一种基于不同数据组织方式的虚拟身份管理系统副本策略的制作方法
本发明属互联网技术领域,具体涉及一种基于不同数据组织方式的虚拟身份管理系统副本策略。
背景技术:
eID(electronic IDentity)全称为公民网络电子身份标识,elD是网络上远程证明个人真实身份的权威性电子信息文件。当eID在网络上远程使用时,使用基于公安人口数据库以及elD服务平台完成真实身份的验证,可在实现个人身份的真实性和有效性确认的同时保护公民身份隐私,具有权威性、安全性、可追溯、方便易用等特点。在互联网中,用户与各种应用、平台下的虚拟身份之间存在着一对多的关系,而在基于eID的网络环境中,上述这些对应关系都可基于eID这个唯一标识,而虚拟身份数据指的就是eID用户在不同的应用下具有的所有数据。
文献[2]中的一致性hash算法是一种特殊的hash算法,当调整hash表大小时,平均只有K/n个数据需要被重新映射,其中K是数据量的大小,n是缓冲的大小。相对地,在大多数其它hash表中,缓冲数组的变化基本上导致其中所有数据都需要重新映射。
文献[3]中的分布式一致性hash算法就是在一致性hash算法的基础之上增加了虚拟节点的考虑,其目的就是把hash的结果尽可能平均地分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
文献[3]中采用了Cassandra数据库来存储虚拟身份数据,通过建立外部索引来提高查询效率,采用Cassandra自带的副本策略来实现数据的备份,合理利用 了文献[1]和文献[2]的技术,对海量虚拟身份数据的存储有较高的效率。但该方法是通过建立大量的外部索引来提高查询效率,所需存储空间较大,算法比较复杂;在副本问题上,沿用了Cassandra数据库自带的副本策略,将副本仅仅当做存储冗余来看待,并没有合理利用副本的作用。
[1]JiaKui Zhao,PingFei Zhu,LiangHuai,Yang.Effective Data Localization Using Consistent Hashing in Cloud Time-Series Databases[J].Applied Mechanics and Materials,2013,347:2246-2251.
[2]一致性哈希改进[EB/OL].http://blog.163.com/lin_guoqian@126/blog/static/1693687432012151010409/.
[3]邓璐,海量虚拟身份数据的存储管理关键技术研究与实现,2010.
技术实现要素:
针对以上问题,本发明参考文献[3]的方法选用Cassandra数据库来存储虚拟身份数据库,提供一种基于不同数据组织方式的虚拟身份管理系统副本策略,适用于虚拟身份管理系统的数据副本放置问题。
本发明的技术方案如下:
一种基于不同数据组织方式的虚拟身份管理系统副本策略,主要包括以下步骤:
(1)虚拟身份数据划分:将Cassandra列数据库的按列存储的思想应用在虚拟身份数据上,对虚拟身份数据进行水平划分与垂直划分,水平方向按照eID进行划分,垂直方向按照应用程序进行划分;
(2)副本1的数据组织:将同一个用户的所有数据对象存储在一起,存储完一个用户的所有数据后,再存储下一个用户,同时,在用户的存储顺序上,将同一个地区的用户集中存储并按注册时间的先后顺序进行排序;
(3)副本2的数据组织;
(4)副本分布;
(5)数据查询:当客户端要查询数据的时候,先分析查询语句,然后根据分析结果选择指令发送到副本1或副本2。
进一步的,在所述的步骤(3)中还包括以下步骤:
1)按应用平台对数据对象进行划分;
2)在各个应用平台内部,按照用户所在地区进行划分;
3)应用平台内一个地区的用户,按照数据副本1的方式排序;
4)如果用户在平台下未注册,则直接跳过。
进一步的,在所述的步骤(4)中还包括以下步骤:
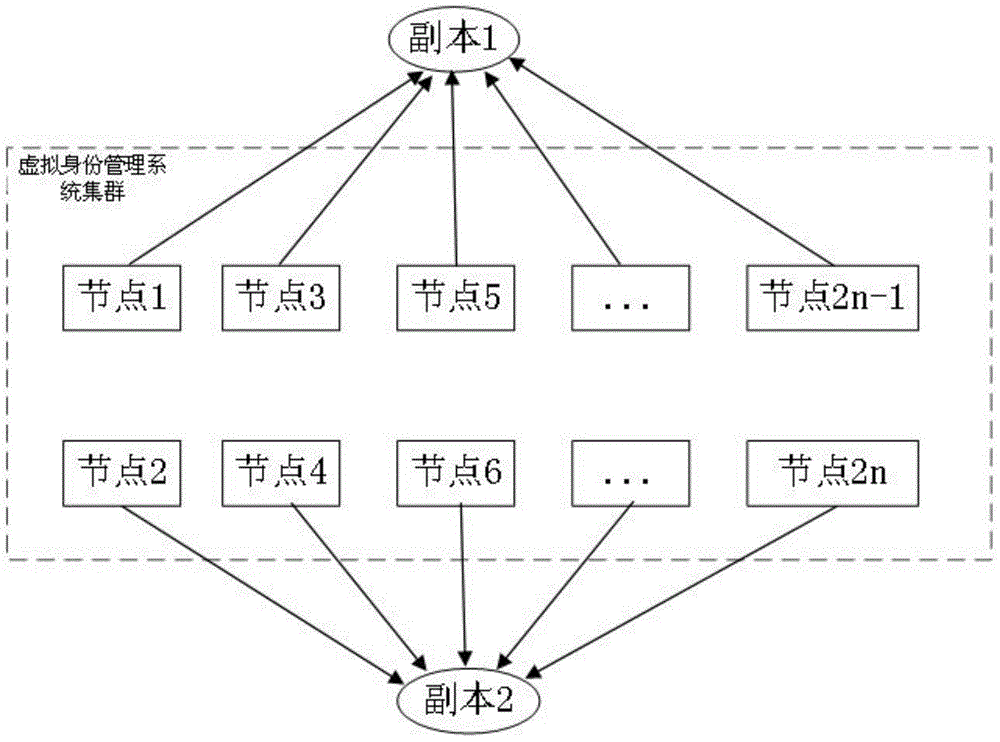
