视觉交互式搜索的制作方法
对其它申请的交叉引用
本申请是在2014年9月23日由nigelduffy提交的名称为“visualinteractivesearch”的美国申请no.14/494,364(代理档案号:gnfn3120-2)的部分继续申请,该申请根据35u.s.c119(e)要求在2014年5月15日由nigelduffy提交的名称为“visualinteractivesearch”(代理档案号gnfn3120-1)的美国临时申请no.61/994,048的权益。上述两个申请针对它们的教导在此通过引用而被并入本文。
本发明总体上涉及用于以交互和可视的方式搜索数字文档的工具。数字文档的示例包括:照片、产品描述或网页。例如,该工具可以被用在移动设备上以搜索可用于经由在线零售商销售的家具。
更具体而言,本发明涉及具有相关性反馈的文档检索。
背景技术:
当前的计算机搜索技术允许用户执行查询并用有序的结果列表来对那些查询进行响应。查询可以是结构化查询语言、自然语言文本、语音或参考图像的形式。但是,返回的结果经常没有满足用户的搜索目标。用户然后继续细化或修改查询以试图更好地实现期望的目标。
技术实现要素:
在此描述的系统使用具有相关性反馈的新颖的迭代搜索技术来解决这一挑战。
粗略地描述,一种数据库,在该数据库中要被搜索的文档的目录已经被嵌入到嵌入空间中。数据库标识嵌入空间中的文档中的每对文档之间的距离,该距离对应于文档对之间的不相似性的预定测量。向用户呈现来自嵌入空间内的初始(i=0)候选空间的n0个候选文档的初始(i=0)集合,该初始集合具有比初始候选空间少的文档。可以基于初始搜索查询来建立初始候选空间,初始搜索查询可以是文本的,语言的或视觉的,例如,经由原型图像。然后,对于从第一次迭代(i=1)开始的每个第i次迭代,用户从文档的当时文档选择文档的第i个被选择的子集(被称为文档的第(i-1)个集合),并且响应于选择,系统几何地约束嵌入空间以标识第i个候选空间,从而使得第i个候选空间中的文档比第(i-1)个候选空间中的文档在嵌入空间中集体地更靠近第i个被选择的子集中的文档。系统向用户呈现来自第i个候选空间的ni>1个候选文档的第i个集合,并且该过程重复下一次迭代,其中用户从向用户呈现的当时集合选择文档的新子集。最终,用户对当时集合中的文档中的一个或多个文档感到满意,并且作为响应,系统对文档采取动作。以这种方式,用户可以交互地细化搜索,以便更精确地对预期的搜索目标编码。
提供本发明的上述发明内容是为了提供对本发明的一些方面的基本理解。本发明内容并非旨在标识本发明的关键或重要元件或描绘本发明的范围。其唯一目的是作为稍后呈现的更详细描述的序言以简化形式呈现本发明的一些概念。在权利要求书、说明书和附图中描述了本发明的特定方面。
附图说明
将相对于本发明的具体实施例并且将对附图进行参考来描述本发明,其中:
图1示出了可以在其中实现本发明的各方面的示例环境。
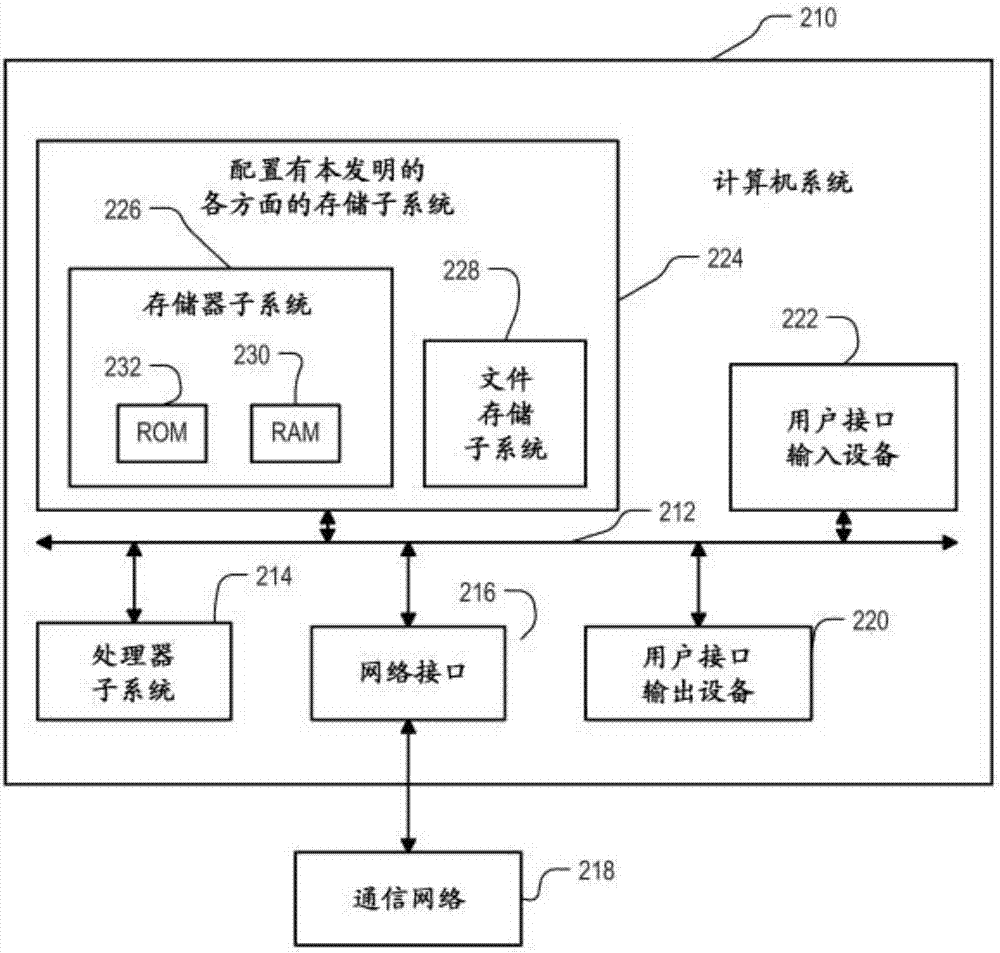
图2是可以被用来实现本发明的各方面的计算机系统的简化框图。
图3至图7以及图10a示出了被嵌入在2维嵌入空间中的文档。
图8是根据本发明的系统的实施例的各种组件的框图。
图9是示出了根据本发明的系统可以通过其进行的各种逻辑阶段的流程图。
图10b在布局空间中示出了来自图10a的某些文档。
图11示出了能够搜索鞋的一个实施例。
图12是根据本发明一个方面的用于实体产品的购买的搜索方法的流程图。
图13是根据本发明一个方面的用于数字产品的购买的搜索方法的流程图。
图14是根据本发明一个方面的用于标识然后被用于产生实体产品的数字内容的搜索方法的流程图。
图15是根据本发明一个方面的用于标识用于共享的内容的搜索方法的流程图。
图16是示出了在图18的实施例中在移动设备和服务器之间传递的消息的示图。
图17示出了在一个实施例中的约束数据库的内容。
图18是根据本发明的系统的移动设备实施例的各种组件的框图。
图19示出了其中针对主题域学习嵌入的实施例的相关部分。
具体实施方式
呈现以下描述以使本领域任何技术人员能够实现和使用本发明,并且在特定应用及其要求的上下文中提供。对所公开的实施例的各种修改对于本领域技术人员来说将是显而易见的,并且在不脱离本发明的精神和范围的情况下,可以将在此定义的一般原理应用于其它实施例和应用。因此,本发明不旨在限于所示出的实施例,而是符合与在此公开的原理和特征相一致的最宽范围。
在本发明的实施例中,系统可以具有几个方面,并且不同的实施例不需要实现所有这些方面:1)用于创建初始查询的模块,2)用于获得满足初始查询的候选结果的集合的模块,3)用于确定候选结果之间的距离或相似度的模块或者用于将候选结果嵌入到向量空间中的模块,4)用于对候选结果的区分性集合进行子选择的模块,5)用于在2个维度中对候选结果进行排列的模块,6)用于获得关于候选结果的用户输入的模块,7)用于细化搜索查询以并入关于用户输入的信息的模块,所述关于用户输入的信息被编码为相对于3的嵌入或距离测量的几何或距离约束,8)用于迭代地获得满足从用户输入累积的几何或距离约束和初始查询的候选结果的集合的模块。
图8是根据本发明的系统的实施例的各种组件的框图。它包括嵌入模块820,嵌入模块820计算源文档到嵌入空间中的嵌入,并且将嵌入信息与文档的标识相关联地写入文档目录数据库816中。用户交互模块822接收来自用户的查询和查询细化输入(诸如相关性反馈),并将它们提供给查询处理模块824。在一个实施例中,用户交互模块822包括计算机终端,而在另一实施例中,它仅包括某些网络连接组件,系统通过这些网络连接组件与外部计算机终端通信。查询处理模块824将查询解释为对嵌入空间的几何约束,并且缩窄或以其它方式修改目录以开发满足几何约束的候选文档的集合。这些被写入到候选空间数据库826中。在此使用的候选空间也是嵌入空间,并且例如可以构成目录816的嵌入空间的一部分。在一些实施例中,查询处理模块还可以在嵌入空间中执行候选文档的重新嵌入。区分性选择模块828然后从候选空间826选择文档的区分性集合,并且经由用户交互模块822将其呈现给用户。用户交互模块822然后可以从用户接收进一步的细化查询,如上所述地对其进行处理,或者它可以接收用户提交指示,在这种情况下,系统针对用户的所选择的文档采取一些动作830,诸如为用户打开文档,进行进一步的搜索细化,将用户的选择的文档处理为针对由文档表示的产品的订单,将用户的选择的文档处理为用于递送由文档表示的数字产品的订单,将用户的选择的文档处理为由要被制造和运送的文档表示的产品的订单,或者将用户的选择的文档处理为用于与由文档表示的其它数字内容共享的请求。
注意,在一些实施例中,用户细化输入可以不要求对候选空间的进一步几何约束,而是可以仅涉及从现有候选空间826选择文档的不同的区分性集合以呈现给用户。此外,在各种实施例中,候选空间数据库可以不被实现为单独的数据库,而是可以按照各种方式与文档目录嵌入空间816组合。在一些实施例中,候选空间也可以是隐式的而不是物理的。
图9是示出了根据本发明的系统可以通过其进行的各种逻辑阶段的流程图。最初,在步骤910中,将数字文档的目录(如在此使用的,包括图像,文本,网页,目录条目和文档的部分)嵌入在嵌入空间中并存储在数据库中。虽然这一文档群组在这里被称为“目录”,但是对该术语的使用并不旨在将该群组限制为可能在零售商店可能提供的目录类型中找到的文档。在数据库中,在嵌入空间中的每对文档之间标识对应于该文档对之间的不相似性的预定测量的距离。在步骤912中,可选地处理初始查询以产生满足查询结果的文档的初始候选空间。初始查询例如可以是常规文本查询。初始候选空间在文档的完整目录内并且可选地小于文档的完整目录。在步骤913中,从初始候选空间导出数字文档的初始集合。文档的这一初始集合是初始候选空间的子集。(如在此使用的,术语“子集”仅仅是指“真”子集)。为了在下文中方便地描述迭代搜索过程,初始候选空间在此有时被称为“i=0”候选空间。类似地,文档的初始集合在此有时被称为“i=0”集合。在一个实施例中,文档的初始集合被选择为目录的区分性子集,而在另一实施例中,文档的初始集合不是区分性的。在步骤914中,向用户标识文档的初始集合。在一个实施例中,这可以包括向用户可视地显示初始集合中的文档的表示。
在步骤915中,开始迭代搜索过程。为了便于描述,在此从迭代1开始连续地对迭代进行编号,并且通常每个迭代为迭代数'i'。有时参考第0次迭代,其指代i=0候选空间和i=0文档集合。
在第i次迭代开始之前,向用户呈现来自先前迭代(i-1)的文档集合。如果i=1,那么文档的这个集合来自步骤914的文档的初始(i=0)集合。如果i>1,那么文档的这个集合是在先前迭代的步骤923中呈现给用户的文档的第(i-1)个集合。
在第i次迭代开始时,在步骤916中,用户提供关于文档的第(i-1)个集合中的文档的相对反馈。优选地,相对反馈采取从第(i-1)个集合对文档的子集的用户选择的形式,其中对文档的选择意味着用户认为:该文档比来自第(i-1)个集合的未被选择的文档更与搜索目标相关。在第i次迭代中被选择的子集在此被称为第i个被选择的子集,并且来自第(i-1)个集合的未被选择的那些文档有时在此被统称为第i个未被选择的子集。
在步骤918中,以在此别处描述的方式从相对反馈导出几何约束的集合。在第i次迭代中导出的几何约束的集合被称为几何约束的第i个集合。
在步骤920中,将几何约束的第i个集合应用于嵌入空间以形成第i个候选空间,并且在步骤922中,选择候选文档的第i个集合作为在第i个候选空间中的文档的子集。在一个实施例中,文档的第i个集合被选择为第i个候选空间的区分性子集,而在另一实施例中,文档的第i个集合不是区分性的。在步骤923中,向用户呈现文档的第i个集合以用于可选的进一步细化。在步骤924中,如果用户对候选结果中的一候选结果满意,则用户指示提交该结果。如果用户输入指示进一步细化,那么逻辑返回到步骤915以进行搜索循环的下一次迭代。如果未指示进一步细化,那么在步骤926中,系统关于用户选择的文档采取动作。
注意,至少步骤910,912和914可以按照任何顺序发生。在一个实施例中,步骤910与其余步骤分开地在后台中连续地发生,并且与其余步骤异步地更新嵌入空间中的文档目录。
一般来说,图9的逻辑以及在此的所有序列和流程图可以使用处理器、通过包括现场可编程集成电路的专用逻辑硬件、或者通过组合专用逻辑硬件和计算机程序而被实现,处理器使用存储在可由计算机系统访问并且可由处理器执行的存储器中的计算机程序而被编程。流程图中的每个块或者逻辑顺序中的阶段描述了可以在硬件中或在一个或多个计算机系统上执行的一个或多个计算处理上运行的软件中实现的逻辑。在一个实施例中,流程图中的每个步骤或者逻辑顺序中的阶段示出或描述了单独的软件模块的功能。在另一实施例中,步骤的逻辑由分布在多于一个模块中的软件代码例程来执行。另外,作为在此使用的术语,“模块”可以包括一个或多个“子模块”,所述子模块本身在此被认为构成“模块”。与本文的所有流程图和逻辑顺序一样,应当理解,许多步骤可以被组合、并行执行或按照不同顺序被执行而不影响所实现的功能。在一些情况下,如读者将理解的那样,步骤的重新布置只有在也做出某些其它改变时才将实现相同的结果。在其它情况下,如读者将理解的那样,步骤的重新布置将仅在满足某些条件时才实现相同的结果。此外,将理解,本文的流程图和逻辑顺序仅示出了与理解本发明相关的方面,并且将理解,在特定实施例中,用于实现该实施例的其它功能的多个附加步骤可以是在所示的那些步骤之前、之后和之间执行。
在一些实施例中,在移动设备上执行对新的或已更新的约束的开发和维护,而在服务器上维护嵌入空间中的文档目录,该服务器通过包括wi-fi或蜂窝数据链路或两者的网络而与移动设备是分开的。总体布置仍然执行图9的步骤(其具有如在此别处所述的变型),但是该布置体现了在两个节点之间的特定的和高度有利的功能分配。具体来说,如在此别处所指出的,维护和更新约束所需的存储器和计算资源是最小的,足以允许在诸如电话或平板电脑之类的移动设备上而不是在服务器上执行和维护约束管理。
图18是根据本发明的系统的这样的移动设备实施例的各种组件的框图。在这个实施例中,服务器1810具有先前被嵌入到嵌入空间中的可访问的文件目录1816。服务器1810还包括候选空间标识模块1824,其可访问文档目录1816。通过将初始查询和当时(then-current)的约束集合应用到文档目录1816中的文档,候选空间标识模块在搜索的每次迭代时确定候选空间。得到的候选空间被临时存储在候选空间数据库1826中。在实施例中,候选空间数据库包含指向文档目录数据库1816中的文档而不是任何实际文档的指针。服务器1810还可选地包括区分性选择模块1828,其从候选空间1826选择文档的区分性集合以用于传输给移动设备1812。
移动设备1812包括用户交互模块1822,用户交互模块1822在每次迭代时向用户呈现文档的集合,并且接收关于该集合的用户反馈。用户交互模块1822将用户反馈转发给约束管理模块1832,约束管理模块1832管理约束数据库1834的内容。如果用户交互模块1822接收到用户提交指示,则它通知动作模块1830,动作模块1830对于用户的选择的文档采取一些行动,诸如在此别处关于图8所提及的动作。
图17示出了一个实施例中的约束数据库1834的内容。它包含后进先出堆栈,其中每个级别对应于搜索的相应迭代。每个第i级存储足够的信息以标识响应于查看呈现给用户的文档的集合而由用户的第i次迭代反馈所导致的几何约束。在一个实施例中,在针对该迭代的堆栈条目中描述对搜索的每次迭代有效的所有约束。在其中约束是累积性的另一实施例中,在针对该迭代的堆栈条目中仅仅描述了在每个迭代中添加的约束集合,所有适用于该堆栈条目的其它约束则由于它们存在于与先前迭代对应的堆栈条目中而被暗含。通常,每个堆栈条目在对应的迭代处“标识”可应用的约束的集合。
