一种获取词语的方法及装置与流程
本发明涉及计算机技术领域,尤其涉及一种获取词语的方法及装置。
背景技术:
随着网络技术的发展,数据信息的规模越来越庞大,要从中获取到有用的数据信息就需要更加有效的文本分类技术。而现有的一些成熟文本分类技术对于英文文本的应用效果相对理想,而对于中文文本的分类效果并不理想。究其原因,其中中文文本中的语义因素的作用是不容忽视的。最为基础的语义关系有两类:1、上位概念和下位概念之间的关系,下位概念的出现仅仅是为了限定上位概念的外延;2、述谓关系,这是最多也最基础的关系。一个基本词汇单位对另一个基本词汇单位的陈述。而语法形式则大部分是为了表达这些关系而产生的。
在上位和下位概念的关系中,最为常见的就是整体与部分的关系:整体通常有一个结构,它们的组成部分是可分离的并且有特定的功能。目前的分本分类处理中,提取整体与部分关系词语的方式一般都是基于一些固定的模式,包括词汇、句法模式来确定词语间的整体与部分关系。例如,基于并列结构的从网页中获取部分整体关系的方法,利用整体与部分关系模式从Google获取语料,匹配出具有并列结构的句子,从中获取出给定的整体概念的部分概念,用层次聚类算法对候选的部分概念进行自动聚类,以确定具有整体与部分关系的词语。但是,这种并列结构的方式所能够匹配出的语料数据只是在形式上与模板的结构相匹配,而在实际的内容上并非是整体与部分的关系,因此该方式的提取准确率相对较低。
技术实现要素:
有鉴于此,本发明提供一种获取词语的方法及装置,主要目的在于通过词语标注领域信息来提高语料词语间整体与部分关系的提取准确率。
为达到上述目的,本发明主要提供如下技术方案:
一方面,本发明提供了一种获取词语的方法,该方法包括:
对获取的文本数据进行预处理,得到带有分词信息的独立语句;
在所述独立语句中,利用结构模板筛选出具有并列结构的候选语句;
利用领域词典以及所述候选语句中的分词信息,确定所述候选语句中具有并列结构的领域分词,所述领域词典是记录有相同领域分词的词典;
根据所述领域分词的位置特征,输出具有整体与部分关系的领域分词集合。
另一方面,本发明提供了一种获取词语的装置,该装置包括:
预处理单元,用于对获取的文本数据进行预处理,得到带有分词信息的独立语句;
筛选单元,用于在所述预处理单元得到的独立语句中,利用结构模板筛选出具有并列结构的候选语句;
确定单元,用于利用领域词典以及所述候选语句中的分词信息,确定所述筛选单元选择的候选语句中具有并列结构的领域分词;
输出单元,用于根据所述确定单元确定的领域分词的位置特征,输出具有整体与部分关系的领域分词集合。
依据上述本发明所提出的一种获取词语的方法及装置,通过对文本语料进行的分词、分句处理,并利用结构模板筛选出具有并列结构的获选语句。就可以初步选定在给文本语料中为并列结构可能是具有整体与部分关系的候选语句。在利用该候选语句中的分词信息,以及选定的领域词典,判断出具有并列结构的分词是否属于相同的领域,若是,则可以根据分词在句中的位置来确定各个分词之间的整体与部分关系,同时以相对应的关系加以输出显示。相对于现有的判断整体与部分关系所采用的固定模板的比对方式而言,本发明所采用的方法通过对句子中的分词加入进一步的判断,确定具有并列结构的分词是属于同一类领域中的分词,从而能够根据分词的具体内容避免分词提取的形式化。再根据分词之间的位置关系判断哪些分词属于整体领域分词,哪些属于部分领域分词。从而进一步提高分词整体与部分关系的提取准确性。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1示出了本发明实施例提出的一种获取词语的方法的流程图;
图2示出了本发明实施例提出的另一种获取词语的方法的流程图;
