一种地址数据的管理方法和装置与流程
本申请涉及通信
技术领域:
,尤其涉及一种地址数据的管理方法和装置。
背景技术:
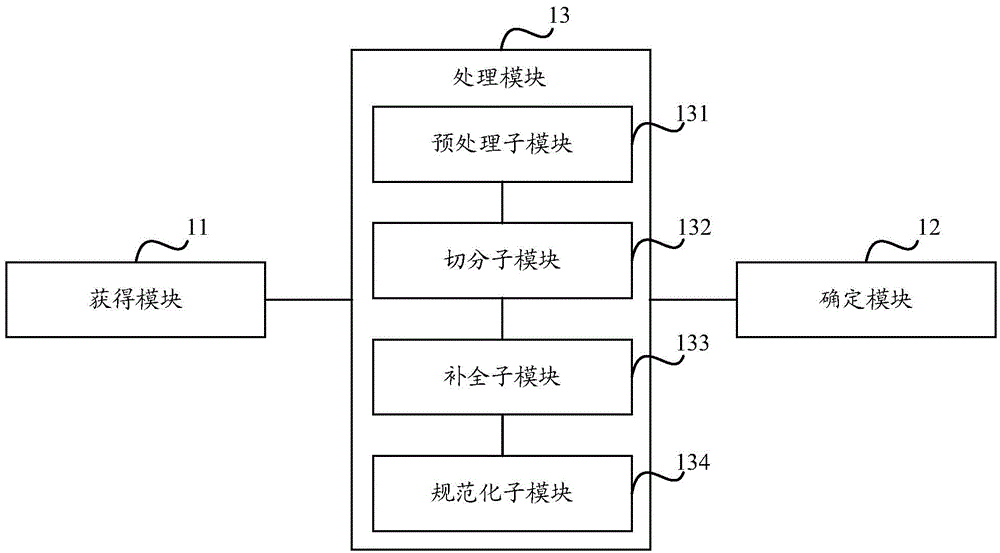
:在电子商务网站和物流系统中产生了大量文本地址,这些文本地址的输入格式和地址元素因用户而不同。例如,用户A输入的文本地址只包括门牌号信息,用户B输入的文本地址只包括POI(PointofInterest,兴趣点)信息,用户C输入的文本地址包括错误的区县或门牌号信息。这些文本地址缺乏规范化、标准化,无法判断不同文本地址间的异同性,无法识别文本地址的相关归属。其中,地址元素是指文本地址中的各级元素,如省、市、区、开发区、镇、路、POI等。POI可以是一栋房子、一个商铺、一个邮筒、一个公交站等。技术实现要素:本申请实施例提供一种地址数据的管理方法和装置,以生成规范化、标准化的地址数据,从而解决无法对文本地址进行规范化的问题。本申请实施例提供一种地址数据的管理方法,所述方法包括以下步骤:地址管理装置获得用户输入的原始地址数据;所述地址管理装置确定包括多个地址类型的结构化地址格式;所述地址管理装置将所述原始地址数据转换为符合所述结构化地址格式的结构化地址数据,所述结构化地址数据包括对应多个地址类型的地址数据。所述地址管理装置将所述原始地址数据转换为符合所述结构化地址格式的结构化地址数据,具体包括:所述地址管理装置基于多个地址类型对原始地址数据进行预处理;所述地址管理装置基于多个地址类型对预处理后的地址数据进行切分;所述地址管理装置基于多个地址类型对切分后地址数据进行补全校验;所述地址管理装置对补全校验后的地址数据进行规范化处理,以得到符合所述结构化地址格式的结构化地址数据。所述地址管理装置基于多个地址类型对原始地址数据进行预处理的过程,具体包括:所述地址管理装置从所述原始地址数据中筛选出未对应所述多个地址类型的地址数据,从所述原始地址数据中删除当前筛选的地址数据,并将所述原始地址数据中存在的非规范格式的地址数据转换为规范格式的地址数据。所述地址管理装置基于多个地址类型对预处理后的地址数据进行切分的过程,具体包括:所述地址管理装置获得所述多个地址类型对应的分词器词典,利用所述多个地址类型对应的分词器词典切分出对应所述多个地址类型的地址数据。所述地址管理装置基于多个地址类型对切分后地址数据进行补全校验的过程,具体包括:所述地址管理装置校验切分后地址数据是否已经包含对应所述多个地址类型的地址数据;如果否,则所述地址管理装置确定切分后地址数据中不包含的地址类型,并基于历史数据补全所述地址类型的地址数据。所述地址管理装置对补全校验后的地址数据进行规范化处理的过程,具体包括:所述地址管理装置利用拼音相似度算法对补全校验后的地址数据进行规范化处理;和/或,所述地址管理装置利用基于概率检索模型的兴趣点POI规范化算法对补全校验后的地址数据进行规范化处理。本申请实施例提供一种地址管理装置,所述地址管理装置具体包括:获得模块,用于获得用户输入的原始地址数据;确定模块,用于确定包括多个地址类型的结构化地址格式;处理模块,用于将所述原始地址数据转换为符合所述结构化地址格式的结构化地址数据,所述结构化地址数据包括对应多个地址类型的地址数据。所述处理模块包括:预处理子模块,用于基于多个地址类型对原始地址数据进行预处理;切分子模块,用于基于多个地址类型对预处理后的地址数据进行切分;补全子模块,用于基于多个地址类型对切分后地址数据进行补全校验;规范化子模块,用于对补全校验后的地址数据进行规范化处理,以得到符合所述结构化地址格式的结构化地址数据。