在图17的实施例中,针对每个第i次迭代的堆栈条目仅包含两个字段:一个字段1710,标识在第i次迭代中用户从文档的集合选择的、呈现给用户的所有文档,以及第二字段1712,标识在第i次迭代中呈现给用户但是用户没有选择的所有文档。在第一字段1710中标识的文档在此有时被称为用户从文档的集合选择的文档的第i个被选择的子集,并且在第二字段1712中标识的文档在此有时被称为用户从文档的集合选择的文档的第i个未被选择的子集。对第i个被选择的子集的用户选择指示:用户认为与第i个未被选择的子集中的文档相比,被选择的文档与目标更加相关。
在图17的实施例中,为了说明清楚起见,假设在每次迭代时仅向用户呈现三个文档,并且用户仅选择其中之一。对于迭代1,向用户呈现文档a,b和c,并且用户选择文档a。对于迭代2,向用户呈现文档d,e和f,并且用户选择文档d。对于迭代3,向用户呈现文档g,h和i,并且用户选择文档g。对于迭代4,向用户呈现文档j,k和l,并且用户选择文档j。系统解释每个条目以针对在堆栈的对应级中标识的每对文档定义单独的几何约束,其中在第一字段1710中标识该对中的一个文档,并且在第二字段1712中标识该对的另一个文档。因此,堆栈的级别1使用对(a,b)来定义一个约束并且使用对(a,c)来定义另一个约束。堆栈的级别2使用对(d,e)来定义一个约束并且使用对(d,f)来定义另一个约束,等等。实际约束是:为了满足约束,候选文档x必须在嵌入空间中离该对的第一文档比离该对的第二文档更近。因此,堆栈的级别1定义了如下约束:候选文档x在嵌入空间中必须离a比它离b更近、并且在嵌入空间中必须离a比它离c更近。这些约束出于本讨论的目的而被缩写为
d(x,a)<d(x,c)和d(x,a)<(x,b),
其中'd'意指嵌入空间中的距离。类似地,堆栈的级别2定义了如下约束:候选文档x必须在嵌入空间中必须离d比它离e更近并且在嵌入空间中必须离d比它离f更近。这些约束出于本讨论的目的而被缩写为
d(x,d)<d(x,f)和d(x,d)<dd(x,e),
等等。可以看出,如果迭代i中的第一字段1710标识pi文档,并且迭代i中的第二字段1712标识qi文档,那么每次迭代i的内容定义总共pi*qi个约束,每个约束个用于第一字段1710中的文档和第二字段1712中的文档的一个组合。应当理解,在不同实施例中可以使用表示在每次迭代中添加的约束的其它方式。
图16是示出在图18的实施例中的移动设备和服务器之间传递的消息的主要类型的示图。在这一实施例中,移动设备1812充当服务器1810的客户端。它管理与用户的交互,并更新和维护约束数据库1834中的约束。服务器1810维护目录,但是不保留关于用户的搜索的状态(虽然它可以记录它以用于以后的离线处理)。
最初,在框1610中,移动设备1812经由用户迭代模块1822从用户接收初始查询。在消息1612中,它将初始查询转发到服务器1810。在框1614中,服务器1810中的候选空间标识模块1824将查询应用于文档的集合1816以确定初始候选空间。在框1616中,服务器1810中的区分性选择模块1828从当时候选空间确定文档的区分性集合,但在另一实施例中,在框1616中选择的集合不一定是有区分性的。通过消息1618,服务器1810将所选择的集合返回给客户端移动设备1812,并且丢弃它在框1614和1616中所使用的约束或查询。消息1618包括呈现给用户和维护约束所需的所有信息,比如文档图像、关于文档的元数据以及它们在嵌入空间中的嵌入的指示。在框1620中,移动设备1812例如通过显示每个文档的图像来向用户呈现集合。在框1622中,以用户选择在框1620中呈现给用户的一个或多个文档的形式,移动设备1812从用户接收相关性反馈。在框1624中,约束管理模块1832基于用户的反馈来确定新的几何约束,并且在框1626中,它用新的约束来更新约束数据库1834。在消息1628中,移动设备1812然后将来自约束数据库1834的当时的约束集合(其包含关于搜索状态的所有相关信息)与来自框1610的初始查询一起被发送给服务器。该过程现在循环返回框1614,其中服务器1810将初始查询和当时的几何约束集合应用于文档的集合1816以导出下一候选空间。
正如可以看出的那样,关于给定用户的搜索,服务器1810是无状态的。这有若干益处:1)减少服务器上的负载,2)很容易通过添加更多的服务器来进行扩展——因为查询交互的每次迭代可以去往不同的服务器,3)由于服务器是无状态的,所以系统更健壮,因此例如如果服务器出故障,则状态被保留在移动设备上。另外,由于存储在约束数据库1834中的约束在当前和所有先前搜索迭代期间对用户的反馈进行了完全编码,所以它们只需要最小的存储和管理。
如上所提及,消息1618包括文档图像。尽管这些通常不大,但是可以实现许多高速缓存方案,其将保留客户端1812上的目录项目。这些高速缓存方案包括高速缓存流行项目或基于人口统计信息或搜索历史被预测为用户感兴趣的项目的方法。还可以通过预测在搜索的后续迭代中可能需要呈现哪些项目来将项目预取到客户端1812上。
数字文档的嵌入
如在此使用的,由嵌入模块820在步骤910中将数字文档嵌入到“嵌入空间”中,该“嵌入空间”是在其中表示文档的几何空间。在一个实施例中,嵌入空间是向量空间,其中文档的特征定义其在向量空间中相对于原点的“位置”。该位置通常被表示为从原点到文档的位置的向量,并且该空间具有基于向量中的坐标数量的维度数量。向量空间处理向量和可以对那些向量执行的操作。在另一实施例中,嵌入空间是度量空间,其不具有位置、维度或原点的概念。不是相对于任何特定原点,而是相对于彼此来保持度量空间中的文档之间的距离。度量空间处理对象以及这些对象之间的距离以及可以对那些对象执行的操作。出于当前讨论的目的,这些对象是重要的,因为存在对向量空间和度量空间进行操作的许多有效算法。例如,度量树可以用于快速地标识彼此“靠近”的对象。在下面的讨论中,我们将对象嵌入到向量空间和/或度量空间中。在向量空间的上下文中,这意味着我们定义一个将对象映射到某个向量空间中的向量的函数。在度量空间的上下文中,这意味着我们定义这些对象之间的度量(或距离),这允许我们将所有这些对象的集合视为度量空间。注意,向量空间允许使用包括欧几里德距离的距离(发散)的各种标准测量。其它实施例可以使用其它类型的嵌入空间。
如在此使用的,“嵌入”是将文档映射到嵌入空间中的映射。通常,它是将要被嵌入的文档的潜在大量的特征作为输入的函数。对于一些嵌入,映射可以由人创建和理解,而对于其它嵌入,映射可以是非常复杂和非直观的。在许多实施例中,后一类型的映射由基于训练示例的机器学习算法来开发,而不是被显式地编程。
让我们首先考虑在向量空间中的嵌入。为了在向量空间中嵌入文档目录,我们将每个文档与一个向量相关联。然后使用向量上的距离的标准测量来确定在这样一个空间中的两个文档之间的距离。
将数字文档嵌入向量空间中的目标是将直观相似的文档彼此靠近地放置。有很多方法来实现这一点。例如,嵌入文本文档的一种常见方式是使用词袋(bag-of-words)模型。词袋模型维护一个字典。字典中的每个单词被赋予一个整数索引,例如,单词aardvark可以被赋予索引1,并且单词zebra可以被赋予索引60,000。通过对该文档中每个字典单词的出现次数进行计数来处理每个文档。创建一个向量,其中在第i个索引处的值是第i个字典单词的计数。该表示的变型以各种方式对计数进行标准化。这种嵌入捕获关于内容的信息,并因此捕获文档的含义。具有相似单词分布的文本文档在此嵌入空间中彼此靠近。
存在各种各样的可以将文档嵌入到向量空间中的手段。例如,可以使用例如尺度不变特征变换(sift)来处理图像以标识共同出现的特征,然后对其进行分箱并且被使用在与上述的词袋嵌入类似的表示中。特别感兴趣的是使用深层神经网络或其它深度学习技术所产生的嵌入。例如,神经网络可以通过针对在训练数据的大型集合上的维度降低的测量来执行梯度下降从而学习适当的嵌入。作为另一示例,可以基于数据来学习内核并且基于该内核来导出距离。同样,可以直接学习距离。这些方法通常使用大型神经网络来将文档、单词或图像映射到高维向量。备选地,人们可以使用具有诸如多维缩放或随机邻近嵌入之类的算法的示例来学习嵌入。到向量空间中的嵌入也可以经由内核被隐式地定义。在这种情况下,可以从不生成或使用显式向量,而是通过在原始空间中执行内核操作来执行向量空间中的操作。
特别感兴趣的其它嵌入捕获关于文档的日期和时间信息,例如,拍摄照片的日期和时间。在这样的情况下,如果在不同星期的同一天,或在同一个月但不同年份拍摄图像,则可以使用将图像定位得更靠近的内核。例如,在圣诞节附近拍摄的照片可以被认为是相似的——即使它们在不同的年份拍摄并且因此在它们的时间戳之间具有大的绝对差。通常,这样的内核可以通过简单地查看时间戳之间的差异来捕获除此之外可用的信息。
类似地,捕获地理信息的嵌入可能是感兴趣的。这样的嵌入可以考虑与文档相关联的地理元数据,例如,与照片相关联的地理标记。在这些情况下,可以使用捕获仅仅两个位置之间的英里差之外的更多信息的内核或嵌入。例如,它可以捕获照片是否在同一城市、同一建筑物或同一国家拍摄。
通常嵌入将以多种方式考虑文档。例如,可以根据与该产品相关联的元数据、该产品的图像以及该产品的评论的文本内容来嵌入产品。这种嵌入可以通过为文档的每个方面开发内核并以某种方式(例如,经由线性组合)组合这些内核而被实现。
在许多情况下,将需要非常高的维度空间来捕获文档之间的直观关系。在这些情况中的一些情况下,可以通过选择将文档嵌入在空间中的歧管(弯曲表面)上而不是嵌入到任意位置中来减少所需的维度。
最后,值得注意的是,不同的嵌入在文档目录的不同子集上可能是适当的。例如,在搜索过程的每次迭代时重新嵌入候选结果集合可能是最有效的。以这种方式,可以将子集重新嵌入以捕获该子集中的变化的或感兴趣的最重要的轴。
为了将数字文档目录嵌入到度量空间中,需要将该目录与距离(或度量)相关联。下面我们讨论定义数字文档之间的距离的一些方法。
数字文档之间的距离和相似性
嵌入空间中的两个文档之间的“距离”“对应于”文档之中的不相似性的预定测量。优选地,它是不相似性的测量的单调函数。通常它等于不相似性的测量。示例距离包括曼哈顿距离,欧几里德距离和汉明距离。
存在测量数字文档之间的距离(或不相似性)的各种各样的方法,并且这些可以被组合以产生新的距离测量。一个重要的概念是可以通过这样的相似性或距离测量来捕获数字文档之间的直观关系。例如,一些有用的距离测量将包含相同人物的图像放置在彼此靠近的相同位置中。同样,一些有用的测量将讨论相同主题的文档放置为彼此靠近。当然,存在着许多轴,数字文档可以沿着这些轴直观地相关,从而使得(相对于该距离)与给定文档靠近的所有文档的集合可以是相当多样的。例如,描述安东尼和克娄巴特拉之间的关系的历史文本可能与其它历史文本、关于埃及的文本、关于罗马的文本、关于安东尼和克娄巴特拉的电影、以及爱情故事相似。这些类型的差异中的每一种构成相对于原始历史文本的不同轴。
这样的距离可以按照各种方式而被定义。一种典型的方式是通过嵌入到向量空间中。其它方式包括经由内核来编码相似性。通过将文档的集合与距离相关联,我们有效地将这些文档嵌入到度量空间中。直观上相似的文档在这个度量空间中将是靠近的,而直观上不相似的文档将相距很远。还要注意,可以学习内核和距离函数。事实上,在搜索的每次迭代时学习有关文档子集的新的距离函数可能是有用的。
注意,无论在何处使用距离来测量文档之间的不相似性,内核都可以被用来测量文档之间的相似性,反之亦然。特别而言,在下文中,例如在约束的定义中我们将参考距离的使用。然而,可以改为直接使用内核,而不需要将它们转换成距离。
内核和距离可以按照各种方式组合。以这种方式可以利用多个内核或距离。每个内核可以捕获关于文档的不同信息,例如,一个内核可以捕获关于一件首饰的视觉信息,而另一个捕获价格,并且再一个捕获品牌。
还要注意,嵌入可以是特定于给定域的,诸如产品的给定目录或内容的类型。例如,学习或开发专用于男鞋的嵌入可能是适合的。这样的嵌入将捕获男鞋之间的相似性,对于男士衬衫来说是不知情的。
数据库组织
在本发明的实施例中使用的诸如数据库816和826之类的数据库可以使用通常可用的装置或其它相关技术来将数据存储在例如关系数据库、文档存储、键值存储中。在每种情况下,原始文档内容(或指向它们的指针)可以被存储并与它们的高维表示或相对于其它文档的距离的测量集合相关联。
为了实现可扩展和快速的搜索性能,索引结构是关键。当将文档嵌入在向量空间中时,可以使用例如kd树来构建索引。当文档与距离度量相关联并因此被嵌入在度量空间中时,可以使用度量树。
将在此描述的数据库存储在一个或多个非临时性计算机可读介质上。如在此使用的,在数据库是否被布置在计算机可读介质“上”或“中”之间不意在区别。另外,如在此使用的,术语“数据库”不一定意味着任何结构的统一。例如,当一起被考虑时,两个或更多个单独的数据库仍构成在此使用的术语“数据库”。
初始查询
在步骤912中呈现给系统的初始查询可以使用各种标准技术而被创建和评估。例如,查询可以被呈现为通过键盘或通过语音输入的一组关键词;查询可以是通过键盘或通过语音输入的自然语言短语或句子;或者查询可以是表示音频信号、图像、视频或者是可以寻找相似的音频信号、图像、视频或文本的原型的一段文本。通过已知的各种手段可以有效地评估这样的初始查询,例如搜索关系数据库或使用反向索引。
初始查询还可以被设计为仅仅返回结果的随机集合。
初始查询也可以为空,即,不施加约束。
用于初始查询的其它接口允许分面搜索。分面搜索为用户提供了一种约束沿着一组轴的搜索的手段。例如,分面搜索可以提供允许用户约束可接受价格范围的滑块。
标识候选结果
从初始查询和后续用户输入创建的搜索约束被用于标识候选结果集合。这可以使用各种手段而被实现。例如,可以针对关系数据库执行初始查询,从而将结果嵌入向量或度量空间中。然后,可以使用例如kd树或度量树来对这些结果编索引,并且搜索这些结果以标识既满足初始查询又满足约束的候选。备选地,也可以将初始查询转换为应用于嵌入文档的集合的几何约束。在这种情况下,组合初始查询和用户输入两者所暗含的约束的几何表示,并且使用适当的索引来标识满足两组约束的嵌入文档。
