车载交互式系统以及车载信息设备的制作方法
本发明涉及一种车载交互式系统以及车载信息设备。
背景技术:
作为本技术领域的背景技术,存在日本特开2014-106927号公报(专利文献1)。在该公报中记载了“具有:操作受理单元33,其受理规定的用户操作;声音识别单元23,其将声音数据转换为文本数据;分类单元222,其从上述声音识别单元所识别的文本数据中提取一个以上的检索关键字,并分类为预先规定的类别;检索关键字生成单元226,其在不存在被分类为类别的检索关键字的情况下,读取记录在检索历史数据中的相同类别的过去的检索关键字而决定为该类别的检索关键字;检索历史记录单元227,其将上述分类单元所分类的检索关键字与类别建立对应并作为上述检索历史数据而以时间序列进行记录;以及参照历史变更单元228,其对检索关键字生成单元从上述检索历史数据中读取检索关键字的时间序列上的位置进行变更。”
现有技术文献
专利文献
专利文献1:日本特开2014-106927号公报
技术实现要素:
用户通过在车辆内与车载装置进行对话而能够检索期望的信息,但是在发声内容自由度高的情况下,用户有时对应该说什么感到困惑。
因此,本发明的目的在于提供一种对于用户而言进一步提高便利性的车载交互式系统以及车载信息设备。
为了实现上述目的,车载交互式系统具备:车载信息设备,其被输入用户发出的语音;交互式声音识别处理部,其对上述语音进行交互式声音识别处理;以及应答部,其将基于上述交互式声音识别处理的结果的应答发送到上述车载信息设备,该车载交互式系统的特征在于,具备:显示部,其设置于上述车载信息设备;以及显示控制部,其将联想到如下单词或语句的图像的影像显示在上述显示部中,该单词或语句在用于得到上述应答的发声中使用。
发明效果
根据本发明,对于用户而言进一步提高了便利性。
附图说明
图1是示意性地示出本发明的实施方式的车载交互式系统的构成的图。
图2是表示车载信息设备的构成的功能框图。
图3是示意性地示出虚像的显示方式的图。
图4是表示服务提供服务器的构成的功能框图。
图5是用于说明内容服务器(contents server)所提供的内容的多样性的树形图。
图6是与联想影像的显示动作相关的序列图。
图7是表示待机画面的一例的图。
图8是表示内容的获取要求中的对话应答画面的显示例的图。
图9是表示POI信息检索要求中的对话应答画面的显示例的图。
图10是联想影像的说明图。
具体实施方式
以下,参照附图说明本发明的实施方式。
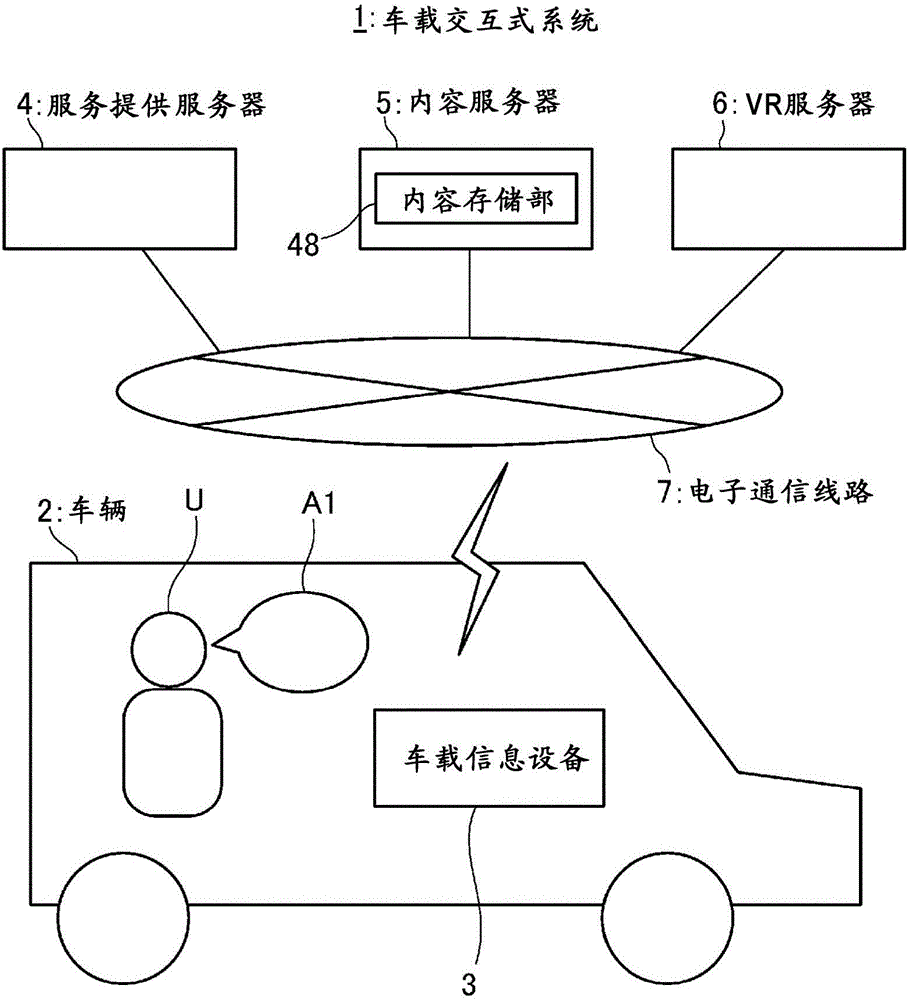
图1是示意性地示出本实施方式的车载交互式系统1的构成的图。
车载交互式系统1为供搭乘于车辆2的用户U(主要是驾驶员)通过声音输入对搭载于该车辆2的车载信息设备3进行指示来进行操作的系统。在该声音输入中使用交互式声音识别处理。
交互式声音识别处理与声音识别处理不同,并非对“指令(command)”进行识别处理而是对“自然的口语”进行识别处理。
“指令”是指为了指示各种操作而预先规定的单词或语句,例如为“声音输入开始”、“○○显示”、“播放音乐”等单词或语句。在使用了“指令”的识别处理中,不识别“指令”以外的单词、语句,因此用户U为了进行恰当的指示而需要具备针对“指令”的预备知识。
另一方面,“自然的口语”中的“口语”是指日常会话所使用的语句,“自然的”“口语”是指在日常生活中用户U在与相对的“听众”之间的会话中通常所使用的语句,而并非是用户U意识到向声音识别装置的声音输入操作而说出的“口语”。
即,在该车载交互式系统1中,即使说出“自然的口语”而进行声音输入,也能通过交互式声音识别处理而识别和理解与“听众”通常所理解的意思等同的内容。因此,用户U不需要预先获知用于对车载信息设备3进行指示的“指令”,能够以与日常生活中谈话时相同的自由的发声进行指示。
另外,该车载交互式系统1通过基于用户U的语音A1的声音输入进行的操作,能够获取内容以及检索POI信息,如图1所示,该车载交互式系统1具备上述车载信息设备3、服务提供服务器4、内容服务器5以及VR服务器6,这些设备及服务器与电子通信线路7以相互进行数据通信的方式连接。