所述预处理子模块,具体用于从原始地址数据中筛选出未对应所述多个地址类型的地址数据,从原始地址数据中删除当前筛选的地址数据,并将原始地址数据中存在的非规范格式的地址数据转换为规范格式的地址数据。所述切分子模块,具体用于获得多个地址类型对应的分词器词典,利用多个地址类型对应的分词器词典切分出对应所述多个地址类型的地址数据。所述补全子模块,具体用于校验切分后的地址数据是否已经包含对应所述多个地址类型的地址数据;如果否,则确定切分后的地址数据中不包含的地址类型,并基于历史数据补全所述地址类型的地址数据。所述规范化子模块,具体用于利用拼音相似度算法对补全校验后的地址数据进行规范化处理;和/或,利用基于概率检索模型的兴趣点POI规范化算法对补全校验后的地址数据进行规范化处理。与现有技术相比,本申请实施例至少具有以下优点:本申请实施例中,通过设置包括多个地址类型的结构化地址格式,并生成符合结构化地址格式的结构化地址数据,从而生成规范化、标准化的地址数据,解决无法对文本地址进行规范化的问题,并能够判断不同文本地址间的异同性,能够识别文本地址的相关归属。具体的,通过对海量历史文本地址中的地址数据进行识别和提取,通过学习的方式从中学习出地址数据之间的知识和规则,并将学习的知识和规则对漏写地址数据进行补全、对错误地址数据进行校验,对非 规范地址数据进行规范化处理,重新生成一条分级的结构化地址数据。附图说明为了更加清楚地说明本申请实施例的技术方案,下面将对本申请实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据本申请实施例的这些附图获得其他的附图。图1是本申请实施例一提供的一种地址数据的管理方法流程示意图;图2是本申请实施例二提供的一种地址管理装置的结构示意图。具体实施方式下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请的一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。实施例一针对现有技术中存在的问题,本申请实施例一提供一种地址数据的管理方法,如图1所示,该地址数据的管理方法具体可以包括以下步骤:步骤101,地址管理装置获得用户输入的原始地址数据。本申请实施例中,地址管理装置内可以配置整合模块,整合模块用于将各方地址数据源进行整合,生成唯一的key(密钥),并装入文本地址库。其中,文本地址库中的针对一个key的地址数据,即用户输入的原始地址数据。步骤102,地址管理装置确定包括多个地址类型的结构化地址格式。其中,结构化地址格式中包括的多个地址类型具体包括但不限于以下之一或者任意组合:省、市、区县、乡镇(街道办)、开发区、主路、主路门牌号、支路、支路门牌号、标志性POI(楼盘等)、幢、单元(楼层)、房间号等。步骤103,地址管理装置将原始地址数据转换为符合结构化地址格式的结构化地址数据,该结构化地址数据包括对应多个地址类型的地址数据。例如,在地址管理装置生成的符合结构化地址格式的结构化地址数据中,可以包括对应于省的地址数据、对应于市的地址数据、对应于区县的地址数据、对应于乡镇(街道办)、对应于开发区的地址数据、对应于主路的地址数据、对应于主路门牌号的地址数据、对应于支路的地址数据、对应于支路门牌号的地址数据、对应于标志性POI(楼盘等)的地址数据、对应于幢的地址数据、对应于单元(楼层)的地址数据、对应于房间号的地址数据等。