利用软件辅助上下文切换的中间线程抢占的制作方法
概括地说,本公开内容涉及电子领域。更具体地说,实施例涉及利用软件辅助上下文切换的中间线程抢占。
背景技术:
当正在运行GPGPU(图形处理单元上的通用计算)工作负载并且硬件对于其它工作负载是必需的时,可以使用一种机制来抢占(pre-empt)或中断GPGPU工作负载。这通常要求响应于中断来完成硬件中的所有现有的或正在执行的线程。这种机制对于期望在短时间内完成的线程效果很好。但是,当线程无限期或长时间运行时,在上下文切换中的响应时间可能非常长,有时甚至导致页面错误。
附图说明
参考附图提供了具体实施方式。在附图中,附图标记的最左边的位标识该附图标记首次出现的附图。相同的附图标记在不同的附图中的使用指示相似或相同的项目。
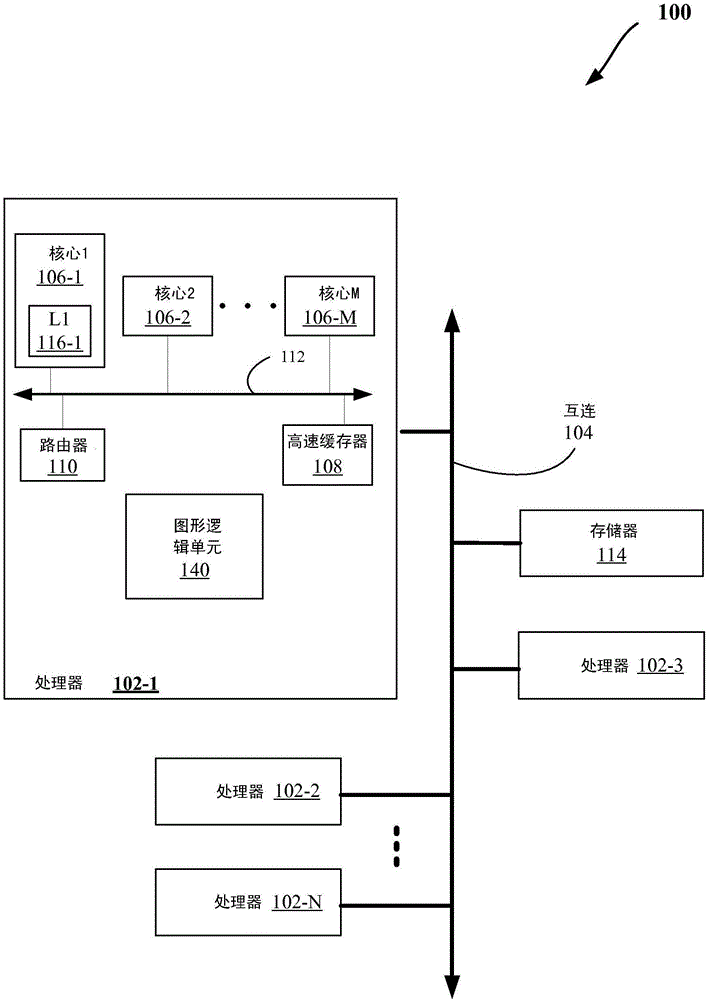
图1和图6-图8示出了可以用于实现本文中讨论的各个实施例的计算系统的实施例的框图。
图2示出了根据一些实施例的用于处理抢占的示例情况。
图3示出了根据实施例的图形逻辑单元的组件的框图。
图4示出了根据实施例的用于保存和恢复图形逻辑单元的上下文的预先确定的存储器映射。
图5和图5A示出了根据一些实施例的流程图。
具体实施方式
在下面的描述中,阐述了大量具体细节以便提供各个实施例的透彻理解。然而,可以在不使用这些具体细节的情况下实施各个实施例。在其它实例中,没有对公知的方法、过程、组件和电路进行详细描述,以防止模糊具体实施例。另外,实施例的各个方面可以使用各种模块来执行,诸如集成半导体电路(“硬件”)、被组织成一个或多个程序的计算机可读指令(“软件”)、或者硬件和软件的某种组合。为了本公开内容的目的,对“逻辑单元”的提及应该意指硬件、软件、固件或者它们的某种组合。
一些实施例提供了利用软件辅助上下文切换的中间线程抢占。实施例对GPGPU内核中间线程进行抢占或中断。系统的状态被保存并且可以在以后的时间点恢复以继续执行被抢占的内核以完成。相比之下,其它解决方案可能依赖于在能够切换到不同工作负载之前完全完成工作负载,或在更粗略的粒度上完成工作负载。
例如,如果线程组中的多个线程被分派(dispatched)用于执行,则一些解决方案可以提供仅在线程组边界处抢占分派的机制。任何分派的线程然后需要完成它们的任务。这增加了GPU对关键中断的响应时间。利用中间线程抢占,已经处于执行模式的所有线程可以在任何指令边界处被中断。这进而提高了工作负载之间切换的性能。
如本文中所讨论的,GPGPU是指图形处理单元(GPU)上的通用计算。GPU可以包括通常执行与图形任务相关的计算(如操纵图像、帧、场景等的操作)的图形逻辑单元或其它类型的逻辑单元,但是在GPGPU的情况下,它们也能够执行或进行通用计算。虽然参考图形逻辑单元讨论了一些实施例,但实施例不限于图形相关的逻辑单元,并且还可以应用于其它类型的非图形(例如,通用)逻辑单元。此外,可以对任何类型的计算设备(如桌上型计算机、移动计算机(如智能手机、平板电脑、UMPC(超移动个人计算机)、膝上型计算机,UltrabookTM计算设备、智能手表、智能眼镜等)、工作站等)执行各个实施例,其可以在实施例中的SOC(片上系统)平台上实现。
因此,一些实施例提供了可以在其它应用中使用的高度灵活的解决方案(例如,在完成之前需要停止工作负载以便为更高优先级的操作做准备的情况下)。一些实施例改进硬件对应用请求的响应性。它们还允许图形逻辑单元是多用途的。