图2是表示车载信息设备3的构成的功能框图。
车载信息设备3为搭载于车辆2的车载型设备,构成为除了能够实现内容提供功能和POI检索功能以外还能够实现导航功能和驾驶支援功能,并且构成为能够通过声音输入来操作这些功能。
即,如图2所示,车载信息设备3具备声音输入部10、操作部11、显示部12、声音输出部15、内容播放部16、导航部17、驾驶支援部18、数据通信部19、存储部20以及控制部30。
控制部30统筹地控制车载信息设备3的各部分,由具备CPU、RAM、ROM等的微型计算机构成。另外,在ROM中存储有用于实现基于控制部30的控制功能的计算机程序。在后文中说明该控制部30的功能性构成。
声音输入部10获取用户U所发出的语音A1并输出到控制部30。
该声音输入部10具备例如收集语音A1并输出模拟声音信号的话筒装置、以规定的编码形式将该模拟声音信号数字化并输出数字声音信号的数字处理器,该数字声音信号被输出到控制部30。
操作部11具备多个操作器,能够对车载信息设备3进行手动操作。
显示部12显示各种信息,具备LCD13和HUD14。
LCD13为液晶显示器,设置于在车辆2上设置的仪表板(未图示),显示主菜单画面、与内容提供功能、导航功能和驾驶支援功能这些各功能对应的画面。
例如作为与内容提供功能对应的画面,显示内容显示画面、用于对音乐内容、动态图像内容的播放进行操作的操作画面。另外,作为与导航功能对应的画面,将显示路线引导用地图的地图画面、周边地图、显示POI(Point of Interest)信息的信息显示画面进行显示。
此外,也可以代替LCD13而使用例如有机EL显示器等其它平板显示器。另外,也可以在LCD13上设置触摸面板来构成上述操作部11。
HUD14为根据行驶中的道路、交通状况来显示支援驾驶员的驾驶的信息的显示单元,是在驾驶员的前方显示基于虚像的虚像画面V的所谓平视显示器(HUD:Head-Up Display)。
图3是示意性地示出虚像画面V的显示方式的图。
如图4所示,HUD14通过将像投影至车辆2的前挡风玻璃40上来使驾驶员视觉识别虚像画面V,具有用于投影虚像画面V的未图示的投影装置、投影光学系统。
为了使驾驶员在驾驶操作中的视觉识别更容易,虚像画面V在从驾驶员观察时显示在方向盘41的正面位置的规定区域42中。
此外,与HUD14的显示位置不同,上述LCD13设置于不容易进入或不会进入驾驶员(其在驾驶操作中正面观察前挡风玻璃40)的视野的位置。
返回至上述图2,声音输出部15输出各种声音,具备配置于车辆2的车室内的扬声器装置。
声音输出部15所输出的声音可举出内容播放声音、车载信息设备3的操作音以及操作引导声音、上述交互式声音识别处理中的对话声音等。
内容播放部16在控制部30的控制下实现音乐内容、动态图像内容、影像内容以及文字内容等多媒体内容的播放输出功能。该内容播放部16具有通常的车载音频装置所具备的多媒体播放功能,通过声音输出部15适当地输出声音,并且在显示部12的LCD13中适当地显示动态图像、影像、文字。即,这些声音输出部15和显示部12还作为将内容以用户能够视听的方式输出内容的输出部而发挥功能。
导航部17在控制部30的控制下实现导航功能。该导航功能包含对从当前所在地或用户指定地点至目的地为止的路线进行检索的路线检索功能、对从当前所在地至目的地为止的路线进行引导的路线引导功能。
该导航部17具有普通的车载导航装置(其具备GPS等测位装置和存储地图数据的存储部等)所具备的各种功能,通过声音输出部15来输出声音,并且在显示部12的LCD13中适当地显示地图、影像、文字等各种信息。另外,在地图数据中作为道路信息而包含驾驶支援部18的驾驶支援所需的各种信息(法定速度、坡度、管制信息、警戒信息等)。
驾驶支援部18在控制部30的控制下实现对驾驶车辆2的驾驶员的驾驶进行支援的驾驶支援功能。如上述图3所示,该驾驶支援部18通过在显示部12的HUD14中显示驾驶支援影像43来支援驾驶员的驾驶。
