短文本垃圾识别以及建模方法和装置与流程
技术特征:
1.一种短文本垃圾识别方法,其特征在于,包括:对待判定短文本进行分词得到词语集合,并对所述待判定短文本进行垃圾特征分析得到分析信息;将所述待判定短文本的分析信息以及词语集合中每个词语分别与预先确定的特征元素集合中的特征元素进行比较,根据与所述特征元素集合中的特征元素相匹配的词语或分析信息的特征值,生成所述待判定短文本的词语特征向量;根据所述待判定短文本的词语特征向量,以及预先训练出的分类模型,确定所述待判定短文本是否为垃圾文本;其中,所述分析信息包括如下任一信息,或如下信息的任意组合:是否包含联系方式特征的信息、干扰性符号的占比信息、生僻字的占比信息、繁体字符的占比信息、词语间的转移概率、前后词的词性间转移概率、名词的占比信息、动词的占比信息、标点符号的占比信息、一元词的占比信息、二元词的占比信息、不同词性词汇搭配比例、标点符号与名词的数量比例信息;以及所述分析信息的特征值具体包括:对于所述是否包含联系方式特征的信息,其特征值为二值的0或1;对于所述干扰性符号的占比信息、或生僻字的占比信息、或繁体字符的占比信息、或词语间的转移概率、或前后词的词性间转移概率、或名词的占比信息、或动词的占比信息、或标点符号的占比信息、或一元词的占比信息、或二元词的占比信息、或不同词性词汇搭配比例、或标点符号与名词的数量比例信息,其特征值为0~1之间的数值。2.如权利要求1所述的方法,其特征在于,在所述生成所述待判定短文本的词语特征向量之前,还包括:对与所述特征元素集合中的特征元素相匹配的分析信息的特征值进行归一化:将其中是否包含联系方式特征的信息的特征值归一化为二值的0或100;将其中干扰性符号的占比信息、或生僻字的占比信息、或繁体字符的占比信息、或词语间的转移概率、或前后词的词性间转移概率、或名词的占比信息、或动词的占比信息、或标点符号的占比信息、或一元词的占比信息、 或二元词的占比信息、或不同词性词汇搭配比例、或标点符号与名词的数量比例信息的特征值乘以100,得到0~100之间的归一化数值。3.如权利要求1或2所述的方法,其特征在于,所述词语的特征值根据如下方法得到:计算该词语的TF、IDF值,并根据如下公式1计算出该词语的特征值:log(TF+1.0)×IDF(公式1)。4.如权利要求1或2所述的方法,其特征在于,所述分类模型的训练方法,以及所述特征元素集合的确定方法包括:对于训练集中已区分为垃圾文本,或非垃圾文本的每个短文本,进行分词后得到该短文本的词语集合,并对该短文本进行垃圾特征分析后得到该短文本的分析信息;针对所述训练集中的每个短文本,计算该短文本的词语集合中每个词语的特征值,并计算该短文本的分析信息的特征值后,对计算出的特征值求取类别区分度;将类别区分度大于设定阈值的词语,以及分析信息作为所述特征元素集合中的特征元素;针对所述训练集中的每个短文本,将该短文本的分析信息以及词语集合中每个词语分别与所述特征元素集合中的特征元素进行比较,根据与所述特征元素集合中的特征元素相匹配的词语或分析信息的特征值,生成该短文本的词语特征向量;根据所述训练集中各短文本的词语特征向量训练出所述分类模型。5.如权利要求4所述的方法,其特征在于,所述根据所述训练集中各短文本的词语特征向量训练出所述分类模型具体为:运用SVM分类算法、或贝叶斯分类算法、或决策树分类算法、或最大熵分类算法,根据所述训练集中各短文本的词语特征向量训练出所述分类模型。6.