基于半监督哈希的图像检索方法与流程
本发明属于图像处理领域,更进一步涉及图像的检索方法,可有效的对图像进行编码,提高图像的检索精度。
背景技术:
随着计算机技术、数字多媒体技术及互联网技术的飞速发展,人们对信息检索的需求也日益扩大。图像作为信息的载体,含有丰富的内容,给人们的生产和生活带来了极大的便利。如何迅速有效的搜索到所需要的图像,成为当前的研究热点之一。为了在大数据中快速有效地检索到用户所需要的图像,人们对原始图像进行编码,用一定长度的哈希码来表示图像。由于计算机中数据的存储及处理均是哈希码,因此使用哈希码能够大大加快信息检索速度。天格科技(杭州)有限公司提出的专利申请“一种基于局部敏感哈希的相似人脸快速检索方法”(申请号:201310087561.5,公开号:CN103207898A)公开了一种基于局部敏感哈希的人脸图像检索方法。该方法通过人脸区域检测、眼睛和嘴巴特征检测和特征提取、肤色检测、人脸肤色分布特征提取等步骤将图像表示为人脸特征向量,然后利用局部敏感哈希方法对人脸特征向量构建索引,从而提高查询时的速度。该方法存在的不足是:局部敏感哈希方法是一种数据无关的哈希方法,随机性很强,并且为了保证较好的检索精度,需要的编码位数很长,因此在实际应用中有很大的限制。浙江大学提出的专利申请“基于稀疏降维的谱哈希索引方法”(申请号:201010196539.0,公开号:CN101894130A)公开了一种基于稀疏表达和拉普拉斯图的哈希索引方法。该方法首先提取图像底层特征,进一步通过聚类得到视觉单词,然后利用有权重的拉普拉斯-贝尔特拉米算子的特征方程和特征根,求得欧式空间到汉明空间的映射函数,得到低维空间汉明向量。该方法用稀疏降维方式代替谱哈希的主成分分析降维方式,增加了结果的可解释性。但是,该专利申请提出的方法存在的不足之处是:该方法仍没有避免谱哈希模型中强制训练数据服从均匀分布的前提假设,使其应用价值受到限制。YunchaoGong和SvetlanaLazebnik在文章“IterativeQuantization:AProcrusteanApproachtoLearningBinaryCodes”(IEEEConferenceonComputerVisionandPatternRecognition,2011,pp.817-824)中提出一种迭代量化方法,该方法首先对图像提取底层特征,然后使用主成分分析方法对底层特征降维,得到低维特征,然后对低维特征旋转并量化得到图像的编码。该方法存在的不足是:该方法的前提假设是底层特征服从高斯分布,但实际数据可能并不服从高斯分布,并且该方法没有使用数据的类标,从而使得检索精度降低。
技术实现要素:
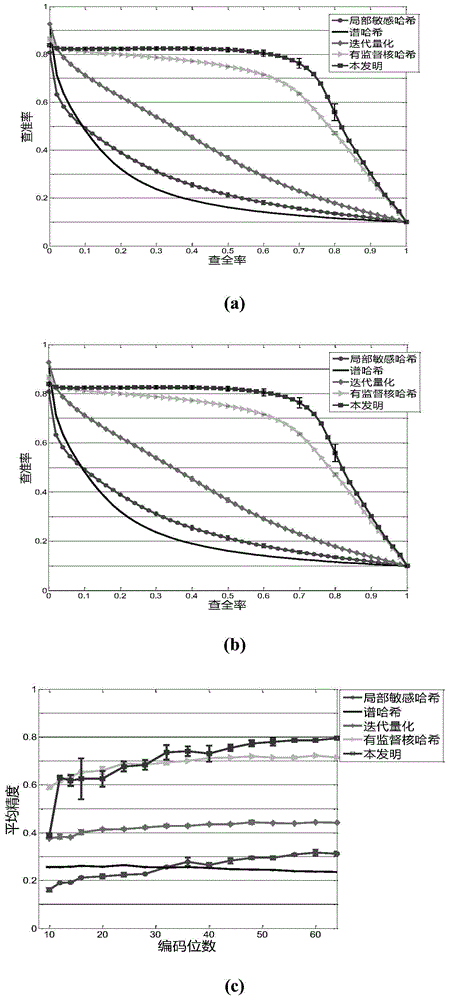
本发明的目的在于针对上述已有技术的不足,提出一种基于半监督哈希的图像检索方法,以节省哈希编码的存储空间,降低检索的时间复杂度,有效提高图像检索的查准率与查全率。实现本发明的技术方案是:对原始图像提取底层特征,通过类标传递对底层特征标记,使用支持向量机对标记后的底层特征分类,根据分类结果对图像编码,达到充分利用少量类标数据,得到更为紧凑的哈希码。其实现步骤包括如下:(1)从图像数据库中提取10000张原始图像,对每一张原始图像提取局部空间约束的全局频率特征,得到每一张图像的特征数据;(2)对每一张图像的特征数据做归一化处理,得到归一化数据;(3)将所有图像的归一化数据随机分成三部分:已标记的训练数据L、未标记的训练数据U、测试数据T,并对已标记的训练数据L标记类标HL,将已标记的训练数据L和未标记的训练数据U组合得到训练数据矩阵X;(4)根据训练数据矩阵X和已标记的训练数据的类标HL,使用类标传递方法求得未标记训练数据U的类