一种基于hadoop集群的数据迁移方法和工具与流程
本发明涉及计算机网络技术领域,特别地涉及一种基于hadoop集群的数据迁移方法和工具。
背景技术:
在建设数据平台的过程中,随着业务的增长,集群规模的扩大,以及软硬件环境的升级,不可避免的会遇到如集群数据迁移,合并等工作,因此,为保证数据迁移的高效性以及数据的完整性、准确性,开发一套基于hadoop环境的数据迁移方法和工具是具有重要意义的。
现有的数据迁移形式主要有以下两种:
1)、基于hadoop本身提供的数据同步命令,逐各目录手动进行拷贝迁移;
2)、使用其它编程语言,如java,python等基于hadoop API开发一套单独的数据读写同步工具。
但是以上两种数据迁移方法都存在一定的缺陷,下面分别说明:
1)、基于hadoop本身提供的数据同步命令,逐各目录手动进行拷贝迁移的方式适用于小数据量目录的临时同步操作,不适用于大数据量的一次性同步操作,缺少对同步过程进度及数据准确性的监控;
2)、使用其他编程语言的方式编程较复杂,开发成本较高,同时也需要同步开发相应的监控管理功能。
技术实现要素:
有鉴于此,本发明提供一种基于hadoop集群的数据迁移方法和工具,利用Web service自动计算比对差异并分发任务,能够实现数据同 步的工具化,提高数据同步操作的便捷性,方便监控管理数据同步过程,并且保证数据同步的准确性,高效性。同时,使用本发明的方法和工具,成本较低。
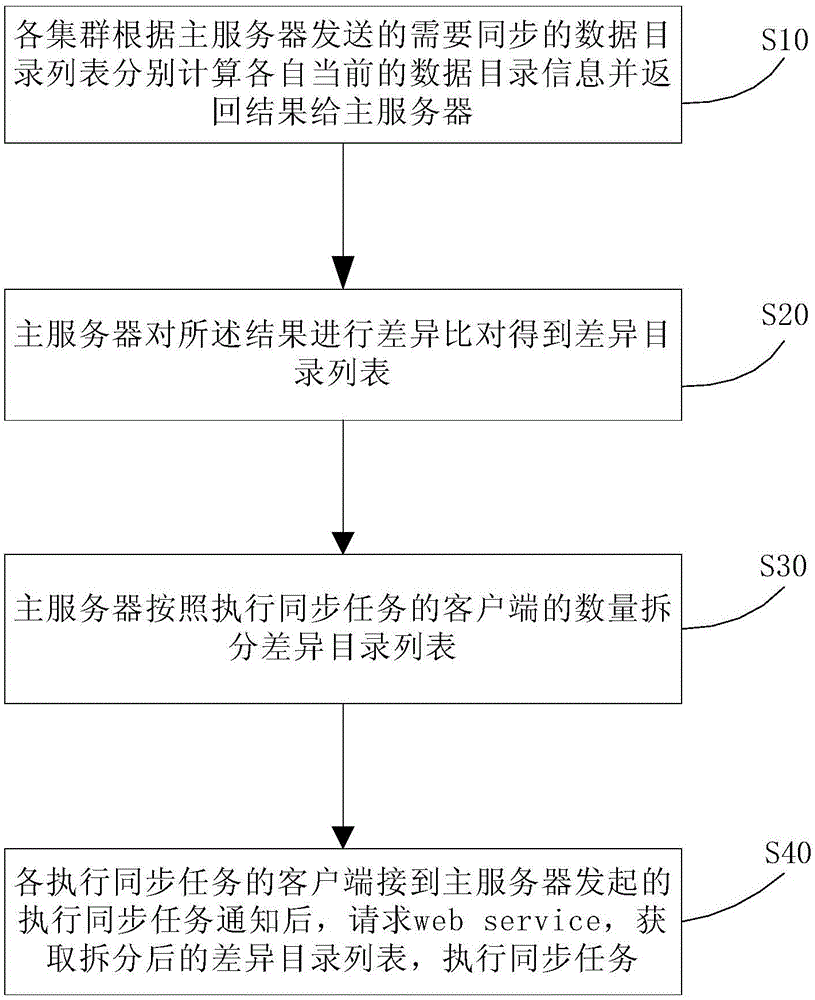
为实现上述目的,根据本发明的一个方面,提供了一种基于hadoop集群的数据迁移方法,包括:各集群根据主服务器发送的需要同步的数据目录列表分别计算各自当前的数据目录信息并返回结果给主服务器;主服务器对所述结果进行差异比对得到差异目录列表;主服务器按照执行同步任务的客户端的数量拆分差异目录列表;各执行同步任务的客户端接到主服务器发起的执行同步任务通知后,请求web service,获取拆分后的差异目录列表,执行同步任务。
可选地,各集群根据主服务器发送的需要同步的数据目录列表分别计算各自当前的数据目录信息并返回结果给主服务器包括:主服务器从hive元数据库中获取需要同步的数据目录列表;主服务器将所述数据目录列表分发到不同集群;各集群根据接收到的数据目录列表分别计算各自当前的数据目录信息并返回结果给主服务器。
可选地,各执行同步任务的客户端接到执行同步任务通知后,请求web service,获取拆分后的差异目录列表,执行同步任务之后,所述方法还包括:各执行同步任务的客户端将日志写入主服务器;主服务器根据汇总的日志情况进行解析计算,发送数据同步信息给用户。
可选地,该方法支持单个主服务器发起,多个客户端同时运行同步任务的功能。
可选地,各执行同步任务的客户端均支持多线程并发提交同步任务的功能。
可选地,主服务器以邮件形式发送数据同步信息给用户。
可选地,所述数据同步信息包括数据同步进度,数据同步速度以及数据同步失败列表。
根据本发明的另一个方面,提供了一种基于hadoop集群的数据迁移工具,包括:计算模块,设置于各集群中,用于根据主服务器发送的需要同步的数据目录列表分别计算各自当前的数据目录信息并返回结果给主服务器;差异比对模块,设置于主服务器中,用于对所述结果进行差异比对得到差异目录列表;拆分模块,设置于主服务器中,用于按照执行同步任务的客户端的数量拆分差异目录列表;数据同步模块,设置于各执行同步任务的客户端中,用于接到主服务器发起的执行同步任务通知后,请求web service,获取拆分后的差异目录列表,执行同步任务。