一种建模方法,其特征在于,包括:对于训练集中已区分为垃圾文本,或非垃圾文本的每个短文本,进行分词后得到该短文本的词语集合,并对该短文本进行垃圾特征分析后得到该短文本的分析信息;针对所述训练集中的每个短文本,计算该短文本的词语集合中每个词语的特征值,并计算该短文本的分析信息的特征值后,对计算出的特征值求取类别区分度;将类别区分度大于设定阈值的词语,以及分析信息作为特征元素集合中的特征元素;针对所述训练集中的每个短文本,将该短文本的分析信息以及词语集合中每个词语分别与所述特征元素集合中的特征元素进行比较,根据与所述特征元素集合中的特征元素相匹配的词语或分析信息的特征值,生成该短文本的词语特征向量;根据所述训练集中各短文本的词语特征向量训练出分类模型;其中,所述分析信息包括如下任一信息,或如下信息的任意组合:是否包含联系方式特征的信息、干扰性符号的占比信息、生僻字的占比信息、繁体字符的占比信息、词语间的转移概率、前后词的词性间转移概率、名词的占比信息、动词的占比信息、标点符号的占比信息、一元词的占比信息、二元词的占比信息、不同词性词汇搭配比例、标点符号与名词的数量比例信息;以及所述分析信息的特征值具体包括:对于所述是否包含联系方式特征的信息,其特征值为二值的0或1;对于所述干扰性符号的占比信息、或生僻字的占比信息、或繁体字符的占比信息、或词语间的转移概率、或前后词的词性间转移概率、或名词的占比信息、或动词的占比信息、或标点符号的占比信息、或一元词的占比信息、或二元词的占比信息、或不同词性词汇搭配比例、或标点符号与名词的数量比例信息,其特征值为0~1之间的数值。7.如权利要求6所述的方法,其特征在于,在所述计算该短文本的分析信息的特征值后,以及所述根据与所述特征元素集合中的特征元素相匹配的词语或分析信息的特征值,生成该短文本的词语特征向量之前,还包括:对该短文本的分析信息的特征值进行归一化:将所述是否包含联系方式特征的信息的特征值归一化为二值的0或100;将所述干扰性符号的占比信息、或生僻字的占比信息、或繁体字符的占比信息、或词语间的转移概率、或前后词的词性间转移概率、或名词的占比信息、或动词的占比信息、或标点符号的占比信息、或一元词的占比信息、或二元词的占比信息、或不同词性词汇搭配比例、或标点符号与名词的数量 比例信息的特征值乘以100,得到0~100之间的归一化数值;以及所述根据与所述特征元素集合中的特征元素相匹配的词语或分析信息的特征值,生成该短文本的词语特征向量具体为:根据与所述特征元素集合中的特征元素相匹配的词语或分析信息的归一化后的特征值,生成该短文本的词语特征向量。8.如权利要求6或7所述的方法,其特征在于,所述根据所述训练集中各短文本的词语特征向量训练出所述分类模型具体为:运用SVM分类算法、或贝叶斯分类算法、或决策树分类算法、或最大熵分类算法,根据所述训练集中各短文本的词语特征向量训练出所述分类模型。9.一种建模装置,其特征在于,包括:特征提取模块,用于对于训练集中已区分为垃圾文本,或非垃圾文本的每个短文本,进行分词后得到该短文本的词语集合,并对该短文本进行垃圾特征分析得到该短文本的分析信息;特征元素集合确定模块,用于针对所述训练集中的每个短文本,计算该短文本的词语集合中每个词语的特征值,并计算该短文本的分析信息的特征值后,对计算出的特征值求取类别区分度;将类别区分度大于设定阈值的词语,以及分析信息作为特征元素集合中的特征元素;特征向量确定模块,用于针对所述训练集中的每个短文本,将该短文本的分析信息以及词语集合中每个词语分别与所述特征元素集合中的特征元素