只要是表示对驾驶员的驾驶操作有益的信息的影像,则该驾驶支援影像43就可以使用任意的影像。例如将指示到达目的地的路径的方向的路径引导影像、表示行驶中道路信息(例如法定速度、坡度、管制信息、警戒信息等)的影像、对周围及/或行驶方向前方的障碍物进行警告的影像等影像使用于驾驶支援影像43。
驾驶支援部18根据导航部17所具备的地图数据和GPS、以及车辆2所具备的各种车辆信息传感器(例如车速脉冲传感器、周围物体检测装置、刹车操作检测传感器等),来特定对驾驶员的驾驶操作有益的信息,将与该信息相应的驾驶支援影像43显示在HUD14中。
数据通信部19具备通过无线通信与电子通信线路7进行通信的功能。在该无线通信中能够使用例如使用了移动电话网的通信、无线LAN等各种移动体通信。另外,数据通信部19也可以具有将智能手机、无线LAN路由器终端等其它通信装置用作中继器而与电子通信线路7进行通信的结构。
存储部20存储控制部30所执行的计算机程序、各种数据。
上述控制部30具备内容播放控制部31、导航控制部32、驾驶支援控制部33、显示控制部34以及服务器协作部35。
内容播放控制部31、导航控制部32以及驾驶支援控制部33分别控制内容播放部16、导航部17以及驾驶支援部18的动作。
显示控制部34控制各种信息向显示部12所具备的LCD13的显示以及虚像画面V向HUD14的显示。
另外,该显示控制部34在能够受理基于语音A1的声音输入时,如上述图3所示,将表示处于声音输入的待机状态这一情况的话筒影像44显示在HUD14中。通过在HUD14中显示话筒影像44,即使用户U处于驾驶操作中,也不需要移开视线就能够掌握能够受理基于语音A1的声音输入这一情况。
此外,显示控制部34在话筒影像44显示时显示联想影像45,在后文中说明该情况。
服务器协作部35经由数据通信部19与服务提供服务器4进行通信,通过与该服务提供服务器4的协作,通过交互式声音识别对语音A1进行声音识别和理解,执行向用户U提供内容和POI信息检索。
具体地说,在该车载交互式系统1中,服务提供服务器4统筹地执行与对用户U的语音A1的声音识别和理解相关的处理、以及与用户U所要求的内容获取和POI信息的检索相关的处理。
即,服务器协作部35将用户U发出的语音A1转换为声音数据并发送到服务提供服务器4,从该服务提供服务器4接收基于对该语音A1进行交互式声音识别处理而得到的结果的应答并输出到显示部12、声音输出部15。
车载信息设备3从服务提供服务器4所接收的应答例如为:用户U所要求的内容、POI信息检索的结果以及向用户U请求应答的对话应答句。
图4是表示服务提供服务器4的构成的功能框图。
服务提供服务器4为通过交互式声音识别处理对用户U的语音A1进行声音识别及理解、并将用户U所要求的内容或POI信息发送到车载信息设备3的服务器计算机,如图4所示,该服务提供服务器4具备控制部50、数据通信部51以及存储部52。
数据通信部51经由电子通信线路7在与车载信息设备3、内容服务器5以及VR服务器6之间进行数据通信。
存储部52存储控制部50所执行的计算机程序、各种数据。
控制部50统筹地控制各部分并且执行交互式声音识别处理,具备CPU、RAM以及ROM等,根据存储在存储部52中的计算机程序来进行动作。
交互式声音识别处理部54具有实现交互式声音识别处理的功能,具备语音输入部56、声音识别部57、发声内容理解部58以及应答部59。
语音输入部56被输入经由数据通信部51从车载信息设备3接收到的用户U的语音A1并输出到声音识别部57。该语音输入部56为了提高声音识别部57对语音A1的声音识别精度,而在去除该语音A1的声音数据内包含的噪声(noise)之后,输出到声音识别部57。此外,在噪声去除中能够使用声音信号处理领域中的任意方法。
声音识别部57对语音A1进行声音识别,向发声内容理解部58输出将语音A1转换为文字列(文本)而得到的文本数据。
在该车载交互式系统1中,为了高精度地对语音A1的声音识别进行处理,如上述图1所示,设置有承担声音识别处理的VR服务器6,声音识别部57使用该VR服务器6将语音A1转换为文本数据。
