一种分词词库更新方法及系统与流程
本发明涉及数据处理技术领域,更具体地说,涉及一种分词词库更新方法及系统。
背景技术:
在搜索系统中,分词效果的好坏是影响搜索效果的关键因素。而分词过程所依赖的词库,是分词技术的重要组成部分。
目前常见的词库生成方法是采用统计的方法:对输入语料中相邻共现的各个字的组合(即字组)的频度进行统计,计算其互现信息,其中,该互现信息体现了汉字之间结合关系的紧密程度,当紧密程度高于某一个阈值时,则可认为此字组可能构成了一个词。通过上述方法生成词库,再将词库应用与线上分词业务。
然而采用上述词频统计的方法生成的中文词库,存在的技术问题主要有:经常切分出一些共现频度高但并不是词的常用字组;大部分词库都是属于通用词库,不适合某些垂直搜索场景,比如商品名称搜索、地名搜索、人名搜索等;词库往往是静态的,线下生成再线上使用,不能快速根据实际使用情况进行更新和完善;词库对于新词的识别效果较差。
技术实现要素:
本发明要解决的技术问题在于,针对现有的词频统计方法生成中文词库的上述缺陷,提供一种分词词库更新方法及系统。
本发明解决上述问题的技术方案是提供了一种分词词库更新系统,包括:
日志采集模块,用于采集分词业务系统在运行过程中输出的分词业务日志;
日志分析模块,用于对所述日志采集模块采集到的所述分词业务日志进行统计分析,并提取相关有效数据;
分词评价模块,用于根据评价规则对所述相关有效数据进行评价得到分词效果不好的分词输入;以及
分词校正与过滤模块,用于对所述分词评价模块所得到的所述分词效果不好的分词输入进行分词校正和过滤输出新词词组,并将该新词词组更新到分词词库中。
在上述分词词库更新系统中,所述分词业务系统包括搜索系统,所述相关有效数据包括搜索结果的订购次数或者浏览次数和/或搜索关键词的转换率和/或搜索结果的首页命中比例和/或搜索关键词的召回率和/或分词输入的分词结果;所述评价规则包括搜索关键词的转换率小于第一预设阈值和/或搜索结果个数小于第二预设阈值和/或使用量小于预设阈值和/或分词输入的分词结果大于第三预设阈值。
在上述分词词库更新系统中,所述分词校正与过滤模块包括构造子模块和切分子模块,其中:
所述构造子模块,用于扫描语料数据,并计算每个单词到下一个单词的概率来构造一参考概率表;
所述切分子模块,用于对所述分词效果不好的分词输入进行全切分得到基础分词词组。
在上述分词词库更新系统中,所述分词校正与过滤模块还包括过滤子模块,所述过滤子模块用于根据使用所述参考概率表的Z分词过滤算法对所述切分子模块全切分后得到的所述基础分词词组进行过滤得到所述新词词组,并将所述新词词组更新到分词词库中。
在上述分词词库更新系统中,所述过滤子模块包括:
扫描单元,用于扫描该基础分词词组并获取该基础分词词组中基础分词共有但未包含在该基础分词词组中的前向词列表;
第一判断单元,用于判断该前向词列表的长度是否大于第一变量i,其中,该第一变量i的初始值为0;
第一添加单元,用于在判断该前向词列表的长度大于第一变量i时,从参考概率表中查询该前向词列表中第i个前向词的概率,并在判断该第i个前向词的概率存在或者大于或等于预设的第一阈值时,将该第i个前向词添加到该基础分词词组中;
