一种安全生产大数据挖掘系统的制作方法
本发明涉及安全生产技术数据领域,特别涉及一种能够有效及时排查事故隐患、降低事故发生的安全生产大数据挖掘系统。
背景技术:
近年来,随着信息技术的高速发展,数据量呈爆炸性增长。安全生产行业数据量增长也呈现出相似的态势,在数据增长过程中发生的事故隐患凸显严重,如何从海量数据中识别出有用的数据,分析潜在事故隐患,已经成为安全生产行业当务之急。目前,安全生产企业事故隐患排查工作主要靠人工,通过数据挖掘人员利用专业知识发现生产中存在的安全隐患,过程显得复杂,因此,这种方式易受到主观因素影响,且很难界定安全与危险状态,可靠性差。
可见在整个数据挖掘过程中,由于安全生产事故隐患数据量大、数据类型繁多不一、价值密度低、处理速度慢,人工无法准确在当前条件下对数据内容进行检索和管理,缺乏对来自不同数据源的离散数据集中分析的问题,安全事件数据库信息难以人为管理。且每个数据库之间的衔接、数据传递和交互很容易出现问题,无法保证有价值的数据得到提取,且数据挖掘效率低。
通过大数据挖掘系统预测隐患事故,防范事故发生是一个亟待解决的难题。如何实现高效率、高准确、高价值的大数据挖掘?提取有价值的信息?针对以上问题,本发明提供了一种安全生产大数据挖掘系统。
技术实现要素:
现有安全生产事故隐患排查主要靠人工完成,通过数据挖掘人员利用专业知识发现生产中存在的安全隐患。面对海量数据,人工操作过程复杂,海量数据对比丧失正确性。无法正确的挖掘出有用的信息,很难界定隐患事故的安全与危险状态。
针对以上问题,本发明提供一种安全生产大数据挖掘系统,以解决现有技术中数据挖掘过程中无法保证数据对比正确性及整个挖掘过程效率低的问题。
本发明提供一种安全生产大数据挖掘系统,如图1所示大数据挖掘过程包括:数据抽取模块101,用于获取数据库中关键数据信息,对每个数据信息进行唯一的编号ID;数据预处理模块102,用于对从数据库中获取的数据信息进行预处理的数据预处理模块;数据挖掘模块103,用于对数据进行运算然后实现挖掘;数据分析模块104,用于对数据挖掘模块挖掘出来的结果进行分析;输出模块105,用于将分析后的结果显示输出。
本发明所述数据抽取模块101,利用数据访问接口规定的数据源和访问方法,从不同的平台和不同的应用中抽取数据,存入系统中,为数据挖掘提供数据来源。采用任务平衡和多线程机制进行,并且在抽取到的数据上增加索引。
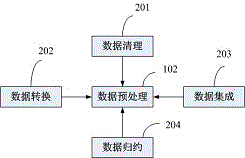
本发明所述数据预处理模块102中包括用于填补遗漏的数据值、平滑有噪声的数据、识别或去除异常值的数据清理模块201;用于对数据信息进行编码处理,将数据库中字段的不同取值转换成数码形式,以便于搜索的数据转换模块202;用于将来自多个数据库数据合并到一起的数据集成模块203;用于在不影响最终挖掘结果的情况下减小数据挖掘的范围,以提高效率的数据规约模块204。
本发明所述数据挖掘模块103设有加权平均法处理模块、卡尔曼滤波处理模块、统计决策处理模块以及神经网络处理模块。
本发明所述数据分析模块104包括用于获取计算模型输出结果的数据取值模块;用于对数据取值模块获取数据进行有效范围选择的数据选择模块、用于对选择后数据进行聚类分配的聚类分配模块、用于对聚类分配后数据进行分析的数据分析模块以及用于输出数据分析结果的显示输出模块。
本发明与现有技术相比,能够减少人工的参与量,对事故隐患数据库中输入的数据进行多层面、全方位的挖掘处理,并将挖掘结果进一步结构分析后,进行分类、可视化等处理,具有高效率、高准确、高价值等优点。
通过本发明安全生产大数据挖掘系统对安全生产事件信息的收集整理、统一存储,从原始安全生产事件信息数据库中发掘高质量的安全数据信息,自动做出响应,根据事故隐患严重程度给用户提供最为准确的安全隐患信息,以最大化的减少隐患的危害对安全生产产生的负面影响。使用户能有效监控和管理其不断扩大的安全事故隐患,而无需配备更多专业安全人员。