VR服务器6经由电子通信线路7从服务提供服务器4接收语音A1的声音数据,实施声音识别处理并转换为文字列,并将该文字列的文本数据发送到服务提供服务器4。该文本数据通过声音识别部57被输出到发声内容理解部58。
发声内容理解部58根据文本数据对用户U所说出的内容进行理解,并将理解结果输出到应答部59。
详细而言,该发声内容理解部58并非从文本数据中提取出上述“指令”而对指示进行理解,而是从文本数据的单词列中提取该服务提供服务器4执行任务时变得重要的关键字,将这些关键字作为理解结果而输出到应答部59。
任务是指用户U所要求的要件,在该车载交互式系统1中,为内容的获取要求或POI信息的检索要求。
即,在发声内容理解部58中,获取内容时变得重要的单词(例如,内容的种类、详细内容、名称等)以及POI信息检索时变得重要的单词(成为检索关键字的单词)作为关键字而被提取。
例如,在语音A1的文本数据为“嗯…我想知道足球世界杯的结果。”这种文字列的情况下,发声内容理解部58理解为用户U的要求(任务)为内容的获取要求,作为该理解结果,将“足球、世界杯、结果”作为关键字而提取。
另外,例如在语音A1的文本数据为“希望找到附近的意大利餐馆。”这一文字列的情况下,发声内容理解部58理解为用户U的要求为POI信息的检索要求,作为该理解结果,将“附近、意大利、餐馆”作为关键字而提取。
应答部59根据由发声内容理解部58提取的关键字,执行由发声内容理解部58理解的任务(用户U的要求),将执行结果作为应答而发送到车载信息设备3。
具体地说,在任务为内容的获取要求的情况下,应答部59根据关键字来特定用户U所要求的内容,并将该内容发送到车载信息设备3。例如在关键字为“足球、世界杯、结果”的情况下,作为用户U所获取要求的内容,特定足球世界杯的比赛结果的信息。
另外,例如在任务为POI信息检索要求的情况下,应答部59根据关键字来检索POI信息,并将检索结果发送到车载信息设备3。例如在关键字为“附近、意大利、餐馆”的情况下,检索当前所在地周边的意大利餐馆的POI信息。
应答部59在获取内容或POI信息的数据的情况下,从内容服务器5(图1)获取并发送到车载信息设备3。
此外,应答部59在理解结果的关键字不足而无法特定用户U所要求的内容或POI信息检索的情况下,生成对这些内容或POI信息的特定所需的语音A1的输入进行催促的对话应答句,并将对话应答句的文本数据发送到车载信息设备3。对于车载信息设备3而言,输出基于该对话应答句的文本数据的合成声音,由此,以对话形式推进基于用户U的声音输入操作。
在上述图1中,内容服务器5为所谓内容提供商(contents provider)所管理的服务器计算机,具备将多种内容的数据(以下,称为“内容数据”)以能够提供给服务提供服务器4的方式进行存储的内容存储部48。
图5是用于说明内容服务器5所提供的内容的多样性的树形图。
如该图所示,内容服务器5将“新闻”、“广播”、“天气”以及“美食”这些各类型J的内容数据以能够提供的方式保持。
关于“新闻”、“广播”以及“天气”的类型J,被细分化为相对于类型J位于下级层级的下级层级类型J1,在这些下级层级类型J1中分别保持有内容数据。
例如在“新闻”这一类型J的下面配置有“经济”、“IT”以及“体育”等下级层级类型J1,在每个下级层级类型J1中准备有与新闻的类型J相关的内容数据。
另外,“广播”这一类型J是指所谓网络广播,在“广播”这一类型J的下面配置有“摇滚乐”、“爵士乐(JAZZ)”等下级层级类型J1,在每个下级层级类型J1中准备有音乐内容数据。
另外,“天气”这一类型J为提供天气信息的类型,在“天气”这一类型J的下面配置有以地区单位分类的“关东地区”、“九州地区”等下级层级类型J1。另外,在该下级层级类型J1的下面进一步分别形成层级结构而配置有以县单位分类的下级层级类型J2以及将县进一步以市区町村单位分类的下级层级类型J3。而且,在作为最下层的下级层级类型J3中分别准备有天气内容数据。
“美食”表示POI信息的检索对象的类型J,例如准备有餐馆信息等POI信息K。
