一种数据获取方法和装置与流程
本申请涉及网络领域,特别涉及一种数据获取方法和装置。
背景技术:
通常,在使用网络爬虫程序获取数据的过程中,会由于网络故障、网站暂时瘫痪以及的URL(Uniform Resource Locator,统一资源定位符)失效等情况而导致的数据无法获取的情况,使得需要提供一种数据获取方法,实现在网络故障、网站暂时瘫痪以及URL失效等情况下数据的获取。
在现有技术中,通过将页面URL记录后存储在队列中,隔一个间隔时间重复一次,在重复次数达到一个阀值时,若仍然无法获取该的数据之后,判定该URL已失效,并停止对该的数据的获取。
但是在采用现有技术所提供的方法时,由于无法找到一个合适的间隔时间。若设置时间间隔过长,容易造成因网络故障而导致的数据无法获取的在队列中大量堆积,加重内存负担;若设置的时间间隔过短会造成因URL失效和网站暂时瘫痪而导致的数据无法获取的被频繁重试,加重服务器和网络负担。同时,由于网站暂时瘫痪的恢复时间无法度量,可能在网站恢复之前该URL已经达到重试次数被丢弃,造成因网站暂时瘫痪而导致的数据无法获取的被丢弃的情况,使得在使用现有技术所提供的方法时,降低了数据获取的可靠性,降低了数据获取的效率。
技术实现要素:
为了提高数据获取的可靠性,提高数据获取的效率,本申请实施例提供了 一种数据获取方法和装置。所述技术方案如下:
本申请提供了一种数据获取方法,所述方法包括:
获取失败的数据爬取任务,其中,所述数据爬取任务至少包含:数据爬取失败的次数和数据爬取失败的时间;
根据所述数据爬取失败的次数和/或数据爬取失败的时间,确定所述失败的数据爬取任务重新进行数据爬取的时间;
根据所述重新进行数据爬取的时间,对所述失败的数据爬取任务执行重新数据爬取任务。
本申请还提供了一种数据获取装置,所述装置包括:
获取模块,用于获取失败的数据爬取任务,其中,所述数据爬取任务至少包含:数据爬取失败的次数和数据爬取失败的时间;
第一处理模块,用于根据所述数据爬取失败的次数和/或数据爬取失败的时间,确定所述失败的数据爬取任务重新进行数据爬取的时间;
第二处理模块,用于根据所述重新进行数据爬取的时间,对所述失败的数据爬取任务执行重新数据爬取任务。
本申请实施例提供了一种数据获取方法和装置,包括:获取失败的数据爬取任务,其中,数据爬取任务至少包含:数据爬取失败的次数和数据爬取失败的时间;根据数据爬取失败的次数和/或数据爬取失败的时间,确定失败的数据爬取任务重新进行数据爬取的时间;根据重新进行数据爬取的时间,对失败的数据爬取任务执行重新数据爬取任务。通过根据数据爬取失败的次数和/或数据爬取失败的时间,确定失败的数据爬取任务重新进行数据爬取的时间,使得可以根据数据爬取失败的次数和/或数据爬取失败的时间对该失败的数据爬取任务重新进行数据爬取的时间进行调整,从而避免了对由于网站暂时瘫痪等原因导致的无法获取数据的遗漏,保证了数据获取的可靠性,同时避免了短时间内通 过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的网络资源负担和装置的系统资源负担,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本申请实施例提供的一种数据获取方法流程图;
图2是本申请实施例提供的一种数据获取方法流程图;
图3是本申请实施例提供的一种数据获取装置结构示意图;
图4是本申请实施例提供的一种数据获取装置结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
本申请实施例提供一种数据获取方法,该方法应用场景包括通过网络爬虫程序通过执行爬取任务获取网页数据,该爬取任务至少包括所要获取的网页数据所在的网页标识。除此之外,该方法还可以应用于其他根据网页标识信息获取网页数据的场景,该网页标识可以为该网页的URL(Uniform Resource Locator,统一资源定位符),本申请实施例对具体的应用场景不加以限定。
实施例一为本申请实施例提供的一种数据获取方法,参照图1所示,该方 法包括:
101、获取失败的数据爬取任务。
其中,数据爬取任务至少包含:数据爬取失败的次数和数据爬取失败的时间。获取失败的数据爬取任务,可以通过实时监测的方式或者预设的存储失败的数据爬取任务的数据库中获取。