本申请实施例中,地址管理装置将原始地址数据转换为符合结构化地址格式的结构化地址数据的过程,具体包括但不限于:地址管理装置基于多个地址类型对原始地址数据进行预处理;之后,地址管理装置基于多个地址类型对预处理后的地址数据进行切分;之后,地址管理装置基于多个地址类型对切分后地址数据进行补全校验;之后,地址管理装置对补全校验后的地址数据进行规范化处理,以得到符合结构化地址格式的结构化地址数据。本申请实施例中,地址管理装置基于多个地址类型对原始地址数据进行预处理的过程,具体包括:地址管理装置从原始地址数据中筛选出未对应多个地址类型的地址数据,从原始地址数据中删除当前筛选的地址数据,并将原始地址数据中存在的非规范格式的地址数据转换为规范格式的地址数据。本申请实施例中,地址管理装置内可以配置预处理模块,由该预处理模块从原始地址数据中筛选出未对应多个地址类型的地址数据,并从原始地址数据中删除当前筛选的地址数据。进一步的,由该预处理模块将原始地址数据中存在的非规范格式的地址数据转换为规范格式的地址数据。其中,由于用户输入的原始地址数据是用户填写的,具有随意性,因此原始地址数据中会包含对应多个地址类型的地址数据,如河北省、保定市等地址数据,原始地址数据中也会包含未对应多个地址类型的地址数据,如话 费充值信息、虚拟游戏点卡信息等,这些未对应多个地址类型的地址数据是需要进行数据清洗的。基于此,预处理模块从原始地址数据中筛选出未对应多个地址类型的地址数据,并从原始地址数据中删除当前筛选的地址数据。其中,由于用户输入的原始地址数据是用户填写的,具有随意性,因此原始地址数据中会存在非规范格式的地址数据。如英文;数字写为全角;非香港、澳门、台湾地区的地址存在繁体地址现象;香港、澳门、台湾地区的地址存在简体地址现象;门牌号的地址存在中文现象(如二十号);以数字命名的道路名出现数字现象(如文2路)等。基于此,预处理模块将原始地址数据中存在的非规范格式的地址数据转换为规范格式的地址数据。其中,规范格式的地址数据包括但不限于:英文、数字的全角更改为半角;大陆地址一律规范格式为简体中文;港澳台地区的地址一律规范格式为繁体中文;道路名一律规范格式为中文;门牌号、房间号等一律规范格式为数字。本申请实施例中,地址管理装置基于多个地址类型对预处理后的地址数据进行切分的过程,具体包括但不限于如下方式:地址管理装置获得多个地址类型对应的分词器词典,并利用该多个地址类型对应的分词器词典将预处理后的地址数据切分出对应于这多个地址类型的地址数据。例如,基于多个地址类型对应的分词器词典,地址管理装置可以将预处理后的地址数据切分出对应于省的地址数据、对应于市的地址数据、对应于区县的地址数据、对应于乡镇(街道办)、对应于开发区的地址数据、对应于主路的地址数据、对应于主路门牌号的地址数据、对应于支路的地址数据、对应于支路门牌号的地址数据、对应于标志性POI(楼盘等)的地址数据、对应于幢的地址数据、对应于单元(楼层)的地址数据、对应于房间号的地址数据等。本申请实施例中,地址管理装置内可以配置切分模块,由该切分模块获得多个地址类型对应的分词器词典,并利用该多个地址类型对应的分词器词典将预处理后的地址数据切分出对应于这多个地址类型的地址数据。其中,分词器词典包括但不限于:省、市、区县词典;乡镇词典;工业区词典;村庄词典;街道词典;高校词典;社区标准词典;社区自学习词典。其中,在切分模块利用分词器词典将预处理后的地址数据切分出对应于多个地址类型的地址数据的过程中,则相应的切分算法具体包括:前向有限状态最大匹配算法,其切分规则包括:基于关键字切分,如:镇,街,路,公司,大厦,中学,门牌号,社区详细地址(幢、单元、房间号)等。