内容服务器5将图5示出的多种类型J的内容数据以及POI信息保持于内容存储部48,但是这些内容数据并非按类型J分开管理,而是将类型J及下级层级类型J1、J2···与包含其它附加信息的标签信息建立关联而管理。附加信息是指针对每个内容数据而固有的信息、表示基于详细内容的特征的信息等。
内容服务器5在从服务提供服务器4接收到内容数据或POI信息的要求的情况下,并非以针对每个与要求相应的类型J而将层级向下级追溯的方式进行缩小范围的检索(细化检索)来检索匹配的内容数据或POI信息,而是如以下那样进行检索。
即,内容服务器5在接收到内容数据的要求的情况下,从全部内容数据中检索具有与要求相匹配的程度高的标签信息的内容数据,并发送到服务提供服务器4。
另外,内容服务器5在接收到POI信息的要求的情况下,也从全部POI信息中检索具有与要求相匹配的程度高的标签信息的POI信息,并发送到服务提供服务器4。
根据该检索,在要求内容数据时,即使未指定该内容数据所属的类型J和下级层级类型J1、J2···,也能够提取与要求相匹配的内容数据。
即,在用户U通过语音A1的声音输入来要求内容数据时,即使不说出用于指定类型J和下级层级类型J1、J2···的单词,也能特定期望的内容数据。
这样,在该车载交互式系统1中,用户U在要求内容和POI信息时,即使不了解图5示出的类型J、下级层级类型J1、J2、···,只要发出与期望的内容和POI信息相关的单词、语句,则也能通过服务提供服务器4获取该期望的内容和POI信息,并提供给用户U。
除此以外,对于该车载交互式系统1而言,如上所述,用户U即使不发出“指令”等规定的单词,也能够通过日常自由的发声对车载信息设备3进行基于声音的指示。
即,用户U在对车载信息设备3进行指示时,可以说出任何内容,也可以以任意表现进行发声,从而实现用于声音输入的发声的自由度非常高的车载交互式系统1。
另一方面,对于未掌握车载交互式系统1可提供的内容的种类、POI信息的用户U而言,当用于声音输入的发声的自由度高时,反而难以确定说什么好。
于是,例如如果用户U对操作部11进行手动操作而使主菜单等显示于LCD13,则能够掌握可提供的内容的种类等,但是在驾驶操作中驾驶员最好不注视LCD13的画面。
另一方面,HUD14位于驾驶操作中的驾驶员的视野内,因此当在该HUD14中以文字方式显示优选使用于声音输入的发声的例句等时,驾驶员会无意识地读取文字而有可能减弱驾驶员的集中力。
另外,对于用户U需要掌握可提供的内容这一情况,不能说是不需要预备知识的声音输入操作,更不用说显示使用于声音输入的发声的例句等并使用户U读完该例句等这一情况,与基于“指令”的声音输入没有任何区别。
因此,在该车载信息设备3中,在HUD14的虚像画面V中如上述图3所示那样显示上述联想影像45,使得即使用户U并未掌握可提供的内容并且处于驾驶操作中,用户U也能够直观地感受用于进行指示的发声。该联想影像45为描绘了如下图像的影像,该图像使用户联想到在通过声音输入向车载信息设备3进行指示时使用的单词或语句,联想影像45向HUD14的显示由车载信息设备3的显示控制部34进行控制。另外,使用于该联想影像45的图像是由表示或象征该单词、语句的图形、图案、绘画等构成的影像,不包含直接表示该单词、语句的文字列。
图6是与联想影像45的显示动作相关的序列图。
如该图所示,车载信息设备3在等待接收声音输入的待机时,作为虚像画面V而显示待机画面V1(步骤S1)。
图7是表示待机画面V1的一例的图。
该图示出的待机画面V1为车辆2的行驶中的显示例,包含支援驾驶操作的驾驶支援影像43,另外显示有表示处于声音输入的待机状态这一情况的话筒影像44。而且,与该话筒影像44相邻地显示有联想影像45。
在该车载交互式系统1中,如上述图5所示,用户U能够通过声音输入操作来获取“新闻”、“广播”、“天气”以及“美食”这些各类型J的内容数据、POI信息。
因而,对于声音输入的待机画面V1而言,车载信息设备3作为联想影像45而显示描绘了如下图像的影像,该图像会使用户联想到在为了获取这些各类型J的内容以及检索POI信息而通过声音输入进行指示时使用的单词、语句。
