JAVA堆使用的季节趋势、预报、异常检测和端点预测的制作方法
本申请还根据35U.S.C.§119(e)要求2013年4月11日提交的题为“SEASONAL TRENDING,FORECASTING,ANOMALY DETECTION,AND ENDPOINT PREDICTION OF JAVA HEAP USAGE”的美国临时专利申请序列号61/811,102的优先权,这里通过引用并入该申请的内容;并且要求2013年12月17日提交的题为“SEASONAL TRENDING,FORECASTING,ANOMALY DETECTION,AND ENDPOINT PREDICTION OF JAVA HEAP USAGE”的美国专利申请序列号14/109,546的优先权,这里通过引用并入该申请的内容。本申请还根据35U.S.C.§119(e)要求2013年4月11日提交的题为“PREDICTIVE.DIAGNOSIS OF SLA VIOL ATIONS IN CLOUD SERVICES BY SEASONAL TRENDING AND FORECASTING WITH THREAD INTENSITY ANALYTICS”的美国临时专利申请序列号61/811,106的优先权,这里通过引用并入该申请的内容;并且要求2013年12月17日提交的题为“PREDICTIVE DIAGNOSIS OF SLA VIOLATIONS IN CLOUD SERVICES BY SEASONAL TRENDING AND FORECASTING WITH THREAD INTENSITY ANALYTICS”的美国专利申请序列号14/109,578的优先权,这里通过引用并入该申请的内容。本申请还根据35U.S.C.§119(e)要求2013年10月1日提交的题为“DATA DRIVEN BUS INESS PROCESS AND CASE MANAGEMENT”的美国临时专利申请序列号61/885,424的优先权,这里通过引用并入该申请的内容;并且要求2013年12月17日提交的题为“KNOWLEDGE INTENSIVE DATA MANAGEMENT SYSTEM FOR BUSINESS PROCESS AND CASE MANAGEMENT”的美国专利申请序列号14/109,651的优先权,这里通过引用并入该申请的内容。
背景技术:
个人和组织面临快速增加的数据量。这些数据可在复杂性和紧迫性方面快速增加。个人和组织经常需要分析这些数据以便用适当且及时的方式按照数据进行行动。在一些领域,个人和组织采取的行动受也趋于变得日益复杂的规则管理。例如,规则可能要求维护在某问题应该发生的情况下易受审计的细致历史记录。另选地,进入商业组织之间的服务级别协议(SLA)可能要求系统性分析数据并且主动对数据中的可行性信息进行行动,以避免违反SLA并且还确定是否满足协议。遵循规则、服务级别协议和其它要求可能会非常繁重,并且随时间经过可能会变得更繁重。
因为监管和SLA要求变得如此极其复杂,计算机软件适合于帮助个人和组织努力符合要求。然而,因为规则和SLA趋于演进,计算机软件本身具有一致演进以保持不衰退的任务。不幸的是,用于开发和更新计算机软件的常规处理慢且麻烦。软件开发周期通常长。困扰计算机软件演进的这些困难能部分归因于数据经常隐藏在程序上的软件代码中这一事实。数据经常与能应用于该数据的知识分离。
附图说明
图1A-B示出根据本发明的实施方式的例示用于应用线程或堆栈段强度分析学的技术示例的流程图。
图2A-B示出根据本发明的实施方式的例示用于更新堆栈帧统计学的技术示例的流程图。
图3A-J示出根据本发明的实施方式的例示用于分类线程和这些线程的堆栈段的技术示例的流程图。
图4是根据本发明的实施方式的例示用于应用季节趋势过滤器的技术示例的流程图。
图5A-C示出根据本发明的实施方式的例示用于在堆栈帧之前或之后在分支点处分开堆栈段的技术示例的流程图。
图6A-E示出根据本发明的实施方式的例示用于合并线程的堆栈段的技术示例的流程图。
图7A-B示出根据本发明的实施方式的例示用于登记指定堆栈踪迹的线程分类项和合并段的指定集合的技术示例的流程图。
图8是根据本发明的实施方式的例示用于更新指定线程分类信息项的线程分类统计学的技术示例的流程图。
图9是例示根据本发明的实施方式的用于更新指定段信息项的堆栈段统计学的技术示例的流程图。
图10是例示根据本发明的实施方式可使用的系统环境的组件的简化框图。
图11是根据本发明的实施方式可使用的计算机系统的简化框图。
图12是根据本发明的实施方式的使用各种功能转变数据的各种状态的框架的框图。
图13是根据本发明的实施方式的示出趋势的图。
图14是根据本发明的实施方式的示出已被自动分类的一组数据点的示例的图。
具体实施方式
概述
数据能归类为事实、信息、假设和指令。通过知识应用基于其它类别的数据生成特定类别的数据的行为能归类为分类、评估、求解和制定。这些归类能用于增强诊断系统,例如通过历史记录保存。这种诊断系统能包括基于向诸如线程或堆栈段强度和虚拟机的内存堆使用的系统生命征应用知识来预测计算系统故障的系统。这些生命征是能被分类以产生诸如内存泄漏、堵塞线程、死锁、拥塞或其它问题的信息的事实。分类能涉及自动生成类以及趋向采样间隔具有不规则持续时间的时间序列数据。
维持数据与行为之间的关系
根据本发明的实施方式,公开了维持行为与激发这些行为的数据之间的形式关系的技术。更具体地,形式上识别为事实的数据能在形式上与基于这些事实推导信息的分类行为相关,或映射到基于这些事实推导信息的分类行为。这种信息在一般意义上也是数据,但是能在形式上识别为区别于事实的信息。基于这种信息推导假设的评估行为能在形式上与该假设相关或映射到该假设。基于这种信息和假设推导指令的求解行为能在形式上与该指令相关或映射到该指令。指令也是数据,但在形式上识别为区别于事实和信息的指令。基于这种指令推导更进一步事实的制定行为能在形式上与这些更进一步事实相关或映射到这些更进一步事实。
因此,在本发明的实施方式中,各数据项能被标记为事实、信息、假设或指令。各行为能被标记为分类、评估、求解或制定。从外部源接收到系统(例如传感器)的原始数据能被标记为总体上定量而非定性的事实。基于知识的自动化处理或应用于这些事实的人为判断能被标记为分类。得自分类的数据能被标记为信息。信息总体上指示什么事实被判断或确定为表示定性的。基于知识的自动化处理或应用于这种信息的人为判断能被标记为评估。得自评估的数据能被标记为假设。类似地,基于知识的自动化处理或应用于这种假设的人为判断能被标记为求解。得自求解的数据能被标记为指令。指令总体上规定被认为适于在改正或改善信息指示的状态所做的努力中进行表现的操作。基于知识的自动化处理或应用于这种指令的人为判断能被标记为制定。制定总体上承载指令规定的操作。得自制定的数据(可通过相对于制定产生的状态进行的测量得到)也能被标记为事实。能相对于这些事实进行更进一步分类,因此以上描述的顺序能迭代重复。在各迭代中,能执行附加分类、评估、求解和指定。因此,本发明的实施方式能涉及周期的分类产生信息的事实、评估产生假设的信息、求解产生指令的信息和制定产生更进一步事实的指令。此周期称为CARE(分类-评估-求解-制定)环。
在本发明的实施方式中,对于在系统中发生的各分类,能生成并存储该分类与激发该分类的事实之间的映射。对于在系统中进行的各评估,能生成并存储该评估与激发该评估的信息之间的映射。对于在系统中进行的各求解,能生成并存储该求解与激发该求解的信息之间的映射。对于在系统中进行的各制定,能生成并存储该制定与激发该制定的指令之间的映射。另外,能生成并存储各分类与得自该分类的信息之间的映射。另外,能生成并存储各评估与得自该评估的假设之间的映射。另外,能生成并存储各求解与得自该求解的指令之间的映射。另外,能生成并存储各制定与得自该制定的事实之间的映射。
在本发明的实施方式中,建立一组面向对象的类以归类事实、分类、信息、评估、假设、求解、指令和制定的实例。能从这些类推导这些类中的每类的领域特定子类。例如,对于特定领域(例如,数据中心健康监控、诊断和管理),能从事实类推导事实类的领域特定子类,能从分类类推导分类类的领域特定子类,能从评估类推导评估类的领域特定子类,能从假设类推导假设类的领域特定子类,能从求解类推导求解类的领域特定子类,能从指令类推导指令类的领域特定子类,能从制定类推导制定类的领域特定子类。这些领域特定子类中的每个能被赋予适于它们所应用的领域的标签和属性。例如,在数据中心健康监控、诊断和管理领域中,事实类的领域特定子类可以是线程库(thread dump)类。对于另一示例,信息类的领域特定子类可以是堵塞线程(堵塞线程)类。对于另一示例,指令类的领域特定子类可以是负载均衡类。
在本发明的实施方式中,对于作为事实的各数据项,能实例化作为事实类的领域特定子类的实例的对象,以存储属于该数据项的属性的值。对于作为信息的各数据项,能实例化作为信息类的领域特定子类的实例的对象,以存储属于该数据项的属性的值。对于作为指令的各数据项,能实例化作为指令类的领域特定子类的实例的对象,以存储属于该数据项的属性的值。
在本发明的实施方式中,对于作为分类的各行为,能实例化作为分类类的领域特定子类的实例的对象,以存储属于该行为的属性的值。对于作为评估的各行为,能实例化作为评估类的领域特定子类的实例的对象,以存储属于该行为的属性的值。对于作为求解的各行为,能实例化作为求解类的领域特定子类的实例的对象,以存储属于该行为的属性的值。对于作为制定的各行为,能实例化作为制定类的领域特定子类的实例的对象,以存储属于该行为的属性的值。
在本发明的实施方式中,能生成并存储这些对象之间的映射。这些映射能稍后被调用,可能通过对能存储这些映射的数据库执行查询进行调用。
分类-评估-求解-制定环
在本发明的实施方式中,定义了四种单独的数据类:事实,信息,假设,指令。在实施方式中,定义了四种单独的知识类:分类,评估,求解,制定。信息实例能包括分类处理从事实提炼的观察和/或预测和/或标准和/或目标。假设实例能从评估处理进行的观察和/或预测推导。指令实例能从求解处理进行的假设推导。制定处理能生成新事实。
在实施方式中,能通过应用分类知识将事实—到系统的原始输入—还原为观察和/或预测和/或标准。事实能被映射至代表建立的观察的术语的离散的标签性质。观察能用于执行评估以便推导假设。这种假设能具有概率、量级和反应紧迫性。观察、预测、标准和/或假设能用于确定用于处理情况的指令—动作计划。能通过应用制定知识来执行指令。当制定了指令时,能分类新出现的事实。能执行更进一步的评估以确定情况是否已被求解或者是否应该查明更进一步指令。
这里公开的技术能用于开发应用。这里公开的知识、信息、处理和社会交互模型能用于开发数据驱动的应用。能通过将数据区分为事实、信息、假设、指令来将语义学与数据关联。能使用CARE-环将如此区分的这些数据与分类、评估、求解、制定知识相互关联。数据库技术能用于实现这里公开的技术并且实现这里公开的模型。
知识、信息、处理和社会交互模型
使用这里公开的模型作为普通设计模式,能开发演进的应用。能通过编码的知识处理的逐渐注入来开发这些应用。这些编码的知识处理能用于使人工处理自动化。指令类能关联至必要隐性知识的简档以执行指令。行动者类能与隐性知识简档关联。通过匹配指令的隐性知识要求和行动者的隐性知识简档,能选择最优人的资源并分配给各任务。CARE环能用作构建动态反应系统的引擎。
知识、数据和行动者
在本发明的实施方式中,能定义三个面向对象的类:数据类,知识类,行动者类。能从这些类实例化对象。这些对象能存储在数据库中用于应用。各对象的多个版本能维持在临时数据库中使得如果需要则可获得各对象的历史。
数据对象—数据类的实例—能代表结构化、半结构化、非结构化的原始内容,例如事实、事件流、关系、可扩展标记语言(XML)文档、文本等。数据对象还能代表诸如类别、标签、关系和容器的元数据。数据对象还能代表通过诸如用户接口表单、规定表单和通知模板的获取处理捕获的内容。
知识对象—知识类的实例—能代表算法、脚本、处理、查询、资源描述框架(RDF)公理、产生式规则、决策树、支持向量机、神经网络、贝叶斯网络、隐马尔可夫模型、霍普菲尔德模型、隐性人的知识和其它。知识能在数据对象被添加、改变或删除时应用于这些数据对象。知识对象的升级能触发该知识对象中的知识已应用至的数据对象的追溯处理。一部署了知识对象,就能应用这些知识对象中的知识。
行动者对象—行动者类的实例—能代表个体、个体的组或组织。行动者对象能具有诸如组织的上下文、技能简档、知识简档、兴趣简档、喜好简档的属性。这种知识简档能用编码方式指示行动者对象处理但系统可能不处理的隐性知识。当行动者对象代表个体时,则行动者对象能指定对象代表的行动者的实时存在。当行动者对象代表个体时,则行动者对象能指定对象代表的行动者的实时行为。能最佳地基于行动者对象的属性将这些行动者对象分配给未决指令。
在本发明的一个实施方式中,能从相同的基本类推导数据、知识和行动者类。
事实、信息、假设和指令
在本发明的实施方式中,能从以上讨论的数据类推导三个单独的面向对象的类:事实类,信息类,假设类,指令类。能从这些类实例化对象。对象能存储在数据库中用于应用。
事实对象—事实类的实例—能代表到系统的输入。这种输入例如能包括来自JVM中的垃圾收集器的数据流、来自周期性线程库的堆栈踪迹、内存堆库、数据库AWR报告等。事实对象能代表非结构化的会话、表单输入或设备收集的定量测量。
信息对象—信息类的实例—能代表来自事实的观察或预测的定性解释。在本发明的实施方式中,能从信息类推导三个单独的面向对象的类:观察类、预测类、规则类、目标类。每个类的对象能被实例化。观察对象能代表事实到离散值的个性化。例如,阻挡数据库连接事实的线程的强度(数量)能个性化为具有诸如标准的、谨慎的、严重的或关键的定性值的观察对象。预测对象能代表从改变的条件预报的定性值。预测对象能代表观察的模型可能通过模拟插入或推断的定性值。标准对象能代表历史基线的定性值。目标对象能代表成果应该是寻找观察和预测对象以便实现总体目标和求解的目的定性值。目标和观察之间的差异能被分类。目标和观察之间的差异程度能影响指令的确定。
假设对象—假设类的实例—能代表观察和/或预测的诊断或起因。例如,导致线程的类的线程强度被分类为两个服务器的集群的第一服务器中的过紧状态(强度显著高于标准)和第二服务器中的过松状态(强度显著低于标准)负载均衡器的故障是假设的领域特定示例。
指令对象—指令类的实例—能代表要执行的行为。取得堆库或配置内存管理策略的命令是指令的领域特定示例。
分类、评估、求解和制定
在本发明的实施方式中,能从以上讨论的知识类推导四个面向对象的类:分类类,评估类,求解类,制定类。能从这些类实例化对象。对象能存储在数据库中用于应用。这些对象能共同代表机构知识的抽象。这种知识例如能编码在自动化的软件程序中,或者这种知识能是人的知识。知识能采取算法、技术、处理或方法的形式。知识能应用于数据以推导其它种类的数据。
分类对象—分类类的实例—能代表用于将定量事实还原为定性观察的技术。分类技术的应用能生成从事实池取得的重要事实的紧凑代表。
评估对象—评估类的实例—能代表用于生成关于观察的起因的假设的技术。这些技术能是人工的、计算机引导的、或完全自动化的。
求解对象—求解类的实例—能代表用于生成指令集以处理假设的技术。这些技术能是人工的、计算机引导的、或完全自动化的。求解能寻求基于从标准推导了多少观察或预测来开发。
制定对象—制定类的实例—能代表用于解释指令意图并且用于执行该意图的技术。制定能寻求回应假设。制定能寻求捕获附加事实。
行动者
行动者对象—行动者类的实例—能代表人、团体、公众和自动化代理。行动者对象处理诸如简档和存在上下文的属性。人可以是与系统交互的个体。人的简档能代表该人的纪律、角色和责任。人的隐性知识简档能从该人贡献或创作的消息、报告和公开自动提取。团体可以是个体的团队。团体的简档能代表该团体的纪律、角色和责任。团体的隐性知识简档能从团体的成员贡献或创作的消息、报告和公开自动提取。公众能是组织、论坛、会议、杂志等。公众的隐性知识简档能基于公众的谈论自动生成。自动化代理能是包封诸如工作流、模拟、支持向量机、神经网络和贝叶斯网络等等的算术处理的软件。自动化代理能处理指示代理性能的简档。
在实施方式中,诸如由分类对象、评估对象、求解对象、制定对象代表的那些知识行为能至少部分基于行动者对象处理的属性被分配为该行动者对象。因此,要执行的各行为能被分配给最能够最有效率地执行该行为的行动者。
在实施方式中,能直接或间接捕获行动者对象的至少一些属性。这些属性能包括简档。行动者对象能处理喜好。使用自然语言处理,专门技能寻找工具能从该行动者的贡献(诸如,消息,报告,公开)提取行动者的专门技能和兴趣。能通过名词和主题指示这种专门技能和兴趣。工具能将各名词短语或主题分类为是专门技能、兴趣、喜欢、厌恶、建议等。在实施方式中,能基于行动者的简档为这些行动者自动创建事件订阅。
在一个实施方式中,行动者的简档能随时间改变。能为各行动者维持这些简档随时间的不同版本。重新评估行动者的贡献能导致该行动者的专门技能随时间改变。行动者的简档历史能存储在双时态数据库中并且被查询。
在实施方式中,能基于行动者参与的社会交互的内容自动构造该行动者的简档。这些社会交互能包括例如会话线程。社会交互能表示为容器对象。这种社会交互容器对象能代表会议、聊天室、电子邮件收件箱、电子邮件发件箱、日程、任务列表和论坛。这些容器对象中的行动者的内容贡献能在上下文中被作出简档。诸如分类、评估、求解、制定的知识功能能被参数化,使得参数在可能的程度上被个人化为各行动者的专门技能、喜好和社会网络简档,同时仍然观察组织的约束。在某些实施方式中,行动者能基于情况、他们自己的喜好和限制组织因子选择最好的团队成员。
应用演进
根据本发明的实施方式,由于来自用户接口应用的知识的分离,应用能不断演进。在实施方式中,能单独维持知识并且执行引擎能适当应用知识。某些种类的知识(诸如人类处理的隐性知识)在计算系统内不是预知的。在一个实施方式中,为了使得能够获取这些种类的知识,系统能呈现一用户环境,该用户环境鼓励并且激发该环境的用户表达这些种类的知识。系统能呈现一用户环境,该用户环境回报用户该环境用于表达这些种类的知识。系统然后能捕获知识并且使用它用于机器的监督学习,例如用于分类、评估、求解、制定目的。
根据本发明的实施方式,提供用户接口,通过用户接口,人类用户能输入用于描述这些用户为什么作出他们所作的决策的数据。系统能将这些描述与指示用户执行或导致被执行的行动的数据关联地存储。之后,能查询存储的记录以便针对任何行动查明为什么执行了执行行动的原因。另外,这些记录能反映执行行动的决策所基于的时间的事实。因此,能在系统中为处理提供证明。
一些分类行为能由人类执行而非由自动化处理执行。在本发明的一个实施方式中,响应于人类的分类行为的执行,系统能要求人类提供执行行为所针对的情况的描述。系统然后能将此描述与代表分类行为的分类对象关联地存储。在一个实施方式中,系统能要求人类可能通过引导的社会标签使用词汇表提供注释。系统然后能将这些注释与分类对象关联地存储。在本发明的一个实施方式中,系统能要求用户识别分类行为基于的事实的最小集合。系统然后能将此事实集合与分类对象关联地存储。
一些评估行为能由人类执行而非由自动化处理执行。在本发明的一个实施方式中,响应于人类的评估行为的执行,系统能要求人类声明将基于分类进行的评估以便达到假设。系统能要求人类通过引导的社会标签使用词汇表对评估进行注释。系统能要求人类可能通过引导的社会标签指示分类集合中的哪些观察、预测、标准和目标与评估相关。系统能要求人类可能使用引导的社会标签通过提供词汇表声明假设形式的评估结果。系统能要求人类声明将基于假设的评估进行的求解。系统能要求人类通过引导的社会标签使用词汇表对求解进行注释。系统能要求人类指定一个或多个指令形式的行动计划。系统能要求人类将行动计划注释为行动计划内的指令的全部和每个。系统能将输入和注释一起与评估和求解对象关联地存储。
在本发明的实施方式中,当系统要求人类提供注释时,系统能至少部分基于与人类的行动者对象关联的简档向人类推荐词汇表。在本发明的一个实施方式中,系统能基于与和人类所关联的行动者对象所属的公众属于同一公众的行动者对象关联的知识项的相似性向人类推荐标签。在本发明的一个实施方式中,系统能基于行动者公众中的其他行动者使用标签的频率向人类推荐这些标签。在某些实施方式中,系统能利用与流行的社会网络体验类似的引导的社会标签体验。引导的社会标签能导致更标准化的词汇、更可识别的情况以及更可重复的处理。这使处理从点对点(ad hoc)实践演进到良好定义且优化的实践(例如,护理实践的标准)。此外,用户注释能用作模式识别算法的模式和监督的机器学习算法的正负示例,以使得应用能够随注释进行演进。
数据驱动框架对特定领域的应用
