基于在线自中心模型的动态网络分析系统及方法与流程
本发明关于一种动态网络分析系统及方法,特别是涉及一种基于在线自中心模型的动态网络分析系统及方法。
背景技术:
网络分析,特别是动态网络分析(DynamicNetworkAnalysis,即DNA)在包括社会科学与生物学在内的许多领域中已经显得越来越重要。虽然现在已经有不少关于动态网络分析的工作,但是其中绝大多数要不就是只关注极粗的细粒度下的大规模数据,要不就是只关注在一个很小的网络中的微细粒度的分析。近年来,有人提出了动态自中心模型(DynamicEgocentricModel,即DEM),这个模型基于多变量计数过程并成功地对微细粒度的大规模的时变引用网络进行建模。一般来说,在DEM原文中,有两个DEM的变种:一个只对链接特征进行建模,另一个同时对链接特征与话题特征(文本信息)进行建模。由于后者的准确度远高于前者并且一篇文章的文本信息是较容易得到的,除非特殊说明,在本发明中的DEM指的是后者。以下简单介绍DEM:n是网络中节点(文章)的总数。DEM试图通过在每个节点i(i=1,2,…,n)上放置一个计数过程Ni(t)以对动态网络进行建模。其中Ni(t)表示节点i上″事件″的截止时间t的累计发生次数。这里″事件″的定义要取决于上下文。比如,在引用网络中,一个″事件″可以对应着一次引用。虽然可以最大化这些计数过程的全概率,推出一个连续时间的模型,但是对于引用网络来说,显然通过最大化偏概率的方法来估计那些与时变统计量相关的参数会更加实际。所以DEM试图最大化下面整个网络的likelihood:其中m是引用事件的总次数,e是每次引用事件的索引,ie表示在事件e中被引用的文章,te表示事件e发生的时间,Yi(t)的值当节点i在时间t存在是为1,否则为0。si(te)表示节点i在时间te的特征向量。β是需要学习的参数向量。si(te)中的向量可以分为两类。一类称为″链接特征(统计量)″,另一类称为″话题特征″。在DEM中有8个链接特征,包括三个preferentialattachment统计量、三个triangle统计量与两个out-path统计量。另外还通过对文章的摘要运行LDA对每篇文章提取了50个话题特征。更具体地,假设在时间te新到的文章为i,可以如下计算任何已有文章j的话题特征:其中θi表示文章i的话题比例,о为向量间的元素逐项相乘。由上可知,si(te)是一个含有58个特征的向量,其中前8个特征为链接特征,后面50个为话题特征。对应地,β为一个长度为58的参数向量。然而,虽然在动态网络的预测过程中,DEM能够动态地更新节点(在原文中表示文章)的链接特征,但DEM学习出来的参数β与话题特征θi在预测过程中却是固定的。因此,DEM随着时间的推移,预测的准确度会严重地下降,因为实际上话题特征与参数都应该是随着时间变化的。比如,模型的链接特征之一是截至某个时间点节点的入度(文章被引用的次数),随着时间的推移,一篇文章的被引用次数会变得越来越多,因此整个数据集中引用数的分布也会随着时间而改变,这样的结果就是,对应这个特征的参数,甚至是其他参数,也应该跟着改变。另外,关于话题特征,虽然乍一看,一篇文章的话题特征会随着时间改变可能显得有点不可思议,因为按常理来讲,一篇发表的文章的文字都是不会随着时间改变的,然而,引用这篇文章的许多文章却时时在变化。因此,将引用信息与文本内容信息结合起来决定一篇文章的话题特征要更加合理。比如,一篇关于神经网络的文章在20世纪50年代可能会被认为是与心理学或者生物学高度相关的,但是在今天,它却更可能被划分为关于机器学习的文章,因为几十年来有越来越多发表的文章引用了它。由此可知,一篇文章的话题特征显然是会随着时间改变的,只是幅度的大小不同而已。由于无法对时变的参数与话题参数建模,DEM并没法很好地对动态网络进行精确的建模从而使得预测的准确度会随着时间而下降。