此外,在该图7的示例中,为了有助于理解,对每个联想影像45一并记载了类型J的名称,但是并不一定要在HUD14中显示类型名称。在对联想影像45一并记载了文字的情况下,优选将该文字设为构成一个单词的文字列,以使得用户U看一眼就能够瞬间理解。
在图7的示例中,使得联想到与“新闻”的类型J相关联的单词的图像为“报纸”,该“报纸”的图像向用户U暗示或使用户U联想到“新闻”、“政治”、“经济”、“体育”、或“足球的比赛结果”等与“报纸”相关联的单词、语句。
此时,如果在待机画面V1上没有明确显示类型J的名称,则视觉观察联想影像45的图像的用户U会纯粹联想与各个关心的事、兴趣的方向相符合的单词、语句而促进其发声。
这样联想的单词、语句并不局限于类型J的名称而是纯粹表示用户U的各个关心的事、兴趣,因此在交互式声音识别处理中,是包含与发声内容理解部58所理解的关键字充分相称的单词在内的单词、语句的可能性提高,即,在上述图5的树形图中,是能够直接特定下级层级类型J1、J2、···的内容数据的单词、语句的可能性提高。
因而,通过将这种单词、语句使用于语音A1,能够通过一次语音A1的声音输入来容易地特定所期望的内容数据。
返回至上述图6,车载信息设备3若在待机画面V1显示时被输入用户U的语音A1(步骤S2),则将该语音A1的声音数据发送到服务提供服务器4(步骤S3)。
服务提供服务器4在接收到语音A1的声音数据时(步骤S4),对该声音数据实施交互式声音识别处理而进行声音识别和理解(步骤S5)。该语音A1的理解的结果是,特定用户U所要求的任务(内容的获取要求或POI信息的检索要求)和对于任务的执行而言重要的关键字。
此外,在该车载交互式系统1中,如上所述,声音识别由VR服务器6进行。
接着,服务提供服务器4判断是否需要内容的细化(步骤S6)。对于是否需要该细化,在根据语音A1的理解结果无法特定应提供的内容的情况下或POI信息的检索结果超出规定数量的情况下,判断为“需要”细化。
例如在内容的获取要求中,在语音A1中包含能够直接特定下级层级类型J1、J2、···的内容的单词、语句的情况下,用户U所要求的内容被充分特定,因此判断为“不需要”细化。
与此相对,在例如用户U仅将“新闻”这一类型J的名称作为语音A1而输入的情况下,对应的内容数量变得过多,因此不能特定用户U所要求的内容。因而,在该情况下,服务提供服务器4判断为“需要”上述细化。
内容的细化以与用户U之间对话的形式来进行,服务提供服务器4生成对话应答句(其促使细化所需的语音A1的答复)的文本数据,并发送到车载信息设备3(步骤S7)。
车载信息设备3在接收到对话应答句的文本数据时(步骤S8),以合成声音来读完该文本数据而进行声音输出,并且将对话应答画面V2显示在HUD14中(步骤S9)。
图8是表示内容的获取要求中的对话应答画面V2的显示例的图。
在内容的获取要求中,在对话应答画面V2上以文字列方式显示对话应答句46。通过显示对话应答句46,即使在对话应答句的声音输出被车辆2的行驶音等掩盖而用户U未能听见的情况下,用户U也能够掌握对话应答的内容。
并且,对于该对话应答画面V2而言,通过对话应答句46暗示了用户U应答复的内容,但是为了使用户U容易想象其答复的发声所使用的单词、语句,也在该对话应答画面V2上显示联想影像45。
该显示例为用于使属于“新闻”的类型J的新闻内容细化的对话应答画面V2,因此,作为联想影像45,使用与配置在“新闻”的类型J下级的下级层级类型J1的名称即“经济”、“体育”等相关联的影像。
图9是表示POI信息检索要求中的对话应答画面V2的显示例的图。
在POI信息检索要求中,在对话应答画面V2中针对每个在检索中查到(hit)的POI信息来显示联想影像45。各个联想影像45的影像为例如POI信息所示的施设、建筑物、风景的照片影像,用户U根据该联想影像45,联想到表示POI的名称、特征的单词、语句。
另外,在对话应答画面V2中,在各个联想影像45中一并显示项目编号(标识符)。在POI信息检索要求中,该项目编号与对话应答句相当,在对话应答画面V2显示时也通过合成声音读完。用户U通过代替从联想影像45联想到的单词、语句而说出项目编号,能够容易地指定期望的POI信息。
