其他数据库代理根据旧主库XM的数据更新状况补齐对应数据库中缺乏的数据,从而能够自动高效地完成数据库集群中单点故障下主从库XS的切换、以及主从数据库的数据同步处理。在本实施例提供的优选实施方式中,数据库代理仅根据领导协调的指示对数据库的读写状态进行设置,不对数据库中的其他数据进行操作,能够保障数据安全性。以下对图2中分布式协调集群21的工作原理进行说明。图4示出了图2所示系统中基于分布式协调机制的领导协调终端的工作流程图,如图4所示,领导协调终端的工作流程包括如下处理过程:步骤41、领导协调终端接收与数据库集群中的数据库对应设置的数据库代理发送的数据库读写状态信息;步骤42、领导协调终端在超过预定时限未接收到任意一个数据库读写状态信息、或接收到的任意一个数据库读写状态信息为异常时,确定数据库集群中存在单点故障。基于分布式协调机制的领导协调终端,能够根据接收到的数据库的读写状态信息来识别数据库集群的单点故障,从而能够高效可靠地识别数据库集群的单点故障。以下处理过程为协调集群21的优选实施方式的工作流程,具体包括:步骤一、领导协调终端21L与其他各从属协调终端21F进行通信,在能够与超过半数以上的从属协调终端21F进行正常通信的情况下,处理进行到步骤二,在不能与全部从属协调终端21F通信的情况下,处理进行到步骤九;步骤二、领导协调终端21L接收各个数据库代理发送的数据库读写状态信息;将接收到的数据库读写状态信息发送给各个从属协调终端21F;步骤三、领导协调终端21L判断是否超过预定时限未接收到任意一个数据库的读写状态信息、或接收到的数据库读写状态信息为异常,在判断超过预定时限未接收到主库的读写状态信息、或接收到的主库读写状态信息为异常,处理进行到步骤四,在判断超过预定时限未接收到从库的读写状态信息、或接收到的从库读写状态信息为异常,处理进行到步骤八;步骤四、领导协调终端21L确定主库发生单点故障,将发生单点故障的主库标记为旧主库,通知与读写状态信息正常的从库对应的数据库代理上报从库的数据更新状况信息;步骤五、领导协调终端21L根据各数据库代理上报的从库的数据更新状况信息,将数据更新数量最多的从库确定为新主库,指示与新主库对应的数据库代理将新主库的数据读写状态设置为可读可写;将各数据库代理上报的从库的数据更新状况信息发送给各个从属协调终端21F;步骤六、领导协调终端21L将新主库的数据更新状况信息发送给与从库对应的数据库代理,以使与从库对应的数据库代理根据新主库的数据更新状况信息,读取从库中缺乏的数据;步骤七、领导协调终端21L在能够与旧主库对应的数据库代理通信的情况下,指示与旧主库对应的数据库代理将旧主库的读写状态设置为只读、上报旧主库中的数据更新状况信息,并将与旧主库对应的数据库代理上报的旧主库的数据更新状况信息发送给与新主库对应的数据库代理和与从库对应的数据库代理;将旧主库的数据更新状况信息发送给各个从属协调终端21F;步骤八、领导协调终端21L确定从库发生单点故障,指示与发生单点故障的从库对应的数据库代理将该从库的读写状态设置为不可用;步骤九、各从属协调终端21F之间基于分布式协调机制进行通信,选举出新的领导协调终端21’L;步骤十、新的领导协调终端21’L将自身的IP地址和端口号发送给每一个数据库代理,处理返回步骤一。图2中所示的基于分布式协调机制的协调集群,在超过半数以上的协调终端之间能够通信时就能够可靠稳定的运行,并且在领导协调终端发生故障、与其他从属协调终端之间不能通信时,从属协调终端之间基于分布式协调机制进行通信,选举出新的领导协调终端,该新的领导协调终端面向数据库代理进行通信,从而能够保障图2所示监控系统的运行稳定性,相比与现有技术,能够提高监控数据库集群单点故障的稳定性和可靠性。具体地,协调集群在具体实施的过程中,可采用基于Paxos协议的Chubby实例,或者采用基于Zab协议的Zookeeper实例。下面对本申请实施例具体实施的情况进行说明。图5示出了本申请实施例具体实施的场景示意图,数据库集群中的主库拆分为2个主库XM1中和主库XM2,主库XM1中和主库XM2中的数据不交叉,主库XM1的从库为从库XS1至从库XS5,主库XM2的从库为从库XS6至从库XS7,数据库集群构成数据库集群(DBC,DataBaseCluster),2个主库XM和5个从库被部署在三个的机房中,主库XM1和从库XS1至从库XS3部署在机房A中,从库XS4和从库XS5部署在机房B中,主库XM2和从库XS6、从库XS7部署在机房C中,各数据库均为MySQL实例,对每个数据库对应设置数据库代理Agent,对应设置的Agent和数据库位于同一个服务器中,3个基于分布式协调机制的协调终端构成协调集群(DCSC,DistributedCooperationServicesCluster),DCSC中包括一个领导协调终端(Leader)、2个从属协调终端(Follower),每个协调终端均为Zookeeper实例,每个Agent中均保持各个协调终端的IP地址和端口号。