第一种情况,当监测到数据爬取任务失败时,可以获取该数据爬取任务的失败时间(即该时间可以是初次数据爬取失败的时间,也可以是执行主体扫描到该数据爬取任务失败时的时间,对此本申请不做任何限定),以及执行主体所设置的在数据爬取失败时重新执行爬取任务的次数,然后,根据实际爬取目标的需求,将将所述数据爬取失败的次数和所述数据爬取失败的时间至预设的数据库。其中,爬取目标可以是指网站访问量的爬取、微博点击量的爬取等。
此处需要注意的是,若系统未设置在数据爬取失败时重新执行爬取任务的次数,则可默认为数据爬取失败的次数为零。
第二种情况,针对爬取效率较低的系统(即执行主体),对于步骤101获取失败的数据爬取任务,还可以是从预设的存储失败的数据爬取任务的数据库中来获取,以提高该执行主体执行数据爬取任务的效率。
具体地,在执行主体执行从任务池中获取的数据爬取任务时,若爬取失败,则将失败的数据爬取任务存储至预设的数据库,该失败的数据爬取任务包括数据爬取失败的次数和数据爬取失败的时间、所处于爬取失败的环境等信息。
该预设的数据库可以被预先设置在服务器上,也可以被预先设置在装置的缓存中,还可以被预先设置在装置的数据库中,本申请实施例对该预设的数据库所在的位置不加以限定。
其中,该预设的数据库所包含的至少一个失败的数据爬取任务可以根据添加的时间进行排序。
102、根据数据爬取失败的次数和/或数据爬取失败的时间,确定失败的数据 爬取任务重新进行数据爬取的时间。
具体地,首先,可以根据所执行的数据爬取任务的不同爬取目标、数据爬取失败的次数或数据爬取失败的时间来确定数据爬取的时间间隔;其中,这里所说的爬取目标,可以是指网站访问量的爬取、微博点击量的爬取等环境,对此本申请不做任何限定。然后,根据所述数据爬取的时间间隔、所述数据爬取失败的次数和/或数据爬取失败的时间,生成所述失败的数据爬取任务重新进行数据爬取的时间。
103、根据重新进行数据爬取的时间,对失败的数据爬取任务执行重新数据爬取任务。若满足,则设置失败的数据爬取任务为网络爬虫程序当前将要执行的任务。
具体地,可利用判断重新进行数据爬取的时间是否满足网络爬虫程序当前将要执行的时间,以重新执行所述失败的数据爬取任务,其中,网络爬虫程序当前要执行的时间,可以根据所需要执行的数据爬取的环境来设置,对此本申请不做任何限定。
进一步地,当所述重新进行数据爬取的时间不满足网络爬虫程序当前将要执行的时间时,步骤105还可以包括:将失败的数据爬取任务存储至预设的数据库中,以待进行下一次的重新进行数据爬取的时间判断。
本申请实施例提供了一种数据获取方法,通过根据数据爬取失败的次数和/或数据爬取失败的时间,确定失败的数据爬取任务重新进行数据爬取的时间,使得可以根据数据爬取失败的次数和/或数据爬取失败的时间对该失败的数据爬取任务重新进行数据爬取的时间进行调整,从而避免了对由于网站暂时瘫痪等原因导致的无法获取数据的遗漏,保证了数据获取的可靠性,同时避免了短时间内通过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的网络资源负担和装置的系统资源负担,从而进一步提高 了数据获取的可靠性,提高了数据获取的效率。另外,判断重新进行数据爬取的时间是否满足网络爬虫程序当前将要执行的时间;若满足,则设置失败的数据爬取任务为网络爬虫程序当前将要执行的任务,不仅进一步的避免了短时间内通过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的网络资源负担和装置的系统资源负担,从而进一步提高了数据获取的可靠性,提高了数据获取的效率,还保证了由于网站暂时瘫痪等原因导致的无法获取数据的在网站暂时瘫痪解决之后,该信息的及时获取,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。
实施例二为本申请实施例提供的一种数据获取方法,参照图2所示,该方法包括:
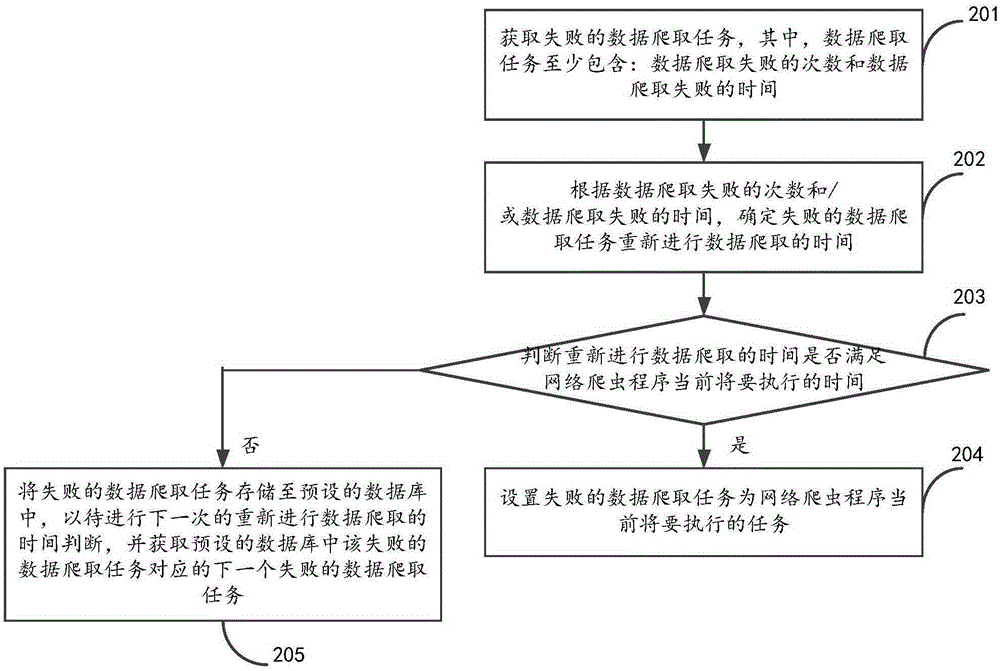
201、获取失败的数据爬取任务,其中,数据爬取任务至少包含:数据爬取失败的次数和数据爬取失败的时间。
具体地,在预设周期之后,从预设的数据库中获取失败的数据爬取任务。
从预设的数据库中获取失败的数据爬取任务的过程可以为:
在预设周期之后,通过对预设的数据库中所包含的失败的数据爬取任务进行扫描,并根据该预设的数据库中的所包含的失败的数据爬取任务的添加时间顺序,从预设的数据库中获取添加时间较早的失败的数据爬取任务。
