基于查询需求从行存储数据库自适应地构建和更新列存储数据库的方法和系统与流程
基于数据记录的存储格式,关系数据库系统中,可用行存储或列存储来保存数据记录。在行存储数据库中,数据记录以行格式排列。在通常包含INSERT/DELETE/UPDATE操作的联机事务处理(online transaction processing,OLTP)事务中,行存储通常表现出良好的性能。例如,可以为涉及一个磁盘I/O操作的整行更改信息。另一方面,在列存储数据库中,数据记录以列格式排列。列存储在在联机分析处理(online analytical processing,OLAP)查询方面性能良好,因为它只需要读取处理查询所需的那些列,大大减少了磁盘I/O操作。
由于行存储和列存储适用于不同类型的查询,因此已提出在数据库系统中同时包含行存储和列存储,即混合行/列存储,来处理混合工作负载。目标是在单个数据库系统实现良好的OLTP性能并输出实时(或几乎实时)的分析结果。从行存储数据库构建列存储数据库的常见方法是:从行存储中提取数据记录,并转换它们,再将数据加载到各自列的属性向量中。即,在接收或执行任何分析查询之前,列存储是静态构建的。例如,在数据库不可用于联机访问的非高峰期,执行ETL(Extract-Transform-Load,抽取-转换-加载)流程,以向列存储数据库转移数据。
然而,构建列存储数据库的典型方法是有问题的,因为根据所述方法,必须过度构建数据库以包括与任何后续查询无关的数据。特别地,哪些查询会在数据库上运行,这些查询又针对哪些数据,都是很难预见的。因此,列存储最可能被过度构建以便涵盖所有可能的查询(例如,为行存储数据库中的每个属性都构建属性向量或列)。
同时,随着世界各地的客户和公司对数据库记录不断访问的需求的日益增长,可能没有足够长的好时间窗来执行ETL流程,以将数据从行存储转移到列存储中。即,不再有任何非高峰期,也没有足够的时间来构建列存储数据库而又不会严重影响数据库系统的可访问性。
此外,传统的混合行/列存储数据库系统不能提供实时分析。即,分析查询不能实时执行,因为查询必须等ETL操作在查询执行之前的调度时间期间完成后进行。
因此,现有的混合行/列存储数据库系统仍然依赖于猜测查询执行期间会访问哪些属性的预测方法,并倾向于在接收或执行任何查询之前过度构建其列存储数据库。此外,为了加快访问速度,这些传统的列存储数据库构建在如随机存取存储器(random access memory,RAM)等的主存储器中,但是当整个列存储数据库被擦除时,在系统崩溃期间会遭受巨大的性能损失。因此,在重建整个列存储数据库的系统恢复过程中,系统仍然宕机。
从行存储数据库构建列存储数据库将是有利的,该行存储数据库不是对于需要访问数据的查询而被过度构建的,并且提供实时查询分析执行。
技术实现要素:
在本发明一些实施例中,公开了一种计算机系统。所述计算机系统包括:存储器,存储有计算机可执行指令,以及处理器,执行存储在所述存储器中的计算机可执行指令。所述可执行指令包括:构建用于存储数据的行存储数据库,所述行存储数据库行包括多个属性。所述指令还包括:构建列存储数据库,其包括为满足接收到的分析查询而构造的数据,所述列存储包括与所述行存储中的至少一个属性对应的多个属性向量,所述多个属性向量中的每一个包括用于满足多个先前接收到的分析查询中的至少一个的数据。所述指令还包括:接收针对所述行存储的多个改变事务,所述多个改变事务中的每一个都是有序的。所述指令还包括:当第一分析查询引用的第一引用属性对应于所述列存储中的第一属性向量时,基于与针对所述第一引用属性的改变事务对应的日志信息更新第一属性向量,以满足所述第一分析查询。
在另一些实施例中,公开了一种用于通过查询从行存储数据库自适应地构建和更新列存储数据库的方法。所述方法包括:构建用于存储数据的行存储数据库,所述行存储数据库行包括多个属性。所述方法还包括:构建列存储数据库,其包括为满足接收到的分析查询而构造的数据,所述列存储包括与所述行存储中的至少一个属性对应的多个属性向量,所述多个属性向量中的每一个包括用于满足多个先前接收到的分析查询中的至少一个的数据。所述方法包括:接收针对所述行存储的多个改变事务,所述多个改变事务中的每一个都是有序的。所述方法包括:当第一分析查询引用的第一引用属性对应于所述列存储中的第一属性向量时,基于与针对所述第一引用属性的改变事务对应的日志信息更新第一属性向量,以满足所述第一分析查询。
在本发明又一些实施例中,公开了一种非瞬时性计算机可读介质,具有用于使计算机系统执行信息访问方法的计算机可执行指令。所述方法包括:构建用于存储数据的所述行存储数据库,所述行存储数据库行包括多个属性。所述方法还包括:构建所述列存储数据库,包括为满足接收到的分析查询而构造的数据,所述列存储包括与所述行存储中的至少一个属性对应的多个属性向量,所述多个属性向量中的每一个包括用于满足多个先前接收到的分析查询中的至少一个的数据。所述方法包括:接收针对所述行存储的多个改变事务,所述多个改变事务中的每一个都是有序的。所述方法包括:当第一分析查询引用的第一引用属性对应于所述列存储中的第一属性向量时,基于与针对所述第一引用属性的改变事务对应的日志信息更新第一属性向量,以满足所述第一分析查询。
在阅读各种绘图中示出的以下实施例的具体描述后,本领域普通技术人员将意识到本发明各种实施例的这些以及其他目的和优势。
附图说明
附图包含在并且构成本说明书的一部分,其中相同的数字描绘相同的元件,附图说明本发明的实施例,并且与描述内容一起用于解释本发明的原理。
图1是本发明实施例提供的包括行存储数据库和列存储数据库的数据库系统的框图,所述列存储数据库使用自适应、即时、恰好足够的流程构建;
图2A是本发明实施例提供的前述定义的雇员表的行条目的示例性示意图;
图2B是本发明实施例提供的图2A所示的雇员表中工资属性的示例性属性向量的示意图;
图3A是本发明实施例提供的使用自适应、即时、恰好足够的过程从行存储数据库构建的列存储数据库中访问数据的方法的流程图;
图3B是本发明实施例提供的通过导入为满足执行查询的数据而动态自适应地构建列存储数据库,从而提供查询的实时分析结果的方法的流程图;
图4是本发明实施例提供的雇员表的B树示意图,其中当自适应地构建列存储数据库中的引用属性向量时,主索引用于执行部分表扫描;
图5是本发明实施例提供的实现用以管理元数据的示例性算法的示图,所述元数据指示在列存储数据库中已经构建了哪些属性向量以及哪些范围的信息包含在这些属性向量内;
图6A-6F是本发明实施例提供的将属性向量的覆盖区间与查询范围进行比较的各种示例的示意图;
图7是本发明实施例提供的用于通过导入用于满足执行查询的数据来动态自适应地构建列存储数据库的统一建模语言(Unified Modeling Language,UML)序列图的示意图;
图8是本发明实施例提供的包括行存储数据库和列存储数据库的数据库系统的框图,其中响应于执行分析查询来构建和更新所述列存储数据库;
图9是本发明实施例提供的通过将目标量数据导入到引用属性向量来动态自适应地更新列存储数据库,从而提供实时分析结果以满足分析查询的方法的流程图;
图10是本发明实施例提供的引用列存储数据库中的至少一个属性向量的显式改变事务的示意图;
图11是本发明实施例提供的示出与引用列存储数据库中的属性向量的改变事务对应的日志信息的流的数据流程图;
图12是本发明实施例提供的列存储数据库的日志信息格式的示意图,所述日志信息对应于引用列存储数据库中的至少一个属性向量的改变事务;
图13A是本发明实施例提供的用于展示更新列存储数据库的第一阶段的统一建模语言(Unified Modeling Language,UML)序列图的示意图,该更新涉及存储与引用列数据库中的属性向量的改变事务对应的日志信息;
图13B是本发明实施例提供的用于展示更新列数据库的第二阶段的统一建模语言(Unified Modeling Language,UML)序列图的示意图,该更新涉及响应于查询将改变应用到列存储数据库中的属性向量,所述改变对应于阶段一中先前存储的改变事务;
图13C是本发明实施例提供的通过将目标量数据导入到引用属性向量来动态自适应地更新列存储数据库,从而提供实时分析结果以满足分析查询的示例性算法的示意图;
图14A是本发明实施例提供的响应于执行分析查询来动态自适应地更新列存储数据库中的所有属性向量从而提供实时分析结果的流程图;
图14B是本发明实施例提供的通过导入列存储数据库中的属性向量的所有改变数据来动态自适应地更新列存储数据库,从而提供实时分析结果以满足分析查询的示例性算法的示意图;
图15是本发明实施例提供的用于(例如,通过实现迁移混合迁移技术)通过以下操作提供实时分析结果的方法的流程图:通过将目标量数据导入到引用属性向量来动态自适应地更新列存储数据库中的引用属性向量,以满足分析查询;以及当包含来自同步点的改变事务的迁移缓冲器已经达到阈值时,动态自适应地更新列存储数据库中的所有属性向量。
具体实施方式
现将详细地对本发明的各种实施例、附图示出的示例做出参考。虽然会结合这些实施例进行描述,但可以理解的是它们并不用于将本发明限制于这些实施例。相反,本发明旨在覆盖可以包括在由所附权利要求书限定的本发明公开的精神和范围内的替代物、修改和等同物。另外,在以下本发明的详细描述中,阐述了许多特定细节以便提供对本发明的透彻理解。然而,可以理解的是,实际应用中,可以不包括本发明的这些特定细节。在其他实例中没有详细描述众所周知的方法、流程、部件和电路,以免对本发明的各方面造成不必要地模糊。
因此,本发明实施例提供用于从行存储数据库自适应地构建列存储数据库的方法和系统,以满足针对引用属性向量或列的分析查询。本发明其他一些实施例提供了从行存储数据库中构建列存储数据库的方法和系统,没有使用对访问数据库的分析查询无用的数据过度构建所述行存储数据库。本发明又一些实施例提供了使用在多个接收到的查询中的每一个运行时自适应构建的列存储数据库实时执行查询的方法和系统。本发明再一些实施例提供用于从行存储数据库自适应地更新列存储数据库的方法和系统,以满足分析查询。其他实施例提供通过响应于查询而更新列存储数据库来为列存储数据库上运行的查询提供即时数据一致性的方法和系统。另外,其他实施例公开了单个数据库管理系统中的混合行/列存储数据库,其中恢复系统不改变行存储数据库系统的系统恢复时间,因为在系统恢复操作期间,不需要更新列存储数据库中的属性向量,就可以将存储器拷贝到列存储数据库的迁移缓冲器中。
下面详细描述的一些部分以能够在计算机存储器中执行的数据位上的操作的程序、步骤、逻辑块、处理、以及其他象征性的表现形式呈现。这些描述和表现形式是数据处理领域技术人员用于向本领域其他技术人员最有效传达其工作实质的方式。在此将程序、计算机生成的步骤、逻辑块、过程等一般设想为首尾一致的步骤或指令序列,以产生期待结果。步骤是需要物理量的物理操作的那些步骤,是指计算系统的动作和过程,等等,该计算系统包括:处理器,用于将表示为计算机系统的寄存器和存储器内的物理(电子)量的数据处理并转换为类似地表示为计算机系统的存储器或寄存器或其他此类信息存储、传输或显示设备内的物理量的其他数据。
