一种网页内容识别方法和系统与流程
本发明涉及互联网技术领域,特别涉及一种网页内容识别方法和系统。
背景技术:
随着网络的迅速发展,互联网成为大量信息的载体,文字、图片、数据库、音频、视频多媒体等不同类型数据大量出现于网络,再加以各式各样的网页设计,人类进入了信息爆炸的时代。截至2014年12月,仅中国的网页数量达到1899亿个,年增长26.6%。随着个人博客、自媒体的发展,以及互联网媒体的快速发展,互联网页的数量将会以几何级速的增长。
当人们用搜索互联网页时,经常会发现搜索结果中包含了大量内容重复的网页,这些网页不仅大大加重了用户检索和阅读的负担,降低了搜索效率,而且浪费了大量的存储资源,同时也影响了准确率。因此,把这些内容重复的网页去掉是一项具有实际意义的工作。
优化搜索结果可以采用多种手段,如通过提取网页的特征进行基于内容的信息检索,利用用户反馈的信息进一步精确检索结果,将结果集中的重复信息尽可能地消除等。为此,一些传统的通用搜索引擎,如AltaVista,Yahoo和Google等,应运而生,作为一个辅助人们检索信息的工具成为用户访问互联网网的工具。但是,这些通用性搜索引擎也存在着一定的局限性:
1、不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。
2、通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
3、互联网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、 视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。
4、通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
为此,网页去重技术越来越显得重要。常用的网页去重代表技术包括:
目前,网页去重代表性方法有3种.
1、基于聚类的方法。该方法是基于网页文本内容以6763个汉字作为向量的基,文本中某组或某个汉字所出现的频率就构成了代表网页的向量,通过计算向量的夹角确定是否是相同的网页。
2)排除相同URL方法。各种元搜索引擎去重主要采用此方法,它分析来自不同搜索引擎的网页URL,URL相同即被认为是相同的网页,可将其去除。
3、基于特征码的方法。这种方法利用标点符号多数出现在网页文本的特点,以句号两边各5个汉字作为特征码来唯一地表示网页。
上述方法都具有实现算法复杂,运算量大,占用资源大的缺点。
技术实现要素:
本发明提供一种网页内容识别方法和系统,简化了网页识别的运算量,算法相对简单,进一步的降低了系统资源的占用,对于提高搜索时间、减小系统资源占用具有积极的意义。
本发明的技术方案提供了一种网页内容识别方法,包括以下步骤:
网络爬虫从互联网抓取网页;
所述新抓取的网页和网页数据库中存储的网页进行比较;
有效页面存储于网页数据库。
进一步的,所述网络爬虫在互联网抓取网络页面,进一步包括;
网络爬虫自动抓取互联网网页的内容,包括但不限于网页结构、网页标签、程序或者脚本信息。
进一步的,所述网页结构根据下述信息生成:包括但不限于网页标题,网 页正文内容,图片、声音或视频信息。
进一步的,所述新抓取的网页与网页数据库中网页的网页结构比较结果不一致,则判断为有效页面。
进一步的,所述新抓取的网页与网页数据库中网页的网页结构比较结果一致,则比较网页特征码,比较结果不一致,则判断为有效页面。
进一步的,所述特征码通过采集下述信息生成:包括但不限于网页的标签数量,标签中文字长度。
进一步的,所述新抓取的网页与网页数据库中网页的标签内容比较结果一致,则判断为无效页面。
进一步的,所述新抓取的网页与网页数据库中网页的标签内容的比较结果不一致,则判断为有效页面。