在一些应用领域中,诸如监控健康并且回应大数据中心的不同部分中的问题的应用,可能不能提前完全指定、设计和编程期望的应用行为。对于这些系统,需要响应于演进数据和知识的会聚以及时方式实现应用行为。在实现应用之后,需要针对数据和知识中代表的改变信息持续调整应用行为。在这种领域中,应用开发处理必须是数据驱动的,其中应用行为由包封从数据推导的知识的功能元素组成。对于随改变的数据和知识有效演进的应用,需要在支持起源踪迹的系统中将知识元素与其它类型的数据一起管理作为数据形式。利用起源支持,当事实改变时,系统能重新表征从事实推导的知识,当知识改变时,系统能重新评价事实中的信息。在这里公开的本发明的一个实施方式中,通过分类、评估、求解、制定类型归类知识元素。并非所有知识元素都被编码为自动化功能或处理。通过行动者的隐性知识的交互也被捕获为起源数据库中的分类、评估、求解、制定知识的应用的示例。数据驱动的处理控制跟踪编码的知识或行动者的隐性知识执行的各分类行动,作为起源数据库中的三元组(事实,分类,信息)。编码的知识或行动者的隐性知识执行的各评估行动被捕获为三元组(信息,评估,假设)。编码的知识或行动者的隐性知识执行的各求解行动被捕获为三元组(假设,求解,指令)。类似地,编码的知识或行动者的隐性知识执行的各制定行动被捕获为三元组(指令,制定,事实)。在本发明的某实施方式中,三元组的这些实例表示为数据库中的资源描述框架(RDF)三元组和具体化三元组。
在本发明的一个实施方式中,用作分类-评估-求解-制定(CARE)处理控制引擎的系统以驱动引擎的四种类型的行为命名。引擎主动发起行动者与自动化的分类、评估、求解、制定处理之间的交互。引擎循环通过分类、评估、求解、制定阶段以在处理循环的各阶段产生事实、信息、假设、指令数据。在实施方式中,诸如分类、评估、求解、制定的功能提供处理方面,而事实、信息、假设、指令提供数据方面。功能在本质上是可转换的。在某实施方式中,CARE控制引擎有权完全控制以生成并维持事实、信息、假设、指令数据,以及起源数据。这样做,CARE控制引擎能预期什么数据将是可用的并且何时可用。引擎还能预期足够数据将可用于应用任何知识类别的正确知识功能的时间。引擎还能强加期限。
CARE控制引擎有权完全控制以生成和维持行动者的隐性知识简档,以及编码的分类、评估、求解、制定功能的性能简档。CARE控制引擎能有权为行动者的隐性知识和喜好制作简档,选择各指令的最有资格的行动者,并且将任务分配给选择的行动者。这种执行模型顺从决策支持自动化系统的演进开发。在某些实施方式中,具有起源数据库中的关联的输入事实和输出信息的行动者执行的分类行动的具体化能用作支持向量机或神经网络的监督学习的训练样本,用于自动分类。系统中执行的评估行动的具体化能用作推导贝叶斯网络中的条件概率以及识别新关联和因果依赖关系以扩展贝叶斯网络用于自动评估的情况。
这里公开的是其中事实的分类是能由行动者或分类机器执行或彼此结合地执行的若干操作之一的框架。从事实分类的信息是原始数据的摘要,能包括趋势、预测、标准和状态向量。除了分类,框架能涉及评估。类似分类,评估是一种向从事实推导的信息应用知识。评估能由行动者或评估机器执行或彼此结合地执行。除了分类和评估,框架能涉及求解。类似分类和评估,求解是一种向从信息推导的假设应用知识。求解能由行动者或求解机器执行或彼此结合地执行。除了分类、评估、求解,框架能涉及制定。类似分类、评估、求解,制定是根据指令的一种知识应用。制定能由行动者或制定机器执行或彼此结合地执行。
图12是根据本发明的实施方式的使用各种功能转换数据的各种状态的框架的框图。框架1200包括事实数据1202,信息数据1204,假设数据1206,指令数据1208。框架1200还包括将事实数据1202转换为信息数据1204的分类功能1210,将信息数据1204转换为假设数据1206的评估功能1212,将假设数据1206转换为指令数据1208的求解功能,将指令数据1208转换为事实数据1202的制定功能。
监控健康并且回应计算机系统的健康问题的技术需要定义系统的“生命征”。技术能涉及监控时间序列数据内的生命征。时间序列数据能源自各种传感器。时间序列数据内包含的信息是特定类型的事实。这些生命征例如能包括内存使用和线程或堆栈段强度。季节趋势技术能利用计算机系统的“生命征”的时间序列数据,以执行趋势的分类。
堆使用和线程或堆栈段强度的季节趋势和分类只是这里公开的框架的许多不同可能应用中的一些。使用框架,能从低级事实推导高级信息。这种低级事实例如能是诸如JVM冗长GC日志和堆栈踪迹的原始数据。原始数据能经历转换以提取越来越高级别的分类信息。例如,堆栈踪迹中的线程段能分类为更简洁的信息。在分类堆栈段和线程之后,技术能提取线程的类与线程和堆栈段(更高形式的分类信息)的下钻合成之间的依赖关系。周期性线程库的时间序列数据包含线程和堆栈段的各类的趋势信息。季节趋势将时间序列数据转换为更高形式的信息,诸如周期性季节循环,线性趋势,方差变化,水平变化,水平漂移,离群值,端点预测。趋势数据能将大量时间序列数据还原为更简洁序列的事件,事件的数量与随观察的时间窗口改变的实质趋势的数量成比例。
在一个实施方式中,系统状态能被从趋势数据提取的特征向量标识,并且系统状态变化能通过代表趋势中的实质改变的事件定界。在某实施方式中,特征向量将由各趋势信息的定性状态组成,定性状态包括季节因子,线性趋势,方差变化,水平变化,水平漂移,离群值,端点预测。各种类型的定性数据类型能分类为少达2或3个离散级别,例如低、正常或高。例如,如果线程或堆栈段的类的强度在季节性调整的期望强度的1-sigma波段内,则强度将被认为是正常。在此示例中,随观察的时间窗口的高或低的值提供关于此线程类的过紧或过松状态的定性信息。在另一个示例中,季节因子可在从周末到工作日的转变或从工作日到周末的转变中展现出不连续性。各季节内的季节因子中趋势的形状(诸如单调模式)和连接不同季节的不连续性的程度(诸如锯齿模式)能在特征向量中以定性形式描述。
能从JVM冗长GC日志文件中的时间序列数据提取特征向量子空间(线性趋势,水平漂移,方差变化,端点预测)中的特征向量,例如(高线性趋势,高水平漂移,高方差变化,接近端点)。在一个实施方式中,通过在特定时间窗口内观察JVM中存留的特征向量(高线性趋势,高水平漂移,高方差变化,接近端点),JVM的内存状态能分类为内存泄漏。状态仅对当特征向量存留在JVM中时的时间窗口的起始时间tl和结束时间t2定界的特定时间间隔有效。当内存泄漏点被识别并且修复时,JVM的特征向量可改变。由于应用缺陷修复,JVM的后续观察状态可通过分类为正常内存状态、可存留于从开始时间t2到结束时间t3的持续时间的新特征向量(例如(低线性趋势,低水平漂移,低方差变化,没有端点))描述。因此,信息可指示系统健康从内存泄漏状态发展到正常内存状态。在一个实施方式中,此状态转变能分类为改进趋势。另选地,在修复内存泄漏之后,内存管理问题可被证明为特征向量中的高方差变化(低线性趋势,低水平漂移,低方差变化,没有端点)。这可涉及更多一个CARE控制循环以求解系统可经历从内存泄漏状态到内存管理问题状态到正常内存状态的状态转变的时间期间。如果相反观察的特征向量从正常内存状态改变为内存泄漏状态,则在一个实施方式中,CARE控制能将信息分类为递归趋势并且调用递归的评估的行动者。内存特征空间的状态能与诸如线程或堆栈段强度趋势的其它特征空间的状态结合以形成JVM的合成状态(正常内存状态,正常线程强度状态)。在某实施方式中,能使用多时态数据库模式(也称为双时态数据库模式)的有效时间列管理特征向量状态的有效时间。
在一个实施方式中,响应于示例场景中的信息改变,第一CARE控制循环可分类内存泄漏状态并且调用推导假设的评估操作。响应于信息改变的链反应,第一CARE控制循环可调用利用库之间的指定时间经过发行指令以从目的JVM收集两个堆库的求解。此指令可被行动者制定并且导致新事实之中的两个堆库文件。第二CARE控制循环可调用分类操作,以通过比较两个堆库中的对象的直方图来识别内存泄漏点。可在内存泄漏点的评估之后发行关于代码缺陷的假设。可在代码缺陷的求解之后发行修复并且修补缺陷的指令。在修复并且修补缺陷的指令的制定之后,第三CARE控制循环可将新事实分类为内存管理问题状态并且调用评估操作。评估行动者的然后可导致关于内存管理策略(例如,软参考LRU策略)的错误配置的假设。第三CARE控制循环可调用导致调谐软参考LRU策略的指令的求解操作。调谐内存管理策略的此指令可由行动者制定。第四CARE控制循环可基于最后制定收集的新事实分类正常内存状态。第四CARE控制循环然后可通过观察从内存泄漏状态到内存管理问题状态到正常内存状态的状态转变来分类改进趋势。
在一个实施方式中,对于JVM的内存发生率中的每个,CARE控制将调用行动者来分类特征向量空间(例如子空间(线性趋势,水平漂移,方差变化,端点预测))中的每一个新事实。当收集足够数量的正负样本时,CARE控制能应用监督学习以构造支持向量机从而分类内存泄漏问题。例如,特征向量(高线性趋势,高水平漂移,高方差变化,接近端点)能被支持向量机分类为内存泄漏。
在一个实施方式中,CARE控制能针对事实中的信息的改变和知识元素(所有都被表示为数据)的改变在数据库中登记查询。事实改变能通过制定引发。事实中的信息改变能被提取或解释信息的知识元素中的制定以及改变引发。知识元素的改变能通过在线或离线机器学习处理(在某些实施方式中,模型化为制定处理)引发。CARE控制能响应于数据变化发起分类、评估、求解、制定行动。在某些实施方式中,CARE控制引擎能使用双时态数据库顶部上的数据库触发器、实时杂志分析和登记查询实现。在某些实施方式中,CARE控制引擎能在数据库中登记查询,用于对象改变通知或查询改变通知。登记的查询参考的对象是登记对象。因此,事实、信息、假设、指令数据中的每个对象能是登记对象。类似地,分类、评估、求解、制定知识元素中的每个对象能是登记对象。
框架能使得能够演进能用于执行类似分类、评估、求解、制定的行动的专门算法。专门算法可能不必直接一起工作。监控线程或堆栈段强度的季节趋势的算法不必与涉及堆使用趋势确定的算法直接工作。CARE控制允许通过将这些不同算法包封为经由标准化的事实、信息、假设和指令数据模型交互的分类、评估、求解和制定组件,使这些算法独立开发并且集成为能够演进为公共应用的单个系统。向系统添加新算法能产生累加效应。系统内的算法能彼此补充和加强。算法能彼此相互关联以便实现更好的诊断。CARE控制执行模型通过持续查询数据变化并且发起相互依赖组件的执行来驱动交互。这些组件中的一些可涉及与人行动者交互的用户接口和消息系统。
应用于基于各种生命征的诸如季节趋势的领域的领域特定算法初始能表征为框架内的分类元件。然而,使用框架,能进一步提炼并且理解这些算法。此增加的提炼和理解能产生捕获能更专用于它们应用的特定环境的模式的能力。这是更进一步程度的分类。此更进一步程度的分类来自将不同信息项彼此相关。例如,在特定领域中,线程或堆栈段强度信息能与内存使用信息相关。这种信息能与在系统内发行的指令相关。系统能捕获发行的这种指令并且在形式上将它们与信息项相关以示出它们之间的联系。由于这些关系在系统内构建,所以关系模式能变得可识别。系统能识别的模式种类能随时间演进。
CARE控制还用作用于监控的数据、知识和目的系统的状态的演进的可视化的模型。例如,能随时间监控关于JAVA虚拟机的(JVM的)堆使用的原始数据。在框架中,这种原始数据是能通过应用知识而分类的事实。知识能采取季节趋势算法、信号处理算法、支持向量机、神经网络和贝叶斯网络等等的形式。信息能从原始数据推导并且在特征向量中呈现。更高级别信息能采取支持向量机用特征向量的分类识别的状态的形式。这种分类信息可指示在状态下持续观察到系统的方面时的时间间隔。这种状态信息可被合成以指示例如观察到系统的方面从一种状态转变到另一种状态时的时间点,例如当对JVM应用缺陷修复时的时间点。这些时间点能通过时间序列图表中信息模式改变的点的确定而变得明显。有时,原始数据中信息改变不明显(这些改变通过肉眼不可见)时的时间点仅通过从原始数据的信息提取或信号检测而明显。在示例场景中,按时间序列的原始数据或趋势信息可能示出在第一时间间隔期间,基线JVM堆使用稳定地漂移更高,即使存在堆使用的高方差。JVM堆使用的这种稳定水平漂移能是内存泄漏的结果。原始数据然后可示出在相继的第二时间间隔期间,在高方差的连续存在中,基线JVM堆使用停止增长。第一间隔与第二间隔之间的点处的原始数据的信息改变能指示内存泄漏被对系统做的某改变所修复。在第二间隔期间,堆使用的高方差可继续。然后,在第二间隔之后的原始数据的信息改变的第三间隔期间,堆使用的方差可能显著减小,指示在时间的第二间隔与第三间隔期间对系统做出了另一改变。第二间隔与第三间隔之间的改变能与对内存LRU策略的调谐动作相关联。
在此示例中,能从原始数据推导多个信息项。首先,能推导关于基线堆使用的漂移的信息。其次,能推导关于堆使用的方差变化的信息。算法能从原始数据推导这种信息。通过过滤和转换原始数据,能从原始数据去除噪声和无关的不相干信息,仅留下感兴趣的信息。过滤例如能涉及去除数据中的季节趋势。在这种过滤后的数据内,对于试图发现模式的自动化系统,这种模式能变得更明显。也可基于数据和从中推导的信息执行预报。例如,基于数据和推导的信息,可以预测,在不存在抵消内存泄漏效应的系统重启的情况下,系统将用光内存并且将来在特定日期和时间崩溃。能针对数据中出现的季节(例如,日,周,季度)趋势调整这种预报。
每次原始数据示出产生以上讨论的不同的第一、第二、第三间隔的系统变化时,该变化能是作为求解行动的输出的某指令的发行的结果。应用这里公开的CARE控制框架还能生成指令而不调用评估行动。与时间序列的季节趋势关联的是基于季节趋势和去季节化的线性和非线性趋势的信息,其能利用特定置信度预测,使用JVM的相同示例场景,如果系统在该时间结束之前不重启,目的JVM将在从当前起的已知时间段内崩溃。这种预测可向系统管理员建议他应该在预测的崩溃将发生的时刻之前在某方便时间(例如,周末)执行涉及JVM重启的系统维护。在分类近期预测的端点之后,CARE控制可发行紧急指导指令,例如重启JVM。而且,在利用内存泄漏条件操作JVM的第一间隔内监控趋势的几天或几周之后,CARE控制能调用将需要行动者收集堆库以识别内存泄漏点并且估计缺陷修复的指令的评估和求解。内存泄漏的缺陷修复的制定可能花费几周。同时,在缺陷修复准备好应用于目的JVM之前,JVM可利用内存泄漏条件操作。CARE控制将在需要时继续发行重启指令,以在操作范围内指导JVM的内存状态,同时制定缺陷修复的未决指令。这些近期指导指令使用关于端点预测的信息通过分类发行,并且可不涉及评估行动。当制定这种重启时,这些重启之前和之后收集的原始数据的信息改变能指示这些重启在堆使用时具有的效应。JVM重启引发的信息改变能被监控为短期趋势,并且能在CARE控制模型中在形式上标记为对系统不具有长期效应的指导指令的实例。例如,尽管JVM的每周重启,以上讨论的特征向量将持续(高线性趋势,高水平漂移,高方差变化,接近端点),这被识别为内存泄漏状态。相比之下,针对内存泄漏缺陷应用修复的指令将具有从第一间隔中的内存泄漏状态到第二间隔中的内存管理问题状态的转变指示的持久效应。同样,调谐以上讨论的内存LRU策略的指令将具有从第二间隔中的内存管理问题状态到第三间隔中的正常内存状态的转变指示的持久效应。
在下面的形式注释中,n元组A能被视为函数F,其域是元组的元素索引X的隐式集,其上域Y是元组的元素集。形式上,n元组(a1,a2,...,an)是系统(X,Y,F),其中X={1,2,...,n},Y={a1,a2,...,an},F={(1,a1),(2,a2),...,(n,an)}。有序偶是2元组,并且三元组是3元组。由πi表示的n元组的投影是πi((a1,a2,...,an))=F(i)=ai。
n元关系R是n元组的集合。关系的属性是作为系统(X,Z,G)的n元组(α1,α2,...,αn)中的原子,X={1,2,...,n},Z={α1,α2,...,αn},G={(1,α1),(2,α2),...,(n,αn)},使得函数G的上域是关系的属性集。由παi表示的n元组的投影是函数παi((a1,a2,...,an))=F(G-1(αi))=ai。n元关系R的投影παi(R)是将R中的所有元组限制到属性αi得到的集合。例如,πFeature Vector:Feature Vector×Valid Time×Figure Of Merit→Feature Vector。投影πFeature Vector(Observation)是通过将观察中的所有元组限制到属性FeatureVector得到的集合。n元关系中的每个n元组与代表n元组变得持久或可恢复时的事务时间的系统改变号(SCN)隐性关联。存在投影函数πSCN,其域是n元组的集合,其上域是系统改变号(SCN)的集合。存在计算SCN的日期时间的函数:SCN→DateTime。
选择σproposition(R)(其中R是关系,命题是布尔表达式)选择R中满足命题的元组。例如,假设AssessmentInput是FeatureType×Assessment中的关系,选择σFeatureType=MemoryState(AssessmentInput)是FeatureType满足MemoryState的AssessmentInput关系中的元组的集合。查询πAssessment(σFeatureType=MemorySate(AssessmentInput))是利用MemoryState Feature作为输入的Assessment函数的集合。
在本发明的实施方式中,KIDS系统是Actor,Agent,Entity,CARE,Metadata和Reification的6元组。
KIDS=(Actor,Agent,Entity,CARE,Metadata,Reification)
Actor是能与系统交互以执行分类、评估、求解、制定行动的行动者的集合。
TacitKnowledgeProfile,SocialNetworkProfile和PreferenceProfile是3个不同的功能,每个均将Actor的成员映射至ProfileVector。
TacitKnowledgeProfile:Actor→ProfileVector
SocialNetworkProfile:Actor→ProfileVector
PreferenceProfile:Actor→ProfileVector
ProfileVector是Profile的n元组的集合,n=1,2,3...
ProfileVector=Profilen
Profile是Value,a ValidTime,a FigureOfMerit和ProfileType之间的关系。
Profile=Value×ValidTime×FigureOfMerit×ProfileType
Personalization是将简档向量应用于参数化的功能模板以产生个人化功能的curry操作:
Personalization:FunctionTemplate×ProfileVector→Function
例如,诸如分类、评估、求解、制定功能的知识功能能通过应用从Actor的隐性知识或喜好Profile的推导的ProfileVector来个人化:
Personalization(ClassificationTemplate)(ProfileVector)=Classification
Personatization(AssessmentTemplate)(ProfileVector)=Assessment
Personalization(ResolutionTemplate)(ProfileVector)=Resolution
Personalization(EnactmentTemplate)(ProfileVector)=Enaciment
Agent是代表用户的计算机程序或硬件设备的集合。
Entity是监控的实体的集合。Entity能包括Java VM的、Oracle的、数据库、服务器、服务器集群、域、pods、网络交换机、防火墙、服务器中的线程和线程段的各个类等。
CARE是Data和Knowledge的有序偶。
CARE=(Data,Knowledge)
Data是Fact,Information,Hypothesis和Directive的4元组。
Data=(Fact,Information,Hypothesis,Directive)
Fact是FSD和Feature的有序偶。
Fact=(FSD,Feature)
FSD(Flexible Schema Data)是Value的n元组、ValidTime、Entity和FSDType之间的关系。
FSD=Valuen×ValidTime×Entity×FSDType
FSD对象的示例是包含来自XYZ-Pod中的CRM-域中的销售-服务器的一系列线程库的线程-库-文件,其中销售-服务器、CRM-域和XYZ-Pod是Entity的成员,线程-库-文件是FSDType的成员。
Feature是Value、ValidTime、FigureOfMerit、Entity、FeatureType之间的关系。Feature代表数据观察范围中的分类值,诸如低、正常、高。
Feature=Value×ValidTime×FigureOfMerit×Entity×FeatureType
Feature对象的示例是XYZ-Pod中的CRM-域中的订单捕获-服务器中的提交-订单-线程的过紧状态,其中,提交-订单-线程、订单捕获-服务器、CRM-域和XYZ-Pod是Entity的成员,过紧状态是线程-强度或堆栈-段-强度FeatureType指定的范围中的值。
FeatureVector是Feature的n元组的集合,n=1,2,3,...