根据本发明实施例,描述了提供视频分段的方法的示例性流程图。虽然在流程图中公开了具体步骤,但这些步骤是示例性的。即,本发明实施例非常适合执行流程图中列举的步骤的各种其他步骤或变型。而且,本文描述的实施例可以在计算机可执行指令的一般上下文中进行讨论,所述指令驻留在某种形式的的诸如程序模块等的计算机可读存储介质上,由一个或多个计算机或其他设备执行。作为示例而非限制,软件产品可以存储在一个非易失性或非瞬时性计算机可读存储介质中,其可以包括非瞬时性计算机存储介质和通信介质。一般而言,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件以及数据结构等。程序模块的功能可以根据需要结合或分布在各种实施例中。
基于查询需求从行存储数据库自适应地构建列存储数据库
图1是本发明实施例提供的包括行存储数据库150和列存储数据库170的数据库系统100的框图,所述列存储数据库170使用自适应、即时、恰好足够的流程构建。具体地,列存储数据库170在每个接收到的分析查询运行时动态逐步地构建,所述列存储数据库自适应地构建以满足每个查询。
根据本发明实施例,数据库系统100可以包括处理器和存储器,其中,处理器用于执行存储在存储器中的计算机可执行指令,处理器用于实现基于自适应、即时、恰好足够的语句的迁移过程,构建列存储数据库。在一实施例中,处理器用于执行本文所描述和/或说明的一个或多个示例性实施例的功能,例如由查询/事务管理器120,820和/或1350执行的操作。处理器可以包括在能够执行计算机可读指令的单或多处理器计算设备或系统内。其最基本的形式中,计算设备可包括至少一个处理器和系统存储器。系统存储器耦合到处理器,一般表示能够存储数据和/或其他计算机可读指令的任何类型或形式的易失性或非易失性存储设备或介质。系统存储器的示例包括但不限于RAM,ROM,闪存或任何其他合适的存储器设备。
出于讨论目的,“存储数据库系统”或“主存储器数据库系统”是指包括CPU和“主存储器”的数据库系统,所述主存储器用于容纳所有数据以便功能正常发挥。这是典型的用于存储数据的传统系统。例如,主存储器可以包括随机存取存储器(random access memory,RAM)。主存储器可以使用永久性存储器或者使用电池备份系统进行备份。出于说明目的,100GB主存储器数据库系统用于在主存储器中存储所有100GB。
另一方面,本发明实施例公开了一种数据库系统,其允许数据单独或组合地分布在主存储器和永久存储器中。例如,在一实施例中,如果不是全部数据,也有大部分数据存储在永久存储器中。即,以所述100GB的存储器系统为例,数据存储在永久存储器中,主存储器(例如,4GB)用于较快访问,比如通过缓冲器。在这种方式下,笔记本电脑是现阶段存储大量数据的合适介质,而传统上笔记本电脑不适合配置100GB的主存储器。在又一实施例中,数据存储在主存储器中用于正常操作,并在永久存储器有备份。
由于行存储数据库和列存储数据库适用于不同类型的查询,本发明实施例使用包括行存储数据库和列存储数据库的数据库系统。具体地,本发明实施例提供数据库系统100中的混合行/列存储访问,以处理混合OLTP/OLAP工作负载。因此,在混合工作负载环境下,混合行存储和列存储数据库系统100实现了高OLTP性能并输出实时(或几乎实时)分析结果。
如图1所示,数据库100包括行存储数据库150。行存储数据库150的每行包括多个属性。例如,行存储数据库150可定义为雇员表,包括8个属性,其中,表是记录的集合。为便于说明,雇员表可包括与公司雇员相关的信息,该信息定义为属性。下面提供了定义示例性雇员表的属性的表定义:
CREATE TABLE Employee
(
EmpNo int not null primary key,
Name varchar(127)not null,
Gender char(1)not null,
DeptNo int not null,
StartDate date,
Title varchar(50)not null,
Salary Decimal(10,2)null,
Comment varchar(255)null,
PRIMARY KEY(EmpNo),
INDEX(Name),
INDEX(DeptNo)
);
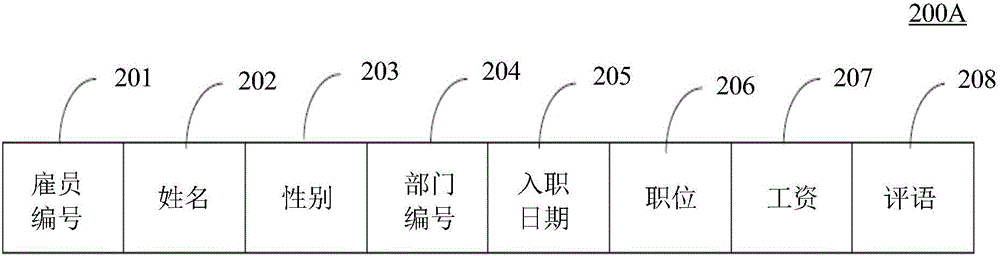
图2A是本发明实施例提供的前述定义的雇员表的行条目200A的示例性示意图。例如,雇员表包括雇员编号属性201、雇员姓名属性202、性别属性203、部门编号属性204、入职日期属性205、职位属性206、工资属性207以及评语属性208。
行存储数据库150包括行数据缓冲器153,用于将数据存储在非永久性主存储器例如RAM中。另外,行存储数据库150包括行数据文件155,可永久存储数据,如存储到磁盘中。行日志管理器(未示出)管理对行存储数据库150的更新和改变。
在一实施例中,行存储数据库150处于一致的数据库状态。即,行存储数据库150相对于当前时间点而言是最新的。例如,行存储数据库150可配置为静态的数据集合,并提供数据库内的数据快照。
另外,数据库系统100包括列存储数据库170,其包括为满足接收到的分析查询而构造的数据。列存储数据库170包括列数据缓冲器163,用于将数据存储在非永久性性主存储器例如RAM中。另外,列存储数据库170包括列数据文件165,可永久存储数据,如存储到磁盘中。列存储日志管理器167管理对列存储数据库170的更新和改变。
在列存储数据库170中,访问数据库系统100的多个查询中的任何一个引用的每个列或属性存在一个属性向量。该属性向量包括表中每个扫描记录的一对信息(例如,rowID,值)。rowID唯一标识与列存储数据库中的信息对应的相关行条目。在另一实施例中,主键用于引用行存储数据库中的行条目,主键可映射到相应的rowID。在一实施例中,值是借助于字典定义的数据的缩写/编码的内部表现形式。
根据本发明实施例,列存储数据库中的属性向量的覆盖范围是指主键值范围。即,合适的主键值范围可以用于定义任何属性向量的覆盖范围。如同rowID,主键值也可以唯一标识记录。rowID和主键之间存在一一映射的关系。例如,在以上提供的雇员表中,主键是雇员编号(EmpNo),其可以用于(例如通过映射)唯一地标识行存储数据库的行条目。每个行条目唯一对应一个不同的雇员。当分析查询需要使用表扫描操作时,即使在给定查询中未引用主键,也会构建主键列的属性向量。该属性向量提供主键值和对应的rowID之间的映射。对于涉及全表扫描操作的查询,覆盖范围仅是具有所有可能值的一个单个区间。对于涉及主键值范围的部分表扫描操作的查询,则使用覆盖该范围的记录的子集来构建引用属性的对应属性向量。
更具体地,从列存储数据库的初始状态开始,对于每个后续接收到的分析查询,将目标量数据从处于对应当前时间状态下的行存储数据库导入到列存储数据库中,以满足相应的后续接收的分析查询。查询管理器/优化器120用于确定目标量数据,如果有的话,则从行存储数据库150导入到列存储数据库170。即,所述查询管理器/优化器120用于确定执行查询的最有效的路径,包括查询所引用的数据。特别地,查询管理器/优化器120用于接收后续接收到的分析查询,例如接收到的查询的序列中的任何一个。所标识的后续接收的分析查询针对多个属性中的第一引用属性(例如,工资)的主键属性的查询范围。例如,寻求雇员编号大于8000的男性雇员的平均工资的查询可以在大于8000的主键属性(雇员编号)的查询范围内访问两个属性向量(例如,性别和工资)。
查询管理器/优化器120中的范围标识器125用于确定列存储数据库120对应的属性向量(例如,第一引用属性)关联的主键属性的覆盖范围是否在主键属性的查询范围之内或包含主键属性的查询范围。特别地,范围标识器125与列存储元数据管理器171进行通信,以访问包括元数据的状态信息的元数据。即,元数据包括与在列存储数据库170中构建的属性向量相关的状态信息。更具体地,元数据包括与列存储数据库中的每个属性向量对应的覆盖范围(例如,主键属性)。在这种方式下,查询管理器/优化器120可以确定覆盖范围是否包括满足查询的查询范围。
当存储在列存储数据库170中的针对第一引用属性的属性向量的主键属性的覆盖范围包括查询范围时,则不需要进行增强,因为列存储数据库170中包含的数据足以满足查询。即,例如,当列存储数据库包括足以满足查询的数据时,要导入的目标量数据是空的数据集合。
另一方面,当存储在列存储数据库170中的针对第一引用属性的属性向量的主键属性的覆盖范围不包括查询范围时,则增强覆盖范围以满足查询。在一实施例中,增强包括:导入包括最小量数据或恰好足够的数据的目标量数据,以支持并满足当前执行的分析查询。以查询雇员编号(EmpNo)大于8000的男性的平均工资为例,包括工资信息的属性向量可包括大于9000的雇员编号的信息。此时,覆盖范围(大于9000的雇员编号)不包括工资属性向量的查询范围(大于8000的雇员编号)。这样,使用目标数据增强工资属性向量,使得主键属性的覆盖范围包括该引用属性的主键属性的查询范围。导入到列存储数据库的目标数据包括从8000到9000的雇员编号的工资信息。更具体地,查询管理器/优化器120的数据导入器127用于从处于对应的当前时间状态下的行存储数据库150导入目标数据,以增强属性向量的覆盖范围来包含查询范围。
当引用属性的主键属性的覆盖范围为空集时,则从行存储数据库构建引用属性的属性向量。即,主键属性的查询范围的值用于构建引用属性的属性向量。
在一实施例中,目标量数据包括最小量数据,或恰好足够的数据,以支持并满足当前执行的分析查询。在一些实施例中,例如,当列存储数据库包括足以满足查询的数据时,目标量数据是空的数据集合。
图3A是本发明实施例提供的访问列存储数据库中信息的方法的流程图300A。在一实施例中,流程图300A示出了一种访问列存储数据库信息的计算机实现方法。在另一实施例中,流程图300A在计算机系统中实现,该计算机系统包括处理器以及耦合到处理器的存储器,存储器中存储有指令。如果计算机系统执行所述指令,则所述系统执行访问列存储数据库信息的方法。在又一实施例中,用于执行所述方法的指令存储在包含计算机可执行指令的非瞬时计算机可读存储介质中,所述计算机可执行指令使计算机系统执行访问列存储数据库信息的方法。在本发明一些实施例中,流程图300A的操作在图1中的数据库系统100和/或查询管理器/优化器120中实现。
在310中,所述方法包括构建存储数据的行存储数据库,所述行存储数据库的每行包括多个属性。在一实施例中,行存储数据库是真值的源。即,行存储数据库是用于构建例如列存储数据库等其他数据库的数据的源。
另外,行存储数据库中的数据的状态相对当前时间点而言是最新的。即,结合当前时间点,行存储数据库不包括在该当前时间点之后执行的信息改变(例如,INSERT/DELETE/UPDATE操作)。在一种情况下,相对当前时间点而言最新的行存储数据库是从包含给定当前时间点的最新信息的数据库生成的,并且是其子集。
