一种数据训练方法及装置与流程
本发明涉及深度学习技术,尤其涉及一种基于深度学习的数据训练方法及装置。
背景技术:
在深度学习模型中,传统的数据训练方法首先对训练数据进行初始化数据分割,及将训练数据切分成与集群节点相同的数据,然后分布到每个集群节点上进行训练,且训练数据与对应的集群节点在接下来的迭代训练中会一直捆绑在一起,并不会发生变化。这样,如果初始化数据分割不平衡,很容易使集群节点对应机器所训练出的深度学习网络系数陷入局部化偏差。
另外,利用传统的数据训练方法进行深度学习过程中,在一次迭代训练结束后,对所有集群节点训练出的深度学习网络系数进行数学平均处理,将处理后的深度学习网络系数作为新的深度学习网络系数分发至所有集群节点,用作新的迭代训练,不利于整个迭代过程收敛的次数。
技术实现要素:
有鉴于此,本发明实施例为解决上述问题而提供一种数据训练方法及装置。
为达到上述目的,本发明实施例的技术方案是这样实现的:
本发明实施例提供一种数据训练方法,所述方法包括:
在第i次迭代训练下,对训练数据进行第i次数据分割,得到第i分割结果;通过与所述集群节点相对应的N个训练器对所述第i分割结果进行第i次迭代训练,得到第i训练结果;将所述第i训练结果传递至所述N个训练器,以使所述N个训练器在第i+1次迭代训练下将所述第i训练结果作为新的网络系数;
其中,所述i小于等于预设值M;所述i、N及M均为正整数。
上述方案中,所述第i分割结果包括与集群节点的总个数N相对应的N个数据集;
相应的,所述通过与所述集群节点相对应的N个训练器对所述第i分割结果进行第i次迭代训练,包括:
将所述第i分割结果中包括的N个数据集分别分配到与集群节点相对应的N个训练器;
利用所述N个训练器分别对所述N个数据集加以训练,得到训练结果;
将通过每个训练器得到的训练结果进行数据处理,得到第i训练结果。
上述方案中,利用所述N个训练器分别对所述N个数据集加以训练,得到训练结果,包括:
将分配到对应训练器的训练集进行划分,分为训练数据和测试数据;
利用所述训练数据对所述训练器进行建模,得到训练模型;
通过所述训练模型对测试数据进行训练,得到训练结果。
上述方案中,所述通过所述训练模型对测试数据进行训练,得到训练结果,包括:
通过所述训练模型对测试数据进行识别处理,得到识别处理结果;
将所述识别处理结果与测试数据所对应的测试标签进行比对,得到训练结果。
上述方案中,所述将通过每个训练器得到的训练结果进行数据处理,得到第i训练结果,包括:
对所述通过每个训练器得到的训练结果进行加权平均处理,得到加权平均处理结果;
将所述加权平均处理结果作为第i训练结果。
本发明实施例还提供一种数据训练装置,所述装置包括数据分割模块、训练模块和传递模块;
所述分割模块,用于在第i次迭代训练下,对训练数据进行第i次数据分割,得到第i分割结果;
所述训练模块,用于通过与所述集群节点相对应的N个训练器对所述第i分割结果进行第i次迭代训练,得到第i训练结果;
所述传递模块,用于将所述第i训练结果传递至所述N个训练器,以使所述N个训练器在第i+1次迭代训练下将所述第i训练结果作为新的网络系数;
其中,所述i小于等于预设值M;所述i、N及M均为正整数。
上述方案中,所述第i分割结果包括与集群节点的总个数N相对应的N个数据集;所述训练模块包括分配单元、训练单元和数据处理单元;