如在此使用的,嵌入空间上的“几何约束”是在嵌入空间中用公式描述的约束,而不是仅仅通过对个体文档或文档特征编目以包括或排除。优选地,基于与用户已经看过的至少两个文档的距离(或相似性)来定义几何约束。例如,这样的约束可以被表示为“与文档b相比与文档a更相似的所有文档”。
在向量嵌入空间中,例如,可以按照定义超曲面的指定函数的形式来描述约束。超曲面一侧上的文档满足约束,而另一侧上的文档不满足约束。超平面可以根据点积或内核而被定义,并且对于固定向量x和候选z,要求k(x,z)>0。同样,圆锥约束对于一些常数c可能要求k(x,z)>c。在度量嵌入空间中,可以按照例如文档之间的距离的函数的形式来描述约束。因此,在度量嵌入空间中,几何约束可以采用例如“与文档x相距在指定距离内的所有文档”的形式,或者“到文档a的距离小于到文档b的距离的所有文档”的形式。在一个实施例中,为度量空间定义的超平面采取“m超平面”的形式,如在此使用的,“m超平面”由度量空间中的两个点a和b定义如下:
由点a和b指定的m超平面将度量空间(x,d)划分为两个集合a和b,其中:
a={x:x中的x从而使得d(a,x)<=e*d(a,b)*d(b,x)+f*d(b,x)+h*d(a,b)+i}
b=x\a
其中e,f,g,h和i是不全等于零的实值常数。
认为仅对位于度量空间的分区a或b中的规定分区中的那些文档满足几何约束。
还可以使用集合操作(例如,联合、交集)来组合几何约束以定义更复杂的几何约束。它们也可以通过采用所讨论的任何示例约束的变换而被创建。例如,对于给定文档x,y和w,可以采用距离的多项式函数,例如d(x,z)*d(x,z)+d(y,z)<d(w,z),并且只有满足函数的那些文档z被认为满足几何约束。
注意,可以独立于距离来使用内核,并且可以根据内核、内核的多项式、内核的变换或内核的组合来直接表示约束。
在一个实施例中,用户搜索序列的每次迭代标识新的约束,并且在该迭代处的结果集合由所有约束的组合效果来定义。例如,如果约束被表示为超曲面,其中只有在超曲面的a侧上的那些候选被认为满足约束,那么在给定迭代处的结果集合可以被认为是在所有约束超曲面的a侧的交集内的所有那些候选文档。
在各种实施例中,(由用户指示的或者被转换为几何约束的)约束可以是“硬的”或“软的”。硬约束是在解(solution)必须满足所有硬约束的条件的意义上必须满足的约束。软约束是如下约束,这些约束不需要被满足,但是对于候选解不满足的每个软约束,可能对候选解处罚。如果这种处罚的累积太大,则在特定实施例中可以拒绝该解。在一些实施例中可以放松约束,例如,可以通过将硬约束与处罚相关联来将硬约束转换为软约束,并且软约束可以减少它们的处罚。
一种可以表示几何约束的方式是维护所有无序的文档对的列表。列表中的每个条目将是对(a,b),其中a表示一个文档,b表示另一个文档。(注意,对(b,a)也可出现在列表中)。每个条目被理解为意指候选必须离该对中的第一元素比离第二元素更靠近。因此,该对的两个元素在此有时被称为“锚文档”。例如,对于文档c,对(a,b)将与约束d(a,c)<d(b,c)相关联。实数可以与每对相关联。在硬约束的情况下,该数可以是0或1,其中1意指必须满足约束,而0意指不需要满足约束。备选地,在软约束的情况下,数字可以是表示与破坏该约束相关联的处罚的任何实数。可以按照其它方式例如使用稀疏表示来维护此信息。一种替代方案是仅维护与非零实数相关联的那些对。
在步骤918中从用户的相对反馈导出的几何约束的每个集合的目标是进一步缩窄或修改先前的候选空间,以形成更好地接近用户期望目标的新候选空间。在每次迭代时,系统具有的关于用户期望目标的信息以用户的相对反馈的形式被提供,用户的相对反馈以文档选择的形式被提供。因此,一般来说,几何约束的每个第i个集合标识第i个候选空间,从而使得根据集体接近度的一些预定义的定义,与在第(i-1)个候选空间中的文档相比,第i个候选空间中的文档在嵌入空间中集体地更靠近在第i个被选择的子集中的文档。这意味着集体接近度的预定义的定义被定义为使得:如果在嵌入空间中d(a,x)<d(b,x),则候选文档x至少被认为与文档b相比更靠近文档a。
对于其中第i个被选择的子集或第i个未被选择的子集或两者可以包含多于一个文档的一个实施例,集体接近度的预定义的定义被进一步定义,从而使得:如果在嵌入空间中离在给定被选择的子集中的最远文档比离在给定未被选择的子集中的最近文档更靠近的在给定候选空间中的文档的部分大于在嵌入空间中离在给定被选择的子集中的最远文档比离在给定未被选择的子集中的最近文档更靠近的在特定先前候选空间中的文档的部分,则与在特定先前候选空间中的文档相比,在给定候选空间中的文档集体地更靠近给定被选择的子集中的文档。
对于其中第i个被选择的子集或第i个未被选择的子集或两者可以包含多于一个文档的另一实施例,集体接近度的预定义的定义被进一步定义,从而使得:如果在给定候选空间中的所有文档y以及第i个被选择的子集中的a和在第i个未被选择的子集中的b的所有文档对(a,b)上其中d(a,y)<d(b,y)的实例的计数,小于在特定先前候选空间中的所有文档x以及所有文档对(a,b)上其中d(a,x)<d(b,x)的实例的计数,其中针对给定候选空间中的文档y的总数与特定先前候选空间中的文档x的总数之间的任何差异对每个计数进行归一化,则与在特定先前候选空间中的文档相比,在给定候选空间中的文档集体地更靠近在给定的被选择的子集中的文档。
对于其中第i个被选择的子集或第i个未被选择的子集或两者可以包含多于一个文档的又一实施例,集体接近度的预定义的定义被进一步定义,从而使得:如果在第i个被选择的子集中的所有文档a上的平均而言离在第i个被选择的子集中的文档a比在第i个未被选择的子集中的所有文档b上的平均而言离在第i个未被选择的子集中的文档b更靠近的在给定候选空间中的文档的部分小于在第i个被选择的子集中的所有文档a上的平均而言离在第i个被选择的子集中的文档a比在第i个未被选择的子集中的所有文档b上的平均而言离在第i个未被选择的子集中的文档b更靠近的在特定先前候选空间中的文档的部分,则与特定先前候选空间中的文档相比,给定候选空间中的文档更靠近给定的被选择的子集中的文档。如在此使用的术语“平均”包括平均值和中值,并且可选地还包括加权。
对于其中第i个被选择的子集或第i个未被选择的子集或两者可以包含多于一个文档的又一实施例,集体接近度的预定义的定义被进一步定义,从而使得:如果在给定候选空间中的所有文档y以及在第i个被选择的子集中的a和在第i个未被选择的子集中的b的所有文档对(a,b)上与其中d(a,y)≥d(b,y)的每个实例相关联的处罚的聚合,小于在特定先前候选空间中的所有文档x以及在所有文档对(a,b)上与其中d(a,x)≥d(b,x)的每个实例相关联的处罚的聚合,其中针对给定文档w满足d(a,w)≥d(b,w)的每个实例与相应的处罚值预先相关联,则与特定先前候选空间中的文档相比,在给定候选空间中的文档集体地更靠近在给定的被选择的子集中的文档。如在此使用的,“聚合”包括总和、百分比或其它归一化,其中进一步包括附加的正数不会减少总聚合。
使用几何约束的优点在于:在实施例中,维护和更新约束所需的存储器和计算资源取决于约束的数量而不是目录大小。这将例如允许在诸如电话或平板电脑的移动设备上而不是在服务器上执行和维护约束管理。
区分性结果集合
搜索查询可能是不明确的或不足的,因此满足查询的文档可能是非常多样的。例如,如果初始查询针对“红色礼服”,则结果在其长度、领口、袖子等方面可以是相当不同的。模块的这个方面对结果的区分性集合进行子选择。直观上来讲,目标是向用户提供结果的集合,从而使得这些结果的选择或取消选择向搜索算法提供最具信息性的反馈或约束。可以将这个步骤认为是标识“信息性的”结果的集合、或者“多样化的”结果的集合、或者“区分性的”结果的集合。执行步骤918的区分性选择模块828以按照多种方式中的任何一种来选择结果的区分性子集。
在一个实施例中,结果的子集可以是区分性的,因为它提供用户可以选择的多样的不同种类的反馈。例如可以如在vanleuken等人的“visualdiversificationofimagesearchresults”,www'09proceedingsofthe18thinternationalconferenceonworldwideweb,第341-350页(2009)中那样来选择多样化图像,通过引用并入本文。选择这个多样化的集合以便向用户提供在下一次迭代时对查询进行细化的各种方式。存在可以用来标识这样的集合的各种方式。例如,可以执行最远的第一次遍历,其逐步地标识“最”多样化的结果的集合。最远的第一次遍历只需要一个距离度量,并且不需要嵌入。也可以用结果的集合对最远的第一次遍历进行初始化;然后,随后的结果与那个初始集合最不同。
用于选择候选结果的区分性子集的其它手段包括使用像pca(主要组件分析)或内核pca的算法来标识完整结果集合中的变化的关键轴。区分性子集然后被构造为包含位于沿着这些最大区分性轴的多个点处的文档。
用于选择候选结果的区分性子集的另一手段可以使用聚类算法来选择候选结果的区分性子集。这种机制可以使用诸如k均值或k中心点之类的的聚类算法来标识候选结果内的相似文档的聚类。请参阅http://en.wikipedia.org/wiki/k-means_clustering(2015年4月29日访问)和http://en.wikipedia.org/wiki/k-medoids(2015年4月29日访问),两者通过引用并入本文。然后将从每个聚类选择一个或多个代表性文档以产生区分性子集。具体而言,当使用k中心点时,每个聚类的中心可以被用作该聚类的代表之一。
另一种手段可以考虑由用户对给定文档进行选择或取消选择而产生的约束的集合。约束的这一集合可以根据其将产生的候选结果而被考虑。可以选择区分性子集以使得通过选择该区分性子集中的任何文档而产生的候选结果集合尽可能不同。
如在此使用的,文档群组中的特定文档的集合的“区分性”是作为集合中的任何文档的用户选择结果而被排除的、在群组中的最少数量的文档。也即是说,如果特定集合中的不同文档的用户选择导致排除了群组中不同数量的文档,那么在此集合的“区分性”被认为是那些数量中的最少者。注意,文档的区分性集合、或者公式——文档的用户选择通过所述公式来确定要排除哪些文档、或者两者应当被选择,以使得通过选择区分性集合中的任何文档而排除的文档的集合的联合等于整个文档群组。
同样如在此使用的,文档群组中的大小为n的文档的集合的“平均区分性”是在该文档群组中的所有大小为n的文档的集合上的该集合的区分性的平均值。同样如在此使用的,如果第一集合的区分性大于第二集合的区分性,则一个特定文档的集合可以比另一个文档的集合“更有区分性”。
优选地,执行步骤918的选择模块828从当前候选空间826选择n1>1个文档的集合,其比候选空间中的大小为nl个文档的集合的平均区分性更有区分性。甚至更优选地,执行步骤918的选择模块828选择这样一个集合:该集合至少与当前候选空间中的大小为n1个文档的其它集合的90%一样有区分性,或者在一些实施例中与全部其它集合一样有区分性。
还要注意,并非所有实施例都需要执行选择候选的区分性子集的步骤918。在一些实施例中,用户交互模块822向用户呈现从候选集合随机选择的或以某种其它方式被选择的文档子集是足够的。在这样的实施例中,区分性选择模块828被简单地用选择模块所替换。
可以选择被选择的子集以平衡区分性与满足软约束。例如,如果使用软约束,那么每个文档变成与其破坏的每个约束的处罚相关联。可以选择被选择的子集以利用该子集的区分性来权衡被选择的子集中的所有候选的总处罚。具体而言,具有最小处罚的文档可以优先地被包括在被选择的子集中——即使它降低了区分性。
在一些情况下,参见下文,可以使用机器学习算法来管理和更新约束。具体而言,这可以包括主动学习算法或赌博机算法。这些算法在每次迭代时标识“信息性”(或区分性)的示例。当这些算法被用来管理约束时,它们对信息性示例的标识可以被用作区分性子集,或者被用作用于确定区分性子集的基础。赌博机算法是特别感兴趣的,因为它们试图通过标识区分性示例来权衡最大化奖励(即,找到目标文档)。
在初始查询之前或之后,用于选择区分性子集的上述技术中的任何一种也可以被用于选择要向用户呈现的候选文档的初始集合。
结果呈现
在步骤920中由用户交互模块822向用户呈现的区分性结果的目的是向用户提供在其中用于细化查询约束的框架。
例如,结果可以被呈现为二维网格。结果应该以一种允许用户认识到这些结果之间的潜在距离(如使用距离测量或嵌入所定义的)的方式而被放置在该网格上。这样做的一种方式是确保相对于距离测量彼此远离的结果在网格上也彼此远离地被显示。另一种方式是例如使用多维缩放(mds)来将嵌入空间投影到两个维度上(例如,参见:jingyang等人的“semanticimagebrowser:bridginginformationvisualizationwithautomatedintelligentimageanalysis”,proc.ieeesymposiumonvisualanalyticsscienceandtechnology(2006),通过引用并入本文)。还有一种方式是在嵌入空间中对轴进行子选择并沿着那些轴对结果进行定位。
预期的其它布局包括不在网格上的2维组织(可能包括重叠的结果),与2维组织类似的3维组织。多维组织类似于2维和3维组织,具有围绕一个或多个轴旋转的能力。通常可以使用m维布局,其中m>1。在嵌入空间具有维度的实施例中,在呈现布局中的维度的数量不需要与嵌入空间中的维度的数量相同。其它布局包括分层组织或基于图形的布局。
布局空间中的文档放置应指示嵌入空间中的文档之间的关系。例如,布局空间中的文档之间的距离应当与嵌入空间中的相同文档之间的距离(单调地,如果不是线性地)对应。此外,如果三个文档在嵌入空间中共线,则有利地它们在布置空间中也被共线地放置。具体而言,在布局空间中与系统将其标识为用户查询的最可能的目标的候选文档(在此被称为主要候选文档)的共线性指示在嵌入空间中与主要候选文档的共线性。