技术实现要素:
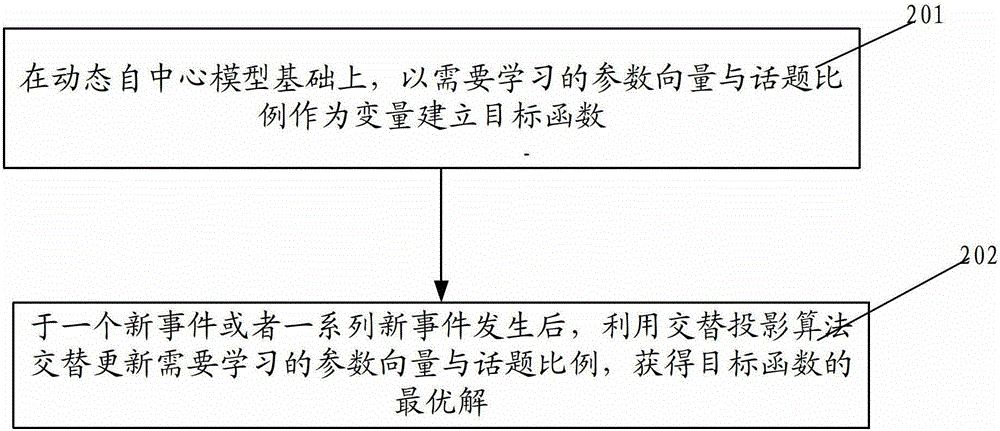
为克服上述现有技术存在的不足,本发明之目的在于提供一种基于在线自中心模型的动态网络分析系统及方法,其通过对时变的话题特征与模型参数进行建模,从而使得模型随着时间推移预测的准确度不会下降。为达上述及其它目的,本发明提出一种基于在线自中心模型的动态网络分析系统,至少包括:目标函数建立模组,在动态自中心模型基础上,以需要学习的参数β与话题比例ωk作为变量建立目标函数;目标函数最小化模块,于一个新事件或者一系列新事件发生后,利用交替投影算法交替更新该需要学习的参数向量β与该话题比例ωk,获得目标函数的最优解。进一步地,该目标函数为:其中ωk是待学习的节点k的新话题比例,θk是节点k当前的话题比例,表示ωk中的每一个元素都是非负的,1是一个元素全为1的向量,这些限制用于保证ωk中的所有元素都是非负的而且元素和为1,λ是一个控制两个项之间权重的超参数。进一步地,该目标函数最小化模块包括:β参数更新模块,于固定话题比例ω后使用牛顿法更新参数需要学习的参数β;话题比例更新模块111,于固定β后在当前话题比例θk的基础上,最小化该目标函数以获得更新后的话题比例ωk。进一步地,该β参数更新模块与该话题比例更新模块在每q次引用事件后更新一次。该β参数更新模块在固定ω后,需要学习的参数β的目标函数如下:其中x是mini-batch中的第一个事件,q是mini-batch中的事件数,mini-batch为累积的事件集合。进一步地,该话题比例更新模块每一次只更新一篇文章的话题比例ωk,在更新ωk时,其他文章的话题比例{ωi|i≠k}保持不变。进一步地,该话题比例更新模块需优化的目标函数为:其中,进一步地,该话题比例更新模块根据对需优化的目标函数偏导获得近似梯度,根据近似梯度得到目标函数的近似目标函数。为达到上述及其他目的,本发明还提供一种基于在线自中心模型的动态网络分析方法,包括如下步骤:步骤一,在动态自中心模型基础上,以需要学习的参数向量β与话题比例ωk作为变量建立目标函数;步骤二,于一个新事件或者一系列新事件发生后,利用交替投影算法交替更新该需要学习的参数向量与话题比例,获得目标函数的最优解。进一步地,该目标函数为:其中ωk是待学习的节点k的新话题比例,θk是节点k当前的话题比例,表示ωk中的每一个元素都是非负的,1是一个元素全为1的向量,这些限制用于保证ωk中的所有元素都是非负的而且元素和为1,λ是一个控制两个项之间权重的超参数。进一步地,该步骤二包括如下步骤:步骤1.1于固定话题比例ω后使用牛顿法更新参数需要学习的参数β;步骤1.2于固定β后在当前话题比例θk的基础上,最小化该目标函数以获得更新后的话题比例ωk;重复步骤1.1及步骤1.2直至符合终止条件。进一步地,该步骤二在每q次引用事件后更新一次。进一步地,该步骤1.1在固定ω后,需要学习的参数β的目标函数如下:其中x是mini-batch中的第一个事件,q是mini-batch中的事件数,mini-batch为累积的事件集合。进一步地,该步骤1.2每次只更新一篇文章的话题比例ωk,在更新ωk时,其他文章的话题比例{ωi|i≠k}保持不变。进一步地,于步骤1.2中,需优化的目标函数为:其中,进一步地,于步骤1.2中,对该需优化的目标函数偏导获得近似梯度,根据近似梯度得到目标函数的近似目标函数。与现有技术相比,本发明一种基于在线自中心模型的动态网络分析系统及方法以对时变的动态网络进行建模,通过随着时间调整学习模型参数与话题特征,使得本发明克服了DEM的缺点,避免了DEM存在的准确率随着时间严重下降的问题。附图说明图1为本发明一种基于在线自中心模型的动态网络分析系统的系统架构图;图2为本发明一种基于在线自中心模型的动态网络分析方法的步骤流程图;图3为图2之步骤202的细部步骤流程图;图4为本发明之实验结果比较示意图。