扩展计数密钥数据的基于块的端到端数据保护方法和系统与流程
本发明涉及一种计算机缓存系统的管理算法,具体是指一种CPU缓存系统的管理方法。
背景技术:
目前,计算机系统访问诸如内存和其他低级存储设备(如硬盘和网络设备)时均有很大的延迟。以访问内存为例,在CPU发出数据和指令的存取命令后,要约100纳秒的时间才能得到数据,这相当于CPU核心执行几百条指令的时间。由于CPU系统对指令和数据的使用有一定的规律,因此根据这些规律,我们便可以设计各种手段猜测CPU将要使用到的指令和数据,并提前预取这些内容到CPU中以备用。这样当CPU要实际使用这些指令和数据时,不需要等待,可以立即得到这些指令和数据。因此,预取(Prefetch)是能够有效地减少CPU访问内存和其他低级存储设备的平均访问延迟的一种手段。
然而,预取在实际应用中的功效取决于两个条件:第一,预取的准确性,也即预取的数据和指令是否及时,是否会被实际地用到;第二,预取的指令和数据对CPU缓存中现有的有用的指令和数据的排挤冲刷作用。虽然预取可以有效地降低内存访问的平均延迟,但是预取的内容会替换掉CPU缓存中现有的有用指令和数据,而这些被预取的内容替换掉的CPU缓存中现有的有用内容是将来要被重新耗费时间读入CPU的。因此对预取内容的处理不当,会增加CPU缓存失误,增加CPU对内存的访问次数,损害性能。
技术实现要素:
本发明的目的在于克服目前CPU预取时,CPU缓存中现有的有用数据会被预取的内容替换掉,从而会增加缓存失误、降低性能的缺陷,提供一种能有效解决上述缺陷的一种扩展计数密钥数据的基于块的端到端数据保护方法和系统。
本发明通过以下技术方案实现:一种扩展计数密钥数据的基于块的端到端数据保护方法和系统,该缓存系统包括一个以上的缓存线,且每个缓存线均包含有一个或多个数据字,同时每个缓存线都有一个命中Hit标识位,所述缓存线的数据字为当前正在使用的或预取的;其管理步骤为:在缓存线装载时,其命中Hit标识位被置为0;在缓存线命中时,命中Hit标识位被置为1;替换时,首先替换命中Hit标识位为0的缓存线,再替换命中Hit标识位为1的缓存线。
进一步地,上述每个缓存线中都还设有一个预取P标识位,其管理步骤为,当缓存线的数据字为预取的内容时,P标识位置1,否则置0;在替换时,首先替换P标识位都为0的缓存线,再替换P标识位为1的缓存线。或者,每个缓存线中还设有一个U标识位,其管理步骤为,当缓存线第一次装载入缓存时,U标识位置1;在替换时,首先替换U标识位都为零的缓存线,再替换U标识位为1的缓存线。
为了较好的实现本发明,本发明的另一种技术方案为:
一种扩展计数密钥数据的基于块的端到端数据保护方法和系统,该缓存系统由多个缓存线构成,且每个缓存线都包含一个或多个数据字,同时每个缓存线都有一个命中Hit标识位。其管理步骤为:在缓存线装载时,命中Hit标识位被置为0;在缓存线命中时,命中Hit标识位被置为1;在替换时,首先替换命中Hit标识位为0的缓存线,再替换命中Hit标识位为1的缓存线;当命中Hit标识位为1的缓存线的数目达到预订的阀值时,或者命中Hit标识位为1的缓存线满足预定的组合逻辑近似条件的设定时,清零全部或者部分缓存线的命中Hit标识位。
为了较好的实现本发明,上述缓存线分为两个或以上的子集,当每个子集中所有缓存线的命中Hit标识位都为1,或者满足预定的组合逻辑近似条件的设定时,全部或者部分清除该子集的缓存线的命中Hit标识位。