然而,应当理解,嵌入空间通常具有非常大量的维度,并且在高维度空间中,实际上非常少的点是共线的。因此,在实施例中,在布局空间中共被线呈现的文档仅指示嵌入空间中的“基本上”共线性。如在此使用的,如果嵌入空间使得每个文档在空间(比如向量空间)中具有一个位置,那么如果在嵌入空间中由三个文档所形成的三角形的最大角度大于160度则在嵌入空间中该三个文档被认为是“基本上共线的”。如果嵌入空间使得文档在嵌入空间中不具有位置,但是它们确实彼此具有距离(例如,对于度量空间),那么如在此使用的,如果嵌入空间中的群组中的文档对之间的两个最小距离之和等于嵌入空间中的群组中的文档对之间的最大距离,则三个文档的群组被认为是共线的。如果两个最小距离之和超过最大距离不超过10%,则这三个文档被认为是“基本上共线的”。如在此使用的,“共线性”和“基本上共线性”不包括重合或基本重合的微不足道的情况。
用户输入
用户交互模块822向用户提供用户接口(ui),所述用户接口(ui)允许用户以各种方式提供输入。例如,用户可以点击单个结果以选择它,或者可以在单个结果的方向上滑动以取消选择它。类似地,用户可以一次选择或取消选择多个结果。例如,这可以使用每个结果上的切换选择器而被完成。用户还可以通过在结果的方向上滑动来隐式地选择一个结果集合,这指示了对于“结果在该方向上”的结果的期望。在这种情况下,“在该方向上”意味着主要结果和正被滑动的结果之间的差异应当被放大。也即是说,结果的下一个集合应该更像正被滑动的结果,而不像“主要结果”。可以通过允许用户“从”一个结果滑动“到”另一个结果来概括这个概念。在这种情况下,新结果应该更像“到”结果,而不像“从”结果。
另外,ui可以向用户提供(例如,经由双击或捏合)以指定结果的下一集合应该比所显示的任何其它结果更像特定结果的能力。也即是说,用户选择所显示的结果之一以指示该结果优于所显示的所有其它结果。然后,这可以被编码为约束集合,为每个未被选择的文档指示未来的候选(在嵌入空间中)应该与未被选择的文档相比更靠近被选择的文档。在这种形式的反馈中,用户选择文档以指示它们比未被选择的文档与用户的期望目标“更相关”,这种形式的反馈在此有时被称为“相对反馈”。它不同于更传统的“分类反馈”,在分类反馈中需要用户选择相关的和不相关的候选。然而,在许多情况下,相关文档非常罕见,以致于可能没有这样的文档可供用户选择。相反,在此的系统的实施例允许相对反馈,其中用户标识可能实际上不与目标严格相关但仍提供有效信息以指导进一步搜索的比较相关的候选。相对反馈和分类反馈都可以被认为是“相关性反馈”的形式。
对相对反馈进行编码的一种方式是作为对嵌入空间的几何约束的集合。对于每个未被选择的图像b,创建形式为d(a,c)<d(b,c)的约束,其中a是被选择的图像,c是对其应用约束的候选图像(d是在嵌入空间中的距离)。然后候选c仅当它满足d(a,c)<d(b,c)时满足约束。以这种方式,单击生成多个约束。这些约束可以被组合,例如使得组合的约束是它们的交集,并且可以给其它候选文档赋予排名(rank),所述排名是候选所破坏的约束中的个体约束的数量的单调函数(较小的排名指示与用户目标的较大的相似性)。备选地,通过将每个这样的约束与处罚相关联,可以将约束用作软约束。在这一备选中,可以向另外的候选文档给予排名,该排名是与候选所破坏的所有个体约束相关联的处罚的总和的单调函数。在另外的实施例中,可以取决于约束的年龄(在迭代搜索中在多早施加约束)来确定排名。在一个实施例中,这可以通过取决于首先施加给定约束的迭代数量来确定(或修改)与每个给定约束相关联的处罚从而来实现。在一个实施例中,处罚可以被设计为随着约束的年龄增加,而在另一实施例中,处罚可以被设计为随着约束的年龄而减小。
可以扩展该方法以允许用户选择更相关的多个图像。这个反馈可以被解释为使得每个被选择的图像比每个未被选择的图像更相关。在一个实施例中,系统然后可以创建与一个被选择文档和一个未被选择文档的每一对对应的不同约束。创建总共p*q个约束,其中p是被选择的文档的数量,q是未被选择的文档的数量。约束可以具有形式d(ai,c)<d(bj,c),i=1...p和j=1...q。
ui可以提供反向能力,即,它可以允许用户选择较不相关的图像而非较为相关的图像,并且上面的描述将被适当地修改。
ui还可以提供指定结果的下一个集合应当像特定选择但比结果的当前被选择的集合更多样化的能力。
此外,ui可以向用户提供移除先前添加的约束的能力。在一个实施例中,约束的堆栈(或历史)被维护。ui为用户提供了从堆栈弹出约束并因此移除先前添加的约束的能力。甚至更具体而言,当每条用户反馈被提供为单个优选图像时,即,被选择的图像优于未被选择的图像时,ui可以显示被选择的图像的序列,并允许用户移除单个(先前被选择的图像)及其相关联的约束,或者可以允许用户通过顺序地从堆栈弹出图像(及其相关联的约束)来回到先前的状态。这可以通过“返回按钮”或通过在用户接口上显示堆栈而被实现。
ui还可以为用户提供用于指定提供相似多样化图像的不同集合的能力。
ui还可以为用户提供用于提供多种不同种类的反馈的能力。
细化查询
系统然后并入用户的输入以创建经细化的查询。经细化的查询包括关于初始查询的信息和从用户到目前为止所进行的细化的迭代序列导出的信息。这个经细化的查询可以被表示为将后续结果聚焦在嵌入空间的区域内的几何约束集合。同样,它可以被表示为距离约束集合,它的交集定义了细化的候选结果集合。它也可以被表示为通过所有可能结果的集合的路径。
例如,经细化的查询可以包括要求后续结果在被选择的候选结果之一的指定距离内的约束。或者,经细化的查询可以包括要求后续结果更靠近一个候选结果而非更靠近另一个候选结果的约束(相对于距离度量)。这些约束以各种方式与先前标识的约束组合。例如,可能要求候选满足所有这些约束,或者可能要求候选满足所有约束中的一定数量的约束,或者在软约束的情况下,它们可以对它们所破坏的每个约束的处罚负责。
管理约束和细化查询的另一种方式是使用机器学习算法,见下文。
用户可以指定不兼容的约束。根据本发明的系统可以具有放松、收紧、移除或修改它确定为不适当的约束的能力。
可以放松或移除约束的一种方式是利用用户反馈。具体而言,ui可以为用户提供移除先前添加的约束或者从历史中弹出约束即“退回”的手段。
系统可以放松或收紧约束的另一种方式是在软约束的上下文中。具体而言,如果几何约束被视为软约束,即,对每个被破坏的约束负责处罚,那么这些处罚对于每个约束可以是不同的。特别地,较旧的约束可能比较新的约束具有更小或更大的处罚。在这里,较新的约束是在最近的迭代中添加的约束,而较旧的约束是在较早的迭代中添加的约束。无论在何处用处罚实现软约束,候选结果继而可以是具有在所有这样的约束上求和的较小总处罚的文档。然后,候选结果集合是其总处罚小于某一预定值的所有文档,或者只有具有最小总处罚的n个文档,其中n是预定义的整数。
用于对查询进行细化的机器学习
可以使用机器学习算法来更新和维护几何约束。在这样的实施例中,用户的反馈被视为对其应用机器学习算法的训练数据,并且该应用的结果产生用户期望目标的模型(在此有时也被称为假设),所述模型在某些情况下是几何约束。然而,所得到的约束通常不直接根据用户的反馈来表示。也即是说,所得到的模型确实显式地测试候选文档和用户已经为其提供反馈的文档之间的距离,而不是该关系是间接的或隐含的。
虽然许多机器学习算法学习将文档分类成两类或更多类,例如相关或不相关,但一些算法根据文档的相关性对顺序文档进行排名。这样的算法的示例包括rankboost(freund等人的“anefficientboostingalgorithmforcombiningpreferences,”journalofmachinelearningresearch4(2003)37页)或排名感知器(collins等人的“convolutionkernelsfornaturallanguage,”inadvancesinneuralinformationprocessingsystems,第625-632页(2001)),两者通过引用并入本文。这样的算法使用反馈或训练示例,其中仅提供有序的信息。具体来说,它们利用训练数据,其中文档(示例)不被分类为相关或不相关,而是相对于它们的相对相关性而进行排名。
当在图9的上下文中查看时,排名顺序学习算法有时将在步骤914中开发的几何约束称为“假设”或“模型”。因此在排名顺序学习算法的这种情况下在步骤914中的几何约束的开发涉及基于与来自先前迭代的反馈相组合的用户反馈来训练或更新当前的假设或模型。在步骤920中向用户呈现的候选的子集通常将是基于当前假设的一些有限数量的最高排名文档。这不一定是“区分性”子集。然而,一些学习算法也自然地将信息性或区分性文档标识为它们的假设开发过程的一部分。这些通常是如下文档:当文档被标记为相关或不相关并被添加到训练集合中时,文档将最大程度地改进模型。对于这些类型的学习算法,选择区分性子集的步骤918仅涉及选择在步骤916中已经被自然标识的文档,并且在步骤920中向用户呈现的候选子集确实是区分性的。
使用机器学习算法来更新和维护几何约束的一种方式是使用分类算法,诸如支持向量机(例如,tong等人的“supportvectormachineactivelearningforimageretrieval”,inproceedingsoftheacminternationalconferenceonmultimedia,12页,acm出版社,2001,通过引用并入本文;或tieu等人的“boostingimageretrieval,”internationaljournalofcomputervision56(1/2),第17-36页,2004,2003年7月16日接受,通过引用并入本文)。支持向量机在嵌入空间中维护单个超平面。支持向量机的变型可以使用主动学习不仅用以每次迭代时标识新约束,而且还用于在每次迭代时选择候选文档的信息性集合。
备选地,我们可以使用所谓的“在线学习算法”(http://en.wikipedia.org/wiki/online_machine_learning,2015年4月29日访问)或所谓的“多臂赌博机”学习算法(http://en.wikipedia.org/wiki/multi-armed_bandit,2015年4月29日访问),其中任一种都可以被用来实现相同的结果。这两篇文档均通过引用并入本文。
在线学习算法,作为在此使用的术语,维护基于训练数据逐步地更新的模型或假设。也即是说,这些算法不需要访问完整的训练数据集合,或者在本上下文中不需要访问完整的用户反馈的集合。当呈现新的训练数据时,这些算法可以更新他们的模型或假设,而不必用先前见过的训练数据对系统进行重新训练。相反,这些算法维护仅基于最近的反馈集合来逐步地进行更新的模型或假设。因此,它们可以需要基本上更少的存储器和/或计算资源,从而允许它们例如在移动设备上被执行。在本说明书的上下文中,假设可以被用来表示几何约束。例如,它可以表示嵌入空间中的超平面,或者它可以表示目录中的项目的加权组合,其中具有较大权重的项目被理解为更接近目标项目。用户的反馈被解释为在线学习算法用来学习的训练数据。也即是说,在线学习算法基于该反馈更新其假设(几何约束)。在一个实施例中,在线学习算法使用“具有专家建议的预测(predictionwithexpertadvice)”框架(cesa-bianchi等人,prediction,learning,andgames,剑桥大学出版社,2006,通过引用并入本文)。在这种情况下,每个目录项目(文档)被解释为专家并被分配权重。最初,这些权重全都是相同的。每个目录项当与相关联的距离组合时可以被理解为提供目录的排序。具体而言,对于目录项目a,可以向目录中的所有其它项目(例如,x)分配对应于它们的距离的数字,例如,d(a,x)。然后可以使用该数字即d(a,x)对目录中的项目进行排序。对于候选集合,与目录项目(例如,a)对应的每个专家推荐对该项目的选择,例如,x,它在该集合中排名最高,即,它是d(a,x)为最小的项目。然后根据用户是否选择该专家的排名最高的项目来增加或减少每个专家的权重。迭代地进行用户正在搜索的项目往往将比任何其它项目更正确(即,从候选集合推荐正确的项目),并因此将获得最大的权重。该一般方法的许多变型是可能的。一般来说,在线学习算法也不提供产生区分性子集的自然方式。然而,它们可以与各种其它手段组合,这样做包括基于pca的手段、聚类方法、或者可以选择高度区分性子集的包括强力搜索方法的任何其它手段。
多臂赌博机算法与“具有专家意见的预测”框架密切相关。与在线学习算法类似,这些算法维护一个基于用户反馈逐步地更新的假设。它们不是维护完整的用户反馈集合,而是仅基于最近的反馈来更新它们的假设。同样,这意味着这些算法可能需要较少的计算资源,并且因此可以在移动设备上被执行。这将允许在移动设备上而不是在单独的服务器上管理约束。这些算法同样维护专家集合(被称为“臂”),并设法标识好的专家。关键区别(在当前设置中)是:在每个回合中,这些算法选择一个或多个“臂”(或专家)来播放(play)。在本上下文中,“播放”意味着呈现给用户。选择臂以便平衡两个目标:播放好的臂,并学习哪些臂是好的。然后,用户反馈被解释为对所选择的臂的奖励——例如,如果用户点击可以转化为高奖励的臂之一。在下面描述一种可以适于维护和更新几何约束并且选择候选的子集的方式。显然,其它适配也可以是有效的。同样,目录中的每个项目(文档)与臂(专家)相关联。每个臂与其奖励的估计(即,其作为查询的解的适合性)和该估计的置信区间(确定性值)相关联。最初,所有的奖励估计是相等的,并且所有的确定性是相同的。在搜索过程的每次迭代中,选择一个或多个臂作为“区分性集合”并呈现给用户。用户点击其中一个候选,并且向相应的臂提供高奖励。向其它候选提供低奖励。更新相应的奖励估计。随着已经收集了更多的数据来估计其奖励,候选集合中的每个臂的确定性增加。现在,算法选择另一个候选集合(臂),从而使得集合包含高奖励的或者包含关于它们的奖励具有较大不确定性的或者包含两者的臂。迭代地进行,用户的搜索目标将获得高度肯定的高奖励估计并被标识为最佳臂。
