基于处理器使用率动态地修正功率/性能权衡的制造方法与工艺
基于处理器使用率动态地修正功率/性能权衡
背景技术:
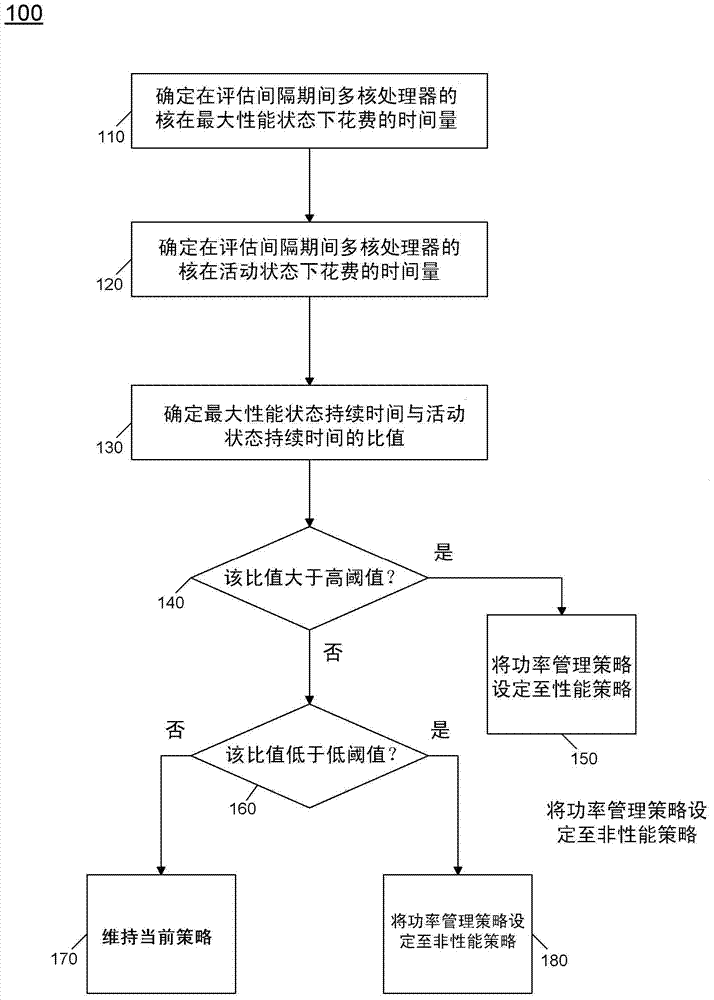
半导体加工和逻辑设计的发展已允许可存在于集成电路设备上的逻辑的量增加。结果,计算机系统配置已从系统中的单个或多个集成电路演变至多硬件线程、多核、多设备和/或单个集成电路上的完整系统。附加地,随着集成电路的密度增加,计算系统的功率需求(从嵌入式系统至服务器)也已逐步升级。此外,软件低效率及其对硬件的需要也已造成计算设备能耗的增加。事实上,一些研究表明,计算设备消耗整个国家(例如美国)的电力供给的相当大百分比。结果,对于与集成电路关联的能效和节能存在至关重要的需求。随着服务器、台式计算机、笔记本计算机、超级本、平板计算机、移动电话、处理器、嵌入式系统等设备变得越来越盛行(从纳入到典型计算机、汽车和电视机至生物技术),这些需求将增加。在许多计算环境中,已成事实的是在大多数时间例如服务器的系统在它们的峰值性能之下很好地工作。在这些低使用率周期,焦点在于节省尽可能多的功率以节省能量成本。功率管理技术可在低使用率周期期间带来显著的功率节省。然而,每种功率管理技术牵涉到功率/性能权衡,尤其是在高活动周期期间。用户理想地在低使用率下想要节省尽可能多的功率,同时在高使用率时间实现最大性能。无法忍受高使用率下的性能损失的用户一般调节功率管理特征以实现性能策略。这暗示当服务器未被充分利用时,将消耗比优化状态更多的功率。想要在低使用率下节省功率的用户一般调节功率管理特征以实现功率节省策略。这暗示当服务器被高利用时,可能无法实现服务器的最高性能。然而,在其中终端用户典型地可容忍较高性能损失的低服务器使用率时,未能实现可获得的功率节省。附图简述图1是根据本发明实施例的具有动态负载线调节的对于不同功率/性能分布的示例功率性能负载线的曲线图。图2是根据本发明实施例的方法的流程图。图3是根据本发明的一个实施例的动态切换架构的框图。图4是根据本发明实施例的确定最大性能和活动状态的时间的方法的流程图。图5是根据本发明实施例的处理器的框图。图6是根据本发明另一实施例的多域处理器的框图。图7是根据本发明实施例的系统的框图。图8是根据本发明一个实施例的具有点对点(PtP)互连的多处理器系统的框图。图9是根据本发明一个实施例的部分连接的四核处理器系统的框图。具体实施方式这些实施例提供检测处理器(例如多核处理器)的低/中等使用率的周期的机制,并响应于该检测调节功率管理特征以节省尽可能多的功率。同时,该机制可检测处理器的高使用率周期并调节功率管理特征以最小化性能损失。更具体地,提供动态负载线调节架构以实现该机制。功率性能负载线是诸如服务器之类的计算机系统在不同使用率下的功耗的表示。该负载线由此代表在每个传递的性能水平下消耗的功率并将功率管理特征对性能的影响考虑在内。图1是服务器对于功率/性能调节的不同设定的示例性功率性能负载线的图形表示。当功率/性能设定藉由性能策略10向性能倾斜时,服务器取得可能的最高性能;然而在低至中等使用率下的功耗更高。当功率/性能设定藉由功率节省策略20向功率倾斜时,在低至中等使用率下的功耗减少;然而峰值性能也降低。进而,功率/性能设定中的平衡策略30提供在功率和性能设定之间的中间立场。如本文中使用的,“功率/性能调节”的概念是以一般方式定义的。在非常一般的术语中,这表示对多功率管理特征的一组调节。术语“性能策略”表示以性能为目标的一组调节。类似地,术语“功率节省策略”用来表示以功率为目标的调节,而术语“平衡策略”用来表示在功率节省策略和性能策略之间的调节。一般来说,功率节省策略和平衡策略可被视为非性能策略。在传统系统中,这些不同的负载线是通过系统的静态配置静态地实现的。