基于跨机房Hadoop集群的数据存储的方法及装置与流程
本发明涉及数据处理
技术领域:
,特别涉及一种基于跨机房Hadoop集群的数据存储的方法及装置。
背景技术:
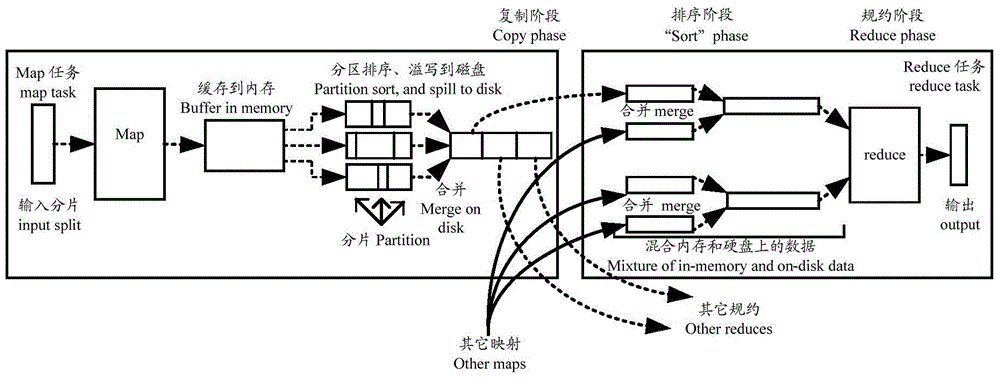
:大数据时代诞生的Hadoop开源软件,普遍应用于PB(PetaByte,10的15次方字节)级、超千台节点规模数据存储和计算系统,从2005年诞生至今,得到了互联网、电信、金融等行业的广泛应用。其吞吐率、可靠性、易用性等方面已经得到了工业界的普遍认可。其中,Hadoop核心包括2个部分:HDFS(HadoopDistributedFileSystem,Hadoop分布式文件系统)和MapReduce(mapreduce,映射归约)。现有技术中,HDFS将多台物理主机上的磁盘聚合成一个“虚拟的文件系统”,并对每一个数据块都自动部署3个物理副本,来保证数据高可靠和高效的计算调度。如图1所示,文件被写入HDFS时,其数据会在3台机器之间拷贝,例如写入1TB文件,则实际上有3TB流量在节点间传输。而MapReduce作为通用的并行计算框架,会将原始计算任务拆分成多个计算进程,运行在各台机器之上;MapReduce分为Map和Reduce两个阶段,中间数据的拷贝过程称为shuffle(洗牌),如图2所示,当对1TB数据进行计算时,shuffle阶段在网络上传输的数据可能高达1~3TB。因此,从上述描述可以看出,每次HDFS数据存储、以及每次MapReduce任务执行时会产生大量的数据在节点间传输,这容易对网络带宽造成巨大压力。目前,Hadoop在部署时,一般是几十个节点起步,通常集群规模的节点 数目为几百个至上千个。当集群规模超出单个机房容量时,就必须跨越两个或多个物理机房,甚至是跨地域的物理机房。而跨机房Hadoop集群中的分布式存储HDFS和MapReduce计算任务将带来巨大的节点间横向流量,由于机房之间交换机的带宽是有限的,因此网速和传输质量会大大降低,容易造成机房间交换机被拥塞,引发业务超时或数据不能被及时处理等问题,从而造成服务不可用的事故。综上所述,目前基于跨机房的Hadoop集群中数据在存储时产生的传输数据流量较大。技术实现要素:本发明实施例提供的一种基于跨机房Hadoop集群的数据存储的方法,用以解决现有技术中存在的基于跨机房的Hadoop集群中数据在存储时产生的传输数据流量较大的问题。第一方面,提供一种基于跨机房Hadoop集群的数据存储的方法,包括:在接收到需要写入的数据表后,确定用于计算所述数据表中数据的任务类型;根据确定的所述任务类型,将所述数据表中满足同一预设条件的数据存储到同一机房中或将所述数据表中全部数据存储到同一机房中。结合第一方面,在第一方面的第一种可能的实现方式中,根据下列方式确定用于计算所述数据表中数据的任务类型:将预先设置的任务类型作为用于计算所述数据表中数据的任务类型;或根据计算和流量模型确定用于计算所述数据表中数据的任务类型。结合第一方面的第一种可能的实现方式,在第一方面的第二种可能的实现方式中,根据计算和流量模型确定用于计算所述数据表中数据的任务类型,包括:在确定需要写入的数据表的原始数据量后,确定中间产生的传输的数据 量;根据原始数据量与中间产生传输的数据量的比值,通过计算和流量模型确定用于计算所述数据表中数据的任务类型。结合第一方面的第一种实现方式或第二种实现方式,在第一方面的第三种可能的实现方式中,若所述任务类型为单表汇聚计算类型或多表关联计算类型,则将所述数据表中满足同一预设条件的数据存储到同一机房中;结合第一方面的第一种实现方式或第二种实现方式,在第一方面的第四种可能的实现方式中,若所述任务类型为非单表汇聚计算类型和非多表关联计算类型,则将所述数据表中的全部数据存储到同一机房中。结合第一方面的第三种实现方式,在第一方面的第五种可能的实现方式中,将所述数据表中满足同一预设条件的数据存储到同一机房中,包括:针对所述数据表中当前需要存储的一条数据,从数据表对应的预设条件中,确定所述数据满足的预设条件,并将所述数据存储到确定的预设条件对应的机房中,其中一个预设条件对应一个机房;或针对所述数据表对应的一个预设条件,确定所述数据表中满足所述预设条件的每条数据,并将确定的每条数据,存储到所述预设条件对应的机房中,其中一个预设条件对应一个机房;或针对所述数据表对应的一个预设条件,从数据表对应的预设条件中,确定所述数据表中满足所述预设条件的每条数据,根据确定数据的存储容量和机房的平均使用率,从能够存储所述数据的机房中确定一个机房,并将确定的每条数据存储到确定的机房中。