一种执行代码生成方法及设备与流程
本申请涉及通信
技术领域:
,特别涉及一种执行代码生成方法。本申请同时还涉及一种执行代码生成设备。
背景技术:
:传统的数据操作首先需要将数据采集并存储在DBMS(数据库管理系统,DatabaseManagementSystem)中,然后与DBMS进行交互进行数据处理,进而才能得到用户所需要的结果。在这整个过程中用户是主动的,而DBMS系统是被动的。但是对于现在大量存在的实时数据,比如股票交易的数据,这类数据实时性强,数据量大,没有止境,传统的架构并不合适。而流计算就是专门针对这种数据类型准备的,在流数据不断变化的运动过程中实时地进行分析,捕捉到可能对用户有用的信息,并把结果发送出去。得益于高速的数据处理特性,互联网的服务提供商或平台运营商针对流计算平台越来越予以重视。目前,支持可线性扩展、高吞吐和高可用的主流流计算服务化平台一般都支持SQL(StructuredQueryLanguage,结构化查询语言),同时可构建MRM(MapReduceMerge)的增量计算模型。在利用增量技术解决了中间数据集容错效率的问题后,用户可在云端方便的管理和配置任务,并且能够提供稳定、容错和可扩展的云端流计算服务能力,接入交易、点击、搜索等各种实时数据源以构建实时数据仓库,为数据化运营、实时ETL(Extract-Transform-Load,抽取转换装载)、个性化推荐、流数据挖掘等各种实时数据分析和应用提供秒级甚至毫秒级的流计算服务。目前,传统流计算ETL开发过程包括以下步骤:S101,用户在线下环境通过类型为文本编辑器的工具开发流计算SQL语句,并在本地调试开发的SQL语句;S102,用户通过RPM软件包管理器进行打包处理。S103,用户安装RPM软件包管理器(RPMPackageManager)至生产的预发机器,并修改SQL语句中的数据源表和结果表的配置,通过使用线上真实数据源表运行流计算任务比对结果表的产出。S104,将RPM软件包管理器安装至生产环境,在修改SQL语句中的数据源表和结果表的配置后运行此任务。结合上述流程以及现有的开发经验,本申请的发明人在实现本申请的过程中发现,现有的流计算ETL开发中开发和生产环境在网络上是物理隔离的,导致开发环节无法模拟真实的数据源。某一段执行代码在开发、调试通过后,开发人员还需要在打包发布前修改源头表和结果表的配置信息。如果忘记对这些配置信息进行修改,就会造成生产故障。由此可见,现有的开发和生产的流计算数据源无法共享,导致开发环境不能完全模拟生产数据,并且开发和生产的代码无法统一,用户需要在生产环境修改部分配置时非常容易出错。因此,如何提高现有的流计算ETL开发过程的效率,节省人力以及避免由于人工失误带来的损失,成为本领域技术人员亟待解决的技术问题。技术实现要素:本申请提供了一种执行代码生成方法,用以提高现有的执行代码在不同执行环境下的处理效率,减少人力消耗以及避免人工失误带来的损失。该方法包括:将原始代码拆分为输入表语句、输出表语句以及数据转换逻辑语句;确定所述输入表语句中的变量值,以及与当前的执行环境对应的替换值;将所述输入表语句中的所述变量值替换为所述替换值,并根据所述执行环境、替换后的输入表语句、输出表语句以及所述数据转换逻辑语句生成执行代码;根据所述执行环境执行所述执行代码。优选地,将原始代码拆分为输入表语句、输出表语句以及数据转换逻辑语句,具体为:获取所述原始代码;对所述原始代码进行结构化查询语言SQL解析,根据解析结果生成所述输入表语句、所述输出表语句以及所述数据转换逻辑语句。优选地,将所述输入表语句中的所述变量值替换为所述替换值,具体为:获取与所述执行环境对应的配置文件,所述配置文件预设与所述变量值对应的数值;将所述数值作为所述替换值,并根据所述替换值对所述变量值进行变量替换。优选地,根据所述执行环境执行所述执行代码,具体为:若所述执行环境为开发环境,将所述执行代码的输出表的数据重定向至输出流,并在所述输出流的数据验证正确之后执行所述执行代码;若所述执行环境为生产环境,执行所述执行代码。