作为一个例子,操作系统(OS)可提供这三种策略中的一种的静态选择,这可通过终端用户进行配置。替代地,实施例提供在向功率倾斜的设定和向性能倾斜的设定之间动态地和自动地切换的技术。如此,在低使用率下可节省功率而在高使用率下保持性能。更具体地,实施例提供在低使用率下遵循功率节省策略20而在高使用率下则替代地经由动态负载线切换25动态地向性能策略10移动的功率性能负载线。在各实施例中,可使用动态负载线调谐算法来检测使用率点,在该使用率点下达到可供当前功率/性能调节的最大性能水平,并朝着向性能倾斜的调节来切换策略。这种最大性能水平在各实施例中是可配置的。作为基于使用率的例子,动态负载线调节可在约8瓦(W)至30W之间以及40%和70%使用率之间的任何情况下节省。也可以看出,在将近100%的使用率下,性能水平与性能策略相匹配。实施例由此在低使用率下最大化功率节省,同时在高使用率下最大化性能。尽管下面的实施例是参照例如计算平台或处理器的特定集成电路中的节能和能效来描述的,然而其它实施例适用于其它类型的集成电路和逻辑器件。本文描述的实施例的相似技术和教导可适用于可从更好的能效和节能中获益的其它类型的电路或半导体器件。例如,所披露的实施例不限于任何具体类型的计算机系统,并也可用于其它设备,例如手持设备、芯片上系统(SoC)以及嵌入式应用。手持设备的一些例子包括蜂窝电话、互联网协议设备、数字相机、个人数字助理(PDA)和手持PC。嵌入式应用一般包括微控制器、数字信号处理器(DSP)、网络计算机(上网本)、机顶盒、网络集线器、广域网(WAN)交换机或能执行下面教导的功能和操作的任何其它系统。此外,本文描述的装置、方法和系统不限于物理计算设备,而是也涉及对节能和能效的软件优化。如从下面的描述中变得更清楚的那样,本文描述的方法、装置和系统的实施例(不管是针对硬件、固件、软件或其组合)对于“绿色技术”未来是至关重要的,例如涵盖美国经济的很大一部分的产品中的节能和能效。现在参照图2,其中示出了根据本发明一实施例的方法的流程图。如图2所示,方法100可在诸如处理器的功率控制单元(PCU)的功率控制器中执行。更具体地,PCU可包括根据本发明一个实施例的动态负载线调节逻辑。如图所示,方法100可通过在评估间隔(方框110)期间确定多核处理器的核花费在最大性能状态下的时间量而开始。如下文中进一步描述的那样,可采用不同的确定该持续时间的方式。注意尽管图2的方法关于多核处理器,然而要理解本发明的范围不限于这方面,并且其它实施例等同地适用于单核处理器。如进一步看到的那样,方法100在评估间隔期间通过确定处理器核花费在活动状态下的时间量而继续(方框120)。由于这些核中的至少一个核对于评估间隔的至少一些量的时间可能处于活动状态但不是最大性能状态,因此花费在活动状态下的时间量有可能大于花费在最大性能状态下的时间量。仍然参见图2,在方框130可确定比值。更具体地,该比值可对应于最大性能状态下的持续时间与活动状态下的持续时间的比较。如此,如果两个持续时间相同,则该比值为1。如果在活动状态下花费的时间远大于在最大性能状态下花费的时间,则该比值将更接近0。这些实施例可充分利用该比值信息以确定是否在功率管理策略之间动态地切换。具体如图2中的菱形140所示,可以确定该比值是否大于第一阈值,即高阈值。尽管本发明的范围不仅限于这个方面,然而在一些实施例中,该高阈值可在大约70%和90%之间。注意,该高阈值可由用户动态地配置,例如基于系统的典型工作负载的表征。如果该比值高于该高阈值,则控制进至方框150,在那里将功率管理策略设定至性能策略。是这样的,由于在该高比值下,核在其活动的绝大多数时间处于最大性能状态,并由此系统可能从较高性能策略中获益,这尽管可能减少功率节省,但能增加吞吐量并由此可能降低总的消耗功率。仍然参见图2,如果相反该值比小于该高阈值,则控制进至菱形框160,在那里可确定该比值是否低于低阈值。