结合第一方面的第五种实现方式,在第一方面的第六种可能的实现方式中,若所述任务类型为多表关联计算类型,则多个数据表对应相同的至少一个预设条件。结合第一方面的第五种实现方式,在第一方面的第七种可能的实现方式中,若所述任务类型为单表汇聚计算类型,则每个数据表对应不同的预设条件。结合第一方面的第四种实现方式,在第一方面的第八种可能的实现方式中,将所述数据表中的全部数据存储到同一机房中,包括:确定平均存储使用率最低的机房,并将数据表中的全部数据存储到所述平均存储使用率最低的机房中。结合第一方面,在第一方面的第九种可能实现的方式中,将所述数据表中满足同一预设条件的数据存储到同一机房中或将所述数据表中全部数据存储到同一机房中之后,还包括:在接收到计算任务时,确定所述计算任务需要处理的数据;根据所述计算任务需要处理的数据,确定存储所述计算任务需要处理的数据的机房;若存储需要处理的数据的机房是多个,确定在每个机房中需要处理的数据满足的预设条件,根据需要处理的数据满足的预设条件,将所述计算任务划分为至少两个计算子任务,并将计算子任务分别发送到存储需要处理的数据的机房;若存储需要处理的数据的机房是一个,将计算任务直接发送到所述机房。第二方面,本发明实施例提供了一种基于跨机房Hadoop集群的数据存储的装置,包括:存储器,用于存储需要写入的数据表;处理器,用于在所述存储器接收到需要写入的数据表后,确定用于计算所述数据表中数据的任务类型;以及根据确定的所述任务类型,将所述数据表中满足同一预设条件的数据存储到同一机房中或将所述数据表中全部数据存储到同一机房中。结合第二方面,在第二方面的第一种可能的实现方式中,所述处理器根据下列方式确定用于计算所述数据表中数据的任务类型:将预先设置的任务类型作为用于计算所述数据表中数据的任务类型;或根据计算和流量模型确定用于计算所述数据表中数据的任务类型。结合第二方面的第一种可能的实现方式,在第二方面第二种可能的实现方式中,所述处理器,具体用于:在确定需要写入的数据表的原始数据量后,确 定中间产生的传输的数据量;根据原始数据量与中间产生传输的数据量的比值,通过计算和流量模型确定用于计算所述数据表中数据的任务类型。结合第二方面和第二方面的第一种可能的实现方式,在第二方面第三种可能的实现方式中,所述处理器,具体用于:若所述任务类型为单表汇聚计算类型或多表关联计算类型,将所述数据表中满足同一预设条件的数据存储到同一机房中。结合第二方面和第二方面的第一种可能的实现方式,在第二方面第四种可能的实现方式中,所述处理器,具体用于:若所述任务类型为非单表汇聚计算类型和非多表关联计算类型,将所述数据表中的全部数据存储到同一机房中。结合第二方面第三种可能的实现方式,在第二方面第五种可能的实现方式中,所述处理器,具体用于:针对所述数据表中当前需要存储的一条数据,从数据表对应的预设条件中,确定所述数据满足的预设条件,并将所述数据存储到确定的预设条件对应的机房中,其中一个预设条件对应一个机房;针对所述数据表对应的一个预设条件,确定所述数据表中满足所述预设条件的每条数据,并将确定的每条数据,存储到所述预设条件对应的机房中,其中一个预设条件对应一个机房;或针对所述数据表对应的一个预设条件,从数据表对应的预设条件中,确定所述数据表中满足所述预设条件的每条数据,根据确定数据的存储容量和机房的平均使用率,从能够存储所述数据的机房中确定一个机房,并将确定的每条数据存储到确定的机房中。结合第二方面第五种可能的实现方式,在第二方面第六种可能的实现方式中,若所述任务类型为多表关联计算类型,则多个数据表对应相同的至少一个预设条件。结合第二方面第五种可能的实现方式,在第二方面第六种可能的实现方式中,若所述任务类型为单表汇聚计算类型,则每个数据表对应不同的预设条件。结合第二方面第五种可能的实现方式,在第二方面第七种可能的实现方式中,若所述任务类型为单表汇聚计算类型,则每个数据表对应不同的预设条件。结合第二方面第四种可能的实现方式,在第二方面第八种可能的实现方式中,所述处理器,具体用于:确定平均存储使用率最低的机房,并将数据表中的全部数据存储到所述平均存储使用率最低的机房中。