一种高效的新术语识别系统和方法与流程
本发明涉及汉语自然语言处理、汉语新词语自动识别领域,特别是涉及一种新术语自动识别系统和方法。
背景技术:
伴随互联网的快速发展,各类新术语层出不穷,这个自然语言处理应用、自动应用软件(如分词系统)、词典收编工作灯带来很大的困难。
新术语识别的研究已经展开了多年。现存的方法有以下三类。第一基于统计的方法。例如,Kenneth Ward Church和Béatrice Daille等人使用互信息(Mutual Information)来抽取词语的固定组合和搭配,他们认为频繁共现的邻近字符组合一般都是术语,然后使用互信息判断词组的共现程度。又如,Ted Dunning和Jonathan D.Cohen等人采用用对数似然比(Log-Likelihood Ratio)来统计低频词语的识别问题,从理论和事实两方面论证了这种方法的有效性。统计方法还包括条件随机场方法、隐马尔科夫方法、最大熵方法等。第二是基于语言学特征和词法模式的方法。例如,刘磊、王石和田国刚采用多特征,结合词法和句法模式,获得新的专业术语。第三是前两种方法的集成应用,因而克服了各自的不足。
但是,经过详细的实验分析,上述方法存以下两个问题。
问题1:新术语识别精度问题。采用纯统计的方法,虽然能识别较多地新术语,但是通常会引入大量的错误;也即,不是新术语的汉字串,被误以为是新术语。例如,在语句“总部组织干部学习中央精神”中,采用统计方法时,很容易就将“总部组织干部”、“组织干部”、“干部学习”等误识为新术语,而本质上,它们均不是。另一方面,要确保新术语额度识别精度很高,识别广度又受到限制。这是本发明需要解决的关键问题之一。
问题2:新术语识别广度问题。由于词语的组合情况很多,因此新术语自动识别很容易遗漏掉新有意义的术语。因此,如何提高识别广度是一个重要的问题。这也是本发明需要解决的关键问题之一。
技术实现要素:
本发明所要解决的技术问题:新术语识别精度问题、识别广度问题。
针对问题1,本发明引入了种子术语词典技术,不仅利用种子词典进行新术语的识别, 同时也用它来验证新获得的新术语。
针对问题2,本发明引入了多源迭代式新术语识别技术。首先,采用多源分析方法,根据多个文本进行比照验证,提升新术语的识别精度;同时将获得的新术语加入到种子术语词典中,不断地循环使用,从而获得更多的新术语。
为了实现上述目的,本发明提供了如下技术方案:一种高效的新术语识别系统,其特征在于:包括对输入文本库RCorpus中的每篇文档进行分词,形成文本词序列模块A;对分词后的文本库TCorpus中的每篇文档词语序列进行新术语识别模块B;对识别的新术语进行验证模块C;
上面所述模块中,模块A对输入文本库RCorpus中的每篇文挡进行分词,形成分词后的文本词序列,因此形成分词后的文本库TCorpus,供新术语识别模块B使用;新术语识别模块B对分词后的文本库TCorpus中的每篇文档进行新术语识别,形成一组待验证的新术语结果,供验证模块C使用;验证模块C对新术语识别模块B识别的新术语进行进一步的验证。
一种高效的新术语识别方法,其特征在于:包括以下步骤:
第一步:文本词序列模块A对输入文本库RCorpus中的每篇文本进行分词,形成文本词序列;
我们采用一个开源的ICTCLAS系统对RCorpus中的每篇输入文本D进行分词,分词结果为T′=W1/pos1W2/pos2…Wi/posi…Wn/posn,其中每个Wi是一个汉语词、汉字、标点符号、阿拉伯数字、英文单词或字母,posi是其对应的词性;