所述分配单元,用于将所述第i分割结果中包括的N个数据集分别分配到与集群节点相对应的N个训练器;
所述训练单元,用于利用所述N个训练器分别对所述N个数据集加以训练,得到训练结果;
所述数据处理单元,用于将通过每个训练器得到的训练结果进行数据处理,得到第i训练结果。
上述方案中,所述训练单元包括划分子单元、建模子单元和训练子单元;
所述划分子单元,用于将分配到对应训练器的训练集进行划分,分为训练数据和测试数据;
所述建模子单元,用于利用所述训练数据对所述训练器进行建模,得到训练模型;
所述训练子单元,用于通过所述训练模型对测试数据进行训练,得到训练结果。
上述方案中,所述训练子单元,还用于通过所述训练模型对测试数据进行识别处理,得到识别处理结果;将所述识别处理结果与测试数据所对应的测试标签进行比对,得到训练结果。
上述方案中,所述数据处理单元,还用于对所述通过每个训练器得到的训练结果进行加权平均处理,得到加权平均处理结果;将所述加权平均处理结果作为第i训练结果。
本发明实施例所提供的数据训练方法,在第i次迭代训练下,对训练数据 进行第i次数据分割,得到第i分割结果;通过与所述集群节点相对应的N个训练器对所述第i分割结果进行第i次迭代训练,得到第i训练结果;将所述第i训练结果传递至所述N个训练器,以使所述N个训练器在第i+1次迭代训练下将所述第i训练结果作为新的网络系数;其中,所述i小于等于预设值M;所述i、N及M均为正整数。如此,通过在每次迭代训练之前均对训练数据进行数据分割,能够降低训练数据不平衡造成的模型偏差,在一定程度上有效提高深度学习的准确率。
附图说明
图1a为本发明实施例数据训练方法的流程示意图一;
图1b为本发明实施例数据训练方法的实现示意图一;
图2a为本发明实施例数据训练方法的流程示意图一;
图2b为本发明实施例利用所述N个训练器分别对所述N个数据集加以训练的流程示意图;
图2c为本发明实施例数据训练方法的实现示意图二;
图3为传统的迭代训练方法的流程示意图;
图4为本发明一应用示例迭代训练方法的流程示意图;
图5为本发明实施例数据训练装置的组成结构示意图。
具体实施方式
下面结合附图及具体实施例对本发明再作进一步详细的说明。
在本发明实施例中,在第i次迭代训练下,对训练数据进行第i次数据分割,得到第i分割结果;通过与所述集群节点相对应的N个训练器对所述第i分割结果进行第i次迭代训练,得到第i训练结果;将所述第i训练结果传递至所述N个训练器,以使所述N个训练器在第i+1次迭代训练下将所述第i训练结果作为新的网络系数;其中,所述i小于等于预设值M;所述i、N及M均为正整数。
实施例一
图1a为本发明实施例数据训练方法的流程示意图一,如图1a所示,本发明实施例数据训练方法包括:
步骤101:在第i次迭代训练下,对训练数据进行第i次数据分割,得到第i分割结果;
其中,所述第i分割结果包括与集群节点的总个数N相对应的N个数据集。
步骤102:通过与所述集群节点相对应的N个训练器对所述第i分割结果进行第i次迭代训练,得到第i训练结果;
步骤103:将所述第i训练结果传递至所述N个训练器,以使所述N个训练器在第i+1次迭代训练下将所述第i训练结果作为新的网络系数。
其中,所述i小于等于预设值M;所述i、N及M均为正整数。
