全篇专利文献翻译方法及翻译系统与流程
本发明涉及机器翻译技术,尤其涉及全篇专利文献的机器翻译方法及翻译系统。
背景技术:
机器翻译是使用计算机实现从一种自然语言文本到另一种自然语言文本的翻译。其研究方法分为规则和统计两种。由于规则系统开发周期长,资金和人力的需求大,所以规则系统进展缓慢。相对而言,统计方法开发周期短、便于处理大规模语料等优点而显出优势。在统计机器翻译方法中,基于短语的翻译方法得到充分的发展。但从目前看,对于专业的领域的翻译来说,比如在专利文档的翻译中,较长的短语常常被分词为几个短语进行翻译。例如,“所述超低温热封聚丙烯流延膜,...”,可能会被分词为“所述”、“超低温”、“热”、“封”、“聚丙烯”和“流延膜”。而在专利文献撰写中,“所述”后的词语通常是固定的,其本身就可以看为一个固定短语,所以能将“超低温热封聚丙烯流延膜”作为一个短语整体进行处理,则只需要一次分析和翻译,就可以在此专利文献中出现该短语时直接套用。另外,对于复杂短语,在句法分析的时候,会由于上下语境的不同而产生不同的短语分词结果,造成同一篇专利文档中译文前后不一致,但对于专利文献来说,很多复杂短语是固定的,在全文中会多次出现,因此只要在全文范围内识别出这样的短语,就可以在全文翻译中直接套用其译文,而不必再对同样的内容进行分析。公开号为CN103116578A的中国专利申请,公开一种融合句法树和统计机器翻译技术的机器翻译方法与装置,该方法首先建立不同语种语言之间的词典库、语法规则库、短语翻译概率表以及目标语语言模型,然后对原文输入句子进行切分、词性消兼和语法分析,生成句法树,然后采用自顶向下的策略遍历该句法树,对单个节点和部分跨句法的连续节点,取其叶节点的原文与统计机器翻译所训练出的短语翻译概率表进行智能匹配,利用短语翻译表的译文和目标语言的语言模型来达到提高输出译文流利度和准确度的目的。此方法对短语的提取不是基于全文的,因此会存在同样的短语翻译不一致以及多次分析、翻译的情况。因此,在现有技术的翻译过程中,复杂名词短语不能保持一致性,同时,同一短语被多次地分析、翻译,耗时费力。
技术实现要素:
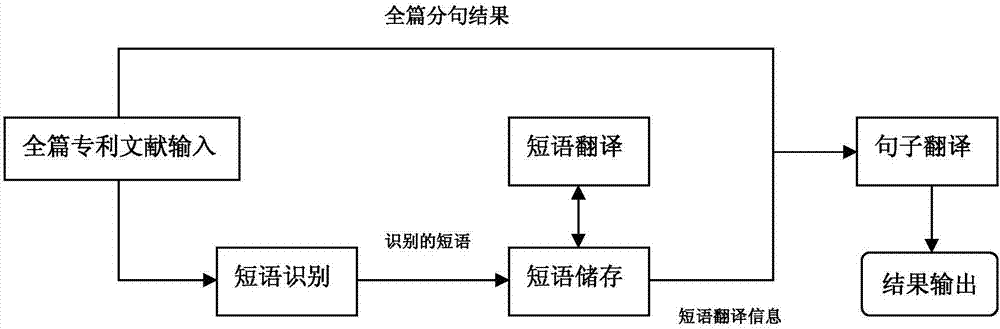
为了克服现有的缺陷,本发明提出一种全篇专利文献的机器翻译方法和系统。根据本发明的一个方面,提出了一种全篇专利文献的机器翻译方法,该方法包括以下步骤:A步骤:针对文献全文,识别出各级标题信息并标注;B步骤:对全文进行词法分析,得到分词和词性标注信息;C步骤:根据B步骤的分词和词性标注信息进行短语识别,得到识别名词短语RNP并将该识别名词短语RNP翻译成目标语言;和D步骤:以句子为单位进行翻译,对于标注为RNP的短语直接使用步骤C所得的译文,翻译完毕后,按原文标题顺序输出。根据本发明的另一个方面,提供了一种机器翻译系统,包括:输入模块,用于接收并分析文献全文,首先识别各级标题,然后进行词法分析,标注分词、词性信息;短语识别模块,所述短语识别模块用于得到识别名词短语RNP短语翻译模块,所述短语翻译模块翻译识别名词短语,并保存在短语存储器中;全文翻译模块,所述全文翻译模块对全文逐句翻译,对于识别名词短语RNP不再进行句法展开,直接从短语存储器中取译文;和输出模块,所述输出模块将翻译结果按原标题顺序输出。本发明提供一种全篇专利全文机器翻译方法和翻译系统,解决了现有技术中常用复杂名词短语翻译不一致及翻译效率低的问题。附图说明本发明的上述及其它方面和特征将从以下结合附图对实施例的说明清楚呈现,在附图中:图1是全篇专利文献机器翻译方法流程图;图2是句法分析结果图;图3是短语翻译器句法分析的一个例子;图4是全篇专利文献机器翻译系统的结构图;图5是短语识别模块的工作流程图;和图6是短语翻译模块的工作流程图。具体实施方式下面结合附图和具体实施例对本发明提供的一种全篇专利文献机器翻译方法和系统进行详细描述。如图1所示,图1提供了专利文献机器翻译方法总体技术方案实现流程图。该方法包括以下步骤:A步骤:接收全文,识别各级标题信息、XML标签信息、特征内容并标注;B步骤:对全文进行词法分析,得到分词和词性标注信息;其中,根据需要还可以进行浅层句法分析或完整的句法分析;C步骤:根据B步骤的分词结果对短语进行提取、判定、识别和修正,得到识别名词短语RNP;翻译识别名词短语RNP并存放在短语存储器中;D步骤:以句子为单位进行翻译,翻译时遇到标注为RNP的短语,直接从短语存储器中取译文,不再对短语进行分析,翻译完后按原文标题顺序输出译文。在步骤A中,专利内容部分包括名称、摘要、权利要求书、说明书(技术领域、
背景技术:
、
技术实现要素:
、附图说明、具体实施方式);标注的方法举例如下:权利要求1可以标注为<claiml>。在步骤C中,包括以下步骤:C01步骤:短语提取;C02步骤:短语判定;C03步骤:短语识别和修正;C04步骤:为全文中出现的所有该短语标注RNP标签;和C05步骤:短语翻译。在步骤C01中,短语提取可以使用模板提取方法,即通过一些设定的边界信息,利用模板进行短语提取。【例1】一种用于控制飞机飞行的系统,其特征在于,...可以将“一种”、“其特征在于”作为起始边界信息,利用模板:{一种}+{短语A}+{,其特征在于},提取短语“用于控制飞机飞行的系统”。短语提取方法还可以为规则提取方法,即利用词性标注特征POS(part-of-speech)加前后缀组合方法进行短语提取,撰写的规则例子如下:(-1)CAT(V)+(0)CAT[N]+(1)Suffix→NP[0,1]。【例2】...提供词性标注方法其中,后缀为“方法”,词性标注特征为:提供/v词性/n/标注/nv方法/n。将后缀“方法”与“词性/n/标注/nv”结合,得到短语“词性标注方法”。短语提取方法可以为计算权重法,对其权重进行打分,如果其权重高于设定值,比如0.5×ω*,则判定为候选短语,ω*为当前专利文档中短语权重的最大值。此外,在计算ω*时,要排除在停用高频短语列表中的短语。权重打分方法可以为TF-IDF法:其中ωNP为短语的权重,fNP为短语在全文中的频率(其计算公式根据上文中公式),nNP为在专利文档库中出现的该短语的文档数,N为专利文档库中文档数。打分方法还可以为TFC法:其中,ωNP为短语的权重,fNP为短语在全文中的频率(其计算公式根据上文中公式),nNP为在专利文档库中出现该短语的文献数,N为专利文档库中文档数。∑NP表示对全文中所有短语求和。打分方法还可以为ITC法:其中,ωNP为短语的权重,fNP为短语在全文中的频率(其计算公式根据上文中公式),nNP为在专利文档库中出现该短语的文档数,N为专利文档库中文档数,∑NP表示对全文中所有短语求和。权重打分方法还可以为TF-IWF法:ωNP为短语的权重,fNP为短语在全文中的频率(其计算公式根据上文中公式),CNP为短语在全文中出现的次数,∑NP表示对全文中所有短语求和。在计算出权重之后,根据短语出现的位置设置位置权重系数βi,对权重进行调整,公式如下:【公式1】ω*=ω*βi其中βi为位置权重系数。βi根据其在分析处理阶段(A步骤)中识别出的各标题部分的位置信息,取不同的值,具体如下:β1表示说明书摘要、
背景技术:
、具体实施方式部分的权重;β2表示权利要求、技术领域部分的权重;β3表示附图说明部分的权重;β4表示标题、权利要求主题名称部分的权重。βi取值范围的关系满足不等式1:β1<β2<β3<β4βi优选为:0.1<β1<0.60.2<β2<0.80.3<β3<0.90.5<β4<1且满足不等式1所限定的取值范围。βi更加优选为:β1=0.4β2=0.5β3=0.6β4=0.8停用高频短语列表是通过计算短语频,降序排列后取排名1至排名n的短语而构成,计算短语频率的公式为:【公式2】其中fNPL表示该短语在专利文档库L中的频率,CNPL为该短语在专利文档库中出现的次数,CL表示专利文档库中所有短语出现的总次数,计算公式为:【公式3】表示专利文档库中短语i出现的次数。排名n为20-1000,优选为50-500,更优选为100。该专利文档库可以是大于或等于一万篇的专利文档库,优选与所述被翻译的专利文档技术领域相同或相似的专利文档库。进一步地,在步骤C01中可以使用上述三种方式的任意组合来进行短语提取。在步骤C02中,短语判定方法可以为短语频率方法,即计算专利全文中该短语出现的频率,按照设定的选择阈值ε,如果出现频率小于该阈值,则该短语不属于候选短语。短语频率的计算公式为:【公式4】其中,fNP为该短语的频率,CNP为该短语在专利全文中出现的次数,C为专利全文中所有短语出现的总次数。C的计算公式为:【公式5】其中,Ni为短语i在专利全文中出现的次数。阈值ε的计算公式为:【公式6】更优选为:【公式7】最优选为:【公式8】其中,NALL为全篇专利文献中短语的总个数。同时,查询该短语是否存在于停用高频短语列表中,若存在,则该短语不属于候选短语。短语判定方法还可以是修正的短语频率法,计算方法为:【公式9】fNP′=fNP*βi其中βi为位置权重系数,具体的取值在前面已有描述。短语判定方法还可以为记忆鉴定方法,首先从一个专利文档库的所有专利全文中提取短语,经过人工判定等方式得到正确的短语,存入记忆库。判定时,使用边际编辑距离算法和最长公共字串法对提取的短语与记忆库中的短语进行比较,生成候选短语。进一步地,短语判定方法还可以是上述3种方法的任意组合。对于多种判定方法,可以通过投票法对结果进行选择。所述投票法表示用多种方法获得的短语中,取相同结果数量最多的一种。例如,有两种方...
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1