返回至上述图6,当用户U进行对对话应答句答复的发声而输入了语音A1时(步骤S10),车载信息设备3将该语音A1的声音数据发送到服务提供服务器4(步骤S11)。
服务提供服务器4在接收到语音A1的声音数据时(步骤S12),对该声音数据实施交互式声音识别处理而进行声音识别和理解(步骤S13)。
然后,服务提供服务器4判断是否需要内容数据的细化(步骤S14),在“需要”细化的情况下,返回至步骤S7而重复进行用于细化的处理。
另外,在“不需要”细化的情况下,服务提供服务器4从内容服务器5中获取用户U所要求的内容数据或POI信息的检索结果(步骤S15),并发送到车载信息设备3(步骤S16)。
车载信息设备3在接收到内容数据或POI信息的检索结果时(步骤S17),将该内容数据或POI信息的检索结果通过声音和显示进行输出,由此提供给用户U(步骤S18)。
具体地说,车载信息设备3在内容数据或POI信息的检索结果包含文本数据的情况下,通过合成声音将该文本数据读完,并且对LCD13输出基于内容数据或POI信息的检索结果的显示。并且,在内容数据为音乐内容数据的情况下,车载信息设备3将音乐内容数据进行播放输出。
此外,车载信息设备3在通过显示来输出内容数据和POI信息的检索结果的情况下,也可以在HUD14中也以虚像方式显示与内容数据和POI信息的检索结果相关的信息。
根据上述说明的实施方式,起到以下效果。
即,在输出应答(其基于对用户U所发出的语音A1进行交互式声音识别处理而得到的结果)的车载信息设备3中,构成为将使得联想到在用于得到应答的发声中使用的单词或语句的图像即联想影像45显示在显示部12的HUD14中。
通过该结构,用户U通过视觉观察联想影像45,能够联想到通过声音输入说出的单词或语句,针对车载信息设备3的声音输入操作,即使不具备预备知识,也能够与期望的应答相匹配地适当地进行发声。
由此,可实现能够以自由的发声来进行声音输入操作并且用户U不会对使用于发声的单词、语句感到困惑的、便利性非常高的车载信息设备3。
另外,根据本实施方式,将使得联想到能够由车载信息设备3输出的内容的图像作为联想影像45而进行显示。
由此,用户U联想到与能够由车载信息设备3输出的内容相关的单词、语句并将其使用于发声,因此即使用户U并不预先获知能够输出的内容的范围,也能容易地获取内容。
另外,根据本实施方式,构成为在通过用户U的语音A1无法特定内容的情况下,将用于特定内容的对话应答句46以及使得联想到在答复该对话应答句时的发声中使用的单词或语句的联想影像45显示在显示部12的HUD14中。
由此,用户U在答复对话应答句时,也不会对使用于答复的单词、语句感到困惑而能够顺利地执行声音输入操作。
另外,根据本实施方式,构成为在作为用户U所要求的POI信息而特定了多个POI信息的情况下,将针对各个POI信息的每一个的联想影像45与作为标识符的项目编号47一起显示在HUD14中。
根据该结构,用户U在用于选择POI信息的发声中除了使用从联想影像45联想到的单词、语句以外,还能够使用项目编号47。特别是,用户U通过将项目编号47使用于发声,能够唯一地选择POI信息。
此外,在任务为内容获取要求的情况下,在特定了多个内容数据时,与POI信息同样地,当然也可以将针对每个内容数据的联想影像45与标识符一起作为对话应答画面V2而显示在HUD14中。
另外,根据本实施方式,构成为在HUD14中显示联想影像45。
根据该结构,即使驾驶员在驾驶操作中,也无需较大地偏离视线就能够视觉识别联想影像45,联想到使用于发声的单词、语句。
并且,对于联想影像45使用使得联想到用于发声的单词、语句的图像,由于并非是直接表示该单词、语句的文字列,因此即使在显示驾驶支援影像43的显示器中显示联想影像45,也能够避免驾驶时读取文字这种危险的行为。
此外,上述实施方式在始终不脱离本发明的宗旨的范围内能够任意地变形和应用。
例如,在上述实施方式中,在用户U习惯于自由度高的声音输入操作的情况下,也可以中止联想影像45的显示。
另外,也可以是,服务提供服务器4例如与对话应答句的内容相匹配地生成联想影像45的影像数据并发送到车载信息设备3并显示在HUD14中。