在一示例中,如图1b所示,以集群节点的总个数N取值为4为例,在第i次迭代训练时,将训练数据data分割为与集群节点的总个数4相同的数据,依次为data1、data2、data3、data4;在第i+1次迭代训练时,重新对所述训练数据data进行分割,分割为data1’、data2’、data3’、data4’。这样,训练数据被切分成与集群节点相同的数据,然后分配至每个集群节点对应的训练器Worker上进行迭代训练;每一次迭代训练后,所有的训练数据会被打乱重新进行切分,然后依次分配到每个集群节点对应的训练器Worker上进行再次迭代训练,直到迭代完成。
如此,通过本发明实施例所述数据训练方法,通过在每次迭代训练之前均对训练数据进行数据分割,能够降低训练数据不平衡造成的模型偏差,在一定程度上有效提高深度学习的准确率。
实施例二
图2a为本发明实施例数据训练方法的流程示意图二,如图2a所示,本发明实施例数据训练方法包括:
步骤101:在第i次迭代训练下,对训练数据进行第i次数据分割,得到第 i分割结果;
其中,所述第i分割结果包括与集群节点的总个数N相对应的N个数据集。
步骤1021:将所述第i分割结果中包括的N个数据集分别分配到与集群节点相对应的N个训练器;
步骤1022:利用所述N个训练器分别对所述N个数据集加以训练,得到训练结果;
在一示例中,如图2b所示,本发明实施例所述利用所述N个训练器分别对所述N个数据集加以训练,得到训练结果,包括:
步骤1022a:将分配到对应训练器的训练集进行划分,分为训练数据和测试数据;
步骤1022b:利用所述训练数据对所述训练器进行建模,得到训练模型;
步骤1022c:通过所述训练模型对测试数据进行训练,得到训练结果。
具体地,通过所述训练模型对测试数据进行识别处理,得到识别处理结果;将所述识别处理结果与测试数据所对应的测试标签进行比对,得到训练结果。
步骤1023:对所述通过每个训练器得到的训练结果进行加权平均处理,得到加权平均处理结果,将所述加权平均处理结果作为第i训练结果;
步骤103:将所述第i训练结果传递至所述N个训练器,以使所述N个训练器在第i+1次迭代训练下将所述第i训练结果作为新的网络系数。
其中,所述i小于等于预设值M;所述i、N及M均为正整数。
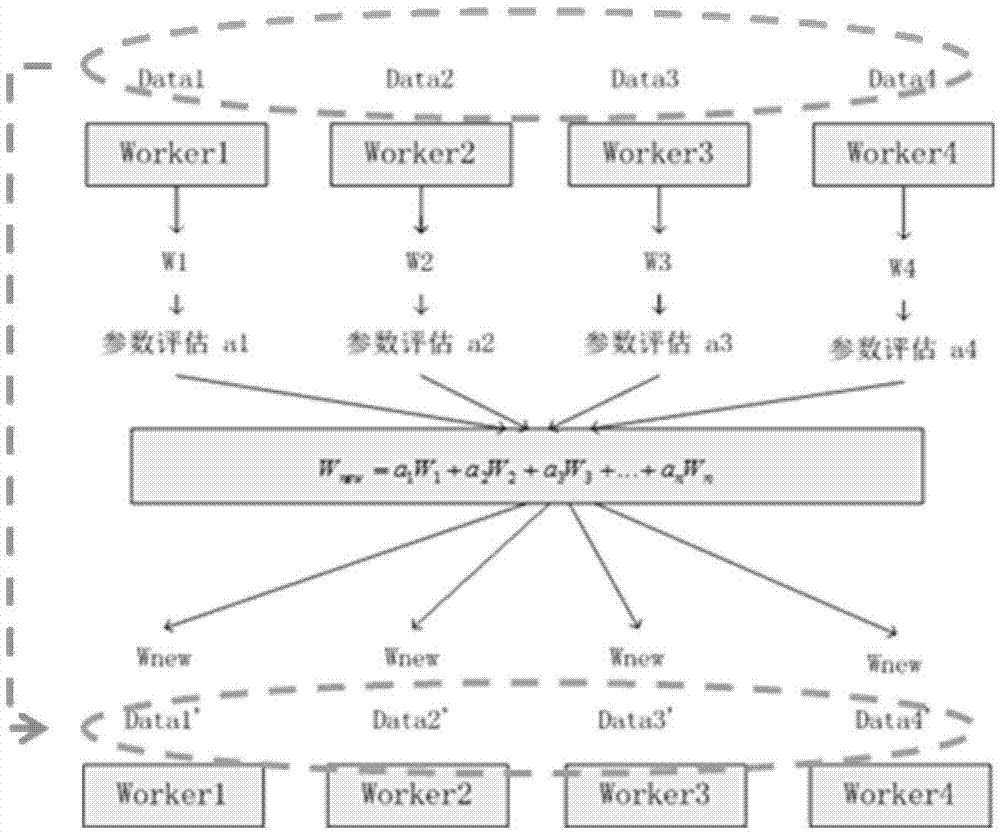
在一示例中,如图2c所示,对照本发明实施例步骤1022~1023,在训练过程中,为了对所有集群节点训练的深度学习网络进行评价,通过所述训练模型对测试数据进行识别处理,得到识别处理结果W1,W2,W3,…,WN;将所述识别处理结果与测试数据所对应的测试标签进行比对,得到训练结果a1,a2,a3,…,aN;进一步地,在一次迭代训练结束后,将训练结果传递给N个训练器Worker之前,为了保证效果好的节点所产生的系数在未来的平均中占有更大的权重,效果差的节点所产生的系数在未来的平均中占有小的权重,通过对所述通过每个训练器得到的训练结果进行加权平均处理,得到加权平均处理结果 Wnew=a1W1+a2W2+a3W3+…+aN WN,并将所述加权平均处理结果Wnew作为第i训练结果传递至所述N个训练器,以使所述N个训练器在第i+1次迭代训练下将所述第i训练结果Wnew作为新的网络系数。