尽管本发明的范围不仅限于这个方面,然而在一些实施例中,该低阈值可在大约10%和30%之间。如果该比值低于该低阈值,则控制进至方框180,在那里可将功率管理策略设定至非性能策略。否则如果该比值在这些阈值之间,则控制进至方框170,在那里可维持当前策略。注意策略的更新可通过更新配置寄存器(例如在CPU中)的值来实现。虽然在图2的实施例中示出具有该特定实现,然而要理解本发明的范围不限于此方面。随着要求的系统性能增加,操作系统请求更高的性能状态(被称为P状态)。在给定的性能状态下,如果核变得闲置,则它们进入闲置状态(被称为C状态)。这些状态可根据基于OS的机制,即先进配置和平台接口(ACIP)标准(例如2006年10月10日公布的修订版3.0b)。根据ACPI,处理器可工作在多种功率和性能状态下。对于功率状态,ACPI规定不同的功耗状态,一般指的是所谓的C1至Cn状态。当核处于活动时,其运行在C0状态,而当核处于闲置时,其处于核低功率状态、所谓的核非零C状态(例如C1-C6状态)。除了这些功率状态,处理器可进一步被配置成运行在多个性能状态中的一个下,即从P0-PN。一般来说,P1性能状态可对应于能够由OS请求的最高保证性能状态。除了该P1状态,OS可进一步请求更高的性能状态,即P0状态,该状态对应于最大性能状态。该P0状态由此可以是投机状态,其中当功率和/或热预算可用时,处理器硬件可配置该处理器或其至少一些部分以工作在比保证频率更高的频率下。随着系统使用率从中等水平移动至高水平,平均P状态增加并最终到达最大涡轮(turbo)状态。同时,可用闲置周期减少并且核在多数时间保持活动。在一个实施例中,通过检测所有核对于整个评估间隔均处于最高P状态所在的点,可推断出达到当前功率/性能设定的最高性能点。对于给定的评估周期T(Eval),当第i核在最高P状态(Pmax)下处于活动状态(例如C0)时其花费的时间被表示为T(i,C0,Pmax),并且可被称为最大活动时间。跨所有核(例如M个核)的该时间之和由此等于:T(C0,Pmax)=ΣT(i,C0,Pmax).T(C0,Pmax)的最高值等于M*T(Eval)。当T(C0,Pmax)到达其最高值时,则达到对于当前功率/性能设定的最高性能点。这是根据本发明实施例的用于动态切换检测器的原理。对于检测器,可计入两个附加的考量。首先,可使检测器不受性能的瞬时变化影响。为此,可计算出总最大活动时间度量的指数移动平均值。对第N周期计算的平均值在下面给出,其中α代表平均常数。平均T(C0,Pmax,N)=α*平均T(C0,Pmax,N-1)+(1-α)*T(C0,Pmax)第二考量是活动核的数量从一个工作负载至另一工作负载和从一个周期至另一周期地改变。为了确保检测器能适应这种变化的工作负载,可执行下列操作。在每个周期T(Eval)中,T(C0,i)代表第i核的活动时间。当跨M个核求和时,这得到T(C0)并可被称为活动时间。现在可使用与对T(C0,Pmax)求平均的相同方法来计算出第N周期的T(C0)的平均值:平均T(C0,N)=α*平均T(C0,N-1)+(1-α)*T(C0)平均T(C0,N)由此代表所有核的平均活动时间,而平均T(C0,Pmax,N)代表所有核当活动并处于最高P状态时的平均时间。在最高性能点,两个平均值将变得彼此非常靠近。由此,检测器可部分地根据下列操作来确定性能策略和非性能策略之间的最佳切换点:检测器比值=平均T(C0,Pmax,N)/平均T(C0,N)。如果检测器比值非常接近1(例如在大约80%和100%之间),则可执行向性能策略的切换。相反如果检测器比远低于1,则可作出向非性能策略的切换(基于用户配置,向功率节省策略或者向平衡策略切换)。