在320中,所述方法包括构建列存储数据库,其包括为满足接收到的分析查询而构造的数据。列存储数据库包含表中的属性向量的集合。更具体地,访问数据库系统的多个查询中的任一个引用的每个列或属性存在一个属性向量。如前所述,属性向量包括表(例如,行存储数据库)的每个扫描记录的一对信息(例如,rowID,值;或主键,值)。图2B是本发明实施例提供的雇员表200A的工资属性的示例性属性向量200B的示意图。如包含工资的属性向量200B的信息块250所示,列中的每个条目包括标识行存储数据库中的相关行条目的rowID和表示对应雇员的工资的值。例如,在字段251中,行条目是“0001”,工资“xxx”;在字段252中,行条目是“0002”,工资“yyy”;对于字段259,行条目是“000N”,工资“zzz”。
在一实施例中,在运行时查询的扫描操作期间,动态自适应地从对应的行存储数据库中导出列存储数据库的属性向量。更具体地,在330中,所述方法包括:从列存储数据库的初始状态开始,对于每个后续接收的分析查询,将目标量数据从处于对应的当前时间状态下的行存储数据库导入到列存储数据库中,以满足后续接收的分析查询。具体地,在导入目标信息期间,对行存储数据库执行扫描操作(全表扫描或部分表扫描),从而在行存储查询行存储时,构建/增强列存储中每个被引用列的属性向量。一般来说,第一组分析查询会较慢,因为在其所需范围内的属性向量是逐步构建的。然而,不需导入目标数据,可使用列存储中的现有属性向量快速执行稍后的分析查询。下面图3B将会更充分地描述导入目标数据的过程。
图3B是本发明实施例提供的通过导入为满足执行查询的数据而动态自适应地构建列存储数据库,从而提供查询的实时分析结果的方法的流程图300B。在一实施例中,流程图300B示出了通过导入用于满足执行查询的数据来动态自适应地构建列存储数据库的计算机实现的方法。在另一实施例中,流程图300B在计算机系统中实现,所述计算机系统包括处理器和耦合到处理器的存储器,存储器中存储有指令。如果计算机系统执行所述指令,则所述系统执行通过导入用于满足执行查询的数据而动态自适应构建列存储数据库的方法。在又一实施例中,用于执行所述方法的指令存储在非瞬时性计算机可读存储介质中,该非瞬时性计算机可读存储介质具有计算机可执行指令,使得计算机系统执行通过导入用于满足执行查询的数据来动态自适应地构建列存储数据库的方法。在本发明一些实施例中,流程图300B的操作在图1中的数据库系统100和/或查询管理器/优化器120中实现。
通过实现流程图300B中概述的流程构建自适应于接收到的分析查询的列存储,以动态即时地处理该接收到的查询;并且使用恰好足够的数据来构建列存储数据库,以服务于从行存储数据库的一致数据库状态(例如,当前时间状态)导入的每个接收到的分析查询。
特别地,通过在接收和执行分析查询时实现流程图300B来自适应动态地构建/增强列存储数据库的属性向量。在350中,所述方法包括:接收第一分析查询,所述第一分析查询针对与多个属性中的第一引用属性对应的第一引用属性向量的主键属性的查询范围。第一分析查询表示接收到的用于访问行存储数据库中最初包含的数据的分析查询序列中的任一个。更具体地,第一分析查询在其执行或运行期间引用一个或多个列,以包括每个引用属性及其属性向量的主键属性的查询范围内的数据。例如,查询管理器/优化器(例如,图1中的管理器120)用于确定第一分析查询引用了哪些范围内的哪些属性向量。对于特定查询,主键属性的查询范围应用到该查询引用的每个属性向量。
在一实施例中,当运行时的查询中引用了列并且首先调用了表扫描操作来获取表记录时,构建属性向量。与不同列对应的不同属性向量可以在不同时间构建,这取决于它们在运行时的查询中被引用的时间。如果在后续查询中引用了附加范围,则可以稍后增强属性向量。
在一实施例中,对于除了主键属性外的任何接收到的分析查询中未引用的列,不需要创建对应的属性向量,并且不需要将其加载到列存储数据库中。另外,对于为满足查询范围而执行的扫描操作期间从未扫描过的数据记录(即它们不在范围断定中),这些数据记录不包括在列存储数据库的属性向量中。因此,从不会使用对任何接收到的分析查询都无用的任何数据过度构建列存储数据。与静态构建列存储(例如,ETL)相比,本发明实施例公开了自适应动态地构建列存储数据库的属性向量,更有效满足存储需求,因为没有资源用于存储在任何接收的分析查询期间未引用的数据。
在360中,所述方法包括:确定与列存储数据库中第一引用属性对应的第一引用属性向量的主键属性的覆盖范围是否在主键属性的查询范围内。例如,第一属性向量内的工资属性的覆盖范围可包含大于8000的雇员编号的信息。查询范围定义了查询请求的信息范围。例如,查询范围可针对大于9000的雇员编号(例如,主键范围)的工资信息,在这种情况下,查询范围包含在覆盖范围内。在其他情况下,查询范围可能不包含在属性向量的覆盖范围内。例如,查询范围可能针对大于5000的雇员编号的工资信息。因此,部分查询范围不包含在覆盖范围内,具体地,在5000到8000之间的雇员编号的信息是目标量数据。
在一实施例中,生成和存储元数据,其跟踪在列存储数据库中构建的属性向量及其记录或覆盖范围。流程图300B中概述的方法包括:访问元数据,其包括与列存储数据库中的每个属性向量相关的信息和与列存储数据库中的每个属性向量对应的覆盖范围(例如,主键范围),以确定引用属性向量的覆盖范围是否包含第一分析查询的查询范围。例如,查询管理器/优化器用于访问和查询元数据,以确定每个分析查询引用了哪些范围内的哪些属性向量。如果列存储数据库包含查询的整个数据集,则查询管理器/优化器用于指示查询直接访问列存储数据库。
另一方面,如果列存储数据库不包含查询的整个数据集,则查询管理器/优化器用于使用为满足查询而导入的目标数据来增强列存储数据库。更具体地,在370中,当主键属性的覆盖范围不在引用属性的引用属性向量的主键属性的查询范围内时,所述方法包括:在查询执行期间从行存储数据库导入目标量数据,增强覆盖范围,以包含查询范围满足第一分析查询。
特别地,当执行查询时,通常使用扫描算子来访问行存储数据库中的数据。当在行存储数据库上执行查询时,本发明实施例能够搭载在扫描算子执行的操作之上,以构建/增强列存储中的每个引用列的属性向量。在本发明实施例中,扫描算子执行的扫描操作可通过执行全表扫描来接触表中所有记录,或通过执行部分表扫描来接触表中部分记录。这样,可以执行全表扫描或部分表扫描来(例如,通过扫描算子),来访问导入到列存储数据库的目标量数据。
在列存储数据库中,表数据通过列保存,每列一个文件。因此,当访问一列数据时,只用进行一次磁盘I/O。当将十列的新记录添加到表时,系统需要修改列存储中的十个文件。在一实施例中,批量处理记录,以加速修改列存储数据库。
在一实施例中,更新列存储数据库中的属性向量相关的元数据来反映改变,元数据包括列存储数据库中的每个属性向量相关的信息和列存储数据库中的每个属性向量对应的覆盖范围(例如,主键范围)。特别地,更新属性向量的覆盖范围,以反映为满足查询而导入的目标量数据。
在一实施例中,一旦使用为满足第一分析查询而导入的目标量数据修改列存储,所述方法包括:将列存储数据库永久地存储到磁盘。在这种方式下,当数据库系统故障时,即使主存储器(例如,缓冲器或RAM)中存在的列存储数据库也可能故障,列存储数据库的备份也会存储在非易失性存储器中(例如磁盘),可从非易失性存储器中进行恢复。
在本发明实施例中,与后续的分析查询相比,接收的第一组分析查询将执行得较慢。这是因为新创建了属性向量并创建了覆盖范围。然而,随着接收和执行每个后续的分析查询,逐步构建列存储数据库的属性向量,稍后接收的分析查询执行地更快,因为列存储数据库中已经构建属性向量,并且可能或者可能不需要增强来满足相应查询。
全表扫描
仅为了说明目的,在先前介绍的雇员表上执行以下分析查询序列,其中,在图2A中描述行条目200A。在该示例中,将该序列中用于分析包含在雇员表或行存储数据库(例如,包含图2A中的行条目200A的数据库)内的数据的第一分析查询呈现为SQL语句,如下:“SELECT SUM(salary)FROM Employee;”。该查询针对行存储数据库中的一个或多个属性的工资属性。为了效率,如图2B所示,本发明实施例从包含工资信息的对应属性向量或列中访问工资信息。在一实施例中,进行全表扫描,以访问导入到列存储数据库中对应属性向量中的目标量数据,以满足查询。例如,为工资列构建属性向量。
继续以此为例,呈现序列中的第二分析查询,如下:“SELECT Name FROM Employee WHERE StartDate>‘mm/dd/yyyy’;”。在行存储中的入职日期列上没有次索引的情况下,查询管理器/优化器将使系统扫描整个表以获取姓名值。这样,将为姓名列构建属性向量,并包括雇员姓名属性,也会为入职日期列构建另一属性向量并包括雇员入职日期。在所呈现的序列中,在前一次查询期间构建工资属性之后,构建姓名和入职日期属性向量。该示例示出了为运行时间查询自适应即时地构建属性向量。
在一实施例中,不需要创建在接收到的分析查询中未引用的列或列的范围,并且不需要将它们加载到列存储数据库中。即,使用自适应即时的方法构建列存储数据库的属性向量以满足运行时间查询,不会使用接收的分析查询未引用或无用的列过度构建列存储数据库。例如,如果未在任何分析查询中引用,前述呈现的雇员表中的‘评语’列将不会出现在列存储中。
在一实施例中,当数据库系统使用次索引来获取记录时,不需要使用次索引访问方法来构建属性向量。即,当系统需要从行存储数据库中仅获取少量记录时,可使用次索引。这是因为当仅需少量记录时,列存储数据库不会显示良好性能优点。对于该查询,数据库系统可以直接从行存储获取记录。继续以此为例,呈现序列中的第三分析查询,如下:“SELECT*FROM Employee WHERE EmpNo=2001;”。该选择查询使用主索引从行存储数据库中仅检索一个记录(例如,雇员编号2001的),而没有进行全表扫描。在这种情况下,数据库系统直接从行存储获取记录。当执行该查询时,不需要构建/增强列存储。
部分表扫描
当构建列存储数据库中的属性向量以满足查询时,可以使用部分表扫描访问行存储数据库。出于说明目的,呈现新的查询序列来说明部分表扫描操作的使用。例如,在先前介绍的雇员表上执行如下分析查询序列,其中,图2A中描述了行条目200A。在该示例中,将该序列中用于分析包含在雇员表或行存储数据库(例如,包含图2A中的行条目200A的数据库)内的数据的第一分析查询呈现为SQL语句,如下:
SELECT EmpNo,Name,DeptNo,Title FROM Employee
WHERE EmpNo>8000;