本发明的技术方案还提供了一种网页内容识别系统,包括网络爬虫单元,网页数据库单元,索引数据库单元,索引单元,其中,
网络爬虫单元用于从互联网自动提取网页信息;
网页数据库单元用户存储有效网页;
索引数据库单元用于存储有效网页的特征码;
索引单元用于对有效网页进行识别。
进一步的,所述特征码根据网络爬虫所采集的网页信息生成。
本发明技术方案由于在网页识别的过程中采用了创新的网页特征码技术和网页结构技术,能够通过简单的计算获得网页的特征信息,能够过滤掉大量的重复网页,去重算法简单,减小了去重运算量;而且创新的特征码技术能够降低系统资源占用,节约硬件成本,对于快速发展的互联网资源,能够提高搜索效率、降低成本支出,提高搜索的准确率。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可 通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例一中网页内容识别方法的流程图;
图2为本发明实施例二中根据网页结构识别网页为有效页面的方法流程图;
图3为本发明实施例一和二中网页内容识别系统结构图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
图1为本发明实施例一中网页内容识别方法的流程图。如图1所示,该流程包括以下步骤:
步骤101、网络爬虫抓取网页。
网络爬虫在互联网抓取网络页面;
网络爬虫自动抓取互联网网页的内容,包括但不限于网页结构、网页标签、程序或者脚本信息。
步骤102、生成网页结构、标签、特征码。
网页结构根据下述信息生成:包括但不限于网页标题,网页正文内容,图片、声音或视频信息;
特征码通过采集下述信息生成:包括但不限于网页的标签数量,标签中文字长度。
步骤103、判断网页结构是否一致。
若一致,则为执行步骤104;
若不一致,则执行步骤106。
步骤104、判断特征码是否一致。
若一致,则执行步骤105;
若不一致,则执行步骤106。
步骤105、判断标签是否一致。
若一致,则执行步骤106;
若不一致,则执行步骤107。
步骤106、判断为无效页面,放弃。
步骤107、判断为有效页面,存储。
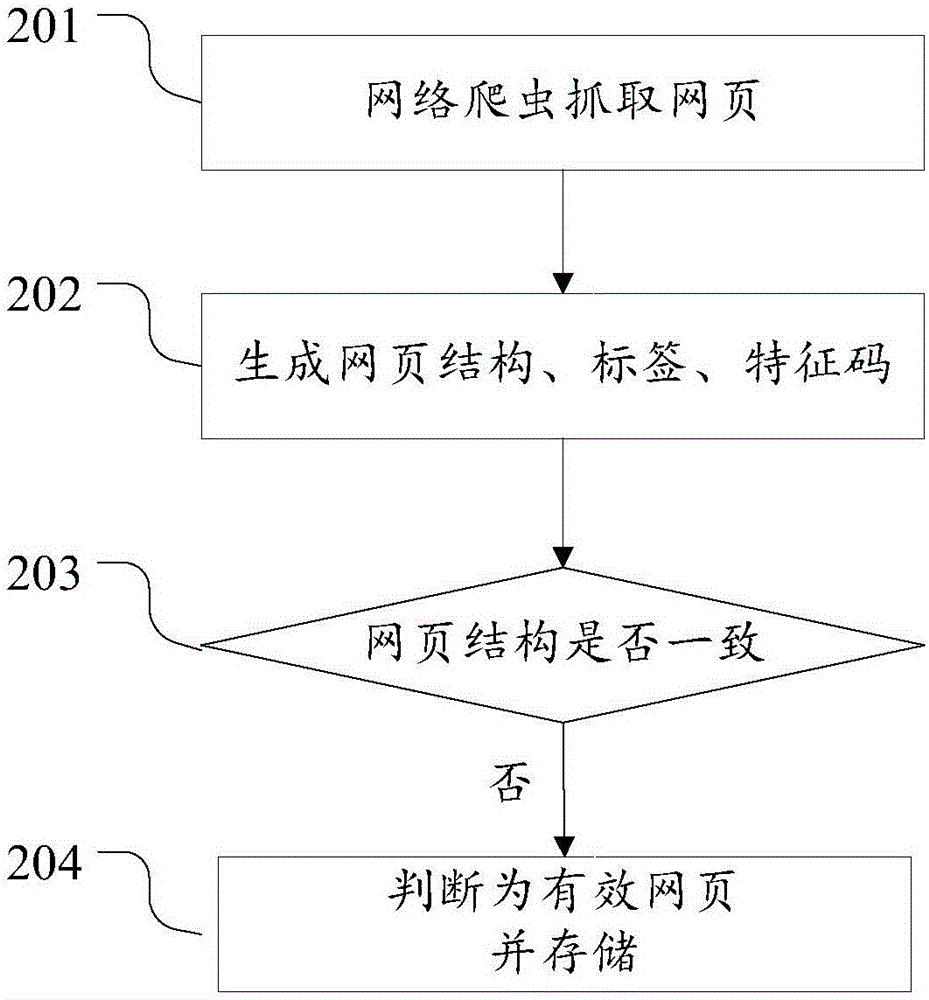
图2为本发明实施例二中根据网页结构识别网页为有效页面的方法流程图。如图2所示,该流程包括以下步骤:
步骤201、网络爬虫抓取网页。
网络爬虫在互联网抓取网络页面;
网络爬虫自动抓取互联网网页的内容,包括但不限于网页结构、网页标签、程序或者脚本信息。
步骤202、生成网页结构、标签、特征码。
网页结构根据下述信息生成:包括但不限于网页标题,网页正文内容,图片、声音或视频信息;
特征码通过采集下述信息生成:包括但不限于网页的标签数量,标签中文字长度。
步骤203、判断网页结构是否一致。
判断结果不一致,执行步骤204。
步骤204、判断为有效页面,存储。
为了实现上述网页内容识别流程,本实施例还提供了一种网页内容识别系统,图3为本发明实施例一和二中网页内容识别系统结构图。如图3所示,该系统包括网络爬虫单元301,索引单元302,索引数据库单元303,网页数据库单元304,其中,
网络爬虫单元用于从互联网自动提取网页信息;
网页数据库单元用户存储有效网页;
索引数据库单元用于存储有效网页的特征码;
索引单元用于对有效网页进行识别。
进一步的,所述特征码根据网络爬虫所采集的网页信息生成。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个 流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!