可选地,所述计算模块还用于:主服务器从hive元数据库中获取需要同步的数据目录列表;主服务器将所述数据目录列表分发到不同集群;各集群根据接收到的数据目录列表分别计算各自当前的数据目录信息并返回结果给主服务器。
可选地,所述数据同步模块还用于:各执行同步任务的客户端将日志写入主服务器;主服务器根据汇总的日志情况进行解析计算,发送数据同步信息给用户。
可选地,该工具支持单个主服务器发起,多个客户端同时运行同步任务的功能。
可选地,各执行同步任务的客户端均支持多线程并发提交同步任务的功能。
可选地,主服务器以邮件形式发送数据同步信息给用户。
可选地,所述数据同步信息包括数据同步进度,数据同步速度以及数据同步失败列表。
根据本发明的技术方案,基于hadoop自身提供的同步命令,在其基础上进行开发封装,包括数据差异比对,多线程并发同步,同步结果校验,同步进度跟踪,过程监控;在主服务器启用web service用于在多个客户端间的数据传输交互。本发明还具有以下有益效果:
1)、方便操作,部署过程简单,减少数据同步过程中的人工干预;
2)、易于管理,程序启动后会自动发送进度及监控邮件,能够快速掌握数据同步情况;
3)、高效同步,程序自动处理多个客户端并发执行多个任务,充分利用集群资源和带宽资源;
4)、灵活配置,可设置需要同步的数据目录列表,可灵活配置客户端数量,并发任务数,资源占用量,邮件通知规则等。
附图说明
附图用于更好地理解本发明,不构成对本发明的不当限定。其中:
图1是根据本发明提供的一种基于hadoop集群的数据迁移方法的架构图;
图2是根据本发明提供的一种基于hadoop集群的数据迁移方法的主要步骤的示意图;
图3是根据本发明提供的一种基于hadoop集群的数据迁移工具的主要模块的示意图。
具体实施方式
以下结合附图对本发明的示范性实施例做出说明,其中包括本发明实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本发明的范围和精神。同样,为了清 楚和简明,以下的描述中省略了对公知功能和结构的描述。
图1是根据本发明提供的一种基于hadoop集群的数据迁移方法的架构图的示意图;图2是根据本发明提供的一种基于hadoop集群的数据迁移方法的主要步骤的示意图;如图1-2所示,该方法主要包括如下步骤:
步骤S10:各集群根据主服务器发送的需要同步的数据目录列表分别计算各自当前的数据目录信息并返回结果给主服务器。该步骤具体包括:主服务器从hive元数据库中获取需要同步的数据目录列表;主服务器将所述数据目录列表分发到不同集群;各集群根据接收到的数据目录列表分别计算各自当前的数据目录信息并返回结果给主服务器。其中,所述集群可以为两个,其分别为数据源集群和目标集群。所述数据目录信息为hdfs数据目录信息。
步骤S20:主服务器对所述结果进行差异比对得到差异目录列表。
步骤S30:主服务器按照执行同步任务的客户端的数量拆分差异目录列表。根据实际需求,可以灵活配置客户端的数量。