在一实施例中,数据库系统使用主键/索引来获取记录以构建引用属性的对应属性向量,尤其是当访问大量记录时。对于上述查询,当为包含雇员编号在8000之后的信息的列导入目标量数据时,主键/索引可用于获取那些工资记录,而不是进行全表扫描。如果查询对表进行连续部分扫描,则为所扫描的那些记录构建引用属性向量或向量。即,那些属性向量是最初创建的。当执行后续查询,扫描其余记录时,可增强这些属性向量。
假设前面介绍的雇员表在行存储数据库中的主键列雇员编号上有类似B树的簇索引。例如,图4是本发明实施例提供的雇员表的B树400的示意图,其中,当自适应地构建列存储数据库中的引用属性向量时,主索引用于进行部分表扫描。第一层包括指向包含雇员标识的第二层420中的各种字段的指针。第二层中的指针提供对包含整个雇员记录的第三层中的各种字段的访问。
如图所示,主键为雇员标识,定义在第二层420的字段中。可使用合适的主键/索引引用B树400的一部分。例如,可以跟随雇员1的主索引的指针401,然后跟随指针411,获得雇员编号标识1、100和200的记录。并且,可以跟随雇员300的主索引的指针402,然后跟随指针412,获得雇员标识300、400和500的记录。进一步地,可以跟随雇员8000的主索引的指针403,然后跟随指针413,获得雇员标识8000、8100和8200的记录。
可使用部分表扫描访问引用数据,执行上述查询。首先使用8000的主键定位雇员记录,然后前向扫描以进行部分表扫描。如果这是第一次部分扫描雇员表,则为雇员编号列中大于8000的记录,创建雇员编号,姓名,部门编号和职位属性向量。元数据还保存在属性向量的可用范围和覆盖范围内。
继续以此为例,呈现序列中的第二分析查询,如下:
SELECT EmpNo,Name,DeptNo,Title FROM Employee
WHERE EmpNo>9000;
因为查询引用的大于9000的雇员编号的查询范围在大于8000的雇员编号的属性向量的覆盖范围内,所以不需要增强属性向量。这是因为覆盖范围包含查询范围。
继续以此为例,呈现序列中的第三分析查询,如下:
SELECT EmpNo,Name,DeptNo,Title FROM Employee
WHERE EmpNo>5000;
由于查询引用的大于5000的雇员编号的查询范围不在大于8000的雇员编号的属性向量的覆盖范围内,现在需要增强属性向量。这是因为查询范围是覆盖范围的超集。因此,需要使用雇员编号5000到雇员编号8000的记录来增强雇员编号的属性向量的覆盖范围。
在本发明实施例中,对于分析查询序列中未扫描的记录,如上述情况中小于5000的雇员编号的记录,不需要使用小于5000的雇员编号的记录对应的数据来构建或增强属性向量。即,在构建属性向量的覆盖范围的自适应和恰好足够的方法中,不使用任何接收的分析查询无用的或未引用的任何数据记录来构建列存储数据库。
元数据
在本发明实施例中,构建列存储数据库的自适应、即时、恰好足够的方法引用包括关于数据库中的属性向量信息的元数据。例如,元数据指示在列存储数据库中已经构建了哪些属性向量以及哪些信息范围(如主键范围)包含在这些属性向量内。因此,查询管理器/优化器用于在分析查询运行时查询元数据,以决定是否需要构建/增强引用属性向量。例如,如果列存储数据库包含查询引用的整个数据集,则查询管理器/优化器指示查询直接访问列存储。
图5是本发明实施例提供的实现用以管理元数据的示例性算法500的示图,所述元数据指示在列存储数据库中已经构建了哪些属性向量以及哪些信息范围(例如主键范围)包含在这些属性向量内。在本发明一些实施例中,分别在图1和图8的数据库系统100和/或元数据管理器171和877内部分实现算法500的操作。
假设min表示簇索引(也称为主键)的最小可能值,max表示相同簇索引的最大可能值。元数据中需要反映属性向量的所有覆盖范围(例如,主键范围)。特别地,对于每个覆盖区间i,保存两个范围点(Li,Ui),其中,Li是下限值,Ui是上限值。
SQL查询中的选择断定可分解为由OR算子连接的一个或多个不相交范围。具有连续区间的每个不相交范围可具有以下格式之一:1)范围条件(A<v)可规范地表示为(min<A<v);2)范围条件(A>v)可规范地表示为(v<A<max);3)范围条件‘(A>u)且(A<v)’可表示为(u<A<v)。
如果包括整个表格范围,则覆盖区间的范围(例如,主键范围)设置为(min,max)。当覆盖整个表时,则应及早退出确定和存储元数据的过程,因为不会再改变覆盖区间。
算法500的条件包括:合并簇索引A上的查询范围断定LA<A<UA和已经覆盖的范围(例如,主键范围)。另一条件包括通过INCL指示是否包括LA。即,当INCL为真,单侧范围条件为LA<=A;否则,LA<A。又一个条件包括通过INCU来指示是否包括UA。另一个条件包括通过min来表示表中最小可能主键值,通过max表示表中最大可能主键值。又一个条件包括:对于元数据中的覆盖区间,定义Li为区间i的下限,定义Ui为覆盖区间i的上限。
如算法500所示,所有不相交的覆盖区间(例如,主键范围)的下限和上限都是按照以下属性顺序排列:L1<U1<L2<U2<L3<U3<…。大多数情况下,不期待在后续查询快速执行前,使用很多执行查询的区间来充分构建列存储数据库的属性向量。期待的是列的覆盖区间可以快速合并到一个区间(min,min)。一旦(min,max)覆盖整个列,则不再改变给定列或属性向量的元数据。因此,在一实施例中,简单的一维数组(或向量)足以包含覆盖区间的所有限值。在存在许多覆盖区间的情况下,可以使用二叉树,例如AVL-tree,来包含所有下限/上限值,以便可以快速定位查询范围断定的LA和UA。
图6A至图6F是本发明实施例提供的比较属性向量的覆盖区间(例如,主键范围)与查询范围的各种示例的示意图。
如图6A所示,对于情况1,属性向量600包括在min和max之间的范围(例如,主键范围)内的信息。覆盖范围包括区间1,其下限为L1、上限为U1。覆盖范围还包括区间2,其下限为L2、上限为U2。覆盖范围还包括区间3,其下限为L3、上限为U3。在情况1中,查询范围的下限为LA,上限为UA。因为查询范围完全包含在区间1中,所以不改变元数据,且无需导入额外数据,属性向量600就足以满足该查询。
如图6B所示,对于情况2,现在查询范围(LA,UA)与区间1重叠,使得覆盖范围不足以包含查询范围。例如,查询范围的下限LA在区间1内,而上限UA在区间1至3中任一个之外的未覆盖空间中。当查询运行时,使用增强区域610中的范围(U1,UA)中的记录来增强属性向量600。在元数据中,区间1的边界修改为新形成的连续区间(L1,UA)。即,区间1的上限修改为UA。
如图6C所示,对于情况3,查询范围(LA,UA)与两个区间重叠:区间1和区间2。查询范围的下限LA在区间1内,而上限UA在区间2内。当查询运行时,使用增强区620中的范围(U1,L2)内的记录来增强属性向量600。在元数据中,将区间1和区间2替换为范围为(L1,U2)的新连续区间。例如,区间1的上限可修改为U2,而将区间2擦除。同样有效地,区间2的下限可修改为L1,而将区间1擦除。
如图6D所示,对于情况4,如增强区630所示,查询范围完全在单个未覆盖的区间中。当查询运行时,使用增强区630中所示的范围(LA,UA)内的记录增强属性向量600。元数据包括范围为(LA,UA)的新区间4。
如图6E所示,对于情况5,查询范围(LA,UA)完全覆盖区间2。然而,下限LA和上限UA在不同的未覆盖区间中。例如,下限LA在区间1和区间2之间,上限UA在区间2和区间3之间。当查询运行时,使用增强区640中的范围(LA,L2)内的记录和增强区650中的范围(U2,UA)内的记录来增强属性向量600。在元数据中,将区间2替换为范围为(LA,UA)的新区间。
如图6F所示,对于情况6,下限LA在区间1和区间2之间的未覆盖区间中,上限UA在覆盖区间3中。当查询运行时,使用增强区660中的范围(LA,L2)内的记录和增强区670中的范围(U2,L3)内的记录来增强属性向量600。在元数据中,将区间2和区间3合并,并替换为范围为(LA,U3)的连续区间。例如,区间2的下限和上限可修改为(LA,U3),而将区间3擦除。同样有效地,区间3的下限和上限可修改为(LA,U3),而将区间2擦除。
图7是本发明实施例提供的通过导入目的为满足执行查询的数据,动态自适应地构建列存储数据库的统一建模语言(Unified Modeling Language,UML)序列图700的示意图。仅出于说明目的,通过执行样本查询来描述UML序列图700,如下:“SELECT DeptNo,SUM(salary)FROM Employee GROUP BY DeptNo;”。SELECT语句要求对每个部门员工的工资求和。如图7所示,当执行SELECT语句时,在组件之间按时间顺序安排各种交互。
在操作705中,查询管理器790接收查询或SELECT语句。查询管理器790管理构建列存储数据库和访问列存储数据库中的数据的过程,以处理查询并获得结果。在操作710中,从列元数据793(例如,从列日志文件中)获取列存储数据库中的属性向量的覆盖范围/区间(例如,主键范围),并返回到查询管理器790。在操作715中,查询管理器790比较覆盖区间和查询范围/区间,以确定是否需要创建属性向量或增强覆盖范围。如果需要增强属性向量,则查询管理器790执行并管理略图701中定义的流程。否则,属性向量的覆盖范围足以满足查询,在操作770中,从列数据缓冲器794获取列数据,或者在771中,从列数据文件795(例如,磁盘)获取,并返回至列数据缓冲器794。在操作775中,返回列数据至查询管理器790,以处理查询。
查询管理器/优化器790用于使用表扫描算子来获取查询引用的所有雇员记录,以计算结果。当需要创建或增强属性向量时,执行略图701中的操作。在操作720中,从行数据缓冲器791获取未覆盖区间(例如,主键范围)内的数据。如果缓冲器791不包含该数据,则在操作725中,从行数据文件792获取未覆盖区间中的数据,并在操作730中,将其返回到行数据缓冲器791。在735中,将未覆盖区间中检索的数据(例如,目标量数据)传送到列数据缓冲器794。在操作740中,提交所应用的改变,并报告给列日志管理器796。另外,在操作745中,保存属性向量及其对应的元数据至磁盘。在提交改变之后,在操作750中,返回函数调用至行数据缓冲器,在操作755中,返回另一函数调用至查询管理器790。在操作760中,查询管理器合并更新列元数据793,以反映改变,返回函数调用765至查询管理器790。在这种方式下,查询管理器790理解可使用列存储数据库处理查询。继续该流程,以在操作770中,从列数据缓冲器794中获取列数据,或当数据不在存储器中,在771中,从列数据文件795(例如,磁盘)中获取列数据,并返回至列数据缓冲器794。在操作775中,返回列数据至查询管理器790以处理查询。
在一实施例中,应该在一个事务中完成更新属性向量及其元数据,从而保持元数据的内容与对应的属性向量一致。应注意,在一实施例中,内部构建列存储及其元数据,以加快分析查询。即,它们对终端用户是透明的。这样,终端用户仅接触行存储数据库中定义的表模式。