为了表示区别,RCorpus中的每篇文本文本经过分词后,所产生的文本,我们记为TCorpus;
第二步:新术语识别模块B对分词后的文本库TCorpus中的每篇文本词语序列进行新术语识别;
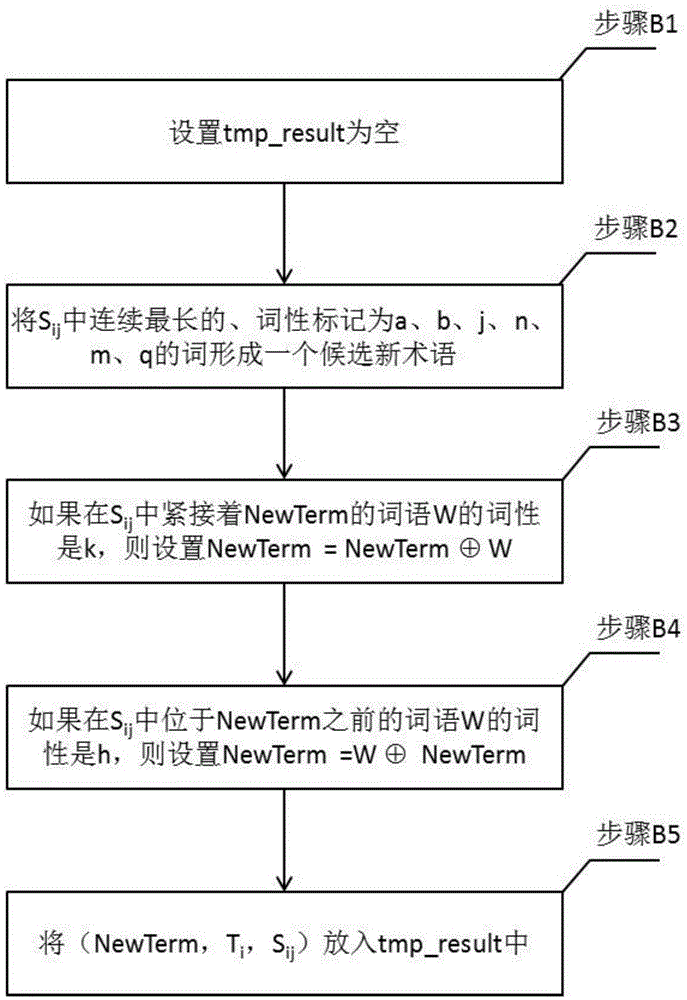
当前待识别文本为Di,Ti为它的标题,Sij为Di的当前待识别的第j条语句;对Sij进行以下步骤的处理,形成候选的新术语结果,存放在集合tmp_result中:
步骤B1:设置tmp_result为空;
tmp_result用于存放识别出的新术语结果,传递给验证模块C进行验证。因此,tmp_result中的新术语结果也称候选的新术语结果,也称待验证的新术语结果;
步骤B2:将Sij中连续最长的、词性标记为a、b、j、n、m、q的词形成一个候选新术语,记为NewTerm;所述“连续最长”,是指在Sij中NewTerm的两端没有词性为a、b、j、n的词;
步骤B3:如果在Sij中紧接着NewTerm的词语W的词性是k,即W可能是NewTerm的后缀, 则设置
步骤B4:如果在Sij中位于NewTerm之前的词语W的词性是h,即W可能是NewTerm的后缀,则设置
步骤B5:将(NewTerm,Ti,Sij)放入tmp_result中;
第三步:验证模块C对识别的新术语进行验证;
验证模块C的主要工作是采用多源验证法、特殊验证法,对新术语识别模块B产生的tmp_result中的新术语进行验证,验证过的新术语放入集合result中;验证模块C的方法如下:
步骤C1:设置result为空;
步骤C2:对tmp_result中的每一对(NewTerm,Ti,Sij)循环做以下步骤C3、C4和C5;
步骤C3:如果在tmp_result中存在(NewTerm,Ti′,Sij′),并且Ti与Ti′不同“即NewTerm出现在TCorpus中的两篇不同的文本中”,则将NewTerm放入result中;否则,执行步骤C4;
如上述步骤C3中所述,尽管NewTerm在题名为Ti的语句Sij中被识别为候选新术语,但是NewTerm并不一定就是一个正确的新术语;但是,在题名为Ti′的语句Sij′中也被识别为新术语,则NewTerm是正确的新术语的可能性会大大提升;
步骤C4:如果在种子词典中存在一个种子术语Term,使得NewTerm与Term的加权相似度wsim(NewTerm,Term)>α,其中α∈[0,1]为一个阈值),则将NewTerm放入result中;否则,执行步骤C5;
为给出两个术语的加权相似度wsim(NewTerm,Term)的计算,我们先给出函数2gram的计算方法;对一个非空汉字串Sent=C1C2…Ci-1Ci…CK-1CK,其中Ci为汉字、数字、英文字母,我们引入一个带头尾标记的汉字串Sent=$C1C2…Ci-1Ci…CK-1CK$;2gram(Sent)是一个由Sent中自左向右连续的两个字符构成的集合,即2gram(Sent)={$C1,C1C2,…,Ck-1CK,CK$};
需要指出的是,2gram(Sent)中各个元素的重要性不相同:Ci-1Ci是汉语中的一个词时,Ci-1Ci在2gram(Sent)的作用更大;为了反映出2gram(Sent)中各个元素的重要性,对前面定义的Interset(S1,S2)进行改进,引入一个新的基数,叫作加权交集基数WInterset(S1,S2);其计算方法如下:对给定了两个集合S1和S2:
(1)WInterset(S1,S2)=0;