相应地,本申请还提出了一种执行代码生成设备,包括:拆分模块,将原始代码拆分为输入表语句、输出表语句以及数据转换逻辑语句;确定模块,确定所述输入表语句中的变量值,以及与当前的执行环境对应的替换值;替换模块,将所述输入表语句中的所述变量值替换为所述替换值;生成模块,根据所述执行环境、替换后的输入表语句、输出表语句以及所述数据转换逻辑语句生成执行代码。优选地,还包括:执行模块,根据所述执行环境执行所述执行代码。优选地,所述拆分模块具体用于:获取所述原始代码;对所述原始代码进行结构化查询语言SQL解析,根据解析结果生成所述输入表语句、所述输出表语句以及所述数据转换逻辑语句。优选地,所述替换模块具体用于:获取与所述执行环境对应的配置文件,所述配置文件预设与所述变量值对应的数值;将所述数值作为所述替换值,并根据所述替换值对所述变量值进行变量替换。优选地,所述执行模块具体用于:若所述执行环境为开发环境,将所述执行代码的输出表的数据重定向至输出流,并在所述输出流的数据验证正确之后执行所述执行代码;若所述执行环境为生产环境,执行所述执行代码。由此可见,通过应用本申请的技术方案,在将原始代码拆分为输入表语句、输出表语句以及数据转换逻辑语句之后,确定所述输入表语句中的变量值以及与当前的执行环境对应的替换值,将输入表语句中的变量值替换为替换值,并根据执行环境、替换后的输入表语句、输出表语句以及数据转换逻辑语句生成执行代码,从而实现了通过统一的平台在不同的执行环境实现执行代码的自动生成,提高了现有执行代码的处理效率,避免了人工处理代码所带来的问题。附图说明图1为本申请提出的一种执行代码生成方法的流程示意图;图2为本申请具体实施例中的流计算开发平台系统结构图;图3为本申请具体实施例提出的一种流作业执行流程图;图4为本申请提出的一种执行代码生成设备的结构示意图。具体实施方式有鉴于
背景技术:
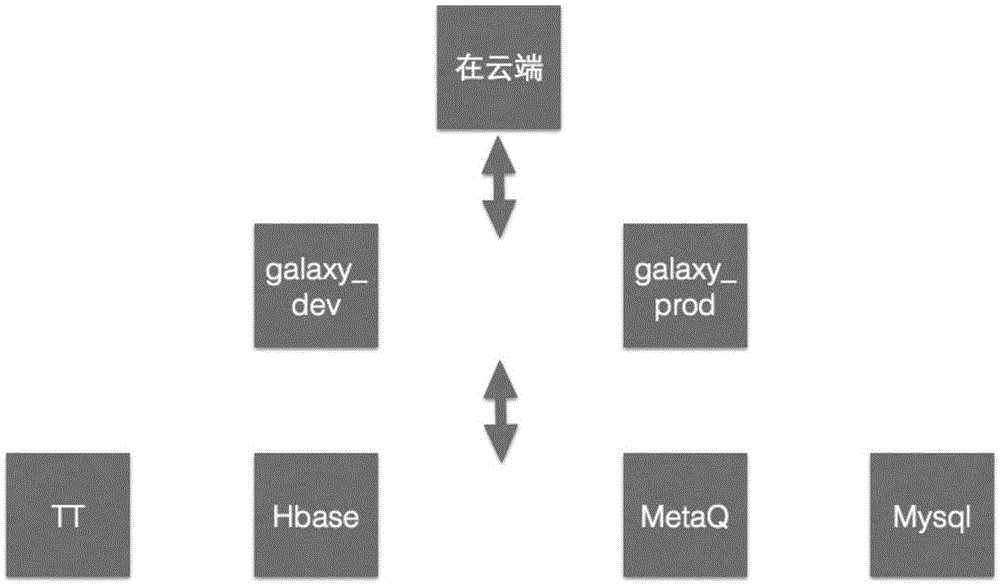
中的问题,本申请提出了一种执行代码生成方法,在应用本申请的技术方案之后,技术人员无论是在开发环境还是生产环境都可以订阅相同一个数据源表,同时流计算数据源表和结果表在开发环境和生产环境互相隔离,互相不影响。即通过一个平台实现开发、调试、发布、执行流计算作业。如图1所示,为本申请提出的一种执行代码生成方法的流程示意图,包括以下步骤:S101,将原始代码拆分为输入表语句、输出表语句以及数据转换逻辑语句。输入表语句主要用来构建流式计算的源头数据,通过此语句订阅实时的数据。输出表语句主要用来构建流计算最终结果数据表,数据转换逻辑会把数据实时的写到结果表。由于执行代码在根据当前的不同执行环境选择不同的变量以执行,而不同的变量存在于代码的不同部分,因此在将原始的执行代码执行之前,需要针对原始代码进行拆分处理,并且获取其中最为重要的输入表语句、输出表语句以及数据转换逻辑语句这三个部分。由于目前的执行代码大多采用SQL语句组成,因此在本申请的优选实施例中,该步骤首先获取原始代码,并针对原始代码进行结构化查询语言SQL解析,根据解析结果生成所述输入表语句、所述输出表语句以及所述数据转换逻辑 语句。需要说明的是,尽管以上通过SQL解析的方式举例说明了执行代码的解析过程以及具体各个部分的获取方式,但是本申请并不仅限于此,在后续面对其他类型语句或是格式的执行代码时,技术人员亦可基于实际情况采取其他实现方式,这些均属于本申请的保护范围。如图2所示,为本申请具体实施例中流计算开发平台系统结构图,在云端(流计算平台)是对用户可见的产品形态。Galaxy是流计算引擎。TT、Hbase、MetaQ、Mysql等是流计算引擎的数据源。在用户申请开通流计算时,平台会自动帮助用户建立两个项目空间galaxy_dev以及galaxy_prod。这两个项目主要用于隔离开发和生产的流计算作业。以目前的技术来说,TT和Metaq的一个订阅无法同时被多个galaxy流作业使用。用户在构建流作业之前,针对同一个数据源需要申请subscribe1以及subscribe2这两个订阅,这样给用户的代码执行带来了极大的不便。因此在图3所示的具体实施例中,当输入sql之后,即开始进行galaxysql解析,具体地,通过词法以及语法解析将代码分别拆分成三个部分:输入表、输出表、数据转换逻辑。