为了确保算法是稳定的,可定义高、低阈值Threshold_High和Threshold_Low。检测器由此确定该工作点,它可用来动态地设定正确的策略。如果检测器比大于Threshold_High,则策略被设定至性能策略。如果检测器比小于Threshold_Low,则策略被设定至非性能策略,例如功率节省策略或平衡策略中的一个。替代地,OS或其它软件也可被给予选择Threshold_High和Threshold_Low值的灵活性。图3是根据本发明的一个实施例的动态切换架构的框图。如图3所示,在一个实施例中可实现在PCU电路中的动态策略切换器200可用来确定评估间隔期间处理器处于多个状态下的时间量,以给定方式比较这些持续时间,并至少部分地基于该比较和可选地基于阈值确定在下一操作间隔期间拟被运用的功率管理策略,这在一些实施例中可对应于下一评估间隔。如图所示,切换器200接收关于处理器的一个或多个核的状态改变的信息。一旦出现任何这类状态改变,就可更新最大性能累加器210和活动性能累加器220以维持其中处理器核处于给定状态的评估间隔的总持续时间之和。如图所示,该信息可被提供给累加器采样器230,该累加器采样器230可根据预定的间隔(例如每毫秒)采样来自累加器的值。同时,采样器可使累加器值重置以开始对下一评估间隔进行累加。采样器230将在评估间隔期间处理器处于最大性能状态的持续时间提供给移动平均值最大性能处理器240。另外,采样器230将与在处理器核处于活动状态的评估间隔期间的持续时间相对应的活动状态值提供给移动平均值活动状态处理器250。如图所见,这些处理器可进一步接收α值,其细节将在后面进一步讨论。基于该信息,这些处理器可产生移动平均值,这些移动平均值可以是在数个评估间隔内的多个采样器输出的平均值。例如,尽管本发明的范围不限于这个方面,然而在一些实施例中,移动平均值可以由大约5毫秒和100毫秒之间的评估间隔形成。由此,可将这些平均持续时间值提供给比较器和阈值检测器260。首先,可确定与最大性能状态的时间量与处于活动状态的总时间对应的比值。然后可将该比值与一个或多个阈值进行比较。基于该比较,可选择与前一评估间隔的功率管理策略相同的功率管理策略,或者可以是例如从非性能策略至性能策略(或相反)的动态切换。下面将描述所执行的实际计算的进一步细节。在各实施例中,最大活动状态累加器210产生所有核在(C0,Pmax)状态下花费的总时间之和。该累加器可实现在事件处理程序中,该事件处理程序每当存在任何核的C状态和/或P状态改变时被触发。事件处理程序保持两个变量,即每个核对于(C0,Pmax)状态的进入时间戳以及代表一特定核在上次调用事件处理程序时是否曾处于(C0,Pmax)状态的状态掩码。当调用事件处理程序时,其跨所有核循环并计算当前状态掩码。它将当前状态掩码与上次状态掩码比较并检测特定核退出(C0,Pmax)状态还是进入(C0,Pmax)状态还是保持如前的相同状态。当从(C0,Pmax)状态检测到退出时,从当前时间戳减去进入时间戳并将结果值加至T(C0,Pmax)累加器。如果检测到进入(C0,Pmax),则将当前时间戳存储在对于该核的上次时间戳中。当跨所有核完成这些动作时,累加器包含T(C0,Pmax)的最新值。在各实施例中,活动状态累加器220产生跨所有核在(C0)状态下花费的总时间之和。该累加器可同样实现在事件处理程序中,该事件处理程序每当存在核的C状态和/或P状态改变时被触发。事件处理程序保持两个变量,每个核对于(C0)状态的进入时间戳以及代表一特定核在上次调用事件处理程序时是否曾处于(C0)状态的状态掩码。当调用事件处理程序时,其跨所有核循环并计算当前状态掩码。它将当前状态掩码与上次状态掩码比较并检测特定核退出(C0)状态还是进入(C0)状态还是保持如前的相同状态。当从(C0)状态检测到退出时,从当前时间戳减去进入时间戳并将结果值加至T(C0)累加器。