一种面向中文新闻文本的事件地点抽取方法与流程
本发明涉及计算机科学与技术中的文本挖掘、自然语言处理、舆情分析领域,特别涉及一种面向中文新闻文本的事件地点抽取方法。
背景技术:
新闻文本中,存在机构名、处所名词、地名等词汇或短语,但是它们并不一定是事件发生的地点。例如,在新闻文本中“2012年6月19日,在墨西哥洛斯卡沃斯召开的G20峰会期间,阿根廷总统克里斯蒂娜向英国首相卡梅伦递交有关马尔维纳斯群岛主权的函件”中,存在地名“墨西哥”、“洛斯卡沃斯”、“马尔维纳斯群岛”三个地名,但是“马尔维纳斯群岛”并不是事件发生的地点。如何从机构名、处所名词、地名中识别出事件地点是事件抽取中的一个难题。关于面向中文新闻文本的事件地点抽取的专利。专利名称《一种地名识别方法和装置》公开号CN103186524A;该发明公开了一种地名识别方法和装置,用以进行地名识别。该发明方法包括:对待识别的字符串进行分词得到候选词;获取各候选词在地址名称库中的所属类别;对各候选词进行遍历,若当前候选词的所属类别为第一类别,则将当前候选词作为地名添加到候选地名集合;若当前候选词的所属类别为第二类别,则对当前候选词以及在所述地址名称库中与当前候选词临近的候选词进行组合得到合成词,并将所述合成词作为地名添加到候选地名集合。但是该专利只能识别文本中的地名,还不能识别出事件地点。
技术实现要素:
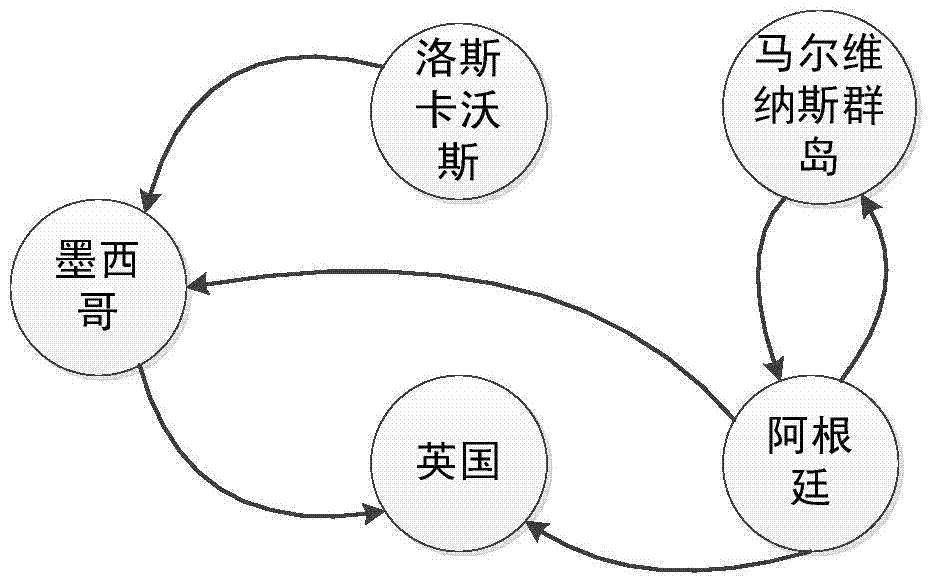
为了克服上述现有技术的缺陷,本发明的目的在于提供一种面向中文新闻文本的事件地点抽取方法,该方法从新闻文本中抽取上下文特征、位置特征、拓扑特征三个特征构成特征向量,利用RandomForest分类器从分词获取机构名、处所名词、地名中识别出事件地点;能够在地名识别的基础上,进一步识别出新闻事件发生的地点。为达到以上目的,本发明的技术方案为:一种面向中文新闻文本的事件地点抽取方法,包括如下步骤:步骤一:候选事件地点抽取(1)首先,利用ICTCLAS中文分词工具对中文新闻文本T进行分词,生成一个由二元组构成的序列ST=(w1,p1),(w2,p2),...,(wi,pi),...,(wn,pn),其中,n表示切分出的词汇的个数,n>0,wi表示ICTCLAS切分出的词汇,pi表示wi的词性;(2)从ST中依次选择所有满足pi=″ni″pi=″nl″、pi=″ns″三种情况之一的二元组,pi=″ni″pi=″nl″、pi=″ns″分别表示对应的wi为机构名、处所名词、地名;所有被选中的二元组中的wi构成一个集合WT={w′1,w′2,...,w′j,...,w′m},WT将作为候选事件地点的集合,m表示WT中词汇的个数,m>0;步骤二:特征向量构建对于集合WT中的每个w′j,选择三个特征,包括:w′j在新闻文本T中的上下文Context特征;w′j在新闻文本T中的位置特征;w′j在新闻文本T中的拓扑特征;三个特征的计算如下:特征一:w′j在新闻文本T中的上下文特征cjw′j在新闻文本T中的上下文特征用w′j所匹配的正则表达式的权重表示,记为cj;(1)若w′j在新闻文本T中能够匹配下表中的某个正则表达式,假设为第k个,则cj=ak;ak表示“若词汇匹配第k个正则表达式,则该词汇是事件地点的比率”,ak的计算公式为:ak=|Lk|/|Sk|,其中,Sk表示标注数据中能成功匹配第k个正则表达式的所有词汇的集合,Lk表示属于Sk且在标注数据中是事件地点的词汇构成的集合,标注数据是指人工标注了事件地点的新闻文本集;(2)若w′j在新闻文本T中能够匹配下表中的多个正则表达式,设为第k1,k2,...,kl(l>1)个正则表达式,则(3)若w′j在新闻文本T中不能匹配下表中的正则表达式,则cj=0。