一种答案推荐方法和装置与流程
技术特征:
1.一种答案推荐方法,其特征在于,包括:
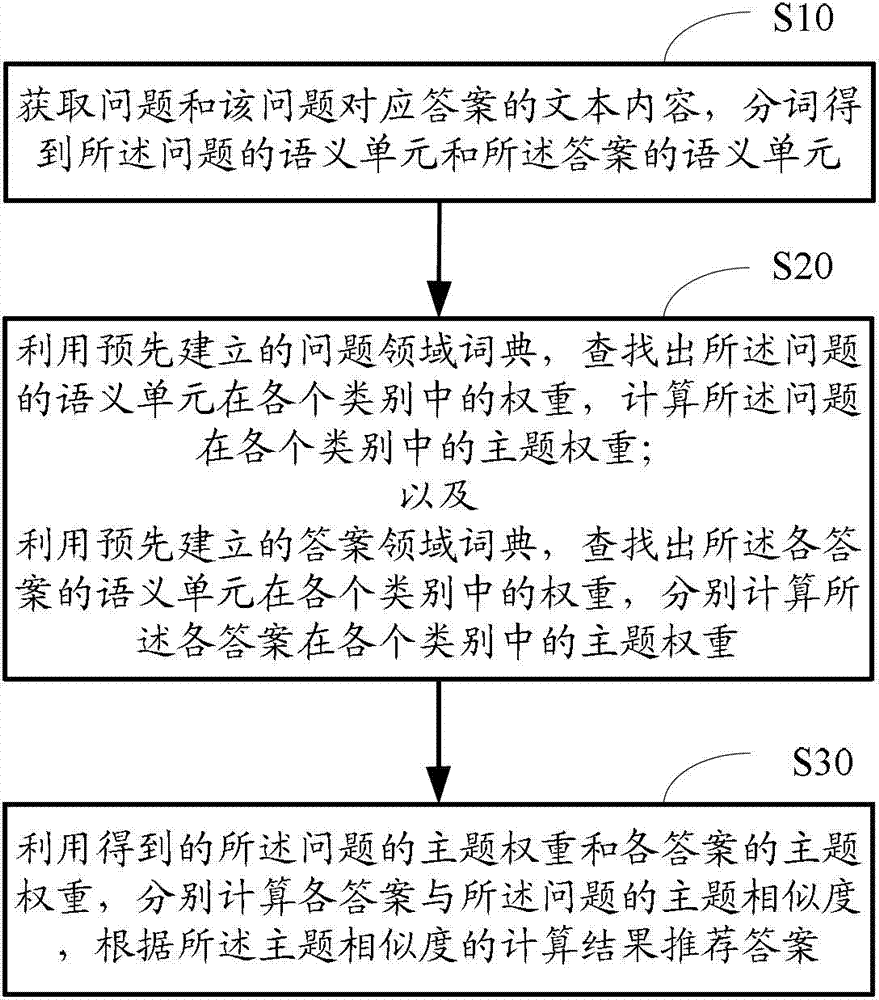
S1、获取问题和该问题对应答案的文本内容,分词得到所述问题的语义单元和所述答案的语义单元;
S2、利用预先建立的问题领域词典,查找出所述问题的语义单元在各个类别中的权重,计算所述问题在各个类别中的主题权重;
以及
利用预先建立的答案领域词典,查找出所述各答案的语义单元在各个类别中的权重,分别计算所述各答案在各个类别中的主题权重;
S3、利用得到的所述问题的主题权重和各答案的主题权重,分别计算各答案与所述问题的主题相似度,根据所述主题相似度的计算结果推荐答案。
2.根据权利要求1所述的方法,其特征在于,所述问题领域词典的建立方法,具体包括:
获取问答对语料中问题的内容,分词得到所述问题的语义单元;
分别计算所述问题的各语义单元在各个类别中的权重;
将所述各语义单元及其在各个类别中的权重形成问题领域词典。
3.根据权利要求1所述的方法,其特征在于,所述答案领域词典的建立方法,具体包括:
获取问答对语料中答案的内容,分词得到所述答案的语义单元;
分别计算所述答案的各语义单元在各个类别中的权重;
将所述各语义单元及其在各个类别中的权重形成答案领域词典。
4.根据权利要求2或3所述的方法,其特征在于,在所述得到所述问题的语义单元或答案的语义单元之后,还包括:
将词频低于预设词频阈值的语义单元过滤掉;
仅对过滤后剩余的语义单元,分别计算在各个类别中的权重。
5.根据权利要求2或3所述的方法,其特征在于,所述语义单元在各个类别中的权重根据以下所列的一种或任意组合进行计算:
所述语义单元的词频在各类别之间的差异性、所述语义单元在各类别中出现的词频或者所述语义单元的逆词频率。
6.根据权利要求5所述的方法,其特征在于,所述语义单元在各个类别中的权重计算方法为:
其中,w(tokeni,Cj)表示语义单元tokeni在类别Cj中的权重;
pij=Tij/Lj,Lj表示类别Cj中含有的所有语义单元的次数总和,Tij表示语义单元tokeni在类别Cj中出现的次数;
其中,m为类别数;
表示在语义单元tokeni在类别Cj中出现的词频,n为词频影响因子;
N表示语料中所有语义单元出现的次数总和,N(tokeni)表示语义单元tokeni出现的次数。
7.根据权利要求2所述的方法,其特征在于,在所述将各语义单元及其在各个类别中的权重形成问题领域词典之前,还包括:
对各语义单元在各个类别之间的权重进行相似权重过滤,针对同一语义单元,将在同一权重区间中出现次数大于预设阈值的权重过滤掉;
仅将语义单元在剩余类别中的权重用以形成问题领域词典。
8.根据权利要求3所述的方法,其特征在于,在所述将各语义单元及其在各个类别中的权重形成答案领域词典之前,还包括:
对各语义单元在各个类别之间的权重进行相似权重过滤,针对同一语义单元,将在同一权重区间中出现次数大于预设阈值的权重过滤掉;
仅将语义单元在剩余类别中的权重用以形成答案领域词典。
9.根据权利要求7或8所述的方法,其特征在于,所述权重区间根据所述语义单元在各个类别中的权重大小来进行设置。