第一自加单元,用于在判断该第i个前向词的概率不存在或者小于预设的第一阈值时,或者在将该第i个前向词添加到该基础分词词组后,第一变量i自加;
第二扫描单元,用于在判断该前向词列表的长度小于或等于该第一变量i时,扫描该基础分词词组,获取具有前向关系的词组的集合,其中,具有前向关系的词组表示为{A,B},A为第一词元,B为第二词元;
第二判断单元,用于判断该集合的大小是否小于第二变量j,其中,第二变量j的初始值为0;
第二添加单元,在判断该集合的大小小于第二变量j时,取出该集合中第j个词组中的第一词元A和第二词元B,并从参考概率表中查询P(A)和P(AB),并计算P(B|A);在判断P(B|A)小于预设的第二阈值时,判断该第二词元B是否已经存在于分词词库中,若否,则将该第二词元B添加到该基础分词词组;
第二自加单元,用于在判断P(B|A)大于或等于预设的第二阈值时,或者在判断第二词元B已经存在于分词词库中时,或者将第二词元B添加到该基础分词词组后,第二变量j自加;
第三添加单元,用于在判断该集合的大小大于或等于第二变量j时,将该基础分词词组进行排重后得到的新词词组添加到分词词库中。
本发明还提供了一种分词词库更新方法,该方法包括以下步骤:
S1、采集分词业务系统在运行过程中输出的分词业务日志;
S2、对采集到的所述分词业务日志进行统计分析,并提取相关有效数据;
S3、根据评价规则对所述相关有效数据进行评价得到分词效果不好的分词输入;
S4、对得到的所述分词效果不好的分词输入进行分词校正和过滤输出新词词组,并将该新词词组更新到分词词库中。
在上述分词词库更新方法中,所述分词业务系统包括搜索系统,所述相关有效数据包括搜索结果的订购次数或者浏览次数和/或搜索关键词的转换率和/或搜索结果的首页命中比例和/或搜索关键词的召回率和/或分词输入的分词结果;所述评价规则包括搜索关键词的转换率小于第一预设阈值和/或搜索结果个数小于第二预设阈值和/或使用量小于预设阈值和/或分词输入的分词结果大于第三预设阈值。
在上述分词词库更新方法中,所述步骤S4包括:
S41、扫描语料数据,并计算每个单词到下一个单词的概率来构造一参考概率表;
S42、对所述分词效果不好的分词输入进行全切分得到基础分词词组。
在上述分词词库更新方法中,所述步骤S4还包括:
S43、根据使用所述参考概率表的Z分词过滤算法对所述切分子模块全切分后得到的所述基础分词词组进行过滤得到所述新词词组,并将所述新词词组更新到分词词库中。
在上述分词词库更新方法中,所述步骤S43包括:
S431、扫描该基础分词词组并获取该基础分词词组中基础分词共有但未包含在该基础分词词组中的前向词列表;
S432、判断该前向词列表的长度是否大于第一变量i,其中,该第一变量i的初始值为0,若是执行步骤S433,若否,则执行步骤S435;
S433、在判断该前向词列表的长度大于第一变量i时,从参考概率表中查询该前向词列表中第i个前向词的概率,并在判断该第i个前向词的概率存在或者大于或等于预设的第一阈值时,将该第i个前向词添加到该基础分词词组中;
S434、在判断该第i个前向词的概率不存在或者小于预设的第一阈值时,或者在将该第i个前向词添加到该基础分词词组后,第一变量i自加,并在该第一变量i自加后,重复步骤S432至步骤S434;
