一种基于语义的海量数据处理方法与流程
技术特征:
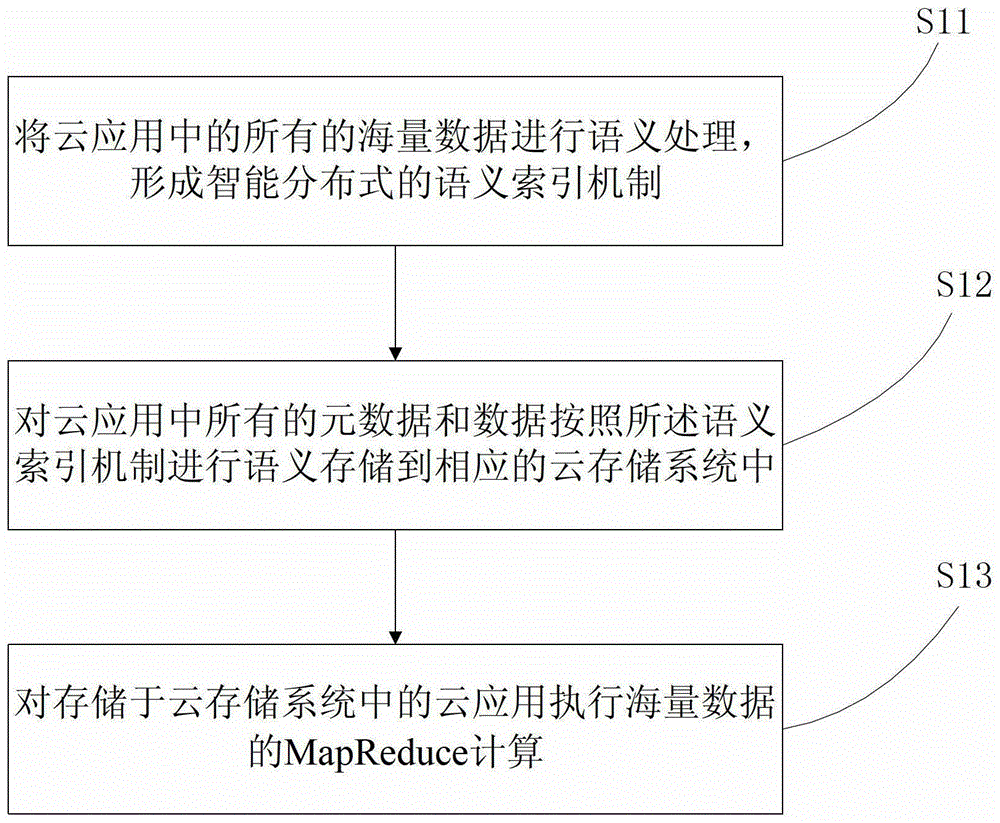
1.一种基于语义的海量数据处理方法,其特征在于,其包括以下步骤:A、对不同的云应用,分别将所述云应用中的所有的海量数据进行语义处理,形成智能分布式的语义索引机制;B、对云应用中所有的元数据和数据按照所述语义索引机制进行语义存储到相应的云存储系统中,以使具有语义关联的数据存储紧密;所述步骤B包括以下步骤:B1、按照所述语义索引机制获得子云应用;B2、对所述子云应用的元数据分配到元数据服务器,其具体包括以下情况:B21、若子云应用的数量小于元数据服务器的数量,则每个子云应用的元数据均分配一个元数据服务器;B22、若子云应用的数量等于元数据服务器的数量,则每个子云应用的元数据均分配一个元数据服务器;B23、若子云应用的数量大于元数据服务器的数量,则按照以下步骤执行元数据库服务器的分配:B231、给每个元数据服务器均先分配一个子云应用的元数据;B232、剩余的子云应用的元数据继续按照一个子云应用的元数据对应分配给一个元数据服务器的方式进行分配,分配过程中,须使每个元数据服务器的元数据之和均衡;B233、重复步骤B232,直到将所有的子云应用的元数据分配完成;B3、将子云应用的数据分配到数据存储节点集群,其具体包括以下步骤:B31、计算每个子云应用的负载,并将所有的子云应用的负载求和获取负载和,根据所述数据存储节点集群的具体数量计算出每台数据存储节点的平均存储负载;B32、列出子云应用中所有负载位于平均存储负载阈值范围内的所有子云应用,并将这些满足条件的子云应用的数据分配到一台数据存储节点中;B33、计算子云应用的负载之和位于平均存储负载阈值范围内的所有子云应用,并将这些满足条件的子云应用的数据分配到一台数据存储节点中;B34、将子云应用的负载大于平均存储负载阈值的所有子云应用进行分割,分割后的负载尽量均位于平均存储负载阈值的范围内,并将分割后的子云应用所对应的所有数据分配至不同的数据存储节点;B35、重复步骤B31-B34,直到所有的子云应用的数据分配完成;C、对存储于云存储系统中的云应用执行海量数据的MapReduce计算。2.根据权利要求1所述的基于语义的海量数据处理方法,其特征在于,所述平均存储负载阈值为[90%平均存储负载,110%平均存储负载]。3.根据权利要求2所述的基于语义的海量数据处理方法,其特征在于,所述子云应用为将一社区网络按照社会网络算法得到的子社区,其中,所述社区网络为各种基于社会网络的数据密集型应用的文件通过一个聚类或者社会网络算法得到的。4.根据权利要求3所述的基于语义的海量数据处理方法,其特征在于,所述社会网络算法为聚类算法。5.根据权利要求1所述的基于语义的海量数据处理方法,其特征在于,所述子云应用为将本体网络或标记网络进行分割,让有联系的元数据文件集中在一起,同时对该有联系的元数据文件进行相应的聚合而形成的相应的语义聚合对,其中,所述本体网络或标记网络为根据各种语义算法对各种来自分类的密集型应用的文件进行语义计算得到的。6.根据权利要求1所述的基于语义的海量数据处理方法,其特征在于,所述海量数据包括海量结构化数据、海量半结构化数据以及海量非结构化数据。7.根据权利要求6所述的基于语义的海量数据处理方法,其特征在于,所述云存储系统包括用来存储海量非结构化数据的云文件系统、以及用于存储海量结构化数据和海量半结构化数据的云数据库系统。8.根据权利要求7所述的基于语义的海量数据处理方法,其特征在于,所述云文件系统包括单一Master节点的云文件系统,以及大于一个Master节点的Master集群的云文件系统。9.根据权利要求7或8所述的基于语义的海量数据处理方法,其特征在于,所述云数据库系统包括单一Master节点的云数据库系统,以及大于一个Master节点的Master集群的云数据库系统。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1