一些实施例可以应用于包括一个或多个处理器(例如,具有一个或多个处理器核心)的计算系统(如参考图1-图8讨论的那些),包括例如移动计算设备(如智能手机、平板电脑、UMPC(超移动个人计算机)、膝上型计算机、UltrabookTM计算设备、智能手表、智能眼镜等)。更具体地说,图1根据实施例示出了计算系统100的框图。系统100可以包括一个或多个处理器102-1至102-N(在本文中统称为“一些处理器102”或“处理器102”)。在各个实施例中,处理器102可以是通用CPU和/或GPU。处理器102可以经由互连或总线104通信。每个处理器可以包括多个组件,为了清楚起见,仅结合处理器102-1对这些组件中的一些进行讨论。因此,其余处理器102-2至102-N中的每个处理器可以包括与结合处理器102-1所讨论的相同或相似的组件。
在实施例中,处理器102-1可以包括:一个或多个处理器核心106-1至106-M(在本文中被称为“一些核心106”或“核心106”)、高速缓存器108和/或路由器110。处理器核心106可以在单个集成电路(IC)芯片上实现。另外,芯片可以包括一个或多个共享和/或私有高速缓存器(如高速缓存器108)、总线或互连线(如总线或互连线112)、图形和/或存储器控制器(如结合图6-图8所讨论的那些)、或者其它组件。
在一个实施例中,路由器110可以用于在处理器102-1和/或系统100的各个组件之间进行通信。另外,处理器102-1可以包括一个以上的路由器110。另外,多个路由器110可以处于通信中,以便数据能够在处理器102-1内部或外部的各个组件之间进行路由。
高速缓存器108可以对由处理器102-1的一个或多个组件(如核心106)使用的数据(例如,包括指令)进行存储。例如,高速缓存器108可以对存储在存储器114中的数据以本地方式进行高速缓存,以便由处理器102的组件更加快速地访问(例如,由核心106更快地访问)。如图1中所示,存储器114可以经由互连线(interconnection)104与处理器102通信。在实施例中,高速缓存器108(可以是共享的)可以是中级高速缓存器(MLC)、最后级高速缓存器(LLC)等。另外,核心106中的每个核心可以包括1级(L1)高速缓存器(116-1)(在本文中通常被称为“L1高速缓存器116”)或其它级别的高速缓存器(如2级(L2)高速缓存器)。此外,处理器102-1的各个组件可以直接地、通过总线(例如,总线112)和/或存储器控制器或集线器与高速缓存器108通信。
如图1中所示,处理器102还可以包括用于执行如本文中所讨论的各种图形和/或通用计算相关的操作的图形逻辑单元140。逻辑单元140可以访问本文中所讨论的一个或多个存储设备(如高速缓存器108、L1高速缓存器116、存储器114、寄存器或系统100中的另一个存储器)以存储与逻辑单元140的操作相关的信息(如本文中所讨论的与系统100的各个组件通信的信息)。此外,虽然逻辑单元140被示为在处理器102内部,但是在各个实施例中,逻辑单元140可以位于系统100中的其它地方。例如,逻辑单元140可以替换核心106中的一个,可以直接耦合到互连112和/或互连104等。
通常,硬件(例如,逻辑单元140)中的状态可以分类为:(a)固定功能硬件中的状态;(b)线程的状态(即寄存器和指令指针等);和(c)SLM(或共享本地存储器,其指的是由图形逻辑单元/GPU用于中间结果的高速缓存/存储以及原本指向全局/主存储器的其它分散/聚集操作的存储器,例如,包括要频繁重复使用的缓冲数据)。例如,SLM可以支持这样的操作,其需要不同线程以便在它们之间共享数据和/或传递数据。