如果检测到进入(C0),则当前时间戳被存储在对于该核的上次时间戳中。当跨所有核完成这些动作时,累加器包含T(C0)的最新值。在一个实施例中,累加器采样器230可每1ms一次地对累加器进行采样。可基于期望的响应时间对该采样率作出调整。一旦对累加器进行了采样,就可将它们重置至零以允许对下一评估周期进行累加。可将采样的值存储在例如一对寄存器的给定存储区内,以分别存储T(C0,Pmax,N)和T(C0,N)。进而,处理器240、250通过使用T(C0,Pmax,N)和T(C0,N)的最新采样输入来更新这些平均值来执行指数移动平均值计算。处理器240、250可在累加器采样器以相同速率(例如每1ms一次)产生采样值之后立即产生平均值,并由此可产生平均值T(C0,Pmax)和平均值T(C0)。进而,可响应于平均值的接收而执行比较器260。在比较器260中,可计算平均值T(C0,Pmax)和平均值T(C0)之比值。然后可将该比值与高阈值和低阈值进行比较。从该比较可如前所述地产生操作策略的最终确定。尽管关于确定最大性能和活动状态的持续时间的分析是参考图3的电路和图4接下来的流程图讨论来描述的,然而要理解关于这些持续时间的确定在不同实施例中可以其它方式进行。现在参见图4,图4是根据本发明的实施例确定最大性能和活动状态的时间的方法的流程图。在一些实施例中,方法300可实现在图3的电路200中。如图所示,方法通过确定至少一个核的功率或性能状态是否已发生改变而开始(菱形框310)。可通过接收在PCU或其它功率控制器中的这种状态改变的请求而确定是否已发生上述改变。根据关于不同处理器的更新状态的这种信息,可产生当前状态掩码(方框320)。注意,可以存在多种状态掩码,即关于最大性能状态的一个和关于活动状态的一个。在方框325,可将这些掩码与之前的状态掩码进行比较。如此可确定给定核的状态是否由于方法300的上次执行已改变。因此,对于多核处理器的每个核,可执行在菱形框330开始的循环。在菱形框330,可确定给定核的状态是否已发生改变。如果是,则控制进至菱形框335,在那里可确定该状态改变是否是从最大性能状态和/或活动状态的退出。如果是,控制进至方框350,在那里可确定核在最大性能状态和/或活动状态中的停留长度。如进一步讨论的,这种确定在一些实施例中可基于时间戳信息。然后可在方框360将该确定的值累加到相应累加器中。控制然后进至菱形框365,在那里可确定是否要分析额外的核。如果是,则控制进至方框370,在那里可对核数递增,并且如前所述控制回到菱形框330。此外注意,如果在菱形框330确定给定核状态没有改变,则可在方框333完成相同的核递增,并且控制还是进至菱形框330。仍然参见图4,否则如果确定该核没有退出,则控制进至菱形框340,在那里可确定是否已发生对最大性能和/或活动状态的进入。如果是,控制进至方框345,在那里可对相应的核记录当前时间戳以指示该进入时间。控制如前所述地进至菱形框365。一旦已确定所有核的状态并相应地更新各值,控制就进至方框380,在那里可对累加器采样以获得最大性能停留值和活动状态停留值。控制然后进至方框390,在那里根据这些值产生最大性能停留和活动状态停留的平均值(例如移动平均值)。在一个实施例中,这些值可用来确定它们之间的比值,并从中可作出给定的功率管理策略选择。尽管在图4的实施例中示出具有该特定实现,然而要理解本发明的范围不限于此方面。现在参见表1,其示出根据本发明一个实施例的累加器算法伪代码。