本发明的第三种技术方案为:一种扩展计数密钥数据的基于块的端到端数据保护方法和系统,该缓存由多个缓存线构成,且每个缓存线包含多个数据字,同时每个缓存线按地址分成多个子集,每个子集对应一个或者多个数据字;每个子集设置一个或多个局部Sub-block 标识位;当缓存查询和填充等操作采用缓存线子集对应的地址的粒度时,根据缓存线子集对应的地址粒度记录缓存线相应子集的状态和历史信息,并将信息保存在该子集对应的局部Sub-block标识位中。
为了较好的实现本发明,上述每个缓存线子集设置一个局部使用Sub-block Used标识位;整个缓存线设置一个或多个全局标识位,其管理步骤如下:
当缓存线第一次装入缓存时,除了正在访问的地址所对应的子集的局部使用Sub-block Used标识位置1,其他子集的局部使用Sub-block Used标识位置0;当缓存线在缓存中命中时,如果命中的地址所对应的子集的局部使用Sub-block Used标识位为0,则置1;如果命中的地址所对应的子集的局部使用Sub-block Used标识位已经为1,则改变全局标识位。
或者,在上述基础上,每个缓存线中都还设有一个全局命中Global Hit标识位,其管理步骤如下:当缓存线第一次装入缓存时,全局命中Global Hit标识位置为0,除了正在访问的地址所对应的子集的局部使用Sub-block Used标识位置1,其他子集的局部使用Sub-block Used标识位置0;当缓存线在缓存中命中时,如果命中的地址所对应的子集的局部使用Sub-block Used标识位为0,则置1;如果命中的地址所对应的子集的局部使用Sub-block Used标识位已经为1,则置全局命中Global Hit标识位为1;替换时,首先替换全局命中Global Hit标识位为0的缓存线,在替换全局命中Global Hit标识位为1的缓存线。
第四种技术方案为:一种扩展计数密钥数据的基于块的端到端数据保护方法和系统,每个缓存线有一个全局使用Global Used标识位,其管理步骤如下:当缓存线第一次装入缓存时,全局Global Used标识位置为1,除了正在访问的地址所对应的子集的局部使用Sub-block Used标识位置1,其他子集的局部使用Sub-block Used标识位置0;缓存线在缓存中命中时,如果命中的地址所对应的子集的局部使用Sub-block Used标识位为0,则置1;如果命中的地址所对应的子集的局部使用Sub-block Used标识位已经为1,则置全局使用Global Used标识位为1;替换时,首先替换全局使用Global Used标识位为0的缓存线,再替换全局使用Global Used标识位为1的缓存线。
第五种技术方案:一种扩展计数密钥数据的基于块的端到端数据保护方法和系统,该缓存由多个缓存线构成,且每个缓存线有多个数据字;每个缓存线的数据字按地址分为多个子集,且每个子集都设置一个用于记录该子集访问历史的标识位,其管理步骤如下:
若子集对应的地址被访问,则将该子集的标识位置为1;若子集的标识位为1的数目达到预订阀值或者设定条件时,则发出内存访问的的预取命令。
本发明较现有技术相比,具有以下优点及有益效果:
(1)本发明能确保CPU系统具有效地进行指令和数据的预取,能在指令和数据被真实使用前,提前发出请求从内存或者其他存储机构将指令和数据取回到CPU中,能显著地降低平均访问延迟,从而提高运算速度。
(2)本发明CPU 系统中预取的指令和数据既可以单独存放于一块缓存区,也可以与非预取的指令和数据存放于同样的缓存中,使用范围较广。
(3)本发明采用的缓存替换算法,能确保CPU系统运行的稳定性,最大程度地降低缓存失误,最少次数地对内存进行访问。
(4)本发明还具有防止WLRU缓存替换算法的过杀伤功能,因此能确保本发明的使用效果。
附图说明
图1为本发明涉及的CPU内部结构示意图。
图2为本发明实施例1中的缓存线的存储结构示意图。