标HU,将已标记的训练数据的类标HL和未标记训练数据的类标HU组合得到训练数据矩阵的类标H;(5)根据训练数据矩阵X及训练数据矩阵的类标H产生更新的训练数据的编码B′;(6)使用训练数据矩阵X和更新的训练数据的编码B′对K个支持向量机分类器进行训练,其中K表示编码位数;(7)使用训练得到的K个支持向量机分类器对训练数据X和测试数据T进行分类,根据分类结果得到训练数据X的哈希码CX和测试数据T的哈希码CT;(8)从测试数据的哈希码CT中取一个测试数据的哈希码t,计算该哈希码t与训练数据的哈希码CT之间的汉明距离,得到汉明距离向量;(9)对汉明距离向量中的数值按从小到大的顺序进行排序,按顺序输出对应的原始图像,得到检索结果。本发明与现有技术相比具有以下优点:第一,本发明由于引入了基于类标传递的半监督方法,克服了现有技术中对于类标数量不足而引起的精度下降的缺点,使得检索精度更高。第二,本发明由于使用支持向量机分类器产生哈希码,得到了更为紧凑的哈希码,因此可以减少内存空间的占用。第三,本发明由于使用汉明距离度量图像间的相似度,可通过计算机很快的计算出汉明距离,因此加快了检索速度。附图说明图1为本发明的实现流程图;图2为本发明与现有哈希方法在手写数字数据库下的仿真实验结果图;图3为本发明与现有哈希方法在PIE人脸数据库下的仿真实验结果图。具体实施方案下面结合附图,对本发明实现的步骤和效果作进一步的详细描述。参照图1,本发明的实现步骤如下:步骤1,获取原始图像。从给定的图像数据库中提取10000张原始图像,如果图像数据库中的图像不足10000张,则取图像数据库中的所有图像。步骤2,对每一张原始图像提取局部空间约束的全局频率特征,得到每一张图像的特征数据。(2a)对每一张原始图像3个颜色通道的像素值取均值,得到该原始图像数据的灰度图像;(2b)利用Gabor滤波器对灰度图像进行4个尺度、8个方向的滤波,得到灰度图像的32个特征图;(2c)将每个特征图分成大小为4×4的子网格,分别对每个子网格中的所有像素取均值,将该均值排列在一个向量中,得到这张图像的特征数据。步骤3,对每一张图像的特征数据做归一化处理,得到归一化数据。(3a)对所有图像的特征数据求均值,用每一张图像特征数据减去该均值,得到特征数据的中心化数据;(3b)对中心化数据中的每一个向量除以该向量的模,得到特征数据的归一化数据。步骤4,对所有图像的归一化数据随机划分。(4a)将所有图像的归一化数据随机分成三部分:第一部分是已标记的训练数据L,第二部分是未标记的训练数据U,第三部分是测试数据T;(4b)将已标记的训练数据L的类标标记为HL;(4c)将已标记的训练数据L和未标记的训练数据U进行组合,得到训练数据矩阵X。步骤5,根据训练数据矩阵X和已标记的训练数据的类标HL,使用类标传递方法求得所有训练数据的类标H。(5a)建立初始标记矩阵Y,Y的行数与训练数据矩阵X的行数相同,Y的列数与已标记的训练数据的类标HL中的最大值相同,Y中的每一个元素均初始化为零;(5b)对于训练数据矩阵X的第i行为已标记、且其类标为c的训练数据,将初始标记矩阵Y的第i行第c列的数赋值为1,从而得到更新的初始标记矩阵Y;(5c)求训练数据矩阵X的每两行之间的欧氏距离d,根据相似度公式求得这两行之间的相似度w,其中σ=0.9,将训练数据矩阵X中的每两行之间的相似度组合成相似度矩阵W;(5d)对相似度矩阵W的每一行求和,将求和结果作为矩阵的对角值,得到相似度矩阵的度矩阵D;(5e)根据相似度矩阵W和度矩阵D得到归一化的相似度矩阵S:S=D-1/2WD-1/2(5f)根据相似度矩阵S和初始标记矩阵Y得到类标矩阵F:F=I-αS-1Y其中I是单位矩阵,α是调节参数,取值为0.9,·-1表示对矩阵求逆;(5g)求类标矩阵F的每一行的最大值所在位置,将最大值所在位置作为这一行所对应的数据的类标,从而得到所有训练数据的类标H。