基于查询需求从行存储数据库自适应地构建和更新列存储数据库
图1至7中描述的本发明实施例公开了响应于接收到的分析查询从行存储数据库动态自适应地构建列存储数据库的属性向量的方法和系统,所述行存储数据库处于一致的或当前时间状态。图8至15中描述的本发明其他实施例公开了在保持行存储数据库处于一致的或最新状态的同时,响应于接收到的分析查询从行存储数据库动态自适应地构建和更新列存储数据库的属性向量的方法和系统。
图8是本发明实施例提供的包括行存储数据库150和列存储数据库870的数据库系统800的框图,其中构建和更新所述列存储数据库870以响应于执行分析查询。数据库系统800包括先前描述的与图1中的数据库系统100相关的组件,其中编号类似的部件具有类似功能。特别地,针对执行的分析查询动态自适应性地构建所述列存储数据库870。在行存储数据库上实施通常使用的扫描操作(全表扫描或部分表扫描),以在对行存储数据库执行查询时构建/增强列存储中的每个引用列的属性向量。进一步地,当引用属性向量及其覆盖区间由查询使用时,最近提交的改变需要被包括在列内,以便显示实时的数据内容。具体地,当将改变提交到行存储数据库时,不会立即更新列存储数据库的内容以反映这些改变,因此列存储数据不会与行存储数据实时同步。相反,本发明实施例基于运行时的分析查询通过刷新列存储数据来动态自适应地更新列存储数据库。
如图8所示,数据库系统800包括行存储数据库150,其中每行包括多个属性。行存储数据库150是真值的源,因此行存储数据库150中的数据存储真值。在一实施例中,行存储数据库始终保持数据一致性,因此行存储数据库是最新的。
如前介绍的示例中所示,行存储数据库150可以定义为包括八个属性的雇员表,该表是记录的集合。为了说明,雇员表可以包括与公司的雇员相关的信息,将该信息定义为属性,以包括雇员编号,姓名,性别,部门编号,入职日期,职位,工资和评语。
如前所述,行存储数据库包括用于以非永久性方式存储数据的行存储数据缓冲器153和用于以永久性方式存储数据例如将数据存储到磁盘的行存储数据文件155。行存储日志管理器151通过控制通过行存储数据缓冲器153和行存储数据文件155的数据流来管理对行存储数据库150的更新和改变。另外,根据查询/事务管理器820的指示,行存储日志管理器151用于管理改变事务的确定和该改变事务向迁移缓冲器850的迁移,以便稍后用于更新列存储数据库以响应接收分析查询,被迁移的改变事务针对所述列存储数据库中的现有列。
另外,数据库系统800包括列存储数据库870,其包括为满足接收到的分析查询而构造的数据。列存储数据库包括用于以非永久性状态存储数据(例如,将数据存储到主存储器)的列存储数据缓冲器873和用于以永久性状态存储数据(例如,将数据存储到磁盘)的列存储数据文件875。列存储器日志管理器871通过控制通过列存储数据缓冲器873和列存储数据文件875的数据流来管理对列存储数据库870的更新和改变。同样,列存储元数据管理器877管理元数据信息,例如已经构建了哪些属性向量,各种属性向量的覆盖范围,以及同步点等。
列存储数据库包括多个属性向量,其中每个属性向量包括行存储数据库中的对应属性的条目。例如,属性向量的每个条目对应于行表的扫描记录,并且包括一对信息(例如,RowID,值),其中RowID对应于相关行条目,值是数据的缩写/编码内部表现形式。如前所述,主键用于引用行存储数据库中的行条目,并且可映射到对应的RowID。此外,多个属性向量中的每一个包括存储的用于满足多个先前接收到的分析查询中的至少一个的数据。
查询/事务管理器820用于接收针对行存储数据库的多个改变事务(例如,插入/删除/更新)。每个改变事务是有序的,例如将改变事务与对应的日志序列号(log sequence number,LSN)相关联。在一实施例中,行存储数据库150的排序或日志序列信息用于将改变数据迁移到列存储数据库870。因此,改变事务与LSN相关联,该LSN提供数据库系统800上执行的操作/事务和/或查询的时间戳或顺序排序机制。重要的是,查询/事务管理器820用于基于与针对第一属性向量中的属性的改变事务对应的日志信息来更新第一分析查询引用的第一引用属性对应的第一属性向量,以满足第一分析查询。
特别地,查询/事务管理器820用于管理改变事务的执行,并在改变事务执行期间管理数据到行存储数据库150内的存储。特别地,查询/事务管理器820包括用于在行存储数据库上执行多个改变事务的执行管理器823。
另外,查询/事务管理器820还用于随着随后接收到的分析查询的执行来管理数据到列存储数据库的迁移。因此,列存储数据库870内的数据用于满足先前接收到的查询。具体地,在分析查询处理期间的最后一刻使用日志改变数据来更新列存储数据库870,使得列存储数据库在处理分析查询的最后一刻实现数据一致性(以匹配给定查询中引用的列存储数据库中的所有列的行存储数据库的状态)。这是在两阶段迁移过程中迁移改变。
在迁移过程的阶段1中,查询/事务管理器820中的列存储引用管理器825用于从接收到的针对存储在列存储数据库中的多个属性向量中的属性的多个改变事务中确定改变事务的子集。即,在阶段1中,识别行存储器日志信息的合适子集以用于迁移。提取日志信息的子集并将其导入到迁移缓冲器850,该日志信息对应于改变事务的子集。在一实施例中,在迁移缓冲器空间耗尽的情况下,将迁移缓冲器850内的数据写入迁移文件855以用于永久性存储。
从在行存储数据库上执行的多个改变事务中确定出的改变事务的子集在进行迁移时满足三个条件。第一个条件是子集内的改变事务针对列存储数据库中的现有列或属性向量。第二个条件是子集内的每个改变事务针对列存储数据库中对应的且现有的列或属性向量的覆盖区间(例如,主键范围)。第三个条件是每个改变事务都是已提交事务。
执行阶段1对OLTP性能的影响应当最小,因为其仅将行存储中的日志改变数据的子集复制到与列存储数据库相关联的迁移缓冲器。因此,没有为行存储数据库提交过程引入额外的磁盘I/O。阶段1操作在插入/删除/更新事务期间发生。
查询/事务管理器820用于接收针对多个属性中的第一引用属性的第一分析查询。例如,示例性查询可以寻求公司中的男性人数,因此其针对性别属性。即,通过访问与性别属性对应的引用属性向量中的值,可以执行查询以呈现结果。理解的是,第一引用属性对应于列存储数据库870中的第一属性向量(包含从行存储条目迁移的第一属性值)。
查询/事务管理器820还包括列存储数据库迁移管理器827,用于基于与针对第一引用属性的改变事务对应的日志数据来更新第一属性向量。对列存储数据库执行两阶段更新过程以满足第一分析查询,使得在查询执行期间列存储数据库中的数据与行存储数据库150中的数据一致。在第一阶段中,迁移管理器827自身或通过指示行存储日志管理器151来处理所选择的改变事务的行存储日志数据向迁移缓冲器的迁移,以便稍后更新列存储数据库870。当在分析查询运行时,由迁移管理器827执行第二个阶段,以将保存在迁移缓冲器中的增量/改变应用到列存储数据库870的引用属性向量。
图9是本发明实施例提供的通过将目标量数据导入到引用属性向量来动态自适应地更新列存储数据库,从而提供实时分析结果以满足分析查询的方法的流程图900。在一实施例中,流程图900示出了通过将目标量数据导入到引用属性向量来动态自适应地更新列存储数据库,从而提供实时分析结果以满足分析查询的计算机实现的方法。在另一实施例中,流程图900在计算机系统内实现,该计算机系统包括处理器以及耦合到处理器并且其中存储有指令的存储器,如果该指令由计算机系统执行,则使得系统执行通过将目标量数据导入到引用属性向量来动态自适应地更新列存储数据库,从而提供实时分析结果以满足分析查询的方法。在又一实施例中,用于执行所述方法的指令存储在非瞬时性计算机可读存储介质上,该非瞬时性计算机可读存储介质具有用于进行以下操作的计算机可执行指令:通过将目标量数据导入到引用属性向量来动态自适应地更新列存储数据库,从而提供实时分析结果以满足分析查询。在本发明一些实施例中,流程图900中的操作分别在图1和图8中的数据库系统100和/或数据库系统800内实现。
实施流程图900中公开的操作,以使用即时和恰好足够的方法来从行存储数据库动态地构建和更新列存储数据库。当处理针对引用属性的查询时,更新列存储数据库中的对应属性向量以包括保存在迁移缓冲器中的最近提交的改变数据,以便显示实时的数据内容。即,当将改变提交到行存储数据库时,不会立即更新对应的列存储数据库来反映那些改变,使得该列存储数据不与行存储数据实时同步。相反,改变数据首先保存在迁移缓冲器中,然后基于后续运行时的查询需求更新列存储数据库。
流程图900中公开的操作通常包括:构建用于存储数据的行存储数据库,所述行存储数据库行包括多个属性;构建列存储数据库,其包括为满足接收到的分析查询而构造的数据,所述列存储数据库包括与所述行存储数据库中的至少一个属性对应的多个属性向量,所述多个属性向量中的每一个包括用于满足多个先前接收到的分析查询中的至少一个的数据;接收针对所述行存储数据库的多个改变事务,所述多个改变事务中的每一个都是有序的;当第一分析查询引用的第一引用属性对应于列存储数据库中的第一属性向量时,基于与针对所述第一引用属性的改变事务对应的日志信息来更新第一属性向量,以满足所述第一分析查询。下面更详细地描述流程图900。
在905中,所述方法包括:构建用于存储数据的行存储数据库,所述行存储数据库行包括多个属性。行存储数据库是可以构建例如列存储数据库的其他数据库的数据源。在一实施例中,行存储数据库始终保持数据一致性,使得行存储数据库是最新的。另外,行存储数据库中的属性与行条目/记录中的字段相关联。例如,属性可以是先前介绍的雇员表中的雇员信息(例如,雇员编号,工资等),该表是记录的集合。
在910中,所述方法包括:构建列存储数据库,其包括为满足接收到的分析查询而构造的数据。即,列存储数据库包括为满足先前接收到的查询而选择和存储的数据。具体地,列存储数据库包括多个属性向量,每个属性向量对应于行存储数据库中的属性。因此,每个属性向量对应于列存储数据库中的列,并且包括来自行存储数据库中的一个或多个行条目的对应属性的值。此外,多个属性向量中的每一个包括用于满足多个先前接收到的分析查询中的至少一个的数据。
在915中,所述方法包括:接收针对所述行存储数据库的多个改变事务,所述多个改变事务中的每一个都是有序的。在一实施例中,为了对数据库内的操作和事务进行排序,每个改变事务与对应的日志序列号(log sequence number,LSN)相关联。
在一实施例中,从数据库系统的初始状态下开始存储改变事务。由于改变事务是有序的,因此可以基于引用列来为查询确定相关改变事务,该相关改变事务用于在查询运行时更新列存储数据库。例如,从引用属性向量的最后一个同步点开始的改变事务用于更新。在另一实施例中,在迁移缓冲器中仅识别从最后一个同步点开始的改变事务,因此所存储的改变事务用于更新。