一些上下文保存和恢复过程可以作为状态机内置到硬件中,例如,在挂起状况(halt condition)下,某种形式的DMA(直接存储器访问)引擎/逻辑单元将所有硬件状态在预先定义的位置写入存储器中,并且遵照预先定义的序列。在实施例中,可编程引擎(图形逻辑单元/GPU的EU或执行单元(Execution Unit))中的现有控制用于在软件的协助下将线程的内容移动到存储器。为此目的可以对主要用于调试的异常处理硬件/逻辑单元进行扩展。此外,内核可以跳转到系统例程,其可以将硬件的一些上下文移动到存储器。
该机制可以被用来响应于中断而保存EU的状态。虽然一些特征可能已经存在,但是它们通常限于仅处理一些寄存器,并且可能不保存所有的线程状态。另外,系统例程的过程要求例程在完成之后返回到应用例程。在实施例中,系统可以在完成系统例程之后退出。在根据一些实施例示出用于处理抢占的不同情况的图2中描绘了该变化。
图2所示的三种情况如下:
情况A:现有的系统例程处理程序从给定的应用例程开始。启动的新线程是应用例程。系统例程返回到应用例程来完成。
情况B:实施例提供了一种途径,以便系统例程完成对存储器的写操作并在不返回到应用例程的情况下终止工作负载。这使得能够启动新的工作负载。
情况C:一个实施例提供了一种途径,以便以系统例程启动线程然后移动到应用例程,其将完成工作负载以终止。
图3示出了根据实施例的图形逻辑单元140的组件的框图。如图3所示,图形逻辑单元140包括线程孵化器302(例如,用于孵化一个或多个软件线程,包括提供传统上下文保存路径)、EU复杂逻辑单元(例如,包括用于执行指令的一个或多个执行单元,指令包括由系统例程发起的保存周期数据(saving cycle data))、SLM 306(例如,用于存储和处理共享的本地存储器功能,包括DMA写操作)以及存储器308(用于存储与图形逻辑单元140的操作相关的数据,包括如本文中所讨论的来自SLM 306的SLM数据)。存储器308可以是任何类型的存储器,如本文中参考图1-图8所讨论的那些,包括例如高速缓存。此外,复用器310将存储器308耦合到逻辑单元302和306以及SLM 306。
在实施例中,保存图形硬件/逻辑单元140状态的顺序如下:
(a)在中断时,固定功能(fixed function)(例如,线程孵化器逻辑单元302)确保没有新线程孵化(spawn)到(例如,EU复合体304中的EU的)流水线中;
(b)固定功能(例如,线程孵化器逻辑单元302)请求线程停止执行;
(c)线程完成流水线中的任何未决的挂起周期(outstanding pending cycles),以及完成停止;
(d)当系统变为空闲时,线程继续进行系统例程;
(e)系统例程将线程(其中在一个实施例中所有工作在软件中处理)的硬件状态(如中间寄存器、流控制指针、栈、架构控制寄存器等)移动到存储器308(例如,其中这样的移动在一个实施例中是预先确定的)。
(f)当所有线程已完成数据移动时,系统例程将控制移动到固定功能(其也可访问如SLM 306的DMA引擎);
(g)该DMA现在将SLM 306数据移动到存储器308;
(h)当该DMA移动完成时,其余的状态(如流水线状态、步行器(walker)状态和处理障碍(barrier)的中间状态机)都保存到上下文中;以及
(i)硬件现在可以刷新(flush)并执行新的上下文。
相比之下,先前的解决方案涉及使用预先定义的硬件状态机来处理这样的数据移动。根据一些实施例,由于使用了软件方法,新的混合方法提高了灵活性并降低了风险。