结合第二方面,在第二方面第九种可能的实现方式中,所述处理器还用于:将所述数据表中满足同一预设条件的数据存储到同一机房中或将所述数据表中全部数据存储到同一机房中之后,在接收到计算任务时,确定所述计算任务需要处理的数据;根据所述计算任务需要处理的数据,确定存储所述计算任务需要处理的数据的机房;若存储需要处理的数据的机房是多个,确定在每个机房中需要处理的数据满足的预设条件,根据需要处理的数据满足的预设条件,将所述计算任务划分为至少两个计算子任务,并将计算子任务分别发送到存储需要处理的数据的机房;若存储需要处理的数据的机房是一个,将计算任务直接发送到所述机房。本发明有益效果如下:本发明技术方案中由于能够在接收到写入的数据表后,确定该数据表的任务类型,并根据确定的任务类型,将数据表中满足同一预设条件的数据存储到同一机房中,或将数据表中的全部数据存储到同一机房中,使得同一数据不会存储在多个机房中,从而避免了在存储过程中产生的跨机房数据流量,另一方面,在执行计算任务时,由于所需数据都在同一机房中,从而避免的计算时产生的大量跨机房数据流量。附图说明图1为现有技术中HDFS写入流程及节点间流量传输模型;图2为现有技术中MapReduce节点间流量传输模型;图3为本发明实施例基于跨机房Hadoop集群的数据存储的方法流程示意 图;图4为本发明实施例跨机房调度系统整体示意图;图5为本发明实施例基于跨机房Hadoop集群的数据存储的方法流程示意图;图6为本发明实施例基于跨机房Hadoop集群的数据存储的装置的示意图;图7为本发明实施例基于跨机房Hadoop集群的数据存储的装置的硬件结构示意图。具体实施方式本发明实施例在接收到需要写入的数据表后,确定用于计算数据表中数据的任务类型;根据确定的任务类型,将数据表中满足同一预设条件的数据存储到同一机房中或将数据表中全部数据存储到同一机房中。这种技术方案由于能够在接收到写入的数据表后,确定该数据表的任务类型,并根据确定的任务类型,将数据表中满足同一预设条件的数据存储到同一机房中,或将数据表中的全部数据存储到同一机房中,使得同一数据不会存储在多个机房中,从而避免了在存储过程中产生的跨机房数据流量。下面结合说明书附图对本发明实施例作进一步详细描述。如图3所示,本发明实施例基于跨机房Hadoop集群的数据存储的方法,包括:步骤300,在接收到需要写入的数据表后,确定用于计算数据表中数据的任务类型。步骤301,根据确定的任务类型,将数据表中满足同一预设条件的数据存储到同一机房中或将数据表中全部数据存储到同一机房中。本发明实施例的执行主体可以为负责用于描述数据存储位置、历史数据、资源查找、文件记录等的中心服务器(又称名称节点)namenode,也可以为ETL(Extract-Transform-Load,数据仓库)。假设跨机房Hadoop集群中仅包括两个机房:A机房和B机房,本发明实施例基于跨机房Hadoop集群的数据存储的方法应用的系统架构如图4所示。其中,跨机房调度系统为执行本发明技术方案的模块,若执行主体为namenode,则将该模块配置在namenode中,若执行主体为ETL,则该模块配置在ETL中,此外,该模块还可单独配置在一个服务器或主机上。需要说明的是,本发明实施例可以应用于2G网络、3G网络、4G网络、固网等能够用于传输数据的网络中。本发明实施例中的数据表如表1所示,其中表1为C网上网流量话单。表1MSISDN流量时间地域业务类型1890923759715K20130101010101普陀微信1890923504010K20130203123325浦东QQ18923452343110K20130305110101黄埔微博1890923246135K20130315070809浦东微博1890923342544K20140518111215普陀微信以表1为例对数据表中数据进行说明,数据表中的一行或一条,如MSISDN:18909237597—流量:15K—时间:20130101010101—地域:普陀—业务类型:微信为一个数据。其中,本发明实施例的用于计算数据表中数据的任务类型包括:单表汇聚计算类型、多表关联计算类型或其他存在多个并发执行的计算任务的情况。具体来说,单表汇聚计算类型即为单个大数据集做Groupby汇聚计算类型,多表关联计算类型即为多表做关联Join计算的类型,其多表可以为两个表也可以为两个以上的表。在本发明实施例中,一种确定计算任务类型的方式为:将预先设置的任务类型作为用于计算数据表中数据的任务类型。例如,若预设任务类型为单表汇聚计算任务类型,则执行主体确定任务类 型为单表汇聚计算类型;若预设任务类型为多表关联计算任务类型,则执行主体确定任务类型为多表关联计算任务类型;若预设任务类型既不为单表汇聚计算任务类型也不为多表汇聚计算任务类型,则执行主体确定任务类型既不为单表汇聚计算任务类型也不为多表汇聚计算任务类型。