1)将副本1和副本2分开存储,副本1存储在集群的奇数节点上,副本2存储在集群的偶数节点上;
2)奇数节点与偶数节点相邻,节点1与节点2n相邻;
3)设定两种不同的hash函数,使计算得出的数据对象的hash值分别按副本1和副本2的数据组织方式进行排序,然后用一致性hash算法将数据和节点进行映射。
更进一步的,在所述的步骤3)中所述的hash函数是将一个对象映射成另一个对象,可以先将对象排序,然后再根据对象的排序方式,设置hash函数。
更进一步的,在所述的步骤3)中进行一致性hash算法计算数据对象hash值时,将数据对象的基本单位设定为某个用户在某个应用下的所有数据,及一个eID账号和一个应用名称共同组成一个数据对象的主键。
进一步的,在所述的步骤(5)中还包括以下步骤:
1)分析查询语句,判断是否为以用户为主的查询;
2)若是以用户为主的查询,则将指令发送到副本1,并执行查询操作;
3)若不是以用户为主的查询,则分析查询语句,判断是否为以应用平台为主的查询;
4)若是以应用平台为主的查询,则将指令发送到副本2,并执行查询操作;
5)若不是以应用平台为主的查询,则根据当前系统负载选择副本,并执行查询操作。
本发明的有益效果是:传统的副本策略要求相同数据的副本不能放到同一台物理机上,但对不同数据的副本之间的放置没有要求。本发明主要对Cassandra数据库的副本策略进行改进,副本数量设置为2,当Csassandra数据库用一致性hash算法对虚拟身份数据进行划分之后,将数据的副本重新组织,选用有利于查询的划分方法对虚拟身份数据进行重新划分,然后遵从相同数据副本不在同一台物理机的规则对副本进行放置。数据副本1的组织方式有利于将eID用户数据分地区管理,当需要读取数据的时候,根据要请求数据的特点,选择要进行操作的副本,从而提高数据访问效率,使得数据副本不再只是为了灾备而进行的冗余存储,而是通过不同副本采用不同的数据组织方式以应对不同的查询请求,减少查询时间,减少网络传输代价,最大化系统效率,适用于虚拟身份管理系统的数据副本放置问题。
附图说明
图1为本发明的数据查询流程图。
图2为本发明的副本分布图。
图3为本发明实施例1中的虚拟身份信息图。
图4为本发明实施例1中的副本1的组织方式图。
图5为本发明实施例1中的虚拟身份数据分布图。
图6为本发明实施例1中的副本2的组织方式图。
具体实施方式
为了便于理解本发明,以下结合说明书附图和实施例对本发明作进一步说明。
本发明提供一种基于不同数据组织方式的虚拟身份管理系统副本策略,主要包括以下步骤:
(1)虚拟身份数据划分:将Cassandra列数据库的数据模型应用在虚拟身份数据上,对虚拟身份数据进行水平划分与垂直划分,水平方向按照eID进行划分,垂直方向按照应用程序进行划分;
(2)副本1的数据组织:将同一个用户的所有数据对象存储在一起,存储完一个用户的所有数据后,再存储下一个用户,同时,在用户的存储顺序上,将同一个地区的用户集中存储并按固定的顺序进行排序;
(3)副本2的数据组织;
(4)副本分布;
(5)数据查询:当客户端要查询数据的时候,先分析查询语句,然后根据分析结果选择指令发送到副本1或副本2。
本发明的开发环境:Linux操作系统的X86平台,JDK1.7,采用java语言编写,数据服务器需要安装Cassandra1.0或更高版本的数据库软件,为系统提供数据支持。
本发明的运行环境:服务器端运行于安装有Linux操作系统的X86平台,JDK1.7或以上版本的多个机器节点,客户端为普通个人电脑。
以下为本发明的典型实施方式:
实施例1:
(1)虚拟身份数据划分:在网域空间,用户根据自己的需求在不同的应用平台上注册账号,这些应用平台包括电子商务,社交网络,网络游戏等。虚拟身份管理系统通过eID将这些信息统一起来,一个用户拥有唯一的eID标识,他在不同的应用平台下又拥有不同的虚拟账户,这些数据部结构不一,大小不同,而且数据量巨大。将Cassandra列数据库的数据模型应用在虚拟身份数据上,如表1所示:
表1虚拟身份数据模型
