用于线性广义LL识别和上下文感知解析的方法和系统与流程
本申请要求于2015年7月10日提交的美国申请No.14/796,782和于2014年7月11日提交的美国临时申请No.62/023771的优先权,其以引用方式并入全文。
技术领域
如本文所示和所述的本发明的实施例涉及根据形式文法的规则的形式语言中的符号串的解析。具体地,实施例提供了在不存在歧义的情况下具有O(n)性能的改进的通用LL(从左至右,最左侧推导)解析处理。
背景技术:
解析(parsing)(也称为语法分析)是对可以是字符串或类似格式的一组符号进行分析的处理,其中,“字符串(string)”是项目(在此情况下为符号)的序列,其中序列是有限的且符号是从被称为字母表的一组可能的符号中选择的。解析处理可应用于自然语言、计算机语言和包括DNA序列的类似系统。解析处理应用特定于被处理的语言的形式文法的一组规则。解析处理是计算机实现的处理,并且在计算机科学领域并且更具体地在计算语言学领域中所理解的意义上使用该术语。
在计算语言学中,解析处理还被理解为用于指代通过计算机处理器和程序对自然语言或计算机语言中的句子或其它单词串进行形式分析得到其组成部分,并得出显示每个组成部分与每另一个组成部分之间的语法关系的解析树。该解析树还可以包含关于被处理的句子或单词串的语义信息和其它相关信息。
在计算机科学中的一些应用中,解析处理用于计算机语言的分析,并且涉及对输入的代码进行语法分析得到其组成部分,以有助于起到将以一种计算机语言编写的代码转换为可执行形式(即,计算机处理器能够执行的计算机语言)的功能的编译器和/或解释器的后续功能。
技术实现要素:
一种计算机系统和一种文法分析的方法,用以生成用于运行时识别的代码,以产生在随后的解析期间给定语句要遵循的方向(direction)的列表或多个列表的图形表示。所述计算机系统实施所述方法以:解析文法以创建中间表示;构造表示文法的所有特征的用于分析的图形,所述特征包括递归、交替(alternation)、备选项的分组、和循环;处理所述图形中的每个决策点,用以生成所述中间表示;生成返回运行时解析决策中使用的方向列表的识别函数的代码;并且修补每个决策点标记(token)以引用或内联每个决策点的顶层识别代码。
附图说明
在附图的图中通过示例而非限制的方式示出了本发明的实施例,其中相同的附图标记指示类似的元件。应当注意,在本公开中对本发明的“一”或“一个”实施例的引用不一定是指相同的实施例,并且它们意味着至少一个。
图1是代码的图形表示的一个实施例的流程图。
图2是代码的图形表示的一个实施例的流程图。
图3A至图3D是根据图1的递归子图的推导的一个实施例的示图。
图4是用于代码生成的处理的流程图。
图5是决策点分析处理的一个实施例的流程图。
图6是决策点分析列表处理的一个实施例的流程图。
图7、图8和图9示出了运行时分析处理的最简单的版本(使用受限制的GOTO模型)。
图7是总体框架的流程图。
图8是添加到方向列表的处理的流程图。
图9是构造方向图的处理的流程图。
图10是解析系统的一个实施例的示图。
图11是编译器和链接器系统的一个实施例的示图。
图12是实施解析处理的计算机系统的一个实施例的示图。
具体实施方式
在下面的描述中,阐述了许多具体细节。然而,应当理解,本发明的实施例可在没有这些具体细节的情况下实践。在其它情况下,未详细示出公知的电路、结构和技术,以免模糊对本说明书的理解。然而,本领域中技术人员将理解,本发明可在没有这些具体细节的情况下实践。本领域普通技术人员利用所包括的描述将无需过多的实验就能够实现适当的功能。
将参照附图中所示示例性实施例来描述附图中的流程图中所描述的操作。然而,应当理解,流程图中所描述的操作可以由除了参照附图所讨论的本发明的实施例之外的实施例来执行,并且参照附图中的示图所讨论的实施例可以执行与参照附图的流程图所讨论的那些操作不同的操作。
可以使用在一个或多个电子装置(例如,终端站、网络元件等)上存储和执行的代码和数据来实现附图中所示的技术。这样的电子装置使用非暂时性机器可读或计算机可读介质(比如,非暂时性机器可读或计算机可读存储介质(例如,磁盘、光盘、随机存取存储器、只读存储器、闪速存储器和相变存储器)和暂时性计算机可读传输介质(例如,电、光、声或其它形式的传播信号(诸如载波、红外信号、数字信号)))来对代码和数据进行存储和通信(内部通信和/或经由网络与其它电子装置的通信)。此外,这种电子装置通常包括耦接至一个或多个其它部件的一个或多个处理器的组,比如,一个或多个存储装置、用户输入/输出装置(例如,键盘、触摸屏和/或显示器)和网络连接。本文中所使用的“组”是指任何正整数个项目。所述一组处理器与其它部件的耦接通常通过一个或多个总线和网桥(也称为总线控制器)来实现。存储装置表示一个或多个非暂时性机器可读或计算机可读存储介质以及非暂时性机器可读或计算机可读通信介质。因此,给定的电子装置的存储装置通常存储用于在该电子装置的一个或多个处理器的组上执行的代码和/或数据。当然,本发明的实施例的一个或多个部分可以使用软件、固件和/或硬件的不同组合来实现。