(2)对Interset(S1,S2)每一个元素e,如果e是汉语中的一个词,则WInterset(S1,S2)=WInterset(S1,S2)+1.2,即WInterset(S1,S2)累加1.2,而不是1;否则WInterset(S1,S2)= WInterset(S1,S2)+1,即WInterset(S1,S2)累加1;
wsim(NewTerm,Term)的计算方法如下:
(1)如果NewTerm与Term具有相同的前缀和后缀,wsim(NewTerm,Term)=1;
(2)如果NewTerm与Term不具有相同的前缀和后缀,
步骤C5:利用NewTerm在Sij的语境进行验证;具体方法是:当NewTerm在Sij前面的分词的词性为c、d、p、r、u、z之一,并NewTerm在Sij后面的分词的词性为c、d、p、r、u、z之一时,NewTerm是一个正确的新术语,加入到result中;否则放弃,即不加入到result中;
步骤C6:输出result做为最后结果。
有益效果:本发明提出了一种精度高、召回率高的新术语识别方法和系统。在经过多达2GB页面语料的测试中,除了新闻领域,也涵盖各种行业和专业领域。新术语的识别精度为93.8%。因此,本发明取得了较好的识别性能,已经达到了实际应用的目的,为词典编撰、分词应用、文本分类、舆情分析、广告分析等大量的应用,奠定了坚实的基础。
附图说明
图1是本发明的新术语识别系统的工作流程图;
图2是模块B的工作方法示意图;
图3是模块C的工作方法示意图。
具体实施方式
为了能够更清楚的说明本发明,以下定义并解释如下的术语:
(1)词长:即词的长度。一个汉语词由一个或多个汉字做成,一个词的长度等于该词所含的字的个数。词长为1的词称为一字词,词长为2的词称为二字词,词长为3的词称为三字词,以此类推。
(2)多字词:由词长为3或以上的汉字组成、具有一定意义的词称为多字词,例如“中共精神”、“正能量”,其中前者为四字词,后者为三字词。
(3)词典:由一组词构成的词的列表,其中的词可以是单字词(即词长为1)、二字词(即词长为2)或多字词。
(4)新术语:给定一个术语词典,不在此词典出现的术语称为新术语,也称未收录术语。
(5)文本词序列、语句词序列:对一个文本进行分词,形成一个词的序列,称为文 本词序列,简称词序列。当文本是一个语句时,我们有时也称语句词序列。在上下文清晰的情况下,我们也将语句词序列简称为词序列。
(6)ICTCLAS系统:一个免费的、开源的分词系统。该系统以文本为输入,输出为该文本的分词序列。ICTCLAS系统下载网址为:http://ictclas.nlpir.org。分词后,每个分词标有词性,其中a表示形容词、b表示区别词、c表示连词、d表示副词、h表示前缀词、j表示简称词、k表示后缀词、m表示数词、n表示名词、p表示介词、q表示量词、r表示代词、u表示助词、z表示状态词,等等。
(7)文本:无论是一个短的语句,还是长的文章,我们都统称文本。为了简单起见,在说明书中,凡是我们提到的网页,在无其他特别解释的情况下,均指经过去除HTML标签、CSS代码(即层叠样式表,英文全名Cascading Style Sheets)、DIV代码(即层叠样式表中的定位技术,英文全名Division)和JS代码(英文全名javascripts)等所得到的纯文本。
(8)字符串拼接:给定任意两个字符串V1和V2,V1和V2的拼接为将它们无缝连接在一起得到的新的字符串,记为例如,V1=泛,V2=分析,