FeatureVector=Featuren
在一个实施方式中,FeatureVector是具有共同ValidTime的Feature的阵列。
ValidTime是DateTime的有序偶的集合。[t1,t2)代表的时间间隔是集合{t|t1<t2且t>=t1且t<t2,其中t,t1,t2∈DateTime}。例如,两个ValidTime的[2013-08-31 12:00AM PST,2013-09-01 9:00AM PST)和[2013-09-01 9:00 AM PST,∞)能结合为一个ValidTime[2013-08-31 12:00AM PST,∞)。时间实例t1能由[t1,NA)表示。
ValidTime=[DateTime,DateTime∪{∞.NA})
FigureOfMerit是表示置信度、置信区间、概率、分数、均方根误差等的定量或定性值。下面结合图13进一步讨论FigureOfMerit。
Information是Observation,Prediction,Norm和Objective的4元组。
Information=(Observation,Prediction,Norm,Objective)
Observation是FeatureVector、ValidTime、FigureOfMerit之间的关系。
Observation=FeatureVector×ValidTime×FigureOfMerit
Prediction是FeatureVector、ValidTime、FigureOfMerit之间的关系。
Prediction=FeatureVector×ValidTime×FigureOfMerit
Norm是FeatureVector、ValidTime、FigureOfMerit之间的关系。
Norm=FeatureVector×ValidTime×FigureOfMerit
Objective是优化目标函数的FeatureVector、ValidTime、FigureOfMerit之间的关系。
Objective=FeatureVector×ValidTime×FigureOfMerit
Hypothesis是FeatureVector、ValidTime、FigureOfMerit之间的关系。
Hypothesis=FeatureVector×ValidTime×FigureOfMerit
Directive是FeatureVector、ValidTime、FigureOfMerit之间的关系。
Directive=FeatureVector×ValidTime×FigureOfMerit
Knowledge是Classification,Assessment,Resolution和Enactment的4元组。
Knowledge=(Classification,Assessment,Resolution,Enactment)
Classification是均将FSD的n元组或FeatureVector的m元组映射到Observation、Prediction、Norm或Objective的函数的集合。
Classification={f|f:(FSDn∪FeatureVectorm)→(Observation∪Prediction∪Norm∪Objective),对于某个整数n,m}
Assessment是均将FeatureVector映射至Hypothesis的函数的集合。
Assessment={f|f:FeatureVector→Hypothesis}
Resolution是均将FeatureVector映射至Directive的函数的集合。
Resolution={f|f:FeatureVector→Directive}
SymptomResolution是域被限制到Fact或Information之中的FeatureVector的Resolution函数的子集。
SymptomResolution={f|f:FeatureVector→Directive,使得FeatureVector=πFeatureVector(上域(g)),其中函数g是Enactment或Classification的成员}
ClassificationResolution是域被限制到Information中的Observation,Prediction,Norm和Objective之中的FeatureVector的Resolution函数的子集。
ClassificationResolution={f|f:FeatureVector→Directive,使得FeatureVector=πFeatureVector(上域(g)),其中函数g是Classification的成员}
AssessmentResolution是域被限制到Hypothesis之中的FeatureVector的Resolution函数的子集。
AssessmentResolution={f|f:FeatureVector→Directive,使得FeatureVector=πFeatureVector(上域(g)),其中函数g是Assessment的成员}
ExpertResolution是作为Classification,Assessment和Resolution函数的合成的Resolution函数的子集。
ExpertResolution=Classification·Assessment·Resolution
ExpertResolution:(FSD∪FeatureVector)→(Observation∪Prediction∪Norm)×Hypothesis×Directive
Enactment是均将Directive映射到FSD的集或FeatureVector的集的函数的集合。
Enactment={f|f:Directive→(FSDn∪FeatureVectorm),对于某个整数n,m}
MetaData是ProfileType,FSDType,FeatureType和Influence的4元组。
MeiaData=(ProfileType,FSDType,FeatureType,Influence)
ProfileType是均定义简档的名称、数据类型和值范围的对象的集合。ProfileType能指定诸如“角色”的名称和诸如(工头,监督者,主管,管理者)的值范围。在另一个示例中,ProfileType能指定诸如“责任”的名称和诸如(WebLogic管理员,数据库管理员,Linux管理员,网络管理员)的值范围。对于另一个示例,对于具有名称“内存调谐专门技能”的ProfileType,范围能包括诸如“专家”、“中级”和“学徒”的定性值。对于另一个示例,对于具有名称“应用源代码知识”的ProfileType,范围能包括诸如“开发器”、“架构”和“测试器”的定性值。这些值能用于定义简档。
ProfileType=名称×类型×范围×默认值
FSDType是由定义文件类型的分类值组成的集合,分类值诸如为冗长的GC日志、周期性线程库、堆库、OS看守器日志、数据库AWR快照、数据库踪迹文件、点击流、REUI记录、访问日志、以及过滤到聚集体的规则或不规则的时间序列数据,例如季节因子、水平漂移、水平移位、水平尖峰、方差变化、离群值、端点预测、重启、内存用光事件、堵塞线程事件等。
FSDType=名称×{二进制,文本}×编码×语言
FeatureType是均定义特征的名称、数据类型和值范围的对象的集合。FeatureType能指定诸如“内存状态”的名称和诸如(内存泄漏,内存管理问题,正常内存)的值范围。在另一个示例中,FeatureType能指定诸如“线程强度状态”的名称和诸如(过紧,过松,护航效应)的值范围。对于另一个示例,对于具有名称“方差”的FeatureType,范围能包括诸如“高”、“正常”和“低”的定性值。对于另一个示例,对于具有名称“端点”的FeatureType,范围能包括诸如“近”、“远”和“无端点”的定性值。这些值能用于定义特征。
FeatureType=名称×类型×范围×默认值
能从数据提取特征。类型能是分类的而非定量的。特征和特征类型一起定义能约束到一组允许值的名称-值对。当从数据提取这些值时,这些值的有效时间能与特征一起扩散。下面提供有效时间的讨论。
图13是根据本发明的实施方式的示出趋势的图。使用这里描述的技术,基于趋势,能在特定时间和日期预测端点1302。有效时间1304与已用于预测端点1302的趋势数据关联。在这种情况下,预测端点出现在有效时间1304的几个小时内。用于预测端点1302的数据是有效时间1304的部分。例如可使用这种数据来在到达端点1302之前重启JVM。
在实施方式中,有效时间1306能跨越多个间隔,其中各间隔之间的边界由诸如JVM重启的某事件限定。各时间间隔或段能示出它在时间上靠近某端点。端点的靠近是特征的示例。在这种情况下,有效时间可由JVM的生命周期定界。在另一个示例中,有效时间可由数据库的生命周期定界。在重复如图13所示的模式之后,预期某状态可改变。例如,缺陷修复可能导致状态改变。在这种事件后续的有效时间1308之后,趋势可能不增加。
如以上讨论的,品质因数可代表置信区间或概率。例如,如果品质因数代表图13中的置信区间1310,则品质因数可指示端点1302的预测的置信区间1310是正负5小时。尽管在一些实施方式中,品质因数能定量表示,但在其他实施方式中,品质因数能定性表示。例如,并非置信区间1310是诸如正负5小时的定量测量,置信区间1310可以是诸如“相当精确”的定性测量。这种定性测量可以是主观的,而非客观的意见。
可从同一机器观察多个统计参数。除了稳定趋势之外,观察可由近似于稳定趋势的高波动方差构成。代表高波动方差的特征可由与代表端点的特征类型不同的特征类型表示。方差的特征类型例如可包括诸如“高”、“正常”或“低”的定性值范围。然而,特征的有效时间可重叠。特征可代表同一系统的不同方面。各特征的有效时间可通过系统与该特征一起扩散。在一个实施方式中,包括多个特征的特征向量的有效时间是所有这些特征的有效时间的交集。
事实数据的观察可揭示多个不同特征相关。例如,当特征的有效时间重叠的跨度小于整个数据集的有效时间时,可揭示这种相关。
Influence是FSDType、FeatureType、以及Knowledge的元素之间的输入和输出关系的8元组。
Influence=(ClassificationInput,ClassificationOutput,AssessmentInput,AssessmentOutput,ResolutionInput,ResolutionOutput,EnactmentInput,EnactmentOutput)
ClassificationInput是FSDType、FeatureType、以及Classification之间的关系。
ClassificationInput=(FSDType∪FeatureType)×Classification×Mandatory
ClassificationOutput是Classification和FeatureType之间的关系。
ClassificationOutput=Classification×FeatureType
AssessmentInput是FeatureType和Assessment之间的关系。
AssessmentInput=FeatureType×Assessment×Mandatory
AssessmentOutput是Assessment和FeatureType之间的关系。
AssessmentOutput=Assessment×FeatureType
ResolutionInput是FeatureType和Resolution之间的关系。
ResolutionInput=FeatureType×Resolution×Mandatory
ResolutionOutput是Resolution和FeatureType之间的关系。
ResolutionOutput=Resolution×FeatureType
EnactmentInput是FeatureType和Enactment之间的关系。
EnactmentInput=FeatureType×Enactment×Mandatory
EnactmentOutput是Enactment和FSDType或FeatureType之间的关系。
EnactmentOutput=Enactment×(FSDType∪FeatureType)
Mandatory是指示输入的FeatureType是否被强制调用函数的布尔值。
Reification是(CARELoop,Classified,Assessed,Resolved,Enacted)的5元组。
CARELoop=Classified×Assessed×Resolved×Enacted
Classified=(FSD∪FeatureVector)×Classification×(Observation∪Prediction∪Norm)×(Actor∪Agent)×TransactionTime
Assessed=FeatureVector×Assessment×Hypothesis×(Actor∪Agent)×TransactionTime
Resolved=SymptomResolved∪ClassificationResolved∪AssessmentResolved∪ExpertResolved
SymptomResolved=FeatueVector×SymptomResolution×Directive×(Actor∪Agent)×TransactionTime
ClassiticationResolved=FeatureVector×ClassificationResolution×Directive×(Actor∪Agent)×TransactionTime
AssessmentResolved=FeatureVector×AssessmentResolution×Directive×(Actor∪Agent)×TransactionTime
ExpertResolved=FeatureVector×ExpertResolution×Observation×Prediction×Norm×Hrpothesis×Directive×(Actor∪Agent)×TransactionTime
Enacted=Directive×Enactment×(FSD∪FeatureVector)×(Actor∪Agent)×TransactionTime
TransactionTime是DateTime的有序偶的集合。[t1,t2])表示的时间间隔是集合{t|t1<t2and t>=t1andt<t2,其中t,t1,t2∈DateTime}。例如,两个TransactionTime的[2013-08-31 12:00 AM PST,2013-09-019:00 AM PST)和[2013-09-019:00 AM PST,∞)能结合为一个TransactionTime[2013-08-31 12:00 AM PST,∞)。时间间隔t1能由[t1,NA)表示。TransactionTime记录信息变得持久或变得可恢复并且对其它可恢复事务可见期间的时段。
TransactionTime=[DateTime,DateTime∪{∞.NA})
当FSD存在变化时,例如,当JVM的GC日志更新时,CARE控制能确定FSDType。CARE控制能使用FSDType从ClassificationInput关系中选择该FSDType的FSD的影响的Classification功能。CARE控制还能查询包括Classification(分类)功能的输入的FeatureType的闭包。CARE控制然后能合并所需的FSD和FeatureVector以调用Classification。如果Classification功能由季节过滤器、决策规则、支持向量机等表示,则CARE控制将发起功能的执行。如果Classification功能由隐性知识简档表示,则CARE控制将识别隐性知识简档最佳地匹配Classification功能的隐性知识简档的一个或多个行动者并且发起与行动者的交互以执行分类行动。在机器和隐性知识分类二者的情况下,此Classification功能的结果是Observation(观察)、Prediction(预测)或Norm(标准)。此步骤之后,CARE控制能具体化输入FSD的集、输入FeatureVector的集、Classification功能、以及Observation或Prediction或Norm之间的关系。CARE控制能在具体化中包括任意数量的Actor's、任意数量的Entity's、实现Classification功能的程序的版本、应用于Classification功能的参数、以及其他上下文信息。
在某些实施方式中,可从时间序列数据的段的ValidTime's推导FSD的ValidTime。类似地,能从FeatureVector中的每个Feature's的ValidTime's的并集推导FeatureVector的ValidTime。在Classification功能的调用之后,将产生新的FeatureVector,其将触发信息改变通知。CARE控制能Classificationlnput、Assessmentlnput和Resolutionlnput关系之中选择分别被新的FeatureVector中的任意Feature's影响的任何Classification、Assessment(评估)和Resolution(求解)功能。在取得与影响Classification、Assessment和Resolution功能的FeatureType's对应的所有所需Feature's的闭包之后,CARE控制能顺序或并行调用选择的这些功能。在示例场景中,一旦有新的FeatureVector的改变通知,例如(高水平漂移,高方差变化,接近端点预测),CARE控制能选择更高级别的分类功能以分类此FeatureVector。高级别的分类功能(诸如支持向量机)能将特征空间(季节因子,水平漂移,水平移位,方程变化,离群值,端点预测,重启,内存用光事件)中的FeatureVector映射至诸如内存泄漏、内存管理问题、正常内存、过紧、过松、护航效应、死锁等的分类特征。在分类内存泄漏状态之后,CARE控制能接收信息改变的另一通知。
诸如学习支持向量机的那些监督学习技术的机器学习技术能接收具有关联的分类的一组特征向量作为输入,并且能自动学习以将其中的新数据点分类为属于单独的不同分类。图14是根据本发明的实施方式的示出已被自动分类的一组数据点的示例的图。类除法器1402的一侧的点视为属于类1404,而类除法器1402的另一侧的点视为属于类1406。例如,类1404可包含为“真”的数据项,而类1406可包含为“假”的数据项。在此示例中,分类是二进制的。在本发明的各种实施方式中,分类能是N向的,其中N是类的数量。因此,支持向量机能接收特征向量,并且使用之前从一组分类的样本数据以监督方式学习的诸如类除法器1402的一个或多个类除法器,能基于该特征向量内包含的数据确定特征向量的类。一个类中的数据点可指示系统中存在内存泄漏,而另一个类中的数据点可指示系统中不存在内存泄漏。
在调用分类功能之后,如果CARE控制选择求解功能,则它能执行求解功能以产生指定。在分类功能之后没有评估功能而产生的这种指令能用于沿着期望轨迹指导系统,以收集事实的新成分,或者迅速防止惨重故障。例如,如果特征向量指示JVM将要用光内存,则可发行指令以在周末重启JVM,从而避免接下来的工作日中的季节尖峰时间期间的崩溃。在本发明的实施方式中,CARE处理周期能迭代,以通过发行Directive's维持Norm或Objective的某限度内的所有Observation's和Prediction's。
在另一个示例场景中,CARE控制能选择被新的FeatureVector中的Feature's的新集合影响的Assessment功能。CARE控制能从AssessmentInput关系之中查询影响Assessment功能的所需FeatureType。CARE控制然后能查询满足Assessment功能所需的Feature's的闭包,在一种情况下,Assessment功能可被分配给隐性知识简档匹配Assessment功能的专门技能简档的行动者。在另一种情况下,Assessment功能能由贝叶斯网络表示。CARE控制能合并满足贝叶斯网络所需的特征空间上的FeatureVector。贝叶斯网络的输入FeatureVector的ValidTime能从如上讨论的每个成分Feature's的ValidTime推导。CARE控制然后能发起贝叶斯网络的执行。在执行贝叶斯网络之后,CARE控制能具体化FeatureVector、代表Assessment功能的贝叶斯网络和Hypothesis之间的关系。
一旦有贝叶斯网络的与Hypothesis关联的新FeatureVector的改变通知,CARE控制能从ResolutionInput关系之中选择被新FeatureVector中的Feature’s影响的任何Resolution功能。在取得与Resolution功能所需的FeatureType’s对应的Feature’s的闭包之后,CARE控制能调用Resolution功能以产生Directive。如果Resolution功能由隐性知识简档表示,则CARE控制将识别隐性知识简档最佳地匹配Resolution功能的隐性知识简档的一个或多个行动者并且发起与行动者的交互以执行求解动作。CARE控制能具体化FeatureVector、Resolution功能和Directive之间的关系。
在某些实施方式中,一旦有Enactment或Classification功能产生的新FeatureVector的改变通知,CARE控制处理能选择SymptomResolution或ClassificationResolution功能。CARE控制处理能将选择的SymptomResolution或ClassificationResolution功能与目的是产生Hypothesis的AssessmentResolution功能包裹。如果如此选择的SymptomResolution或ClassificationResolution功能与隐性知识简档关联,则CARE控制处理将选择隐性知识简况匹配与SymptomResolution或ClassificationResolution功能关联的隐性知识简档的一个或多个Actor’s。CARE控制处理将选择提供词汇以合成合适的Hypothesis的AssessmentResolution功能(在第49段和第50段中描述为引导的社会标签)。CARE控制能要求Actor可能使用引导的社会标签通过提供词汇表声明Hypothesis。CARE控制能具体化FeatureVector、SymptomResolution或ClassificationResolution功能之间的关系。CARE控制能在具体化中包括Actor和AssessmentResolution功能。FeatureVector和Hypothesis之间以及Hypothesis和Directive之间的此具体化关系能用作样本情况,以通过机器学习技术开发自动Assessment和AssessmentResolution功能。
在某些实施方式中,一旦有Enactment功能产生的新FeatureVector的改变通知,CARE控制处理能选择ExpertResolution功能。ExpertResolution功能通常与隐性知识简档关联。CARE控制将选择隐性知识简档匹配与ExpertResolution功能关联的隐性知识简档的一个或多个Actor’s。CARE控制将分配Actor’s以执行ExpertResolution功能。Actor’s能可能使用引导的社会标签提供包括Observation,Prediction,Norm,Objective,Hypothesis和Directive的ExpertResolution功能的所有必要输出。CARE控制然后能具体化FeatureVector、ExpertResolution功能、Observation,Prediction,Norm,Objective,Hypothesis和Directive之间的关系。CARE控制能在具体化中包括一个或多个Actor’s。在此场景中,Actor’s能在单个步骤中实现Classification、Assessment和Resolution的角色。
一旦有Resolution功能需要的新Directive的改变通知,CARE控制能选择被新Directive的FeatureVector中的Feature’s的新集合影响的Enactment功能。CARE控制能从EnactmentInput关系之中查询影响Enactment功能所需的FeatureType。CARE控制然后能查询满足Enactment功能所需的Feature’s的闭包。CARE控制然后能调用受Directive影响的Enactment功能。诸如收集目的JVM的堆库的命令的Directive能被分配给简档包括JVM专门技能的Actor。