步骤6,根据训练数据矩阵X产生投影后的数据矩阵M和投影后的数据矩阵M的中值向量DM。(6a)随机产生K个投影向量,组成投影矩阵P,其中K表示哈希码的位数;(6b)将训练数据矩阵X与投影矩阵P相乘,得到投影后的数据矩阵M;(6c)将投影后的数据矩阵M的每一列按从小到大排序,取排序结果的中间值,得到这一列的中值,将每一列的中值组合在一起,得到投影后的数据矩阵的中值向量DM。步骤7,根据投影后的数据矩阵M、训练数据的类标H和投影后的数据矩阵M的中值向量DM产生更新的训练数据的编码B′。(7a)将训练数据的编码B初始化为全零矩阵,B的行数与训练数据矩阵X的行数相同,B的列数为编码位数K;(7b)根据训练数据的类标H,从投影后的数据矩阵M中取出第c类数据,组成单类标数据矩阵Mc;(7c)从单类标数据矩阵Mc中取出第j列,组成向量vj;(7d)将向量vj中的每一个数与中值向量DM的第j个数DMj进行比较,统计向量vj中数值大于DMj的个数mj和向量vj中数值小于DMj的个数nj;(7e)将上述mj与nj进行比较,如果mj大于nj,将训练数据的编码B的第j列的属于第c类的行的数赋值为1,反之,将训练数据的编码B的第j列的对应的数赋值为0,从而得到更新的训练数据编码B′。步骤8,使用训练数据矩阵X和更新的训练数据的编码B′对K个支持向量机分类器进行训练,得到K个训练好的支持向量机分类器,其中K表示哈希码的位数。步骤9,使用K个训练好的支持向量机分类器对训练数据X进行分类,将分类结果作为训练数据X的哈希码CX,使用K个训练好的支持向量机分类器对测试数据T进行分类,将分类结果作为测试数据T的哈希码CT。步骤10,从测试数据T的哈希码CT中取一个测试数据的哈希码t,计算该哈希码t与每一个训练数据X的哈希码CX之间的汉明距离,组成汉明距离向量R。步骤11,输出检索结果。(11a)计算汉明距离向量R的最小值Rmin以及最小值Rmin所在的位置Pmin;(11b)将原始图像数据库中位置在Pmin的图像输出;(11c)将最小值Rmin从汉明距离向量R中删除;(11d)重复(11a)到(11c),直到汉明距离向量R中不含有任何数据,完成图像检索。本发明的效果结合以下仿真实验进一步说明:1.仿真条件本发明是在中央处理器为Intel(R)Corei5-34703.20GHZ、内存8G、WINDOWS7操作系统上,运用MATLAB软件进行的实验仿真。2.仿真内容仿真1:在手写数字数据库下分别采用本发明方法和现有哈希方法进行图像检索仿真实验,实验结果如图2所示。其中,图2(a)为哈希编码长度取48位的查全率-查准率曲线图,横轴表示查全率,纵轴表示查准率。图2(b)为哈希编码长度取64位的查全率-查准率曲线图,横轴表示查全率,纵轴表示查准率。图2(c)为平均准确率曲线图,横轴表示哈希编码长度,纵轴表示平均准确率。仿真2:在PIE人脸数据库下分别采用本发明方法和现有哈希方法进行图像检索仿真实验,实验结果如图3所示。其中,图3(a)为哈希编码长度取48位的查全率-查准率曲线图,横轴表示查全率,纵轴表示查准率。图3(b)为哈希编码长度取64位的查全率-查准率曲线图,横轴表示查全率,纵轴表示查准率。图3(c)为平均准确率曲线图,横轴表示哈希编码长度,纵轴表示平均准确率。由图2和图3的仿真结果可见,采用本发明进行图像检索的查全率-查准率性能及平均准确率性能都优于现有的哈希方法。因此,与现有技术相比,本发明利用类标传递和支持向量机的方法,能有效获取原始图像数据的哈希码,从而提高了图像检索的性能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1