图4示出了根据实施例的用于保存和恢复图形逻辑单元140的上下文的预先确定的存储器映射。如图所示,每个SLM分配至多64KB的空间。这之后是在相应EU上运行的每个线程的专用空间。此外,在实施例中,线程状态保存在8KB预分配空间(其被划分为GRF(通用寄存器文件)寄存器、ARF(架构寄存器文件)寄存器以及可选地一些保留空间)中。取决于实现方式和要保存的数据量,可以使用其它预分配空间。
图5示出了根据一些实施例的用于执行利用软件辅助上下文切换的中间线程抢占的方法500的流程图。本文中参考图1-图4和图6-图8所讨论的一个或多个组件(包括例如图形逻辑单元140)可以用于执行参考图5讨论的一个或多个操作。
参照图1-图5,在操作504处,一旦(例如,经由中断)检测到抢占请求(例如,中间线程或以其它方式,在GPU上执行的一个或多个线程的执行期间),则系统中所有线程的任何执行停止(例如,以指令级粒度)。在实施例中,抢占请求指示“其它线程或操作将抢占当前正在运行的线程的执行”。当前正在运行的线程和/或其它进行抢占的(pre-empting)线程或操作可以作为GPGPU执行。
在操作506处,确定流水线中的所有未决任务是否完成(例如,所有正在运行的线程已经以指令级粒度完成了它们的任务),以使系统的其余部分进入空闲状态。在操作508处,机制的硬件/软件组合被用来将上下文(包括线程和SLM数据)移动/复制到存储器(如参考图3所讨论的)。例如,上下文数据可以响应于一个或多个软件指令被复制到存储器308。在操作510处,新的工作负载/线程被允许执行(例如,对应于或以其它方式引起进行抢占的请求的生成),并且还提供用于将所保存的工作负载从先前它被停止的地方继续的机制(如参考图3所讨论的)。
与上述保存序列类似的序列可以用于恢复(restore)先前保存的上下文。更具体地说,图5A示出了根据一些实施例的用于恢复先前保存的上下文的方法550的流程图。本文中参考图1-图5和图6-图8所讨论的一个或多个组件(包括例如图形逻辑单元140)可以用于执行参考图5A讨论的一个或多个操作。在实施例中,参考图5A讨论的所有数据流是从存储器到硬件/逻辑单元140。
参照图1-图5A,在操作552处发起上下文切换。操作554确定所发起的上下文是否是新的。根据上下文是新的还是先前保存的,方法550以操作556或558-560来继续。如果上下文是新的,则操作556执行新上下文;否则,操作558调用相应的系统例程并发起用于先前保存的上下文的数据恢复序列。在操作560处,一旦恢复完成,则系统例程移动到下一个应用例程。例如,在所有状态信息被恢复之后,系统跳转到应用内核指针并且继续执行以完成工作负载。
图6示出了根据实施例的计算系统600的框图。计算系统600可以包括经由互连网络(或总线)604通信的一个或多个中央处理单元(CPU)602或处理器。处理器602可包括通用处理器、网络处理器(其对计算机网络603上传输的数据进行处理)或者其它类型的处理器(包括精简指令集计算机(RISC)处理器或复杂指令集计算机(CISC))。
此外,处理器602可以具有单核或多核设计。具有多核设计的处理器602可以将不同类型的处理器核心集成在同一个集成电路(IC)管芯上。此外,具有多核设计的处理器602可以实现为对称或非对称多处理器。在实施例中,处理器602中的一个或多个处理器可以与图1的处理器102相同或相似。例如,系统600的一个或多个组件可以包括参考图1-图5讨论的逻辑单元140。另外,结合图1-图5所讨论的操作可以由系统600的一个或多个组件来执行。