S435、在判断该前向词列表的长度小于或等于该第一变量i时,扫描该基础分词词组,获取具有前向关系的词组的集合,其中,具有前向关系的词组表示为{A,B},A为第一词元,B为第二词元;
S436、判断该集合的大小是否小于第二变量j,其中,第二变量j的初始值为0,若是,则执行步骤S437,若否,则执行步骤S439;
S437、在判断该集合的大小小于第二变量j时,取出该集合中第j个词组中的第一词元A和第二词元B,并从参考概率表中查询P(A)和P(AB),并计算P(B|A);在判断P(B|A)小于预设的第二阈值时,判断该第二词元B是否已经存在于分词词库中,若否,则将该第二词元B添加到该基础分词词组;
S438、在判断P(B|A)大于或等于预设的第二阈值时,或者在判断第二词元B已经存在于分词词库中时,或者将第二词元B添加到该基础分词词组后,第二变量j自加,并在该第二变量j自加后,重复步骤S436至步骤S438;
S439、在判断该集合的大小大于或等于第二变量j时,将该基础分词词组进行排重后得到的新词词组添加到分词词库中。
实施本发明的分词词库更新方法及系统,有益效果有:基于分词业务日志分析,通过对分词业务系统的分词效果进行评价,提取出分词效果不好的分词输入,根据使用参考概率表的Z分词过滤算法对分词效果不好的分词输入进行分词校正和过滤输出新词词组,并将该新词词组更新到分词词库中,不断完善分词词库,解决了分词词库不能适时且适应实际分词应用环境的问题,有效提高分词效果。同时,分词业务系统可定期加载更新后的分词词库,进而可继续进行分词服务,能快速进行更新。
附图说明
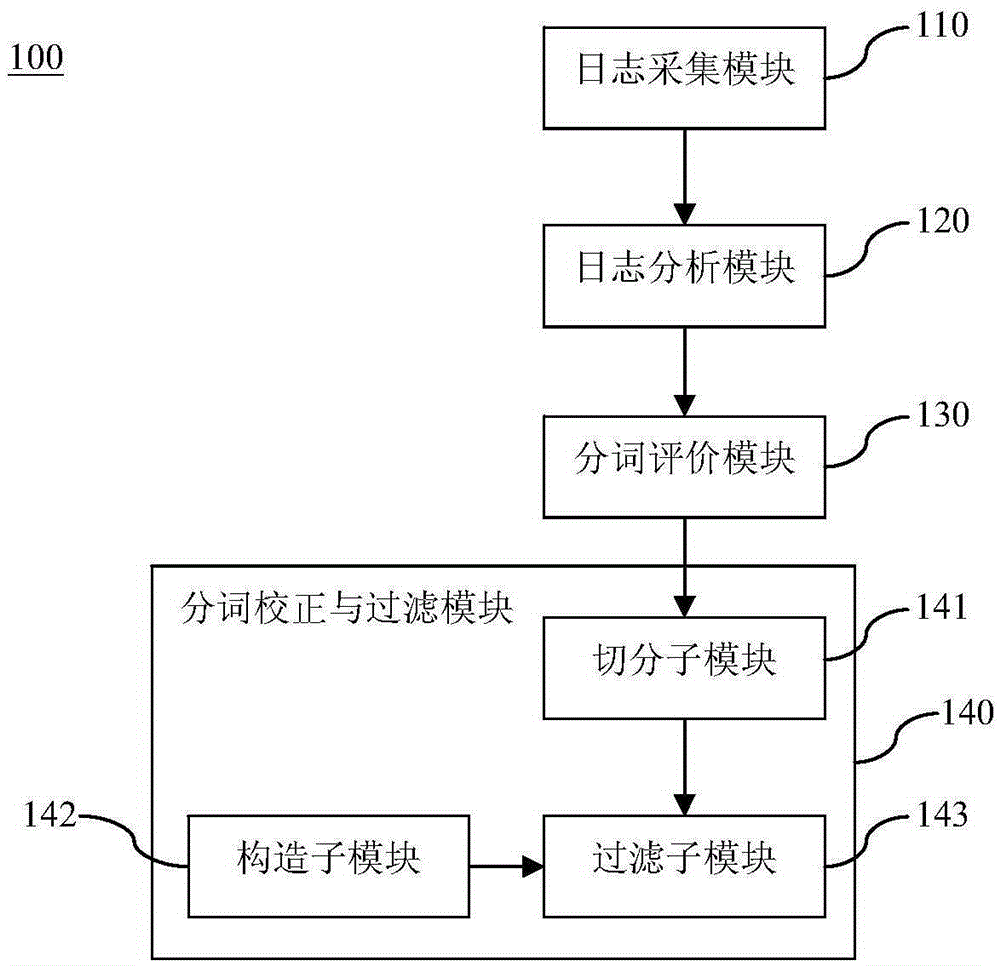
图1是本发明的分词词库更新系统实施例的结构示意图。
图2是本发明的分词词库更新方法实施例的流程图。
图3是本发明的分词词库更新方法实施例的具体的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅 用以解释本发明,并不用于限定本发明。
本发明的分词词库更新系统及方法基于分词业务日志分析,通过对分词业务系统的分词效果进行评价,提取出分词效果不好的分词输入,根据使用参考概率表的Z分词过滤算法对分词效果不好的分词输入进行分词校正和过滤输出新词词组,并将该新词词组更新到分词词库中,不断完善分词词库,解决了分词词库不能适时且适应实际分词应用环境的问题,有效提高分词效果。
如图1所示,是本发明的分词词库更新系统实施例的结构示意图。该系统100包括日志采集模块110、日志分析模块120、分词评价模块130以及分词校正与过滤模块140,其中:
日志采集模块110的输入端与分词业务系统连接,用于采集分词业务系统在运行过程中输出的分词业务日志,其中,分词业务系统是指应用分词功能的系统,包括搜索系统,此时,搜索系统在运行过程中输出的分词业务日志为搜索服务日志,包括用户的搜索输入、该搜索系统返回的结果以及用户对搜索结果的浏览和订购行为等。