进行比较,根据与所述特征元素集合中的特征元素相匹配的词语或分析信息的特征值,生成该短文本的词语特征向量;分类模型构建模块,用于根据所述特征向量确定模块确定出的所述训练集中各短文本的词语特征向量,构建分类模型;其中,所述分析信息包括如下任一信息,或如下信息的任意组合:是否包含联系方式特征的信息、干扰性符号的占比信息、生僻字的占比信息、繁体字符的占比信息、词语间的转移概率、前后词的词性间转移概率、名词的占比信息、动词的占比信息、标点符号的占比信息、一元词的占比信息、二元词的占比信息、不同词性词汇搭配比例、标点符号与名词的数量比例信息;以及所述分析信息的特征值具体包括:对于是否包含联系方式特征的信息,其特征值为二值的0或1;对于干扰性符号的占比信息、或生僻字的占比信息、或繁体字符的占比信息、或词语间的转移概率、或前后词的词性间转移概率、或名词的占比信息、或动词的占比信息、或标点符号的占比信息、或一元词的占比信息、或二元词的占比信息、或不同词性词汇搭配比例、或标点符号与名词的数量比例信息,其特征值为0~1之间的数值。10.如权利要求9所述的装置,其特征在于,所述特征向量确定模块具体用于针对所述训练集中的每个短文本,将该短文本的分析信息以及词语集合中每个词语分别与所述特征元素集合中的特征元素进行比较,根据与所述特征元素集合中的特征元素相匹配的词语或分析信息的归一化后的特征值,生成该短文本的词语特征向量。11.一种短文本垃圾识别装置,其特征在于,包括:特征提取模块,用于对于待判定短文本进行分词后得到词语集合,并对所述待判定短文本进行垃圾特征分析得到分析信息;特征向量确定模块,用于将所述待判定短文本的分析信息以及词语集合中每个词语分别与预先确定的特征元素集合中的特征元素进行比较,根据与所述特征元素集合中的特征元素相匹配的词语或分析信息的特征值,生成所述待判定短文本的词语特征向量;垃圾识别模块,用于从所述特征向量确定模块获取所述待判定短文本的词语特征向量后,根据所述待判定短文本的词语特征向量,以及预先训练出的分类模型,确定所述待判定短文本是否为垃圾文本;其中,所述分析信息包括如下任一信息,或如下信息的任意组合:是否包含联系方式特征的信息、干扰性符号的占比信息、生僻字的占比信息、繁体字符的占比信息、词语间的转移概率、前后词的词性间转移概率、名词的占比信息、动词的占比信息、标点符号的占比信息、一元词的占比信息、二元词的占比信息、不同词性词汇搭配比例、标点符号与名词的数量比例信息;以及所述分析信息的特征值具体包括:对于是否包含联系方式特征的信息,其特征值为二值的0或1;对于干扰性符号的占比信息、或生僻字的占比信息、或繁体字符的占比 信息、或词语间的转移概率、或前后词的词性间转移概率、或名词的占比信息、或动词的占比信息、或标点符号的占比信息、或一元词的占比信息、或二元词的占比信息、或不同词性词汇搭配比例、或标点符号与名词的数量比例信息,其特征值为0~1之间的数值。12.如权利要求11所述的装置,其特征在于,所述特征向量确定模块具体用于将所述待判定短文本的分析信息以及词语集合中每个词语分别与预先确定的特征元素集合中的特征元素进行比较,根据与所述特征元素集合中的特征元素相匹配的词语或分析信息的归一化后的特征值,生成所述待判定短文本的词语特征向量。
相关技术
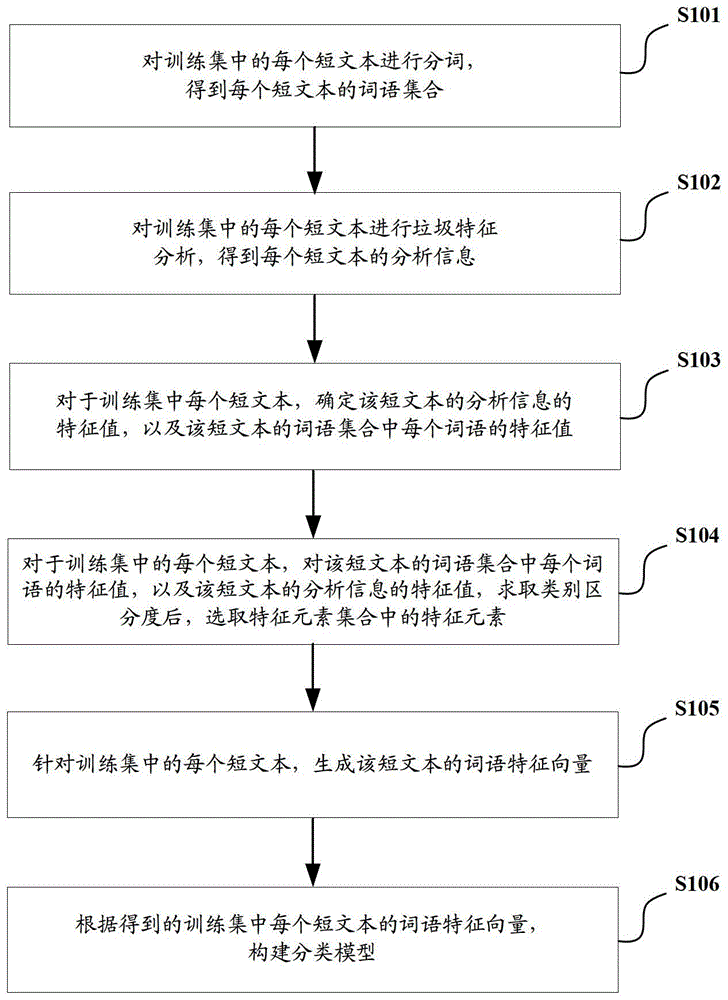
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1