为使的执行主体更加智能和主动,本发明实施例还提供了一种确定任务类型的方式:根据计算和流量模型确定用于计算数据表中数据的任务类型。举例来说,所述计算可为一计算任务,所述计算任务可包含SQL查询、数据挖掘以及互联网网页分析等等其中之一或其组合。其中,计算和流量模型为原始数据量与中间产生的跨节点传输的数据量的比值以及原始数据量与中间产生的跨节点传输的数据量的比值与计算类型的对应关系。具体来说,在确定需要写入的数据表的原始数据量后,确定中间产生的传输的数据量;根据原始数据量与中间产生传输的数据量的比值,通过计算和流量模型确定用于计算数据表中数据的任务类型。这是由于不同的计算任务类型对应的计算和流量模型是不同的,即一个计算任务类型对应一个计算和流量模型。例如,通过计算写入数据表的原始数据流量为2TB,中间产生的传输的数据量为0.2TB,则原始数据量与中间传输的数据量的比值为1:0.1,在计算和流量模型中1:0.1对应的计算类型为Grep计算类型,因此确定用于计算数据表中数据的任务类型为Grep计算类型。此外,由于在确定原始数据量与中间传输的数据量时可能会存在误差,导致确定的原始数据量与中间传输的数据量的比值会存在一定的误差,可根据实际情况的需要预先设置允许的误差范围,若在比值与计算与流量模型中的比值的误差在预先设置的误差范围内,则将通过计算与流量模型确定用于计算数据表中数据的任务类型。例如,确定的原始数据量与中间传输的数据量的比值1.01:1,若预先设置的误差范围为[-2.5%,2.5%],与计算和流量模型中的比值1:1误差为1%,在预先设置的误差范围[-2.5%,2.5%]内,而1:1对应的计算任务模型为wordcount,则将用于计算数据表中数据的任务类型确定为wordcount。由于其他任务类型的确定方式与上述方式类似,在此不再赘述。本发明实施例的技术方案在确定任务类型为单表汇聚计算类型或是多表关联计算类型后,将数据表中满足同一预设条件的数据存储到同一机房中;或是确定任务类型为非单表汇聚计算类型和非多表关联计算类型后,将数据表中的全部数据存储到同一机房中。需要说明的是,一个数据表对应多个预设条件,以表1为例进行说明。例如,表1对应预设条件地域为普陀或浦东和预设条件地域为黄埔,其中,预设条件地域为普陀或浦东对应的机房为A机房,预设条件地域为黄埔对应的机房为B机房;或预设条件地域为黄埔对应的机房为A机房,预设条件地域为普陀或浦东对应的机房为B机房;或,表1对应预设条件MSISDN中号码开头的前7位为“1890923”和预设条件MSISDN中号码开头的前7位为“1892345”,其中,预设条件MSISDN中号码开头的前7位为“1890923”对应的机房为A机房;预设条件MSISDN中号码开头的前7位为“1892345”对应的机房为B机房或预设条件MSISDN中号码开头的前7位为“1892345”对应的机房为A机房,预设条件MSISDN中号码开头的前7位为“1890923”对应的机房为B机房。其中,预设条件不仅限于上述举例中预设条件的设定方式,还可以用户根据实际情况的需要预先进行设定。为使得本发明实施例中的技术方案更容易实现,本发明实施例还提供了三种将满足同一预设条件的数据存储到同一机房中的方式:方式一:针对所述数据表中当前需要存储的一条数据,从数据表对应的预设条件中,确定所述数据满足的预设条件,并将所述数据存储到确定的预设条 件对应的机房中,其中一个预设条件对应一个机房;以表1为例进行说明,若预设条件业务类型为微信或QQ时对应的机房为A机房,若预设条件业务类型为微博时对应的机房为B机房,其中,若数据存储到A机房,其该数据的备份也存储到A机房,从而减少了数据在存储时跨机房的传输流量。具体的存储过程为:若当前要存储的数据为MSISDN:18909237597—流量:15K—时间:20130101010101—地域:普陀—业务类型:微信,该数据满足预设条件业务类型为微信或QQ,则将该数据存储到A机房,在将该数据存储到A机房完成后,当前要存储的数据变为MSISDN:18909235040—流量:10K—时间:20130203123325—地域:浦东—业务类型:QQ,该数据满足预设条件业务类型为微信或QQ,则将该数据存储到A机房,其他数据按相同的方式依次存储到预设条件对应的机房中,直到将数据表中的全部数据存储到机房中为止。其存储结果如表2和表3所示,表2中A机房存储的数据,表3中为B机房存储的数据。