图3示出了本发明实施例提出的一种获取词语的装置的组成框图;
图4示出了本发明实施例提出的另一种获取词语的装置的组成框图。
具体实施方式
下面将参照附图更详细地描述本发明的示例性实施例。虽然附图中显示了本发明的示例性实施例,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本发明,并且能够将本发明的范围完整的传达给本领域的技术人员。
本发明实施例提供了一种获取词语的方法,如图1所示,该方法用于获取文本语料中具有整体与部分关系的词语,具体步骤包括:
101、对获取的文本数据进行预处理,得到带有分词信息的独立语句。
在本发明实施例中,获取的文本数据是指用于提取具有整体与部分关系词语的语料数据,具体获取的来源可以从不同的语料库选取不容领域或主题的文本数据。而预处理则是指对大段或整篇的文本进行分割处理,得到便于处理的句子或词组等简短的文本数据。具体的可以是通过分词、分句的文本处理技术进行文本的细分,由于分词、分句技术已经是广泛使用的文本处理技术,因此,本发明实施例对此不做具体说明,同时也不限定具体的分词方式或分句方式。其目的是得到带有分词信息的独立语句。其中,独立语句是具有完成结构或形式的单句,而分词信息则是将该单句进行分词处理后所得到的分词结果,如该单句中有哪些分词,各分词在句中 的位置等信息。
102、利用结构模板筛选出具有并列结构的候选语句。
在步骤101所得到的独立语句中,使用结构模板进行筛选,选出具有并列结构的独立语句。其中,结构模板是预置在系统中用于判断句子结构的模板,在本实施例中,所使用的结构模板是用于判断独立语句中是否具有并列结构的模板。而在一个独立语句中并列结构还包括词的并列和词组的并列,对于具体的并列结构本发明实施例也不做具体限定。只是根据独立语句的句式结构进行判断,将符合并列结构的独立语句确定为候选语句。
103、利用领域词典以及候选语句中的分词信息,确定该候选语句中具有并列结构的领域分词。
领域词典是记录有相同领域分词的词典,由于具有整体与部分关系的分词或词组必然是属于相同的领域,因此,通过判断候选语句中具有并列结构的分词是否属于相同的领域就成为判断这些分词是否能构成整体与部分关系的前提。也就是说,如果两个具有并列结构的分词并不属于同一个领域,则这两个词也不可能具有或与该局中其他分词具有整体与部分的关系。在本步骤中,除了要确定候选语句中具有别列结构的分词所属领域外,还需要确定该局中其他的分词是否属于该领域词典,以便后续根据分词具体的位置信息确定分词之间是否具有整体与部分的关系。
104、根据领域分词的位置特征,输出具有整体与部分关系的领域分词集合。
领域分词的位置特征是在上述分词过程中记录的分词在独立语句中的位置信息,根据不同的位置信息来判断分词之间的整体与部分关系。例如,汽车包括发动机、变速箱和轮胎等,其中,“发动机”、“变速箱”、“轮胎”就是具有并列结构的分词,且这些分词同属于汽车领域,所以,通过判断“汽车”与“发动机”、“变速箱”、“轮胎”的位置关系,可以判断出“汽车”与“发动机”、“变速箱”、“轮胎”是具有整体与部分关系的分词。
在得到文本中所有整体与部分关系的分词组合后,输出包含所有具备整体与部分关系的领域分词集合。
结合上述的实现方式可以看出,本发明实施例所采用的获取词语的方 法,通过对文本语料进行的分词、分句处理,并利用结构模板筛选出具有并列结构的获选语句。就可以初步选定在给文本语料中为并列结构可能是具有整体与部分关系的候选语句。在利用该候选语句中的分词信息,以及选定的领域词典,判断出具有并列结构的分词是否属于相同的领域,若是,则可以根据分词在句中的位置来确定各个分词之间的整体与部分关系,同时以相对应的关系加以输出显示。相对于现有的判断整体与部分关系所采用的固定模板的比对方式而言,本发明实施例所采用的方法通过对句子中的分词加入进一步的判断,确定具有并列结构的分词是属于同一类领域中的分词,从而能够根据分词的具体内容避免分词提取的形式化。再根据分词之间的位置关系判断哪些分词属于整体领域分词,哪些属于部分领域分词。从而进一步提高分词整体与部分关系的提取准确性。