通过根据该预设的数据库中的所包含的失败的数据爬取任务的添加时间顺序,获取失败的数据爬取任务,使得添加时间较早的待重试的爬取任务优选进行爬取,从而保证了由于网站暂时瘫痪等原因导致的无法获取数据的在恢复至数据可获取的状态时,该数据的及时获取,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。
202、根据数据爬取失败的次数和/或数据爬取失败的时间,确定失败的数据爬取任务重新进行数据爬取的时间。
具体的,根据确定的数据爬取时间间隔、数据爬取失败的次数和/或数据爬取失败的时间,生成失败的数据爬取任务重新进行数据爬取的时间。
为了进一步说明本申请实施例的方法,假设数据爬取失败的次数为M,数据爬取的时间间隔为N,数据爬取失败的时间为TF,该失败的数据爬取任务重新进行数据爬取的时间为TF;
可以根据第一预设函数,实现根据数据爬取时间间隔和数据爬取失败的次数,生成失败的数据爬取任务重新进行数据爬取的时间的过程,该第一预设函数TS1可以为公式[1]所示:
TS1=N×aM [1]
还可以根据第二预设函数,实现根据数据爬取的时间间隔和数据爬取失败的时间,生成失败的数据爬取任务重新进行数据爬取的时间的过程,该第二预设函数TS2可以为公式[2]所示:
TS2=TF+N×a [2]
另外,还可以根据第三预设函数,实现根据数据爬取的时间间隔、数据爬取失败的时间和数据爬取失败的次数,生成失败的数据爬取任务重新进行数据爬取的时间的过程,该第三预设函数TS3可以为公式[3]所示:
TS3=TF+N×aM [3]
其中,上述公式[1]-公式[3]中的a为预设系数,且a大于1。
需要说明的是,上述第一预设函数、第二预设函数和第三预设函数仅仅是示例性的,除此之外,还可以包括其他函数性质为非减函数的预设函数,本申请实施例对具体的预设函数不加以限定。
通过所确定的数据爬取的时间间隔、数据爬取失败的次数和/或数据爬取失败的时间,生成失败的数据爬取任务重新进行数据爬取的时间,保证了数据爬取失败的次数较多的失败的数据爬取任务的执行时间晚于数据爬取失败的次数较少的失败的数据爬取任务的执行时间,而失败次数越多,说明该数据爬取任务的成功执行的概率越低,保证了成功执行的概率越高的任务优先执行,保证 了数据的及时获取,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。另外,通过数据爬取失败的时间,生成失败的数据爬取任务重新进行数据爬取的时间,保证了由于网站暂时瘫痪等原因导致的无法获取数据的在恢复至数据可获取的状态时,该数据的及时获取,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。另外,通过根据数据爬取失败的次数,生成失败的数据爬取任务重新进行数据爬取的时间,避免了短时间内通过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的网络资源负担和装置的系统资源负担,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。
203、判断重新进行数据爬取的时间是否满足网络爬虫程序当前将要执行的时间;若满足,则执行步骤204,若不满足,则执行步骤205。
其中,网络爬虫程序当前将要执行的时间为可以设置为数据爬取时间间隔的整数倍。
通过判定重新进行数据爬取的时间小于网络爬虫程序当前将要执行的时间,避免了短时间内通过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的网络资源负担和装置的系统资源负担,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。
204、设置失败的数据爬取任务为网络爬虫程序当前将要执行的任务。
具体地,将该失败的数据爬取任务添加至网络爬虫程序的任务池中。
通过将失败的数据爬取任务设置为网络爬虫程序当前将要执行的任务,保证了该失败的数据爬取任务的及时重新爬取,进而保证了数据的及时获取,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。
值得注意的是,步骤203至步骤204是实现根据重新进行数据爬取的时间,对失败的数据爬取任务执行重新数据爬取任务,除了上述步骤的方式之外,还可以通过其他方式实现该过程,本申请实施例对具体的方式不加以限定。
