一种快速的多关键字文本匹配方法及装置与流程
本申请涉及语义检索,尤其涉及一种基于关键字的文本匹配方法及装置。
背景技术:
在企业中提到数据保护,大家可能常常想起文档,很少有人会关注文档中的内容,对数据的管理也比较单一,通常就是全加密、全授权,对文档的重要性不做区分,随着社会的发展,文档的格式越来越多,安全事件的不断爆发,使得人们对数据的关注度发生了变化,数据也分成了结构化数据和非结构化数据,更加的关注文档内容中的敏感信息,使用文档的应用有哪些,对不同类型的文档、含有不同内容的文档有区别的管理和存储。
以前要管控数据,大多是强管控,直接全部隔离,或者全部加密,我们称之为囚笼、枷锁式的管控,在实际的数据生产、使用、流转中带来了很多不必要的麻烦,人们需要更加灵活的方式来处理数据,智能化的数据安全管控应运而生,企业管理员可以按照数据的重要程度有针对性的对数据进行控制。核心能力就是文档的内容识别,通过识别可以扩展到对数据的防控。内容识别应该具备的识别能力具体来说有关键字、正则表达式、文档指纹、文档聚类等。
基于内容的基础检测技术中通常有三种方式:正则表达式检测、关键字检测和关键字对检测。基础检测方法采用常规的检测技术进行内容搜索和匹配,比较常见的都是正则表达式和关键字,此两种方法可以对明确的敏感信息内容进行检测。
基于关键字的内容搜索一般分为单模算法和多模算法两种。每次找一个词用单模算法,要同时查找多个词用多模算法。多模算法常用的有ac算法、wm算法、正则表达式等。采用ac算法可以一次性找出所有给定的词。
目前,现有技术存在以下缺点:
(1)只是简单的使用ac算法多次查找文本,不能处理关键词重复,关键词分组、关键词计数等问题,并不能完全发挥ac算法的优势。有的甚至使用的是单模算法做文本匹配。
(2)需要多次读取文件内容进行匹配,或者读取整个文本内容到内存再用ac算法匹配,匹配速度慢,占用内存较大。
技术实现要素:
本发明提出一种基于快速的文本匹配方法,用于快速搜索文本内容。
本发明解决的技术问题:
本发明在常规多模算法的基础上合并多组要搜索的关键词在一起,通过建立关键词的多值索引来解决关键词重复和关键词分组的问题。通过对大文件分块内存映射和内存块拼接解决占用内存过大和性能问题。
本发明的技术方案:
本发明提供一种快速的多关键字文本匹配方法,包括以下步骤:(1)建立匹配规则,一条匹配规则包含多个关键词组,该多个关键词组之间是或的关系,一个关键词组包含多个关键词以及该关键词组的词频阈值,组内关键词与关键词之间是等价关系,定义关键词组内关键词出现的次数和为词频,若某关键词组的词频超过该关键词组的词频阈值则认为该关键词组所属的匹配规则命中;(2)建立关键词的多值索引,使不同匹配规则或不同关键词组之间重复的关键词对应多条“匹配规则+关键词组”组合,由此,通过关键词即可找到对应的所有“匹配规则+关键词组”组合,对找到的所有“匹配规则+关键词组”组合内的该关键词分别进行计数,即重复的关键词在不同的关键词组内分别计数,相当于每个关键词组都独立的进行一次匹配,从而使一次匹配达到多次匹配的效果。