另外,在行存储数据库上执行多个改变事务。在一实施例中,实时地执行改变事务,使得行存储数据库是最新的且反映最新信息。在这种方式下,行存储数据库是信息引用时的真值来源。
在920中,所述方法包括:确定从多个改变事务中获取的改变事务的子集,该子集中的改变事务针对存储在多个属性向量内的值或属性。具体地,在920中,公开了从行存储到列存储迁移改变的第一阶段(也称为“阶段1”),所述行存储中的事务日志用于将改变迁移到迁移缓冲器,以便在稍后运行查询时读入列存储。在一实施例中,第一阶段可以由图8中的查询/事务管理器820执行。在另一实施例中,行存储日志管理器151在查询/事务管理器820的请求下执行迁移的第一阶段。结合图11和图12更详细地描述了第一阶段。
满足以下条件中的每一个的改变事务可以被存储并用于更新列存储数据库。首先,当改变事务针对现有属性向量时,更具体地,当改变事务正在列存储数据库中的现有属性向量中的条目上运行时,选择该改变事务作为子集的一部分。第二,为了作为子集的一部分,改变事务必须针对现有属性向量的覆盖范围内的数据。例如,改变事务正在属性向量的主键的覆盖范围内的条目上运行。第三,为了作为子集的一部分,改变事务必须是已提交事务,使得事务已经记录其在行存储数据库和/或日志文件中的所有改变。
在925中,所述方法包括:存储对应于改变事务的子集的日志数据或元数据。尽管可以从行存储数据库构建属性向量,但此过程是繁重且低效的,尤其是当包含许多记录的大表只有少量改变时。本发明实施例利用了行存储数据库中记录了对行存储数据库的所有改变的事务日志。在许多数据库系统中,事务日志管理器经常使用“预写日志”协议。在此协议中,改变事务不能提交,直到其已将其所有改变记录到磁盘上的对应日志文件。另外,可以将日志记录添加到日志页面缓冲器,当事务提交时,该日志记录永久性地保存到磁盘。在事务提交后,可以将表数据的改变写入磁盘。
例如,出于说明目的,行存储数据库的日志文件1000可以包括图10中提供的条目,图10是本发明实施例提供的引用列存储数据库中的至少一个属性向量的显式改变事务1029的示意图。日志文件1000中所列出的条目可以应用到标识为“txn 1029”的单个改变事务,但包括多个数据语句,例如附加的INSERT语句。为txn 1029分配多个LSN 1-4。LSN 1指示txn 1029的开始,LSN 4指示txn 1029的结束。具体地,改变事务1029包括两个INSERT语句,其中第一INSERT语句LSN 2将现有的和/或新的雇员记录的信息插入到雇员表中。例如,INSERT语句LSN 2插入包括雇员编号(9051)的值,姓名(John Smith),性别(M)等八列的值。第二INSERT语句LSN 3将现有的和/或新的部门记录的信息插入到部门表中。例如,INSERT语句LSN 3插入包括部门编号101的值和软件工程的部门名称等至少两列的值。
出于说明目的,日志数据可以包括改变事务的LSN,改变事务,条目的前图像,条目的后图像等。然而,读取行存储的日志文件以找到增量改变并增加到列存储是不希望的,因为日志文件上用于读取访问的顺序写操作的中断可能会重新定位磁盘读/写磁头,这可能导致读和写的更长的磁盘访问时间。相反,本发明实施例不会在查询运行时中断对行存储的日志文件的顺序写入操作,而是将对应于改变事务的那些日志数据迁移到迁移缓冲器,以便用于后续接收到的查询执行时的后续访问。
在930中,所述方法包括:接收针对多个属性中的第一引用属性的第一分析查询。查询可以引用不止一个属性,并且在这种情况下,使用流程图900来更新用于单独更新与引用属性之一相关联的每个属性向量的过程。
在935中,所述方法包括:基于与针对第一属性向量中的条目的改变事务对应的日志数据来更新与第一引用属性相关联的第一属性向量,以满足第一分析查询。这描述了实现用以将改变移动到列存储数据库中的属性向量的迁移的第二阶段。即,当现有属性向量与第一引用属性相关联时,使用适当的改变事务的日志数据来更新属性向量。当分析查询正在运行时,动态自适应地构建和更新列存储。结合图11和图13更详细地描述了第二阶段。
在实施例中,流程图900中概述的方法可选地返回到905和/或图14A和图15中的流程图1400A和1500中分别使用的连接点A或B。在这种方式下,可以出于更新列存储数据库的目的以任何方式组合MRC和MAC迁移技术。例如,任何配置形式的MRC和MAC迁移技术的组合公开了迁移混合迁移技术。
先前,为列存储数据库收集的元数据指示已经构建了哪些属性向量,以及在那些属性向量内覆盖了什么信息的记录范围(例如,主键范围)。因此,可以在分析查询运行时(例如由查询/事务管理器820)查询元数据,以决定是否需要构建/增强引用属性向量。此外,列存储数据库的元数据可以在系统崩溃的情况下永久性地存储到磁盘。在一实施例中,由于经常引用元数据,因此也应将元数据缓存在存储器缓冲器中以便快速访问。
另外,在本发明实施例中,元数据包括已经应用了增量的属性向量的特定点。即,在行存储数据库的日志文件中,为每个日志条目收集LSN,所述LSN是显示每个日志条目的序列号的单调增加的数字。在查询运行时迁移缓冲器中向行存储数据库已提交的事务的最新LSN用于表示对于列存储数据库中的对应属性向量已经被迁移到该点的改变。直到该点,列存储数据库中的信息与行存储数据库同步。将作为新的和/或更新的同步点的最新LSN保存为列存储数据库的元数据。
因此,流程图900中的935中的更新过程包括:确定第一属性向量的同步点。同步点指示第一属性向量最后更新到哪个时间点或其他排序序列中的哪一点。例如,同步点与LSN相关联,并且指示在列存储数据库的第一属性向量上执行的最后一个改变事务。因此,通过包括在该LSN之后提交的改变事务,第一属性向量将与行存储数据库实时同步。
因此,当已经为某个列构建了第一属性向量,并且还覆盖了(例如,主键的)引用范围时,则更新包括:并入来自最后一次访问或最后一个同步点的所有改变或增量。如前所述,这包括:在同步点之后访问对应于改变事务的日志数据,被访问的日志数据针对第一属性向量中的第一属性。在一实施例中,日志数据包括可直接用于更新第一属性向量中的对应条目的后图像信息。例如,后图像包括第一属性向量中的对应条目的值的快照。
另外,在首次构建属性向量时,或者在通过扩展到一些未覆盖区间来改变覆盖区间(例如,主键)时,将最新的LSN保存到元数据。对于这两种情况,不使用改变事务的日志数据,而是在不查看行存储数据库的日志数据的情况下直接从行存储获取最新的表记录。最新的LSN或同步点快速指示直到什么时候数据会当前用于特定属性向量的该属性向量的覆盖区间。
此外,在另一实施例中,可以采取附加步骤来构建或增强由查询引用的属性向量的覆盖范围。如前面图3A-3B中所述,使用扫描算子来执行行存储数据库的全表扫描或部分表扫描,以在对行存储数据库执行查询时构建或增强列存储数据库中的每个引用列的属性向量。即,当属性向量的覆盖范围(例如,主键)不包含由查询引用的属性向量的查询范围时,在查询运行时自适应地构建和/或增强该属性向量。例如,当第一引用属性不与列存储数据库中的任何属性向量对应时,构建与第一引用属性对应的属性向量。特别地,确定属性的查询范围,第一分析查询针对查询范围,查询范围内的第一属性的值直接从行存储数据库中的对应条目导入。
对列存储数据库的改变的两阶段迁移
如前所述,实施两阶段操作以在查询运行时将对行存储数据库所作的改变迁移到对应的列存储数据库。图11是本发明实施例提供的包括与引用列存储数据库中的属性向量的改变事务对应的日志信息的流的两阶段操作的数据流程图。
如图11所示,改变事务应用到行存储数据库1105。特别地,将对应于改变事务的改变存储在数据库缓冲器1110中。这些改变也应用到存储在包括一个或多个易失性(例如,主存储器或RAM)或非易失性(例如,永久性)存储器的磁盘1130中的数据记录。另外,还生成与改变相关的信息并将其存储在日志文件/记录中。在一实施例中,与存储器页面相关联地生成日志文件/记录,其是虚拟存储器的固定长度的连续块的最小单元。当将事务提交到行存储数据库1105时,将日志文件/记录添加到日志页面缓冲器1120,并且永久性地存储到磁盘1140。在一实施例中,当将改变记录到磁盘1140上的日志文件/记录时,事务已经提交。
在第一阶段,列存储数据库1150从行存储数据库1105导出,其中行存储数据库1105充当真值源。在一实施例中,“预写协议”用于将相关改变迁移到列存储数据库1150。具体地,单独的迁移缓冲器1155将所有改变保持在存储器中,这些改变稍后应用到列存储数据库1150。如前所述,在第一阶段中,不是所有存储在日志页缓冲器1120中的信息都被复制到迁移缓冲器1155。相反,在行存储数据库1105的事务提交操作中,提取改变和/或改变事务的子集并将其迁移到迁移缓冲器1155,如前所述并简要总结,改变满足以下三个条件:(1)已经构建好属性向量的列;(2)改变处于覆盖区间内;(3)已提交事务中的改变。未提交的改变(或稍后中止的改变)将会跳过。如前所述,图8中的查询/事务管理器820内的列存储数据库迁移管理器827用于基于日志记录/文件数据来确定哪些改变事务针对列存储数据库中的现有属性向量。例如,将日志记录/文件中列出的列标识与列元数据进行匹配,该元数据指示列存储数据库中存在哪些范围内的哪些属性向量。
添加到列存储数据库1150的迁移缓冲器1155的改变包括在日志记录/文件中,该日志记录/文件包括给定列的例如表ID,列ID和后图像等信息,使得系统可以适当地将改变应用到对应属性向量。图12是本发明实施例提供的行存储数据库的行存储日志数据/信息格式的示意图,其中日志条目1200中的日志信息与引用列存储数据库中的至少一个属性向量的改变事务对应。例如,改变事务可以与图10中的txn 1029相关联。出于说明目的,日志条目1200包括块1201中的用于在事务1029内的改变操作的LSN信息,该事务1029在块1202中存储为事务ID(例如,txn 1029)。例如,改变操作是具有LSN 2的插入雇员记录语句。日志条目1200包括块1203中的表ID(例如,参考上述雇员表)。事务ID允许将多个语句组合在一起,例如两个不同表(例如,雇员表和部门表)的两个INSERT语句。另外,一个或多个块1204A-N中每个包括一对列ID/值信息,对应的列ID指示行存储数据库中的哪一列以及列存储数据库中的相关属性向量/列与改变事务相关联。块1204A-N中的任何一个的列ID/值对中的对应值可以包括在更新期间存储的记录的后图像。如图所示,第一阶段发生在插入/删除/更新事务期间。
不会将不具有对应属性向量或不是为对应属性向量中的条目所作的那些列的改变迁移到列存储数据库1150的迁移缓冲器1155。这是因为,当在查询的扫描操作中首次引用列时,直接从行存储数据库1105中的表记录构建对应属性向量。表记录将包含最新内容,因此改变信息没必要迁移因为它将是多余的。
在另一种情况下,即使存在并构建了列的属性向量,也不会迁移对未覆盖范围/区间所作的改变。稍后,当查询引用未覆盖区间中的那些列值时,通过直接从行存储数据库1105中的表记录中获取列数据来增强属性向量。例如,如图3A-AB中先前所述,使用扫描算子来执行行存储数据库的全表扫描或部分表扫描,以在对行存储数据库执行查询时构建或增强列存储数据库中的每个引用列的属性向量。