支持顾客服务请求、缺陷报告或在线帮助论坛的系统通常使用户以自然语言文本发布问题并且提交与问题有关的文件集合。在CARE中,包括自然语言文本和日志文件的这些非结构化的数据能包括事实和信息的部分。通常,分析者或其它参与者将通过以自然语言文本回应用户的帖子来建议问题求解。在某些实施方式中,自然语言处理(NLP)工具能用于提取用户的问题描述文本中的FeatureVector’s和分析者的响应文本中的Directive’s。在本发明的实施方式中,CARE控制能指定SymptomResolution功能,目的是具体化从外部库中的非结构化内容提取的FeatureVector’s和Directive’s。CARE控制能通过针对服务请求、缺陷报告、或在线帮助论坛中的每个箱具体化FeatureVector、SymptomResolution功能和Directive之间的关系,从外部缺陷报告、服务请求、帮助论坛库引入样本箱。CARE控制能使用从外部库中的箱提取的FSD和FeatureVector,通过在系统中调用Classification、Assessment和Resolution功能来模拟CARE环。
在示例场景中的若干CARE控制周期之后,Reification能包括(1)GC日志的FSD’s的集合,其与(2)由堆趋势的规则时间序列数据组成的FSD有关,与(3)Classification功能有关,与(4)从诸如季节因子、水平漂移、水平移位、水平尖峰、方差变化、离群值的聚集推导的FeatureVector有关,与(5)另一Classification功能有关,与(6)代表内存泄漏状态的FeatureVector有关,与(7)贝叶斯网络代表的Assessment有关,与(8)代表作为Hypothesis的部分的内存泄漏代码缺陷的FeatureVector有关,与(9)Resolution功能有关,与(10)取得堆库的Directive有关,与(11)涉及Actor的Enactment功能有关,与目的JVM的堆库的FSD’s的集合有关,与(13)Classification功能有关,与(14)从堆中的对象的直方图推导的FeatureVector有关,与(15)涉及Actor的Assessment功能有关,与(16)代表导致内存泄漏的代码点的Hypothesis FeatureVector有关。季节趋势过滤器的版本和过滤器参数也能直接或间接有关。这些关系能在它们变得持久或者变得可恢复并且对其它可恢复事务可见时用TransactionTime’s加上时间戳,并且稍后使用双时态ValidTime和TransactionTime查询进行调用。基于这些Reification关系,用户能对于数据中显示的任何事件(诸如两个间隔之间发生的信息改变)确定该改变的起因是什么。关系例如能示出特定间隔器件的Fact’s被分类为内存泄漏,以及发行了缺陷修复作为纠正内存泄漏的指令。在实施方式中,用户能指示系统示出发行的所有Directive’s,以便弄清楚数据改变为什么发生。
公开的框架跟踪各信息项的ValidTime和当该项变得持久或者变得可恢复并且对其它可恢复事务可见时的TransactionTime。ValidTime和TransactionTime能允许完好存档Directive’s和它们的原因。对于各指令,该指令所基于的信息能在形式上与该指令相关。结果,用户能对于各指令逆动地确定指令发行时刻可用的信息。随时间推移,新信息可能变得可用,这可能是由于之前发行的Directive’s,并且新信息可逆动地应用于截至当信息变得可用(例如,变得可恢复并且对其它可恢复事务可见)时不同TransactionTime’s处过去的ValidTime的状态。然而,因为发行指令后发生的信息改变明确分离为与指令非因果,并且使用改变的TransactionTime描述,尽管改变可逆动地应用于在形式上与该指令有关的ValidTime属性。稍后获取的信息(如果该信息然后可用,则影响了指令的选择)能明确识别为与指令非因果并且能使用事务时间在视图上过滤,使得用户不受可能应该导致了发行不同指令的信息困扰。在任何时刻,通过在稍后的TramsactionTime’s调用截至修正任何新信息之前的较早事务时间的信息,系统能告知用户为什么发行了特定指令,以及该指令的有效时间可用的信息,以支持该特定指令的选择。在某些实施方式中,此双时态起源能力用于满足特定规则要求。
系统趋势和生命征的预报
以上讨论的框架能用于确定趋势并且预报计算系统的“生命征”的未来行为的技术。这些生命征例如能包括JAVA虚拟机(JVM)的内存堆使用和编程线程或堆栈段的强度。通过确定这些生命征的趋势,能确定计算系统是否有可能崩溃。基于这些趋势,能作出关于计算系统何时有可能崩溃的预报。响应于这种预报,系统管理员能在预测的崩溃之前安排系统重启或维护,使得能避免崩溃。
确定趋势的任务能概念化为事实的分类,以便产生信息。以上讨论的框架能系统性地支持这种分类功能。在此特定领域中,事实能涉及关于在不同时间点JVM使用了多少内存和/或程序代码的各种块执行的强度的事实。分类能涉及取得这些事实并且产生决定性信息(例如内存泄露显然存在或程序代码的特定块是过度“热点”)的自动化处理的应用。
符合服务级别协议(SLA)的性能度量的连续监控是云服务提供商的关键运行要求之一,它需要预测诊断能力以检测即将发生的SLA违背,使得操作能够避免大多数SLA违背,并且提供当违背发生时发行的更快求解,从而最小化对顾客体验的影响。预测诊断求解的功效的关键在于系统的相对高级状态空间模型的代表,其可修正以估计和更新从低级事件和测量的状态,并且能有效地预测关键性能指示符的轨迹。系统状态变量应该包括构成系统功能的生命征的各种系统统计的测量。能比喻代表基本身体功能的生命征的诸如心率、血压、体温、呼吸频率的各种生理统计(根据病人的年龄、活动和环境上下文由测量的正常和非正常范围表征)的测量。
云服务功能的生命征能基于来自以规则时间间隔取得的一系列线程库样本的线程和堆栈段的各种类的强度统计的测量值进行定义。能通过此生命征的解释能通过泊松过程和排队论的数学框架中规划的线程或堆栈段强度统计的分析模型告知。强度驱动的分类技术能被应用以逐渐分类线程和堆栈段。系统的状态模型能使用Holt-Winter指示移动平均过滤器根据线程和线程段的各类的季节趋势、线性趋势和一阶非线性趋势进行代表。状态模型表征形成基线的系统的规则操作范围以检测测量离群值。离群值的集群可代表系统的过紧或过松状态,其可与系统故障相互关联并且可被顾客观察为SLA违背。模型支持线程段的动态分类以及下钻分类等级的能力,以观察线程段的特定子类的强度,从而改进导致SLA问题的指示符的小性能差错的观察性和灵敏性。模型还支持季节性调整的长期性能趋势预报。趋势或堆栈段强度能用作系统功能的生命征。系统功能的生命征的观察性、灵敏性和预报都使能有效的预测诊断能力。另外,模型支持线程的类之间的相互依赖信息以捕获线程之间的线程间和进程间通信,提供对线程之间的通信通道或资源池中的队列的业务强度的观察性。
来自Oracle公共云中的融合应用的中层中的WebLogic服务器的线程库能展现与中层、操作系统(OS)、网络和数据库中的系统故障相互关联的模式。WebLogic服务器能用仪器装备,以检测困住长于指定时间(默认为10分钟)的线程。本发明的实施方式能采用提供自适应方法的线程强度的季节和长期趋势的状态模型,以检测困住长于它们预期的响应时间的线程。堵塞线程的大集群指示系统的由于朝向后端服务器和数据库的下流的拥塞导致的过紧状态。模型还能检测系统的由于留下许多线程空闲的系统的拥塞上流导致的过松状态。空闲线程的高强度是堵塞线程的高强度的会话。
线程段分类签名能从收集自云上的所有顾客pods的线程库档案以及来自能放大线程的各类的强度的应力测试系统的线程库档案获知。线程分类签名能由MapReduce算法从Hadoop分布式文件系统(HDFS)集群中存储的大量线程库提取。这些分类签名能自举到生产系统中的预测诊断监控器上。
线程强度或堆栈段强度
线程或堆栈段强度提供系统功能中的性能热点的“热(hotness)”的统计测量。代码块的热通过代码块的调用数量乘以代码块的执行时间而量化。工具能测量调用计数和低级事件的响应时间,诸如指令指针处指令、方法、系统调用、同步等待、硬件计数器溢出等的执行。能用仪器装备应用程序以收集事件的精确测量,但在这种方法中,仪器能影响测量。当由于调用计数增加而关于方法的仪器代码的执行时间支配方法自己的执行时间时,此问题能更显著。在这方面事件的统计采样的热测量的估计比精确测量更有效。包括Oracle、Intel、AMD的CPU供应商提供的性能分析工具利用CPU中设置的硬件计数器来采样事件。这些工具提供基于时间或基于事件的事件的统计采样。在基于时间的采样中,工具记录诸如时间戳、指示指针、内核微状态、线程id、CPU核id和各定时器中断事件处的调用堆栈的事件。在基于事件的采样中,工具记录硬件计数器溢出事件处的事件属性的类似集合。Oracle、Intel、AMD CPU's提供硬件计数器的集合,以采样L1/L2高速缓存缺失、分支误预测、浮点运算等。程序中的指令指针的样本计数的直方图通常在程序中传递热点的定性简档。GNU gprof采样子例程的执行时间,但是使用代码手段来测量调用计数。采样误差通常多于一个采样周期。如果子例程的预期执行时间是n个采样周期,则执行时间估计的预期误差是n个采样周期的平方根。
程序的不同部分的热点简档能呈现在调用图表、调用树和调用堆栈观点中。在各观点中,调用计数统计能与基本执行时间统计组合以将执行时间归于上卷和下钻观点的调用者和调用方法。程序中的指令指针的样本计数的直方图通常传递程序中的热点的定性简档。
线程或堆栈段强度统计的分析模型示出指令指针或堆栈踪迹的站点的基于时间和基于事件的采样,提供不应解释为与仪器技术测量的执行数量的精确计数近似的计数。通过统计采样推导的计数器值的因素包括在站点的执行频率和站点的响应时间二者。站点的执行数量的精确计数不是执行时间的因素。给定指令指针处的指令的执行时间取决于指令需要的CPU时钟周期的数量。在指令指针站点的精确执行计数与统计采样之间的标准化均方根误差、样本覆盖和订单偏差度量的观察的差异中,统计采样计数导致的额外因素是重要因素。站点的统计采样能视为分析模型中的强度测量。
扩展这些统计技术,本发明的实施方式能使用调用堆栈的自动分类和标出系统生命征的季节、线性和一阶非线性趋势的状态空间代表基础的强度统计。本发明的实施方式能扩展线程的单个类的调用堆栈模型,以捕获线程间和进程间通信的线程类之间的依赖。此模型能代表涉及经由远程方法调用(RMI)的客户端-服务器调用、网络服务、JAVA数据库连接性(JDBC)连接、JAVA命名和目录接口(JNDI)连接等的调用堆栈链。它还能代表两个或更多个调用堆栈线程的交互,以进入关键部分或从资源池(诸如JDBC连接池)获取资源。两个交互调用堆栈的强度统计之间的差异能揭示它们之间的通信通道或资源池中的拥塞。另外,调用堆栈依赖模型使得操作者能够将来自多个服务器的发生报告相互关联。通过诊断性框架沿调用链传播的执行内容ID(ECID)能用于将中间件和数据库层上的异常踪迹相互关联,以帮助各个执行上下文中的问题的根本原因分析。对于使用系统生命征的诊断系统问题,诸如线程或堆栈段强度统计,线程或堆栈段的类之间的依赖信息能用于将中间件和数据库层上的发生率相关关联,以帮助根本原因分析。
为了下钻数据库层线程,系统能收集高级结构化查询语言(SQL)语句执行状态报告的统计,诸如SQL自动工作负载责任(AWR)报告,以及数据库服务器OS处理的低级线程库。阻挡经由JDBC连接的数据库操作的各线程类能与数据库服务器中的SQL语句执行计划相互关联。诸如两个SQL AWR快照之间的间隔中的SQL语句执行计划的执行计数和执行时间的统计能被周期性采样。SQL语句执行计划的执行强度能推导为执行计数和平均执行时间的乘积。从中层中的高强度数据库操作线程,实施方式能下钻到数据库层中的高强度SQL语句以诊断问题。例如,次优执行计划能下钻到不合适的数据库方案设计或合适索引缺少用于预测评估。因此,线程依赖信息模型使得监控器能够相关关联中层的强度和数据库层线程以提供完整的端对端图片。
中间件和数据库服务的分类
融合应用(FA)包括财政管理,顾客关系管理(CRM),人力资本管理(HCM),供应链管理(SCM),项目组合管理(PPM),采购以及治理风险承诺。融合应用在代表融合应用的子集的逻辑柱中组织;例如租客系统能由三个柱组成,一个柱包括财务、SCM、PPM和财务服务,第二柱包括HCM服务,第三柱包括CRM服务。柱结构使能大系统的颗粒维护、打包和升级。柱可共享同一FA数据库,但为了使能应用和数据方案的颗粒维护、打包和升级,各柱应该具有利用数据库之间的表复制的单独的数据库。Oracle数据集成器(GDI)能执行两个或更多个柱的数据库之间的数据转变(如果它们使用不同版本的表)。Oracle公共云(OPC)中的FA租客通过包括柱的FA服务族的集合分类;例如,较早示例中的三个FA pods将分别被(财务,SCM,PPM,采购柱)、(HC柱)、(CRM柱)类分类。
Oracle融合应用架构定义在融合中间件架构顶部上,该架构通过将应用组织为能映射到若干可能的Oracle虚拟机(OVM)拓扑(通过编辑Oracle虚拟组件构建器产生的组件)或分布在多个主机上的物理拓扑服务器和域的逻辑拓扑,支持应用服务的负载均衡和高可用性。服务器是运行应用服务的WebLogic服务器的实例。域是包含WebLogic服务器的一个或多个实例的WebLogic服务器域。诸如用于财务管理的{总账,应收账款,支票}的FA服务族能在财务域中按服务器集合组织。FA服务沿域域x服务器维度分类,例如(财务域,管理员服务器),(财务域,总账服务器),(财务域,应收账款服务器),(财务域,支票服务器),(CRM域,管理员服务器),(CRM域,顾客服务器),(CRM域,销售服务器),(CRM域,订单捕获服务器)等。FA服务的各类能在集群中部署,用于负载均衡和高可用性。
域和服务器集群结构能映射到pod中的合适OVM拓扑。例如,融合应用pod中的所有域上的管理员服务包括(CRM域,管理员服务器)、(SCM域,管理员服务器)、(FICM域,管理员服务器)、(财务域,管理员服务器)等,能映射到同一管理员OVM。对于CRM租客,比其它服务需要更多CPU和内存资源的两个服务类(CRM域,顾客服务)和(CRM域,销售服务器)能以集群映射到一对主OVM's,而(CRM域,...)、(SCM域,...)、(HCM域,...)、(财务域,...)、(采购域,...)、(项目域,...)类之中的支持服务能在另一对次级OVM's中在集群中加固。诸如ODI服务器(Oracle数据集成器)、SOA服务器(融合中间件SOA)和ESS服务器(企业调度服务)的一些融合中间件服务能在各域中复制以划分工作负载。
融合应用pod包括三个逻辑数据库服务,即OAM DB(用于Oracle访问管理器)、OIM-APM DB(用于Oracle身份管理和授权策略管理器)和融合DB(用于应用方案),其能映射到RAC数据库服务器的若干不同拓扑。OAM库包含用于认证、单点登录(SSO)和身份辨别的策略;OIM库包含用户简档和组成员;APM库包含RBAC授权策略。融合DB包含用于FA、MDS、SOA、Bl、UCM、WebCenter的各种库。Oracle访问管理器(OAM)和授权策略管理器(APM)使用WebLogie安全服务提供商接口提供用于Java授权和验证服务(JAAS)和Java容器授权协议(JACC)的服务。WebLogic服务器中的OAM网关、访问口和网络服务管理器(OWSM)组件访问OAM库中的验证策略。WebLogic服务器中的Oracle平台安全服务(OPSS)框架访问OIM仓库中的用户的组成员信息并且使用此信息访问APM库中的RBAC授权策略。
FA服务器中的数据访问操作能被它们依赖的数据库服务(数据库,OAM DB)、(数据库,OIM-APM DB)、(数据库,融合DB)标识。能在模型中并入下面的数据库依赖信息:
FA服务器中的OAM连接取决于访问服务器和OAM DB,
FA服务器中的JNDI连接取决于Oracle互联网目录服务器和OIM-APM DB,
来自FA服务器中的OPSS框架的JDBC连接取决于OIM-APM DB,
来自FA服务器中的ADF商业组件(ADF-BC)和元数据服务(MDS)的JDBC连接取决于融合DB,
来自SOA和BI服务器中的BPM、WebCenter、UCM和BI的JDBC连接取决于融合DB。
SQL语句的分类
云顾客的(租客的)FA服务能分布在多个柱/pods、域、服务器集群上。分布式服务器有效地将数据库连接分为JDBC连接池。取决于服务质量(QoS)要求,系统能将不同数量的JDBC连接分配给各池。例如,销售服务器、订单捕获服务器、市场服务器、分析服务器等中的连接池能被分配不同数量的JDBC连接以控制QoS。连接池的大小能被执行数据库操作的中层数据库操作线程类的季节强度趋势和阻抗匹配引导,等待JDBC连接池、以及有效SQL语句类中的连接。通过中层连接池的数据库连接的划分帮助SQL语句的分类并且使得能够隔离问题。它能防止低优先级应用中的差调谐SQL语句针对高强度中层线程阻挡高性能SQL语句。
通过堆栈踪迹的线程和线程依赖关系的分类
堵塞线程的堆栈踪迹能揭示阻挡线程的操作。例如,通过接近下面的堆栈踪迹的开始的堆栈帧“oracle jdbc driver Oracle Statement doExecuteWithTimeout”,接口能被绘出对于数据库操作阻挡线程:
oracle.jdbc.driver.T4CCallableStatement.executeForRows(T4CCallableStatement.java:991)
oracle.jdbe.driver.OracleStatement.doExecuteWithTimeout(OracleStatement.java:1285)
oracle.mds.core.MetadataObject.getBaseMO(MetadataObject.java:1048)
oracle.mds.core.MDSSession.getBaseMO(MDSSession.java:2769)
oracle.mds.core.MDSSession.getMetadataObject(MDSSession.java:1188)
oracle.adf.model.servlet.ADFBindingFilter.doFilter(ADFBindingFilter.java:150)
oracle.apps.setup.taskListManager.ui.customization.Customization Filter.doFilter(CustomizationFi lter.java:46)
weblogic.servlet.internal.WebAppServletContext.secoredExecute(WebAppServlet Context.java:2209)
weblogic.servlet.internal.ServletRequestImpl.run(ServletRequest Impl.java:1457)
weblogic.work.ExecuteThread.execute(FxecuteThread.java:250)
weblogic.work.ExecuteThread.run(ExecuteThread.java:213)
在以上堆栈踪迹中,JDBC驱动器堆栈之下的堆栈帧“oracle mds core MetadataOb ect getBaseMO”指示MDS库发行JDBC操作。MDS库堆栈之下的堆栈帧“oracle adf model serviet ADFBindingFilter doFilter”指示MDS被ADF应用调用,ADF应用通过超文本转换协议(HTTP)服务请求调用。由于此线程在CRM域中的顾客Serviet WebLogic实例中观察,堵塞线程能分类为(CRM域,顾客服务器,HTTP Serviet,ADF应用,ADF-MDS,数据库操作)。此线程取决于由(数据库,融合DB)分类的数据库服务器线程。
下面是用于另一堵塞线程的堆栈踪迹:
com.sun.jndi.ldap.LdapCtx.connect(LdapCtx.java:2640)
com.sun.jndi.ldap.LdapCtxFactory.getInitialContext(LdapCtxFactory.java:48)
javax.naming.spi.NamingManager.getInitialContext(NamingManager.java:637)
javax.naming.InitialContext.init(InitialContext.java:219)
atoracle.adf.controller.internal.security.AuthorizationEnforcer.checkPermission(AuthorizationEnforcer.java:114)
oracle.adf.model.servlet.ADFBindingFilter.doFilter(ADFBindingFilter.java:150)
oracle.apps.setup.taskListManager.ui.customization.CustomizationFilter.doFilter(CustomizationFilter.java:46)
weblogic.servlet.internal.webAppServletContext.securedExecute(WebAppServletContect.java:2209)
weblogic.servlet.internal.ServletRequestImpl.run(ServletRequestImpl.java:1457)
weblogic.work.ExecuteThread.execute(ExecuteThread.java:250)
weblogic.work.ExecuteThread.run(ExecuteThread.java:213)
此堵塞线程被轻量目录访问协议(LDAP)连接阻挡。JNDI堆栈之下的堆栈帧“oracle adfinternal controller state ControllerState eheckPermission”指示ADF控制器使用LDAP连接,可能为了加载将来自LDAP服务器的允许对象用于授权检查。第二线程具有与第一线程相同的堆栈帧“oracle adf model servlet ADFBindingFilter doFilter”之下的堆栈踪迹。它因此与第一线程共享公共分类(FfTTP Servlet,ADF应用)。如果也在CRM域中的顾客服务器Weblogic实例中观察到第二线程,它将分类为(CRM域,顾客服务器,HTTP Servlet,ADF应用,ADF-SECURJTY,LDAP操作)。第二线程取决于通过(OID)分类的OID线程,进而取决于通过(数据库,OIM-APM DB)分类的数据库服务器线程。
线程分类信息模型捕获一个线程类与另一个的依赖关系。例如,为高级线程类定义下面的依赖关系以总结子类的依赖关系:
(ADF网络服务调用)→(ADF网络服务,ADF-BC)
(ADF-BC,数据库操作)→(数据库,融合DB)
(ADF-MDS,数据库操作)→(数据库,融合DB)
(ADF-SECURITY,数据库操作)→(数据库,OIM-APM DB)
(ADF-SECUR1TY,LDAP操作)→(OID)→(数据库,OIM-APM DB)
(SOA-BPEL,数据库操作)→(数据库,融合DB)
(ESS,数据库操作)→(数据库,融合DB)
依赖关系(ADF网络服务调用)→(ADF网络服务,ADF-BC)是包括ADF服务的依赖关系的许多子类的总结。此依赖关系的一个子类是(CRM域,销售服务器,ADF-应用,ADF网络服务调用)→(CRM域,订单捕获服务器,ADF网络服务,ADF-BC,数据库操作)。关系的客户端侧和服务器侧的线程段能被下钻。例如,依赖关系(ADF-BC,数据库操作)→(数据库,融合DB)的客户端侧能下钻至高强度关系(CRM域,订单捕获服务器,ADF网络服务,ADF-BC,数据库操作)→(数据库,融合DB)。类似地在服务器侧,数据库中的调用图表、调用树或调用堆栈模型(包括SQL执行计划和执行踪迹)能下钻为(数据库,融合DB)线程的高强度子类。
包容等级
分类方案的包容等级通过元组投影引入。例如,给定元组(顾客服务器,ADF应用)是元组(CR域,顾客服务器,HTTP Servlet,ADF应用)的投影,分类(CRM域,顾客服务器,HTTP Servlet,ADF应用)包容在分类(顾客服务器,ADF应用)下面。因为分类(CRM域,顾客服务器,HTTP Servlet,ADF应用,ADF-MDS,数据库操作)和(CRM域,顾客服务器,HTTP Servlet,ADF应用,ADF-SECURITY,LDAP操作)包容在分类(CRM域,顾客服务器,HTTP Servlet,ADF应用)下面,以上的两个样本线程包容在(CRM域,顾客服务器,HTTP Servlet,ADF应用)的任何投影下面。因此,两个样本线程的统计聚集在(CRM域,顾客服务器,HTTP Servlet,ADF应用)和其超类的统计中。
除了HTTP Servlet,ADF应用能通过Outlook连接器和Web服务调用。能在(通道x应用)维度中定义附加分类:
(HTTP Servlet,ADF应用)
(Outlook连接器,ADF应用)
(Web服务,ADF应用)
ADF应用部署在不同域中的不同服务器中。能通过取得交叉乘积(域x服务器x通道x应用)分类它们。例如,分类(CRM域,顾客服务器,HTTP Servlet,ADF应用)、(CRM域,顾客服务器,Outlook连接器,ADF应用)、(CRM域,顾客服务器,网络服务,ADF应用)具有最小公共超类(CRM域,顾客服务器,ADF应用)。
操作维度包括分类数据库操作、LDAP操作、网络服务调用等等。数据访问库是另一个维度,包括分类ADF-MDS、ADF-安全、ADF-BC、AQ-JMS等等。能通过取得交叉乘积(域x服务器x通道x应用x库x操作)下钻类等级。