如本文所使用的网络元件(例如,路由器、交换机、网桥等)是包括硬件和软件的一件网络化装备,其通信地将网络上的其它装备(例如,其它网络元件、终端站等)相互连接。一些网络元件是为多个网络功能(例如,路由、桥接、交换、二层聚合、会话边界控制、多点广播和/或订户管理)提供支持和/或为多个应用服务(例如,数据、语音和视频)提供支持的“多服务网络元件”。
综述
现有技术中的通用解析方法具有O(n3)性能。本文中的实施例描述了一种用于在没有歧义(即,对于给定的“字符”序列存在多个备选解释,在自然语言中这些被称为“双关语”)的情况下具有O(n)性能的解析处理的方法及系统。根据本文所描述的原理和技术创建的解析器通过以下步骤运行:首先,执行识别阶段,其生成用于对决策点进行导航的方向序列;随后或与识别阶段穿插地执行解析阶段,该阶段遵循所述方向,同时执行可能由实施解析处理的编译器、DNA序列分析器或类似部件为解决可以由有限状态自动机处理的问题所使用的所有动作。
为了生成实施该处理的识别器和解析器,以两种备选形式表示文法:具有将表示待匹配的标记类型的顶点连接的有向边的图形、以及抽象语法树(AST)。该图形用于识别决策点(具有多个输出边的顶点),并被处理以生成识别器代码。AST表示用于生成包括对识别器例程的调用的解析代码。通常,根据用产生式(production)来描述的文法来生成AST表示,接下来,根据该AST形式逐产生式地导出用于构造图形的元素,然后构造该图形。在图形构造期间,AST形式变得复杂,并且一些产生式被复制以确保决策被唯一命名;这些产生式被添加到原始的AST;复杂的AST用于生成解析代码。
介绍性内容
形式语言通过由“规则”或“产生式”构成的文法描述,该文法定义了构成语言中的句子的“字符”的全部合法的序列。上下文无关语言是可以由上下文无关文法(CFG)描述的一种形式语言,其中无上下文无关文法G被定义为
G=(N,T,P,S)
其中,N是非终结符号的集合,T是语言允许的终结符号(字符)的集合,P是以下形式的产生式(或重写规则)的集合:
n-><终结符和非终结符的序列>,
n是非终结符;
并且S是开始符号(另一个非终结符)。
对于语言处理,通过备选项运算符“|”扩充CFG规范,使得对于每个n存在唯一的产生式。这被称为巴科斯范式(Backus-Naur Form,BNF),其经常被扩展(EBNF)以包括短语分组(grouping of phrases)(短语)、以及重复--A*表示A的0次或更多次出现,而A+表示一次或多次出现,并且A?表示0次或1次出现。如本文所使用的非终结符以小写字母开始,并且终结符以大写字母开始;产生式被写作:
a:<符号序列>;
事实上,更普遍的形式语言以扩充的CFG来定义,用以支持以通用编程语言(包括语义谓词)所描述的“动作”。语义谓词用于查询上下文信息,并在谓词求值为false时使备选项无效。
图形表示
扩充的CFG可以以具有连接顶点(“节点”)的有向边的图形的形式来表示,其中,每个顶点被单个终结符、动作或语义谓词所占据。由于CFG支持递归,因此还需要添加两个附加的节点类型,这些节点类型是支持保存和恢复返回上下文信息所需要的;逻辑上,这些节点类型压入(push)和弹出(pop)来自堆栈的值,其中POP节点基于从堆栈中取回的值确定哪个节点跟随。要理解这一点,考虑递归产生式:
a:A a B
|B a C
|D;
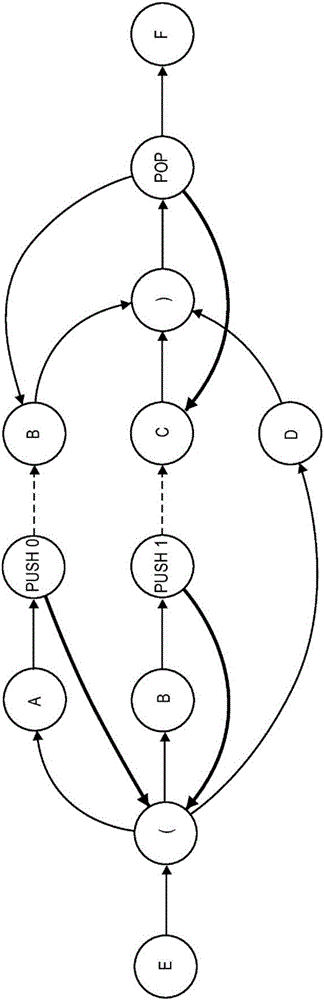
在第一备选项中,在识别A并且递归调用a之后返回路径必须涉及识别B;而在第二备选项中识别B并且递归调用a之后返回路径必须涉及识别C。在图形形式中,在递归调用(回到a的第一次调用的循环)之前,必须插入PUSH_CONTEXT节点;在产生式的末尾(分号出现的地方)处插入POP_CONTEXT节点。为了处理方便,还支持表示可能的决策点(与POP_CONTEXT节点一样)的“(”和“)”节点。
如果添加了如下形式的开始产生式:
s:E a F;
则可以将所得到的文法表示为图1所示的图形。
在图1中,向前箭头是黑色的,回环以粗体显示。虚线箭头表示在构造之后可能存在或可能不存在、但在代码生成期间不被遵循的连接。图1中有一个决策点:“(”节点。注意,“(”节点和“)”节点在文法中是隐含的。与“(”节点一样,POP节点有多个可能的跟随节点,但是方向的选择由堆栈上的值确定,而不是根据输入字符的匹配而确定。关于从“(”节点处采取哪条路径的决策由从输入流取得的下一个标记(“字符”)确定;这被称为LA(1)决策,因为它仅需要一个预读(lookahead,LA)标记。
一些决策(比如,图2中所示的那些)可能需要多于一个的预读标记。
在图2中有两个决策节点:BLOCK节点和EOB节点。呈现这些节点是为了指示结构而非待匹配的值,因此,BLOCK决策在序列ABC和ABD之间,而EOB决策在ABC、ABD和ABE之间。两者都需要三个预读标记(第三个标记将C与D和E区分开)以确定采用从决策引出的哪个路径。