进一步的,相应的切分流程具体包括:省、市、区切分:采用基于省市区词典初始化的分词器切割详细地址,若切分后的省、市、区与原始的省、市、区字段不同,则替换,并减少后续切分误差,保留剩余地址。乡镇(工业区)切分:采用基于乡镇(工业区)词典初始化分词器(以市为单元共362个)切分上一步的剩余地址;若分词器切分失败则切分详细地址;若仍切分失败则采用乡镇规则切分,并标记后续处理。道路切分:与乡镇(工业区)切分流程类似,只是采用乡镇词典初始化362个道路分词器。门牌号切分:采用相应的切分规则进行切分。社区(楼盘)切分:采用社区词典初始化社区分词器(以市为单元共362个),切分上一步的剩余地址;若分词器切分失败则切分详细地址;若切分出两个社区元素,则字串长度最大的作为社区元素;若仍切分失败则采用自学习词典的分词器切分详细地址;若仍切分失败则采用社区规则切分,并将采用自学习词典或社区规则切分的社区标记后续处理。社区内详细地址切分(幢、单元、房间号):采用相应的切分规则进行切分。本申请实施例中,地址管理装置基于多个地址类型对切分后地址数据进行补全校验的过程,具体包括但不限于:地址管理装置校验切分后地址数据是否已经包含对应所有多个地址类型的地址数据;如果否,则地址管理装置确定切分后的地址数据中不包含的地址类型,并基于历史数据补全该地址类型的地址数据;如果是,则地址管理装置不需要补全相应的地址数据。例如,当地址管理装置基于多个地址类型切分出对应于省的地址数据、 对应于区县的地址数据、对应于开发区的地址数据、对应于主路的地址数据、对应于主路门牌号的地址数据、对应于支路的地址数据、对应于支路门牌号的地址数据、对应于单元(楼层)的地址数据时,则:地址管理装置校验出切分后的地址数据未包含对应所有多个地址类型的地址数据,并基于历史数据补全对应于市的地址数据、对应于乡镇(街道办)、对应于标志性POI(楼盘等)的地址数据、对应于幢的地址数据、对应于房间号的地址数据。本申请实施例中,地址管理装置内可以配置补全校验模块,由该补全校验模块校验切分后地址数据是否已经包含对应所有多个地址类型的地址数据;如果否,则确定切分后的地址数据中不包含的地址类型,并基于历史数据补全该地址类型的地址数据;如果是,则不需要补全相应的地址数据。其中,地址数据中存在大量非正确的地址数据,如正确地址数据:杭州市文二路391号西湖国际科技大厦B座2楼小邮局,而用户填写如下非标准或不正确的地址数据:杭州市文二路391号2楼小邮局;杭州市文二路西湖国际科技大厦B座2楼小邮局;杭州市文二路380号西湖国际科技大厦B座2楼小邮局。基于上述情况,补全校验模块在地址数据处理过程中,对上述情况进行处理,在切分后的地址数据的门牌号或社区字段进行补全与校正。其中,基于结构地址标准库,则可以将结构地址标准库中的每条地址数据采用相应的切分算法进行结构化为:市+区县+道路+门牌号+社区。统计以上5个字段都完全的地址频次。筛选地址频次大于3的地址。统计市+区县+道路+门牌号下每个社区的使用频次,并保留频次最大的市+区县+道路+门牌号+社区,并将其加入结构地址标准库中。或者,基于结构地址标准库,则可以将结构地址标准库中的每条地址数据采用相应的切分算法进行结构化为:市+道路+门牌号+社区。统计以上4个字段都完全的地址频次。筛选地址频次大于等于1的地址。统计市+道路+门牌号下每个社区的使用频次,并保留频次最大的市+道路+门牌号+社区,并将其加入结构地址标准库中。基于结构地址标准库,则在地址数据的补全与校正过程中,假设市+区县+道路+门牌号下仅有一个社区,针对每一条已结构化的地址数据,如果社区字段为null(空)或者为规则切分或者为自学习词典分词器切分,则可以从结构地址标准库中查询市+区县+道路+门牌号为key的社区,并补全或者校正社区字段。