一种基于URL的互联网信息分类识别方法及系统与流程
本发明涉及互联网应用技术领域,尤其涉及一种基于URL的互联网信息分类识别方法及系统。
背景技术:
许多搜索引擎服务,例如百度和google,为搜索提供了通过互联网可以访问的信息。这些搜索引擎服务允许用户去搜索用户感兴趣的显示页,例如新闻网页。在用户提交了包括检索项的搜索请求后,搜索引擎服务识别可能与那些检索项相关的网页。任何特定的网页的关键词能够利用各种公知的信息检索技术来识别,例如识别标题的词、在网页的元数据中提供的词、高亮的词等等。搜索引擎服务可以根据每个匹配的接近程度、网页普及性等等,生成相关分数来指出网页的信息与搜索请求的相关程度。搜索引擎服务接着根据它们的排序的顺序,向用户显示到那些网页的链接。
尽管搜索引擎服务可以返回许多网页作为搜索结果,以排序顺序出现的网页,可能很难使用户来实际发现那些用户特别感兴趣的网页。由于第一个呈现的网页可能被定向到流行的主题,对不著名的主题感兴趣的用户可能需要浏览搜索结果的许多的页才能发现感兴趣的网页。为了使用户更容易地发现感兴趣的网页,搜索结果的网页可以根据网页的某些分类或类别,以分级的组织来呈现。例如,如果用户提交“court battles”的搜索请求,搜索结果可以包括被分类为运动相关的或法律相关的网页。用户可能更喜欢一开始显示网页的分类列表,这样用户能够选择感兴趣的网页的分类。例如,可能首先为用户呈现已经被分类为运动相关的和法律相关的搜索结果的网页的指示。用户能够接着选择法律相关的分类来查看法律相关的网页。相反的,由于运动相关的网页比法律相关的网页更流行,如果最流行的网页首先呈现,用户可能要浏览许多网页来发现法律相关的网页。
手工分类当前可用的成百万的网页是不切实际的。尽管自动分类技术已经被用来分类基于文本的内容,但那些技术通常不适于网页的分类。网页具有包括有干扰的内容的组织,例如广告或导航栏,它们不是与网页首要主题直接相关的。因为传统的基于文本的分类技术在 分类网页时,将利用这样的有干扰的内容,这些技术将导致产生网页的不正确的分类。
现有的对于网页的分类技术主要是,基于互联网页面内容的分析识别,这种方法准确率并不实用,对于高并发的大量请求,响应速度也并不靠谱。
技术实现要素:
鉴于目前互联网应用技术领域存在的上述不足,本发明提供一种基于URL的互联网信息分类识别方法及系统,能够基于URL的分层识别分类,准确率高,响应速度快。
为达到上述目的,本发明的实施例采用如下技术方案:
一种基于URL的互联网信息分类识别方法,所述基于URL的互联网信息分类识别方法包括以下步骤:
从互联网抓取模式化的信息;
基于关键字对抓取的信息进行人工分类处理以获得分类信息来建立分类信息库;
向知识库中导入分类信息库中的分类信息;
根据知识库中的分类信息结合URL结构对互联网信息的URL进行分层识别及分类;
输出识别和分类的结果。
依照本发明的一个方面,所述向知识库中导入分类信息库中的分类信息的具体实施方式可为:导入分类信息库中的分类信息到知识库中进行存储,并将所有知识库加载到内存中。
依照本发明的一个方面,所述根据知识库中的分类信息结合URL结构对互联网信息的URL进行分层识别及分类包括以下步骤:根据知识库中的分类信息对互联网信息的URL进行初步分类,基于URL结构对初步分类后的互联网信息进行进一步分层识别及分类。
依照本发明的一个方面,所述根据分类信息库对互联网信息的URL进行初步分类的具体实施方式可为:根据分类信息库中的关键字,对包含所述关键字的互联网信息的URL进行初步分类。
依照本发明的一个方面,所述基于URL结构对初步分类后的互联网信息进行进一步分层识别及分类的具体实施方式可为:对初步分类 后的互联网信息的URL结构进行分析,基于分层的概念,根据URL层次的不同将所述互联网信息进行进一步分类。
依照本发明的一个方面,所述基于关键字对抓取的信息进行人工分类处理以获得分类信息来建立分类信息库中的分类信息具体可包括:明文分类信息和密文分类信息。
依照本发明的一个方面,所述基于URL的互联网信息分类识别方法包括以下步骤:通过socket连接的方式输入互联网信息以进行查询和分类识别。
一种基于URL的互联网信息分类识别系统,所述基于URL的互联网信息分类识别系统包括:
搜集模块,用于从互联网抓取模式化的信息;
信息分类模块,用于基于关键字对抓取的信息进行人工分类处理以获得分类信息来建立分类信息库;
导入模块,用于向知识库中导入分类信息库中的分类信息;
分类识别模块,用于根据知识库中的分类信息结合URL结构对互联网信息的URL进行分层识别及分类;
输出模块,用于输出识别和分类的结果。
依照本发明的一个方面,所述分类识别模块包括:初步分类模块,用于根据知识库中的分类信息对互联网信息的URL进行初步分类;分层识别模块,用于基于URL结构对初步分类后的互联网信息进行进一步分层识别及分类。
依照本发明的一个方面,所述基于URL的互联网信息分类识别系统还包括:socket连接模块,用于通过socket连接的方式输入互联网信息以进行查询和分类识别。
本发明实施的优点:本发明所述的基于URL的互联网信息分类识别方法,通过从互联网抓取模式化的信息;基于关键字对抓取的信息进行人工分类处理以获得分类信息来建立分类信息库;向知识库中导入分类信息库中的分类信息;根据知识库中的分类信息结合URL结构对互联网信息的URL进行分层识别及分类;输出识别和分类的结果,通过机器识别和人工识别,准确率可以达到极高,同时因为不需要针对海量的文本内容进行文本分析或者图像识别,只是网址的分层识别, 服务响应能力可以无限提高,还把所有的知识库加载到内存中,分类引擎工作的时候,并不需要进行硬盘IO,完全是网络IO和内存访问,减少了对系统资源的消耗,基于分层的概念,可以做到同一个站点,既有相同内容,又有不同内容的分类,因为键值的简单,因此在分类查询的时候,就可以做到对系统资源的最小消耗。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明所述的一种基于URL的互联网信息分类识别方法示意图;
图2为本发明所述的一种基于URL的互联网信息分类识别系统结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,一种基于URL的互联网信息分类识别方法,所述基于URL的互联网信息分类识别方法包括以下步骤:
步骤S1:从互联网抓取模式化的信息;
所述步骤S1从互联网抓取模式化的信息的具体实施方式可为:通过网络爬虫技术等,从互联网中爬取用户搜索要求相关的模式化的信息。此时的信息是海量的网页信息,需要对海量的网页信息进行识别和分类,以提供给用户。
步骤S2:基于关键字对抓取的信息进行人工分类处理以获得分类信息来建立分类信息库;
所述步骤S2基于关键字对抓取的信息进行人工分类处理以获得分类信息来建立分类信息库的具体实施方式可为:基于关键字,例如新 闻、娱乐等,对抓取的互联网网页信息进行人工分类,分为新闻和娱乐等类,获得分类信息,从而建立分类信息库。
其中,在实际应用中,所述分类信息库中分类信息可包括明文分类信息和密文分类信息。
步骤S3:向知识库中导入分类信息库中的分类信息;
所述步骤S3向知识库中导入分类信息库中的分类信息的具体实施方式可为:导入分类信息库中的分类信息到知识库中进行存储,并将所有知识库加载到内存中。通过将知识库加载到内存中进行使用,只是单纯的网络访问和内存访问,无需访问硬盘,减少了资源的占用,服务器响应速度可以大幅提高。
步骤S4:根据知识库中的分类信息结合URL结构对互联网信息的URL进行分层识别及分类;
所述步骤S4根据知识库中的分类信息结合URL结构对互联网信息的URL进行分层识别及分类的具体实施方式可为:根据知识库中的分类信息对互联网信息的URL进行初步分类,基于URL结构对初步分类后的互联网信息进行进一步分层识别及分类。
在实际应用中,所述根据分类信息库对互联网信息的URL进行初步分类的具体可为:根据分类信息库中的关键字,对包含所述关键字的互联网信息的URL进行初步分类。例如,根据分类信息库中的关键字“新闻”,对互联网信息中有关新闻的互联网信息的URL进行了分类,比如将URL中含news的互联网信息分为一类。
在实际应用中,所述基于URL结构对初步分类后的互联网信息进行进一步分层识别及分类的具体实施方式可为:对初步分类后的互联网信息的URL结构进行分析,基于分层的概念,根据URL层次的不同将所述互联网信息进行进一步分类。基于分层的概念,可以做到同一个站点,既有相同内容,又有不同内容的分类。