如此,通过本发明实施例所述数据训练方法,通过在每次迭代训练之前均对训练数据进行数据分割,能够降低训练数据不平衡造成的模型偏差,在一定程度上有效提高深度学习的准确率。同时,通过对所述通过每个训练器得到的训练结果进行加权平均处理,即与传统的深度学习迭代训练相比,在对训练结果的处理过程中,采用加权平均处理代替等权重平局,能够加快网络模型的收敛,从而减短训练时间。
具体应用场景:
图3为传统的基于深度学习的迭代训练方法的流程示意图,如图3所示,假设集群节点的总个数为4,对应四台训练器Worker。具体迭代训练过程如下:
1)将训练数据进行分割,得到分割结果,依次排序为data1、data2、data3、data4,分别分配到四台训练器Worker上;Master节点初始化深度学习网络的weights。
2)Master节点向Worker节点推送weights。
3)Worker节点通过各自分配的数据训练新的weights,并向Master发送更新后的weights。
4)在一个给定的时间点里,Master节点对来自所有Worker节点的weights求平均值。
5)Master节点将平均值发送给所有Worker。
6)重复3-5步骤,直到满足目标函数要求。
需要说明的是,当步骤6)完成后,有一个层就被训练了。后续层也重复这些步骤。当所有的层都被训练以后,深度网络就会通过使用错误反向广播机制准确地调整好。
在传统的迭代训练过程中存在如下明显的缺陷:一方面,训练数据被切分 成与集群节点相同的数据,然后分布到每个集群节点对应的训练器上进行训练,训练数据与对应的集群节点在接下来的迭代中会捆绑在一起,不会发生变化。如果初始化的数据分割不平衡,很容易使该训练器训练出的系数陷入局部化偏差;另一方面,在一次迭代训练结束后,对所有训练器训练的深度学习网络系数进行平均,平均之后的深度学习网络系数作为新的系数分发至所有节点,用作新的迭代训练,不利于整个迭代过程收敛的次数。
图4为本发明一应用示例中基于深度学习的迭代训练方法的流程示意图,如图4所示,假设集群节点的总个数为4,对应四台训练器Worker。具体迭代训练过程如下:
1)将训练数据进行分割,得到分割结果,依次排序为data1、data2、data3、data4,分别分配到四台训练器Worker上;Master节点初始化深度学习网络的weights。
2)Master节点向Worker节点推送weights。
3)Worker节点通过各自分配的数据训练新的weights。每个节点对各自训练出的weights评估其效果(准确率),并将weights和评估效果一同发送至Master。
4)在一个给定的时间点里,Master节点对来自所有Worker节点的weights根据各自的评估效果计算按照不同的权重计算所有的weights的均值,权重的计算方法:将每个worker的计算准确率按照大小进行归一化处理,准确率比较高的worker权重较大,准确率低的worker权重较小。
5)Master节点将更新的weights发送给所有Worker。
6)将所有的训练数据打乱,重新进行分割,得到分割结果,依次排序为data1’、data2’、data3’、data4’,分别分配到四台训练器Worker上。
7)重复3-6步骤,直到满足目标函数要求。
需要说明的是,当步骤7)完成后,有一个层就被训练了。后续层也重复这些步骤。当所有的层都被训练以后,深度网络就会通过使用错误反向广播机制准确地调整好。