迁移的第一阶段对OLTP性能的影响应当最小,因为仅将来自行存储数据库1105的日志缓冲器1120到列存储数据库1150的迁移缓冲器1155的子集信息复制到存储器。因此,在行存储数据库1105的提交过程中没有引入额外的盘I/O。此外,列存储1150维护自己的日志缓冲器1155和日志文件以处理其包括改变的日志信息。
先前介绍的雇员表用于说明第一和第二阶段的迁移过程。雇员表包括雇员编号(EmpNo);雇员姓名(Name);性别(Gender);部门编号(DeptNo);入职日期(StartDate);职位(DeptNo);工资(Salary)以及评语的属性。另外,对应的列存储数据库包括在最后接收到的分析查询之后的列雇员编号,姓名,部门编号,入职日期和工资的五个属性向量。
以下INSERT语句将新记录插入到行存储数据库的雇员表中。
INSERT Employee VALUES(9051,‘John Smith’,‘M’,201,‘01/02/2014’,‘Engineer’,90000.00,‘First employee in year 2014’);
在行存储数据库的事务提交期间,将新记录的改变复制到具有已经构建的属性向量的五个引用列的迁移缓冲器中,并且该改变针对各自的覆盖范围或区间。
图13A是本发明实施例提供的在更新列存储数据库的第一阶段期间的数据流的统一建模语言(Unified Modeling Language,UML)序列图1300A,该更新涉及存储与引用以上列出的INSERT语句的列存储数据库中的属性向量的改变事务对应的日志信息。在1301中,INSERT语句由请求将八个属性值插入到行存储数据库的事务管理器1350接收。在1305中,将新记录输入到行存储数据库,更具体地,输入到与行存储数据库相关联的行数据缓冲器1351(例如,非永久性主存储器)。在1310中,将针对雇员表中的八个属性中的每一个的后图像写入与行存储数据库相关联的行日志缓冲器1353(例如,主存储器)。稍后,在1315中,将结束事务写入磁盘,更具体地,写入与行存储数据库相关联的行日志缓冲器1353(例如,主存储器)。此时,事务已提交到行存储数据库。另外,到目前为止,所有操作都与改变行存储数据库一致。
在迁移到列存储数据库的第一阶段中,在1320中,(例如,由查询/事务管理器和/或行存储器日志管理器)迁移与列存储数据库中的列相关联的五个属性向量的改变信息。即,从行日志缓冲器1353获得满足先前介绍的条件的改变子集的日志信息,并且将其迁移到与列存储数据库相关联的迁移缓冲器1355。在1325中,将函数调用返回到行日志缓冲器1353,并且通知行日志缓冲器1353日志信息向迁移缓冲器1355的迁移完成。
进而,返回到对行存储数据库进行改变,在1330中,行日志缓冲器1353将结束事务写入与行存储数据库相关联的行日志文件1354。日志文件1354可以是永久性的。在1335和1340中,函数调用返回到行日志缓冲器1353和事务管理器1350,使得事务管理器1350知道事务何时已经提交。之后,在1345中,从事务管理器1350向行数据缓冲器发送指令以清空数据。在1347中,从行数据缓冲器1351清空数据并将其写入行数据文件1352。在一种情况下,将行数据文件1352永久性地存储到磁盘。此时,行存储数据库的改变事务完成。
当查询运行时,迁移的第二阶段开始将改变数据应用到查询引用的对应属性向量。公开了三种不同的迁移技术用于基于何时应用多少量的改变将改变迁移到列存储数据库。在三种技术中的任一种中,在第二阶段中,将在某点迁移到迁移缓冲器的改变数据应用到列存储数据库的属性向量。第一种迁移技术称为只迁移引用列(Migrate Referenced Columns Only,MRC)。第二种迁移技术称为迁移所有列(Migrate All Columns,MAC)。第三种迁移技术是MRC和MAC迁移技术的混合。
迁移引用列(Migrate Referenced Columns,MRC)
其核心意思是,至少将改变应用到查询引用的属性向量。特别地,在MRC中,从迁移到对应属性向量的最后一个已提交事务开始只迁移对于给定查询中引用的那些列的属性向量的改变。具体地,对于引用列,从迁移文件中的元数据确定列的改变的最后一个提交的LSN。此时,从最后一个提交的LSN的改变事务开始,MRC向前扫描以定位已提交的针对行存储数据库的改变,并将这些改变应用到与给定引用列对应的属性向量。将这些未迁移但已提交的改变存储在列存储数据库的迁移缓冲器中。在MRC中,对引用列以外的列所作的所有改变都将被忽略。例如,先前结合图9引入了MRC。
在MRC中,将给定引用列Ci的新LSNi或同步点保存到其对应的元数据中,以供将来引用。因此,每个属性向量具有各自的保存在元数据中的LSN。此外,可以针对每个引用列扫描一次列存储数据库的迁移文件。因此,如果有多个引用列,则可能扫描列存储数据库的迁移文件一次,并根据表ID和列ID对其进行排序。排序后,每个引用列可以使用一个线程将改变迁移到对应属性向量。在这种方式下,可以并行迁移任务以加速操作。
在一实施例中,MRC可用于批量式地对给定列进行许多改变,并在单个批次中执行改变。另外,MRC高度保持“即时”和“恰好足够”的精神。
继续使用结合图13A提供的示例,在INSERT语句之后,接收分析查询,如下:
SELECT DeptNo,SUM(salary)FROM Employee GROUP BY DeptNo;
使用MRC技术,将部门编号和工资列的改变迁移到其对应的属性向量,以满足查询。对例如雇员编号,姓名和入职日期等未引用列执行的其他改变将会跳过。
在上述SELECT查询之后,在MRC中,整个列存储不处于一致的数据库状态,因为一些属性向量将接收和更新最新改变,而其他属性向量将不会。但是,查询的引用列处于一致的状态,并与行存储数据库同步。因此,针对上述查询动态地构建并且即时自适应地更新引用列或属性向量,因为更新它们的内容是为了示出呈现查询结果之前对行存储进行的最新改变。
图13B是本发明实施例提供的在使用MRC更新列存储数据库的第二阶段期间的数据流的UML序列图1300B,并且涉及针对上面列出的SELECT语句,使用与引用列存储数据库中的属性向量的改变事务对应的日志信息。根据本发明实施例,所应用的改变对应于阶段一中的先前存储的改变事务。
在1370中,SELECT查询由查询/事务管理器1350接收。在1373中,从每个引用属性向量的列元数据中获取与最后一个同步点对应的LSN。即,在MRC中,对于每个属性向量独立地生成同步点,因此,不同的属性向量可以具有不同的同步点。在1375中,同步点的LSN用于确定需要为给定属性向量获取哪些改变。具体地,从对应的属性向量的同步点开始从迁移缓冲器1355中获取改变。在实现中,改变具有比同步点的LSN更高的LSN。如前所述,改变可以是在最后一个同步点存储在属性向量的条目中的后图像。
在1377中,如果(例如,由于溢出)改变不位于迁移缓冲器中,则可选地从迁移文件1358(例如,永久性存储器)中获取存储器中的改变。在1379中,读取改变并将其存储回迁移缓冲器1355中用于处理。
特别地,所获取的改变应用到列存储数据库。即,在1381中,将部门编号和工资列的改变存储到列数据缓冲器1359。
在1383中,将列元数据1356中的LSN或同步点更新为最近的LSN,例如最后一个提交的事务的LSN或查询。在1385中,将与属性向量的同步点对应的新LSN存储在列日志管理器1361中。
另外,在1387中,将已更新的查询所需的数据返回到查询/事务管理器1350以执行查询。在1389中,将来自查询/事务管理器1350的指令呈现给列数据缓冲器1359以清洗更新的数据。在1391中,将更新的数据写入列数据文件1360。
图13C是本发明实施例提供的通过将目标量数据导入到引用属性向量来动态自适应地更新列存储数据库,从而提供实时分析结果以满足分析查询的示例性MRC算法1300C的示意图。MRC算法1300C假设列存储数据库的迁移缓冲器仅包含已提交改变。另外,MRC算法1300C从给定引用列的最后一次提交开始,迁移仅由查询引用的列的改变。
迁移所有列(Migrate All Columns,MAC)
第二种迁移技术称为迁移所有列(Migrate All Columns,MAC)。在MAC中,确定列存储数据库中的所有属性向量的最后一个同步点。从该点起,MAC向前扫描所有后续改变,直到迁移缓冲器中最新事务的最后提交的LSN。然后将扫描且已提交的改变应用到所有对应的属性向量,即使在给定查询中未引用列。因此,MAC算法可以比需要的速度更快地更新一些属性向量。
在MAC中,用于指示行存储数据库的最新事务和最新点的相同日志序列号也可以用于整个列存储数据库,更具体地,用于列存储中的每个属性向量。这是因为自最后一个同步点以来,迁移缓冲器中的所有改变都应用到列存储数据库中的所有属性向量。这简化了列存储中使用的日志文件的内容,因为在将改变迁移到列存储之后,只有同步点的一个LSN需要写入日志文件。例如,在向列存储数据库迁移之后,将与最新提交到行存储数据库(例如,迁移缓冲器)中的改变事务相关联的最新LSN用作新的和/或更新的同步点。
图14A是本发明实施例提供的响应于执行分析查询来动态自适应地更新列存储数据库中的所有属性向量从而提供实时分析结果,例如当执行MAC迁移技术时,的方法的流程图1400A。在一实施例中,流程图1400A示出了响应于执行分析查询来动态自适应地更新列存储数据库中的所有属性向量从而提供实时分析结果的计算机实现的方法。在另一实施例中,流程图1400A在计算机系统内实现,该计算机系统包括处理器以及耦合到处理器并且其中存储有指令的存储器,如果该指令由计算机系统执行,则使得系统响应于执行分析查询来动态自适应地更新列存储数据库中的所有属性向量从而提供实时分析结果的方法。在又一实施例中,用于执行所述方法的指令存储在非瞬时性计算机可读存储介质中,该非瞬时性计算机可读存储介质具有响应于执行分析查询来动态自适应地更新列存储数据库中的所有属性向量,从而提供实时分析结果的计算机可执行指令。在本发明一些实施例中,流程图1400A中的操作分别在图1和图8中的数据库系统100和/或数据库系统800内实现。
在实施例中,流程图1400A中概述的方法可选地回到1410,流程图900中的操作935,和/或流程图15中使用的连接点B。在这种方式下,可以出于更新列存储数据库的目的以任何方式组合MRC和MAC迁移技术。例如,任何配置形式的MRC和MAC迁移技术的组合公开了迁移混合迁移技术。
在1410中,所述方法包括:确定每个属性向量的同步点,所述同步点指示(例如,整体的)列存储数据库最后一次更新的时间点,所述同步点对应于与最后一个先前接收到的分析查询的执行时间(例如,在查询执行期间存储在迁移缓冲器中的最后提交的改变事务的LSN)相关联的日志序列号。即,同步点普遍应用到列存储数据库中的每个属性向量。因此,对于列存储数据库只需要存储一个同步点。