日志分析模块120的输入端与日志采集模块110的输出端连接,用于对日志采集模块采集到的分词业务日志进行统计分析,并提取相关有效数据。以分词业务系统包括搜索系统为例,该有效数据包括搜索结果的订购次数或者浏览次数和/或搜索关键词的转换率和/或搜索结果的首页命中比例和/或搜索关键词的召回率和/或分词输入的分词结果,其中,搜索结果的订购次数或者浏览次数表示针对某个搜索词,用户的订购次数或者浏览详情页的次数;搜索关键词的转化率表示针对某个搜索词,用户浏览详情页的次数或者订购次数与搜索次数的比例值;搜索结果的首页命中比例表示针对某个搜索词,用户在搜索结果的首页获得到所需要的结果的次数与搜索次数之间的比例值;搜索关键词的召回率表示针对某个搜索关键词,搜索系统返回的结果的个数;分词输入的分词结果表示针对用户输入搜索关键词最终的分词结果中的单子个数。
分词评价模块130的输入端与日志分析模块120的输出端连接,用于根据评价规则对相关有效数据进行评价得到分词效果不好的分词输入,其中,评价规则为预先设置的,根据相关有效数据的种类来确定评价规则的数目,以分词业 务系统包括搜索系统为例,评价规则包括搜索关键词的转换率小于第一预设阈值和/或搜索结果个数小于第二预设阈值和/或使用量小于预设阈值和/或分词输入的分词结果大于第三预设阈值,其中,根据搜索关键词的转换率小于第一预设阈值和/或搜索结果个数小于第二预设阈值进行评价得到的分词输入是搜索关键词,使用量包括商品详情页的浏览量和订购量,根据使用量小于预设阈值这一评价规则来进行评价得到的分词输入是热门搜索记录,例如,搜索的商品名称、标签、详细描述等。
分词校正与过滤模块140的输入端与分词评价模块130的输出端连接,用于对分词评价模块所得到的分词效果不好的分词输入进行分词校正和过滤输出新词词组,并将该新词词组更新到分词词库中。至此,实现了分词词库的更新,不断完善了分词词库,此时,分词业务系统可定期加载更新后的分词词库,进而可继续进行分词服务,能快速进行更新。需要说明的是,在发明中分词输入是指在分词业务系统中所有需要分词的数据,例如,在搜索索引创建过程中需要分词的数据,如商品的名称、描述等,以及在搜索过程中需要分词的用户的输入等。
具体地,在本实施例中,该分词校正与过滤模块140包括构造子模块142、切分子模块141以及过滤子模块143,切分子模块的输入端作为该分词校正与过滤模块140的输入端、输出端与过滤子模块143的第一输入端连接,构造子模块142的输出端与过滤子模块的第二输入端连接,其中,该构造子模块142用于扫描语料数据,并计算每个单词到下一个单词的概率来构造一参考概率表,需要说明的是,语料数据可以是特定搜索环境下的语料数据,例如商品搜索系统中所有商品的名称、详细描述、标签、商品提供方名称等,也可以是日常常见的语料数据,如新闻、小说、传记等。举例说明,若存在一语料库,包括语料AA、AB、AC、ABC和ABCD,则在A的条件下下一单词是A的数量为1,而语料库中以A开头的单词的数量为5,因此,A-A的概率为1/5,即0.2,相应地,A-C的概率为0.2;A-B(P(B|A))的概率为0.6;A-B-C(P(C|AB))的概率为1;A-B-C-D(P(D|ABC))的概率为1,因此,A-A的概率、A-C的概率、A-B(P(B|A))的概率、A-B-C(P(C|AB))的概率、A-B-C-D(P(D|ABC))的概率就构成了一参考 概率表。