具体实施方式以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。图1为本发明一种基于在线自中心模型的动态网络分析系统的系统架构图。如图1所示,本发明一种基于在线自中心模型(OEM)的动态网络分析系统,至少包括:目标函数建立模组10以及目标函数最小化模块11。其中,目标函数建立模组10在动态自中心模型基础上,以需要学习的参数向量β与话题比例ωk作为变量建立目标函数。虽然可以从整个文章的集合中完整地学习LDA(LatentDirichletallocation,三层贝叶斯概率模型),但是显然如果直接使用在线的LDA模型的话会十分的耗费时间。因此,在本发明中,先固定话题后再学习话题比例θ。因为在引用网络中,即使一些文章本身的话题比例会随着时间而改变,主要的话题是相对稳定不变的,所以这么做是合理的。需说明的是,在本发明实施例中,只需要在每隔一段比较长的时间更新全部的话题。从实验可以看出,这样做依然可以达到很好的准确度。因此,在本发明较佳实施例中,目标函数为:其中ωk是待学习的节点k的新话题比例,θk是节点k当前的话题比例,L(β,ω)的定义与DEM的式子(1)中的L(β)相同,除了这里将β与话题比例都作为变量(注意L(β,ω)与L(β)是不同的,在L(β)中,只有β是变量而ω是常数)。表示ωk中的每一个元素都是非负的,1是一个元素全为1的向量,这些限制用于保证ωk中的所有元素都是非负的而且元素和为1。λ是一个控制两个项之间权重的超参数。目标函数最小化模块11,于一个新事件或者一系列新事件发生后,利用交替投影算法(altematingprojection)交替更新需要学习的参数向量β与话题比例,获得目标函数的最优解。当一个新事件或者一系列新事件被观察到,式子(2)中的第二项会保证更新后的话题比例ωk不会距离目前的话题比例θk太远。除此之外,本发明使用旧的β作为初始值来更新β。显然可见,式子(2)的优化问题并不是对(β,ω)联合凸的。但是可以证明这个目标函数是在一个变量固定时,关于另外一个变量是凸的。于是本发明设计了一个交替投影算法(altematingprojection)以找出目标函数的最优解。具体地说,目标函数最小化模块11进一步包括:β参数更新模块110以及话题比例更新模块111,其中,β参数更新模块110,于固定话题比例ω后使用牛顿法更新参数需要学习的参数β,初始化用的是当前的β;话题比例更新模块111,于固定β后在当前话题比例θk的基础上,最小化目标函数以获得更新后的话题比例ωk。β参数更新模块110与话题比例更新模块111往往需要重复几次直到符合终止条件。需说明的是,每次一篇新文章i出现,可以将它加入原引用网络中后马上使用利用β参数更新模块110与话题比例更新模块111直至收敛。但是,这对于大规模的引用网络来说是十分耗时间的。因此,在本发明中,可以等新文章积累到一定数量后才开始更新。这种mini-batch技巧不仅可以节省计算时间,而且可以减少噪声的影响。因此在本发明之较佳实施例中,β参数更新模块110与话题比例更新模块111在每q次引用事件后更新一次而非每次事件后更新一次。q在实验中设置为1500左右具体地说,β参数更新模块110在固定ω后,需要学习的参数β的目标函数如下:其中x是mini-batch中的第一个事件,q是mini-batch中的事件数。为了避免在更新β时遍历所有之前的引用事件,本发明用了一个训练窗口,使得在训练参数β时只需要考虑引用事件中的一个比较小的子集。若训练窗口的宽度为Wt(1≤Wt≤q),可以通过优化下面式子来学习β:而且本发明还可以缓存每个节点的链接特征以进一步减小计算负担,正如DEM所做的。