标识接下来的结果
给定要被搜索的文档之间的距离(不相似性测量),或者将这些文档嵌入到向量空间中或嵌入到歧管上,存在可以被用来对文档目录进行索引且因此允许快速搜索的各种数据结构。这样的数据结构包括度量树、kd树、r树、通用b树、x树、球树、位置敏感哈希和反向索引。
系统使用这样的数据结构的组合来基于经细化的查询来标识候选结果的下一集合。
使用几何约束的优点是它们可以与这样的高效数据结构一起被使用,以标识在目录的大小上是子线性的时间上的下一个结果。
学习距离
用户行为数据可以由根据本发明的系统收集并被用来改进或专门化搜索体验。具体而言,表达距离或相似性的许多方式可以被参数化,并且这些参数可以被拟合。例如,使用内核的线性组合所定义的相似性可以具有基于用户行为数据调谐的该线性组合的系数。以这种方式,系统可以适应个体(或社区或上下文)相似性的概念。
类似地,可以独立于搜索方法来学习这样的内核或距离。也即是说,它们可以在以不同方式收集的数据上被学习。这种数据可以与在搜索过程期间捕获的数据组合或可以不与在搜索过程期间捕获的数据组合。
特别感兴趣的是使用深度学习(例如,具有多于3层的神经网络)来学习距离或相似性。
在一些实施例中,专门针对特定应用来学习距离。例如,一个实施例使用该方法来搜索潜在的伙伴(例如,在约会网站上)可以学习捕获面部相似性的内核。它还可以学习基于人们的facebook简档来捕获兴趣的相似性的内核。对这些内核(或距离)进行专门学习以解决相关联的搜索问题,并且可能在该问题之外没有实用性。图19示出了其中专门针对主题域来学习距离的实施例的相关部分。
参考图19,在步骤1910中,定义主题域。主题域的示例包括服装,首饰,家具,鞋,附件,度假租赁,房地产,汽车,艺术品,照片,海报,印刷品,家居装饰,一般实体产品,数字产品,服务,旅行套装,各种其它项目类别的任意项目。在步骤1912中,被认为是在主题域内的一个或多个项目被标识,并且被认为是在主题域外的一个或多个项目被标识。在步骤1914中,提供训练数据库,其仅包括被认为是在主题域内的文档。这个训练数据库包括第一项目,但不包括第二项目。在步骤1916中,仅根据所提供的训练数据来学习嵌入——即,不基于被认为在主题域外的任何文档来学习嵌入。机器学习算法可以被用来学习这种嵌入。在步骤1918中,使用所学习的嵌入来将文档的目录嵌入到嵌入空间中。优选地,嵌入到嵌入空间中的文档的目录本身限于主题域内的文档。稍后的处理可以继续图9的步骤912或步骤914或其变型,如在此述。
一些说明
图3示出了被嵌入在2维空间中的文档的集合。本发明的各方面设想将文档嵌入在大维度的空间中,因此两个维度仅用于说明的目的。空间310包含文档,例如321,322。每对文档在它们之间具有距离330。
图4示出了来自图3的文档的集合,此外还示出了圆形几何约束410。这个圆内部的那些文档例如421,422被认为满足约束。本发明的各方面以这样的几何约束的形式表达查询和用户输入。满足约束的文档是查询的当前结果。当用户提供进一步输入时,可以添加附加约束,或者可以添加或移除现有约束。
图5示出了来自图3的文档的集合,此外还示出了非圆形几何约束510。本发明的各方面设想了任意形状的几何约束、以及这种约束的联合、交集和差异。
图6示出了可以响应于用户输入来更新图4的圆形约束的手段。原始圆形约束610可以通过增加其半径以产生圆形约束620、或者通过减小其半径以产生约束630来进行修改。这些修改响应于用户输入而被完成。满足这些约束的文档的集合将随着约束被修改从而减少或扩展被考虑用于向用户显示的图像集合而改变。
图7示出了可以选择用于呈现给用户的文档的区分性子集的手段。突出显示的文档例如711,712彼此不同并且与包含在圆形约束区域中的其它文档不同。
图10a示出了嵌入空间中的文档的集合,其中查询处理模块824已经将集合缩窄到圆1020内的那些文档,并且已经标识出主要结果文档1018。此外,区分性选择模块828已经选择了文档1010,1012,1014和1016作为向用户呈现的区分性集合。可以看出,在嵌入空间中,文档1012,1018和1016基本上是共线的,并且文档1010,1018和1014基本上是共线的。
图10b示出了系统可以如何在布局空间中呈现文档的集合。(虚线是隐含的,而不是可见的。)文档的特定位置不一定与嵌入空间中的位置匹配,部分是因为空间的维度已经减小。然而,在嵌入空间中基本上共线的文档在布局空间中是共线的。特别来说,如果图10a中的虚线表示候选文档沿着其而不同的嵌入空间中的维度,则文档在图10b中的布局空间中的布置指示那些相同的维度。此外,沿着布局空间中的共线性的每条线的文档之间的相对距离也指示嵌入空间中的相对距离。
图11示出了能够搜索鞋的一个实施例。这一实施例在移动设备1101上。在此实施例中,维护目录并且在服务器上标识候选结果,同时在移动设备上维护约束。通过应用被训练来捕获鞋之间的视觉相似性的神经网络,将鞋嵌入高维空间中。使用对关于鞋的元数据(例如,其品牌)进行比较的内核来对嵌入做出其它的贡献。主要结果被显著地显示为左上角1102中的大图像。最靠近嵌入空间1103中的主要结果(即,最相似)的鞋子被显示为最靠近主要结果。然后显示满足当前约束的结果的区分性集合。在不同实施例中,这些约束可以是硬约束或软约束,或者一些可以是硬约束而其它是软约束。注意,这些结果维护显著的多样性,例如,嵌入空间最远的(并且显示为距离主要结果最远的)鞋1104与主要结果不同的颜色、但是相同的品牌。这个实施例维护约束的堆栈。每个约束要求:与一个未被选择的图像相比,候选更靠近用户选择的图像。因此,在每次迭代处,可以添加多个约束,例如11。在一个实施例中,这些约束被视为软约束,因为每个候选对于每个被破坏的约束都遭受处罚。候选结果是那些具有较小处罚的结果。在该实施例中,在1105处显示所选图像的堆栈,其中最旧的用户选择在左侧,而较新的用户选择在右侧。用户可以点击此堆栈中的任何图像。这将从堆栈弹出所有图像(及其相关联的约束)到被点击的图像的右边。这具有使用户返回到先前搜索状态的效果,该先前搜索状态由在选择被点击的图像之前有效的约束集合来定义。
优于现有系统的优点
在此描述的方法的各种实施例可以产生优于现有系统的以下优点中的一个或多个:
·实施例不必限于文档的单个固定层级。更具体而言,实施例不需要明确确定描述文档目录的分类法。也不需要将文档聚类到静态层级中。也即是说,用户可以执行的细化的序列不需要被约束为在一些预定义的分类或层级中缩窄或拓宽。
·实施例可以是非常灵活的,并且可以应用于图像、文本、音频、视频和许多其它类型的数据。
·与使用分类或标签相比而言,使用文档之间的相似性或距离的概念更容易表达关于文档之间的关系的直觉。
·以视觉方式对候选结果进行选择和取消选择是用于在移动设备或平板电脑上执行搜索的更容易的接口。
·根据几何约束对查询细化进行编码允许更灵活的用户交互。具体而言,在实施例中,用户不需要熟悉预定义的标记本体,也不需要熟悉被用来对约束进行组合的查询逻辑。
此外,在实施例中,这样的几何约束可以对特征标记或注释过程中的错误更加健壮。
·逐步细化搜索的能力有助于良好的用户体验。
·候选结果的区分性子集的使用使得更有效地使用了有限的显示空间。显示器上的杂波被最小化,同时捕获在完整结果集合中可用的高比例的信息,并且为用户提供各种选项以对查询进行细化。
·假定距离、嵌入和相似性可以是机器学习的,使用这种方法的系统可以提供将搜索体验专门化到个人、群体、文化和文档类别的能力。
·与基于内容的图像检索(cbir)技术相比,本发明的实施例可以更适合于搜索的逐步细化。具体而言,用户可以拍摄照片并使用cbir系统来标识相关或高度相似的照片。然而,如果用户对结果不满意,则cbir系统不向他们提供改进搜索目标的方式。
示例1
一种实现方式允许用户搜索个人照片的目录。用户最初被显示任意照片(主要结果),例如,最近拍摄或查看过的照片。这被显示在来自目录中的3×3网格的照片的中心。每张照片被选择为靠近(下面定义)主要结果,但是相对于主要结果沿着不同的轴而彼此不同。例如,如果主要结果是与家人上周在家拍摄的照片,则其它照片可以是:a)与家人去年在家的照片,b)与家人上周在户外的照片,c)没有家人的上周在家的照片等。在一些情况下,系统可以在主要结果的相对侧上放置两张照片,这两张照片沿着相同的轴但是它们的位置沿着该轴彼此不同。例如,放置在左侧的照片可以比主要结果中更显著地示出家庭成员a,而放置在右侧的照片可以比主要结果中更不显著地示出家庭成员a。
用户选择9张照片中的一张,然后其成为主要结果。然后,这被布局在更新后的再次“靠近”它但彼此不同的3×3网格的照片中。
如果在任何时候用户双击主要结果,则“靠近”的定义改变为“较小规模”(下面定义)。如果用户使用“捏出”手势,则“靠近”的定义改变为“较大规模”,并且更新结果集合。
以这种方式,用户可以导航照片的目录以找到特定的照片。
在这一示例中,照片可以被认为相对于多个标准是相似的,包括:
·照片的gps位置
·照片的时间
·照片的颜色内容
·照片是在室内还是室外拍摄的
·照片中是否有人
·照片中是谁
·照片中的人是快乐还是悲伤
·照片中描述的活动
·照片中包含的对象
还有很多其它的。这些标准被捕获到数值“距离”中,或者作为在一些空间中定位照片的向量。在后一种情况下,可以使用相似性或距离的标准概念,例如,点积或欧几里得距离。在实施例中,可以应用归一化函数,以便沿着不同轴的距离彼此相当。
当用户导航照片的目录时,用户正在搜索的“规模”改变。这个规模指定结果集合中的照片有多“靠近”主要结果。更确切地说,结果集合中的所有照片必须具有小于某个阈值的“距离”。随着规模增大或减小,该阈值增大或减小。
关于上述步骤来考虑该示例:
·嵌入:对于个人照片的用户目录中的每张照片,产生具有与例如经度、纬度、时间、星期几、面部的数目、给定活动是否被描述以及其它更多对应的索引的向量。
·初始查询:在这种情况下,初始查询为空,也即是说所有照片都是候选结果,呈现给用户的那一个是任意的。
·初始查询作为几何约束:初始查询产生几何约束的空集合
·将几何约束应用于嵌入照片集合以标识满足约束的那些,即候选结果
·使用最远的第一次遍历来从候选结果选择9张照片的区分性子集。
·9张照片以3×3网格呈现给用户
·用户选择其中一张照片来指示希望看到与那张相似的更多照片。
·处理用户选择的照片以产生新的几何约束,该几何约束可以被表示为嵌入空间中的被选照片周围的球体。将这个新约束添加到当前约束集合。组合的约束是到目前为止所选择的所有照片周围的球体的交集。
示例2
另一实现方式关注于搜索附件(服装、家具、公寓、首饰等)。在这一实现方式中,用户使用文本、语音或者用原型图像作为初始查询进行搜索。例如,用户使用文本条目来搜索“棕色钱包”。搜索引擎通过标识多样化可能结果集合来进行响应,例如,各种类型和各种色调的棕色的钱包。这些结果被布置在二维布置(例如,网格)中,由此更相似的结果被定位成彼此更靠近,并且更不同的结果被定位成彼此相对远离。然后,用户例如使用单选按钮来选择一个或多个图像。然后,由搜索引擎使用图像选择来定义嵌入空间中的“搜索方向”或向量,沿着该向量可以获得进一步的结果。
关于上述步骤来考虑这一示例:
·嵌入:对于附件目录中的每个条目,使用经过训练以区分附件的深度学习技术来产生向量。
·初始查询:在这种情况下,初始查询是一种文本搜索,其将进一步的结果缩窄到整个目录的一部分内。这个限制是初始候选结果的集合。
·初始查询作为几何约束:初始查询产生几何约束的空集合
·几何约束被应用于受限集合中的嵌入附件集合(即,初始候选结果),以标识满足约束的那些,即候选结果
·使用最远的第一次遍历从候选结果选择9个目录条目的多样化子集。
·9个目录条目以3×3网格被呈现给用户
·用户选择一个目录条目来指示希望看到与那个相似的更多附件。
·处理用户选择的附件以产生新的几何约束,该几何约束可以被表示为嵌入空间中的所选附件周围的球体。将这个新约束添加到当前约束集合。组合的约束是到目前为止所选择的所有附件周围的球体的交集。
一些变型
文档在诸如向量空间或度量空间之类的嵌入空间中被编码(经由距离)。搜索作为查询细化的序列继续进行。将查询细化编码为向量空间或度量空间上的几何约束。显示区分性候选结果以向用户提供添加区分性约束的能力。用户输入(例如,选择或取消选择结果)被编码为几何约束。
这种方式的变型对于读者而言是显而易见的。例如,可以在初始查询被处理之后嵌入文档,并且可以仅嵌入满足查询的那些文档。类似地,可以在过程中的任何点处使用不同嵌入来重新嵌入文档。在这种情况下,将在新的嵌入中重新解释几何约束。
可以在具有非几何约束的任何点处增补几何约束。在这种情况下,可以按照一种直截了当的方式来过滤候选结果,以便仅选择满足非几何约束的那些。以这种方式,可以用分面搜索、文本或语音输入来增补交互。在过程的每次迭代中,几何约束可以与非几何约束集合一起被管理。
示例实现方式可以通过这些步骤来继续进行:
1.从用户获得原型图像(至少1个)的集合;
2.从原型图像标识集合中距离小于阈值t的所有图像;
3.标识在(2)中收集的图像的区分性子集;
4.以二维布局向用户呈现图像的区分性子集;
5.如果用户对所呈现的图像之一感到满意,则接收对这种满意的指示并针对所选择的图像采取期望的动作;
6.如果用户尚未满意,则从用户获得更像所期望结果的所呈现图像的选择;
7.产生经修订的原型图像的集合;
8.减小阈值t;
9.转到2。
可以从与计算机系统交互的用户的观点或者与用户交互的计算机系统的观点或者这两者来观察上述方法。