芯片组606还可以与互连网络604通信。芯片组606可以包括图形存储器控制中心(GMCH)608,其可以位于系统600的各个组件(如图6所示的组件)中。GMCH 608可以包括与存储器612(其可以与图1的存储器114相同或类似)通信的存储器控制器610。存储器612可以存储数据,其包括可由指CPU 602或计算系统600中包括的任何其它设备执行的令序列。在一个实施例中,存储器612可以包括诸如随机存取存储器(RAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、静态RAM(SRAM)或其它类型的存储设备的一个或多个易失性存储(或存储器)设备。非易失性存储器还可以用作硬盘。诸如多个CPU和/或多个系统存储器的额外的设备可以经由互连网络604通信。
GMCH 608还可以包括与显示设备616通信的图形接口614。在一个实施例中,图形接口614可以经由加速图形端口(AGP)或外围组件互连(PCI)(或PCI express(PCIe)接口)与显示设备616通信。在实施例中,显示器616(如平面显示器)可以通过例如信号转换器与图形接口614通信,该信号转换器将存储在存储设备(如视频存储器或系统存储器)中的图像的数字表示转换成由显示器616解释和显示的显示信号。由显示设备产生的显示信号在由显示器616解释并随后在显示器417上进行显示之前可以通过各种控制设备。
集线器接口618可以允许GMCH 608和输入/输出控制集线器(ICH)620进行通信。ICH 620可以提供到与计算系统600通信的I/O设备的接口。ICH 620可以通过外围桥接器(或控制器)624(诸如外围组件互连(PCI)桥接器、通用串行总线(USB)控制器或其它类型的外围桥接器或控制器)来与总线622通信。桥接器624可以提供CPU 602与外围设备之间的数据路径。可以使用其它类型的拓扑结构。另外,多个总线可以与ICH 620通信,例如,通过多个桥接器或控制器。另外,在各个实施例中,与ICH 620通信的其它外围设备可以包括:集成驱动电子设备(IDE)或小型计算机系统接口(SCSI)硬盘驱动器、USB端口、键盘、鼠标、并行端口、串行端口、软盘驱动器、数字输出支持(例如,数字视频接口(DVI))或其它设备。
总线622可以与音频设备626、一个或多个磁盘驱动器628、以及网络接口设备630(其与计算机网络603通信)通信。其它设备可以经由总线622通信。另外,在一些实施例中,各个组件(例如网络接口设备630)可以与GMCH 608通信。此外,处理器602和GMCH 608可以组合形成单个芯片。另外,在其它实施例中,图形加速器416可以包括在GMCH 608中。
另外,计算系统600可以包括易失性和/或非易失性存储器(或存储)。例如,非易失性存储器可以包括下列各项中的一个或多个:只读存储器(ROM)、可编程ROM(PROM)、可擦除PROM(EPROM)、电EPROM(EEPROM)、磁盘驱动器(例如,628)、软盘、压缩盘ROM(CD-ROM)、数字多功能盘(DVD)、闪存器、磁光盘、或者能够存储电子数据(例如包括指令)的其它类型的非易失性机器可读介质。
图7示出了根据实施例的布置成点对点(PtP)配置的计算系统700。具体而言,图7示出了由多个点对点接口互连的处理器、存储器和输入/输出设备系统。结合图1-图6所讨论的操作可以由系统700的一个或多个组件来执行。