表1BitVectorLast_C0_Mask[Num_Cores];BitVectorLast_C0Pmax_Mask[Num_Cores];BitVectorCurrent_C0_Mask[Num_Cores];BitVectorCurrent_C0Pmax_Mask[Num_Cores];ArrayLast_C0_Time_Stamp[Num_Cores];ArrayLast_C0Pmax_Time_Stamp[Num_Cores];T_C0Pmax_Accumulator;T_C0_Accumulator;Current_Time_Stamp;On(P-状态或C-状态改变)://采样当前时间戳Current_Time_Stamp=Read_TSC()//捕捉当前状态掩码For(i=1;i<=Num_Cores;i++){If(current_state=C0),Current_C0_Mask[i]=1If(current_state=C0andP-state=Pmax),Current_C0Pmax_Mask[i]=1}//与前一状态比较,更新C0、Pmax累加器For(i=0;i<=Num_Cores;i++){If(Current_C0Pmax_Mask[i]=1andLast_C0Pmax_Mask[i]=0)//进入C0Pmax{Last_C0Pmax_Time_Stamp[i]=Current_Time_Stamp}Elseif(Current_C0Pmax_Mask[i]=0andLast_C0Pmax_Mask[i]=1)//从C0Pmax退出{T_C0Pmax_Accumulator+=Current_Time_Stamp–Last_C0Pmax_Time_Stamp[i]}Elseif(Current_C0Pmax_Mask[i]=1andLast_C0Pmax_Mask[i]=1)//继续在C0Pmax{T_C0Pmax_Accumulator+=Current_Time_Stamp-Last_C0Pmax_Time_Stamp[i]Last_C0Pmax_Time_Stamp[i]=Current_Time_Stamp}}//与前一状态比较,更新C0累加器For(i=0;i<=Num_Cores;i++){If(Current_C0_Mask[i]=1andLast_C0_Mask[i]=0)//进入C0{Last_C0_Time_Stamp[i]=Current_Time_Stamp}Elseif(Current_C0_Mask[i]=0andLast_C0_Mask[i]=1)//从C0退出{T_C0_Accumulator+=Current_Time_Stamp–Last_C0_Time_Stamp[i]}Elseif(Current_C0_Mask[i]=1andLast_C0_Mask[i]=1)//继续在C0{T_C0_Accumulator+=Current_Time_Stamp-Last_C0_Time_Stamp[i]Last_C0_Time_Stamp[i]=Current_Time_Stamp}}在一个实施例中,动态负载线调节算法具有三个可调节参数。α、阈值高和阈值低。在一些实施例中,这些值可在具有真实工作负载的系统中被调节,该系统可基于这些值运行在不同的使用率下以确保切换发生在最大性能下。使用本发明的实施例,终端用户可在低使用率下实现降低的功耗,并更具体地,终端用户可在低/中等使用率下选择优选的调节策略,即令目标使用率的功率节省最大化的调节。在高使用率下,处理器可动态地和自动地切换至性能策略,由此防止任何性能损失。因此,处理器可动态地检测使用率并基于使用率动态地切换功率/性能策略。如此,之前使用性能策略的用户可通过选择功率节省或平衡模式实现典型使用(例如低/中等使用率)功率节省,而不需要顾虑损失峰值性能。实施例可实现在用于多个市场的处理器中,包括服务器处理器、台式机处理器、移动处理器等等。现在参照图5,其中示出了根据本发明一实施例的处理器的框图。