表2MSISDN流量时间地域业务类型1890923759715K20130101010101普陀微信1890923504010K20130203123325浦东QQ1890923342544K20140518111215普陀微信表3MSISDN流量时间地域业务类型18923452343110K20130305110101黄埔微博1890923246135K20130315070809浦东微博方式二:针对数据表对应的一个预设条件,确定数据表中满足预设条件的 每条数据,并将确定的每条数据,存储到预设条件对应的机房中,其中一个预设条件对应一个机房。以表1为例进行说明,若预设条件为流量不大于35K不小于5K时对应的机房为A机房,若预设条件为流量大于35K时对应的机房为B机房,其具体的存储过程为:从表1中确定满足流量不大于35K不小于5K时的数据,包括:MSISDN:18909237597—流量:15K—时间:20130101010101—地域:普陀—业务类型:微信、MSISDN:18909235040—流量:10K—时间:20130203123325—地域:浦东—业务类型:QQ、MSISDN:18909232461—流量:35K—时间:20130315070809—地域:浦东—业务类型:微博,将其这三个数据存储到A机房中,由于表1中的另两个数据满足预设条件流量大于35K,则将这两个数据存储到B机房中。方式三:针对数据表对应的一个预设条件,从数据表对应的预设条件中,确定数据表中满足预设条件的每条数据,根据确定数据的存储容量和机房的平均使用率,从能够存储数据的机房中确定一个机房,并将确定的每条数据存储到确定的机房中。以表1为例进行说明,假定Hadoop集群中部署了两个机房A和B,且预设条件是MSISDN中号码开头的前7位为“1890923”和MSISDN中号码开头的前7位为“1892345”,则具体的存储过程为:监测每个机房的平均存储使用率,确定在接收到写入数据表后,每个机房的平均使用率的大小,如A机房的平均使用率大于B机房,一种可选的方式是,确定所有的预设条件对应的机房为B机房,则将数据表中的数据全部存储到B机房中,第二种可选的方式是确定数据表中满足MSISDN中号码开头的前7位为“1890923”的所有数据的存储容量1,以及确定数据表中满足MSISDN中号码开头的前7位为“1892345”的所有数据的存储容量2,若存储容量1大于存储容量2,则确定预设条件为MSISDN中号码开头的前7位为“1890923”对应的机房为B机房,预设条件为MSISDN中号码开头的前7位为“1892345”对应的机房为A机房,并将数 据分别存储到预设条件对应的机房中,即将存储容量大的数据存储到平均存储使用率较小的机房中。其中,当任务类型为多表关联计算类型时,多个数据表对应相同的至少一个预设条件。需要说明的是,多表可以为两表或两个以上的表,以表1和表4为例进行说明,其中,表4为IPTV为点播时长话单。表4MSISDN点播时长时间地域1890923759730min20130101010101普陀1890923504060min20130203123325浦东1892345234345min20130305110101黄埔1890923246133min20130315070809浦东1890923342578min20140518111215普陀若表1中,预设条件是业务类型为MSISDN中号码开头的前7位为“1890923”,以及MSISDN中号码开头的前7位为“1892345”,若为任务类型为多表关联计算,则表2的预设条件为MSISDN中号码开头的前7位为“1890923”,以及预设条件为MSISDN中号码开头的前7位为“1892345”,即表1和表2对应的预设条件为相同的预设条件,且相同的预设条件对应的相同的机房,如表1中的预设条件业务类型为MSISDN中号码开头的前7位为“1890923”对应的机房为A机房,则表2中的预设条件业务类型为MSISDN中号码开头的前7位为“1890923”对应的机房也为A机房,由于这样的设置方式能够在运行多表关联计算时,在同一机房中找到所需的所有数据,这种数据调度的策略为对等分区调度。其中,存储结果如表5、表6、表7、表8所示,表5和表7为A机房中存储的数据,表6和表8为B机房中存储的数据。