根据待匹配的标记的序列,在可以区分合适路径之前,复杂决策可包括多个决策点。
文法图处理期间的决策分析
分析决策点的基本方法是:从决策点构建备选路径列表,并比较沿所有路径的下一个标记类型。单例(Singleton)标记类型表示“缺失项(dropout)”:如果匹配这种标记类型,则当该类型在运行时匹配时,从其中找到该标记类型的路径将是有效的,并且可以返回相应的路径索引,并且可以从列表中删除相应的路径。如果其余路径都表示相同的标记类型,则生成代码以匹配该标记类型,并将其余路径推进到下一个标记。否则,按标记类型拆分列表,并针对每个生成的列表继续该处理。对于每个新列表,生成函数并生成用以调用每个新函数的代码,并终止对于先前路径列表的处理;新函数的主体将在处理在决策点处生成的列表时生成。当遇到二次决策点或POP节点时出现困难;这些情况将在下文中更详细地描述。通过使用在构造新列表之后所检查的列表处理表来避免重复的列表处理;如果在表中找到了等同的列表,则对新创建的列表的引用被替换为对在表中找到的列表的引用,并且新列表被丢弃而不进行进一步处理。这防止了分析处理进入无限循环。
在图2中,第一个决策(图中左侧处的“(”)的分析处理如下。首先,构造指向图中的各个A的备选路径的列表。生成匹配A代码,并且路径被推进到各个B节点。两者均匹配,因此产生匹配B代码。此外,路径被推进,然后,路径列表经过第二个决策“(”变复杂,以拥有C路径、C路径和D路径。D是缺失项;为此生成代码,并且也生成匹配C代码。再次,路径被推进到虚线的E节点和D节点。为这些缺失项生成代码,留下空路径列表,且分析终止。
运行时的决策分析
在运行时,识别(预读)阶段或者可以在解析之前运行到完成;或者可以穿插运行,其中,在解析期间遇到所选决策点时在所选决策点处调用识别代码。这些运行方式之间的区别在于,运行至完成需要仅针对遇到的第一决策点的识别代码,在解析输入被用尽之前,没有解析方向被返回,而穿插识别在每当各备选路径减少到单个路径时就进行返回。这个讨论将假定后一种方法;但在任一情况下,解析方向由对从决策点引出的路径进行选择的索引的列表(或多列表或图形,将在下文中进一步讨论)组成。作为示例,列表{3,2,1}指导解析在第一决策点处采用备选项3,在第二决策点处采用备选项2,并且在第三决策点处采用备选项1。第四决策将需要另一个识别调用。
特殊标记类型
在本文中描述的一个示例实现方案中,在文法中引用的大多数标记类型表示要在运行时匹配的标记,但是某些表示决策或所需的处理动作,并且均存在于AST和图形表示中。
它们包括:
BLOCK备选项分组的开始(当存在备选项时所使用的决策点)
EOB分组的结束(用于循环的决策节点)。
CLOSURE用于(...)*的决策点,其在图中被表示为((...)+)?。
POP_CONTEXT如上所述。
PUSH_CONTEXT-如上所述。
SEMANTIC_PREDICATE谓词决策点。这在图形表示中是决策节点,但在AST中不是,在AST中它表示动作(运行时执行的代码)。
SYNTACTIC_PREDICATE开始强制预读;,跟随SYNTACTIC_PREDICATE之后的备选项只有在该谓词在整体上匹配的情况下才有效。
END_SYNTACTIC_PREDICATE结束预读。
对于BLOCK、EOB和CLOSURE标记,重要的是在图形表示中使用在AST表示中所使用的相同的标记,使得在一种表示中的编辑可以在另一种表示中读取。这些标记嵌入在AST或图形表示或两者中的“载体(carrier)”节点中。
AST到图形的转换
所采用的基本方法是针对开始产生式遍历AST,从而生成标记序列。然后对这些标记进行处理以构建文法图:除了需要特殊处理的递归产生式之外,将非终结符标记内联扩展。扩展由以下组成:针对引用的产生式遍历AST(第一次遇到),或(后续遇到)复制所引用的AST并运行该复本;这些遍历步骤生成了按序处理的标记序列,还在遇到非终结符时扩展这些非终结符。复制时,复制的产生式将被重命名,非终结符引用也是如此。递归产生式是内联扩展的例外情况;其被动态地转换为循环。
处理递归
为了追踪递归,在图形构造期间保持追踪规则嵌套的非终结符名称的堆栈;在添加另一级嵌套之前,对照栈的内容检查非终结符;如果存在,则将PUSH_CONTEXT节点添加到图形和用于递归产生式的上下文值的数组中。该节点包含被设置为其到数组的偏移量的上下文索引值。当递归产生式的扩展完成时,该数组用于创建从PUSH_CONTEXT节点到图形中的该产生式的起点的回环;将POP_CONTEXT节点附加到图形上,并环回至图形中的PUSH_CONTEXT节点之后的节点。这在图3A至图3D中示出,其遵循根据图1的递归子图的推导。