进一步的,基于结构地址标准库,假设市+区县+道路+社区下仅有一个门牌号,针对每一条已结构化的地址数据,如果门牌号为null或者为规则切分或者为自学习词典分词器切分,则可以从结构地址标准库中查询市+区县+道路+社区为key的门牌号,并补全或者校正门牌号字段。本申请实施例中,地址管理装置对补全校验后的地址数据进行规范化处理的过程,具体包括但不限于如下方式:地址管理装置利用拼音相似度算法对补全校验后的地址数据进行规范化处理;和/或,地址管理装置利用基于概率检索模型的POI规范化算法对补全校验后的地址数据进行规范化处理。本申请实施例中,地址管理装置内可以配置规范化模块,规范化模块利用拼音相似度算法对补全校验后的地址数据进行规范化处理;和/或,利用基于概率检索模型的POI规范化算法对补全校验后的地址数据进行规范化处理。其中,用户填写的地址数据中存在大量的地址数据的简称、缩写、错别字、谐音等非规范现象。如标准地址数据为西湖国际科技大厦,非规范化的地址数据为西湖国际(缩写);标准地址数据为浙江大学第一附属医院,非规范化的地址数据为浙大一附院(简称);标准地址数据为古墩路,非规范化的地址数据为古吨路(谐音);标准地址数据为保淑路,非规范化的地址数据为保椒路(错别字)。虽然在地址结构化过程中能够将这些地址数据切分出来,但由于多名称现象在地址坐标标注及后续的地址数据分析中存在很大的困难和弊端,因此,规范化模块需要对非规范化的地址数据进行规范化处理。进一步的,规范化模块对非规范化的地址数据进行规范化处理的算法包括但不限于:拼音相似度算法、基于概率检索模型的POI规范化算法。针对拼音相似度算法:规范化模块将非规范化的地址数据和规范化的地址数据转换为拼音,计算相似距离(如最小编辑距离),并将高于阈值且相似度最高的规范化的地址数据作为非规范化的地址数据的标准化地址数据。针对基于概率检索模型的POI规范化算法,规范化模块将识别出来的类POI进行bigram(二元语法)切分,然后对于同时出现在类POI和候选标准POI中的bigram,累加每个bigram的估值,各bigram的估值的和就是候选标准POI与类POI的相关性度量。进一步的,计算出候选POI的相关性得分,并对这些POI得分进行从大到小的排序,筛选出POI类型、POI的区县与地址类型以及地址对应的区县相符的且得分最大的POI,即为规范POI。为了实现上述过程,可以采用如下的BM25(二元独立模型)计算公式:S=Σi∈Qlog(ri+0.5)/(R-ri+0.5)(ni-ri+0.5)/(N-ni-R+ri+0.5)*k+1K+1*wI]]>K=k((1-b)+b*dlavdl)]]>I=(1-b)+b*indexiavg_indexi]]>w=0.35indexi<0.3330.50.333≤indexi<0.660.15indexi≥0.66]]>其中,上述四个公式的相关参数说明如下所示:相关POI不相关POIPOI数量bi=1rini-rinibi=0R-ri(N-R)-(ni-ri)N-niPOI个数RN-RN进一步的,S:候选POI的相关性得分;N:一个城市或者区县的POI数 量;R:与类POI具有两个相同的bigram且jaccard(相似性系数)相似度大于0.4的相关POI数量;ni:为包含bigrambi的POI数量;dl:当前候选标准POI中的bigram个数;avdl:平均每个候选标准POI包含的bigram个数;ri:为ni中的相关POI数量;indexi:bi在当前POI中出现的位置次序;avgindexi:bi在包含其的POI中出现的平均位置次序;k,b:为自由调节参数,根据经验k设置为:1.2,b设置为0.75;K,I:为公式中的临时变量。