在LISP表达中,元组能视为具有从reverse(cdr(reverse(tuple))))到(tuple)的有效状态转变的线程状态。在这种情况下,car(reverse(tuple))给出堆栈踪迹顶部上的堆栈帧。例如,当ADF应用调用ADF-BC时,状态(HTTP Servlet,ADF应用)中的线程能转变到状态(HTTP Servlet,ADF应用,ADF-BC)。
这里公开的是强度驱动的分类技术,其跟踪各堆栈帧随时间的强度,并且通过堆栈帧的强度引发的堆栈段之间的等同关系区分堆栈踪迹中的堆栈段。它给出在具有同一强度的同一堆栈段中出现的堆栈段的同一分类。此分类技术连续将堆栈段划分为更小的堆栈段,因为段中的各个堆栈帧的强度随时间发散。每次堆栈段分为构成段,对于各构成段,技术创建新分类。例如,当(ADF-BC)段的强度从(ADF应用)段的强度会聚时,对于可划分为(ADF应用)和(ADF-BC)的堆栈段,技术可开始于分类(ADF应用商业组件)。分类(ADF应用商业组件)是新分类(ADF应用)和(ADF-BC)下面包容的别名(ADF应用,ADF-BC),
每次创建新分类以分类堆栈段时,该技术生成全局唯一标识符(QUID)。当堆栈段分为均被分配新分类的各构成段时,算法可从合并段的分类的标识符推导新分类的标识符。例如,合并段的标识符可能是546372819。如果此段分为2个构成段,则技术能将标识符546372819-1和546372819-2分配给构成段。如果段546372819-1再次上分为2个构成段,技术能将标识符546372819-1-1和546372819-1-2分配为构成段。
隐性知识能应用以将诸如(ADF-BC)、(ADF-MDS)或(ADF-VIEW)的有意义名称分配给分类。隐性知识还能分配诸如通道、应用或操作的维度,以组织分类。分类和维度的知识库能提供以自举自动分类技术。如果为后续分为构成段的堆栈段的分类识库指定名称,例如(ADF-VIEW),对于来自合并段的名称(ADF-VIEW)的构成段,技术能推导推导诸如(ADF-VIEW-1)、(ADF-VIEW-2)、(ADF-VIEW-1-1)等分类名称。
隐性知识能帮助创建和维护线程依赖关系的知识库,其用于关联服务中的出现与问题下的服务器以帮助根本原因分析。线程依赖关系(诸如[(ADF网络服务调用,HTTP-客户端)→(ADF网络服务,ADF-BC)]和[(ADF-BC,数据库操作)→(数据库,融合DB)])在隐性知识分配的堆栈段名称方面定义。
线程或堆栈段强度统计的上卷和下钻
此分类方案提供上卷和下钻统计分析的许多维度。一个感兴趣统计是线程或堆栈段的强度。假设泊松分布到达,预期强度ρ(对应于预期响应时间τ的时间间隔期间的预期到达数量)通过Little的公式与预期响应时间τ和到达速率λ有关:
ρ=λ·τ
线程或堆栈段的类的平均强度能从规则地取得(例如每1分钟)的一系列线程库样本测量。给定恒定到达速率λ,线程或堆栈段的平均强度ρ与线程或堆栈段的平均响应时间τ成比例。到达速率能假设在短时间间隔期间(例如,15分钟)不改变用于季节索引。Holt-Winter预报和季节趋势过滤器能跟踪许多季节周期上的各季节索引的季节因子。如果季节索引的季节因子调整的样本的强度的尖峰在平均强度之上,则它指示线程堵塞长于平均响应时间。离群值过滤器能检测这作为异常。
各线程库中的线程或堆栈段的类(调用特定操作)的强度能是样本时间窗口的预期长度内的操作的到达数量的测量。强度提供样本时间窗口的预期长度的直接测量。
线程或堆栈段强度统计暗示系统将趋于看到具有高到达速率和长响应时间的组合的线程或堆栈段的堆栈踪迹。强度小于1(诸如0.05的分数值)的线程或堆栈段能通过计数足够数量的线程库上的对应堆栈踪迹的出现率而检测。例如,具有每秒0.5的到达速率和0.1秒的预期响应时间的线程或堆栈段的类将具有每线程库0.05的预期线程或堆栈段强度。每线程库0.05的强度意味着此线程或堆栈段的类的堆栈踪迹的平均一个出现率应该在20个线程库中可检测。如果各线程库代表预期长度τ=0.1秒的样本时间窗口,则20个线程库总计达预期长度20·τ=2秒的样本时间窗口。因此2秒窗口中的线程或堆栈段的此类的发生率的预期数量由20·γ·τ=1给出。
对于泊松处理,以上推理有效,只要样本时间窗口非重叠。为了确保样本时间窗口非重叠,采样间隔必须显著大于给定线程类的预期响应时间τ。这里公开的是抗锯齿方法,其检测之前的样本时间窗口中已经计数的堵塞线程,以确定系统仅计数在当前样本时间窗口内到达的线程。这保持样本时间窗口非重叠。如果线程不堵塞,仍可能的是拖延线程出现为连续线程库中的不同子类。例如,ADF应用线程可计数多次作为一个线程库中的(ADF应用,ADF-MDS)和另一个线程库中的(ADF应用,ADF-BC)。本发明的实施方式避免计数拖延线程多于一次,以确保样本时间窗口是独立的。如果诸如设置线程的执行上下文的servlet过滤器的根类中的应用在线程名称中附加时期计数器,拖延线程能针对抗锯齿检测。时期计数器能与线程的执行上下文的ECID相关。
嵌套线程或堆栈段强度统计
嵌套的子类能表示为状态机中的状态。例如,示例类(ADF应用)能包含示例子类(ADF应用,ADF-BC),其能包含示例子类(ADF应用,ADF-BC,数据库操作)。这三个嵌套子类中的每个能表示为状态机中的状态。
各子类中的线程能具有各种强度。为了下面讨论的目的,ρ(ADF)代表(ADF应用)线程的强度,ρ(ADF-BC)代表(ADF应用,ADF-BC)线程的强度,ρ(ADF-BC-JDBC)代表(ADF应用,ADF-BC,数据库操作)线程的强度。(ADF应用,ADF-BC,数据库操作)线程的强度包括在(ADF应用,ADF-BC)线程的强度中,进而包括在(ADF应用)线程的强度中。
(ADF应用,ADF-BC,数据库操作)线程的强度代表间隔τ(ADF-BC-JDBC)内的数据库操作的到达数量。这些数据库操作的到达数量可观察为离开之前取得的线程库中的JDBC堆栈帧。数据库操作的到达和离开能表示为状态机中到“开始数据库操作”和“结束数据库操作”状态的状态转变。强度(即,预期到达数量)取决于到达点的强度和“开始数据库操作”和“结束数据库操作”状态之间的时间间隔的预期长度。如果到达点的密度λ和/或数据库操作的预期响应时间τ(ADF-BC-JDBC)尖峰,数据库操作的强度将尖峰。假设到达点的密度λ在季节索引内恒定,强度中的尖峰能归于堵塞长于预期的数据库操作。线程的三个嵌套类的强度能沿链上卷:
划分线程或堆栈段强度统计
调用ADF-BC库的线程的分数可能需要使用JDBC执行数据访问,而线程的其它可访问高速缓存中的数据。此场景的状态转变图能用泊松进程到两个泊松子进程的划分表示。如果λ(ADF-BC)表示ADF-BC线程的到达密度,λ(ADF-BC-JDBC)表示ADF-BC-JDBC线程的密度,λ(ADF-BC-cache)代表跳过JDBC操作的ADF-BC线程的密度,则两个泊松进程ADF-BC-JDBC和ADF-BC-cache的和是泊松进程ADF-BC,密度和强度如下给出
λ(ADF-BC)=λ(ADF-BC-JDBC)+λ(ADF-BC-cache)
ρ(ADF-BC)=ρ(ADF-BC-JDBC)+ρ(ADF-BC-cache)
如果p代表调用JDBC操作的λ(ADF-BC)的百分比,则
λ(ADF-BC-JDBC)=p·λ(ADF-BC)
λ(ADF-BC-cache)=(1-p)·λ(ADF-BC)
如果用τ(ADF-BC)、τ(ADF-BC-JDBC)、τ(ADF-BC-cache)代表对应的预期响应时间,则
ρ(ADF-BC)=ρ(ADF-BC-JDBC)+ρ(ADF-BC-cache)
ρ(ADF-BC)=λ(ADF-BC-JDBC)·τ(ADF-BC-JDBC)+λ(ADF-BC-cache)·τ(ADF-BC-cache)
λ(ADF-BC)·τ(ADF-BC)=p·λ(ADF-BC)·τ(ADF-BC-JDBC)+(1-p)·λ(ADF-BC)·τ(ADF-BC-cache)
τ(ADF-BC)=p·τ(ADF-BC-JDBC)+(1-p)·τ(ADF-BC-cache)
线程的嵌套类的强度能沿有向链上卷:
合并线程或堆栈段强度统计
线程的两个示例类(顾客服务器,HTTP Servlet,ADF应用)和(顾客服务器,Outlook连接器,ADF应用)能在示例超类(顾客服务器,ADF应用)下合并。ADF应用的强度统计包括通过HTTP Servlet和Outlook连接器的请求。可假设ADF应用的响应时间对于HTTPServlet和Outlook连接器通道相同。
τ(ADF)=τ(HTTP-ADF)=τ(Outlook-ADF)
合并进程的到达率是λ(ADF)=λ(HTTP-ADF)+λ(Outlook-ADF)
合并进程的强度是
ρ(ADF)=λ(ADF)·τ(ADF)
=(λ(HTTP-ADF)+λ(Outlook-ADF))·τ(ADF)
=λ(HTTP-ADF)·τ(HTTP-ADF)+λ(Outlook-ADF)·τ(Outlook-ADF)
=ρ(HTTP-ADF)+ρ(Outlook-ADF)
分段线程或堆栈段强度统计
线程的示例类(ADF应用)能包括线程的三个示例子类(ADF应用,ADF-BC)、(ADF应用,ADF-MDS)、(ADF应用,ADF-SECURITY)。这三个线程子类代表合成状态的调用的序列。能用以下方式表示对应的线程强度。ρ(ADF-BC)代表(ADF应用,ADF-BC)线程的强度;ρ(ADF-MDS)代表(ADF应用,ADF-MDS)线程的强度;ρ(ADF-SECURITY)代表(ADF应用,ADF-SECURITY)线程的强度。
ADF应用的预期响应时间能分段为ADF-BC、ADF-MDS、ADF-SECURITY调用的响应时间:
τ(ADF)≈τ(ADF-BC)+τ(ADF-MDS)+τ(ADF-SECURITY)
ADF应用的线程或堆栈段强度能被组件响应时间分段:
ρ(ADF)≈λ(ADF)·τ(ADF)
≈λ(ADF)·(τ(ADF-BC)+τ(ADF-MDS)+τ(ADF-SECURITY))
由于到达密度λ(ADF)对于所有3个子类相同,超类线程或堆栈段的强度由线程或堆栈段的3个子类的强度组成:
ρ(ADF)≈λ(ADF-BC)·τ(ADF-BC)+λ(ADF-MDS)·τ(ADF-MDS)+λ(ADF-SECURITY)·τ(ADF-SECURITY)
≈ρ(ADF-BC)+ρ(ADF-MDS)+ρ(ADF-SECURITY)
因此,合成状态的预期强度能按比例归于合成状态的预期强度。
乘以线程或堆栈段强度统计中的到达速率
假设ADF-JAAS代表从ADF-BC、ADF-MDS、ADF-SECURITY状态中的任何堆栈帧可调用多次的访问控制检查,投影(ADF应用,ADF-JAAS)代表执行访问控制检查的线程的状态。其合并以下三个子类(ADF应用,ADF-BC,ADF-JAAS)、(ADF应用,ADF-MDS,ADF-JAAS)、(ADF应用,ADF-SECURITY,ADF-JAAS)的强度统计。
根据预期次数,每个ADF应用线程可调用访问控制检查,状态(ADF应用,ADF-JAAS)的到达速率(ADF-JAAS)能是ADF应用的到达速率λ(ΑDF)的倍数。在下面的等式中,ω代表乘法因子:
λ(ADF-JAAS)=ω·λ(ADF)
ADF线程样本的到达处理是泊松到达处理。ADF-JAAS线程样本的到达处理不是泊松到达处理,因为ADF-JAAS线程样本的多个到达能取决于一个ADF线程样本的到达。然而,我们仍能应用Little的公式ρ=λ·τ,其对于任意平均遍历的到达处理成立。我们认为,如果它们的到达时间之间的间隔足够大,ADF-JAAS线程样本的到达处理是平均遍历的,因为任意两个ADF-JAAS线程样本的到达是独立的。因此线程或堆栈段(ADF应用,ADF-JAAS)的强度由以下给出:
ρ(ADF-JAAS)=λ(ADF-JAAS)·τ(ADF-JAAS)
=ω·λ(ADF)·τ(ADF-JAAS)
如果替代λ(ADF)=ρ(ADF)/τ(ADF),则产生以下等式:
ρ(ADF-JAAS)=ω·[τ(ADF-JAAS)/τ(ADF)]·ρ(ADF)
线程或堆栈段(ADF应用,ADF-JAAS)的强度是线程或堆栈段(ADF应用)的因子ω·τ(ADF-JAAS)/τ(ADF)。例如,如果对ADF应用的每个请求执行5个访问控制检查,即,ω=5,并且ADF-JAAS的预期响应时间构成ADF应用的预期响应时间的10%,即,τ(ADF)=10·τ(ADF-JAAS),则线程或堆栈段的平均强度将构成ADF应用线程或堆栈段的50%。能预期
因此,ω·τ(ADF-JAAS)/τ(ADF)<1。
通过线程或堆栈段强度统计的阻抗匹配
可考虑以下示例:两节点CRM域销售服务器集群和两节点CRM域订单捕获服务器集群之间存在通信通道。这些通道能支持销售服务中的线程类与订单捕获服务中的线程类之间的客户端-夫妻依赖关系:
(CRM域,销售服务器,ADF应用,ADF网络服务调用)→(CRM域,订单捕获服务器,ADF网络服务,ADF-BC)
对应的线程强度能如下表示:ρ(ADF-HTTPClient)表示销售服务器集群中的(CRM域,销售服务器,ADF应用,ADF网络服务调用)线程的强度;ρ(ADF-HTTPClient(i))表示销售服务器节点i中的(CRM域,订单捕获服务器,ADF网络服务器,ADF-BC)线程的强度;ρ(WebService-ADF-BC)代表订单捕获服务器集群中的(CRM域,订单捕获服务器,ADF网络服务,ADF-BC)线程的强度;ρ(WebService-ADF-BC(i))代表订单捕获服务器节点i中的(CRM域,订单捕获服务器,ADF网络服务,ADF-BC)线程的强度。
给定在销售服务器和订单捕获服务器集群中分别存在n个和m个节点:
如果销售服务器和订单捕获服务器之间的通信通道没有向从销售服务从订单捕获服务的网络服务调用引入任何阻抗失配,则:
ρ(ADF-HTTPClient)=ρ(WebService-ADF-BC)
如果观察到客户端和服务器线程的强度的差异,则能归于通信通道中的拥塞。如果ρ(channel)表示客户端和服务器线程之间的通信通道针对业务强度,则:
ρADF-HTTPClient)=ρ(WebService-ADF-BC)+ρ(channel)
当到达和离开速率平衡时:
λ(ADF-HTTPClient)=λ(WebService-ADF-BC)=λ(channel),并且τ(ADF-HTTPClient)=τ(WebService-ADF-BC)+τ(channel)。
能增加通信通道的能力以减少客户端服务与服务器服务之间的阻抗失配,该失配对客户端的响应时间τADF-HTTPClient)贡献了延迟τ(channel)。
强度饱和
线程或堆栈段强度是线程库中的线程或堆栈段的类的堆栈踪迹的预期数量的测量。线程强度将随线程或堆栈段的给定类的到达速率和预期响应时间增加而增加。
一些系统对可用于运行给定线程类的线程的最大数量施加限制。当达到此限制时,线程或堆栈段强度变得饱和(达到最高极限)并且统计将不再反映关系ρ=λ·τ,即使到达速率或响应时间可继续增加。本发明的实施方式能够识别何时达到饱和点。本发明的实施方式包括推断强度的发展趋势的Holt-Winter三重指数移动平均过滤器。当这些实施方式检测强度在最大处趋于稳定并且停止遵循投影的发展趋势时的一系列离群值时,它们能识别饱和点。
如果系统不对最大强度施加限制,线程或堆栈段强度可能发展超出界限,并且导致系统中内存用光错误。此条件能被Holt-Winter三重指数移动平均过滤器预测为端点。
抗锯齿
泊松计数处理需要样本窗口非重叠并且独立。这需要堵塞线程和拖延线程计数不超过一次。系统使用Threadlnfo.getThreadld()和ThreadMXBean.getThreadCpuTime(long id)in java.lang.managementAPI监控各线程的中央处理单元(CPU)时间。技术推测,如果线程的CPU时间自之前线程库起不改变,线程堵塞。技术还跟踪其中此线程被检测为堵塞的连续线程库的数量。这些变量能维持在ThreadAntiAliasingInfo数据结构中。
如果线程拖延但不堵塞,CPU时间将改变。为了检测拖延线程,抗锯齿技术与诸如堆栈踪迹的根帧之中的servlet过滤器的类协作以使用java.lang.Thread setName编程接口(API)将时期计数器附加到线程的名称。如果线程名称与ThreadAntiAliasingInfo中记录的之前线程名称相同,则技术推测线程已被计数。当线程名称中的时期信息重用于新时期时,当线程池中的同一线程被观察为锯齿时,线程名称中的时期信息提供抗锯齿解决。
如果针对特定线程类持续检测到堵塞或拖延线程,技术能自适应采样间隔(利用每第N个线程库),直到此线程类的样本时间窗口的预期长度小于N*M分钟,其中M是采样时间间隔。
过紧和过松状态
JVM能用仪器装备以检测可代表系统的过紧状态的堵塞线程。过紧状态能被诊断为朝向数据库或后端服务器的下流路径中的拥塞。然而,本发明的实施方式也能检测当由于上流路径中的拥塞导致请求不能进入服务器时的过松状态(脱水)。后一条件不能被用于堵塞线程检测的常规JVM仪器检测到。使用线程或堆栈段强度的离群值检测能对称地检测过紧和过松状态二者。
如果线程的最大数量是N并且预期ρ线程或堆栈段强度是ρ,则通过泊松分布给出饱和的概率:
如果预期线程或堆栈段强度是5并且线程或堆栈段的最大数量是10,使线程或堆栈段强度饱和的概率是0.032,这意味着线程库的3.2%将示出在10饱和的强度。假设预期线程或堆栈段强度是50并且线程或堆栈段的最大数量是100,则线程或堆栈段强度饱和的概率是3.2E-10。此概率下,饱和的正常起因不大可能,线程或堆栈段强度饱和必然是由于诸如到服务器的下流严重拥塞的异常起因。同样,在概率5.0E-10下,线程或堆栈段强度不大可能降至14之下,除非服务器由于到服务器的上流拥塞而严重脱水。
堆栈帧的强度驱动的分类
通常,在某时段上线程库被采样足够次数之后,能预期低强度线程或堆栈段的堆栈踪迹的检测。有时,强度太低以至于即使在线程库的长周期后无法被检测到的堆栈帧能由于系统差错或软件升级的回归而被检测到。然而,能存在非常少的保持未被检测且未被分类的堆栈帧。当堆栈帧的新踪迹在足够数量的线程库之后或者在造成它们的强度达到尖峰的系统差错之后被检测到时,本发明的实施方式能连续分类堆栈帧的新踪迹。这里公开的是由堆栈帧的强度测量驱动的分类方案。
系统跟踪各个堆栈帧以及在堆栈踪迹中与堆栈帧相邻出现的在先和后续堆栈帧的强度。系统将同一分类分配给以相同强度出现的相邻堆栈帧—即,总是一起作为堆栈踪迹中的有序阵列出现的堆栈帧。例如,方案将把(JDBC-Execute)类分配给总是一起作为具有同一强度的有序阵列出现的下面的堆栈帧:
oracle.jdbc.driver.T4CCallableStatement.executeForRows(T4CCallableStatement.java:991)
oracle.jdbe.driver.OracleStatement.doExecuteWithTimeout(OracieStatement.java:1285)
oracle.jdbe.driver.OraclePreparedStatement.executeInternal(OraclePreparedStatement.java.3449)
oracle.jdbe.driver.OraclePreparedStatement.execute(OraclePreparedStatement.java:3550)
oracle.jdbe.driver.OracleCallableStatement.execute(OracleCallableStatement.java:4693)
oracle.jdbe.driver.OraclePreparedStatementWrapper.execute(OraclePreparedStatementWrapper.java:1086)
如以上讨论的,ADF应用的强度ρ(ADF)能通过将其分段为3个组分ρ(ADF-BC),ρ(ADF-MDS)和ρ(ADF-SECURITY)而近似:
ρ(ADF)≈ρ(ADF-BC)+ρ(ADF-MDS)+ρ(ADF-SECURITY)
为了改进模型,与ADF-BC、ADF-MDS、ADF-SECURITY状态不相交的各种ADF应用状态的强度能在(ADF应用,ADF-misc)类下上卷。相比于3个主要组分的强度,最后状态的强度ρ(ADF-misc)可以是可忽略的:
ρ(ADF)=ρ(ADF-BC)+ρ(ADF-MDS)+ρ(ADF-SECURITY)+ρ(ADF-misc)
(ADF应用,ADF-misc)类下面的线程或堆栈段的子类的强度由于系统差错而达到尖峰是可能的。例如,文件系统差错能导致一些ADF应用线程在文件写操作中堵塞:
java.io.FileOutputStream.writeBytes(Native Method)
java.io.FileOutputStream.write(fileOutputStream.java:260)
java.io.OutputStreamWriter.flush(OutputStreamWriter.java:213)
org.apache.log4j.heipers.QuietWriter.flush(QuietWriter.java:57)
org.apache.log4j.WriterAppender.append(WriterAppender.java:159)
at oracle.adf.View.process(View.jaca:632)
假设此堆栈帧在阈值之上达到尖峰,ADF应用线程的新状态(ADF应用,ADF-View-misc)能被分类。对于尖峰持续时间,ADF应用的强度ρ(ADF)能分解为4个组分:
ρ(ADF)=ρ(ADF-BC)+ρ(ADF-MDS)+ρ(ADF-SECURITY)+ρ(ADF-View-misc)
执行文件写操作的堆栈帧可出现在ADF-View-misc堆栈帧以及ADF-BC、ADF-MDS和ADF-Seeurity堆栈帧的顶部。随时间推移,系统可检测到在ADF-View-misc中文件写操作堆栈帧的强度偏离其它堆栈帧的强度。分离不同组的堆栈帧的强度将导致新分类(文件写操作)并且分类(ADF-View-misc)分段为(ADF-View,文件写操作)。之前的分类(ADF-View-misc)归入新的(文件写操作)和(ADF-View)类下面。新的(文件写操作)类还与(ADF-BC)、(ADF-MDS)、(ADF-Security)类交互以形成新的子类(ADF-BC,文件写操作),(ADF-MDS,文件写操作)、(ADF-Security,文件写操作),它们的强度也达到尖峰。因此强度驱动(文件写操作)和(ADF-View)类的分类。
系统可征求人类隐性知识以分类堆栈帧并且将分类分配给合适维度,在本发明的某些实施方式中,归纳学习处理能将新分类分配给系统已经定义的维度。例如,通过分析(ADF-BC,文件写操作)、(ADF-MDS,文件写操作)、(ADF-Security,文件写操作)、(ADF-View,文件写操作)堆栈踪迹的强度和邻接统计,归纳学习处理可将(文件写操作)类分配给操作维度并且将(ADF-View)类分配给库维度,如以下所示:
操作=(数据库操作)|(LDAP操作)|(网络服务调用)|(文件写操作)
库=(ADF-BC)|(ADF-MDS)|(ADF-SECURITY)|(ADF-VIEW)
为了实现堆栈踪迹中的各个堆栈帧的分类,系统维持当前线程库中的堆栈帧的出现的数量(numOfOccur)、所有线程库中的出现的总数(totalNumOfOccur)、在先的列表、后续的列表、以及使用StackFramelnfo数据结构的合并段。StackFramelnfo数据结构中的classMethodLineNumber变量保持字符串,诸如代表线程库中的堆栈帧的“weblogic.work.ExecuteThread run(ExecutaThread.java:213)”。numOfOccur保持当前堆栈库中的字符串“weblogic.work.ExecuteThread run(ExecutaThread.java:213)”的出现的数量。通常强度=totalNumOfOccur/totalNumOfDumps给出推导的变量的强度测量。
如果诸如(ADF-View-misc)的现有分类划分为两个新分类,诸如(ADF-View,文件写操作),则新分类保持为原始分类的第一段和第二段。原始分类设置为新分类的合并段。术语分类的堆栈帧的也维持为分类中的元素。分类和维度的名称是可选的,能被隐性知识指定。使用StackSegmentlnfo数据结构维持合并段、第一构成段、第二构成段以及堆栈段分类的元素。
由于递归程序构造能重复可变次数的堆栈段也被StackSegmentlnfo分类。此递归的StackSegmentlnfo能出现在不同上下文中,即,它能出现在多于合并段或线程的一个类中。RecursiveSegmentlnfo数据结构用于在各上下文中代表StackSegmentlnfo的递归出现,以在RecursiveSegmentlnfo数据结构中记录递归(numOfRecur)的深度。RecursiveSegmentlnfo还能构成访客设计模式中的互递归段,用于树遍历。例如,简单互递归构造将是(A,B)n,其中A和B互相调用。其中互递归涉及不同类型的树节点{Al,A2,A3}和不同类型的访客节点{Bl,B2,B3}的访客设计模式将是((A1,B1),(A3,B3)2,(A2,B2),(A3,B3)5,...)。互递归段(例如段(A3,B3)n)能在堆栈踪迹中的不同位置出现任意次数。各位置由RecursiveSegmentlnfo的实例代表。