如图7所示,系统700可以包括若干处理器,其中,为了清楚起见仅示出了两个处理器702和704。处理器702和704可以分别包括用于能够与存储器710和712进行通信的本地存储器控制器集线器(MCH)706和708。存储器710和/或712可以对各种数据(例如结合图6的存储器612讨论的那些数据)进行存储。
在实施例中,处理器702和704可以是结合图6讨论的处理器602中的一个。处理器702和704可以经由点对点(PtP)接口714分别使用PtP接口电路716和718来交换数据。另外,处理器702和704可以使用点对点接口电路726、728、730和732经由各自的PtP接口722和724分别与芯片组720交换数据。芯片组720还可以经由图形接口736与图形电路734交换数据(例如,使用PtP接口电路737)。
可以在处理器702和704内提供至少一个实施例。例如,系统700的一个或多个组件可以包括图1-图6的逻辑单元140(包括位于处理器702和704内的)。然而,其它实施例可以存在于其它电路、逻辑单元、或图7的系统700中的设备。另外,其它实施例可以分布在若干个电路、逻辑单元或图7中示出的设备中。
芯片组720可以使用PtP接口电路741与总线740通信。总线740可以与一个或多个设备(如总线桥接器742和I/O设备743)通信。经由总线744,总线桥接器742可以与诸如键盘/鼠标745、通信设备746(如调制解调器、网络接口设备或可以与计算机网络603通信的其它通信设备)、音频I/O设备747和/或数据存储设备748的其它设备通信。数据存储设备748可以对可由处理器702和/或704执行的代码749进行存储。
此外,本文中所讨论的场景、图像或帧(例如,其可由各个实施例中的图形逻辑单元处理)可由图像捕捉设备(如数字相机(其可嵌入诸如智能手机、平板电脑、膝上型计算机、独立照相机等的另一个设备中)或其捕捉的图像随后被转换为数字形式的模拟设备)捕捉。此外,本文中所讨论的场景、图像或帧可以通过艺术设计、游戏设计或任何种类的3D/2D(二维/三维)工业设计来生成。例如,场景可以指一组几何结构和相关纹理图,照明效果等。此外,在实施例中,图像捕捉设备可以能够捕捉多个帧。此外,在一些实施例中,在计算机上设计/生成场景中的一个或多个帧。此外,场景的一个或多个帧可以经由显示器(如参考图6和/或图7讨论的显示器,包括例如平板显示设备等)来呈现。
在一些实施例中,本文中讨论的组件中的一个或多个组件可以体现为片上系统(SOC)设备。图8根据实施例示出了SOC封装的框图。如图8所示,SOC 802包括一个或多个中央处理单元(CPU)核820、一个或多个图形处理器单元(GPU)核830、输入/输出(I/O)接口840和存储器控制器842。如本文中参考其它图所讨论的,SOC封装802的各个组件可以耦合到到互连或总线。此外,如本文中参考其它图所讨论的,SOC封装802可以包括更多或更少的组件。此外,SOC封装820的每个组件可以包括一个或多个其它组件(例如,如本文中参考其它图所讨论的)。在一个实施例中,在一个或多个集成电路(IC)管芯(例如,其封装到单个半导体器件中)上提供SOC封装802(及其组件)。
如图8所示,SOC封装802经由存储器控制器842耦合到存储器860(其可以与本文中参考其它附图讨论的存储器类似或相同)。在实施例中,存储器860(或其一部分)可以集成在SOC封装802上。
I/O接口840可以耦合到一个或多个I/O设备870(例如经由如本文中参考其它附图讨论的互连和/或总线)。I/O设备870可以包括下列各项中的一项或多项:键盘、鼠标、触摸板、显示器、图像/视频捕捉设备(如相机或摄像机/视频记录器)、触摸屏、扬声器等等。此外,在实施例中,SOC封装802可以包括/集成逻辑单元140。或者,可以在SOC封装802之外提供逻辑单元140(即,作为分立逻辑单元)。