在遍历AST以根据第0039-0041段的“a”文法生成图3A至图3D的过程中,首先,将初始“(”添加到图形,然后添加A节点,在此之后,遇到递归引用。此时,创建数组来保存指向PUSH_CONTEXT节点的指针,将具有索引0的PUSH_CONTEXT节点添加到图形中,并且使得数组的第0个条目指向该PUSH_CONTEXT节点;由此生成图3A。然后,将B附加到该路径,并且继续对下一个备选项进行处理。添加第二个B(第0040段),并且遇到对a的第二个递归调用。添加PUSH_CONTEXT1节点,并更新数组以使得第1个条目指向该节点。图3B示出了中间图形。然后,添加C以完成该路径。然后,构造进行到第三路径,并且添加D。然后,将决策中的各路径利用“)”进行结合以到达产生式的终端。由于存在为此产生式而构建的数组,因此添加了POP_CONTEXT节点;这在图3C中示出了。然后,该数组用于生成图3D中所示的回环:首先,构造从PUSH_CONTEXT节点到最初决策节点的回环,然后增加数组条目,并添加来自POP_CONTEXT节点的回环以完成图形。
决策处理
处理图中的每个决策节点以生成识别代码;可以在图形构造期间或通过图形的系统遍历来收集决策节点。处理由备选项列表的建立和遍历组成,其中每个步骤涉及将列表中的各个备选项的值相互比较;如果所有节点都具有匹配的标记类型,则为该标记类型生成匹配代码(或中间表示),并将每个备选项推进到下一个节点。当备选项到达与其它备选项均不匹配的标记类型时,为该备选项生成终止代码,并对其余备选项继续进行列表处理。包含谓词、二次决策和PUSH_CONTEXT或POP_CONTEXT的节点强制执行特殊处理;当列表在删除单例类型后包含多个标记类型时,列表将被拆分为每种标记类型的列表,并且每个列表被单独地处理。
处理歧义
当来自决策点的各个备选路径在决策处理期间合并(共享公共节点)时,出现歧义。具体地,在这种情况下,这两个路径被描述为句法上有歧义;也就是说,存在可以以两种不同的方式解释的标记序列。广义解析涉及向前推进所有备选项。另一种方法,即,解析表达文法(PEG)方法,任意选择一个备选项并丢弃其它备选项。PEG类型歧义消解对形式语言来说是有用的;形式语言往往具有有限的句法歧义,并且没有语义歧义。
使用PEG类型的歧义消解,总是只有一个有效的解析,并且该解析可以由方向列表进行指导。对于广义解析,识别阶段生成多个有向图形而非列表,表示多个列表的多个图形,其中的每一个可以用于指导解析。
对于广义解析,存在多个有效的解析,因此方向列表被替换为以紧凑形式表示所有有效方向列表的有向图形。
代码生成模型-Java或其它缺乏无限制的GOTO的语言
当创建每个列表/图形时,为该列表/图形创建两个函数:主函数将保存用以进行标记处理的代码,而辅函数当退出主函数时被调用。退出函数构建备选项索引的列表/图形。列表中的每个备选项都由包含决策索引和当前图形节点的数据结构表示。当备选项的表示被添加到列表(从先前列表复制或从决策节点处的备选项重新构造)时,生成用以返回索引值的代码;如果该代码用于新创建的表示,则该代码包括将其备选项索引添加到索引列表。随着决策处理的进行,用于标记匹配的代码被添加到列表的主函数,以及用于特殊处理的代码(语义谓词、当列表被拆分时的“switch”语句、用于处理语义谓词的if...else...then语句、用于PUSH_CONTEXT的push语句和后面跟着切换(switch)语句的用于处理POP_CONTEXT的pop语句)也是如此。对于每个递归产生式,都有一个命名的堆栈;压入和弹出是对它们所出现的上下文的适当的堆栈进行的。
循环结构生成递归函数调用;为了支持这种递归,必须将当前节点的集合(以及当前节点在列表中的布置)相同的所有列表视为等同物,并将它们映射至生成的代码中的单个函数。这还有助于通过避免具有相同主体的多个函数来最小化所生成的代码。当创建路径列表时,对照列表处理表来检查路径列表,如果在表中找到一个路径列表,则替代对先前列表的引用,如果在表中没有找到等同物,则向表中添加新的条目。
代码生成模型-具有无限制的GOTO的语言
上述代码生成模型的不幸的特征是它可以导致非常深的函数调用堆栈。然而,在每个生成的函数中,只需要和定义一个局部变量“index”,因此,主函数的调用可以用GOTO替换。这遗留了退出函数的返回调用问题。这些可以通过将返回函数地址“发布”到刚好在GOTO调用之前的主函数中的返回函数地址列表中来得到处理。可以如下地处理该列表(C/C++代码):
while(offset<listSize){
index=(*list[offset++](index);
}
其中,从列表中的最后一个条目向下至第一个条目添加列表值,并由“offset”索引,然后向上处理。这避免了任何堆栈深度问题,并且可以相当快。
代码生成处理
图4是用于代码生成的处理的流程图。该处理通过解析输入语言的文法来创建每个文法产生式的AST或类似的中间形式以表示输入语言(块401)而开始。