技术将现场的堆栈踪迹划分为叶子级堆栈段的序列,然后合并叶子级堆栈段,直到它得到顶级合并堆栈段的序列,各顶级合并堆栈段能获得代表构成段的等级的二叉树结构。此代表形成用于分类线程的等价类的签名并且减少对于大的线程库匹配线程的模式的时间复杂度。使用ThreadClassificationInfo数据结构维持线程分类信息。
本发明的实施方式还过滤堆栈帧的各分类的强度的季节趋势。SeasonalTrendInfo数据结构包含一些过滤器变量。SeasonalTrendInfo中的rawIntensity变量在当前线程库中记录堆栈帧、堆栈段或线程类的强度。如果堆栈段是叶子级段(无子分段),则numOfOccur将与堆栈段中的各StackFramelnfo元素的numOfOccur相同。过滤器更新平滑的强度和平滑的强度发展速率以预报强度的发展趋势。预报的强度的标准化残留能用作用于检测离群值的过滤器,其代表测量的强度何时与预期强度偏离。此条件能代表服务的过紧或过松状态。
强度驱动的分类的示例场景
假设系统分类了堆栈踪迹中的堆栈帧的阵列,则堆栈帧的列表能构成堆栈段(A)的元素。各堆栈帧元素维持强度、出现次数、在先和后续信息。在10个线程库之后,此类中的堆栈帧例如可具有1.3的相同强度。
在100个线程库之后,堆栈段(A)中的堆栈帧的强度可能分为三个组,底部3个堆栈帧的强度增加至2.5,顶部3个堆栈帧的强度稍微增加至1.33,用作glue帧的中间堆栈帧的强度停留在大约1.3。随着强度分开,系统将堆栈段(A)划分为两个构成堆栈段(A-1)和(A-2),并且再次将堆栈段(A-2)划分为(A-2-1)和(A-2-2)。中间堆栈帧(A-2-1)的强度表示堆栈段(A)的强度,即,A=(A-1,A-2-1,A-2-2)。(A-1)和(A-2-2)的强度分开是因为它们出现在堆栈踪迹(A-1,AC,C)和(B,BA,A-2-2)中,其中(AC)和(BA)代表分别将(A-1)与(C)连接并且将(B)与(A-2-2)连接的glue帧。特定堆栈帧能具有多个在先和多个后续。
当技术检测堆栈段的堆栈帧之间的强度的发散时,它划分新构成堆栈段之中的堆栈帧元素。例如,构成堆栈段(A-1)、(A-2)、(A-2-1)、(A-2-2)(每个直接或间接参考堆栈段(A)作为合并段)能从这种划分产生。在示例中,堆栈段(A)中的元素能划分为堆栈段(A-1)中的元素和堆栈段(A-2)中的元素。堆栈段(A-2)进而能划分为堆栈段(A-2-1)中的元素和堆栈段(A-2-2)中的元素。更新堆栈段以参考对应的叶子级合并段。各种元素的合并段能被更新以反映元素所属的新堆栈。
可以观察仅通过构成元素的递归深度而不同的堆栈段的变化。假设某些分段的强度保持相同,但是其他分段的强度由于任意递归深度而发散,系统能将原始段划分为构成段。原始堆栈段的元素能包含可变数量的堆栈段,其由A-2-1分类。因此,原始堆栈段的构成段将包含可变数量的段A-2-1。匹配指定模式的任何堆栈踪迹能被同一分类签名标识。递归段能指向堆栈段A-2-1作为合并段A-2的第一构成段的分类。
系统能针对各新堆栈段(A-l)、(A-2)、(A-2-1)、(A-2-2)在堆栈段(A)中创建SeasonalTrendlnfo数据的一个副本,以用作初始过滤器状态。随后,能独立更新(A-l)、(A-2)、(A-2-1)、(A-2-2)的SeasonalTrendlnfo数据。
线程类依赖信息模型
线程分类和强度测量算法能用提供线程类之间的依赖信息的知识库自举。依赖信息能用于估计线程类之间的通信通道中的业务强度。它们还能关联事件并且发生用于根本原因分析的问题容器中的FA服务器的不同部分中的两个或更多个线程类。例如,假设线程类依赖(CRM域,销售服务器,ADF应用,ADF网络服务调用)→(CRM域,订单捕获服务器,ADF网络服务,ADF-BC),则如果FA pod中的销售服务器和订单捕获服务器同时报告客户端线程的过松状态和服务器线程的过紧状态,这些事件能在出现时收集。如果这些事件发生足够经常,则能打开票并且分配给拥有者以分析销售服务器域订单捕获服务器集群之间的通信通道中的可能的阻抗失配。拥有者可访问这些发生作为阻抗匹配问题并且提交服务请求。
通常,在超类级别指定依赖信息。例如,依赖(ADF网络服务调用)→(ADF网络服务,ADF-BC)捕获分布在Fapod中的WebLogic域和服务器上的ADF服务之间的服务调用的普通模式。此摘要依赖包括依赖(CRM域,销售服务器,ADF应用,ADF网络服务调用)→(CRM域,订单捕获服务器,ADF网络服务,ADF-BC)。在另一种情况下,摘要依赖模式(ADF-BC,数据库操作)→(数据库,融合DB)和(ADF-SECURITY,数据库操作)→(数据库,OIM-APM DB)实现JDBC线程的过紧问题的差分诊断,以隔离一个数据库服务器中的问题。
信息模型能映射线程之间的依赖关系。ThreadClassDependencylnfo能代表从客户端线程类到服务器线程类的多对一映射。ThreadClassInfo能通过堆栈段的元组指定线程的类。例如,(ADF-BC,数据库操作)是堆栈段(ADF-BC)和(数据库操作)的元组。类(CRM域,订单捕获服务器,ADF网络服务,ADF-BC,数据库操作)是(ADF-BC,数据库操作)的子类。ThreadClassInfo包含代表用于分类线程的签名的堆栈段的列表。技术能执行二叉树的单个深度优先遍历(从堆栈帧的底部至顶部),从访问的堆栈段对象的partOfThreadClasses属性提取线程类对象,并且针对分类签名中的堆栈段匹配ThreadClassInfo中的堆栈段。当线程类匹配时,客户端或服务器线程类包括在警报或发生报告中。
应用线程或堆栈段强度分析
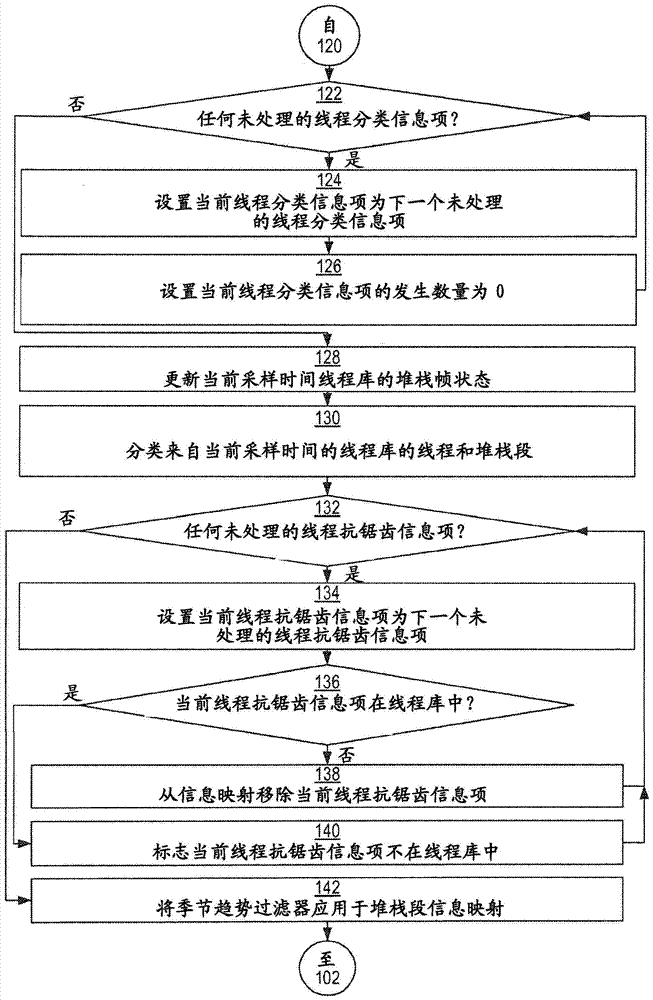
图1A-B示出根据本发明的实施方式的例示用于应用线程或堆栈段强度分析学的技术示例的流程图。技术维持堆栈帧信息映射、堆栈段信息映射、线程分类映射和抗锯齿信息映射。堆栈帧信息映射、堆栈段信息映射、线程分类映射由从截至时间点收集(在采样时间之前的一系列采样时间收集)的线程库样本提取的堆栈帧、堆栈段、线程分类组成。这些映射能可选地用从历史档案中的线程库提取的堆栈帧、堆栈段和线程分类自举。抗锯齿信息映射可代表在之前的线程库中采样的线程。线程抗锯齿信息映射用于识别之前采样时间的线程库中已经遇到的当前采样时间的线程库中的线程。采样数据的线程库的堆栈踪迹能使用堆栈帧信息映射、堆栈段信息映射和线程分类映射分类。这些映射是图1A-B和后续图中的流程图描绘的处理的上下文的部分。首先参考图1A,在框102,当前采样时间到达。
在框104,当前采样时间设置为下一个采样时间,经过了采样时间间隔时的时间点。在框106,获得当前采样时间处的所有线程的线程库。例如,当前采样时间的线程库能从java.lang.management.ThreadMXBean获得。在框108,线程库计数器增加。
对于各采样时间的线程库,堆栈帧信息映射中的各堆栈帧信息项的发生计数器的数量重置为0,使得计数器能用于计数当前线程库中的堆栈帧的发生数量。为了实现这,在框110,确定堆栈帧信息映射中的未处理的堆栈帧信息项是否保持被处理。如果是,则控制转到框112。否则,控制转到框116。
在框112,当前堆栈帧信息项设置为堆栈帧信息映射中的下一个未处理的堆栈帧信息项。在框114,当前堆栈帧信息项的发生的数量设置为0。控制转回框110。
对于各样本点的线程库,堆栈段信息映射中的各堆栈段信息项的发生计数器的数量重置为0,使得计数器能用于计数当前线程库中的堆栈段的发生数量。为了实现这,在框116,确定堆栈段信息映射中的未处理的堆栈段信息项是否保持被处理。如果是,则控制转到框118。否则,控制转到图1B的框122。
在框118,当前堆栈段信息项设置为堆栈段信息映射中的下一个未处理的堆栈段信息项。在框120,当前堆栈段信息项的发生的数量设置为0。控制转回框116。
对于各样本点的线程库,线程分类信息映射中的各线程分类信息项的发生计数器的数量重置为0,使得计数器能用于计数当前线程库中的线程的发生数量。为了实现这,现在参考图1B,在框122,确定线程分类信息映射中的未处理的线程分类信息项是否保持被处理。如果是,则控制转到框124。否则,控制转到框128。
在框124,当前线程分类信息项设置为线程分类信息映射中的下一个未处理的线程分类信息项。在框126,当前分类信息项的发生的数量设置为0。控制转回框122。
在框128,更新当前采样时间的线程库的堆栈帧统计。下面参考图2A-B公开更新当前时间间隔的线程库的堆栈帧统计的技术。在框130,通过分类来自当前采样时间的线程库的线程和堆栈段确定线程类的集合。下面参考图3A-J公开分类来自当前采样时间的线程库的线程和堆栈段的技术。
对于各样本时间的线程库,检查线程抗锯齿信息映射中的各线程抗锯齿信息项中的标志,以确定分类的线程是否出现在当前线程库中。如果分类的线程不出现在当前线程库中,将其从线程抗锯齿信息映射移除。为了实现这,在框132,确定未处理的线程抗锯齿信息项是否保持在线程抗锯齿信息映射中。如果是,则控制转到框534。否则,控制转到框142。
在框134,当前线程抗锯齿信息项设置为线程抗锯齿信息映射中的下一个未处理的线程抗锯齿信息项。在框136,确定指示当前线程信息项是否出现在当前采样时间的线程库中的用于当前线程抗锯齿信息项的标志是否为假。如果是,则控制转到框138。否则,控制转到框140。
在框138,从线程抗锯齿信息映射移除当前线程抗锯齿信息项。控制转回框132。
在框140,用于当前线程抗锯齿信息项的标志设置为假。控制转回框132。
在框142,相对于当前样本时间的堆栈段信息映射应用季节趋势过滤器。下面参考图4公开用于应用季节趋势过滤器的技术。控制转回图1A的框102。
更新堆栈帧统计
图2A-B示出根据本发明的实施方式的例示用于更新堆栈帧统计学的技术示例的流程图。能相对于以上参考图1A-B参考的当前采样时间的线程库执行技术。首先参考图2A,在框202,确定线程库中的未处理的线程信息项是否保持被处理。如果是,则控制转到框204。否则,图2A-B中例示的技术结束。
在框204,当前线程信息项设置为线程库中的下一个未处理的线程信息项。在框206,当前堆栈踪迹设置为当前线程信息项中的堆栈踪迹。在框208,重置堆栈踪迹元素索引。例如,能通过将索引设置为-1来重置索引。在框210,当前堆栈踪迹元素设置为当前堆栈踪迹的底部的堆栈踪迹元素。
在框212,堆栈踪迹元素索引增加。在框214,通过与密钥匹配,即,得到与当前堆栈踪迹元素的密钥具有相同密钥的堆栈帧信息项,当前堆栈帧信息项设置为对应于当前堆栈踪迹元素的堆栈帧信息项(在堆栈帧信息映射中或根据需要创建)。例如,密钥能由源代码语句、行号、目标代码地址或这些的组合组成。
在框216,确定当前堆栈踪迹元素是否在当前堆栈踪迹的底部。例如,如果堆栈踪迹元素索引等于0,则这能指示当前堆栈踪迹元素在当前堆栈踪迹的底部。如果当前堆栈踪迹元素在当前堆栈踪迹的底部,则控制转到框218。否则,控制转到框220。
在框218,当前堆栈帧信息项标记为堆栈帧信息映射中的底部帧。这可通过将诸如“FRAME_FLOOR”的恒定堆栈帧信息项添加到当前堆栈帧信息项的在先列表属性实现。当前堆栈帧信息项也能被添加到“FRAME_FLOOR”的后续列表属性。控制转到图2B的框224。
在框220,确定当前堆栈踪迹元素是否处于当前堆栈踪迹的顶部。例如,如果堆栈踪迹元素索引等于比当前堆栈踪迹的大小小1,则这能指示当前堆栈踪迹元素处于当前堆栈踪迹的顶部。如果当前堆栈踪迹元素处于当前堆栈踪迹的顶部,则控制转到框222。否则,控制转到图2B的框224。
在框222,当前堆栈帧信息项标记为堆栈帧信息映射的顶部帧。这可通过将诸如“FRAME_CEILING”的恒定堆栈帧信息项添加到当前堆栈帧信息项的后续列表属性实现。当前堆栈帧信息项也能被添加到“FRAME_CEILING”的在先列表属性。控制转到图2B的框224。
现在参考图2B,在框224,当前堆栈帧信息项的发生属性的数量增加。当前堆栈帧信息项的发生属性的总数也能增加。在框226,之前的堆栈帧信息项(如果它不为空)添加到当前堆栈帧信息项的在先列表属性。在框228,确定任何堆栈踪迹元素是否存在于当前堆栈踪迹中的当前堆栈踪迹元素之上。如果是,则控制转到框230。否则,控制转到框236。
在框230,下一个堆栈踪迹元素设置为紧挨在当前堆栈踪迹元素之上存在的堆栈踪迹元素。在框232,下一个堆栈帧信息项设置为具有与下一个堆栈踪迹元素的密钥相同密钥的堆栈帧信息项(在堆栈帧信息映射中)。例如,密钥能由源代码语句、行号或对应于堆栈帧的目标代码地址组成。在框234,下一个堆栈帧信息项添加到当前堆栈帧信息项的后续列表属性。控制转到框236。
在框236,之前的堆栈帧信息项设置为当前堆栈帧信息项。在框238,确定任何堆栈踪迹是否存在于当前堆栈踪迹中的当前堆栈踪迹元素之上。如果是,则控制转到框240。否则,控制转回图2A的框202。
在框240,当前堆栈踪迹元素设置为紧挨在当前堆栈踪迹中的当前堆栈踪迹元素之上存在的堆栈踪迹元素。控制转回图2A的框212。
分类线程和它们的堆栈段
图3A-J示出根据本发明的实施方式的例示用于分类线程和这些线程的堆栈段的技术示例的流程图。能相对于以上参考图1A-B参考的当前采样时间的指定线程库执行技术。技术能产生代表线程分类信息项的集合的线程类的集合。首先参考图3A,在框3002,创建线程分类信息项的空集,具有线程库中的每个线程能由集合中的(可能不同的)线程分类项表示的性质,使得线程库中的等价线程由同一线程分类项表示。能创建遵守这些性质的新线程分类项并且通过下面描述的操作将其添加到集合。在框3004,确定线程库中的未处理的线程信息项是否保持被处理。如果是,则控制转到框3006。否则,控制转到框3182。
在框3006,当前线程信息项设置为线程库中的下一个未处理的线程信息项。在框3008,线程名称设置为当前线程信息项的名称。在框3010,指示在之前的线程库(即,对于之前的采样时间)中是否发现当前线程信息项的锯齿的标志设置为假。在框3012,确定线程抗锯齿信息映射中的未处理的线程抗锯齿信息项是否保持被处理,如果是,则控制转到框3014。否则,控制转到图3B的框3024。
在框3014,当前线程抗锯齿信息项设置为线程抗锯齿信息映射中的下一个未处理的线程抗锯齿信息项。在框3016,确定线程名称(在框3008中参考)是否与当前线程抗锯齿信息项的名称相同。如果是,则控制转到框3018。否则,控制转回框3012。
在框3018,当前线程抗锯齿信息项的块属性的数量增加。在框3020,当前线程抗锯齿信息项的指示在当前线程库(即,对于当前采样时间)中是否发现该项的锯齿的标志属性设置为真。在框3022,在框3010中参考的指示在之前的线程库是否发现当前线程信息项的锯齿的标志设置为真。控制转到框3024。
现在参考图3B,在框3024,确定在框3010和3022中参考的标志是否等于真。如果是,则控制转回图3A的框3004。否则,控制转到框3026。
在框3026,创建对应于当前线程信息项的新线程抗锯齿信息项。在框3028,新线程抗锯齿信息项的指示在当前线程库(即,对于当前采样时间)中是否发现对于该项的锯齿的标志属性设置为真。在框3030,新线程抗锯齿信息项的名称设置为线程名称(在框3008中参考)。在框3032,新线程抗锯齿信息项添加到线程抗锯齿信息映射。在框3034,创建新细粒度段列表以跟踪当前线程信息项的新细粒度段。在框3036,当前堆栈踪迹设置为当前线程信息项的堆栈踪迹。在框3038,重置堆栈踪迹元素索引。例如,能通过将堆栈踪迹元素索引的值设置为-1来重置索引的值。在框3040,当前堆栈踪迹元素设置为当前堆栈踪迹底部的堆栈踪迹元素。
在框3042,堆栈踪迹元素索引增加。在框3044,当前堆栈帧信息项设置为具有与当前堆栈踪迹元素的密钥相同密钥的堆栈帧信息项(在堆栈帧信息映射中)。例如,密钥能由源代码语句、行号或对应于堆栈帧的目标代码地址组成。
在框3046,确定当前堆栈踪迹元素是否处于当前堆栈踪迹底部。例如,如果堆栈踪迹元素索引等于0,则这能指示当前堆栈踪迹元素处于当前堆栈踪迹底部。如果当前堆栈踪迹元素处于当前堆栈踪迹底部,则控制转到图3C的框3048。否则,控制转到图3D的框3066。
现在参考图3C,在框3048,确定当前堆栈帧信息项是否已被分类。例如,能通过确定当前堆栈帧信息项的合并段属性是否等于空进行此确定。如果此属性等于空,则当前堆栈帧信息项未被分类。如果当前堆栈帧信息未被分类,则控制转到框3050。否则,控制转到框3062。
在框3050,创建新堆栈段信息项并且分配给当前堆栈段信息项的值。在框3052,当前堆栈帧信息项的合并段属性(在框3048中参考)的值设置为当前堆栈段信息项。在框3054,当前堆栈帧信息项添加到当前堆栈段信息项的元素列表属性。在框3056,生成新季节趋势信息项。在框3058,当前堆栈段信息项的趋势属性的值设置为新季节趋势信息项。在框3060,当前堆栈段信息项添加到细粒度段列表(在框3034中参考)。控制转到框3064。
在框3062,当前堆栈段信息项设置为当前堆栈帧信息项的合并段属性(在框3048中参考)的值。控制转到框3064。
在框3064,当前堆栈段信息项标记为当前堆栈踪迹中的底部段。这可通过将诸如“SEGMENT_FLOOR”的恒定堆栈段信息项添加到当前堆栈段信息项的在先列表属性来实现。当前堆栈段信息项能添加到“SEGMENT_FLOOR”的后续列表属性。控制转到图3J的框3162。
现在参照图3D,在框3066,在先堆栈踪迹元素设置为具有比当前堆栈踪迹元素索引的值小1的索引的堆栈踪迹元素(在当前堆栈踪迹中)。在框3068,在先堆栈帧信息项设置为具有与在先堆栈踪迹元素的密钥相同密钥的堆栈帧信息项(在堆栈帧信息映射中)。例如,密钥能由源代码语句、行号或对应于堆栈帧的目标代码地址组成。在框3070,在先堆栈段信息项设置为在先堆栈帧信息项的合并段属性的值。
在框3072,确定当前堆栈帧信息项是否已被分类。例如,能通过确定当前堆栈帧信息项的合并段属性是否等于空进行此确定。如果此属性等于空,则当前堆栈帧信息项未被分类。如果当前堆栈帧信息项未被分类,则控制转到框3074。否则,控制转到图3G上的框3120。
在框3074,确定在先堆栈帧信息项是否是在先堆栈段信息项的元素列表属性中的最后的堆栈帧信息项。如果是,则控制转到框3076。否则,控制转到图3F的框3098。
在框3076,确定在先堆栈帧信息项的后续列表属性是否具有作为当前堆栈帧信息项的仅一个条目。如果是,则控制转到框3078。否则,控制转到框3082。
在框3078,确定当前堆栈帧信息项的在先列表属性是否具有作为在先堆栈帧信息项的仅一个条目。如果是,则控制转到图3E的框3080。否则,控制转到框3082。
现在参考图3E,在框3080,当前堆栈帧信息项的合并段属性的值设置为在先堆栈段信息项。在框3081,当前堆栈帧信息项添加到在先堆栈段信息项的元素列表属性。控制转到图3J的框3162。
在框3082,创建新堆栈段信息项并且分配给当前堆栈段信息项的值。在框3084,当前堆栈帧信息项的合并段属性(在框3048中参考)的值设置为当前堆栈段信息项。在框3086,当前堆栈帧信息项添加到当前堆栈段信息项的元素列表属性。在框3088,在先堆栈段信息项添加到当前堆栈段信息项的在先列表属性。在框3090,当前堆栈段信息项添加到在先堆栈段信息项的后续列表属性。在框3092,生成新季节趋势信息项。在框3094,当前堆栈段信息项的趋势属性的值设置为新季节趋势信息项。在框3096,当前堆栈段信息项添加到细粒度段列表(在框3034中参考)。控制转到图3J的框3162。
现在参考3F,在框3098,在先堆栈段信息项的踪迹段划分为在在先堆栈帧信息项与后续堆栈帧信息项的索引之间出现的分离的第一和第二新堆栈段信息项,使得在先堆栈帧信息项处于第一新堆栈段信息项的端部。下面参考图5A-C公开划分堆栈段以在指定堆栈之前或之后添加分支点的技术。在此场景中,能调用该堆栈段划分技术以在指定堆栈段信息项之后(而非之前)执行划分,指定堆栈段信息项在此场景中是在先堆栈段信息项。
在框3100,在先堆栈信息项设置为通过框3098的划分产生的第一新堆栈段信息项。在框3102,创建新堆栈段信息项并且分配给当前堆栈段信息项的值。在框3104,当前堆栈帧信息项的合并段属性(在框3048中参考)的值设置为当前堆栈段信息项。在框3106,当前堆栈帧信息项添加到当前堆栈段信息项的元素列表属性。在框3108,在先堆栈段信息项添加到当前堆栈段信息项的在先列表属性。在框3110,当前堆栈段信息项添加到在先堆栈段信息项的后续列表属性。在框3112,生成新季节趋势信息项。在框3114,当前堆栈段信息项的趋势属性的值设置为新季节趋势信息项。在框3116,用在先堆栈段信息项的值代替细粒度段列表(在框3034中参考)中的最后已有条目的值。在框3118,当前堆栈段信息项添加到细粒度段列表。控制转到图3J的框3162。
现在参考图3G,在框3120,当前堆栈段信息项设置为当前堆栈帧信息项的合并段属性的值。在框3122,确定当前堆栈段信息项是否等于后续堆栈段信息项。如果是,则控制转到框3124。否则,控制转到图3I的框3142。
在框3124,确定当前堆栈帧信息项的在先列表属性是否具有多于一个条目。如果是,则控制转到框3128。否则,控制转到框3126。
在框3126,确定在先堆栈帧信息项的后续列表属性是否具有多于一个条目。如果是,则控制转到框3128。否则,控制转到图3J的3162。
在框3128,确定当前堆栈段信息项的元素列表属性中的第一个条目是否与当前堆栈帧信息项相同。如果是,则控制转到框3130。否则,控制转到图3H的框3132。
在框3130,更新代表细粒度段列表中的在先堆栈段信息项和当前堆栈段信息项的递归段。在实施方式中,此更新能涉及如果细粒度段列表中的最后的段是递归段则增加最后的段的递归属性的数量的值,或者如果最后的段是堆栈段则向细粒度段列表的末端添加新递归段。下面图6A-E的讨论中将看到关于这些变量的进一步信息。控制转到图3J的框3162。
现在参考图3H,在框3132,当前堆栈段信息项的踪迹段划分为在先堆栈段信息项与当前堆栈段信息项的索引之间出现的分离的第一和第二新堆栈段信息项,使得在先堆栈帧信息项处于第一新堆栈段信息项的结尾,并且使得当前堆栈帧信息项处于第二新堆栈段信息项的开始。下面参考图5A-C公开用于在指定堆栈帧之前或之后的分支点划分堆栈段的技术。在此场景中,能调用该堆栈段划分技术以在指定的堆栈段信息项(在此场景中是当前堆栈段信息项)之前(而非之后)执行划分。
在框3134,在先堆栈段信息项设置为通过框3132的划分产生的第一新堆栈段信息项,在框3136,当前堆栈段信息项设置为通过框3132的划分产生的第二新堆栈段信息项,在框3138,用在先堆栈段信息项的值代替细粒度段列表(在框3034中参考)中的最后已有条目的值。在框3140,当前堆栈段信息项添加到细粒度段列表。控制转到图3J的框3162。
现在参考图3I,在框3142,确定在先堆栈段信息项的元素列表属性的最后条目是否与在先堆栈帧信息项相同。如果是,则控制转到框3150,否则,控制转到框3144,
在框3144,在先堆栈段信息项的踪迹段划分为在先堆栈帧信息项与后续堆栈帧信息项的索引之间出现的分离的第一和第二新堆栈段信息项,使得在先堆栈帧信息项处于第一新堆栈段信息项的结尾。下面参考图5A-C公开用于在指定堆栈帧之前或之后的分支点划分堆栈段的技术。在此场景中,该堆栈段划分技术能被调用,以在指定堆栈段信息项(在此场景中是在先堆栈段信息项)之后(而非之前)执行划分。
在框3146,在先堆栈段信息项设置为通过框3144的划分产生的第一新堆栈段信息项。在框3148,用在先堆栈段信息项的值代替细粒度段列表(在框3034中参考)中的最后已有条目的值。控制转到框3150。
在框3150,确定当前堆栈段信息项的元素列表属性的最后条目是否与当前堆栈帧信息项相同。如果是,则控制转到框3156,否则,控制转到框3152。
在框3152,当前堆栈段信息项的踪迹段划分为出现在在先堆栈帧信息项与当前堆栈帧信息项的索引之间的分离的第一和第二新堆栈段信息项,使得当前堆栈帧信息项处于第二新堆栈段信息项的开始。下面参考图5A-C公开在指定堆栈帧之前或之后的分支点划分堆栈段的技术。在此场景中,能调用该堆栈段划分技术以在指定堆栈段信息项(在此场景中是当前堆栈段信息项)之前(而非之后)执行划分。
在框3154,当前堆栈段信息项设置为通过框3152的划分产生的第二新堆栈段信息项。控制转到框3156。
在框3156,当前堆栈段信息项添加到细粒度段列表(在框3034中参考),在框3158,在先堆栈段信息项添加到当前堆栈段信息项的在先列表属性。在框3160,当前堆栈段信息项添加到在先堆栈段信息项的后续列表元素。控制转到图3J的框3162。
现在参考图3J,在框3162,确定当前堆栈踪迹元素是否处于当前堆栈踪迹顶部。此确定可通过确定堆栈踪迹元素索引是否等于比当前堆栈踪迹大小小1进行。如果堆栈踪迹元素索引等于比当前堆栈踪迹大小小1,则当前堆栈踪迹元素处于当前堆栈踪迹的开始。如果当前堆栈踪迹元素处于当前堆栈踪迹的开始,则控制转到框3164。否则,控制转到框3166。
在框3164,当前堆栈段信息项标记为当前堆栈踪迹中的顶部段。这可通过将诸如“SEGMENT_CEILING”的恒定堆栈段信息项添加到当前堆栈段信息项的后续列表属性来实现。当前堆栈段信息项能添加到“SEGMENT_CEILING”的在先列表属性。控制转到框3166。
在框3166,确定任何堆栈踪迹元素是否存在当前堆栈踪迹中的当前堆栈踪迹元素之上。如果是,则控制转到框3168。否则,控制转到框3170。