10.根据权利要求2所述的方法,其特征在于,在所述将各语义单元及其在各个类别中的权重形成问题领域词典之前,还包括:
将单字、重复数字串或数字串长度超过预设长度阈值的语义单元过滤掉;
仅将过滤后剩余的语义单元用以形成问题领域词典。
11.根据权利要求3所述的方法,其特征在于,在所述将各语义单元及其在各个类别中的权重形成答案领域词典之前,还包括:
将单字、重复数字串或数字串长度超过预设长度阈值的语义单元过滤掉;仅将过滤后剩余的语义单元用以形成答案领域词典。
12.根据权利要求1所述的方法,其特征在于,所述答案与问题的主题相似度的计算方法包括:
分别计算所述答案与问题在各个类别下的主题相似度;
选取计算得到的主题相似度最大值作为所述答案与问题的主题相似度。
13.根据权利要求12所述的方法,其特征在于,所述答案与问题的主题相似度的计算方法为:
sim(query,ans)=Maxj{weight(query,Cj)×weight(ans,Cj)}
其中,sim(query,ans)表示答案与问题的主题相似度,weight(query,Cj)表示问题在类别Cj中的主题权重,weight(ans,Cj)表示答案在类别Cj中的主题权重。
14.一种答案推荐装置,其特征在于,包括:
文本获取模块,用于获取问题和该问题对应答案的文本内容,分词得到所述问题的语义单元和所述答案的语义单元;
主题权重计算模块,用于利用预先建立的问题领域词典,查找出所述问题的语义单元在各个类别中的权重,计算所述问题在各个类别中的主题权重;
以及
用于利用预先建立的答案领域词典,查找出所述各答案的语义单元在各个类别中的权重,分别计算所述各答案在各个类别中的主题权重;
相似度计算模块,用于利用所述主题权重计算模块得到的所述问题的主题权重和各答案的主题权重,分别计算各答案与所述问题的主题相似度,根据所述主题相似度的计算结果推荐答案。
15.根据权利要求14所述的装置,其特征在于,所述问题领域词典预先通过问题词典建立模块建立,所述问题词典建立模块具体包括:
问题获取子模块,用于获取问答对语料中问题的内容,分词得到所述问题的语义单元;
第一权重计算子模块,用于分别计算所述问题的各语义单元在各个类别中的权重;
第一整合子模块,用于将所述各语义单元及其在各个类别中的权重形成问题领域词典。
16.根据权利要求14所述的装置,其特征在于,所述答案领域词典预先通过答案词典建立模块建立,所述答案词典建立模块具体包括:
答案获取子模块,用于获取问答对语料中答案的内容,分词得到所述答案的语义单元;
第二权重计算子模块,用于分别计算所述答案的各语义单元在各个类别中的权重;
第二整合子模块,用于将所述各语义单元及其在各个类别中的权重形成答案领域词典。
17.根据权利要求15所述的装置,其特征在于,所述问题词典建立模块,还包括:
词频过滤子模块,用于将词频低于预设词频阈值的语义单元过滤掉;
将过滤后剩余的语义单元提供给所述第一权重计算子模块。
18.根据权利要求16所述的装置,其特征在于,所述答案词典建立模块,还包括:
词频过滤子模块,用于将词频低于预设词频阈值的语义单元过滤掉;
将过滤后剩余的语义单元提供给所述第二权重计算子模块。