该概念可以被概括为指代“数字文档”而不是图像,其中数字文档除了图像之外还包括数字目录中的音频、视频、文本、html、多媒体文档和产品列表。
该概念还可以被概括为使得在步骤1获得的初始集合作为用户在另一信息检索系统或搜索引擎内执行搜索(查询)的结果而被获得。
该概念还可以被概括为使得不是在步骤8减小阈值,而是用户接口提供减小或增加阈值或使其维护不变的能力。
该概念还可以被概括为使得在步骤1和步骤6存在原型图像的两个集合,并且在步骤2,系统标识距离小于第一集合的阈值t1并且大于第二集合的t2的图像。
该概念还可以被概括为使得在步骤6的一次迭代中,用户沿着至少一个轴的第一子集选择图像,并且在步骤6的另一次迭代中,用户沿着至少一个轴的第二子集选择图像,其中轴的第二子集包含未被包括在轴的第一子集中的至少一个轴。
示例使用
图9的搜索方法(包括在此提及的它的所有变型)可以用于各种目的,其中几个在下面进行概述。
图12是用于购买实体产品的图9的搜索方法的流程图,所述实体产品比如服装、首饰、家具、鞋、附件、房地产、汽车、艺术品、照片、海报、印刷品和家居装饰。在此提及的所有变型可以与图12的方法一起被使用。
最初,在步骤1210中,将数字文档的目录嵌入在嵌入空间中并存储在数据库中。在数据库中,在嵌入空间中的每对文档之间标识与由该对文档表示的产品之间的不相似性的预定测量对应的距离。在步骤1212中,可选地处理初始查询以产生满足查询结果的文档的初始(i=0)候选空间。初始查询例如可以是常规文本查询。初始候选空间在文档的完整目录内并且可选地小于文档的完整目录。在步骤1213中,从初始候选空间导出数字文档的初始集合。文档的这个初始(i=0)集合是初始候选空间的子集。在一个实施例中,文档的初始集合被选择作为目录的区分性子集,而在另一个实施例中,文档的初始集合不是区分性的。在步骤1214中,向用户标识文档的初始集合。在一个实施例中,这可以包括向用户可视地显示初始集合中的文档的表示。在步骤1215中,搜索过程以一个迭代的开始而开始,为了方便起见该迭代在这里被编号为迭代1。
在每个第i次迭代开始之前,向用户呈现来自先前迭代(i-1)的文档的集合。如果i=1,那么文档的这个集合是来自步骤1214的文档的初始(i=0)集合。如果i>1,则文档的这个集合是在先前迭代的步骤1223中呈现给用户的文档的第(i-1)个集合。
在第i次迭代开始时,在步骤1216中,用户提供关于文档的第(i-1)个集合中的文档的相对反馈。优选地,相对反馈采取用户选择来自文档的第(i-1)个集合的子集的形式,其中对文档的选择意味着:与由来自第(i-1)个集合的未被选择的文档表示的产品相比,用户认为由该文档表示的产品与搜索目标更相关。在第i次迭代中被选择的子集在此被称为第i个被选择的子集,并且来自第(i-1)个集合的未被选择的那些文档在此有时被统称为第i个未被选择的子集。在步骤1218中,以在此别处描述的方式从相对反馈导出几何约束的集合。在第i次迭代中导出的几何约束集合被称为几何约束的第i个集合。
在步骤1220中,将几何约束的第i个集合应用于嵌入空间以形成第i个候选空间,并且在步骤1222中,选择候选文档的第i个集合作为在第i个候选空间中的文档子集。在一个实施例中,文档的第i个集合被选择作为第i个候选空间的区分性子集,而在另一个实施例中,文档的第i个集合不是区分性的。在步骤1223中,向用户呈现文档的第i个集合以供可选的进一步细化。在步骤1224中,如果用户输入指示期望进一步细化,那么逻辑返回到步骤1215以进行搜索循环的下一次迭代。否则,用户指示进行提交,并且在步骤1226中,系统针对用户选择的文档采取动作。
然后,图12中的“采取动作”步骤1226涉及:(1)响应于选择标识的对象的用户输入,系统将该项目添加到意愿列表,将其添加到购物车,或者进行购买对话(步骤1228);以及(2)系统(可能在稍后的时间)接受来自用户的付款,以及直接或使用诸如fedex、ups或邮政服务之类的第三方运送公司将项目运送给用户(步骤1230)。接受付款并进行运送的步骤可以按照任何顺序被执行。对于免费产品,可能不需要付款。相应的子模块被包括在动作模块830(图8)中。
图13是用于购买例如电影,音乐,照片或书籍的数字产品的图9的搜索方法的流程图。在此提及的所有变型可以与图12的方法一起被使用。
最初,在步骤1310中,将数字文档的目录嵌入在嵌入空间中并存储在数据库中。在数据库中,在嵌入空间中的每对文档之间标识与由该对文档表示的数字产品之间的不相似性的预定测量对应的距离。在步骤1312中,可选地处理初始查询以产生满足查询结果的文档的初始(i=0)候选空间。初始查询例如可以是常规文本查询。初始候选空间在文档的完整目录内并且可选地小于文档的完整目录。在步骤1313中,从初始候选空间导出数字文档的初始集合。文档的这个初始(i=0)集合是初始候选空间的子集。在一个实施例中,文档的初始集合被选择作为目录的区分性子集,而在另一个实施例中,文档的初始集合不是区分性的。在步骤1314中,向用户标识文档的初始集合。在一个实施例中,这可以包括向用户可视地显示初始集合中的文档的表示。在步骤1315中,搜索过程以一个迭代的开始而开始,为了方便起见该迭代在这里被编号为迭代1。
在每个第i次迭代开始之前,向用户呈现来自先前迭代(i-1)的文档集合。如果i=1,那么文档的这个集合是来自步骤1314的文档的初始(i=0)集合。如果i>1,那么文档的这个集合是在先前迭代的步骤1323中呈现给用户的文档的第(i-1)个集合。
在第i次迭代开始时,在步骤1316中,用户提供关于文档的第(i-1)个集合中的文档的相对反馈。优选地,相对反馈采取用户选择来自文档的第(i-1)个集合的子集的形式,其中对文档的选择意味着:与由来自第(i-1)个集合的未被选择的文档表示的数字产品相比,用户认为由该文档表示的数字产品与搜索目标更相关。在第i次迭代中被选择的子集在此被称为第i个被选择的子集,并且来自第(i-1)个集合的未被选择的那些文档在此有时被统称为第i个未被选择的子集。在步骤1318中,以本文别处描述的方式从相对反馈导出几何约束的集合。在第i次迭代中导出的几何约束集合被称为几何约束的第i个集合。
在步骤1320中,将几何约束的第i个集合应用于嵌入空间以形成第i个候选空间,并且在步骤1322中,选择候选文档的第i个集合作为在第i个候选空间中的文档的子集。在一个实施例中,文档的第i个集合被选择作为第i个候选空间的区分性子集,而在另一个实施例中,文档的第i个集合不是区分性的。在步骤1323中,向用户呈现文档的第i个集合以供可选的进一步细化。在步骤1324中,如果用户输入指示期望进一步细化,那么逻辑返回到步骤1315以进行搜索循环的下一次迭代。否则,用户指示进行提交,并且在步骤1326中,系统针对用户选择的文档采取动作。
然后,图13中的“采取动作”步骤1326涉及:系统(可选地并且可能在稍后的时间)接受来自用户的付款(步骤1328),以及使用一些分发数字内容的手段例如电子邮件或流式传输向用户提供内容(步骤1330)。接受付款和提供内容的步骤可以按照任何顺序被执行。对于免费产品,可能不需要付款。相应的子模块被包括在动作模块830(图8)中。
图14是用于标识随后用于产生实体产品的数字内容的图9的搜索方法的流程图。例如,数字内容可以包括图像的目录,随后可以将其打印在海报、t恤或马克杯上。这里提及的所有变型可以与图12的方法一起被使用。
最初,在步骤1410中,将数字文档的目录嵌入在嵌入空间中并存储在数据库中。在数据库中,在嵌入空间中的每对文档之间标识与由该对文档表示的数字内容之间的不相似性的预定测量对应的距离。在步骤1412中,可选地处理初始查询以产生满足查询结果的文档的初始(i=0)候选空间。初始查询例如可以是常规文本查询。初始候选空间在文档的完整目录内并且可选地小于文档的完整目录。在步骤1413中,从初始候选空间导出数字文档的初始集合。文档的这个初始(i=0)集合是初始候选空间的子集。在一个实施例中,文档的初始集合被选择作为目录的区分性子集,而在另一个实施例中,文档的初始集合不是区分性的。在步骤1414中,向用户标识文档的初始集合。在一个实施例中,这可以包括向用户可视地显示初始集合中的文档的表示。在步骤1415中,搜索过程以一个迭代的开始而开始,为了方便起见该迭代在这里被编号为迭代1。
在每个第i次迭代开始之前,向用户呈现来自先前迭代(i-1)的文档集合。如果i=1,那么文档的这个集合是来自步骤1414的文档的初始(i=0)集合。如果i>1,那么文档的这个集合是在先前迭代的步骤1423中呈现给用户的文档的第(i-1)个集合。
在第i次迭代开始时,在步骤1416中,用户提供关于文档的第(i-1)个集合中的文档的相关性反馈。优选地,相关性反馈采取用户选择来自第(i-1)个集合的文档子集的形式,其中文档的选择意味着:与由来自第(i-1)个集合的未被选择的文档表示的数字内容相比,用户认为由该文档表示的数字内容与搜索目标更相关。在第i次迭代中被选择的子集在此被称为第i个被选择的子集,并且来自第(i-1)个集合的未被选择的那些文档在此有时被统称为第i个未被选择的子集。在步骤1418中,以本文别处描述的方式从相关性反馈导出几何约束的集合。在第i次迭代中导出的几何约束集合被称为几何约束的第i个集合。
在步骤1420中,将几何约束的第i个集合应用于嵌入空间以形成第i个候选空间,并且在步骤1422中,选择候选文档的第i个集合作为在第i个候选空间中的文档子集。在一个实施例中,文档的第i个集合被选择作为第i个候选空间的区分性子集,而在另一个实施例中,文档的第i个集合不是区分性的。在步骤1423中,向用户呈现文档的第i个集合以供可选的进一步细化。在步骤1424中,如果用户输入指示期望进一步细化,那么逻辑返回到步骤1415以进行搜索循环的下一次迭代。否则,用户指示进行提交,并且在步骤1426中,系统针对用户选择的文档采取动作。
然后,图14中的“采取动作”步骤1426涉及由系统执行的以下步骤:
·将所选数字内容添加到购物车或意愿列表,或者以其它方式基于所选内容记录用户购买产品的意图(步骤1428)。这一步骤也可以包括记录用户对特定种类的产品(例如,马克杯或鼠标垫)的选择。
·接受来自用户的付款(步骤1430)
·基于所选择的内容来制造实体产品,例如,通过在实体制品上再现该内容(步骤1432)
·将实体产品运送给用户或者通过运送服务将其运送(步骤1434)。
在各种实施例中,接受付款的步骤可以在制造步骤之后或者在运送步骤之后执行。此外,相应的子模块被包括在动作模块830(图8)中。优选地,上述实施例的唯一目的是标识内容以实现实体产品的制造和购买。
图15是用于标识用于共享的内容的图9的搜索方法的流程图。例如,嵌入空间中的数字文档可以包括用户的个人照片或其它媒体的目录。本文提及的所有变型可以与图15的方法一起被使用。
最初,在步骤1510中,将数字文档的目录嵌入在嵌入空间中并存储在数据库中。在图15的实施例中,目录可以是例如个人照片的用户库。在数据库中,在嵌入空间中的每对文档之间标识与由该对文档表示的内容之间的不相似性的预定测量对应的距离。在步骤1512中,可选地处理初始查询以产生满足查询结果的文档的初始(i=0)候选空间。初始查询例如可以是常规文本查询。初始候选空间在文档的完整目录内并且可选地小于文档的完整目录。在步骤1513中,从初始候选空间导出数字文档的初始集合。文档的这个初始(i=0)集合是初始候选空间的子集。在一个实施例中,文档的初始集合被选择作为目录的区分性子集,而在另一个实施例中,文档的初始集合不是区分性的。在步骤1514中,向用户标识文档的初始集合。在一个实施例中,这可以包括向用户可视地显示初始集合中的文档的表示。在步骤1515中,搜索过程以一个迭代的开始而开始,为了方便起见该迭代在这里被编号为迭代1。
在每个第i次迭代开始之前,向用户呈现来自先前迭代(i-1)的文档的集合。如果i=1,那么文档的这个集合是来自步骤1514的文档的初始(i=0)集合。如果i>1,那么文档的这个集合是在先前迭代的步骤1523中呈现给用户的文档的第(i-1)个集合。
在第i次迭代开始时,在步骤1516中,用户提供关于文档的第(i-1)个集合中的文档的相对反馈。优选地,相对反馈采取用户选择来自第(i-1)个集合的文档子集的形式,其中文档的选择意味着:与由来自第(i-1)个集合的未被选择的文档表示的内容相比,用户认为由该文档表示的内容与搜索目标更相关。在第i次迭代中被选择的子集在此被称为第i个被选择的子集,并且来自第(i-1)个集合的未被选择的那些文档在此有时被统称为第i个未被选择的子集。在步骤1518中,以本文别处描述的方式从相对反馈导出几何约束的集合。在第i次迭代中导出的几何约束集合被称为几何约束的第i个集合。
在步骤1520中,将几何约束的第i个集合应用于嵌入空间以形成第i个候选空间,并且在步骤1522中,选择候选文档的第i个集合作为在第i个候选空间中的文档的子集。在一个实施例中,文档的第i个集合被选择作为第i个候选空间的区分性子集,而在另一个实施例中,文档的第i个集合不是区分性的。在步骤1523中,向用户呈现文档的第i个集合以供可选的进一步细化。在步骤1524中,如果用户输入指示期望进一步细化,那么逻辑返回到步骤1515以进行搜索循环的下一次迭代。否则,用户指示进行提交,并且在步骤1526中,系统针对用户选择的文档采取动作。
然后,图15中的“采取动作”步骤1526涉及由系统执行的以下步骤:
·从用户接受关于共享手段的信息,例如,电子邮件,twitter,facebook(步骤1528)
·从用户接受关于应该与其共享所述项目的一个或多个第三方的信息(步骤1530)
·共享选择项目项目(步骤1532)。
从用户接受关于共享手段的信息的步骤可以在从用户接受关于应该与其共享所述项目的一个或多个第三方的信息的步骤之前或之后执行。此外,对应的子模块被包括在动作模块830(图8)中。同样,优选地,上述实施例的唯一目的是标识要被共享的内容。
计算机环境