表5MSISDN流量时间地域业务类型1890923759715K20130101010101普陀微信1890923504010K20130203123325浦东QQ1890923246135K20130315070809浦东微博1890923342544K20140518111215普陀微信表6MSISDN流量时间地域业务类型18923452343110K20130305110101黄埔微博表7MSISDN点播时长时间地域1890923759730min20130101010101普陀1890923504060min20130203123325浦东1890923246133min20130315070809浦东1890923342578min20140518111215普陀表8MSISDN点播时长时间地域1892345234345min20130305110101黄埔当为单表汇聚计算时对应的调度策略为分区调度,每个数据表可以对应不同的预设条件,也可以对应相同的预设条件。以表1和表4为例进行具体说明,若表1和表4的任务类型都为单表汇聚计算,例如表1的预设条件为业务类型为MSISDN中号码开头的前7位为“1890923”,以及预设条件为MSISDN中号码开头的前7位为“1892345”;表4的预设条件可以为业务类型为MSISDN中号码开头的前7位为“1890923”,以及预设条件为MSISDN中号码开头的前7位为“1892345”,也可以为预设条件为流量不大于35K不小于5K,预设条件为流量大于35K,当表1和表4的 预设条件相同时,若表1中预设条件为业务类型为MSISDN中号码开头的前7位为“1890923”对应的机房为A机房,则表4中预设条件为业务类型为MSISDN中号码开头的前7位为“1890923”对应的机房可为A机房,也可以为B机房,也可以根据机房的平均存储使用率进行确定。为使得本发明实施例中的技术方案更容易实现,本发明实施例还提供了一种将全部数据存储到同一机房中的方式:确定平均存储使用率最低的机房,并将数据表中的全部数据存储到平均存储使用率最低的机房中。具体来说,当确定任务类型为非单表汇聚计算非多表关联计算时,其对应的策略为容量负载均衡调度,其具体实现过程为:监测所有机房的平均使用率,在接收到写入数据表时,确定用于计算该数据表中数据的任务类型为为非单表汇聚计算非多表关联计算时,确定平均存储使用率最低的机房,如平均存储使用率最低的机房为A机房,则并将数据表中的全部数据存储到A机房中。本发明实施例在将数据表中的数据进行存储之后,还提供了一种确定每个机房的计算任务的方法,包括:在接收到计算任务时,确定计算任务需要处理的数据;根据计算任务需要处理的数据,确定存储计算任务需要处理的数据的机房;若存储需要处理的数据的机房是多个,确定在每个机房中需要处理的数据满足的预设条件,根据需要处理的数据满足的预设条件,将计算任务划分为至少两个计算子任务,并将计算子任务分别发送到存储需要处理的数据的机房;若存储需要处理的数据的机房是一个,将计算任务直接发送到机房。需要说明的是,计算任务指的是MapReduce任务。以计算任务为多表关联(Join)计算任务、数据表为表1和表4为例进行说明,若表1和表4的预设条件为业务类型为MSISDN中号码开头的前7位为“1890923”对应的机房为A机房,预设条件为MSISDN中号码开头的前7位 为“1892345”对应的机房为B机房,其具体确定每个机房的计算任务的方式为:在接收到多表关联计算任务时,确定计算任务需要处理的数据所在的机房为A机房和B机房。将计算任务中业务类型为MSISDN中号码开头的前7位为“1890923”的任务作为计算子任务1发送到A机房,将计算任务中业务类型为MSISDN中号码开头的前7位为“1892345”的任务作为计算子任务2发送到B房。当计算任务为非单表汇聚计算非多表关联(Join)计算任务,若计算任务需要处理的数据全部存储在A机房,则直接将计算任务发送到A机房。通过本发明实施例的数据存储和计算方式,大大降低了机房间的数据流量。以多表关联计算任务为例进行说明,按照本发明技术方案的数据存储方式,计算平均每小时需要跨机房传输的数据吞吐率,其中多表为一个为大表,一个为小表。假定每天产生的全网话单总量是2.4TB,并假定需要做“大表小表关联计算”的机房间的数据量比例为10%,需要说明的是,当计算任务为其它任务类型时,不会产生机房间的数据流量。