图5所示系统启动时,先分别启动DBC和DCSC,与数据库位于同一服务器上的Agent后续启动,图5所示系统的工作流程包括如下处理过程:步骤一、各Agent读取相连接的数据库的IP、通信端口,将读取到的数据库的IP、通信端口号发送给DCSC的Leader;步骤二、Leader记录接收到的各数据库的IP、通信端口;步骤三、与主库相对应的AgentM1、AgentM2分别在相对应的主库XM1、XM2中创建主库测试表,在定时能够向主库测试表中写入一条记录、从中读取一条记录,并且和主库的端口ping通时,确定主库的读写状态正常;与从库相连接的AgentS1~AgentS7分别在相对应的从库中创建从库测试表,在定时能够从从库测试表中读取一条记录、并与从库的端口ping通时,确定从库的读写状态正常;步骤四、各Agent在预定的通信时刻到来时,将检测得到的对应数据库的读写状态信息上报给Leader;步骤五、Leader判断超过预定期限未收到AgentM1发送的主库XM1的读写状态信息,并且AgentS2发送的从库XS2的读写状态信息为异常;步骤六、Leader将主库XM1标记为旧主库XM’1,通知与正常存活的(即读写状态信息为正常)的从库XS1、从库XS3、从库XS4、从库XS5相连接的AgentS1、AgentS3、AgentS4、AgentS5上报从库的数据同步点记录,并指示与从库XS2相连接的AgentS2将从库XS2的读写状态设置为不可用;步骤七、AgentS1读取从库XS1的数据点同步记录为100条,AgentS3读取从库XS3的数据点同步记录为105条,AgentS4读取从库XS4的数据点同步记录为108条,AgentS5读取从库XS5的数据点同步记录为110条,AgentS1、AgentS3、AgentS4、AgentS5将读取的数据点同步记录上报给Leader;AgentS2根据Leader的指示,将从库XS2的读写状态设置为不可用;步骤八、Leader根据与上报的从库XS的数据同步点记录,将同步点位置最大的从库XS5确定为新主库XM;步骤九、Leader指示AgentS5将从库XS5的读写状态设置为可读可写;步骤九、AgentS5根据Leader的指示,将从库XS5的读写状态设置为可读可写;步骤十、Leader将从库XS5的数据同步点记录110条发送给AgentS1、AgentS3、AgentS4;步骤十一、AgentS1、AgentS3、AgentS4分别根据从库XS5的数据点同步记录,AgentS1从从库XS5中读取101条至110条数据,AgentS3从从库XS5中读取106条至110条数据,AgentS4从从库XS5中读取109条至110条数据;步骤十二、旧主库XM’1重启后,AgentM1与Leader之间重新发起通信,Leader查找与AgentM1相连接的数据库的标记,发现与AgentM1相连接的数据库为旧主库XM’1,指示AgentM1将旧主库XM’1的读写状态设置为只读、并上报旧主库XM’1中的数据同步点记录;步骤十三、AgentM1根据来自Leader的指示,将旧主库XM’1的读写状态设置为只读,在旧主库XM’1中的数据同步点记录可读取的情况下,读取旧主库XM’1中的数据同步点记录为120条,将读取的数据同步点记录为120上报给Leader;步骤十四、Leader将AgentM1上报的数据同步点记录发送给AgentS1、AgentS3、AgentS4;步骤十五、AgentS1、AgentS3、AgentS4分别根据旧主库XM’1的数据点同步记录,AgentS1、AgentS3、AgentS4从旧主库XM’1读取111条至120条数据。相类似地,如果主库2及其从库发生单点故障,也可以根据上述处理过程完成主从数据库的切换及数据同步处理。通过如图5所示的系统及其工作过程,对应将主库拆分为多套数据库的数据库集群中的单点故障,能够及时高效地自动完成数据库的切换、以及数据同步操作,根据经验统计情况,单套库的数据库集群可以在秒单位级别完成切换,对于将主库拆分为16套库的数据库集群,能够在几十秒级别完成主从数据库的切换,并且,数据库代理仅根据领导协调终端的指令对数据库的读写状态进行设置,不对数据库中的数据安全造成威胁,各协调终端基于分布式协调机制构成可靠的分布式协调集群,能够保障系统的稳定性。综上所述,本申请实施例提供的数据库集群单点故障的监控系统及其工作原理,通过由数据库代理和基于分布式协调机制的协调终端构成的分布式结构,能够自动、高效、安全、稳定、可靠地识别数据库集群的单点故障、实现主备数据库的切换、以及各数据库之间的数据同步操作。相比与现有技术中通过人工识别以及通过单点监控端来识别单点故障,能够提高识别单点故障的效率、有效地保障数据库中数据的安全性、提高对单点故障处理的可靠性和稳定性。显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本申请的精神和范围。这样,倘若本申请的这些修改和变型属于本申请权利要求及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1