由于重新进行数据爬取的时间是根据数据爬取失败的次数和/或数据爬取失 败的时间生成的,从而保证了数据爬取失败的次数较多的失败的数据爬取任务的执行时间晚于数据爬取失败的次数较少的失败的数据爬取任务的执行时间,而失败次数越多,说明该数据爬取任务的成功执行的概率越低,保证了成功执行的概率越高的任务优先执行,保证了数据的及时获取,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。
205,将失败的数据爬取任务存储至预设的数据库中,以待进行下一次的重新进行数据爬取的时间判断,并获取预设的数据库中该失败的数据爬取任务对应的下一个失败的数据爬取任务。
通过在重新进行数据爬取的时间不满足网络爬虫程序当前将要执行的时间时,将失败的数据爬取任务存储至预设的数据库中,避免了短时间内通过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的网络资源负担和装置的系统资源负担,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。
通过执行本申请实施例的方法,不仅避免了短时间内通过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的网络资源负担和装置的系统资源负担,还保证了该网站在恢复至数据可获取的状态时,该数据的及时获取,从而提高了数据获取的可靠性,提高了数据获取的效率。
本申请实施例提供了一种数据获取方法,通过根据待重试的爬取任务的重试次数以及上一次重试时的第一任务时间,生成将要重试待重试的爬取任务的第二任务时间,使得可以根据待重试的爬取任务的重试次数和上一次的重试时间对该待重试的爬取任务的重试时间进行调整,从而避免了对由于网站暂时瘫痪等原因导致的无法获取数据的遗漏,保证了数据获取的可靠性。另外,通过根据待重试的爬取任务的重试次数以及上一次重试时的第一任务时间,生成将要重试待重试的爬取任务的第二任务时间,避免了短时间内通过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的 网络资源负担和装置的系统资源负担,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。另外,通过判断第二任务时间是否满足预设条件,若是,则设置待重试的爬取任务为网络爬虫程序当前将要执行的任务;否则,获取该待重试的爬取任务的下一个待重试的爬取任务,不设置爬取任务为网络爬虫程序当前将要执行的任务,不仅进一步的避免了短时间内通过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的网络资源负担和装置的系统资源负担,从而进一步提高了数据获取的可靠性,提高了数据获取的效率,还保证了由于网站暂时瘫痪等原因导致的无法获取数据的在网站暂时瘫痪解决之后,该信息的及时获取,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。
实施例三为本申请实施例提供的一种数据获取装置,参照图3所示,该数据获取装置包括:
获取模块31,用于获取失败的数据爬取任务,其中,数据爬取任务至少包含:数据爬取失败的次数和数据爬取失败的时间;
第一处理模块32,用于根据数据爬取失败的次数和/或数据爬取失败的时间,确定失败的数据爬取任务重新进行数据爬取的时间;
第二处理模块33,用于根据重新进行数据爬取的时间,对失败的数据爬取任务执行重新数据爬取任务。
所述获取模块,用于:针对所获取的失败的数据爬取任务,获得数据爬取失败的次数和数据爬取失败的时间;将所述数据爬取失败的次数和所述数据爬取失败的时间至预设的数据库。
可选的,第一处理模块32可以包括:
确定子模块,用于确定数据爬取的时间间隔;
生成子模块,用于根据确定数据爬取的时间间隔、数据爬取失败的次数和/或数据爬取失败的时间,生成失败的数据爬取任务重新进行数据爬取的时间。
可选的,第二处理模块33具体用于:
判断重新进行数据爬取的时间是否满足网络爬虫程序当前将要执行的时间;
若满足,则设置失败的数据爬取任务为网络爬虫程序当前将要执行的任务。
可选的,第二处理模块33还用于:
将失败的数据爬取任务存储至预设的数据库中,以待进行下一次的重新进行数据爬取的时间判断。