S102,确定所述输入表语句中的变量值,以及与当前的执行环境对应的替换值。由于不同的执行环境对于执行代码所体现的区别主要在于输入表的语句中的实时数据源存在不同,为了保证开发和生产环境代码保持一致,通过变量来指定实时数据源。用户在配置文件(如表1)中具体指定实时数据源的确切值。表1中四个值,有两个用来替换开发环境,有两个用来替换生产环境。因此该步骤通过确定输入表语句中的变量值以及与当前的生产环境对应的替换值,以便于后续步骤的处理。需要说明的是,在该步骤中,与当前的生产环境对应的替换值可以预先设置好,这样在上一步骤解析完成后与输入表语 句中的变量值同时获取。也可以是在确定输入表语句中的变量值之后再按照变量值结合执行环境配置,这些均属于本申请的保护范围。以图3为例,假设通过SQL解析得到的输入表的代码如下:以上为输入表语句,其主要用来构建流式计算的源头数据,通过此语句订阅实时的数据基于上述代码,进行输入表语句的解析所得到的结构化信息如下表1所示:keyvalueinput.typettgalaxy.semantic.source.timetunnel.lognameaplus_textgalaxy.semantic.source.timetunnel.subid${sub_id}galaxy.semantic.source.timetunnel.accesskey${access_key}表1相应地,当前执行环境的输出表的代码如下:以上为输出表语句,其主要用来构建流计算最终结果数据表,数据转换逻辑会把数据实时的写到结果表。通过采用本具体实施例提供的数据转换逻辑进行配置文件解析,得到的结构化数据如下表2所示:keyvaluesub_id_dev1224145515U8LLY8M4512access_key_dev14569d37-b1fa-4603-a496-7600a554d1201sub_id_prod1224145515U8LLY8M4613access_key_prod14569d37-b1fa-4603-a496-7600a554d1202表2其中,表2中的sub_id_dev和access_key_dev是开发环境对应的替换值;而sub_id_prod和access_key_prod则是生产环境对应的替换值。只有开发和生产两个环境。完成以上处理的数据处理逻辑代码如下,需要说明的是,该代码仅为本申请所提出的一种优选实施方案,对本申请的保护范围并没有影响:以上为数据转换逻辑,其主要用于加工输入数据,最终结果写到输出表。S103,将所述输入表语句中的所述变量值替换为所述替换值。在通过S102分析得到了原始代码的变量值和与之对应的替换值之后,该步骤可基于当前的执行环境快速的自动替换并生成执行代码。在本申请的优 选实施例中,替换过程如下:步骤a)获取与所述执行环境对应的配置文件,所述配置文件中预设有与所述变量值对应的数值;步骤b)将所述数值作为所述替换值,并根据所述替换值对所述变量值进行变量替换。S104,根据所述执行环境、替换后的输入表语句、输出表语句以及所述数据转换逻辑语句生成执行代码。在图3所示的具体实施例中,基于S101和S102中的的词法和语法分析,可以快速的重写原始代码并进行变量替换,主要是根据执行环境(开发环境、生产环境)替换sub_id和access_key的值。相应的不同执行环境的代码重写后如下所示:(1)针对开发环境,由表2可知,其对应的替换值为sub_id_dev和access_key_dev,因此针对开发环境,根据表1和表2,将输入表中的galaxy.semantic.source.timetunnel.subid的值替换为表2中的sub_id_dev的值,即1224145515U8LLY8M4512,同时将输入表中的galaxy.semantic.source.timetunnel.accesskey的值替换为表2中access_key_dev的值,即14569d37-b1fa-4603-a496-7600a554d1201,由此,结合上述输出表以及数据转换逻辑,开发环境代码重写后如下,按先后次序分为三个部分:第一部分为输入表,具体如下:第二部分为输出表,具体如下:第三部分为数据转换逻辑,具