另外,图7~图9等示出的联想影像45的画面只不过是例示,并不限定于此。例如在图7中作为使得联想到与“新闻”的类型J相关联的单词的联想影像45而使用绘制了“报纸”的图像。
于是,如上所述,该“报纸”的图像不仅使用户U联想到“新闻”这一类型J的名称,如图10所示,还使用户U联想到在“新闻”的类型J的下级层级中系统排列的“经济”、“体育”等下级层级类型J1的类型的名称、以及这些下级层级类型J1的更下级的层级即“棒球”、“足球”等下级层级类型J2的类型的名称。
除此以外,绘制了“报纸”的联想影像45还作为如下影像而使用,即,该影像还对用户U暗示或使用户U联想到通过标签信息与这些类型J、下级层级类型J1、J2、···建立了关联的内容(例如,“汇率”、“足球比赛结果”等)的单词、语句。
这样,上述实施方式的联想影像45是作为如下图像而绘制的,即,该图像包含类型J、在该类型J的下级层级中系统排列的下级层级类型J1、J2、···以及与这些类型J或下级层级类型J1、J2、···建立了关联的内容的每一个。
由此,例如作为联想影像45,在分别针对每个类型J、下级层级类型J1、J2、···以及内容而将使用户U唯一地识别其名称、单词的影像作为联想影像45进行提示的情况下,用户U仅会说出唯一地识别的名称、单词,相对于此,上述实施方式的联想影像45,从一个联想影像45不仅能够联想到类型J,还能够联想到其下级层级类型J1、J2、···、内容而促使发声,结果是,还能够实现发声输入的次数的减少。
作为这种联想影像45的具体例,除了象征所包含的类型J、下级层级类型J1、J2、···以及内容的全部的、一个图形、文字、标记(以下,称为图形等)的图像以外,例如还存在包含象征类型J的图形等、象征下级层级类型J1、J2、···的图形等以及象征内容的图形等的每一个而绘制的图像。
另外,在上述实施方式中,服务提供服务器4能够受理的任务、能够提供的内容只不过是例示,能够设定任意的任务、内容。
另外,图2和图4是为了使本申请发明更容易理解而根据主要处理内容对车载信息设备3和服务提供服务器4的功能构成进行分类而示出的概要图,也能够根据处理内容将这些构成分类为更多的构成要素。另外,还能够以一个构成要素执行更多的处理的方式进行分类。另外,各构成要素的处理既可以通过一个硬件来执行也可以通过多个硬件来执行。
另外,各构成要素的处理既可以通过一个程序来实现也可以通过多个程序来实现。在该情况下,上述车载信息设备3和服务提供服务器4分别通过例如电子通信线路7来下载这些计算机程序,或从计算机可读取的记录介质中读取这些计算机程序,并通过各自的CPU来执行。
另外,例如上述图6的流程图的处理单位是为了使联想影像45的显示处理的理解更容易而根据主要处理内容来分割的单位。本申请发明并不受处理单位的分割方法、名称的限制。
即,也能够根据处理内容将联想影像45的显示处理分割为更多的处理单位。另外,还能够以使一个处理单位包含更多的处理的方式进行分割。另外,如果同样地进行联想影像45的显示,则上述流程图的处理顺序也并不限定于图示的示例。
另外,上述实施方式的联想影像45只要是通过交互式声音识别处理对用户U的声音输入进行识别并应答的设备,则并不限定于车载型的设备,能够使任意设备的显示部进行显示来使用户操作的便利性提高。
附图标记说明
1:车载交互式系统
2:车辆
3:车载信息设备
4:服务提供服务器
5:内容服务器
10:声音输入部
12:显示部
14:HUD(平视显示器)
15:声音输出部(输出部)
30:控制部
34:显示控制部
35:服务器协作部
40:前挡风玻璃
43:驾驶支援影像
44:话筒影像
45:联想影像
46:对话应答句
47:项目编号(标识符)
48:内容存储部
50:控制部
54:交互式声音识别处理部
56:语音输入部
57:声音识别部
58:发声内容理解部
59:应答部
A1:语音
U:用户
J:类型
J1、J2、···:下级层级类型
V:虚像画面
V1:待机画面
V2:对话应答画面
- 还没有人留言评论。精彩留言会获得点赞!