由于一次性地更新ω中的所有话题比例将会极其耗费时间,话题比例更新模块111每一次只更新一篇文章的话题比例ωk,在更新ωk时,其他文章的话题比例{ωi|i≠k}保持不变。如果在一个大小为q的mini-batch中,节点k在引用事件e1,e2,...,ep中被引用而在时间ep+1,ep+2,...,eq没有被引用(注意e2发生的时间不一定在ep+2之前,虽然前者的下标较后者小),这里,需要优化的目标函数f(ωk)是:其中这里,βl包含着参数β的前8个元素(对应着链接特征),βt包含着参数β的后50个元素(对应的是话题特征),θi是引用事件ei的引用者的话题比例,是引用事件ei中的节点k的链接特征(前8个特征),Cu是一个与ωk无关的常数。式子(3)的一阶与二阶偏导如下:其中I是单位矩阵。从上面式子可以看出Hessian矩阵正定(PD)的,因此(3)的函数是凸的。此时,可以直接使用solver来找到全局最优解。较佳的,在式子(4)中,Ai远大于与且p在每个batch中都相对较小。同理,Bu远大于与而(q-p)也相对较小。因此,(4)中的第二与第三项要远小于其它两项。这意味着可以删去较小的两项以得到一个近似的梯度:基于上面的近似梯度,可以恢复(2)的近似目标函数:本发明将(5)这个OEM的变种称为″近似OEM"(approximativeOEM),而将原来的OEM称为″满OEM″(fullOEM)。在实验中可以发现近似OEM可以达到与满OEM接近的准确度而需要少很多的时间。图2为本发明一种基于在线自中心模型的动态网络分析方法的步骤流程图。如图2所示,本发明一种基于在线自中心模型的动态网络分析方法,包括如下步骤:步骤201,在动态自中心模型基础上,以需要学习的参数向量β与话题比例ωk作为变量建立目标函数。在步骤201,建立的目标函数为:其中ωk是待学习的节点k的新话题比例,θk是节点k当前的话题比例,L(β,ω)的定义与DEM的式子(1)中的L(β)相同,除了这里将β与话题比例都作为变量(注意L(β,ω)与L(β)是不同的,在L(β)中,只有β是变量而ω是常数)。表示ωk中的每一个元素都是非负的,1是一个元素全为1的向量,这些限制用于保证ωk中的所有元素都是非负的而且元素和为1。λ是一个控制两个项之间权重的超参数。步骤202,于一个新事件或者一系列新事件发生后,利用交替投影算法(alternatingprojection)交替更新需要学习的参数向量β与话题比例,获得目标函数的最优解。当一个新事件或者一系列新事件被观察到,式子(2)中的第二项会保证更新后的话题比例ωk不会距离目前的话题比例θk太远。除此之外,本发明使用旧的β作为初始值来更新β。显然可见,式子(2)的优化问题并不是对(β,ω)联合凸的。但是可以证明这个目标函数是在一个变量固定时,关于另外一个变量是凸的。于是本发明设计了一个交替投影算法(alternatingprojection)以找出目标函数的最优解。更具体地,每次迭代中,我们固定两个变量中的一个并更新另一个。具体地说,步骤202进一步包括如下步骤(如图3所示):步骤301,在线β步骤(onlineβstep):固定ω后使用牛顿法更新参数β,初始化用的是当前的β;步骤302,在线话题步骤(onlinetopicstep):固定β后在当前话题比例θk的基础上,最小化式子(2)以获得更新后的话题比例ωk。上述过程需要重复几次直到符合终止条件。需说明的是,每次一篇新文章i出现,可以将它加入原引用网络中后马上使用利用β参数更新模块110与话题比例更新模块111直至收敛。但是,这对于大规模的引用网络来说是十分耗时间的。因此,在本发明中,可以等新文章积累到一定数量后才开始更新。这种mini-batch技巧不仅可以节省计算时间,而且可以减少噪声的影响。因此在本发明之较佳实施例中,每q次引用事件后更新一次而非每次事件后更新一次。