本发明提供一种快速的多关键字文本匹配装置,包括以下模块:(1)匹配规则建立模块,用于建立匹配规则,一条匹配规则包含多个关键词组,该多个关键词组之间是或的关系,一个关键词组包含多个关键词以及该关键词组的词频阈值,组内关键词与关键词之间是等价关系,定义关键词组内关键词出现的次数和为词频,若某关键词组的词频超过该关键词组的词频阈值则认为该关键词组所属的匹配规则命中;(2)关键词多值索引建立及匹配模块,用于建立关键词的多值索引,使不同匹配规则或不同关键词组之间重复的关键词对应多条“匹配规则+关键词组”组合,由此,通过关键词即可找到对应的所有“匹配规则+关键词组”组合,对找到的所有“匹配规则+关键词组”组合内的该关键词分别进行计数,即重复的关键词在不同的关键词组内分别计数,相当于每个关键词组都独立的进行一次匹配,从而使一次匹配达到多次匹配的效果。
优选的,采用文件映射内存的方式来执行搜索。当被搜索的文件较大导致不能一次性加载到内存中时,采用将文件分块且重复搜索块边界的处理方式。采用记录匹配位置在整个文件中的偏移量的方法来滤除重复的匹配结果。多关键字文本匹配采用多模匹配算法,例如ac算法、正则表达式或wm算法。
本发明的技术效果:
1.真正利用ac算法等多模匹配算法,只对输入数据进行一次匹配,性能显著提高。
2.采用文件映射的分块处理方法,减少了内存占用,可以处理超大文件,同时不会降低搜索匹配性能。
附图说明
图1为关键词、关键词组、匹配规则的关系图。
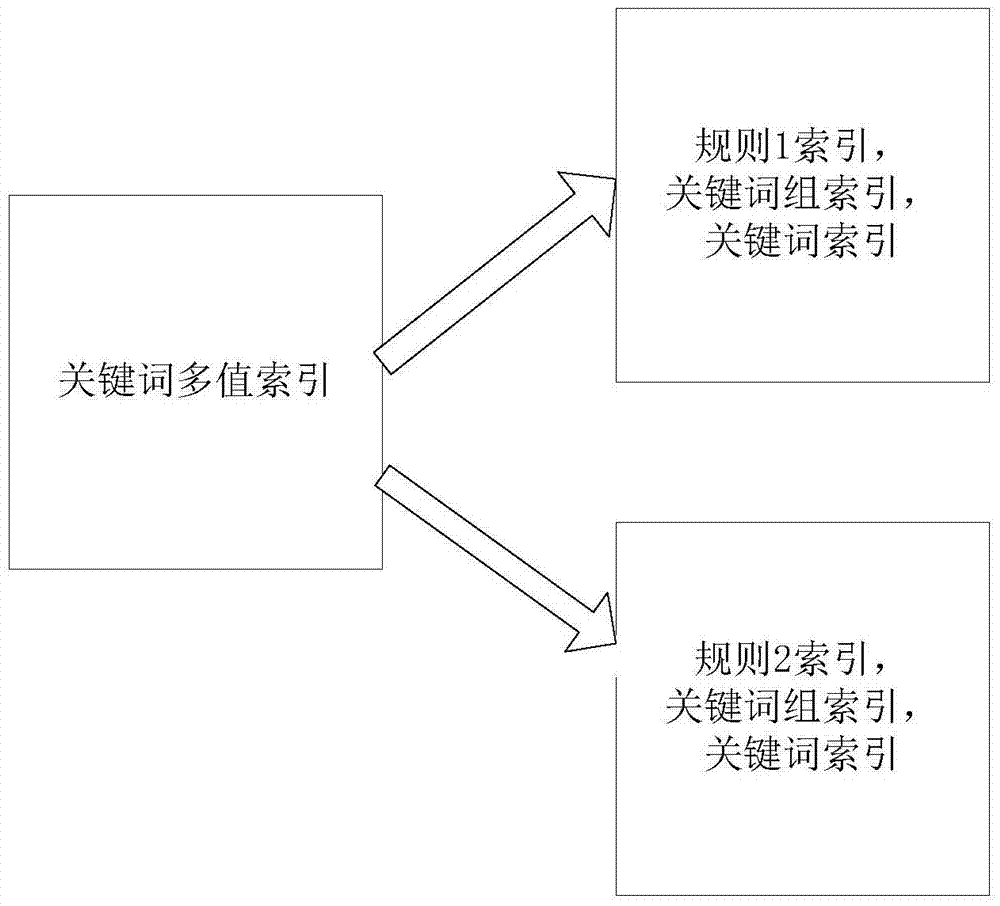
图2为关键词多值索引图。
图3为文件分块处理示意图。
具体实施方式
以下给出相关缩略语和关键术语定义:
ac算法:全称aho-corasick算法,是一种字符串多模式匹配算法。用于在一段文本中查找多个模式字符串。
关键词:ac算法中要匹配搜索的词。
关键词组:一个关键词组包含多个关键词以及该关键词组的词频阈值,组内关键词与关键词之间是等价关系。
词频:关键词组内的关键词出现的次数和。
匹配规则:一条规则包含多个关键词组,关键词组之间是或的关系,任意一组关键词满足词频的阈值则认为匹配规则命中。
如图1所示,匹配规则包含多个“关键词组”,“关键词组”包含多个关键词及该关键词组的词频阈值,不同规则或关键词组内可以包含相同的关键词。
最终要在文本中确定哪些规则是命中的,即任意一个关键词组的词频超过该关键词组的词频阈值则认为该关键词组所在的规则命中。