具体实施方式
下面结合具体的实施例对本发明进行阐述,但本发明的实施方式不限于此。
实施例1
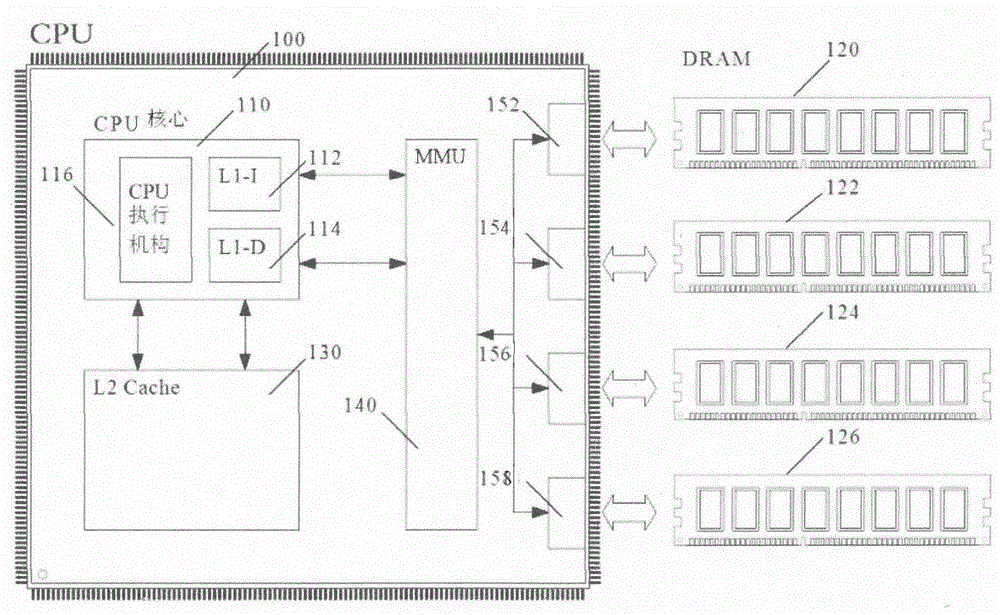
如图1~2所示,本发明CPU系统中的CPU独立芯片100内部集成有CPU核心110 、二级缓存130、内存访问控制器MMU 140及四个内存通道。CPU核心110中内置有CPU执行机构116、第一级指令缓存112(即L1-I Cache)和第一级数据缓存114(即L1-D Cache)。二级缓存130直接与CPU核心110进行数据交换,而所述的四个内存通道(即内存通道一152、内存通道二154、内存通道三156和内存通道四158)则与内存访问控制器MMU 140相连接,以接受其管理指令。
内存访问控制器MMU 140与CPU核心110的指令和数据的填充机构交换数据。图1中的CPU独立芯片100的第一缓存采用的是指令和数据分开的存储的结构:指令存放于第一级指令缓存112 中,数据存放于第一级数据缓存114中。CPU缓存是位于和CPU核心110同一块芯片上的存储区,且CPU缓存的读写延迟要明显小于位于CPU独立芯片100外部的内存,即图1中所设计的四个分别独立与四个内存通道相连接的内存模块120、内存模块122、内存模块124和内存模块126。目前,CPU缓存通常用高速读写电路,比如SRAM制造,而内存由DRAM电路制造。
图2描述了一种缓存线的存储结构示意图,该缓存线有TAG存储区260,Data存储区270,和5个标识位。所述的5个标识位为:V标识位210,H标识位220,A标识位230,D标识位240和P标识位250。其中,V标识位210代表缓存线为合法有效(Valid);H标识位220表示缓存线被命中(Hit)过,在缓存线最初装入时,H标识位220被设置为零,若缓存线命中,则置为1;A标识位230标识该缓存线已经被替换算法分配(Allocated);D标识位240表示该缓存线的内容曾经被改动过(Dirty),在被替换出缓存后,需要将改变后的内容写入内存;P标识位250代表Prefetch,如果该标识位被设置为1,表示该缓存线存储的是预取的内容。
对于非预取的指令和数据,当其填入CPU缓存中时,相应缓存线的P标识位250将被设置为零,以示和存储预取的内容的缓存线的区别。P标识位250为1的缓存线在命中后,P标识位250可以被清零。P标识位250为1的缓存线在第一次命中后,可以其命中H标识位220可以不置1。
在上述过程中,清零缓存线的命中Hit标识位,可以全部清零,也可以只清零一部分,比如清零其中一半的缓存线。部分清零时,可以采用一个伪随机的指针来确定要清零的缓存线。如果清零一半的缓存线,指针只需1位宽。当指针的值为零时,清零低半部分的缓存线的命中Hit标识位;指针的值为1时,清零编号在高半部分的缓存线的命中Hit标识位。如果每次清零一半的缓存线,当指针为0时,清零缓存线0到7,指针为1时,清零缓存线8到15。每做一次清零动作后,指针的值翻转,从0变为1或者从1变为0。
WLRU替换算法的防“过杀伤”设计可以保证新的缓存内容在缓存中能够有适当的停留时间通过这段停留时间,WLRU替换算法可以有效地判断缓存内容的价值,从而保留高价值的缓存内容,尽快地替换无价值的缓存内容。防止“过杀伤”设计的参数可以预先设定好的,也可以是根据应用程序的特征动态配置的。
以上所揭露的仅为本发明的较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明申请专利范围所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!