然后,根据产生式AST,该处理构造用于进一步分析的图形(块403)。通过遍历文法构造图形,从开始产生式开始,当在文法中遇到非终结符时扩展非终结符(产生式引用);在遇到终结符时将终结符添加到图形中;通过插入展开成各个路径(每个备选项对应一个路径)的BLOCK顶点来构造各个块(block)(备选项的分组),这些路径在插入的EOB顶点处合并。通过在EOB节点和对应的BLOCK节点之间添加环回边来处理循环,并且如前所述的那样处理递归产生式。一旦完成了整个图形,则识别器生成处理开始遍历图形以识别决策点。在遍历期间遇到每个决策点时,其被用作决策处理的起点。检查是否存在要处理的其余决策点(块405),如果没有要处理的其余的决策点,则该处理生成解析代码(块413),并将解析代码存储到存储装置(块417)。在一些实施例中,所生成的代码随后可以被合并到可以由机器或人使用的可执行代码或类似代码中(块415)。
如果所有决策点尚未被处理,则该处理取回下一决策点(块407)。处理该决策点以生成中间表示(IR)或代码(块409)。修补决策点标记以引用或内联决策的代码(块411);这使得根据整个文法表示生成的解析代码引用识别函数。通过检查是否仍然还有决策点要被处理来继续遍历(块405),如果是,则继续处理下一个决策点,直到所有决策点都已被处理为止。
图5是决策点分析处理的一个实施例的流程图。该处理通过初始化方法的IR或内联代码而开始(块501)。构建备选项的列表,然后生成备选项的代码,这些备选项以与开始其它备选项的符号或符号集合不同的符号或符号集合开始(块503)。然后,将所生成的列表添加到工作队列(块505)。然后,工作队列开始处理队列中的每个列表,直到所有列表都用尽为止,此时决策点分析结束(块509)。检查是否仍然有列表要被处理(块507),并且当仍然有列表要被处理时,选择并处理下一列表(块511),并且可以在处理期间生成其它列表。下面进一步描述每个列表的处理。
图6是决策点分析列表处理的一个实施例的流程图。列表处理以从工作队列取回列表和比较每个备选项的下一个标记类型而开始(块601)。然后,推进PUSH_CONTEXT节点,并且将索引值添加到本地堆栈(块603)。然后,检查列表是否包括POP_CONTEXT节点(块605)。如果包括POP_CONTEXT节点,则复制该列表,并且在处理完成之前执行POP_CONTEXT处理(块607)。
PUSH_CONTEXT和POP_CONTEXT节点表示递归产生式。递归产生式在文法图形中变成双循环结构,如图3A至图3D所示。第二循环具有与第一循环相同的迭代次数;此外,当存在多个备选项(多个递归引用)时,第二循环备选项的选择取决于第一循环备选项;因此,PUSH_CONTEXT注释了在第一个循环中采用了哪个备选项,且POP_CONTEXT取回索引值并为第二个循环选择备选项。存在两种一个或另一个循环消失的特殊情况:左递归和尾递归。左递归实例不匹配从产生式的起点到PUSH_CONTEXT节点的终结符;在这些情况下,在处理相应的POP_CONTEXT节点时从堆栈弹出索引值是没有意义的,因为没有办法确定应该有多少个索引值已压入到了堆栈。相反,POP_CONTEXT节点被视为这种备选项的简单环回。类似地,对于尾递归,在来自POP_CONTEXT节点的回环中没有要匹配的符号(堆栈上的任何索引值都是不相关的),并且不需要为PUSH_CONTEXT或POP_CONTEXT实例生成代码。
如果列表不包括POP_CONTEXT节点,则执行对缺失项(dropout)(识别单个路径并且因此在匹配时终止识别分析的标记类型或标记类型集合)的处理(块609)。然后检查列表是否具有多个标记类型和/或决策点(块611)。如果存在多个标记类型和/或决策点,则该处理可以使决策精化(elaborate)为各路径(例如,构建新的列表)(块613),然后可以处理决策点,并且如果需要的话则拆分列表,并且在完成之前将生成的列表添加到工作队列(块625)。在决策点处,路径列表被压缩以去除空路径,并且对照路径列表的表(列表处理表)和存储的上下文数据进行检查。如果表中包含给定路径列表的条目,则列表的处理结束,并且用对表的条目的引用来替换对列表的引用。如果不包含,则将引用该列表的条目添加到表中。这避免了在处理环回决策时的无限递归。在没有多个标记类型或决策点的情况下,该处理检查SEMPRED(块615),其表示测试上下文信息以允许或不允许所跟随的备选项的语义谓词。语义谓词仅仅是布尔测试,因此列表被分成“if true”列表和“else”列表,并且生成代码,并且生成以下形式的代码:“if(SEMPRED condition)if true();else if_false();”(块617)。“if true”列表包含所有当前备选项,包括由语义谓词选通的备选项;“if false”列表省略谓词备选项。如果没有SEMPRED,则检查列表中的所有标记类型是否匹配(块619)。如果标记不匹配,则将列表拆分,并且如上面所讨论的那样将所产生的列表添加到工作队列(块625)。如果列表中的所有路径都引用相同的标记类型,则为该标记类型生成匹配代码(块621)。在此完成之后,处理继续到下一个节点进行处理(块623)。如果不是,则将该列表按照标记类型拆分成多个列表,其中每个列表被添加到工作队列,为匹配的标记类型生成用于调用适当的列表函数的转换代码,并且列表处理终止。