(9)集合的交集、并集、基数:给定两个集合S1和S2,它们的并集记为Interset(S1,S2),是由那些出现在S1中而同时也出现在S2中的元素构成的集合。例如,S1={笔记本,电脑},S2={笔记本,电脑,4G},则Interset(S1,S2)={笔记本,电脑}。既然出现在S1或者出现在S2中的元素构成的集合为S1和S2的并集,记为Union(S1,S2)。例如,S1={笔记本,电脑},S2={笔记本,电脑,4G},则Union(S1,S2)={笔记本,电脑,4G}。集合中元素的个数为集合的基数,S1的基数记为|S1|,例如S1={笔记本,电脑},|S1|=2。
下面结合附图和具体实施方式对本发明作进一步详细地说明。
本发明提出的一种高效的新术语识别系统和方法,以一个文本集RCorpus为输入(称为输入文本库),采用下面三个模块进行工作:
模块A:对输入文本库RCorpus中的每篇文本进行分词,形成文本词序列。
模块B:对分词后的文本库TCorpus中的每篇文本词语序列进行新术语识别。
模块C:对识别的新术语进行验证。
模块A:对输入文本库RCorpus中的每篇文本进行分词,形成文本词序列。
我们采用一个开源的ICTCLAS系统对RCorpus中的每篇输入文本D进行分词,分词结果为T′=W1/pos1W2/pos2…Wi/posi…Wn/posn,其中每个Wi是一个汉语词、汉字、标点符号、阿拉伯数字、英文单词或字母,posi是其对应的词性。
在分词中,词性的标记已经在计算机界通行。通常的词性有n(名称)、v(动词)、a(形容词)、d(副词)、p(介词)等。例如,语句“总部组织干部学习中央精神”的分词结果为:“总部/n组织/n干部/n学习/v中央/n精神/n”。
为了表示区别,RCorpus中的每篇文本经过分词后,所产生的文本,我们记为TCorpus。
模块B:对分词后的文本库TCorpus中的每篇文本词语序列进行新术语识别。
模块B的具体实施,如下所述:
假设当前待识别文本为Di,Ti为它的标题,Sij为Di的当前待识别的第j条语句。对Sij进行以下步骤的处理,形成候选的新术语结果(也称待验证的新术语结果),存放在集合tmp_result中:
步骤B1:设置tmp_result为空。
tmp_result用于存放识别出的新术语结果,传递给验证模块C进行验证。因此,tmp_result中的新术语结果也称候选的新术语结果(也称待验证的新术语结果)。
步骤B2:将Sij中连续最长的、词性标记为a、b、j、n、m、q的词形成一个候选新术语,记为NewTerm。
步骤B2中所述“连续最长”,是指在Sij中NewTerm的两端没有词性为a、b、j、n的词。
步骤B3:如果在Sij中紧接着NewTerm的词语W的词性是k(即W可能是NewTerm的后缀),则设置
步骤B4:如果在Sij中位于NewTerm之前的词语W的词性是h(即W可能是NewTerm的后缀),则设置
步骤B5:将(NewTerm,Ti,Sij)放入tmp_result中。
模块C:对识别的新术语进行验证。
本模块的主要工作是采用多源验证法、特殊验证法,对模块B产生的tmp_result中的术语进行验证,验证过的新术语放入集合result中。模块C的方法如下:
步骤C1:设置result为空。
步骤C2:对tmp_result中的每一对(NewTerm,Ti,Sij)循环做以下步骤C3、C4和C5。
步骤C3:如果在tmp_result中存在(NewTerm,Ti′,Sij′),并且Ti与Ti′不同(即NewTerm出现在TCorpus中的两篇不同的文本中),则将NewTerm放入result中;否则,执行步骤C4。