在框3168,当前堆栈踪迹元素设置为紧接在当前堆栈踪迹中的当前堆栈踪迹元素之上存在的堆栈踪迹元素。控制转回图3B的框3042。
在框3170,合并当前线程信息项的细粒度段。下面参考图6A-E公开用于给出指定细粒度段列表的合并细粒度段的技术。参考图6A-E公开的技术产生合并段的集合。在框3172,存储针对当前线程信息项的如此产生的合并段的集合。
在框3174,针对当前堆栈踪迹和合并段的集合(在框3172中存储)登记线程分类信息项(在框3002中参考)。下面参考图7A-B公开用于针对指定堆栈踪迹和合并段的指定集合登记线程分类项的技术。参考图7A-B公开的技术产生线程分类信息项。在框3176,存储如此产生的针对当前堆栈踪迹和合并段的集合(在框3172中存储)的线程分类信息项。
在框3178,更新线程分类信息项(在框3176中存储)的线程分类统计。下面参考图8公开用于更新指定线程分类信息项的线程分类统计的技术。
在框3180,线程分类信息项添加到线程分类信息项(在框3002中参考)的集合。控制转回图3A的框3004。
再次参考图3A,在框3182,产生了线程分类项的集合之后,图3A-J中例示的技术结束。
应用季节趋势过滤器
图4是根据本发明的实施方式的例示用于应用季节趋势过滤器的技术示例的流程图。在框402,确定堆栈段信息映射中的未处理的堆栈段信息项是否保持被处理。如果是,则控制转到框404。否则,图4中例示的技术结束。
在框404,当前堆栈段信息项设置为堆栈段信息映射中的下一个未处理的堆栈段信息项。在框406,Holt-Winter三重指数过滤器应用于作为当前堆栈段信息项的趋势属性的值的季节趋势信息项。在框408,计算第N-步骤(其中N是1,2,...)预报。在框410,计算预报的标准化残留。在框412,确定正常残留是否超过指定截取。如果是,则控制转到框414。否则,控制转到框422。
在框414,确定测量的线程或堆栈段强度是否超过预报大于指定余量的余量。如果是,则控制转到框416。否则,控制转到框418。
在框416,发行关于过紧状态的警告。控制转到框422。
在框418,确定测量的线程或堆栈段强度是否低于预报大于指定余量的余量。如果是,则控制转到框420。否则,控制转到框422。
在框420,发行关于过松状态的警告。控制转到框422。
在框422,计算去季节化的趋势。在框424,针对季节索引调整趋势。在框426,计算预测的时间范围的置信度。在框428,确定预测的时间范围的置信度是否超过指定阈值。如果是,则控制转到框430。否则,控制转回框402。
在框430,发行关于范围中的饱和或端点状态的警告。控制转回框402。
在堆栈帧之前或之后的分支点划分堆栈段
图5A-C示出根据本发明的实施方式的例示用于在堆栈帧之前或之后在分支点处分开堆栈段的技术示例的流程图。能相对于指定堆栈段信息项和对应的指定堆栈帧信息项执行技术。该技术能利用指令调用,以在指定堆栈帧信息项代表的堆栈帧之前或之后执行划分。该技术能产生划分导致的一对(第一和第二)新堆栈段信息项。首先参考图5A,在框502,当前元素列表设置为指定堆栈段信息项的元素列表属性的值。在框504,堆栈帧信息索引设置为当前元素列表内的指定堆栈帧信息项的索引。在框506,确定划分是否被引导在指定堆栈帧之前执行。如果是,则控制转到框508。否则,控制转到框512。
在框508,第一段设置为从当前元素列表的开始跨越到具有比堆栈帧信息索引小1的索引的元素的当前元素列表的子列表。在框510,第二段设置为从具有堆栈帧信息索引的元素跨越到当前元素列表的结尾的当前元素列表的子列表。控制转到框516。
在框512,第一段设置为从当前元素列表跨越到具有堆栈帧信息索引的元素的当前元素列表的子列表。在框514,第二段设置为从具有比堆栈帧信息索引多1的索引的元素跨越到当前元素列表的结尾的当前元素列表的子列表。控制转到框516。
在框516,创建新在先堆栈段信息项。在框518,新在先堆栈段信息项的元素列表属性设置为第一段。在框520,对于第一段中的各在先堆栈帧信息项,在先堆栈帧信息项的合并段属性设置为新在先堆栈段信息项。如果该合并段属性的值之前不等于划分的指定堆栈段信息项,则能产生异常。控制转到图5B的框522。
现在参考图5B,在框522,创建新后续堆栈段信息项。在框524,新后续堆栈段信息项的元素列表属性设置为第二段。在框526,对于第二段中的各后续堆栈帧信息项,后续堆栈帧信息项的合并段属性设置为新后续堆栈段信息项。如果合并段属性的值之前不等于被划分的指定堆栈段信息项,则能产生异常。
在框528,被划分的指定堆栈段信息项的在先列表属性的所有元素添加到在先堆栈段信息项的在先列表属性。在框530,后续堆栈段信息项添加到在先堆栈段信息项的后续列表属性。在框532,在先堆栈信息项添加到后续堆栈段信息项的在先列表属性。在框534,被划分的指定堆栈段信息项的后续列表属性的所有元素添加到后续堆栈段信息项的后续列表属性。
在框536,季节趋势信息项设置为划分的指定堆栈段信息项的季节趋势信息属性的克隆。在框538,在先堆栈段信息项的趋势属性设置为季节趋势信息项的克隆。在框540,后续堆栈段信息项的趋势属性设置为季节趋势信息项。控制转到图5C的框542。
现在参考图5C,在框542,在先堆栈段信息项的发生属性的数量设置为划分的指定堆栈段信息项的发生属性的数量的值。在先堆栈段信息项的发生属性的总数也能设置为划分的指定堆栈段信息项的发生属性的总数的值。在框544,后续堆栈段信息项的发生属性的数量的值设置为划分的指定堆栈段信息项的发生属性的数量的值。后续堆栈段信息项的发生属性的总数也能设置为划分的指定堆栈段信息项的发生属性的总数的值。
在框546,指定堆栈段信息项的第一段属性设置为在先堆栈段信息项。在框548,指定堆栈段信息项的第二段属性设置为后续堆栈段信息项。在框550,在先堆栈段信息项的合并段属性设置为指定堆栈段信息项。在框552,后续堆栈段信息项的合并段属性设置为指定堆栈段信息项。在框554,利用划分导致的产生为新第一和第二堆栈段信息项的先堆栈段信息项和后续堆栈信息项,技术结束。
合并线程的堆栈段
图6A-E示出根据本发明的实施方式的例示用于合并线程的堆栈段的技术示例的流程图。能相对于指定细粒度段列表执行技术。技术能产生合并段的集合。首先参考图6A,在框602,创建段信息项的空合并段列表。在框604,当前索引的值设置为比指定细粒度段列表的大小小1。在框606,最后的段设置为指定细粒度段列表中具有当前索引的段。在框608,当前索引的值减小。在框610,确定当前索引是否小于0。如果是,则控制转到框692。否则,控制转到框612。
在框612,后续段设置为指定细粒度段列表中具有当前索引的段。在框614,指示最后的段是否与后续段合并的标志设置为真。在框616,确定最后的段和后续段二者是否都是递归段。如果是,则比较后续递归段的分类属性是否与最后递归段的分类属性相同。递归段的分类属性在框634和670中参考。在实施方式中,通过确定最后的段和后续段二者是否是递归段信息类的实例实现此确定。如果两个段均是递归段,则比较后续递归段的分类属性与最后递归段的分类属性。如果两个属性值相同,则控制转到框618。否则,控制转到图6B的框620。
在框618,最后的段的递归属性的数量的值增加后续段的递归属性的数量的值。控制转到图6C的框646。
现在参考图6B,在框620,确定最后的段是否是递归段并且后续段是否是堆栈段。如果是,则比较最后递归段的分类属性与后续段的值。递归段的分类属性在图6B的框634和图6D的框670中参考。如果最后的段的分类属性的值与后续段的值相同,控制转到框622。否则,控制转到框624。
在框622,最后的段的递归属性的数量的值增加。控制转到图6C的框646。
在框624,确定在先段是否是递归段并且最后的段是否是堆栈段。如果是,则比较在先递归段的分类属性与最后的段的值。递归段的分类属性在图6B的框634和图6D的框670中参考。如果在先段的分类属性的值与最后的段的值相同,控制转到框626。否则,控制转到框630。
在框626,最后的段设置为在先段。在框628,最后的段的递归属性的数量的值增加。控制转到图6C的框646。
在框630,确定在先段是否等于最后的段。如果是,则控制转到框632。否则,控制转到图6C的框640。
在框632,创建新递归段信息项。在框634,新递归段信息项的分类属性设置为最后的段。在某些实施方式中,能检查此分类属性,作为确定两个相邻递归段是否代表分类属性指示的同一段的递归的部分,因此,相邻递归段能合并为一个递归段,如图6A的框616和图6B的框620、624中参考的。在框636,新递归段信息项的递归属性的数量的值设置为2。在框638,最后的段设置为新递归段信息项。控制转到图6C的框646。
现在参考图6C,在框640,确定最后的段和在先的段是否能合并。在实施方式中,如果所有以下值为真,最后的段和在先的段能合并:(1)各合并段属性的值相同,(2)各合并段属性的值非空,(3)在先段的合并段属性的第一段属性的值是在先段,(4)最后的段的合并段属性的第二段属性的值是最后的段。在特定实施方式中,如果两个相邻段通过图5C的框546、548、550、552从同一合并段划分,则它们能合并。换言之,以上条件(1)和(2)测试框552和554的效果,条件(3)测试框546的效果,条件(4)测试框548的效果。如果最后的段和在先段能合并,则控制转到框642。否则,控制转到框644。
在框642,最后的段设置为最后的段的合并段属性的值。控制转到框646。
在框644,指示最后的段是否与在先段合并的标志(在框614中参考)设置为假。控制转到框646。
在框646,确定指示最后的段是否与在先段合并的标志(在框614中参考)是否设置为真。如果是,则控制转到框648。否则,控制转到图6E的框688。
在框648,后续段设置为合并段列表中的最后段的后续(在框602中参考)。在框650,指示最后的段是否与后续段合并的标志设置为真。在框652,确定最后的段和后续段二者是否都是递归段。如果是,则比较后续递归段的分类属性是否与最后递归段的分类属性相同。在框634和670中参考递归段的分类属性。如果是,则控制转到框654。否则,控制转到图6D的框656。
在框654,最后的段的递归属性的数量的值增加后续段的递归属性的数量的值。控制转到图6E的框682。
现在参考图6D,在框656,确定最后的段是否是递归段并且后续段是否的堆栈段。如果是,则比较最后递归段的分类属性与后续段的值。递归段的分类属性在图6B的框634和图6D的框670中参考。如果最后的段的分类属性的值与后续段的值相同,控制转到框658。否则,控制转到框660。
在框658,最后的段的递归属性的数量的值增加。控制转到图6E的框682。
在框660,确定后续段是否是递归段并且最后的段是否是堆栈段。如果是,则比较后续递归段的分类属性与最后的段的值。递归段的分类属性在图6B的框634中和图6D的框670中参考。如果后续段的分类属性的值与最后的段的值相同,控制转到框662。否则,控制转到框666。
在框662,最后的段设置为后续段。在框664,最后的段的递归属性的数量的值增加。控制转到图6E的框682。
在框666,确定后续段是否等于最后的段。如果是,则控制转到框668。否则,控制转到图6E的框676。
在框668,创建新递归段信息项。在框670,新递归段信息项的分类属性设置为最后的段。在某些实施方式中,能检查此分类属性,作为确定两个相邻递归段是否代表分类属性指示的同一段的递归的部分,因此,相邻的递归段能合并为一个递归段,如图6A的框616和图6B的框620和624中参考的。在框672,新递归段信息项的递归属性的数量的值设置为2。在框674,最后的段设置为新递归段信息项。控制转到图6E的框682。
现在参考图6E,在框676,确定最后的段和后续段是否能合并。在实施方式中,如果以下全部为真,最后的段和后续段能合并:(1)各合并段属性的值相同,(2)各合并段属性的值非空,(3)最后的段的合并段属性的第一段属性是最后的段,(4)后续段的合并段属性的第二段属性的值是后续段。在某实施方式中,如果两个相邻段通过图5C的框546、548、550、552从同一合并段划分,则它们能合并。换言之,以上条件(1)和(2)测试框552和554的效果,条件(3)测试框546的效果,条件(4)测试框548的效果。如果最后的段和后续段能合并,则控制转到框678。否则,控制转到框680。
在框678,最后的段设置为最后的段的合并段属性的值。控制转到图6E的框682。
在框680,指示最后的段是否与后续段合并的标志(在框650中参考)设置为假。控制转到框682。
在框682,确定指示最后的段是否与后续段合并的标志(在框650中参考)是否为真。如果是,则控制转到框684。否则,控制转到框690。
在框684,从合并段列表(在框602中参考)移除后续段。在框686,后续段设置为合并段列表中的最后的段的后续。控制转到框690。
在框688,最后的段增加到合并段列表(在框602中参考)的开始。控制转到框690。
在框690,减少当前索引的值。控制转回图6A的框610。
再次参考图6A,在框692,最后的段添加到合并段列表(在框602中参考)的底部。在框694,以合并段列表的形式产生了合并段的集合之后,技术结束。
登记堆栈踪迹的线程分类签名和线程的合并段
图7A-B示出根据本发明的实施方式的例示用于登记指定堆栈踪迹的线程分类项和合并段的指定集合的技术示例的流程图。技术能相对于指定的堆栈踪迹和合并段的指定集合执行。技术能产生线程分类信息项。首先参考图7A,在框702,堆栈帧的数量设置为指定的堆栈踪迹的大小。在框704,合并段的数量设置为合并段的指定集合的大小。在框706,指示线程分类信息项是否已被登记为代表对应于指定的堆栈踪迹的线程的标志设置为假。在框708,确定任何未处理的登记的线程分类信息项是否保留在线程分类信息映射中。如果是,则控制转到框710。否则,控制转到图7B中的框720。
在框710,当前登记的线程分类信息项设置为线程分类信息映射中的下一个未处理的登记线程分类信息项。在框712,确定(1)堆栈帧的数量是否等于当前登记的线程分类信息项的堆栈帧属性的数量以及(2)合并段的数量是否等于当前登记的线程分类信息项的合并段属性的数量二者。如果是,则控制转到框714。否则,控制转到图7B中的框720。
在框714,确定对于各索引值,具有该索引值的合并段的段是否等于当前登记的线程分类信息项中具有该索引值的段属性。如果是,则控制转到框716。否则,控制转回框708。
在框716,线程分类信息项设置为当前登记的线程分类信息项。在框718,指示线程分类信息项是否已被登记为代表对应于指定的堆栈踪迹的线程的标志(在框706中参考)设置为真。控制转到框720。
现在参考图7B,在框720,确定指示线程分类信息项是否已被登记为代表对应于指定的堆栈踪迹的线程的标志(在框706中参考)是否为真。如果是,则控制转到框734。否则,控制转到框722。
在框722,创建新线程分类信息项。在框724,新线程分类信息项的段属性设置为合并段的指定集合。在框726,新线程分类信息项的趋势属性设置为新季节趋势信息项。在框728,新线程分类信息项的堆栈帧属性的数量设置为堆栈帧的数量。在框730,新线程分类信息项的合并段属性的数量设置为合并段的数量。在框732,新线程分类信息项添加到线程分类信息映射。此添加登记新线程分类信息项以代表对应于指定的堆栈踪迹的线程代表的线程的等价类的签名。控制转到框734。
在框734,产生线程分类信息项之后,技术结束。
更新堆栈分类统计
图8是根据本发明的实施方式的例示用于更新指定线程分类信息项的线程分类统计学的技术示例的流程图。技术能相对于指定的线程分类信息项执行。在框802,指定的线程分类信息项的出现属性的数量的值增加。指定的线程分类信息项的出现属性的总数量的值也能增加。在框804,确定在指定的线程分类信息项中是否保持有任何未处理的段信息项。如果是,则控制转到框806。否则,技术结束。
在框806,当前段信息项设置为指定的线程分类信息项中的下一个未处理的段信息项。在框808,更新当前段信息项的堆栈段统计。
下面参照图9公开了更新指定的段信息项的堆栈段统计。控制转到框804。
更新堆栈段统计
图9是例示根据本发明的实施方式的用于更新指定段信息项的堆栈段统计学的技术示例的流程图。技术能相对于指定的段信息项执行。在框902,指定的段信息项的出现属性的数量的值增加。指定的段信息项的出现数量的总数的值也能增加。在框904,确定在指定的段信息项中是否保存有任何未处理的段信息项。如果是,则控制转到框906。否则,技术结束。
在框906,当前段信息项设置为指定的段信息项中的下一个未处理的段信息项。在框908,使用图9的此技术更新当前段信息项的堆栈段统计。控制返回框904。
基于JAVA堆大小、线程强度和堆栈段强度测量的季节趋势和预报
JAVA平台服务的云控制系统能监控JAVA堆分配的时间序列数据,以估计趋势并且预报内存能力要求。通过检测季节趋势并且预报内存能力要求,系统能在JVM之间动态地重新分配共享系统内存,使能资源分配的弹性。能力要求的预报涉及估计JAVA堆发展速率。Java堆分配通过以不规则时间间隔运行的全垃圾收集周期测量。JAVA堆发展速率的估计涉及通过由于间歇任意接近0的不规则时间间隔复杂化的随机时间间隔的除法。发展速率测量中的噪声是产生柯西分布的两个高斯分布的比率,其可能难于过滤。在大数量的数据点不产生比单个数据点的平均标准偏差的更精确估计的意义上,柯西分布的平均标准偏差未定义。增加样本池能增加遭遇的具有对应于通过时间接近间隔的除法的大绝对值的样本点的概率。不同于采样间隔由于全垃圾收集周期的不规则性而不规则的JAVA堆大小测量,线程或堆栈段强度测量能以规则间隔采样以避免时间接近间隔。即使如此,这里描述的用于JAVA堆分配的相同技术能应用于线程和堆栈段强度测量的季节趋势和预报。技术能由于将附加可变性添加到采样线程的延迟的线程调度和全GC周期的干扰的CPU调度调整变量延迟。技术还能由于分类堆栈段所需的可变计算时间而调整变量采样间隔。
1957和1960年发布的Holt-Winter三重指数过滤器能用于季节趋势和预报。这里通过引用并入C.C.Holt的"Forecasting Trends and Seasonal by Exponentially Weighted Averages,"Office of Naval Research Memorandum,no.52(1957)。这里通过引用并入P.R.Winters的"Forecasting Sales by Exponentially Weighted Moving Averages"Management Science,vol.6,no.3,p.324-342(1960)。Wright在1986年将HoIt-Winter公式扩展以支持不规则时间间隔。这里通过引用并入D.J.Wright的"Forecasting data published at irregular time intervals using an extension of Holt's method,"Management Science,vol.32,no.4,pp.499-510(1986)。在2008年,Hanzak提出了时间接近间隔的调整因子。这里通过引用并入T.Hanzak的"Improved Holt Method for Irregular Time Series,"WDS'08 Proceedings Part I,pp.62-67(2008)。
如果时间间隔在内存泄漏或死锁造成的拥塞期间单调减小,则意图补偿由于速率估计中的随机时间接近间隔的更高相对噪声强度的时间接近间隔的调整因子能无意地妨碍改变速率估计。关于全垃圾收集算法的堆的总大小的多项式时间复杂度能导致随拥塞恶化而减小JVM运行时间隔。在JAVA内存泄漏的情况下,随着时间间隔减小,运行时间能减小,但测量时间能增加,因为JVM能被冷冻更长以用于全垃圾收集。如果JVM在全垃圾收集期间冷冻,则新请求能在JVM外部排队,某部分重新分配给其它JVM。储备能加速后续运行时间期间堆使用的改变速率。在实施方式中,Hanzak的时间接近间隔的调整用于JAVA堆分配的趋势和预报并且跟踪加速堆发展速率。
在实施方式中,指数移动平均能应用,以从全垃圾收集周期平滑时间序列数据,以估计发展速率、发展速率的加速度、季节趋势、预报的误差残留、和预报的绝对偏差,从而使能JAVA内存堆分配的离群值检测和预报。本发明的实施方式能跟踪由于拥塞的发展速率的加速。这里公开的是新调整因子,当测量时间增加时向更近期的样本点给出更多权重。如果测量时间是可忽略的常量并且时间间隔主要包括运行时间,这些调整因子能还原至Hanzak的调整因子。本发明的实施方式能包括数字稳定性的时间的自适应缩放,即,避免双精度浮点表示的下溢。时间间隔能按比例自适应缩放,使得平均时间间隔缩放接近至1。实施方式能被在不同时标运行的三个或更多个独立过滤器并行跟踪。根据时标,这些并行过滤器能用作预测季节趋势、长期能力要求、短期端点(用光内存错误)等的多个策略。本发明的实施方式利用季节索引的改进公式,以从邻近索引之中选择最小化标准化误差残留的季节索引。本发明的实施方式能应用监督控制环,以通过各JVM实例(捕获租客、应用、用户等的操作特性)的非线性递归拟合模型用于估计各种过滤器参数和季节因子。本发明的实施方式能推动来自监督控制器的过滤器参数和季节因子,以更新嵌入各JVM中的过滤器(使用具有热点的Mbean或Jrockit仪器)。
在本发明的实施方式中,除了Holt-Winter三重指数过滤器,第四和第五指数过滤器用于趋向预报误差残留的平均和偏差,以计算标准化误差残留。预报误差残留的平均能解释为过滤器中的识别的模型的偏差。这种偏差能指示存在水平尖峰、暂时水平移位、永久水平移位或水平漂移。预报误差残留的偏差能指示时间序列数据中的方差变化。在实施方式中,方差变化的量级能影响用于检测离群值的过滤器的公差。如果预报误差残留大于预报误差残留偏差的移动平均的百分比,则测量检测为离群值。概念上,离群值是过滤器中识别的趋势模型未说明的测量,因此离群值的集群能指示仅能被一些外来起因解释的异常。本发明的实施方式根据测量的方差变化自适应用于离群值检测的过滤器的公差。此技术通过当高方差变化在系统中持久时减少离群值警报数量降低警报疲劳。
在本发明的实施方式中,Holt-Witer三重指数过滤器能应用于JVM堆使用的季节趋势和预报,以有效率地实现JVM内存分配中的弹性。标准Holt-Winter三重指数过滤器能应用于从规则时间序列的需求预报,能特别调整用于为具有不规则时间接近间隔的随机时间间隔工作。本发明的实施方式能应用用于不规则时间间隔的Wright公式和用于时间接近间隔的Hanzak的调整,用于JAVA堆分配的趋势和预报。能执行适于JVM全垃圾收集中看到的随机时间间隔的过滤器的结构的非平凡选择。Holt-Winter-Wright-Hanzak过滤器的结构能从第一原理推导,以系统性设计自适应,从而匹配JVM全垃圾收集周期生成的时间序列。能执行对预测JVM内存使用趋势有用的过滤器的扩展的非平凡选择。通过最小化标准化误差残留(能用于对软件参考造成的不连续性作出反应),选择的扩展例如能包括扩展以过滤发展速率的加速(以便跟踪拥塞)、扩展以并行运行不同时标(因为不规则时间间隔具有与季节的某种相关)、以及扩展以选择季节索引(类似于模糊逻辑)。本发明的实施方式能补充和增强具有应用参数估计的非线性递归以调谐嵌入的过滤器的非平凡监督控制器和框架的嵌入系统。
这里描述的用于季节趋势、预报、异常检测和端点预测的技术能添加至现有监督控制框架,例如以上讨论的CARE控制框架。监督控制器的模型识别能提供用于检测离群值的基线。离群值的集群能指示系统中的异常。这些异常中的一些能代表系统故障和断供的主要指示符。当检测到关键异常或预测到处理端点时,系统能生成具有线程库和堆库的自动诊断库(ADR)事件报告,以帮助调试应用、配置和系统故障。系统还能向企业管理器(EM)云控制报告关键警报。
在实施方式中,应用指数移动平均的公式以平滑时间序列数据、本地线性趋势、季节趋势、预报的误差残留、预报的绝对偏差,用于诸如内存堆使用和线程或堆栈段强度的资源利用测量的监控和预报。在实施方式中,公式能基于1956年Brown提出的指数过滤器、1957年Holt提出的双重指数过滤器、1960年Winters提出的三重指数过滤器、1986Wright提出的用于不规则时间间隔的扩展、2008年Hanzak提出的用于时间接近间隔的调整因子、以及离群值检测和裁剪。这里通过引用包括以下公布:R.G.Brown,"Exponential Smoothing for Predicting Demand,"Cambridge,Arthur D.Little Inc.(1956),p.15;C.C.Holt,"Forecasting Trends and Seasonal by Exponentially Weighted Averages,"Office of Naval Research Memorandum,no.52,(5957);P.R.Winters,"Forecasting Sales by Exponentially Weighted Moving Averages,"Management Science,vol.6,no.3,p.324-342,(5960);D.J.Wright,"Forecasting data published at irregular time intervals using an extension of Holt's method,"Management Science,vol,32,no.4,pp.499-510(1986);T.Hanzak,"Improved Holt Method for Irregular Time Series,"WDS'08 Proceedings Part I,pp.62-67(2008);以及S.Maung,S.W.Butler和S.A.Henck,"Method and Apparatus for process Endpoint Prediction based on Actual Thickness Measurements,"United States Patent 5503707(1996)。