与现有技术相比,本申请实施例至少具有以下优点:本申请实施例中,通过设置包括多个地址类型的结构化地址格式,并生成符合结构化地址格式的结构化地址数据,从而生成规范化、标准化的地址数据,解决无法对文本地址进行规范化的问题,并能够判断不同文本地址间的异同性,能够识别文本地址的相关归属。具体的,通过对海量历史文本地址中的地址数据进行识别和提取,通过学习的方式从中学习出地址数据之间的知识和规则,并将学习的知识和规则对漏写地址数据进行补全、对错误地址数据进行校验,对非规范地址数据进行规范化处理,重新生成一条分级的结构化地址数据。基于与上述方法同样的申请构思,本申请实施例中还提供了一种地址管理装置,如图2所示,所述地址管理装置具体包括:获得模块11,用于获得用户输入的原始地址数据;确定模块12,用于确定包括多个地址类型的结构化地址格式;处理模块13,用于将所述原始地址数据转换为符合所述结构化地址格式的结构化地址数据,所述结构化地址数据包括对应多个地址类型的地址数据。其中,所述处理模块13具体包括:预处理子模块131,用于基于多个地址类型对原始地址数据进行预处理;切分子模块132,用于基于多个地址类型对预处理后的地址数据进行切分;补全子模块133,用于基于多个地址类型对切分后地址数据进行补全校验;规范化子模块134,用于对补全校验后的地址数据进行规范化处理,以得到符合所述结构化地址格式的结构化地址数据。所述预处理子模块131,具体用于从原始地址数据中筛选出未对应所述多个地址类型的地址数据,从原始地址数据中删除当前筛选的地址数据,并将原始地址数据中存在的非规范格式的地址数据转换为规范格式的地址数据。所述切分子模块132,具体用于获得多个地址类型对应的分词器词典,利用多个地址类型对应的分词器词典切分出对应多个地址类型的地址数据。所述补全子模块133,具体用于校验切分后的地址数据是否已经包含对应所述多个地址类型的地址数据;如果否,则确定切分后的地址数据中不包含的地址类型,并基于历史数据补全所述地址类型的地址数据。所述规范化子模块134,具体用于利用拼音相似度算法对补全校验后的地址数据进行规范化处理;和/或,利用基于概率检索模型的兴趣点POI规范化算法对补全校验后的地址数据进行规范化处理。其中,本申请装置的各个模块可以集成于一体,也可以分离部署。上述模块可以合并为一个模块,也可以进一步拆分成多个子模块。通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到本申请可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述的方法。本领域技术人员可以理解附图只是一个优选实施例的示意图,附图中的模块或流程并不一定是实施本申请所必须的。本领域技术人员可以理解实施例中的装置中的模块可以按照实施例描述进行分布于实施例的装置中,也可以进行相应变化位于不同于本实施例的一个或多个装置中。上述实施例的模块可以合并为一个模块,也可以进一步拆分成多个子模块。上述本申请实施例序号仅仅为了描述,不代表实施例 的优劣。以上公开的仅为本申请的几个具体实施例,但是,本申请并非局限于此,任何本领域的技术人员能思之的变化都应落入本申请的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1