切分子模块141用于对分词效果不好的分词输入进行全切分得到基础分词词组,假如分词效果不好的分词输入为“智能分词”,进行全切分后得到的基础分词词组为由基础分词“智”、“能”、“分”、“词”、“智能”、“能分”、“分词”、“智能分”、“能分词”和“智能分词”构成的基础分词词组。
过滤子模块143用于根据使用参考概率表的Z分词过滤算法对切分子模块141全切分后得到的基础分词词组进行过滤得到新词词组,并将该新词词组更新到分词词库中,具体地,该过滤子模块143包括:
扫描单元,用于扫描该基础分词词组并获取该基础分词词组中基础分词共有但未包含在该基础分词词组中的前向词列表;
第一判断单元,用于判断该前向词列表的长度是否大于第一变量i,其中,该第一变量i的初始值为0。
第一添加单元,用于在判断该前向词列表的长度大于第一变量i时,从参考概率表中查询前向词列表中第i个前向词的概率,并在判断该第i个前向词的概率存在或者大于或等于预设的第一阈值a时,将该第i个前向词添加到基础分词词组中;第一自加单元,用于在判断该第i个前向词的概率不存在或者小于预设的第一阈值a时,或者在将该第i个前向词添加到该基础分词词组后,第一变量i自加。第一自加单元的输出端与第一判断单元的输入端连接,在该第一变量i自加后,第一变量i的值为1,输出到第一判断单元时,第一判断单元重新判断,以此重复循环,将前向词列表中的能从参考概率表中对应查询到概率不存在或者小于第一阈值a的前向词添加到基础分词词组中,以进行判断后扫描获取具有前向关系的词组的集合。
第二扫描单元,用于在判断该前向词列表的长度小于或等于该第一变量i时,扫描该基础分词词组,获取具有前向关系的词组的集合,其中,具有前向关系的词组表示为{A,B},A为第一词元,B为第二词元;
第二判断单元,用于判断该集合的大小是否小于第二变量j,其中,第二变量j的初始值为0。
第二添加单元,在判断该集合的大小小于第二变量j时,取出该集合中第j个词组中的第一词元A和第二词元B,并从参考概率表中查询P(A)和P(AB),并计算P(B|A);在判断P(B|A)小于预设的第二阈值b时,判断该第二词元B是否已经存在于分词词库中,若否,则将该第二词元B添加到该基础分词词组。第二自加单元,用于在判断P(B|A)大于或等于预设的第二阈值b时,或者在判断第二词元B已经存在于分词词库中时,或者将第二词元B添加到该基础分词词组后,第二变量j自加。第二自加单元的输出端与第二判断单元的输入端连接,在该第二变量j自加后,第二变量j的值变为1,输出到第二判断单元时,第二判断单元重新判断,以此重复循环,将该集合中的能从参考概率表中对应查询到概率小于第二阈值b且不存在分词词库中的第二词元添加到基础分词词组中,以进行判断后将该基础分词词组进行排重后得到的新词词组添加到分词词库中,进而实现了分词效果不好的分词输入的过滤,将得到的新词词组添加到分词词库,实现了分词词库的更新。
第三添加单元,用于在判断该集合的大小大于或等于第二变量j时,将该基础分词词组进行排重后得到的新词词组添加到分词词库中。
在本实施例中,第一阈值a和第二阈值b是可配置的,并且根据实际情况进行调整和优化。
如图2所示,是本发明的分词词库更新方法实施例的流程图。该方法始于步骤S1。