q在实验中设置为1500左右在在线β步骤中,在固定ω后,需要学习的参数β的目标函数如下:其中x是mini-batch中的第一个事件,q是mini-batch中的事件数。为了避免在更新β时遍历所有之前的引用事件,本发明用了一个训练窗口,使得在训练参数β时只需要考虑引用事件中的一个比较小的子集。若训练窗口的宽度为Wt(1≤Wt≤q),可以通过优化下面式子来学习β:而且本发明还可以缓存每个节点的链接特征以进一步减小计算负担,正如DEM所做的。由于一次性地更新ω中的所有话题比例将会极其耗费时间,在线话题步骤中,设计了一个交替的算法来更新ω。更具体地,每一次只更新一篇文章的话题比例ωk,在更新ωk时,其他文章的话题比例{ωi|i≠k}保持不变。如果在一个大小为q的mini-batch中,节点k在引用事件e1,e2,...,ep中被引用而在时间ep+1,ep+2,...,eq没有被引用(注意e2发生的时间不一定在ep+2之前,虽然前者的下标较后者小)。这里需要优化的目标函数f(ωk)是:其中这里,βl包含着参数β的前8个元素(对应着链接特征),βt包含着参数β的后50个元素(对应的是话题特征),θi是引用事件ei的引用者的话题比例,是引用事件ei中的节点k的链接特征(前8个特征),Cu是一个与ωk无关的常数。式子(3)的一阶与二阶偏导如下:其中I是单位矩阵。从上面式子可以看出Hessian矩阵正定(PD)的,因此(3)的函数是凸的。此时,可以直接使用solver来找到全局最优解。较佳地,在式子(4)中,Ai远大于与且p在每个batch中都相对较小。同理,Bu远大于与而(q-p)也相对较小。因此,(4)中的第二与第三项要远小于其它两项。这意味着可以删去较小的两项以得到一个近似的梯度:基于上面的近似梯度,可以恢复(2)的近似目标函数:本发明将(5)这个OEM的变种称为″近似OEM″(approximativeOEM),而将原来的OEM称为″满OEM″(fullOEM)。在实验中可以发现近似OEM可以达到与满OEM接近的准确度而需要少很多的时间。由于在每次迭代中,学习的算法保证目标函数的值总是下降,而且目标函数值总是大于等于0,因此本发明是收敛的。以下将通过将现有技术的DEM与本发明之OEM应用于两个引用网络并比较两个模型的实验结果来说明本发明的进步性,同时还分析了文章话题比例的演变。1、数据集引用网络分析是动态网络分析中最重要的应用之一,在本发明实验中,用的是两个引用网络的数据集arXiv-TH与arXiv-PH。两个数据集都是从arXiv(http://snap.stanford.edu/data)爬取的。数据集的主要信息见表1。表1数据集信息arXiv-TH数据集是关于高能物理理论的一系列文章。时间的范围是1993年到1997年,这个数据集有很高的时间解析度(精确到毫秒)。arXiv-PH数据集是关于高能物理现象的一系列文章,时间范围为1993年到1997年,时间精确到每天。由于数据集中的时间解析度非常高,可以假设每篇新文章都在不同的时间加入到网络中而且显然同一个时间中可能有不止一个引用事件。正如前一节提到的,一个batch一个batch地更新话题比例与参数。更具体地,本发明将数据集划分成一个个的mini-batch,每个mini-batch中包含着在一段时间中发生的引用时间。对于arXiv-TH每个mini-batch中的时间戳数为100,而对于arXiv-PH是20。对应与每一个mini-batch的事件数大约为1500。2、基线在实验中,比较了下面4个模型的性能:(1)DEM:原来的有8个链接特征与50个话题特征的DEM。注意原来的DEM并不是在线(online),参数与话题特征在训练后是固定的。(2)OEM-β:只带有在线β步的OEM,这个模型中,β会随时间更新但是话题特征不会。(3)OEM-full:带有在线β步与话题步的满OEM,话题特征与参数都会随着时间改变,使用了目标函数(2)。