特征二:w′j在新闻文本T中的位置特征pjpj=loc(w′j,T),其中,loc(w′j,T)表示词汇w′j在新闻文本T中首次出现的位置,即从文本T起始处到词汇w′j第一次出现位置之间的字数。特征三:w′j在新闻文本T中的拓扑特征tj初始化空集合E;对于任意二元组(w′j,w′j)∈WT×WT且,执行以下两个步骤:STEP1:将字符串“http://www.baike.com/wiki/”与w′j组成URL,下载该URL对应的页面;若下载不到,则不处理二元组(w′j,w′i);STEP2:利用正则表达式/<a[^>]*?href=[″’]?([^’″>]*)[’″]?[^>]*?>(.*?)</a>/ig匹配页面文件,获取所有锚文本;若锚文本中包含w′i,则把E∪{(w′j,w′i)}的结果赋给E;对于任意二元组(w′j,w′i)∈WT×WT且,执行上述两个步骤后,生成以WT为结点集合,E为有向边集合的有向图G;对任意w′j∈WT,计算其聚集系数C(w′j),聚集系数用于衡量不同结点之间连接的紧密程度;上式中,GΔ(w′j)表示G中包含w′j的闭三点组的数量,GΔ(w′j)为表示G中包含w′j的开三点组的数量;闭三点组指图中任意两两相连的三个结点,开三点组指图中被两条边连接起来的三个结点;令w′j在新闻文本T中的拓扑特征tj为C(w′j),即tj=C(w′j);利用w′j在新闻文本T中的上下文特征、位置特征、拓扑特征,构建w′j的三维特征向量(cj,pj,tj)。步骤三:事件地点识别选择100-200个特征向量,人工为每个特征向量标注一个类标签(事件地点与非事件地点),形成一个训练数据集;采用RandomForest分类器训练一个分类器,利用该分类器将集合WT中的每个w′j按照事件地点与非事件地点进行二值分类,从而实现事件地点的抽取。本发明能依据新闻文本中词汇的上下文特征、位置特征、拓扑特征,建立分类器,实现事件地点的自动抽取。附图说明附图1是面向中文新闻文本的事件地点抽取过程。附图2是用于计算拓扑特征tj的一个有向图实例。具体实施方式下面结合附图对本发明做详细叙述。参照附图,该方法的具体实施方案可分为候选事件地点抽取、特征向量构建、事件地点识别三个步骤。具体描述如下:步骤一:候选事件地点抽取a)首先,利用ICTCLAS中文分词工具对中文新闻文本T进行分词,生成一个由二元组构成的序列ST=(w1,p1),(w2,p2),...,(wi,pi),...,(wn,pn),其中,n表示切分出的词汇的个数,n>0,wi表示ICTCLAS切分出的词汇,pi表示wi的词性;b)从ST中依次选择所有满足pi=″ni″、pi=″nl″、pi=″ns″三种情况之一的二元组,pi=″ni″、pi=″nl″、pi=″ns″分别表示对应的wi为机构名、处所名词、地名;所有被选中的二元组中的wi构成一个集合WT={w′1,w′2,...,w′j,...,w′m},WT将作为候选事件地点的集合。以新闻文本“2012年6月19日,在墨西哥洛斯卡沃斯召开的G20峰会期间,阿根廷总统克里斯蒂娜向英国首相卡梅伦递交有关马尔维纳斯群岛主权的函件”为例,经过上述步骤,可生成集合{墨西哥,洛斯卡沃斯,阿根廷,英国,马尔维纳斯群岛}。步骤二:特征向量构建对于集合WT中的每个w′j,选择三个特征,包括:w′j在新闻文本T中的上下文(Context)特征;w′j在新闻文本T中的位置特征;w′j在新闻文本T中的拓扑特征;三个特征的计算如下:特征一:w′j在新闻文本T中的上下文(Context)特征cjw′j在新闻文本T中的上下文特征用w′j所匹配的正则表达式的权重表示,记为cj:a)若w′j在新闻文本T中能够匹配下表中的某个正则表达式,假设为第k个,则cj=ak;ak表示“若词汇匹配第k个正则表达式,则该词汇是事件地点的比率”,ak的计算公式为:ak=|Lk|/|Sk|,其中,Sk表示标注数据中能成功匹配第k个正则表达式的所有词汇的集合,Lk表示属于Sk且在标注数据中是事件地点的词汇构成的集合,标注数据是指人工标注了事件地点的新闻文本集;b)若w′j在新闻文本T中能够匹配下表中的多个正则表达式,设为第k1,k2,...,kl(l>1)个正则表达式,则c)若w′j在新闻文本T中不能匹配下表中的正则表达式,则cj=0。