通过图3和图4的对比可知,通过在每次迭代训练之前均对训练数据进行数据分割,能够降低训练数据不平衡造成的模型偏差,在一定程度上有效提高深度学习的准确率。同时,通过对所述通过每个训练器得到的训练结果进行加权平均处理,即与传统的深度学习迭代训练相比,在对训练结果的处理过程中,采用加权平均处理代替等权重平局,能够加快网络模型的收敛,从而减短训练时间。
实施例五
图5为本发明实施例数据训练装置的组成结构示意图,如图5所示,所述装置包括数据分割模块51、训练模块52和传递模块53;
所述分割模块51,用于在第i次迭代训练下,对训练数据进行第i次数据分割,得到第i分割结果;
所述训练模块52,用于通过与所述集群节点相对应的N个训练器对所述第i分割结果进行第i次迭代训练,得到第i训练结果;
所述传递模块53,用于将所述第i训练结果传递至所述N个训练器,以使所述N个训练器在第i+1次迭代训练下将所述第i训练结果作为新的网络系数;其中,所述i小于等于预设值M;所述i、N及M均为正整数。
在一实施例中,如图5所示,所述第i分割结果包括与集群节点的总个数N相对应的N个数据集;所述训练模块52包括分配单元521、训练单元522和数据处理单元523;
所述分配单元521,用于将所述第i分割结果中包括的N个数据集分别分配到与集群节点相对应的N个训练器;
所述训练单元522,用于利用所述N个训练器分别对所述N个数据集加以训练,得到训练结果;
所述数据处理单元523,用于将通过每个训练器得到的训练结果进行数据处理,得到第i训练结果。
在一示例中,如图5所示,所述训练单元522包括划分子单元5221、建模 子单元5222和训练子单元5223;
所述划分子单元5221,用于将分配到对应训练器的训练集进行划分,分为训练数据和测试数据;
所述建模子单元5222,用于利用所述训练数据对所述训练器进行建模,得到训练模型;
所述训练子单元5223,用于通过所述训练模型对测试数据进行训练,得到训练结果。
在一示例中,所述训练子单元5223,还用于通过所述训练模型对测试数据进行识别处理,得到识别处理结果;将所述识别处理结果与测试数据所对应的测试标签进行比对,得到训练结果。
在一示例中,所述数据处理单元523,还用于对所述通过每个训练器得到的训练结果进行加权平均处理,得到加权平均处理结果;将所述加权平均处理结果作为第i训练结果。
在实际应用中,本发明实施例用于组成所述装置的各模块,各模块所包括的单元及其子单元均可以通过所述装置中的处理器实现,也可以通过具体的逻辑电路实现;比如,在实际应用中,可由位于所述装置中的中央处理器(CPU)、微处理器(MPU)、数字信号处理器(DSP)、或现场可编程门阵列(FPGA)实现。
这里需要指出的是:以上装置实施例项的描述,与上述方法描述是类似的,具有同方法实施例一至四相同的有益效果,因此不做赘述。对于本发明装置实施例中未披露的技术细节,本领域的技术人员请参照本发明方法实施例一至四的描述而理解,为节约篇幅,这里不再赘述。
以上所述仅是本发明实施例的实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明实施例原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明实施例的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!