为了更加详细地说明本发明提出的上述获取词语的方法,本发明实施例还提出了一种获取词语的方法,如图2所示,该方法在提取词语时所包括步骤为:
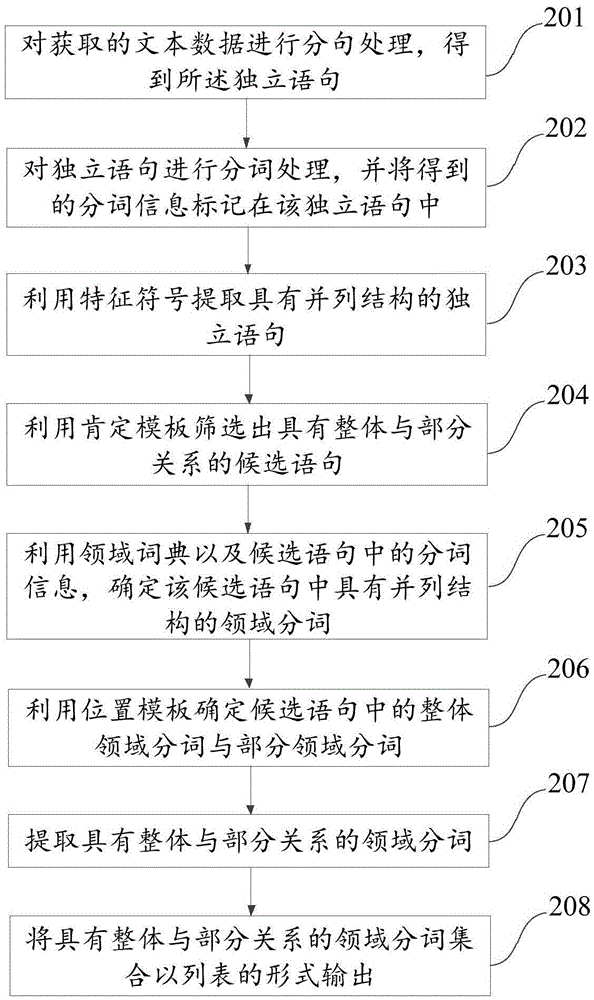
201、对获取的文本数据进行分句处理,得到所述独立语句。
对所获取的文本数据进行分句处理。最简单的方式就是判断文本中的标点符号,将句号、感叹号、问号等能够表示独立语句的符号作为分句的标准,而不能以逗号、顿号、分号等符号进行分句。以此完成对文本的分句处理过程。
202、对独立语句进行分词处理,并将得到的分词信息标记在该独立语句中。
在完成分句处理后,还需要进一步对所得到独立语句进行分词处理,并将分词的结果标记在该独立语句中,以便后续处理的读取调用。其中,分词的结果包括具体的分词以及该分词在独立语句的位置信息。
203、利用特征符号提取具有并列结构的独立语句。
特征符号在本实施例中用于表示独立语句中存在有并列结构,其中该特征符号,可以至少包含下述之一:顿号、逻辑关系符号;例如,顿号可以用“、”表示、逻辑关系符号可以为并列关系符号(可以用“&”表示)、选择关系符号(可以用“‖”表示)等标点或字符。利用特征符号能够将 具有并列结构的独立语句筛选出来。具体的特征符号本发明可以根据实际应用情况选择,对此本发明不进行限定。
204、利用肯定模板筛选出具有整体与部分关系的候选语句。
在具有并列结构的独立语句中,通过肯定模板再选出具有整体与部分关系的独立语句,并定义为候选语句。其中,肯定模板是用于判断独立语句具有整体与部分关系的语句结构。并且,肯定模板中可以包括有多种的语句结构,例如,^(.*?)包括(.*?)、(.*?)、(.*?)$的结构(如手机包括处理器、内存、屏幕、外壳等部件),(.*?)由(.*?)、(.*?)、(.*?)等组成$的结构(如电脑由主机、显示器、鼠标、键盘等组成),(.*?)(为|作为|有|分为)(.*?)、(.*?)、(.*?)$的结构(如汽车分为客车、货车)等等。
该肯定模板中的语句结构可根据需要进行增加或删减。因此,具体模板中的语句结构在本发明实施例中并不做限定。
进一步的,为了提高判断整体与部分关系的准确率,还可以将符合肯定模板的候选语句再利用否定模板进行复核匹配,从而将具有并列结构但不具有整体与部分关系的语句进行排除。例如,手机是通信工具、智能设备、电子设备。该句中的“通信工具”、“智能设备”、“电子设备”具有并列结构但与“手机”并非是整体与部分关系。因此,要将具有这类语句结构的获选语句加以排除。具体的否定模板中的语句结构还包括有:^如(.*?)、(.*?)、(.*?)$的结构,^(.*?)是(.*?)、(.*?)、(.*?)$的结构,(.*?)、(.*?)、(.*?)(为|作为|有|分为)(.*?)$的结构。将不符合否定模板的候选语句保留并进行后续的处理。
205、利用领域词典以及候选语句中的分词信息,确定该候选语句中具有并列结构的领域分词。
在确定领域分词之前,首先是要选定领域词典,而领域词典的选取一般是在获取该文本时根据该文本的内容所确定的,也可以是通过提供可选的领域词典表进行选择。该领域词典是具有该文本所属技术领域的所有分词的词典。通过将候选语句中的分词信息与领域词典中的分词进行匹配,就可以判断出该候选语句中的哪些分词是相同领域的分词,尤其是判断该候选语句中具有并列结构的分词是否为相同领域的分词,若相同,则将这些分词定义为领域分词。