以新闻文本“2012年6月19日,在墨西哥洛斯卡沃斯召开的G20峰会期间,阿根廷总统克里斯蒂娜向英国首相卡梅伦递交有关马尔维纳斯群岛主权的函件”为例,集合{墨西哥,洛斯卡沃斯,阿根廷,英国,马尔维纳斯群岛}中“墨西哥”可匹配第一个正则表达式“^\在\w+$”,则对应的cj为0.64。特征二:w′j在新闻文本T中的位置特征pj对人工标注事件地点的新闻文本统计分析表明,当机构名、处所名词、地名出现的位置越靠前,越有可能是时间地点。为此,引入位置特征,并定义为:pj=loc(w′j,T),其中,loc(w′j,T)表示词汇w′j在新闻文本T中首次出现的位置,即从文本T起始处到词汇w′j第一次出现位置之间的字数。仍以新闻文本“2012年6月19日,在墨西哥洛斯卡沃斯召开的G20峰会期间,阿根廷总统克里斯蒂娜向英国首相卡梅伦递交有关马尔维纳斯群岛主权的函件”为例,“墨西哥”在该文本首次的位置为12,故对应的pj为12。特征三:w′j在新闻文本T中的拓扑特征tj对人工标注事件地点的新闻文本统计分析表明,如果事件发生的地点有多个,则这些事件地点存在较强的相关性。为此,用地点对在“互动百科”对应页面中是否互相出现来描述是否存在相关性。初始化空集合E;对于任意二元组(w′j,w′i)∈WT×WT且,执行以下两个步骤:STEP1:将字符串“http://www.baike.com/wiki/”与w′j组成URL,下载该URL对应的页面;若下载不到,则不处理二元组(w′j,w′i);STEP2:利用正则表达式/<a[^>]*?href=[″’]?([^’″>]*)[’″]?[^>]*?>(.*?)</a>/ig匹配页面文件,获取所有锚文本;若锚文本中包含w′i,则把E∪{(w′j,w′i)}的结果赋给E。对于任意二元组(w′j,w′i)∈WT×WT且,执行上述两个步骤后,生成以WT为结点集合,E为有向边集合的有向图G;以新闻文本“2012年6月19日,在墨西哥洛斯卡沃斯召开的G20峰会期间,阿根廷总统克里斯蒂娜向英国首相卡梅伦递交有关马尔维纳斯群岛主权的函件”为例,可生成图2所示的有向图。对任意w′j∈WT,计算其聚集系数C(w′j),聚集系数用于衡量不同结点之间连接的紧密程度;这里,用于衡量多个获选时间地点之间的相关程度;上式中,GΔ(w′j)表示G中包含w′j的闭三点组的数量,GΔ(w′j)为表示G中包含w′j的开三点组的数量。闭三点组指图中任意两两相连的三个结点,开三点组指图中被两条边连接起来的三个结点;令w′j在新闻文本T中的拓扑特征tj为C(w′j),即tj=C(w′j)。根据图2,“墨西哥”的拓扑特征利用w′j在新闻文本T中的上下文特征、位置特征、拓扑特征,构建w′j的三维特征向量(cj,pi,tj)。以新闻文本“2012年6月19日,在墨西哥洛斯卡沃斯召开的G20峰会期间,阿根廷总统克里斯蒂娜向英国首相卡梅伦递交有关马尔维纳斯群岛主权的函件”为此,“墨西哥”在此文本中的特征向量为(0.64,12,0.6)步骤三:事件地点识别选择100-200特征向量,人工为每个特征向量标注一个类标签(事件地点与非事件地点),形成一个训练数据集。根据w′j在新闻文本T中的上下文特征、位置特征、拓扑特征,采用RandomForest分类器训练出一个分类模型,能够对WT中的词汇按照事件地点与非事件地点进行二值分类,从而实现事件地点的抽取。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1