本申请实施例提供了一种数据获取装置,该数据获取装置通过根据数据爬取失败的次数和/或数据爬取失败的时间,确定失败的数据爬取任务重新进行数据爬取的时间,使得可以根据数据爬取失败的次数和/或数据爬取失败的时间对该失败的数据爬取任务重新进行数据爬取的时间进行调整,从而避免了对由于网站暂时瘫痪等原因导致的无法获取数据的遗漏,保证了数据获取的可靠性,同时避免了短时间内通过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的网络资源负担和装置的系统资源负担,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。另外,判断重新进行数据爬取的时间是否满足网络爬虫程序当前将要执行的时间;若满足,则设置失败的数据爬取任务为网络爬虫程序当前将要执行的任务,不仅进一步的避免了短时间内通过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的网络资源负担和装置的系统资源负担,从而进一步提高了数据获取的可靠性,提高了数据获取的效率,还保证了由于网站暂时瘫痪等原因导致的无法获取数据的在网站暂时瘫痪解决之后,该信息的及时获取,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。
实施例四位本申请实施例提供的一种数据获取装置4,参照图4所示,该数据获取装置4包括存储器41和与存储器41连接的处理器42,存储器41用于存储一组程序代码,处理器42调用存储器41所存储的程序代码用于执行以下操作:
获取失败的数据爬取任务,其中,数据爬取任务至少包含:数据爬取失败的次数和数据爬取失败的时间;
根据数据爬取失败的次数和/或数据爬取失败的时间,确定失败的数据爬取任务重新进行数据爬取的时间;
根据重新进行数据爬取的时间,对失败的数据爬取任务执行重新数据爬取任务。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
将数据爬取失败的次数和数据爬取失败的时间至预设的数据库。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
根据预设时间间隔、数据爬取失败的次数和/或数据爬取失败的时间,生成失败的数据爬取任务重新进行数据爬取的时间。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
判断重新进行数据爬取的时间是否满足网络爬虫程序当前将要执行的时间;
若满足,则设置失败的数据爬取任务为网络爬虫程序当前将要执行的任务。
可选的,处理器42调用存储器41所存储的程序代码用于执行以下操作:
将失败的数据爬取任务存储至预设的数据库中,以待进行下一次的重新进行数据爬取的时间判断。
本申请实施例提供了一种数据获取装置,该数据获取装置通过根据数据爬取失败的次数和/或数据爬取失败的时间,确定失败的数据爬取任务重新进行数据爬取的时间,使得可以根据数据爬取失败的次数和/或数据爬取失败的时间对该失败的数据爬取任务重新进行数据爬取的时间进行调整,从而避免了对由于网站暂时瘫痪等原因导致的无法获取数据的遗漏,保证了数据获取的可靠性,同时避免了短时间内通过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的网络资源负担和装置的系统资源负担,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。另外,判断重 新进行数据爬取的时间是否满足网络爬虫程序当前将要执行的时间;若满足,则设置失败的数据爬取任务为网络爬虫程序当前将要执行的任务,不仅进一步的避免了短时间内通过网络爬虫程序对由于网站暂时瘫痪等原因导致的无法获取数据的进行重复的爬取,而造成的网络资源负担和装置的系统资源负担,从而进一步提高了数据获取的可靠性,提高了数据获取的效率,还保证了由于网站暂时瘫痪等原因导致的无法获取数据的在网站暂时瘫痪解决之后,该信息的及时获取,从而进一步提高了数据获取的可靠性,提高了数据获取的效率。
上述所有可选技术方案,可以采用任意结合形成本申请的可选实施例,在此不再一一赘述。
需要说明的是:上述实施例提供的装置在执行数据获取方法时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的数据获取装置与数据获取方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上仅为本申请的较佳实施例,并不用以限制本申请,凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!