在实际应用中,可进行如下分类方式来分类:
对于http://a.com/1/和http://a.com/1/index.jsp以及http://a.com/1/indes233.jsp作同类处理。
对于http://a.com/1/2/与http://a.com/1/做不同类处理。
对于http://a.com/1/和http://a.com/1/2以及
http://a.com/1/2和http://a.com/1/2/3/4都作不同类处理。
从而,因为键值的简单,因此在分类查询的时候,就可以做到对系统资源的最小消耗。
同时因为不需要针对海量的文本内容进行文本分析或者图像识别,只是网址的分层识别,服务响应能力可以无限提高。
步骤S5:输出识别和分类的结果。
在实际应用,可通过socket连接的方式输入互联网信息以进行查询和分类识别。
在实际应用中,由系统提供socket服务,基于自定义的查询协议,支持批量查询,可以一次性提交任意多个网址查询请求,因此整个系统的服务性能瓶颈,只在于客户使用的网络带宽。
本实施例所述的基于URL的互联网信息分类识别方法,通过从互联网抓取模式化的信息;基于关键字对抓取的信息进行人工分类处理以获得分类信息来建立分类信息库;向知识库中导入分类信息库中的分类信息;根据知识库中的分类信息结合URL结构对互联网信息的URL进行分层识别及分类;输出识别和分类的结果,通过机器识别和人工识别,准确率可以达到极高,同时因为不需要针对海量的文本内容进行文本分析或者图像识别,只是网址的分层识别,服务响应能力可以无限提高,还把所有的知识库加载到内存中,分类引擎工作的时候,并不需要进行硬盘IO,完全是网络IO和内存访问,减少了对系统资源的消耗,基于分层的概念,可以做到同一个站点,既有相同内容,又有不同内容的分类,因为键值的简单,因此在分类查询的时候,就可以做到对系统资源的最小消耗
一种基于URL的互联网信息分类识别系统实施例
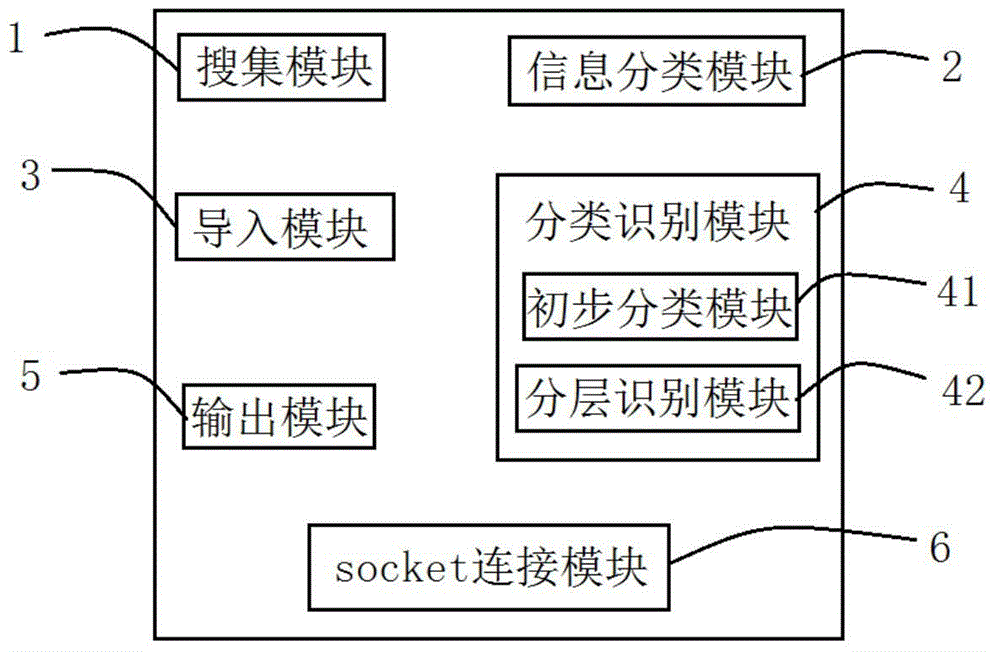
如图2所示,一种基于URL的互联网信息分类识别系统,所述基于URL的互联网信息分类识别系统包括:
搜集模块1,用于从互联网抓取模式化的信息;
信息分类模块2,用于基于关键字对抓取的信息进行人工分类处理以获得分类信息来建立分类信息库;
导入模块3,用于向知识库中导入分类信息库中的分类信息;
分类识别模块4,用于根据知识库中的分类信息结合URL结构对互 联网信息的URL进行分层识别及分类;
输出模块5,用于输出识别和分类的结果。
在实际应用中,所述分类识别模块4包括:初步分类模块41,用于根据知识库中的分类信息对互联网信息的URL进行初步分类;分层识别模块42,用于基于URL结构对初步分类后的互联网信息进行进一步分层识别及分类。
在实际应用中,所述基于URL的互联网信息分类识别系统还包括:socket连接模块6,用于通过socket连接的方式输入互联网信息以进行查询和分类识别。
本发明实施的优点:本发明所述的基于URL的互联网信息分类识别方法,通过从互联网抓取模式化的信息;基于关键字对抓取的信息进行人工分类处理以获得分类信息来建立分类信息库;向知识库中导入分类信息库中的分类信息;根据知识库中的分类信息结合URL结构对互联网信息的URL进行分层识别及分类;输出识别和分类的结果,通过机器识别和人工识别,准确率可以达到极高,同时因为不需要针对海量的文本内容进行文本分析或者图像识别,只是网址的分层识别,服务响应能力可以无限提高,还把所有的知识库加载到内存中,分类引擎工作的时候,并不需要进行硬盘IO,完全是网络IO和内存访问,减少了对系统资源的消耗,基于分层的概念,可以做到同一个站点,既有相同内容,又有不同内容的分类,因为键值的简单,因此在分类查询的时候,就可以做到对系统资源的最小消耗。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本领域技术的技术人员在本发明公开的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!