图1示出了可以在其中实现本发明的各方面的示例环境。该系统包括经由诸如因特网之类的网络114而彼此连接的用户计算机110和服务器计算机112。服务器计算机112具有可访问的数据库816,其标识与诸如在向量空间中的相对距离和/或它们位置之类的嵌入信息相关联的文档。在各种实施例中,用户计算机110还可以具有标识相同信息的可访问的数据库118或者可以不具有这样的数据库118。
最初,嵌入模块820(其例如可以是服务器计算机112或是单独的计算机系统或是在这样的计算机上运行的进程)分析文档的目录以提取关于文档的嵌入信息。例如,如果文档是照片,则嵌入模块820可以包括神经网络并且可以使用深度学习来从照片导出嵌入图像信息。
备选地,嵌入模块820可以导出图像分类(可在其上放置给定照片的轴)的库,每一个都与用于在给定照片中识别给定照片是否满足(或以什么概率)那个分类的算法相关联。然后,嵌入模块820可以将其预先开发的库应用于新近提供的照片的较小集合(比如当前在用户计算机110上的照片)以便确定适用于每张照片的嵌入信息。无论哪种方式,嵌入模块820将用户可以搜索的文档目录的标识写入数据库816中,每个标识与其嵌入信息相关联。
在又一个实施例中,嵌入模块820写入数据库816中的嵌入信息可以从外部源提供或者手动输入。
可以按照多种不同的方式来实现上述迭代标识步骤。在一个实施例中,当用户迭代地搜索期望的文档时,所有计算都发生在服务器计算机112上。操作用户计算机110的用户仅通过浏览器看到所有结果。在这个实施例中,用户计算机110不必具有可访问的文档目录数据库118。在另一个实施例中,服务器计算机112将其在嵌入空间中的整个文档数据库118(或该数据库的子集)发送到用户计算机110,用户计算机110将其写入其自己的数据库118中。在这样的实施例中,当用户迭代地搜索期望的文档时,所有计算都发生在用户计算机110上。许多其它布置也是可能的。
电脑硬件
图2是可以被用来实现并入了本发明各方面的软件的计算机系统210的简化框图。该图表示了用户计算机110和服务器计算机112的实施例。在图18的实施例中,该图也表示了服务器计算机1810和移动设备1812两者的实施例。虽然上述方法指示用于执行指定操作的个体逻辑步骤或模块,但是应当理解,每个步骤或模块实际上使得计算机系统210以指定的方式进行操作。
计算机系统210通常包括处理器子系统214,其经由总线子系统212与多个外围设备通信。这些外围设备可以包括包含存储器子系统226和文件存储子系统228的存储子系统224,用户接口输入设备222,用户接口输出设备220和网络接口子系统216。输入和输出设备允许用户与计算机系统210交互。网络接口子系统216提供到外部网络的接口(包括到通信网络218的接口),并且经由通信网络218耦合到其它计算机系统中的对应接口设备。通信网络218可以包括许多互连的计算机系统和通信链路。这些通信链路可以是有线链路、光链路、无线链路或用于信息通信的任何其它机制,但是通常它是基于ip的通信网络。虽然在一个实施例中,通信网络218是因特网,但是在其它实施例中,通信网络218可以是任何合适的计算机网络。
网络接口的物理硬件组件有时被称为网络接口卡(nic),尽管它们不需要是卡的形式:例如,它们可以是直接适配在母板上的连接器和集成电路(ic)的形式,或者可以是与计算机系统的其它组件一起被制成在单个集成电路芯片上的宏单元的形式。
用户接口输入设备222可以包括键盘,诸如鼠标,轨迹球,触摸板或图形输入板之类的指示设备,扫描仪,并入到显示器中的触摸屏,诸如语音识别系统之类的音频输入设备,麦克风,和其它类型的输入设备。一般来说,术语“输入设备”的使用旨在包括将信息输入到计算机系统210中或计算机网络218上的所有可能类型的设备和方式。通过输入设备222,用户向系统提供查询和查询细化。
用户接口输出设备220可以包括显示子系统,打印机,传真机或诸如音频输出设备之类的非可视显示器。显示子系统可以包括阴极射线管(crt),诸如液晶显示器(lcd)之类的平板设备,投影设备或用于产生可视图像的一些其它机制。显示子系统还可以例如经由音频输出设备提供非可视显示。一般来说,术语“输出设备”的使用旨在包括从计算机系统210向用户或向另一机器或计算机系统输出信息的所有可能类型的设备和方式。通过输出设备220,系统向用户呈现查询结果布局。
存储子系统224存储提供本发明的某些实施例的功能的基本编程和数据结构。例如,实现本发明的某些实施例的功能的各种模块可以被存储在存储子系统224中。这些软件模块通常由处理器子系统214执行。
存储器子系统226通常包括多个存储器,所述多个存储器包括用于在程序执行期间存储指令和数据的主随机存取存储器(ram)230和其中存储固定指令的只读存储器(rom)232。文件存储子系统228为程序和数据文件提供持久存储,并且可以包括硬盘驱动器,软盘驱动器以及相关联的可移动介质,cdrom驱动器,光驱动器或可移动介质盒。实现本发明的某些实施例的功能的数据库和模块可以在诸如一个或多个cd-rom之类的计算机可读介质上提供,并且可以由文件存储子系统228存储。主机存储器226此外包含计算机指令,所述计算机指令当由处理器子系统214执行时使得计算机系统操作或执行如在此述的功能。如在此使用的,被称为在“主机”或“计算机”上或其中运行的过程和软件响应于包括这些指令和数据的任何其它本地或远程存储的主机存储器子系统226中的计算机指令和数据而在处理器子系统214上被执行。
总线子系统212提供了一种机制,通过该机制,计算机系统210的各种组件和子系统按照预期彼此通信。虽然总线子系统212被示意性地示出为单条总线,但是总线子系统的备选实施例可以使用多条总线。
计算机系统210本身可以是各种类型的,包括个人计算机,便携式计算机,工作站,计算机终端,网络计算机,电视,大型机,服务器场或任何其它数据处理系统或用户设备。具体而言,设想了用户计算机110可以是诸如平板计算机或智能电话之类的手持设备。在另一个实施例中,“系统”执行本文描述的所有操作,并且可以将“系统”实现为具有在不同成员计算机之间的任何期望的操作分配的单个计算机或多个计算机。由于计算机和网络的不断变化的性质,图2中描绘的计算机系统210的描述仅仅旨在作为用于说明本发明的优选实施例的具体示例。计算机系统210的许多其它配置可能具有比图2所示的计算机系统更多或更少的组件。
尽管已经在完全功能的数据处理系统的上下文中描述了本发明,但是本领域普通技术人员将理解,本文描述的过程能够以指令和数据的计算机可读介质的形式来被分布,并且不管实际用于执行分发的信号承载介质的具体类型如何,本发明都同样适用。如在此使用的,计算机可读介质是其上可以由计算机系统存储和读取信息的介质。示例包括软盘,硬盘驱动器,ram,cd,dvd,闪存,usb驱动器等。计算机可读介质可以按照编码的格式来存储信息,所述编码格式被解码以用于在特定数据处理系统中的实际使用。作为在此使用的术语,单个计算机可读介质还可以包括多于一个的物理项目,诸如多个cd-rom或多个ram段,或者几个不同种类的介质的组合。如在此使用的,该术语不包括其中信息以信号随时间变化的方式被编码的仅仅时变的信号。
条款
以下条款描述了与本发明的各方面相关的方法和系统的各种示例,其中一些是对权利要求中阐述的各方面的补充。
条款1.一种用于所需文档的用户标识的系统,包括:
处理器;以及
耦合到所述处理器的计算机可读介质,所述计算机可读介质以非瞬态的方式在其上存储多个软件代码部分,所述多个软件代码部分定义用于以下各项的逻辑:
第一模块,用于在计算机可读介质中以非瞬态的方式提供标识嵌入空间中的文档的目录的数据库,所述数据库标识所述嵌入空间中的所述文档中的每对文档之间的距离,所述距离对应于由文档对表示的产品之间的不相似性的预定测量,
第二模块,用于向所述用户标识来自所述嵌入空间内的初始(i=0)候选空间的n0>1个候选文档的初始(i=0)集合,所述初始集合具有比所述初始候选空间少的文档,
第三模块,用于针对以第一次迭代(i=1)开始的多个迭代中的每个第i次迭代:
响应于从文档的第(i-1)个集合对所述文档的第i个被选择的子集的用户选择,几何地约束所述嵌入空间以标识第i个候选空间,从而使得根据集体接近度的预定义的定义,所述第i个候选空间中的所述文档比所述第(i-1)个候选空间中的所述文档在所述嵌入空间中集体地更靠近所述第i个被选择的子集中的所述文档;以及
向所述用户标识来自所述第i个候选空间的ni>1个候选文档的第i个集合,ni小于所述第i个候选空间中的文档的数目,以及
第四模块,用于响应于对向所述用户标识的文档的特定子集的用户选择来引起动作,
其中集体接近度的所述预定义的定义被定义以使得如果在所述嵌入空间中d(a,x)<d(b,x)则候选文档x被认为与文档b相比更靠近文档a。
条款2.根据条款1所述的系统,其中由所述第二模块向所述用户标识的文档的每个第i个集合比在所述第i个候选空间中集合大小为ni的文档的平均区分性更有区分性。
条款3.根据条款1所述的系统,其中所述第一模块包括:
用于根据仅包括被认为在预定义主题域内的文档的训练数据来学习嵌入的模块;以及
用于根据学习的所述嵌入来将来自文档的所述目录的所述文档嵌入到所述嵌入空间中的模块,
其中文档的所述目录中的所有所述文档被认为在所述主题域内。
条款4.如条款1所述的系统,其中在每个第i次迭代中对嵌入空间进行几何约束以标识第i个候选空间,所述第三模块:
标识所述嵌入空间上的几何约束的相应的第i个集合;
针对所述第i个候选空间中的至少一些特定文档中的每个特定文档,确定与未被所述特定文档满足的几何约束的第一至第i个集合中的几何约束的每个几何约束相关联的处罚的聚合,所述几何约束中的每个几何约束的未满足与相应的处罚预先相关联;以及
在第i个候选空间中仅包括来自嵌入空间的所述文档中的ri个文档,其中所述ri个文档中的每个文档的聚合处罚不高于所述嵌入空间中的如下任何其它文档的聚合处罚:在确定聚合的步骤中针对所述任何其它文档确定聚合。
条款5.根据条款1所述的系统,其中在向用户标识来自初始(i=0)候选空间的n0>1个候选文档的初始(i=0)集合时,所述第二模块:
标识所述初始候选空间中的相似文档的聚类;以及
选择所述初始集合以包括来自标识的所述聚类中的每个聚类的至少一个文档。
条款6.根据条款5所述的系统,其中在向所述用户标识候选文档的初始集合时,所述第二模块向所述聚类中的每个聚类的中心点进行标识。
条款7.根据条款1所述的系统,其中在几何地约束所述嵌入空间以标识每个第i个候选空间时,所述第三模块标识所述嵌入空间上的几何约束的相应的第i个集合。
条款8.根据条款7所述的系统,其中所述几何约束中的第j个几何约束标识所述嵌入空间中的相应的文档对(aj,bj),并且被定义使得如果d(aj,x)<d(bj,x)则被特定候选文档x满足。
条款9.根据条款7所述的系统,其中在每个第(i-1)集合中由所述第三模块向所述用户标识但不在所述第i个被选择的子集中的那些文档定义文档的第i个未被选择的子集,
其中在几何地约束所述嵌入空间以标识每个第i个候选空间时,响应于从所述第(i-1)个文档集合对文档的第i个被选择的子集的用户选择,所述第三模块添加对所述嵌入空间的多个添加的约束,
其中如果且仅如果针对文档的所述第i个被选择的子集中的所有文档a和文档的所述第i个未被选择的子集中的所有文档b存在d(a,x)<d(b,x)时,所述多个添加的约束被特定候选文档x满足。
条款10.根据条款1所述的系统,其中在几何地约束所述嵌入空间进行以标识每个第i个候选空间时,所述第三模块更新所述嵌入空间中的超平面,所述第i个候选空间是由更新的所述超平面界定的所述嵌入空间的区域。
条款11.根据条款1所述的系统,其中所述嵌入空间是度量空间,
并且其中在几何地约束所述嵌入空间以标识每个第i个候选空间时,所述第三模块更新所述嵌入空间中的m超平面,所述第i个候选空间是由更新的所述m超平面界定的所述嵌入空间的区域。
条款12.如条款1所述的系统,其中在几何地约束嵌入空间约束以标识每个第i个候选空间时,所述第三模块将在机器学习算法中由用户选择的文档的第i个子集视为训练数据以更新所述用户的期望目标的假设。
条款13.根据条款1所述的系统,其中在几何地约束所述嵌入空间以标识每个第i个候选空间时,所述第三模块标识对所述嵌入空间的几何约束的相应的第i个集合,还包括:
第五模块,其维护标识几何约束的所述集合中的至少两个几何约束的约束数据库;以及
第六模块,其响应于在所述迭代中的第q次迭代之后的返回到其中p<q的第p个候选空间的用户请求,向所述用户标识来自所述第p个候选空间的np>1个候选文档的集合。
条款14.一种用于产品的用户获取的方法,包括:
对计算机系统可访问地提供标识嵌入空间中的文档的目录的数据库,文档的所述目录中的所述文档中的每个文档表示产品,所述数据库标识所述嵌入空间中的所述文档中的每对文档之间的距离,所述距离对应于由文档对表示的所述产品之间的不相似性的预定测量;
计算机系统向所述用户标识来自所述嵌入空间内的初始(i=0)候选空间的n0>1个候选文档的初始(i=0)集合,所述初始集合具有比所述初始候选空间少的文档;
针对以第一次迭代(i=1)开始的多个迭代中的每个第i次迭代:
响应于从文档的第(i-1)个集合对所述文档的第i个被选择的子集的用户选择,计算机系统几何地约束所述嵌入空间以标识第i个候选空间,从而使得根据集体接近度的预定义的定义,所述第i个候选空间中的所述文档比第(i-1)个候选空间中的所述文档在所述嵌入空间中集体地更靠近所述第i个被选择的子集中的所述文档;以及
向所述用户标识来自所述第i个候选空间的ni>1个候选文档的第i个集合,ni小于所述第i个候选空间中的文档的数目;以及
响应于对向所述用户标识的特定文档的用户选择,导致向所述用户运送由所述特定文档表示的产品。
条款15.根据条款14所述的方法,还包括:响应于对所述特定文档的用户选择,接受对由所述特定文档表示的产品的付款。
条款16.一种用于产品的用户获取的系统,包括:
处理器;以及