图7至图9示出了运行时识别处理的最简单版本(使用受限制的GOTO模型)。图7提供了总体框架,而图8示出了添加到方向列表的处理,并且图9示出了构造方向图的处理。图8和图10示出了示例代码和运行时决策。
关于图7,识别处理理论上以对识别函数的调用而开始(块701)。在该函数内,匹配标记(块703),并且在到达决策点或返回调用之前将输入流推进到下一个标记。检查输入流是否已经用尽(块705),如果没有,则检查是否已经找到决策点(块709)。如果用尽了或返回调用到达了,则调用出口以结束分析(块707)。决策采取if...else..then或switch语句的形式以选择要调用的函数和返回索引值(块711)。如果标记类型在决策点无法匹配或无效,则返回错误代码或抛出异常。返回调用开始图9和图11中所述的退出处理。
运行时决策反映由分析处理所生成的代码。可以遇到的主要的运行时决策包括:1)缺失切换(dropout switch);2)语义谓词(SEMPRED)if(..)条件句;3)POP_CONTEXT循环;4)拆分列表切换;和5)函数调用(反映列表合并/精化)。
以下示出了具有缺失切换的函数的示例Java代码。
代码对A进行匹配,推进输入流,对B进行匹配,推进输入,并且随后转到缺失切换。如果随后C、D或E匹配,则用适当的索引值调用endloop0函数以开始退出处理。如果都不匹配,则返回-1(错误代码)。
下面的示例代码示出了典型的语义谓词(baz()返回true或false)。
图8是示出当使用PEG类型(或其它)歧义消解时的退出处理的流程图。拆解来自图7的调用嵌套以构造方向列表并管理递归堆栈。退出处理的第一步是调用退出函数(块801)。在上面的示例代码中,退出函数是具有索引值的endloop0_l();索引值反映分析路径列表中的位置,并用于选择要执行的动作(块803)。检查是否要将该动作附加到方向(块805)。如果是,则该处理通过向方向列表添加值来继续(块807),在返回用于进一步处理的新的索引值(如果需要)之前管理递归堆栈等(块809)。当已经处理了所有调用时(块811),该处理完成并结束退出调用。
下面的代码提供了简单的Java退出函数的形式的示例,该函数与上面提到的匹配函数相对应。
查看以前的代码,第0个备选项以C和对索引为0的endloop0_l的调用而结束。这导致了indexTrack.add(0)调用;该函数表示二次决策的制定,因此将“0”方向索引插入到方向列表中,并且索引值恢复至来自制定前列表的索引。D/1情况与此类似,而E情况表示来自先前决策的保持路径(holdover path)。因此,第3种情况仅影响返回的索引值。
下面呈现的代码提供了识别器的完整的Java示例及生成该识别器的文法(单个产生式)的示例。
文法
生成的识别器代码
此特定示例生成了递归识别器,并且具有一些关注点。顶层函数recursionGenTestO()表示由首个“(”开始的决策。endrecursionGenTestO()函数为该决策构建索引列表条目,并且recursionGenTestO_l()表示两个(BCD)+循环和它们后面的E或F(注意,endrecursionGenTestO_l()对索引列表的贡献)。该函数的主体匹配BCD,然后匹配E或F,并绕回调用堆栈或进行递归调用。最终结果是对recursionGenTestO()的调用构建了{0|1,(0)+}形式的索引列表。
相应的解析函数
解析代码对A进行匹配,随后,在到达决策切换(decision switch)之前评估方向列表。第一种情况在到达循环决策点之前匹配B、C和D,并且再次检查决策列表。如果列表为空,则内联的识别代码执行;E结束该循环,而B(set0的内容)导致继续循环。第二种情况类似,只是用F替换了E。
图9是示出广义退出处理的流程图的一个实施例的流程图,涉及方向图而不是图8的方向列表的构造。这两个处理非常类似,只是本处理通过返回列表进行循环以构造新的返回列表,而非处理单值返回。该处理以调用具有索引或节点列表的退出函数而开始(块901)。检查列表是否为空(块903),如果是,则在最终完成检查之后该处理结束(块915)。如果列表中仍存在项目,则该处理获得下一个列表条目,设置节点和索引(块907)。基于索引选择动作(块905)。如果该动作要被附加到方向中,则该处理添加方向列表索引节点条目,链接至索引处的当前节点(如果是第一节点的话就创建),并且设置节点值(块911)。将索引或节点添加至返回列表(块913)。再次检查列表以确定其是否为空(块903),如果不是,则该处理继续下一个列表条目,否则,完成时处理结束(块915)。
图10是实施解析处理的计算机系统的一个实施例的示图。计算机系统可包括用以执行实施本文中所述解析处理的解析器生成器(parser generator)1003的处理器1001或处理器组。在另一个实施例中,解析器生成器1003和相关联的处理可以以分布式方式跨越彼此相互通信的多个计算机系统而被执行。为了清楚起见,下文中描述了在单个计算机系统中执行的实施例。然而,本领域技术人员应当理解,本文所描述的原理和结构与具有其它配置(比如,分布式实现)的其它实施例一致。