本发明根据以上存储模型,对虚拟身份数据进行水平划分与垂直划分,水平方向按照eID进行划分,垂直方向上按照应用程序进行划分,在进行一致性hash算法计算数据对象hash值时,将数据对象单位设定为某个用户在某个应用下的所有数据,及一个eID账号和一个应用名称共同组成一个数据对象的“主键”。本发明不关注一个数据对象内部的数据组织方式,而是主要解决不同副本数据对象之间的组织方式。
(2)副本1的数据组织方式:在实际的数据请求操作中,往往会请求某个用户在所有应用平台下的虚拟身份信息,例如,用户张三的eID数据出现了异 常,存在被盗的可能,此时就需要查看张三的所有虚拟身份数据。假设用户张三一共申请了包括社交网络,电子商务网站,网络游戏等8个应用平台,那么他在网域空间中的所有虚拟身份信息如图3所示,其中一个矩形框表示一个数据对象。
如果将这些数据对象按照随机的方式分布在数据节点上,那么在完成上述查询的时候可能会跨越很多个不同的节点,不仅影响查询速度,还会占用网络带宽,因此,基于本发明技术,数据副本1的组织方式将同一个用户的所有数据对象存储在一起,存储完一个用户的所有数据后,再存储下一个用户,以此类推。在用户的存储的顺序上,考虑将同一个地区的用户集中存储,统一地区的用户按照一个固定的顺序进行排序。这样有利于将eID用户数据分地区管理。最终副本1的组织方式如图4所示。
(3)副本2的组织方式:在实际的数据请求操作中,通常会对某一个应用平台的数据进行操作,例如查看淘宝网在各个地区的用户情况。此时需要获得淘宝网应用的所有虚拟用户数据,淘宝网的虚拟身份数据分布如图5所示。
如果将所有的数据对象按照一致性hash随机分布在数据节点上或者按照副本1的方式进行分布,在进行这个操作的时候,同样会跨越很多节点,占用带宽,较低了的集群的效率,同时数据副本2仅仅作为了副本1的冗余,并没有把它的作用发挥到最大。基于以上考虑,本发明将数据副本2按照如下方式进行组织:1、先按应用平台对数据对象进行划分;2、在各个应用平台内部,按照用户所在地区进行划分;3、应用平台内一个地区的用户,按照数据副本1的方式排序;4、如果某用户在某平台下未注册,则直接跳过即可,如图6所示。
(4)副本分布:本发明将副本1和副本2分开存储,即副本1存储在集群 其中一半节点上,副本2存储在整个集群的另一半节点上,其分布如图2所示。其中奇数节点与偶数节点相邻,节点1与节点2n相邻。选择合适的hash函数,使得数剧对象的hash值按照副本1和副本2组织方式进行排序,然后用一致性hash算法将数据和节点进行映射。至此,所有的数据副本都按照指定方法分布在了集群中。
所述的hash函数是将一个对象映射成另一个对象,可以先将对象排序,然后再根据对象的排序方式,设置hash函数。
(5)数据查询:当客户端要查询数据的时候,先分析查询语句,然后根据分析结果选择指令发送到副本1或副本2,其流程如图1所示。
传统的副本策略要求相同数据的副本不能放到同一台物理机上,但对不同数据的副本之间的放置没有要求。本发明主要对Cassandra数据库的副本策略进行改进,副本数量设置为2,当Csassandra数据库用一致性hash算法对虚拟身份数据进行划分之后,将数据的副本重新组织,选用有利于查询的划分方法对虚拟身份数据进行重新划分,然后遵从相同数据副本不在同一台物理机的规则对副本进行放置。数据副本1的组织方式有利于将eID用户数据分地区管理,当需要读取数据的时候,根据要请求数据的特点,选择要进行操作的副本,从而提高数据访问效率,使得数据副本不再只是为了灾备而进行的冗余存储,而是通过不同副本采用不同的数据组织方式以应对不同的查询请求,减少查询时间,减少网络传输代价,最大化系统效率,适用于虚拟身份管理系统的数据副本放置问题。
以上是对本发明进行了示例性的描述,显然本发明的实现并不受上述方式的限制,只要采用了本发明技术方案进行的各种改进,或未经改进将本发明的 构思和技术方案直接应用于其它场合的,均在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!