以下实施例涉及另外的实施例。示例1包括一种装置,其包括:逻辑单元,所述逻辑单元至少部分地包括硬件逻辑单元,所述硬件逻辑单元用于响应于对在图形处理单元(GPU)上执行的一个或多个线程进行抢占的请求使所述一个或多个线程以指令级粒度停止,其中,响应于以所述指令级粒度完成所述一个或多个线程,所述一个或多个线程的上下文数据将被复制到存储器。示例2包括示例1的所述装置,其还包括:共享本地存储器(SLM),其用于在所述上下文数据被复制到所述存储器之前对所述上下文数据进行存储。示例3包括示例2的所述装置,其中,所述逻辑单元还将所述上下文数据从所述SLM复制到所述存储器。示例4包括示例3的所述装置,其中,用于复制所述上下文数据的所述逻辑单元包括直接存储器访问(DMA)逻辑单元。示例5包括示例1的所述装置,其中,响应于一个或多个软件指令,使所述一个或多个线程的所述上下文数据被复制到所述存储器。示例6包括示例1的所述装置,其中,所述逻辑单元用于响应于所述请求使在所述GPU上执行的所有线程以所述指令级粒度停止。示例7包括示例1的所述装置,其中,所述一个或多个线程或与所述进行抢占的请求相对应的线程将作为所述GPU上的图形处理单元(GPGPU)上的通用计算来执行。示例8包括示例1的所述装置,包括线程孵化器逻辑单元,其孵化所述一个或多个线程。示例9包括示例1的所述装置,其中,处理器包括所述逻辑单元。示例10包括示例1的所述装置,其中,下列各项中的一项或多项在单个集成电路管芯上:具有一个或多个处理器核心的处理器、所述逻辑单元或所述存储器。
示例11包括:包括一个或多个指令的计算机可读介质,所述指令当在处理器上执行时配置所述处理器执行一个或多个操作以响应于对在图形处理单元(GPU)上执行的一个或多个线程进行抢占的请求使得所述一个或多个线程以指令级粒度停止。其中,响应于以所述指令级粒度完成所述一个或多个线程,所述一个或多个线程的上下文数据将被复制到存储器。示例12包括示例11的所述计算机可读介质,还包括一个或多个指令,当在所述处理器上执行时,所述指令配置所述处理器执行一个或多个操作以使响应于一个或多个软件指令将所述一个或多个线程的所述上下文数据复制到所述存储器。示例13包括示例11的所述计算机可读介质,还包括一个或多个指令,当在所述处理器上执行时,所述指令配置所述处理器执行一个或多个操作以响应于所述请求使在所述GPU上执行的所有线程以所述指令级粒度停止。示例14包括示例11的所述计算机可读介质,其中,所述一个或多个线程或与所述进行抢占的请求相对应的线程将作为所述GPU上的图形处理单元(GPGPU)上的通用计算来执行。示例15包括示例11的所述计算机可读介质,还包括一个或多个指令,当在所述处理器上执行时,所述指令配置所述处理器执行一个或多个操作以引起所述一个或多个线程的孵化。
示例16包括一种方法,其包括:响应于对在图形处理单元(GPU)上执行的一个或多个线程进行抢占的请求,使得所述一个或多个线程以指令级粒度停止。其中,响应于以所述指令级粒度完成所述一个或多个线程,所述一个或多个线程的上下文数据被复制到存储器。示例17包括示例16的所述方法,还包括:响应于一个或多个软件指令将所述一个或多个线程的所述上下文数据复制到所述存储器。示例18包括示例16的所述方法,还包括:响应于所述请求使在所述GPU上执行的所有线程以所述指令级粒度停止。示例19包括示例16的所述方法,还包括:将所述一个或多个线程或与所述进行抢占的请求相对应的线程作为所述GPU上的图形处理单元(GPGPU)上的通用计算来执行。示例20包括示例16的所述方法,还包括:引起所述一个或多个线程的孵化。