如图5所示,处理器400可以是包括多个核410a–410n的多核处理器。在一个实施例中,每个这样的核可处于独立功率域并可被配置成基于工作负载进入和退出活动状态和/或最大性能状态。各核可经由互连415耦合至系统代理或包含多个组件的非核(uncore)420。如所见那样,非核420可包括共享的高速缓冲存储器430,它可以是最末级高速缓冲存储器。另外,非核可包括集成的存储器控制器440、多个接口450和功率控制单元455。在各实施例中,功率控制单元455可包括动态策略切换逻辑459,它可以是基于处理器使用率执行功率管理策略的动态切换的逻辑。如进一步看到的,多个寄存器或其它存储可出现并由逻辑访问。具体地说,状态掩码存储456可存储与活动状态和最大性能状态关联的掩码,包括对于每个状态的当前和前一状态掩码,其每一个具有对于每个核的指标以指示该核是否处于相应状态下。另外,停留计数器(图5中未示出)可存在以存储累加值,该累加值可基于时间戳存储457和时间戳计数器458中的时间戳信息而产生,所述时间戳存储457可存储对于每个核的给定状态的进入时间,所述时间戳计数器458可以是维持当前系统时间戳值的计数器。进一步参见图5,处理器400可经由存储器总线与系统存储器460通信。另外,通过接口450可连接诸如外围设备、大容量存储器等多种芯片外组件。虽然在图5的实施例中示出具有该特定实现,本发明的范围不限于此方面。现在参照图6,其中示出了根据本发明另一实施例的多域处理器的框图。如图6的实施例所示,处理器500包括多个域。具体地说,核域510可包括多个核5100–510n,图形域520可包括一个或多个图形引擎,并且可进一步存在系统代理域550。在各实施例中,系统代理域550可在固定频率下执行并可在所有时间保持加电以应对功率控制事件和功率管理,由此这些域510、520可被控制以动态地进入和退出低功率状态。每个域510、520可工作在不同电压和/或功率下。注意,尽管仅示出了三个域,然而要理解本发明的范围不限于这个方面并且其它实施例中可存在附加的域。例如,可存在多核域,其每一个域包括至少一个核。一般地说,除了各执行单元和附加的处理元件外,每个核510可进一步包括低级高速缓冲存储器。进而,各核可彼此耦合并耦合至由最末级高速缓冲存储器(LLC)5400–540n的多个单元形成的共享高速缓冲存储器。在各实施例中,LLC540可在核和图形引擎以及多种媒体处理电路之中共享。如所见那样,环形互连530由此将核耦合在一起,并提供核、图形域520和系统代理电路550之间的互连。在一个实施例中,互连530可以是核域的一部分。然而在其它实施例中,环互连可以处于其本身的域。如进一步所见那样,系统代理域550可包括显示器控制器552,其可将接口的控制提供给关联的显示器。如进一步所见那样,系统代理域550可包括功率控制单元555,它可包括根据本发明实施例的动态策略切换逻辑559以基于处理器使用率动态地控制为系统提供的活动功率管理,例如使用从策略管理存储557获得的信息。在各实施例中,逻辑可执行图1、图2和图4中如前所述的算法。如图6中进一步所见的,处理器500可进一步包括集成的存储器控制器(IMC)570,它可向例如动态随机存取存储器(DRAM)的系统存储器提供接口。可存在多个接口5800–580n以允许处理器和其它电路之间的互连。例如,在一个实施例中,可提供至少一个直接媒体接口(DMI)接口以及一个或多个高速外设组件互连(PCIExpressTM(PCIeTM))接口。再进一步,为了提供诸如附加处理器或其它电路的其它代理之间的通信,根据快速通道互连(QPI)协议的一个或多个接口也可被提供。尽管在图6的实施例以这样高程度地作出表示,然而要理解本发明的范围不限于此方面。实施例可在许多不同的系统类型中实现。参照图7,其中示出了根据本发明实施例的系统的框图。