(4)OEM-appr:带有在线β步与近似话题步的OEM,话题特征与参数都会随着时间改变,使用了目标函数(5)。3、评测标准与DEM类似,本发明用下面三个标准来评测上面的模型:(1)平均测试log-likelihood(Averageheld-outlog-likelihood):在每个测试引用事件中对式子(1)中的likelihoodL(β)取log后即可得到测试log-likelihood。将所有测试事件的测试log-likelihood的和除以本batch中事件的总数,即可以得到平均测试log-likelihood。这个数值越高,则说明测试准确度越高。(2)召回率@K(Recalloftop-Krecommendationlist):这里的召回率定义为K个最可能的引用事件中真实发生的比例。这里的K是一个切分点(cut-point)。(3)平均测试正规排名(Averageheld-outnormalizedrank):这里每个引用事件的排名(rank)指的是这个引用在已排序好的推荐列表中的实际位置。这个排名除以可能引用事件的总数即得到正规化(normalize)后的排名。这个数值越低,表示预测性能越好。4、结果与分析如DEM,本发明将每个数据集分为三个部分:建立阶段、训练阶段与测试阶段。建立阶段主要是为了建立起引用网络的统计量,一般它的时间范围会较长以缓解截断效应(1993年前的引用时间没有出现在数据集中)并避免bias。在训练阶段中,我们训练出初始的模型参数与话题特征。为了更加全面的展示并比较模型的预测性能,这里的测试阶段比较长。测试阶段被划分为24个batch。注意统计量(链接特征)在训练阶段与测试阶段中都是会动态改变的。每个阶段的数据大小(用引用事件数表示)如表2所示。表2数据集建立、训练、测试阶段的分割为了进一步减少OEM训练与测试的时间,在每个batch中只随机选取了一部分的时间中的引用事件来优化文章的话题比例。比如当优化文章i的话题比例时,在第1个batch到达后,随机选取10%(这里将10%称为citer百分比,下文亦然)的引用者(citer)而不是全部引用者。这可以一定程度加速计算。在OEM中,设超参数λ=0.1,设citer百分比为10%,除非另外说明。超参数citer百分比与λ对模型的影响会在接下来的实验中具体说明。OEM的测试过程的细节如下。先用建立阶段与训练阶段的数据训练一个初始的OEM。显然此时这个初始的OEM等价于DEM。然后评测这个模型在Batch1的预测性能(注意到我们在训练时并没有用到Batch1的数据)。之后再将Batch1的数据吸收为额外的训练数据并更新OEM的参数与特征。然后再接着使用现在这个已更新的OEM来预测Batch2。由此可见,在测试某一个batch之前,并没有将这个batch的数据用于训练。因此测试的结果会真实地反映OEM的泛化/预测能力。图4(a)和(b)是所有模型的平均测试log-likelihood。由于初始的OEM与DEM是等价的,可以看到所有的模型在测试Batch1时的性能都是相同的。然而,随着时间的推移,DEM的预测性能会严重地下降,而OEM的各个变种则不会。比如,从图4(a)可以看出,DEM的log-likelihood随着时间下降十分明显,而OEM-β只是从-8.24下降到-8.97。OEM-full的预测能力超过了前面两个模型,log-likelihood的范围是-7.89到-8.38。OEM-appr则从-8.24下降到-8.56。图4(a)与(b)是测试引用事件的平均测试log-likelihood。(c)与(d)前K推荐列表中的召回率。(e)与(f)为平均测试正规排名。由于所有的模型在建立阶段与训练阶段后的初始参数相同,它们在第1个测试batch的性能是相同的。这个从(a)到(f)可以看到。