步骤S40:各执行同步任务的客户端接到主服务器发起的执行同步任务通知后,请求web service,获取拆分后的差异目录列表,执行同步任务。该方法支持单个主服务器发起,多个客户端同时运行同步任务的功能,同时各执行同步任务的客户端均支持多线程并发提交同步任务的功能。
另外在步骤S40之后,各执行同步任务的客户端将日志写入主服务器;主服务器根据汇总的日志情况进行解析计算,发送数据同步信息给用户。主服务器可以定时以邮件形式发送数据同步信息给用户。所述数据同步信息包括数据同步进度,数据同步速度以及数据同步失败列表。除此之外,主服务器还可以发送其他数据同步信息给用户。
本发明提供的一种基于hadoop集群的数据迁移方法,基于hadoop自身提供的同步命令,在其基础上进行开发封装,包括数据差异比对,多线程并发同步,同步结果校验,同步进度跟踪,过程监控。
图3是根据本发明实施例的一种基于hadoop集群的数据迁移工具的主要模块的示意图。如图3所示,该工具3主要包括计算模块31、差异比对模块32、拆分模块33以及数据同步模块34。
计算模块31,设置于各集群中,用于根据主服务器发送的需要同步的数据目录列表分别计算各自当前的数据目录信息并返回结果给主服务器。所述集群可以为两个,其分别为数据源集群和目标集群。所述数据目录信息为hdfs数据目录信息。所述计算模块还用于:主服务器从hive元数据库中获取需要同步的数据目录列表;主服务器将所述数据目录列表分发到不同集群;各集群根据接收到的数据目录列表分别计算各自当前的数据目录信息并返回结果给主服务器。
差异比对模块32,设置于主服务器中,用于对所述结果进行差异比对得到差异目录列表。
拆分模块33,设置于主服务器中,用于按照执行同步任务的客户端的数量拆分差异目录列表。根据实际需求,可以灵活配置客户端的数量。
数据同步模块34,设置于各执行同步任务的客户端中,用于接到主服务器发起的执行同步任务通知后,请求web service,获取拆分后的差异目录列表,执行同步任务。该工具支持单个主服务器发起,多个客户端同时运行同步任务的功能,同时各执行同步任务的客户端均支持多线程并发提交同步任务的功能。所述数据同步模块还用于:各执行同步任务的客户端将日志写入主服务器;主服务器根据汇总的日 志情况进行解析计算,发送数据同步信息给用户。主服务器可以定时以邮件形式发送数据同步信息给用户。所述数据同步信息包括数据同步进度,数据同步速度以及数据同步失败列表。除此之外,主服务器还可以发送其他数据同步信息给用户。
本发明提供的一种基于hadoop集群的数据迁移工具,基于hadoop自身提供的同步命令,在其基础上进行开发封装,包括数据差异比对,多线程并发同步,同步结果校验,同步进度跟踪,过程监控。
本发明提供的一种基于hadoop集群的数据迁移方法和工具,Hadoop是指:Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hive:hive是基于Hadoop的一个数据仓库工具,提供类sql的查询语言。主服务器:服务发起端机器,包括web service启动,同步任务发起,邮件服务等。客户端:具体执行同步任务端机器。
上述具体实施方式,并不构成对本发明保护范围的限制。本领域技术人员应该明白的是,取决于设计要求和其他因素,可以发生各种各样的修改、组合、子组合和替代。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!