206、利用位置模板确定候选语句中的整体领域分词与部分领域分词。
位置模板类似于上述的肯定模板,用于根据分词在句子中的位置来判断分词的具体属性,即该分词是整体领域分词或是部分领域分词。大多数情况下,具有并列结构的分词都属于部分领域分词。而整体领域分词与部分领域分词的关系是上位概念与下位概念的关系。
207、提取具有整体与部分关系的领域分词。
确定了候选语句中的整体领域分词与部分领域分词后,就可以将分词从候选语句中提取出来。进一步的,还可以对所提取出来的分词进行词语的修正,去除一些分词中不必要的修饰词,如去除数词、量词或尾词后缀等修饰词。
208、将具有整体与部分关系的领域分词集合以列表的形式输出。
最后,将修正后的整体领域分词与部分领域添加到相应的表格中以列表的形式加以输出。需要说明的是,在该列表中,包括有该文本中从所有分句提取出来的具有整体与部分关系的领域分词,因此,该列表也可以视为一个领域分词集合,且为具有整体与部分对应关系的领域分词集合。
进一步的,作为对上述方法的实现,本发明实施例提供了一种获取词语的装置,该装置实施例与前述方法实施例对应,为便于阅读,本装置实施例不再对前述方法实施例中的细节内容进行逐一赘述,但应当明确,本实施例中的装置能够对应实现前述方法实施例中的全部内容。该装置设置在用于文本语料分析的设备中,特别是提取具有整体与部分关系的词语的计算设备,如图3所示,该装置包括:
预处理单元31,用于对获取的文本数据进行预处理,得到带有分词信息的独立语句;
筛选单元32,用于在所述预处理单元31得到的独立语句中,利用结构模板筛选出具有并列结构的候选语句;
确定单元33,用于利用领域词典以及所述候选语句中的分词信息,确定所述筛选单元32选择的候选语句中具有并列结构的领域分词,所述领域词典是记录有相同领域分词的词典;
输出单元34,用于根据所述确定单元33确定的领域分词的位置特征, 输出具有整体与部分关系的领域分词集合。
进一步的,如图4所示,所述预处理单元31包括:
分句模块311,用于对所述文本数据进行分句处理,得到所述独立语句;
分词模块312,用于对所述分句模块311得到的独立语句进行分词处理,得到所述独立语句的分词信息;
标记模块,用于将所述分词模块312得到的分词信息标记在所述独立语句中。
进一步的,如图4所示,所述筛选单元32包括:
提取模块321,用于利用特征符号提取具有并列结构的独立语句,其中,所述特征符号至少包含下述之一:顿号、逻辑关系符号;
筛选模块322,用于在所述提取模块321提取的并列结构的独立语句中,利用肯定模板筛选出具有整体与部分关系的候选语句,所述肯定模板用于判断所述独立语句中具有整体与部分关系的语句结构。
进一步的,如图4所示,所述筛选模块322包括:
筛选子模块3221,用于利用否定模板筛选符合所述肯定模块的独立语句,所述否定模板用于判断所述独立语句中具有非整体与部分关系的语句结构;
确定子模块3222,用于确定不符合所述筛选子模块3221使用的否定模板的独立语句为所述候选语句。
进一步的,如图4所示,所述确定单元33包括:
选择模块331,用于选取领域词典;
判断模块332,用于根据所述候选语句中的分词信息,判断所述候选语句中具有并列结构的分词是否为所述选择模块331选取的领域词典中的领域分词;
确定模块333,用于当所述判断模块332判断分词在所述领域词典中时,确定所述分词为领域分词。
进一步的,如图4所示,所述输出单元34包括:
确定模块341,用于利用位置模板确定所述候选语句中的整体领域分词与部分领域分词,所述整体领域分词与部分领域分词的关系是上位概念与 下位概念的关系;