如图7所示,微处理器系统600是点对点互连系统,并包括经由点对点互连650耦合的第一处理器670和第二处理器680。如图7所示,处理器670、680中的每一个可以是多核处理器,包括第一和第二处理器核(即处理器核674a和674b以及处理器核684a和684b),尽管处理器中可能存在潜在地多得多的核。如本文描述的,处理器中的每一个可包括PCU或其它逻辑以基于处理器使用率执行功率管理策略的动态控制。仍然参见图7,第一处理器670进一步包括存储器控制器中枢(MCH)672和点对点(P-P)接口676、678。类似地,第二处理器680包括MCH682和P-P接口686、688。如图7所示,MCH672、682将处理器耦合至各存储器,即存储器632和存储器634,它们可以是本地附连至各处理器的系统存储器(例如DRAM)的部分。第一处理器670和第二处理器680可分别经由P-P互连652和654耦合至芯片组690。如图7中所示,芯片组690包括P-P接口694和698。此外,芯片组690包括通过P-P互连639将芯片组690耦合至高性能图形引擎638的接口692。进而,芯片组690可经由接口696耦合至第一总线616。如图7所示,各输入/输出(I/O)设备614可耦合至第一总线616以及总线桥618,该总线桥618将第一总线616耦合至第二总线620。各设备可耦合至第二总线620,所述设备包括例如键盘/鼠标622、通信设备626和数据存储单元628,所述数据存储单元628在一个实施例中例如是可包括代码630的盘驱动器或其它大容量存储设备。此外,音频I/O624可耦合至第二总线620。实施例可纳入其它类型的系统,包括诸如智能蜂窝电话、平板计算机、上网本、超级本之类的移动设备。图8是使用QPI链路作为系统互连根据给定的高速缓冲存储器相关协议与点对点(PtP)系统互连耦合的系统的方框图。在图示实施例中,每个处理器710耦合至两个PtP链路725,并包括集成存储器控制器715的一个实例,该集成存储器控制器715进而耦合至系统存储器720的对应本地部分。每个处理器可如本文所述地执行在不同的功率管理策略之间的动态切换。处理器可使用一个链路连接至输入/输出中枢(IOH)730,并且剩下的链路被用来连接两个处理器。参照图9,其中示出了根据本发明另一实施例的系统的框图。如图9所示,系统800可以是部分连接的四核处理器系统,其中每个处理器810(其每一个可以是多核多域处理器)经由PtP链路耦合至每一其它处理器,并经由存储器互连耦合至存储器的本地部分(例如动态随机存取存储器(820)),该存储器互连耦合至对应处理器的集成存储器控制器815。在图9的部分连接系统中,注意存在两个IOH830、840,以使处理器8100、8101直接地耦合至IOH830并且处理器8102、8103类似地直接耦合至IOH840。实施例可以代码的形式实现,而且可存储在其上存储有指令的非瞬态存储介质上,这些指令可用于对系统编程以执行这些指令。存储介质可包括但不限于:包括软盘、光盘、固态驱动器(SSD)、压缩盘只读存储器(CD-ROM)、可重写压缩盘(CD-RW)以及磁光盘的任何类型的盘;诸如只读存储器(ROM)、诸如动态随机存取存储器(DRAM)、静态随机存取存储器(SRAM)之类的随机存取存储器(RAM)、可擦写可编程只读存储器(EPROM)、闪存、电可擦写可编程只读存储器(EEPROM)之类的半导体器件;磁卡或光卡,或适合于存储电子指令的任何其他类型的介质。虽然已经针对有限个实施例描述了本发明,但本领域技术人员将会理解从中得出的多种修改和变化。所附权利要求旨在覆盖落入本发明的真实精神和范围中的所有这些修改和变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1