在一个实施例中,解析器生成器1003包括用于将输入文法处理为AST的文法处理器1005前端、线性广义LL(LGLL;LL表示“左倾斜”解析树,并且是自上而下解析的简写符号)分析引擎1007和代码生成器1009,以创建识别器和解析器代码,它们如上所述地划分解析输入文法和生成代码的职责。文法解析器1005将源代码1011作为输出,并生成如上所述的中间表示(AST)1015。LGLL分析引擎1007将AST作为输入,并且如上文所述地生成图形表示1017。随后它如图4至图6所述的那样处理图形,构建并使用列表处理表1025以避免重复的列表分析。代码生成器1009使用上述函数来处理AST 1015和图形表示1017,以构造生成的解析器1019(其是要被集成至目标应用程序中的源程序)。
文法1011、AST 1015、图形表示1017、列表处理表1025和生成的解析器1019可以存储在计算机系统的工作存储器1021中,并且可以由解析器生成器1003通过总线1013或类似的互连来访问。处理器1001可以通过总线1013、芯片级或系统区域网络或类似的通信系统进行通信,工作存储器1021存储源代码1015、中间表示1015、图形表示1017和生成的解析器1019的。工作存储器1021可以是任何类型的存储装置,比如,固态随机存取存储器。除了存储编译的代码之外,工作存储器1021还可以存储上述数据结构中的任何数据结构,工作存储器1021和永久存储装置(未示出)负责存储编译器和解析器及它们的子部件的可执行代码。
工作存储器1021可以通过总线1013与处理器1001通信。然而,本领域技术人员应当理解,总线1013不严格指示只有总线分离各处理器1001,并且总线113可以包括实现处理器1001和编译器解析器生成器(compiler parser generator)1003之间的通信的中间硬件、固件和软件部件。本领域技术人员应当理解,计算机系统是以示例而非限制的方式提供,并且为了清楚起见,已经省略了计算机系统的公知的结构和部件。
在一个实施例中,解析器生成器和解析器部件实现了参照图4至图9所描述的功能,以生成要在生成可执行代码或类似输出时使用的代码的中间表示。解析器可以被实现为前端编译器的一部分,分布在编译器的多个部件上,或者可以与编译器分开实现。在其它实施例中,软件编译处理中不使用解析器,但在其它类型的代码处理(比如,DNA序列处理或类似的自然发生的或人工创建的数据序列)中使用。本领域技术人员应当理解,本文中参照软件编译描述的处理和结构可适用于或适合于处理用于其它环境的其它代码。
图11是解析过程的另一计算机系统实施例的示图。包括处理器1101的计算机系统执行包括编译器1105和链接器1107的解析器生成器1103。编译器可以包括如上所述的解析器,或者可以对解析器的输出进行操作,并且与链接器一起工作以生成可执行代码。编译器1105与编译器分离,并且可以作为并行处理而执行,特别是对于大程序。编译器1105读入LGLL解析器/分析器(源代码)和用户源代码,并生成目标代码。
随后,链接器1107负责通过操作目标代码1115和库1117来生成具有完整的LGLL解析器1119的可执行代码1119。链接器1107将由编译器生成的目标代码1115链接在一起以创建可以在目标平台上运行的可执行代码1119。链接器1107将单个的目标代码1115与库代码1117和其它目标代码类似代码进行结合以实现平台特定操作和源代码的执行。
图12示出了计算机系统的示例性形式的机器的图示,其中可以执行用于使机器执行本文所讨论的方法中的任何一种或多种的一组指令。在替代实施例中,机器可以连接(例如,联网)到局域网(LAN)、内联网、外联网或互连网中的其它机器。机器可以以客户端-服务器网络环境中的服务器或客户机的身份进行操作,或作为在点对点(或分布式)网络环境中的对等机进行操作。机器可以是个人计算机(PC)、平板PC、机顶盒(STB)、个人数字助理(PDA)、蜂窝电话、web设备、服务器、网络路由器、交换机或网桥,或能够执行指定要由该机器采取的动作的一组指令(序列或其它)的任何机器。此外,尽管仅示出了一个机器,但是术语“机器”也将被认为包括单独地或联合地执行用以执行本文所讨论的方法中的任何一种或多种的一组(或多组)指令的机器(例如,计算机)的任意组合。
示例性计算机系统包括经由总线彼此通信的处理装置1202、主存储器1204(例如,只读存储器(ROM)、闪速存储器,诸如同步DRAM(SDRAM)或Rambus DRAM(RDRAM)等的动态随机存取存储器(DRAM))、静态存储器1206(例如,闪速存储器、静态随机存取存储器(SRAM)等)和辅助存储器1218(例如,数据存储装置)。