如上述步骤C3中所述,尽管NewTerm在题名为Ti的语句Sij中被识别为候选新术语,但是NewTerm并不一定就是一个正确的新术语。但是,在题名为Ti′的语句Sij′中也被识别为新 术语,则NewTerm是正确的新术语的可能性会大大提升。(当然,如果还存在第三个不同的文本来辅助验证NewTerm,NewTerm是正确的新术语的可能性会更高,但是这样会降低新术语识别的宽带,实验表明,不需要第三个不同文本的验证。)
步骤C4:如果在种子词典中存在一个种子术语Term,使得NewTerm与Term的加权相似度wsim(NewTerm,Term)>α(α∈[0,1]为一个阈值),则将NewTerm放入result中;否则,执行步骤C5。
为给出两个术语的加权相似度wsim(NewTerm,Term)的计算,我们先给出函数2gram的计算方法。对一个非空汉字串Sent=C1C2…Ci-1Ci…CK-1CK,其中Ci为汉字、数字、英文字母,我们引入一个带头尾标记的汉字串Sent=$C1C2…Ci-1Ci…CK-1CK$。2gram(Sent)是一个由Sent中自左向右连续的两个字符构成的集合,即2gram(Sent)={$C1,C1C2,…,Ck-1CK,CK$}。
需要指出的是,2gram(Sent)中各个元素的重要性相同:Ci-1Ci是汉语中的一个词时,Ci-1Ci在2gram(Sent)的作用更大。为了反映出2gram(Sent)中各个元素的重要性,本发明对前面定义的Interset(S1,S2)进行改进,引入一个新的基数,叫作加权交集基数WInterset(S1,S2)。其计算方法如下:对给定了两个集合S1和S2:
(1)WInterset(S1,S2)=0;
(2)对Interset(S1,S2)每一个元素e,如果e是汉语中的一个词,则WInterset(S1,S2)=WInterset(S1,S2)+1.2(即WInterset(S1,S2)累加1.2,而不是1);否则如果e不是一个汉语中的词,则WInterset(S1,S2)=WInterset(S1,S2)+1(即WInterset(S1,S2)累加1);
wsim(NewTerm,Term)的计算方法如下:
(1)如果NewTerm与Term具有相同的前缀和后缀,wsim(NewTerm,Term)=1;
(2)如果NewTerm与Term不具有相同的前缀和后缀,
对上述公式的第一种情形,我们给出一个例子做为解释。令NewTerm=“中共十八大第四次会议”,Term=“中共洛川会议”。此时wsim(“中共十八大第四次会议”,“中共洛川会议”)=1,因为Term和NewTerm有共同的前缀和后缀。
步骤C5:利用NewTerm在Sij的语境进行验证。具体方法是:当NewTerm在Sij前面的分词的词性为c、d、p、r、u、z之一,并NewTerm在Sij后面的分词的词性为c、d、p、r、u、z之一时,NewTerm是一个正确的新术语,加入到result中;否则放弃,即不加入到result中。
步骤C6:输出result做为最后结果。
实验效果
本发明提出了一种高效的多字新术语识别方法和系统。在经过多达2GB页面语料的测试中,除了新闻领域,也涵盖各种行业和专业领域。在计算新术语与词典中的种子术语的相似度wsim(NewTerm,Term)时,反复实验表明α=0.6时结果最好,此时多字新术语的识别精度为93.8%。因此,本发明取得了较好的识别性能,已经达到了实际应用的目的,为词典编撰、分词应用、文本分类、舆情分析、广告分析等大量的应用,奠定了坚实的基础。
- 还没有人留言评论。精彩留言会获得点赞!