提取模块342,用于提取所述确定模块341所确定的具有整体与部分关系的领域分词;
输出模块343,用于将所述提取模块342所提取的具有整体与部分关系的领域分词集合以列表的形式输出。
进一步的,如图4所示,所述提取模块342包括:
修正子模块3421,用于对所述整体领域分词与部分领域分词进行修正处理,所述修正处理包括:去除数词、去除量词和/或去除尾词后缀;
提取子模块3422,用于提取所述修正子模块3421经修正处理后的整体领域分词与部分领域分词。
综上所述,本发明实施例所采用的获取词语的方法及装置,通过对文本语料进行的分词、分句处理,并利用结构模板筛选出具有并列结构的获选语句。就可以初步选定在给文本语料中为并列结构可能是具有整体与部分关系的候选语句。在利用该候选语句中的分词信息,以及选定的领域词典,判断出具有并列结构的分词是否属于相同的领域,若是,则可以根据分词在句中的位置来确定各个分词之间的整体与部分关系,同时以相对应的关系加以输出显示。相对于现有的判断整体与部分关系所采用的固定模板的比对方式而言,本发明实施例所采用的方法通过对句子中的分词加入进一步的判断,确定具有并列结构的分词是属于同一类领域中的分词,从而能够根据分词的具体内容避免分词提取的形式化。再根据分词之间的位置关系判断哪些分词属于整体领域分词,哪些属于部分领域分词。从而进一步提高分词整体与部分关系的提取准确性。
所述获取词语的装置包括处理器和存储器,上述预处理单元、筛选单元、确定单元和输出单元等均作为程序单元存储在存储器中,由处理器执行存储在存储器中的上述程序单元来实现相应的功能。
处理器中包含内核,由内核去存储器中调取相应的程序单元。内核可以设置一个或以上,通过调整内核参数来提高语料词语间整体与部分关系的提取准确率。
存储器可能包括计算机可读介质中的非永久性存储器,随机存取存储 器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM),存储器包括至少一个存储芯片。
本申请还提供了一种计算机程序产品,当在数据处理设备上执行时,适于执行初始化有如下方法步骤的程序代码:对获取的文本数据进行预处理,得到带有分词信息的独立语句;在所述独立语句中,利用结构模板筛选出具有并列结构的候选语句;利用领域词典以及所述候选语句中的分词信息,确定所述候选语句中具有并列结构的领域分词,所述领域词典是记录有相同领域分词的词典;根据所述领域分词的位置特征,输出具有整体与部分关系的领域分词集合。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机 实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
在一个典型的配置中,计算设备包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。
存储器可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flash RAM)。存储器是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括要素的过程、方法、商品或者设备中还存在另外的相同要素。
本领域技术人员应明白,本申请的实施例可提供为方法、系统或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘 存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
以上仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!