附图说明
图1是根据本发明实施例提供的一种安全生产大数据挖掘的过程图。
图2是根据本发明实施例提供的一种安全生产大数据挖掘预处理框架图。
具体实施方式
下文与图示本发明原理的附图一起提供对本发明一个或者多个实施例的详细描述。结合这样的实施例描述本发明,但是本发明不限于任何实施例。本发明的范围仅由权利要求书限定,并且本发明涵盖诸多替代、修改和等同物。在下文描述中阐述诸多具体细节以便提供对本发明的透彻理解。出于示例的目的而提供这些细节,并且无这些具体细节中的一些或者所有细节也可以根据权利要求书实现本发明。
下面结合附图对本发明作进一步的说明。
如附图1大数据挖掘步骤所示,本发明提出了一种安全生产大数据挖掘系统,其特征在于数据抽取模块101,用于获取数据库中关键数据信息,对每个数据信息进行唯一的编号ID;数据预处理模块102,用于对从数据库中获取的数据信息进行预处理的数据预处理模块;数据挖掘模块103,用于对数据进行运算然后实现挖掘;数据分析模块104,用于对数据挖掘模块挖掘出来的结果进行分析;结果输出105,用于将分析后的结果显示输出。
本发明所述数据抽取模块101,利用数据访问接口规定的数据源和访问方法,从不同的平台和不同的应用中抽取数据,存入系统中,为数据挖掘提供数据来源。采用任务平衡和多线程机制进行,并且在抽取到的数据上增加索引。
本发明所述数据预处理模块102中包括用于填补遗漏的数据值、平滑有噪声的数据、识别或去除异常值的数据清理模块201;用于对数据信息进行编码处理,将数据库中字段的不同取值转换成数码形式,以便于搜索的数据转换模块202;用于将来自多个数据库数据合并到一起的数据集成模块203;用于在不影响最终挖掘结果的情况下减小数据挖掘的范围,以提高效率的数据约束模块204。
所述数据清理模块201,填充缺失的值,光滑噪声并识别离群点,纠正数据库中数据的不一致性。第一步偏差检测,清理每个属性的定义域和数据类型、每个属性可接受的值、值的长度范围,查看是否所有的值都落在期望的值域内、属性之间是否存在已知的依赖;第二步纠正偏差,纠正数据的不一致。偏差检测与纠正偏差过程迭代执行。
所述数据集成模块202,将多个数据库运行环境中的异构数据进行合并,存放在一致的数据库存储中,属性在不同的数据库中设置相同的名称;设置统一的属性定义域;给定每个属性数据类型和取值范围;给定所有的值都落在期望的值域。
所述数据变换模块203,通过将数据库中属性值按比例缩放,使之落入一个特定区间,使用神经网络算法进行分类挖掘,对数据元组中量度的每个属性输入值进行规范化。
所述数据规约模块204用于在不影响最终挖掘结果的情况下减小数据挖掘的范围,以提高挖掘效率。其中包括用于通过离散化数值属性以及泛化字符型属性值来规约数据库中元组的元组规约模块;用于在安全生产海量数据挖掘之前,对属性进行分析、删除与分析任务不相关或不重要属性的属性规约。
本发明所述数据挖掘模块103设有加权平均法处理模块、卡尔曼滤波处理模块、统计决策处理模块以及神经网络处理模块。
本发明所述数据分析模块104包括用于获取计算模型输出结果的数据取值模块;用于对数据取值模块获取数据进行有效范围选择的数据选择模块、用于对选择后数据进行聚类分配的聚类分配模块、用于对聚类分配后数据进行分析的数据分析模块以及用于输出数据分析结果的显示输出模块。
显然,本领域的技术人员应该理解,上述的本发明的各模块或各步骤可以用通用的计算系统来实现,它们可以集中在单个的计算系统上,或者分布在多个计算系统所组成的网络上,可选地,它们可以用计算系统可执行的程序代码来实现,从而,可以将它们存储在存储系统中由计算系统来执行。这样,本发明不限制于任何特定的硬件和软件结合。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 还没有人留言评论。精彩留言会获得点赞!