第一种情况:假定每天产生的总话单数据量在每小时时段是均匀分布的,则计算得到平均每小时需要跨机房传输的数据吞吐率为85秒,如表9所示:表9描述值备注需关联计算的数据量比例10%估计值每天产生的源数据总量(TB)2.4用户输入平均每小时产生的源数据总量(GB)1002.4TB/24小时=100GB平均每小时需跨机房复制的数据总量(GB)10100*10%机房间城域网带宽(Gbps)1GE网络,120MB/s平均每小时跨机房数据传输耗时(s)8510*1024/120=85s第二种情况,假定每天产生的话单量分布很不均匀(即,某一个小时时段里产生了全天的话单量),则计算得到峰值每小时跨机房数据传输耗时34分钟,如表10所示:表10描述值备注需关联计算的数据量比例10%估计值每天产生的源数据总量(TB)2.4用户输入平均每小时产生的源数据总量(GB)2.4平均每小时需跨机房复制的数据总量(GB)2402.4TB*10%机房间城域网带宽(Gbps)1GE网络,120MB/s平均每小时跨机房数据传输耗时(min)34240*1024/120=2048s=34min综合以上两种情况的分析,对于多表关联计算任务中“大表小表关联计算”的场景,无论是最理想情况(平均分布)或最差情况(峰值出现在某个小时时段),需要跨机房传输的数据量都能在1个小时内完成传输,机房间GE带宽的交换机都不会成为造成数据传输的瓶颈,不仅解决了现有技术中基于跨机房的Hadoop集群中数据在存储时产生的传输数据流量较大,而且解决了在计算时传输数据流量较大的问题,以及减小了由跨机房间的传输流量较大对交换机的冲击,降低了业务宕机的机率。如图5所示,本发明实施例基于跨机房Hadoop集群的数据存储的方法,包括:步骤500,监测Hadoop集群中各个机房的平均存储使用率。步骤501,在接收到需要写入的数据表后,确定计算数据表中数据的任务类型。步骤502,若确定任务类型为单表汇聚计算类型或多表关联计算类型,则将数据表中满足同一预设条件的数据存储到同一机房中;若确定任务非单表汇聚计算类型和非多表关联计算类型,确定平均存储使用率最低的机房,将数据 表中的全部数据存储到该平均存储使用率最低的机房中。其中,若确定任务类型为单表汇聚计算类型或多表关联计算类型,将数据表中满足同一预设条件的数据存储到同一机房中的方式有三种:方式一:针对数据表中当前需要存储的一条数据,从数据表对应的预设条件中,确定数据满足的预设条件,并将数据存储到确定的预设条件对应的机房中,其中一个预设条件对应一个机房;方式二:针对数据表对应的一个预设条件,确定数据表中满足预设条件的每条数据,并将确定的每条数据,存储到预设条件对应的机房中,其中一个预设条件对应一个机房;方式三:针对数据表对应的一个预设条件,从数据表对应的预设条件中,确定数据表中满足预设条件的每条数据,根据确定数据的存储容量和机房的平均使用率,从能够存储数据的机房中确定一个机房,并将确定的每条数据存储到确定的机房中。步骤503,在接收到计算任务时,确定该计算任务需要处理的数据。步骤504,根据该计算任务需要处理的数据,确定存储该计算任务需要处理的数据的机房。步骤505,若存储需要处理的数据的机房是多个,确定在每个机房中需要处理的数据满足的预设条件,根据需要处理的数据满足的预设条件,将计算任务划分为至少两个计算子任务,并将计算子任务分别发送到存储需要处理的数据的机房;若存储需要处理的数据的机房是一个,将计算任务直接发送到机房。基于同一发明构思,本发明实施例中还提供了一种基于跨机房Hadoop集群的数据存储的装置,由于图6的基于跨机房Hadoop集群的数据存储的装置对应的方法为本发明实施例基于跨机房Hadoop集群的数据存储的方法,因此本发明实施例基于跨机房Hadoop集群的数据存储的装置的实施可以参见该方法的实施,重复之处不再赘述。如图6所示,本发明实施例基于跨机房Hadoop集群的数据存储的装置, 包括:存储器600,用于存储需要写入的数据表;处理器601,用于在存储器600接收到需要写入的数据表后,确定用于计算数据表中数据的任务类型;以及根据确定的任务类型,将数据表中满足同一预设条件的数据存储到同一机房中或将数据表中全部数据存储到同一机房中。可选的,处理器601根据下列方式确定用于计算数据表中数据的任务类型:将预先设置的任务类型作为用于计算数据表中数据的任务类型;或根据计算和流量模型确定用于计算数据表中数据的任务类型。可选的,处理器601,具体用于:在确定需要写入的数据表的原始数据量后,确定中间产生的传输的数据量;根据原始数据量与中间产生传输的数据量的比值,通过计算和流量模型确定用于计算数据表中数据的任务类型。可选的,处理器601,具体用于:若任务类型为单表汇聚计算类型或多表关联计算类型,将数据表中满足同一预设条件的数据存储到同一机房中。