耦合到所述处理器的计算机可读介质,所述计算机可读介质以非瞬态的方式在其上存储多个软件代码部分,所述多个软件代码部分定义用于以下各项的逻辑:
第一模块,用于在计算机可读介质中以非瞬态的方式提供标识嵌入空间中的文档的目录的数据库,文档的所述目录中的所述文档中的每个文档表示产品,所述数据库标识所述嵌入空间中的所述文档中的每对文档之间的距离,所述距离对应于由文档对表示的产品之间的不相似性的预定测量,
第二模块,用于向所述用户标识来自所述嵌入空间内的初始(i=0)候选空间的n0>1个候选文档的初始(i=0)集合,所述初始集合具有比所述初始候选空间少的文档,
第三模块,用于针对以第一次迭代(i=1)开始的多个迭代中的每个第i次迭代:
响应于从文档的第(i-1)个集合对所述文档的第i个被选择的子集的用户选择,几何地约束所述嵌入空间以标识第i个候选空间,从而使得根据集体接近度的预定义的定义,所述第i个候选空间中的所述文档比所述第(i-1)个候选空间中的所述文档在所述嵌入空间中集体地更靠近所述第i个被选择的子集中的所述文档;以及
向所述用户标识来自所述第i个候选空间的ni>1个候选文档的第i个集合,ni小于所述第i个候选空间中的文档的数目,以及第四模块,用于响应于对向所述用户标识的文档的特定子集的用户选择来引起动作,以及
第四模块,用于响应于对向所述用户标识的特定文档的用户选择,导致向所述用户运送由所述特定文档表示的产品。
条款17.一种用于数字内容的用户获取的方法,包括:
对计算机系统可访问地提供标识嵌入空间中的文档的目录的数据库,文档的所述目录中的所述文档中的每个文档表示相应的数字内容,所述数据库标识所述嵌入空间中的所述文档中的每对文档之间的距离,所述距离对应于由文档对表示的所述数字内容之间的不相似性的预定测量;
计算机系统向所述用户标识来自所述嵌入空间内的初始(i=0)候选空间的n0>1个候选文档的初始(i=0)集合,所述初始集合具有比所述初始候选空间少的文档;
针对以第一次迭代(i=1)开始的多个迭代中的每个第i次迭代:
响应于从文档的第(i-1)个集合对所述文档的第i个被选择的子集的用户选择,计算机系统几何地约束所述嵌入空间以标识第i个候选空间,从而使得根据集体接近度的预定义的定义,所述第i个候选空间中的所述文档比第(i-1)个候选空间中的所述文档在所述嵌入空间中集体地更靠近所述第i个被选择的子集中的所述文档;以及
向所述用户标识来自所述第i个候选空间的ni>1个候选文档的第i个集合,ni小于所述第i个候选空间中的文档的数目,以及
响应于对所述用户标识的特定文档的用户选择,导致向所述用户递送由所述特定文档表示的数字内容。
条款18.根据条款17所述的方法,其中所述数字内容是由文件,图像,视频,音频文件和流媒体程序组成的群组中的成员。
条款19.一种用于数字内容的用户获取的系统,包括:
处理器;以及
耦合到所述处理器的计算机可读介质,所述计算机可读介质以非瞬态的方式在其上存储多个软件代码部分,所述多个软件代码部分定义用于以下各项的逻辑:
第一模块,用于在计算机可读介质中以非瞬态的方式提供标识嵌入空间中的文档的目录的数据库,文档的所述目录中的所述文档中的每个文档表示相应的数字内容,所述数据库标识所述嵌入空间中的所述文档中的每对文档之间的距离,所述距离对应于由文档对表示的所述数字内容之间的不相似性的预定测量;以及
第二模块,用于向所述用户标识来自所述嵌入空间内的初始(i=0)候选空间的n0>1个候选文档的初始(i=0)集合,所述初始集合具有比所述初始候选空间少的文档,
第三模块,用于针对以第一次迭代(i=1)开始的多个迭代中的每个第i次迭代:
响应于从文档的第(i-1)个集合对所述文档的第i个被选择的子集的用户选择,几何地约束所述嵌入空间以标识第i个候选空间,从而使得根据集体接近度的预定义的定义,所述第i个候选空间中的所述文档比所述第(i-1)个候选空间中的所述文档在所述嵌入空间中集体地更靠近所述第i个被选择的子集中的所述文档;以及
向所述用户标识来自所述第i个候选空间的ni>1个候选文档的第i个集合,ni小于所述第i个候选空间中的文档的数目,以及
第四模块,用于响应于对向所述用户标识的特定文档的用户选择,导致向所述用户递送由所述特定文档表示的数字内容。
条款20.一种用于制造由数字内容制成的实体产品的方法,包括:
对计算机系统可访问地提供标识嵌入空间中的文档的目录的数据库,文档的所述目录中的所述文档中的每个文档表示相应的数字内容,所述数据库标识所述嵌入空间中的所述文档中的每对文档之间的距离,所述距离对应于由文档对表示的所述数字内容之间的不相似性的预定测量;
计算机系统向所述用户标识来自所述嵌入空间内的初始(i=0)候选空间的n0>1个候选文档的初始(i=0)集合,所述初始集合具有比所述初始候选空间少的文档;
针对以第一次迭代(i=1)开始的多个迭代中的每个第i次迭代:
响应于从文档的第(i-1)个集合对所述文档的第i个被选择的子集的用户选择,计算机系统几何地约束所述嵌入空间以标识第i个候选空间,从而使得根据集体接近度的预定义的定义,所述第i个候选空间中的所述文档比第(i-1)个候选空间中的所述文档在所述嵌入空间中集体地更靠近所述第i个被选择的子集中的所述文档;以及
向所述用户标识来自所述第i个候选空间的ni>1个候选文档的第i个集合,ni小于所述第i个候选空间中的文档的数目,以及
响应于对向所述用户标识的特定文档的用户选择,基于由所述特定文档表示的所述数字内容来导致实体产品的制造和递送。
条款21.一种用于制造由数字内容制成的实体产品的系统,包括:
处理器;以及
耦合到所述处理器的计算机可读介质,所述计算机可读介质以非瞬态的方式在其上存储多个软件代码部分,所述多个软件代码部分定义用于以下各项的逻辑:
第一模块,用于在计算机可读介质中以非瞬态的方式提供标识嵌入空间中的文档的目录的数据库,文档的所述目录中的所述文档中的每个文档表示相应的数字内容,所述数据库标识所述嵌入空间中的所述文档中的每对文档之间的距离,所述距离对应于由文档对表示的所述数字内容之间的不相似性的预定测量;以及
第二模块,用于向所述用户标识来自所述嵌入空间内的初始(i=0)候选空间的n0>1个候选文档的初始(i=0)集合,所述初始集合具有比所述初始候选空间少的文档,
第三模块,用于针对以第一次迭代(i=1)开始的多个迭代中的每个第i次迭代:
响应于从文档的第(i-1)个集合对所述文档的第i个被选择的子集的用户选择,几何地约束所述嵌入空间以标识第i个候选空间,从而使得根据集体接近度的预定义的定义,所述第i个候选空间中的所述文档比所述第(i-1)个候选空间中的所述文档在所述嵌入空间中集体地更靠近所述第i个被选择的子集中的所述文档;以及
向所述用户标识来自所述第i个候选空间的ni>1个候选文档的第i个集合,ni小于所述第i个候选空间中的文档的数目,以及
第四模块,用于响应于对向所述用户标识的特定文档的用户选择,基于由所述特定文档表示的所述数字内容来导致实体产品的制造和递送。
条款22.一种用于共享数字内容的方法,包括:
对计算机系统可访问地提供标识嵌入空间中的文档的目录的数据库,文档的所述目录中的所述文档中的每个文档表示相应的数字内容,所述数据库标识所述嵌入空间中的所述文档中的每对文档之间的距离,所述距离对应于由文档对表示的所述数字内容之间的不相似性的预定测量;
计算机系统向所述用户标识来自所述嵌入空间内的初始(i=0)候选空间的n0>1个候选文档的初始(i=0)集合,所述初始集合具有比所述初始候选空间少的文档;
针对以第一次迭代(i=1)开始的多个迭代中的每个第i次迭代:
响应于从文档的第(i-1)个集合对所述文档的第i个被选择的子集的用户选择,计算机系统几何地约束所述嵌入空间以标识第i个候选空间,从而使得根据集体接近度的预定义的定义,所述第i个候选空间中的所述文档比第(i-1)个候选空间中的所述文档在所述嵌入空间中集体地更靠近所述第i个被选择的子集中的所述文档;以及
向所述用户标识来自所述第i个候选空间的ni>1个候选文档的第i个集合,ni小于所述第i个候选空间中的文档的数目;以及
响应于对向所述用户标识的特定文档的用户选择,导致由所述特定文档表示的所述数字内容的共享。
条款23.一种用于共享数字内容的系统,包括:
处理器;以及
耦合到所述处理器的计算机可读介质,所述计算机可读介质以非瞬态的方式在其上存储多个软件代码部分,所述多个软件代码部分定义用于以下各项的逻辑:
第一模块,用于在计算机可读介质中以非瞬态的方式提供标识嵌入空间中的文档的目录的数据库,文档的所述目录中的所述文档中的每个文档表示相应的数字内容,所述数据库标识所述嵌入空间中的所述文档中的每对文档之间的距离,所述距离对应于由文档对表示的所述数字内容之间的不相似性的预定测量;以及
第二模块,用于向所述用户标识来自所述嵌入空间内的初始(i=0)候选空间的n0>1个候选文档的初始(i=0)集合,所述初始集合具有比所述初始候选空间少的文档,
第三模块,用于针对以第一次迭代(i=1)开始的多个迭代中的每个第i次迭代:
响应于从文档的第(i-1)个集合对所述文档的第i个被选择的子集的用户选择,几何地约束所述嵌入空间以标识第i个候选空间,从而使得根据集体接近度的预定义的定义,所述第i个候选空间中的所述文档比所述第(i-1)个候选空间中的所述文档在所述嵌入空间中集体地更靠近所述第i个被选择的子集中的所述文档;以及
向所述用户标识来自所述第i个候选空间的ni>1个候选文档的第i个集合,ni小于所述第i个候选空间中的文档的数目,以及
第四模块,用于响应于对向所述用户标识的特定文档的用户选择,导致由所述特定文档表示的所述数字内容的共享。
条款24.一种用于所需文档的用户标识的系统,包括客户端设备和服务器设备,各自均具有处理器和计算机可读介质,所述计算机可读介质耦合到相应的处理器并且具有以非瞬态的方式在其上存储的多个软件代码部分,
所述服务器具有对其可访问的存储在计算机可读介质中的文档数据库,所述文档数据库标识嵌入空间中的文档的目录,所述文档数据库还标识所述嵌入空间中的所述文档中的每对文档之间的距离,所述距离对应于由文档对之间的不相似性的预定测量,
所述客户端设备具有对其可访问的以非瞬态的方式存储在计算机可读介质中的约束数据库,所述约束数据库标识对所述嵌入空间的几何约束的集合,
所述服务器上的所述多个软件代码部分包括:
用于向所述客户端设备标识来自所述嵌入空间内的初始(i=0)候选空间的n0>1个候选文档的初始(i=0)集合的模块,所述初始集合具有比所述初始候选空间少的文档;以及
用于根据并响应于从所述客户端设备接收到对所述嵌入空间的几何约束的集合来确定第i个候选空间,并且用于向所述客户端设备标识来自所述第i个候选空间的ni>1个候选文档的第i个集合的模块,ni小于所述第i个候选空间中的文档的数目,以及
所述客户端设备上的所述多个软件代码部分包括用于向所述用户呈现从所述服务器接收的候选文档的集合的模块,
所述客户端设备上的所述多个软件代码部分还包括用于针对以第一次迭代(i=1)开始的多个迭代中的每个第i次迭代,进行如下操作的模块:
响应于从所述服务器接收到文档的第(i-1)个集合,向所述用户呈现文档的所述第(i-1)个集合;
响应于从向所述用户呈现的文档的第(i-1)个集合对文档的第i个被选择的子集的用户选择,开发对所述嵌入空间的至少一个几何约束的第i个集合,几何约束的第i个集合标识第i个候选空间,从而使得根据集体接近度的预定义的定义,第i个候选空间中的文档比第(i-1)个候选空间中的文档在所述嵌入空间中集体更靠近第i个被选择的子集中的文档;
根据几何约束的所述第i个集合来更新所述约束数据库;以及
将所述约束数据库中的约束的所述集合向所述服务器转发以用于确定所述第i个候选空间,
客户端设备上的所述多个软件代码部分还包括用于响应于对向用户呈现的特定文档子集的用户选择来采取动作的模块。
条款25.如条款24所述的服务器。
条款26.如条款24所述的客户端设备。
如在此使用的,如果前驱事件或值影响给定事件或值,则给定事件或值“响应”于前驱事件或值。如果存在中介处理元件、步骤或时间段,则给定事件或值仍然可以“响应”于前驱事件或值。如果中介处理元件或步骤组合了多于一个事件或值,则处理元件或步骤的信号输出被认为“响应”于每个事件或值输入。如果给定事件或值与前驱事件或值相同,则这仅仅是退化情况,其中给定事件或值仍被认为“响应”于前驱事件或值。类似地定义了给定事件或值对另一事件或值的“依赖性”。
如在此使用的,对信息项的“标识”不一定要求对该信息项的直接指定。通过简单地通过一个或多个间接层来指向实际信息,或者通过标识一起足以确定实际信息项的一个或多个不同信息项,可以在字段中“标识”信息。另外,术语“指示”在此被用来意指与“标识”相同。
申请人在此分离地公开了在此在说明书和权利要求书中描述的每个个体特征,以及两个或更多个这样的特征的任何组合(在这样的特征或组合能够根据本领域技术人员的公知常识基于本说明书在整体上被实现的程度上),不管这样的特征或特征的组合是否解决了在此公开的任何问题,并且不限制权利要求的范围。申请人指出,本发明的各方面可以由任何这样的特征或特征的组合组成。鉴于前述描述,对于本领域技术人员显而易见的是,在本发明的范围内可以进行各种修改。
已经出于说明和描述的目的而提供了对本发明的优选实施例的前述描述。其并不旨在是穷举的或将本发明限制为所公开的精确形式。很显然,许多修改和变型对于本领域技术人员将是显而易见的。具体而言并且非限制性地,在本专利申请的背景技术部分中通过引用来描述、建议或并入的任何和所有变型通过引用而被特别地并入到对本发明的实施例的在此的描述中。另外,在此关于任何一个实施例通过引用来描述、建议或并入的任何和所有变型也将被认为是相对于所有其它实施例的教导。为了最好地解释本发明的原理及其实际应用,选择和描述了在此描述的实施例,由此使得本领域的其它技术人员能够理解本发明的各种实施例,并且各种修改适于预期的特定用途。本发明的范围旨在于由所附权利要求及其等同体来限定。
- 还没有人留言评论。精彩留言会获得点赞!