体如下:(2)针对生产环境,由表2可知,其对应的替换值为sub_id_prod和access_key_prod,因此针对生产环境,根据表1和表2,将输入表中的galaxy.semantic.source.timetunnel.subid的值替换为表2中的sub_id_prod的值,即1224145515U8LLY8M4613,同时将输入表中的galaxy.semantic.source.timetunnel.accesskey的值替换为表2中access_key_prod的值,即14569d37-b1fa-4603-a496-7600a554d1202,由此,结合上述输出表以 及数据转换逻辑,生产环境代码重写后如下,与开发环境代码重写相同,也按先后次序分为三个部分:分别为输入表,输出表和数据转换逻辑。通过上述代码重写,至此代码本身的处理过程已经完成,后续可基于不 同的执行环境对代码进行处理。在本申请的优选实施例中,根据不同执行环境执行所述执行代码的具体方式如下:(1)若所述执行环境为开发环境,将所述执行代码的输出表的数据重定向至输出流,并在所述输出流的数据验证正确之后执行所述执行代码;(2)若所述执行环境为生产环境,执行所述执行代码。通过S103的具体实施例中的代码重写已经解决了开发环境和生产环境的输入表的隔离问题。但是开发和生产共享生产表,会造成数据被开发作业覆盖的问题。因此本申请该具体实施例引入了流计算引擎内存模式,在这种模式下,输出表数据不会直接写入存储,而是通过日志重定向到一个输出流,用户可以查看这个输出流验证数据是否准确。通过采用上述技术方案,SQL词法、语法解析及SQL重写来隔离流计算作业的开发和生产环境,使得用户在一个平台上完成流计算作业的开发、发布、生产环境运行。在环境隔离的情况下,又能使用真实的数据源。为达到以上技术目的,本申请还提出了一种执行代码生成设备,如图4所示,包括:拆分模块410,将原始代码拆分为输入表语句、输出表语句以及数据转换逻辑语句;确定模块420,确定所述输入表语句中的变量值,以及与当前的执行环境对应的替换值;替换模块430,将所述输入表语句中的所述变量值替换为所述替换值;生成模块440,根据所述执行环境、替换后的输入表语句、输出表语句以及所述数据转换逻辑语句生成执行代码。在具体的应用场景中,还包括:执行模块,根据所述执行环境执行所述执行代码。在具体的应用场景中,所述拆分模块具体用于:获取所述原始代码;对所述原始代码进行结构化查询语言SQL解析,根据解析结果生成所述输入表语句、所述输出表语句以及所述数据转换逻辑语句。在具体的应用场景中,所述替换模块具体用于:获取与所述执行环境对应的配置文件,所述配置文件预设与所述变量值对应的数值;将所述数值作为所述替换值,并根据所述替换值对所述变量值进行变量替换。在具体的应用场景中,所述执行模块具体用于:若所述执行环境为开发环境,将所述执行代码的输出表的数据重定向至输出流,并在所述输出流的数据验证正确之后执行所述执行代码;若所述执行环境为生产环境,执行所述执行代码。通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到本申请可以通过硬件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,本申请的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施场景所述的方法。本领域技术人员可以理解附图只是一个优选实施场景的示意图,附图中的模块或流程并不一定是实施本申请所必须的。本领域技术人员可以理解实施场景中的装置中的模块可以按照实施场景描述进行分布于实施场景的装置中,也可以进行相应变化位于不同于本实施 场景的一个或多个装置中。上述实施场景的模块可以合并为一个模块,也可以进一步拆分成多个子模块。上述本申请序号仅仅为了描述,不代表实施场景的优劣。以上公开的仅为本申请的几个具体实施场景,但是,本申请并非局限于此,任何本领域的技术人员能思之的变化都应落入本申请的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1