可选的,处理器601,具体用于:若任务类型为非单表汇聚计算类型和非多表关联计算类型,将数据表中的全部数据存储到同一机房中。可选的,处理器601,具体用于:针对数据表中当前需要存储的一条数据,从数据表对应的预设条件中,确定数据满足的预设条件,并将数据存储到确定的预设条件对应的机房中,其中一个预设条件对应一个机房;针对数据表对应的一个预设条件,确定数据表中满足预设条件的每条数据,并将确定的每条数据,存储到预设条件对应的机房中,其中一个预设条件对应一个机房;或针对数据表对应的一个预设条件,从数据表对应的预设条件中,确定数据 表中满足预设条件的每条数据,根据确定数据的存储容量和机房的平均使用率,从能够存储数据的机房中确定一个机房,并将确定的每条数据存储到确定的机房中。可选的,若任务类型为多表关联计算类型,则多个数据表对应相同的至少一个预设条件。可选的,若任务类型为单表汇聚计算类型,则每个数据表对应不同的预设条件。可选的,处理器601,具体用于:确定平均存储使用率最低的机房,并将数据表中的全部数据存储到平均存储使用率最低的机房中。可选的,处理器601还用于:将数据表中满足同一预设条件的数据存储到同一机房中或将数据表中全部数据存储到同一机房中之后,在接收到计算任务时,确定计算任务需要处理的数据;根据计算任务需要处理的数据,确定存储计算任务需要处理的数据的机房;若存储需要处理的数据的机房是多个,确定在每个机房中需要处理的数据满足的预设条件,根据需要处理的数据满足的预设条件,将计算任务划分为至少两个计算子任务,并将计算子任务分别发送到存储需要处理的数据的机房;若存储需要处理的数据的机房是一个,将计算任务直接发送到机房。图7是依据本发明一实施例的基于跨机房Hadoop集群的数据存储的装置7的硬件结构示意图。如图7所示,装置7包括处理器71、存储器72、输入/输出接口73、通信接口74和总线75。其中,处理器71、存储器72、输入/输出接口73和通信接口74通过总线75实现彼此之间的通信连接。处理器71可以采用通用的中央处理器(CentralProcessingUnit,CPU),微处理器,应用专用集成电路(ApplicationSpecificIntegratedCircuit,ASIC),或者一个或多个集成电路,用于执行相关程序,以实现本发明实施例所提供的技术方案。存储器72可以是只读存储器(ReadOnlyMemory,ROM),静态存储设备,动态存储设备或者随机存取存储器(RandomAccessMemory,RAM)。存储器72可以存储操作系统和其他应用程序。在通过软件或者固件来实现本发明实施例提供的技术方案时,用于实现本发明实施例提供的技术方案的程序代码保存在存储器72中,并由处理器71来执行。输入/输出接口73用于接收输入的数据和信息,输出操作结果等数据。总线75可包括一通路,在装置7各个部件(例如处理器71、存储器72、输入/输出接口73和通信接口74)之间传送信息。应注意,尽管图7所示的装置7仅仅示出了处理器71、存储器72、输入/输出接口73、通信接口74以及总线75,但是在具体实现过程中,本领域的技术人员应当明白,装置7还包含实现正常运行所必须的其他器件。同时,根据具体需要,本领域的技术人员应当明白,装置7还可包含实现其他附加功能的硬件器件。此外,本领域的技术人员应当明白,装置7也可仅仅包含实现本发明实施例所必须的器件或模块,而不必包含图7中所示的全部器件。本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,上述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,上述的存储介质可为磁盘、光盘、只读存储记忆体(ROM:Read-OnlyMemory)或随机存储记忆体(RAM:RandomAccessMemory)等。从上述内容可以看出:本发明实施例在接收到需要写入的数据表后,确定用于计算数据表中数据的任务类型;根据确定的任务类型,将数据表中满足同一预设条件的数据存储到同一机房中或将数据表中全部数据存储到同一机房中。这种技术方案由于能够在接收到写入的数据表后,确定该数据表的任务类型,并根据确定的任务类型,将数据表中满足同一预设条件的数据存储到同一机房中,或将数据表中的全部数据存储到同一机房中,使得同一数据不会存储在多个机房中,从而避免了在存储过程中产生的跨机房数据流量。本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1