示例21包括一种系统,其包括:处理器,其具有一个或多个处理器核心;存储器,其用于存储与场景的至少一个帧相对应的数据,所述数据要由所述一个或多个处理器核心中的至少一个处理器核心访问;显示设备,其用于呈现所述场景的所述至少一个帧;逻辑单元,所述逻辑单元至少部分地包括硬件逻辑单元,所述硬件逻辑单元用于响应于对在图形处理单元(GPU)上执行的一个或多个线程进行抢占的请求使所述一个或多个线程以指令级粒度停止,其中,响应于以所述指令级粒度完成所述一个或多个线程,所述一个或多个线程的上下文数据将被复制到所述存储器。示例22包括示例21的所述系统,其还包括:共享本地存储器(SLM),其用于在所述上下文数据被复制到所述存储器之前对所述上下文数据进行存储。示例23包括示例21的所述系统,其中,响应于一个或多个软件指令,所述一个或多个线程的所述上下文数据被复制到所述存储器。示例24包括示例21的所述系统,其中,所述逻辑单元用于响应于所述请求使在所述GPU上执行的所有线程以所述指令级粒度停止。示例25包括示例21的所述系统,其中,所述一个或多个线程或与所述进行抢占的请求相对应的线程将作为所述GPU上的图形处理单元(GPGPU)上的通用计算来执行。示例26包括示例21的所述系统,包括线程孵化器逻辑单元,其孵化所述一个或多个线程。示例27包括示例21的所述系统,其中,所述处理器包括所述逻辑单元。示例28包括示例21的所述系统,其中,所述下列各项中的一项或多项在单个集成电路管芯上:所述处理器、所述逻辑单元或所述存储器。
示例29包括一种装置,其包括用于执行任意前述示例中所述的方法的单元。
示例30包括机器可读存储器,其包括机器可读指令,所述机器可读指令当被执行时实现任意前述示例中所述的方法或实现任意前述示例中所述的装置。
在各个实施例中,本文中(例如,结合图1-图8)讨论的操作可以实现为硬件(例如,电路)、软件、固件或它们的组合,其可以提供为计算机程序产品,例如,包括其上存储有用于对计算机进行编程以执行本文所讨论的过程的指令(或软件程序)的有形(例如,非临时性)机器可读或计算机可读介质。机器可读存储介质可以包括诸如针对图1-图8所讨论的存储设备。
另外,这样的计算机可读介质可以作为计算机程序产品下载,其中,程序可以经由通信链路(例如,总线、调制解调器或网络连接)通过在载波或其它传播介质中提供的数据信号的方式从远程计算机(例如,服务器)传送到发出请求的计算机(例如,客户端)。
本说明中提及的“一个实施例”或“实施例”意指结合可以包括在至少一种实现中的实施例描述的特定特征、结构和/或特性。在本说明的各个地方出现短语“在一个实施例中”可能是或者可能不是全部指的是相同的实施例。
另外,在说明书和权利要求书中,可以使用术语“耦合”和“连接”以及它们的派生词。在一些实施例中,“连接”可以用于指示两个或更多元素彼此直接物理或电接触。“耦合”可以意指两个或更多元素直接物理或电接触。然而,“耦合”也可以意指两个或更多元素可以并不彼此直接物理接触,但仍可以协同操作或彼此交互。
因此虽然以特定于结构特征和/或方法动作的语言对实施例进行了描述,但应当理解的是:要求保护的发明主题可以并不受限于所描述的具体特征或动作。而是,公开具体的特征和动作作为实现要求保护的发明主题的示例形式。
- 还没有人留言评论。精彩留言会获得点赞!