19.根据权利要求15所述的装置,其特征在于,所述第一权重计算子模块根据以下所列的一种或任意组合计算所述语义单元在各个类别中的权重:
所述语义单元的词频在各类别之间的差异性、所述语义单元在各类别中出现的词频或者所述语义单元的逆词频率。
20.根据权利要求16所述的装置,其特征在于,所述第二权重计算子模块根据以下所列的一种或任意组合计算所述语义单元在各个类别中的权重:
所述语义单元的词频在各类别之间的差异性、所述语义单元在各类别中出现的词频或者所述语义单元的逆词频率。
21.根据权利要求19或20所述的装置,其特征在于,所述计算所述语义单元在各个类别中的权重的方法为:
其中,w(tokeni,Cj)表示语义单元tokeni在类别Cj中的权重;
pij=Tij/Lj,Lj表示类别Cj中含有的所有语义单元的次数总和,Tij表示语义单元tokeni在类别Cj中出现的次数;
其中,m为类别数;
表示在语义单元tokeni在类别Cj中出现的词频,n为词频影响因子;
N表示语料中所有语义单元出现的次数总和,N(tokeni)表示语义单元tokeni出现的次数。
22.根据权利要求15所述的装置,其特征在于,所述问题词典建立模块,还包括:
权重过滤子模块,用于对各语义单元在各个类别之间的权重进行相似权重过滤,针对同一语义单元,将在同一权重区间中出现次数大于预设阈值的权重过滤掉;
仅将语义单元在剩余类别中的权重提供给所述第一整合子模块,用以形成问题领域词典。
23.根据权利要求16所述的装置,其特征在于,所述答案词典建立模块,还包括:
权重过滤子模块,用于对各语义单元在各个类别之间的权重进行相似权重过滤,针对同一语义单元,将在同一权重区间中出现次数大于预设阈值的权重过滤掉;
仅将语义单元在剩余类别中的权重提供给所述第二整合子模块,用以形成答案领域词典。
24.根据权利要求22或23所述的装置,其特征在于,所述权重区间根据所述语义单元在各个类别中的权重大小来进行设置。
25.根据权利要求15所述的装置,其特征在于,所述问题词典建立模块,还包括:
语义单元过滤子模块,用于将单字、重复数字串或数字串长度超过预设长度阈值的语义单元过滤掉;
仅将过滤后剩余的语义单元提供给所述第一整合子模块,用以形成问题领域词典。
26.根据权利要求16所述的装置,其特征在于,所述答案词典建立模块,还包括:
语义单元过滤子模块,用于将单字、重复数字串或数字串长度超过预设长度阈值的语义单元过滤掉;
仅将过滤后剩余的语义单元提供给所述第二整合子模块,用以形成答案领域词典。
27.根据权利要求14所述的装置,其特征在于,所述相似度计算模块分别计算所述答案与问题在各个类别下的主题相似度,并选取计算得到的主题相似度最大值作为所述答案与问题的主题相似度。
28.根据权利要求27所述的装置,其特征在于,所述相似度计算模块计算所述答案与问题的主题相似度的方法为:
sim(query,ans)=Maxj{weight(query,Cj)×weight(ans,Cj)}
其中,sim(query,ans)表示答案与问题的主题相似度,weight(query,Cj)表示问题在类别Cj中的主题权重,weight(ans,Cj)表示答案在类别Cj中的主题权重。
- 还没有人留言评论。精彩留言会获得点赞!