在步骤S1中,采集分词业务系统在运行过程中输出的分词业务日志;在此步骤中,分词业务系统是指应用分词功能的系统,包括搜索系统,此时,搜索系统在运行过程中输出的分词业务日志为搜索服务日志,包括用户的搜索输入、该搜索系统返回的结果以及用户对搜索结果的浏览和订购行为等。
在步骤S2中,对日志采集模块采集到的分词业务日志进行统计分析,并提取相关有效数据。在此步骤中,以分词业务系统包括搜索系统为例,该有效数据包括搜索结果的订购次数或者浏览次数和/或搜索关键词的转换率和/或搜索结果的首页命中比例和/或搜索关键词的召回率和/或分词输入的分词结果,其中,搜索结果的订购次数或者浏览次数表示针对某个搜索词,用户的订购次数 或者浏览详情页的次数;搜索关键词的转化率表示针对某个搜索词,用户浏览详情页的次数或者订购次数与搜索次数的比例值;搜索结果的首页命中比例表示针对某个搜索词,用户在搜索结果的首页获得到所需要的结果的次数与搜索次数之间的比例值;搜索关键词的召回率表示针对某个搜索关键词,搜索系统返回的结果的个数;分词输入的分词结果表示针对用户输入搜索关键词最终的分词结果中的单词个数。
在步骤S3中,根据评价规则对相关有效数据进行评价得到分词效果不好的分词输入,其中,评价规则为预先设置的,根据相关有效数据的种类来确定评价规则的数目,以分词业务系统包括搜索系统为例,评价规则包括搜索关键词的转换率小于第一预设阈值和/或搜索结果个数小于第二预设阈值和/或使用量小于预设阈值和/或分词输入的分词结果大于第三预设阈值,其中,根据搜索关键词的转换率小于第一预设阈值和/或搜索结果个数小于第二预设阈值进行评价得到的有效数据是搜索关键词,使用量包括商品详情页的浏览量和订购量,根据使用量小于预设阈值这一评价规则来进行评价得到的有效数据是热门搜索记录,例如,搜索的商品名称、标签、详细描述等。
在步骤S4中,对上述步骤S3所得到的分词效果不好的分词输入进行分词校正和过滤输出新词词组,并将该新词词组更新到分词词库中。至此,实现了分词词库的更新,不断完善了分词词库,此时,分词业务系统可定期加载更新后的分词词库,进而可继续进行分词服务,能快速进行更新。需要说明的是,在发明中分词输入是指在分词业务系统中所有需要分词的数据,例如,在搜索索引创建过程中需要分词的数据,如商品的名称、描述等,以及在搜索过程中需要分词的用户的输入等。
具体地,参考图3,在本实施例中,上述步骤S4包括:
在步骤S41中,扫描语料数据,并计算每个单词到下一个单词的概率来构造一参考概率表,需要说明的是,语料数据可以是特定搜索环境下的语料数据,例如商品搜索系统中所有商品的名称、详细描述、标签、商品提供方名称等,也可以是日常常见的语料数据,如新闻、小说、传记等。举例说明,若存在一语料库,包括语料AA、AB、AC、ABC和ABCD,则在A的条件下下一单词是 A的数量为1,而语料库中以A开头的单词的数量为5,因此,A-A的概率为1/5,即0.2,相应地,A-C的概率为0.2;A-B(P(B|A))的概率为0.6;A-B-C(P(C|AB))的概率为1;A-B-C-D(P(D|ABC))的概率为1,因此,A-A的概率、A-C的概率、A-B(P(B|A))的概率、A-B-C(P(C|AB))的概率、A-B-C-D(P(D|ABC))的概率就构成了一参考概率表。