(g)与(h)是在第8001与第8005个时间点是被引用的两个文章集的话题演变。为了防止图像的混乱,我们只画出了比例最高的前几个话题。图4(c)和(d)是前K推荐列表中的召回率,K取值250。可以发现DEM、OEM-β与OEM-appr的性能都随着时间而下降,然而OEM-full却不会。虽然OEM-appr的预测性能也会随着时间下降,但是它的性能依然明显超过DEM。OEM-β的性能与DEM差不多,都不理想。这意味着话题特征的信息量是十分大的,只是更新β是远不够的。注意K取其他值时也可以得到相似的结果,由于篇幅所限这里不予讨论。图4(e)与(f)是平均测试正规排名。可以发现DEM与OEM-β的性能无法随着时间而提高。而OEM-full与OEM-appr则可以。注意排名数值越低意味着预测能力越高。与前面相似,OEM-β的不理想效果进一步说明了话题特征的更新对这一项评测标准的重要性。因为越到后面的batch,候选的引用事件数会越多,如果用绝对的排名,DEM的性能实际上是随着时间而下降的。但是\mbox{OEM-full}却可以防止性能的下降,即使是从绝对排名的角度来看。这个与图4(a)、(b)、(c)与(d)的结果相符。表3比较了OEM与近似OEM的计算消耗。由表可知,虽然近似OEM比满OEM预测性能稍差,但是却节省了50%的时间。表3λ=0.1时OEM-full与OEM-appr的计算时间(秒)表4citer百分比为10%时的平均测试log-likelihood表5λ=0.1时的平均测试log-likelihood为了研究超参数(citer百分比与λ)对预测性能的影响,本发明使用arXiv-TH数据集并计算了citer百分比与λ取不同值时所有测试batch的平均测试log-likelihood。结果详见表4与表5。由表4可知,0.1为λ的最优值。从表5可以看出在citer百分比大于10%后,预测性能随着citer百分比的提高较小,而时间消耗却有很大的增加,这意味着选择10%为citer百分比是合理的。总而言之,模型OEM对于这些超参数并不敏感。本发明从arXiv-TH数据集中选择了2个文章集合来说明文章的话题演变。为了避免混乱对每个文章集合的话题比例取平均,图中只画出了平均的话题比例。由于话题数共有50个,只选择了占的比例最大的话题。具体地说,令St={r1,r2,...,rl}表示在时间t被引用的文章集合(同一个集合中的文章被用一篇文章引用)。则是文章集合St的平均话题向量。这里选择了S8001与S8005作为说明的例子,如图4(g)与(h)。从图4(g)可知,话题7的比例(即)与话题46的比例(即)是随着时间下降的。然而话题15的比例与话题44的比例则相反。一个解释是这个在第8001个时间点被引用的文章集合原来是关于某个物理学的子领域,但是随着时间的推移,这些文章的价值被其他子领域的研究者发现了。再被其他子领域的文章引用了足够多次之后,这个文章集合的话题开始从原话题(话题7与话题46)向新话题(话题15与话题44)转移。同样的事情会发生在统计学、心理学等领域(原领域)与机器学习等领域(新领域)上面。在第8005个时间点被引用的文章集合(S8005)的话题演变与第8001个时间点的类似,如图4(h)所示。综上所述,本发明一种基于在线自中心模型的动态网络分析系统及方法以对时变的动态网络进行建模,通过随着时间调整学习模型参数与话题特征,使得本发明克服了DEM的缺点,避免了DEM存在的准确率随着时间严重下降的问题,在两个真实数据集上的实验结果表明,本发明在实际应用中能达到十分可观的预测性能。虽然本发明的实验仅限于文章引用网络,如DEM所说,本发明也可以适用于其他类型的网络,本发明不以此为限。上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1