处理装置1202表示一个或多个通用处理装置(比如,微处理器、中央处理单元等)。更具体地,处理装置可以是复杂指令系统计算(CISC)微处理器、精简指令系统计算(RISC)微处理器、超长指令字(VLIW)微处理器、实现其它指令系统的处理器或实现指令系统的组合的处理器。处理装置902还可以是一个或多个专用处理装置(比如,专用集成电路(ASIC)、现场可编程门阵列(FPGA)、数字信号处理器(DSP)、网络处理器等)。处理装置902配置为执行用于执行本文中所述操作和步骤的编译器926和/或解析器。
计算机系统900还可以包括网络接口装置908。计算机系统还可以包括视频显示单元1210(例如,液晶显示器(LCD)或阴极射线管(CRT))、字母数字输入装置1212(例如,键盘)、光标控制装置1214(例如,鼠标)和信号生成装置916(例如,扬声器)。
辅助存储器1218可以包括其上存储有体现了本文所述方法或功能中的任何一种或多种(例如,解析器生成器1226)的一组或多组指令(例如,解析器和/或编译器1226)的机器可读存储介质1228(或更具体地,非暂时性计算机可读存储介质)。解析器生成器1226(即,实现本文所述的方法)还可以在由计算机系统1200对其进行执行期间完全或至少部分地驻留在主存储器1204和/或处理装置1202内;主存储器1204和处理装置也构成机器可读存储介质。编译器1228还可以经由网络接口装置1208通过网络被发送或接收。
机器可读存储介质1228(其可以是非暂时性计算机可读存储介质)也可以用于持续地存储解析器生成器1226的模块。虽然在示例性实施例中非暂时性计算机可读存储介质被示出为是单个介质,但是术语“非暂时性计算机可读存储介质”应该被认为包括存储一组或多组指令的单个介质或多个介质(例如,集中式或分布式数据库和/或相关联的高速缓存和服务器)。术语“非暂时性计算机可读存储介质”还将被认为包括能够存储或编码用于使机器执行本发明的方法中的任何一种或多种的由机器执行的指令组的任何介质。因此,术语“非暂时性计算机可读存储介质”应被理解为包括但不限于固态存储器以及光学和磁性介质。
计算机系统1200还可以包括用于实现上述编译处理的功能的解析器生成器1226。本文所描述的模块、部件和其他特征可以实现为离散硬件部件或集成在诸如ASICS、FPGA、DSP或类似装置的硬件部件的功能中。另外,该模块可以实现为硬件装置内的固件或功能电路。此外,可以以硬件装置和软件部件的任意组合来实现该模块。
以计算机存储器内的算法和对数据位的操作的符号表示的形式来呈现了接下来的详细描述的一些部分。这些算法式描述和表示是由数据处理领域的技术人员使用的用来将他们的工作的内容最有效地传达给本领域其他技术人员的手段。算法在本文中且通常被设想为产生期望结果的自洽的步骤序列。这些步骤是需要物理量的物理操纵的那些步骤。通常,尽管不是必须的,但是这些量采取能够被存储、传送、结合、比较和以其它方式操纵的电信号或磁信号的形式。主要出于常用的原因,已经证明有时将这些信号称为比特、值、元素、符号、字符、项、数字等等是方便的。
然而,应当记住,所有这些和类似的术语应与适当的物理量相关联,并且仅仅是应用于这些量的方便的标记。除非另有特别说明,否则从下面的讨论中可以清楚地看出,应当理解在整个描述中,使用诸如“执行”、“确定”、“设置”、“转换”、“构造”、“遍历”等的术语的讨论涉及计算机系统或类似的电子计算装置的动作和处理,其操纵在计算机系统的寄存器和存储器内表示为物理(电子)量的数据,并且将这些数据变换为在计算机系统存储器或寄存器或其它这种信息存储、传输或显示装置中类似地被表示为物理量的其它数据。
本发明的实施例还涉及用于执行本文的操作的设备。该设备可以是为了所需目的而特别构造的,或者它可以包括由存储在计算机系统中的计算机程序选择性编程的通用计算机系统。这样的计算机程序可以存储在计算机可读存储介质中,例如但不限于包括光盘、CD-ROM和磁光盘的任何类型的盘、只读存储器(ROM)、随机存取存储器(RAM)、EPROM、EEPROM、磁盘存储介质、光存储介质、闪速存储装置、其它类型的机器可访问存储介质或适于存储电子指令的任何类型的介质,其中的每个都耦接到计算机系统总线。
本文呈现的算法和显示并非固有地与任何特定计算机或其它设备相关。各种通用系统可以与根据本文的教导的程序一起使用,或者可以证明构造用于执行所需的方法步骤的更专用的设备是方便的。各种这些系统所需的结构将如在下面的描述中所述的那样呈现。另外,不参照任何特定编程语言来描述本发明。应当理解,各种编程语言可以用于实现如本文所描述的本发明的教导。
应当理解,上述描述旨在说明而非限制。在阅读和理解以上描述之后,许多其它实施例对于本领域技术人员将是显而易见的。虽然已经参照具体的示例性实施例描述了本发明,但是应当认识到,本发明不限于所述实施例,可以在所附权利要求的精神和范围内实施修改和变更。因此,说明书和附图应当被理解为是说明性的而不是限制性的。因此,本发明的范围应当参照所附权利要求以及这些权利要求的等同物的全部范围来确定。
- 还没有人留言评论。精彩留言会获得点赞!