要充分利用ac算法的优势就要把所有规则和关键词组内的关键词合并在一起,由ac算法一次匹配完成。考虑到规则之间的关键词会重复出现,则需要过滤掉重复的词,保证ac算法搜索的关键词不会出现重复,这里采用建立关键词的多值索引的方法解决规则或关键词组之间关键词重复的问题,建立多值索引后可以由关键词找到对应的规则和关键词组。关键词的多值索引如图2所示。
重复的关键词对应多条规则和关键词组。当搜索到一个关键词时要对所有规则和关键词组内的相同的关键词进行计数,即重复的关键词会在不同的关键词组内多次计数。相当于每个关键词组都独立的进行一次匹配。这样一次匹配达到了多次匹配的效果。
总结本发明的快速多关键字文本匹配方法,步骤如下:(1)建立匹配规则,一条匹配规则包含多个关键词组,该多个关键词组之间是或的关系,一个关键词组包含多个关键词以及该关键词组的词频阈值,组内关键词与关键词之间是等价关系,定义关键词组内关键词出现的次数和为词频,若某关键词组的词频超过该关键词组的词频阈值则认为该关键词组所属的匹配规则命中;(2)建立关键词的多值索引,使不同匹配规则或不同关键词组之间重复的关键词对应多条“匹配规则+关键词组”的组合,由此,通过关键词即可找到对应的所有“匹配规则+关键词组”组合,对找到的所有“匹配规则+关键词组”组合内的该关键词分别进行计数,即重复的关键词在不同的关键词组内分别计数,相当于每个关键词组都独立的进行一次匹配,从而使一次匹配达到多次匹配的效果。
由于被检索的内容通常是office、pdf、txt等包含文本内容的文件,经过解压缩和文件格式转换后生成纯文本的文件。当文本内容不大时可以一次性加载到内存中进行搜索匹配等处理,当文本内容较大时只能加载部分文本内容到内存中,需要对文件进行分块,每次加载文件的一块到内存进行搜索处理,最后需要合并多次处理结果。这样可以用较小内存来处理很大的文件。当文件分块后会导致文件中的词被拆分到前后两个文件块中,最终导致跨越块边界的词无法被搜索出来,这里采用重复搜索块边界的方法来解决,如图3所示。一般关键词长不会超过2048字节,选取4k字节作为相邻文件块的重复区域,每次搜索一个文件块在加上4k字节。为了提高性能,不采用读取文件的方式,而是采用文件映射内存的方式,每次搜索文件映射长度为一个文件块+4k。例如:文件分块大小为4mb,一次文件映射为4mb+4k,每次匹配的长度为4mb+4k,每块搜索会多搜索4k的数据。当在重复区域搜索出关键词时会导致下一块搜索时再次被搜索出来,这里采用记录上次匹配位置在整个文件中的偏移量的方法过滤掉,因为重复匹配位置的文件偏移量总是相同的。
本发明使用的ac算法可用正则表达式或wm算法等其它多模匹配算法替代。
- 还没有人留言评论。精彩留言会获得点赞!