指数加权移动平均
时间序列数据能被数据点的标准化加权和平滑,其中根据时间序列(自递归移动平均模型中)、时间间隔的长度和其它因子的自动关联适当选择权重:
指数移动平均是数据点的加权和,其中权重是指数形式。此形式假设采样间隔是规则的:
以上表达式给出了规则时间间隔的数据序列的标准化指数加权和。参数α是标准化因子,作为n→∞:
此序列等同地表示为后继形式:
能通过递归地扩展等同于标准化指数加权和的后续形式示出:
对于不规则时间间隔的WRIGHT的扩展
Wright(以上引用的)扩展了用于不规则时间间隔的标准化指数加权和的公式:
用表示标准化因子,用表示加权和:
如果则表达式能由πl,l-m=blbl-1...bl-m+1表示。
如果时间间隔规则,b=bl=bl-1=...=bl-m+1这个表达式还原为:
πl,l-m=(1-α)(l-l+m)
=bm
能推导序列的后继形式:
替代和
能观察到
因此,
推导后继形式:
后续将使用的bn的表达式是:
类似地,推导序列的后继形式:
替代和
能观察到
因此能得到后继形式:
能推导的后继形式:
替代bn
因此得到后继形式
如果时间间隔固定于平均时间间隔q,则后继公式会聚到固定点:
序列的固定点是
u=1-(1-α)q
对于数值稳定性,即,为了避免当tk…tk-1大时双精度浮点表示的下溢,时间间隔能按比例缩放,使得平均时间间隔q缩放至接近1。如果q缩放至精确为1,则得到u=α。
固定点u能用作初始值:
对于时间接近间隔的HANZAK的调整因子
能将调整因子添加到权重以调谐过滤器的响应:
扩展序列
如果且则
能推导后续形式:
Hanzak(以上引用的)增加下面给出的满足等式和的调整因子
当序列包括时间接近样本(时间间隔比平均时间时间小得多的样本)时,此调整因子改进了过滤器的鲁棒性。如果对应的采样间隔ti-ti-1大于当前采样间隔tn-tn-1,因子增加过去的样本点的相对权重。这补偿了由于速率估计中的随机时间接近间隔的除法造成的较高相对噪声强度。
后续将使用的bn的表达式是:
类似地,扩展序列:
得到后继形式:
推导的后继形式:
替代bn
因此得到后继形式:
注意,参数出现在的后继形式中,但不是的后继形式的部分。
使用平均时间间隔q缩放至接近1的初始值:
测量时间和运行时间间隔的调整因子
资源测量的一些类涉及非可忽略测量时间,其应该在过滤器中累计。例如,内存堆使用测量过程涉及未使用堆的全垃圾收集以测量实际使用。堆使用的测量时间随堆大小增加而增加。在一些过程中,运行时间不与测量时间重叠,这是当JVM中的应用在全垃圾收集期间冷冻时用于堆使用测量的情况。因此,时间间隔(tn-tn-1)应该分为非重叠运行时间(tn-t′n-1)和测量时间(t′n-1-tn-1),其中t′n>tn。这里,时间戳tn代表第n个全垃圾收集周期的起点,而t′n代表第n个全垃圾收集周期的结束:
tn-tn-1=(tn-t′n-1)+(t′n-1-tn-1)
当堆分配行为冷冻时,如果假设该过程排除测量时间间隔,即,分母是不包括测量时间的过程运行时间间隔,堆使用测量的改变速率可已如下定义:
因此运行时间的比能用在调整因子中:
使用速率过滤器中的调整因子(避免柯西分布)
Holt过滤器能被参数化的线性运算符表示,其中参数是测量序列,其是信号项和误差项的和:
如果误差项是高斯的,运算符的测量的估计是有效的:
在从原始发展估计发展速率的过程中,这涉及通过随机时间间隔tn-t′n-1的除法,误差项可以是柯西分布:
下面的推导示出了调整因子将误差项还原为高斯:
其中
ti-t′i-1的分母和的分子中的因子ti-t′i-1抵消,给出
的分母和的分子中的因子(tn-t′n-1)抵消,产生
如果过滤器参数β接近0。
因为这给出
这里项是总测量时间间隔。如果测量时间可忽略,公式会聚为极限,其中误差项ε是高斯的:
在一些情况下不规则时间间隔单独的Wright扩展可能不能足以检测周期模式。用于时间接近间隔的Hanzak的调整因子能用于将不规则时间间隔引发的噪声减少至高斯噪声级别。离群值的裁剪进一步改进了单(仅发展速率)或双(发展速率和加速度)过滤器的性能。
调整因子
如果内存泄漏或死锁造成的拥塞期间时间间隔单调减少,时间接近间隔的调整因子(其意图补偿由于速率估计中的随机时间接近间隔导致的更高相对噪声强度)能无意地妨碍改变速率估计。在内存泄漏的情况下,随着时间间隔减少,运行时间减少,但是测量时间增加,因为JAVA虚拟机(JVM)对于全垃圾收集(GC)冷冻更长。如果JVM在全GC期间冷冻,则新请求在JV外面排队(某部分重新分布到其它JVM)。储备能加速后续运行时间期间的堆使用的改变速率。
补偿此储备的一种方式是在调整因子中包括测量时间的比率
如果其测量时间(即,全GC时间)t′i-1-ti-1短于对应于当前采样点的测量时间t′n-1-tn-1,则此因子减少过去的采样点的相对权重。测量时间比率预期抵消运行时间比率并且提供对于趋势的较快响应。因此,当测量时间增加时,新调整因子能对更近期的采样点给出更多权重。如果测量时间是可忽略常量并且时间间隔大部分由运行时间组成,则这些调整因子还原为Hanzak的调整因子。
数学上,且因此过滤器能还原为期望的后继形式:
然后通过后继形式给出过滤器参数
如果测量时间单调减少,可使用下面的调整因子:
应用HOLT的方法
Holt的双重指数移动平均包括三个时间序列:平滑的资源测量本地线性趋势以及本地线性预报给定常量α,0<α<1和0<β<1:
Winters向Holt的双重指数移动平均增加第三指数移动平均,以并入季节趋势。季节周期L和常量0<α<1,0<β<1,0<γ<1的Holt-Winters三重指数移动平均是:
这里代表本地线性预报,而代表线性和季节预报的组合。对于能力监控,长期线性趋势能用于预报资源要求,例如内存、线程、连接、套接字、缓存、盘空间、网络带宽等。
平滑的测量
双重指数移动平均中的第一个能用于平滑原始资源测量。在这种情况下,给定常量α,0<α<1,Wright公式能用于过滤原始资源测量
因子的其它有用公式(取决于测量时间间隔增加还是减少):
本地线性趋势
双重指数移动平均中的第二个代表资源测量的本地线性改变速率。由于改变速率涉及时间间隔长度tn-t′n-1的除法,给定常量β,0<β<1,调整因子能被包括以过滤改变速率
序列代表基于线性趋势的本地线性预报资源测量:
计算和的初始值:
(t0-t-q)>15分钟。
当资源测量(堆使用或线程或堆栈段强度)可与阈值Xmax交叉时,此线性等式能用于预测tn之后的时间t。
资源测量的发展速率和加速度
双重指数移动平均能应用于资源测量的一阶导数和二阶导数,以监控加速资源拥塞(由于内存泄漏或线程死锁)。
资源测量的改变速率能在双重指数移动平均中的第一个中被过滤。此过滤能监控资源测量的长期逐渐发展。由于改变速率涉及通过时间间隔长度tn-t′n-1的除法,能包括调整因子以过滤改变速率:
二阶导数(改变速率的速率)还涉及通过时间间隔tn-tn-1的除法。
能包括Hanzak调整因子以过滤改变速率的速率:
序列代表基于改变速率的线性趋势的资源测量的预报改变速率:
通过给出预报的资源测量
当资源测量可能如下交叉阈值Xmax时,平滑的速率能用于预测tn之后的时间t:
离群值检测和裁剪
在双重和三重指数移动平均的顶部,能引入两个更多指数移动平均以过滤残差和绝对偏差的序列。基于趋势(在用于监控测量和速率的算法1中)或(在用于监控速率和加速度的算法2中)给定具有或不具有季节因子预报资源测量的一步骤线性:
预报的资源测量的残差能计算为:
显著地,对于各n,能使用Wright公式更新给定常量δ,0<δ<1的过滤器参数:
通过给出标准化残留。
如果对应的标准化残留大于截取值Q,即样本被识别为离群值。
在某些实施方式中,标准化残留截取值Q能与时间间隔按比例调整(如果间隔大于阈值α,α≥1,即给定默认截取值Qdef),如下计算标准化残留截取值Q:
用于调整标准化残留截取值的此公式随预报范围扩展,即,随tn-tn-1增加,有效地增加离群值测量的公差。这是预报测量的置信度如何随预报范围扩展而减小的表达式。
如果识别为离群值,则根据以下规则,样本能裁剪为值
若且且
则
若且
则不是离群值。
若且
则
若且且
则
若且
则不是离群值。
若且
则
这些条件总结为:
在这些表达式中,平滑的残差项代表过滤器的偏差。此偏差信息被中心预报补偿。
因此,标准化残留等同于中心预报的残留通过将中心预报移位给出裁剪的离群值测量
偏差代表水平变化。偏差的短持续时间尖峰或低谷代表永久水平移位。尖峰和低谷相继的偏差代表水平尖峰或暂时水平移位。持久负偏差代表向上水平漂移,持久正偏差代表向下水平漂移。持久大绝对偏差代表高方差变化。偏差、绝对偏差(代表1-sigma和2-sigma)和离群值能绘制为Shewhart控制图。在Shewhart控制图中清晰可见并且能被基于简单规则的分类方案检测的持久水平漂移、高方差变化和离群值集群通常代表系统中的异常。异常能被识别并且提升以被更高级分类和评估方案诊断。
季节趋势
当监控堆使用或线程或堆栈段强度时,能单独跟踪周末和工作日季节。这基于以下理论:当用户分布在不同时区中(诸如针对多国组织)时,季节尖峰仅出现在工作日,而一些趋势可涌进周末。周末季节的长度应该是48小时,工作日季节的长度应该是24小时。当更新周末中的移动平均时,能使用季节因子当使用工作日中的移动平均时,能使用季节因子如果使用15分钟的求解,即,季节索引是15分钟的整数倍数,以跟踪季节因子(48小时)和(24小时),则这对于季节因子分别产生T=192和T=96个索引。当时间从tn-1前进至tn时,季节索引应该前进15分钟的倍数,即,索引τn=[[(tn-t12AM)div15分钟]mod T],假设t以分钟给出。通常,季节索引是求解Δτ和周期T参数化的映射:
τn=τ(tn)=[[(tn-t12AM)divΔτ]mod T]
对于周末和工作日给出常量γ(0<γ<1)的季节因子的指数移动平均。在周末,通过以下过滤器跟踪季节因子,其中K(设置为192,如果Δτ是15分钟)是周末季节的周期性:
τn=τ(tn)=[[(tn-t12AM)divΔτ]mod K]
在工作日,通过下面的过滤器跟踪季节因子,其中L(设置为96,如果Δτ是15分钟)是工作日季节的周期性:
τn=τ(tn)=[[(tn-t12AM)divΔτ]mod L]
以上两个过滤器跟踪去季节化的平均之上或之下的原始样本的百分比偏差。季节因子应该在各工作日或周末季节的端部重新标准化,使得因子随一周周期的平均是1,即,将各周末因子和工作日因子除以标准化因子:
可选地,我们能将平滑曲线拟合至各季节端部的季节因子,以平滑季节趋势。
在各工作日或周末季节端部,我们能通过将各季节因子和除以平均每日测量来重新均衡周末和工作日季节因子的相对量级:
当原始值除以对应的季节因子或(之前季节和当前季节的踪迹)时,的更新处理有效地去季节化平均平均基于样本在周末还是工作日中通过两个过滤器之一更新。
周末季节因子的初始值通过首先计算各周末上的平均确定,对于k=0,1,...,K-1:
这里,样本是落入对应周末内的样本。
其次,计算对应于周末季节索引k的落入15分钟时间间隔内的样本的平均
这里,值是对应于周末e=(k div 192)的周末季节索引(k mod 192)的落入15分钟时间间隔内的样本的平均。
然后通过平均各行计算周末季节因子:
…
工作日季节因子的初始值确定如下,对于l=0,1,...,L-1:
首先,计算5个工作日(周一,周二,周三,周四,周五)的平均:
这里,样本是落入对应日内的样本。
第二,对于各季节索引将样本平均除以每日平均
这里,值是对应于日d=(l div 96)的工作日季节索引(l mod 96)的落入15分钟时间间隔内的样本的平均:
第三,通过平均各行计算工作日季节因子:
…
为了重新均衡周末和工作日季节因子的相对量级,我们将各季节因子和除以平均每日测量:
使用更新周末中的移动平均。
使用更新工作日中的移动平均。
在各情况下,本地线性预报是:
如果t0落入周末,的初始值为:
τ0=τ(t0)=[[(t0-t12AM)divΔτ]mod K]
如果t0落入工作日,则:
τ0=τ(t0)=[[(t0-t12AM)divΔτ]mod L]
根据t0落入周末还是工作日,从两个样本季节(即,两个连续工作日之间或两个连续周末之间)计算线性趋势的初始值。
如果t0落入周末:
如果t0落入工作日:
当投影由通过组合平滑的资源测量、本地线性趋势和多变量季节因子在tn之后的时间t的资源测量组成时,第二索引能通过[(t-tn)div 15分钟]投影,假设t以分钟给出。用Δ表示季节索引的投影,根据(τn+Δ)落入周末还是工作日,使用以下两个公式之一,得到时间t的线性和季节预报Ft。
如果τn和(τn+Δ)均落入周末,则:
如果τn和(τn+Δ)均落入连续工作日,则:
如果τn和(τn+Δ)均落入不同季节,可以使用稍微更复杂的模运算。
多变量递归
h步骤预报的均方误差(MSB)残留和平均绝对偏差(MAD)能定义为给定时间序列χt的独立变量α,β,κ,γ,δ和tz的函数。参数tz,-12<tz<12是与东海岸标准时间(EST)的时区偏移。在移位时区偏移之后,周末的起点应该对应于周六12AM,周末的结束应该对应于周一12AM。当多个时区上的工作日行为的尖峰和低谷叠加并且周末中部的水平需要位于周末季节中心时,能优化时区偏移。
能应用非线性多变量递归以确定α,β,κ,γ,δ和tz的值,这些值最小化跨9个连续日或更长的数据的MSE或MAD。
在所有表达式中,时间戳移位tz偏移并且按比例缩放。缩放因子确定为使得平均时间间隔q缩放至接近1。
能通过表示预期平均时间间隔:
简单扩展的HOLT-WINTER季节过滤器
对于性能监控,残差序列是
这里,根据tn落入周末还是工作日,h步骤预报基于平滑的测量线性趋势和季节因子或
为观察的测量的第一指数移动平均(如之前部分中推导的)设置的等式如下。
使用更新周末中的去季节化测量的移动平均。
使用更新工作日中的去季节化测量的移动平均。
注意时间tn在缩放之前移位tz偏移。如果tn在周六12AM与周一12AM之间则使用周末公式。
过滤器参数是:
如果t0落入周末,的初始值是:
τ0=τ(t0)=[(t0-t12AM)divΔτ]mod K
如果t0落入工作日:
τ0=τ(t0)=[(t0-t12AM)divΔτ]mod L
的初始值,其中q是平均时间间隔(缩放至1):
q≈1
为第二指数移动平均设置的用于本地线性趋势的等式:
的初始值:
的初始值,其中q是平均时间间隔(缩放至1):
q≈1
去季节化本地线性预报提供第一和第二指数移动平均之间的联系:
为周末和工作日季节因子的第三指数移动平均设置的等式如下。
在周末:
τn=τ(tn)=[(tn-t12AM)divΔτ]mod K
在工作日:
τn=τ(tn)=[(tn-t12AM)divΔτ]mod L
或者在各季节端部,或者在或的每次更新之后(前一方法更有效率,后者可能太过计算密集),将各周末因子和工作日因子除以标准化因子:
的初始值:
且Ne is是周末e的样本数量
且Nk是间隔k的样本数量
的初始值:
且Nd是日d的样本数量
且Nl是间隔l的样本数量
为了重新均衡周末和工作日季节因子的相对量级,我们将各季节因子和除以平均每日测量:
用于离群值检测的第四和第五指数移动平均的等式集合(注意是一步预报误差残留,设h=1):
和的初始值是0。
的初始值,其中q是平均时间间隔(缩放至1):
q≈1
当标准化残留大于Q时用于检测离群值的表达式:
离群值样本点的裁剪:
如果样本是离群值,则根据时间落入周末还是工作日应该使用裁剪值代替离群值来使用下式中的一个更新平均:
包括测量变化加速度的扩展的HOLT-WINTER季节过滤器
为了拥塞监控,诸如内存泄漏和死锁,能使用以下等式集合(如之前部分中推导的)。
残差序列是
通过下式给出h-步骤预报的测量
为了在h-步骤预报中包括季节趋势,根据tn落入周末还是工作日,去季节化的测量预报能乘以季节因子或
是去季节化的测量。使用下式更新周末中的去季节化的测量:
使用下式更新工作日中的去季节化的测量:
去季节化的测量过滤器参数是:
因子的其它有用公式(取决于测量时间间隔的增加还是减少):
如果t0落入周末,则的初始值为:
τ0=τ(t0)=[(t0-t12AM)divΔτ]mod K
如果t0落入周末:
τ0=τ(t0)=[(t0-t12AM)divΔτ]mod L
是间隔[tn-h,tn]内的平均去季节化的发展速率,通过下式给出:
原始测量是发展速率(一阶导数):
为测量的发展速率的第一指数移动平均设置的等式取决于季节趋势因子。没有季节趋势的原始表达是:
如果引入两个季节趋势(对于周末和工作日),则根据tn-1和tn落入哪个季节,能使用去季节化的测量。
通过给出去季节化的原始发展速率。
使用更新移动平均。
通过以下公式调整过滤器参数:
如果不采用季节趋势,平滑的发展速率的初始值是:
(t0-t-p)>15分钟
的初始值,其中q是平均时间间隔(缩放至1):
q≈1
为发展速率的加速度的第二指数移动平均设置的等式是:
如果不采用季节趋势,平滑的发展加速度的初始值是:
(t0-t-q)>29分钟
的初始值,其中q是平均时间间隔(缩放至1):
q≈1
基于变化速率的线性趋势的去季节化的预报的变化速率:
为周末和工作日季节因子的第三指数移动平均设置的等式如下。
更新周末中的季节乘法因子:
τn=τ(tn)=[(tn-t12AM)divΔτ]mod K
更新工作日中的季节乘法因子:
τn=τ(tn)=[(tn-t12AM)divΔτ]mod L
或者在各季节的端部,或者在更新或之后(前一方法更有效率,后者可能太过计算密集),将各周末因子和工作日因子除以标准化因子:
的初始值:
且Ne是周末e中的样本数量
且Nk是间隔k中的样本数量
的初始值:
且Nd是关于日d的样本数量
且Nl是间隔l中的样本数量
为了重新平衡周末和工作日季节因子的相对量级,我们将各季节因子和除以平均每日测量:
为离群值检测的指数移动平均设置的等式(注意是一步预报误差残留,设h=1):
和的初始值是0。
的初始值,其中q是平均时间间隔(缩放至1):
q≈1
当标准化残留大于Q时用于检测离群值的表达式:
离群值样本点的裁剪:
如果裁剪当前样本,则应该重新计算速率:
如果不采用季节趋势,则值应该用于更新平均:
如果采用季节趋势,则根据时间是落入周末还是工作日使用以下公式中的一个:
通过给出去季节化的原始发展速率。
使用更新移动平均。
硬件概述
图10是例示根据本发明的实施方式可使用的系统环境1000的组件的简化框图。如示出的,系统环境1000包括一个或多个客户端计算设备1002、1004、1006、1008,它们配置为操作包括本机客户端应用以及诸如网络浏览器等的可能的其它应用的客户端应用。在各种实施方式中,客户端计算设备1002、1004、1006、1008可与服务器1012交互。
客户端计算设备1002、1004、1006、1008可以是通用个人计算机(通过示例,包括运行Microsoft Windows和/或Apple Macintosh操作系统的个人计算机和/或膝上型计算机)、手机或PDA(运行诸如Windows Mobile并且联网、e-mail、SMS、Blackberry或使能其它通信协议的软件)、和/或运行各种商业可用UNIX或类UNIX操作系统(包括但不限于各种GNU/Linux操作系统)的工作站计算机。另选地,客户端计算设备1002、1004、1006、1008可以是任何其它电子设备,例如瘦客户端计算机、使能互联网的游戏系统和/或能够经由网络(例如,下面描述的网络1010)通信的个人消息设备。尽管示例性系统环境1000示出为具有4各客户端计算设备,但可支持任意数量的客户端计算设备。诸如具有传感器的设备等的其它设备可与服务器1012交互。
系统环境1000可包括网络1010。网络1010可以是本领域技术人员熟悉的能使用各种商业可用协议(包括但不限于TCP/IP、SNA、IPX、AppleTalk等)中的任意支持数据通信的任何类型的网络。仅通过示例,网络1010能是局域网(LAN),诸如以太网、令牌环网络等;广域网;虚拟网络,包括但不限于虚拟私人网(VPN);互联网;内联网;外联网;公共交换电话网(PSTN);红外网络;无线网络(例如,在IEEE 802.11协议组、现有技术中已知的蓝牙协议、和/或任何其它无线协议中的任意下操作的网络);和/或这些和/或其它网络的任意组合。
系统环境1000还包括一个或多个服务器计算机5012,可以是通用计算机,专用服务器计算机(通过示例,包括PC服务器,UNIX服务器,中间范围服务器,大型计算机,机架安装服务器等),服务器农场,服务器集群,或任何其他合适的配置和/或组合。在各种实施方式中,服务器1012可适于运行一个或多个服务或软件应用。
服务器1012可运行操作系统,包括以上讨论的那些任何操作系统,以及任何商业可用服务器操作系统。服务器1012也可运行各种附加服务器应用和/或中间层应用中的任意应用,包括HTTP服务器,FTP服务器,CGI服务器,JAVA服务器,数据库服务器等。示例性数据库服务器包括但不限于Oracle、Microsoft、Sybase、IBM等商业可用的那些。
系统环境1000也可包括一个或多个数据库1014、1016。数据库1014、1016可驻留于多个位置。通过示例,数据库1014、1016中的一个或多个可驻留于服务器1012本地的非瞬时性存储介质上(和/或驻留于其中)。另选地,数据库1014、1016可远离服务器1012,并且经由基于网络的或专用连接与服务器1012通信。在一组实施方式中,数据库1014、1016可驻留于本领域技术人员熟悉的存储区域网络(SAN)中。类似地,用于执行属于服务器1012的功能的任何必要文件可本地和/或远程存储在服务器1012上。在一组实施方式中,数据库1014、1016可包括关系数据库,例如Oracle提供的数据库,其适于响应于SQL格式的命令存储、更新和检索数据。
图11是根据本发明的实施方式可使用的计算机系统1100的简化框图。例如,服务器1012或客户端1002、1004、1006或1008可使用诸如系统1100的系统实现。计算机系统1100示出为包括可经由总线1124电连接的硬件元件。硬件元件可包括一个或多个中央处理单元(CPU)1102,一个或多个输入设备1104(例如,鼠标,键盘等),以及一个或多个输出设备1106(例如,显示设备,指针等)。计算机系统1100也可包括一个或多个存储设备1108。通过示例,存储设备1108可包括诸如盘驱动器的设备、光学存储设备和诸如随机存取存储器(RAM)和/或只读存储器(ROM)的固态存储设备,可以是可编程的、可闪速更新的等。
计算机系统1100可附加地包括计算机可读存储介质读取器1112、通信子系统1114(例如,调制解调器,网卡(无线或有线),红外通信设备等)、工作内存1118,工作内存1118可包括以上描述的RAM和ROM设备。在一些实施方式中,计算机系统1100也可包括处理加速单元1116,其能包括数字信号处理器(DSP)、专用处理器和/或等。
计算机可读存储介质读取器1112能进一步连接至计算机可读存储介质1110,(并且,选择性地,与存储设备1108结合)综合性地一起代表远程、本地、固定和/或可移除存储设备以及用于暂时和/或更持久包含计算机可读信息的存储介质。通信系统1114可允许与网络1010和/或以上相对于系统环境1000描述的任何其它计算机交换数据。
计算机系统1100也可包括示出为当前位于工作内存1118内的软件元件,包括操作系统1120和/或其他代码1122,例如应用程序(可以是客户端应用,网络浏览器,中间层应用,RDBMS等)。在示例性实施方式中,工作内存1118可包括用于以上描述的趋势预报的可执行代码和关联的数据结构。应该理解,计算机系统1110的另选实施方式可具有以上描述的大量变型。例如,也可使用定制硬件和/或可用硬件、软件(包括便携式软件,诸如applets)或二者实现特定元件。此外,也可采用与诸如网络输入/输出设备的其它计算设备的连接。
包含代码或代码部分的存储介质和计算机可读介质能包括现有技术中已知或使用的任何合适的介质,包括存储介质和通信介质,例如但不限于易失性和非易失性(非瞬时性)、可移除和不可移除介质,它们以用于存储和/或发送例如计算机可读指令、数据结构、程序模块或其他数据的信息的任何方法或技术实现,包括RAM、ROM、EEPROM、闪存或其他存储器技术、CD-ROM、数字多功能盘(DVD)或其他光学存储器、磁带、磁盘存储器或其他磁存储设备、数据信号、数据传输或能用于存储或传输期望信息并且能被计算机访问的任何其他介质。
尽管描述了本发明的特定实施方式,各种修改、替换、另选构造和等同物也包含在本发明的范围内。本发明的实施方式不限于某些特定数据处理环境内的操作,而是在多个数据处理环境内自由操作。另外,尽管使用特定序列的事务和步骤描述了本发明的实施方式,对于本领域技术人员明显的是,本发明的范围不限于描述的事务和步骤的序列。
另外,尽管已经使用硬件和软件的特定组合描述了本发明的实施方式,应该意识到,硬件和软件的其它组合也在本发明的范围内。本发明的实施方式可仅用硬件执行,仅用软件执行,或使用其组合执行。
说明书和附图相应地视为说明性的而非限制性的意义。然而,很明显,在不脱离更广精神和范围的情况下,可以作出增加、裁减、删除和其他修改和改变。
- 还没有人留言评论。精彩留言会获得点赞!