在步骤S42中,对分词效果不好的分词输入进行全切分得到基础分词词组,假如分词效果不好的分词输入为“智能分词”,进行全切分后得到的基础分词词组为由基础分词“智”、“能”、“分”、“词”、“智能”、“能分”、“分词”、“智能分”、“能分词”和“智能分词”构成的基础分词词组。
在步骤S43中,根据使用参考概率表的Z分词过滤算法对全切分后得到的基础分词词组进行过滤得到新词词组,并将该新词词组更新到分词词库中。
具体地,参考图3,在本实施例中,上述步骤S43包括:
在步骤S431中,扫描该基础分词词组并获取该基础分词词组中基础分词共有但未包含在该基础分词词组中的前向词列表;在步骤S432中,判断该前向词列表的长度是否大于第一变量i,其中,该第一变量i的初始值为0,若是,则执行步骤S433,若否,则执行步骤S435。在步骤S433中,从参考概率表中查询前向词列表中第i个前向词的概率,并在判断该第i个前向词的概率存在或者大于或等于预设的第一阈值a时,将该第i个前向词添加到基础分词词组中。在步骤S434中,在判断该第i个前向词的概率不存在或者小于预设的第一阈值a时,或者在将该第i个前向词添加到该基础分词词组后,第一变量i自加,并在该第一变量i自加后,第一变量i的值变为1,重复上述步骤S432至步骤S434。以此重复循环,将前向词列表中的能从参考概率表中对应查询到概率不存在或者小于第一阈值a的前向词添加到基础分词词组中,以进行判断后扫描获取具有前向关系的词组的集合。
在步骤S435中,扫描该基础分词词组,获取具有前向关系的词组的集合,其中,具有前向关系的词组表示为{A,B},A为第一词元,B为第二词元。
在步骤S436中,判断该集合的大小是否小于第二变量j,其中,该第二变量j的初始值为0,若是,则执行步骤S437,若否,则执行步骤S439。在步骤S437 中,取出该集合中第j个词组中的第一词元A和第二词元B,并从参考概率表中查询P(A)和P(AB),并计算P(B|A);在判断P(B|A)小于预设的第二阈值b时,判断该第二词元B是否已经存在于分词词库中,若否,则将该第二词元B添加到该基础分词词组。在步骤S438中,在判断P(B|A)大于或等于预设的第二阈值b时,或者在判断第二词元B已经存在于分词词库中时,或者将第二词元B添加到该基础分词词组后,第二变量j自加,并在该第二变量自加后重复上述步骤S436至步骤S438。以此重复循环,将该集合中的能从参考概率表中对应查询到概率小于第二阈值b且不存在分词词库中的第二词元添加到基础分词词组中,以进行判断后将该基础分词词组进行排重后得到的新词词组添加到分词词库中,进而实现了分词效果不好的分词输入的过滤,将得到的新词词组添加到分词词库,实现了分词词库的更新。在步骤S439中,将该基础分词词组进行排重后得到的新词词组添加到分词词库中。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。最后对本发明中的一些符号进行说明,P(A)表示A发生的概率;P(A|B)表示在B发生的条件下,A发生的概率;P(AB)表示AB同时发生的概率。
- 还没有人留言评论。精彩留言会获得点赞!