在1420中,所述方法包括:在同步点之后访问对应于改变事务的日志数据。具体地,例如在访问改变事务的图像信息之后,确定和访问在最后一个同步点之后接收到的所有改变事务。
在1430中,所述方法包括:基于日志数据更新多个属性向量,日志数据对应于在同步点之后收集的改变事务。即,应用所有改变以更新列存储数据库。此时,保存在列存储数据库中的数据与其在行存储数据库中的对应数据同步。
在1440中,所述方法包括:将同步点设置为应用到列存储数据库中的所有属性向量,以对应于第一分析查询。即,将整个列存储的新同步点设置为记录在迁移缓冲器中的最后提交的改变事务。在1450中,在将改变数据迁移到属性向量之后,系统清除迁移缓冲器的存储空间。
在实施例中,流程图1400A中概述的方法可选地进行到操作1410;进行到图900中的流程图900中的操作915以继续在阶段1和/或阶段2中使用MRC技术;和/或进行到图15中的流程图1500中使用的连接点B。在这种方式下,可以出于更新列存储数据库的目的以任何方式组合MRC和MAC迁移技术。例如,任何配置形式的MRC和MAC迁移技术的组合公开了迁移混合迁移技术。
通常,在MAC迁移技术中,不需要维护大的迁移文件。这是因为迁移缓冲器通常不会达到容量,因为分析查询的频繁运行足以在迁移缓冲器溢出之前不断地清除该缓冲器。即使在一段时间内有最少或没有分析查询运行,并且迁移缓冲器变满,系统此时也可以执行MAC算法。即,当迁移缓冲器已满时,可以将迁移缓冲器中的改变数据应用到列存储器中的属性向量,从而释放迁移缓冲器的空间。
使用以上结合13A提供的示例,在INSERT语句之后,接收相同的分析查询(例如,SELECT语句),但是现在使用MAC迁移技术来对其进行处理,如下:
SELECT DeptNo,SUM(salary)FROM Employee GROUP BY DeptNo;
如前所述,在处理最后的分析查询之后,在列存储数据库中为列雇员编号,姓名,部门编号,入职日期和工资构建了五个属性向量。随后接收到的INSERT语句将一个或多个新记录插入到先去介绍的雇员表中。在事务向行存储的提交期间,对于已经构建好属性向量的那些以上引用的五列,将新记录的改变复制到迁移缓冲器中。
使用MAC迁移技术,将迁移缓冲器中的所有改变分别应用到列存储数据库中的五个列及其对应的属性向量。在执行上述SELECT查询之后,列存储中的所有属性向量都处于一致的状态,因为它们都使用最新改变进行更新。
图14B是本发明实施例提供的通过导入列存储数据库中的属性向量的所有改变数据来动态自适应地更新列存储数据库,从而提供实时分析结果以满足分析查询,例如当执行MAC迁移技术时,的示例性算法1400B的示意图。MAC算法1400B假设列存储数据库的迁移缓冲器仅包含已提交改变。另外,MAC算法1400B从最后一个同步点开始到最后提交事务的所有的列改变迁移到任意列。
迁移混合
第三种迁移技术,称为迁移混合,提供了MRC和MAC迁移技术两者的优点。大多数时候,迁移混合技术在保持“即时”和“恰好足够”的设计理念的同时刷新查询中引用的那些列。这是通过将MRC迁移技术作为默认过程完成的。偶尔,当迁移缓冲器达到阈值并且要达到容量时,使用MAC迁移技术而不是MRC迁移技术。
在实施中,分配合理大的迁移缓冲器(例如,50到100兆字节)。当要运行查询时使用MRC迁移技术,以更新列存储数据库。即,大多数时候,使用MRC迁移技术在保持“即时”和“恰好足够”的设计理念的同时刷新查询中引用的那些列。另外,当迁移缓冲器的存储空间达到阈值(例如,达到容量)时,使用MAC迁移技术。即,当迁移缓冲器的存储空间已满时,将调用MAC算法。因此,迁移混合迁移技术保持了MRC和MAC迁移技术两者的优点。在这种方式下,不需要在列存储中保留迁移文件。即,迁移文件不是必需的,因为每当迁移缓冲器中的信息达到阈值时就被迁移到属性向量。
图15是本发明实施例提供的用于(例如,通过实现迁移混合迁移技术)通过以下操作提供实时分析结果的方法的流程图1500:将目标量数据导入到引用属性向量来动态自适应地更新列存储数据库中的引用属性向量,以满足分析查询;以及当包含来自同步点的改变事务的迁移缓冲器已经达到阈值时,动态自适应地更新列存储数据库中的所有属性向量。在一实施例中,流程图1500示出了(例如,通过实现迁移混合迁移技术)通过以下操作提供实时分析结果的计算机执行的方法:将目标量数据导入到引用属性向量来动态自适应地更新列存储数据库中的引用属性向量,以满足分析查询;以及当包含来自同步点的改变事务的迁移缓冲器已经达到阈值时,动态自适应地更新列存储数据库中的所有属性向量。在另一实施例中,流程图1500在计算机系统中实现,该计算机系统包括处理器以及耦合到处理器并且其中存储有指令的存储器,如果该指令由计算机系统执行,使得系统执行(例如,通过实现迁移混合迁移技术)通过以下操作提供实时分析结果的方法:将目标量数据导入到引用属性向量来动态自适应地更新列存储数据库中的引用属性向量,以满足分析查询;以及当包含来自同步点的改变事务的迁移缓冲器已经达到阈值时,动态自适应地更新列存储数据库中的所有属性向量。在又一实施例中,执行所述方法的指令存储在非瞬时性计算机可读存储介质中,该非瞬时性计算机可读存储介质具有用于(例如,通过实现迁移混合迁移技术)通过以下操作提供实时分析结果的计算机可执行指令:将目标量数据导入到引用属性向量来动态自适应地更新列存储数据库中的引用属性向量,以满足分析查询;以及当包含来自同步点的改变事务的迁移缓冲器已经达到阈值时,动态自适应地更新列存储数据库中的所有属性向量。在本发明的一些实施例中,流程图1500的操作分别在图1和图8中的数据库系统100和/或数据库系统800内实现。
在一实施例中,流程图1500中概述的方法可选地从流程图9,14A和15中使用的连接点A或B开始。在这种方式下,可以出于更新列存储数据库的目的以任何方式组合MRC和MAC迁移技术。例如,任何配置形式的MRC和MAC迁移技术的组合公开了迁移混合迁移技术。一般来说,在迁移混合迁移技术中,如果数据库系统耗尽迁移缓冲器中的存储空间,则使用MAC迁移技术,否则使用MRC迁移技术。
更具体地,在1510中,所述方法包括:将改变事务子集中的改变事务存储在缓冲器中。即,将满足包括在该子集中的三个条件的改变事务,以及自最后一个同步点以来提交的改变事务存储在迁移缓冲器中。三个条件包括(1)已经构建好属性向量的列;(2)改变在覆盖区间内;(3)已提交事务中的改变。例如,可以通过MRC迁移技术实现改变事务的选择和存储。
在1520中,所述方法包括:确定迁移缓冲器是否已经达到阈值。对于迁移到迁移缓冲器的每个改变事务执行该确定。如果迁移缓冲器已经达到阈值(例如,已满),则所述方法进行到流程图14A中的连接点A,以执行MAC迁移技术来将改变数据迁移到列存储数据库,并且清空迁移缓冲器。此时,没有接收到分析查询。
另一方面,如果迁移缓冲器尚未达到阈值,则方法进行到1530并继续MRC技术的阶段1。特别地,执行操作915,920和925以识别满足三个先前定义的迁移到缓冲器的条件的改变事务。
再次,对于迁移到迁移缓冲器的每个改变事务,所述方法在1540中确定是否已经接收到分析查询。如果已经接收到查询,则在迁移混合迁移技术中,在分析查询的执行期间执行MRC迁移技术的阶段2。具体地,执行操作930和935来迁移相关改变数据,以更新列存储数据库中的引用属性向量,以便处理分析查询。另一方面,如果尚未接收到查询,则所述方法返回到1510,并继续可以通过MRC迁移技术实现的对于改变事务的选择和存储。
如流程图1500所示,为了更新列存储数据库,MRC和MAC迁移技术可以以任何方式组合。例如,任何配置形式的MRC和MAC迁移技术的组合公开了迁移混合迁移技术。显然,迁移混合算法是优选实施例,因为它可以保持MRC和MAC算法两者的优点,而没有两者任一个的缺点。
系统恢复
在系统崩溃之后,首先恢复行存储数据库,因为行存储数据库被定义为真值源。在行存储完成恢复操作之后,可以基于行存储数据库中的值来恢复列存储数据库。
特别地,假设LSNR是保存在行存储数据库的日志文件中的最新日志序列号。并且,LSNC是保存在列存储数据库的元数据中的最新日志序列号。将LSNR的值与LSNC的值相互进行比较。如果LSNC小于LSNR,则列存储数据库仍有数据缺口。因此,在列存储数据库的恢复过程中,LSNC的值位于行存储数据库的日志文件中。通过使用先前描述的阶段一迁移过程将已提交改变拷贝到列存储数据库的迁移缓冲器来恢复数据。之后,当调用查询扫描操作时,将在先前描述的迁移技术(例如,MRC,MAC,迁移混合)的第二阶段期间更新列存储。由于列存储数据库中的数据在恢复期间不在磁盘上改变,所以混合行/列存储数据库的整个系统恢复操作将消耗大约与专用于行存储数据库的系统恢复过程相同的时间量。
因此,根据本发明实施例,描述了用于从行存储数据库自适应地构建列存储数据库的系统和方法,以满足针对引用属性向量或列的分析查询。描述了用于从行存储数据库自适应地构建和更新列存储数据库的本发明其他实施例,以满足针对引用属性向量或列的分析查询。
虽然以上披露使用具体的方框图、流程图以及示例阐明了各种实施例,本文中所述和/或图示的每个方框图组件、流程图步骤、操作和/或组件都可以通过各种硬件、软件或固件(或者它们的任意组合)配置单独地和/或共同地实施。另外,对其他组件之中包括的任意组件的披露应该看作为示例,因为可以实施许多其他架构来达到同样的功能。
本文中所述和/或图示的进程参数和步骤顺序仅仅是为了举例并且可以按需要更改。例如,虽然本文中所图示和/或描述的步骤可以按照特定顺序来示出或讨论,但这些步骤并非必须按照所图示或所讨论的顺序来执行。本文中所述和/或所图示的各种示例方法还可以省略本文中所述和/或所图示的一个或多个步骤或还可以包括除披露的那些步骤之外的额外步骤。
虽然本文已经在全功能性计算系统的背景下对不同的实施例进行了描述和/或图示,这些示例实施例中的一个或多个能够以多种方式作为一个程序产品来分发,而不管用于实际进行该分发的计算机可读介质的具体形式如何。本文中所披露的实施例还可以通过使用执行一些特定任务的软件模块来实施。这些软件模块可以包括脚本、成批文件或其他可执行文件,其中这些可以存储在一种计算机可读介质上或者一种计算机系统中。这些软件模块可以配置一个计算机系统以用于执行本文中所披露的一个或多个示例实施例。本文中所披露的一个或多个软件模块可以在云计算环境中实施。云计算环境可以通过互联网提供不同的业务和应用程序。这些基于云的业务(例如,软件即服务、平台即服务、基础设施即服务等等)可以通过网络浏览器或其他远程接口进行访问。本文中所述的各种功能可以通过远程桌面环境或任意其他基于云的计算环境来提供。
虽然已详细地描述了本发明及其优点,但是应理解,可以在不脱离如所附权利要求书所界定的本发明的精神和范围的情况下对本发明做出各种改变、替代和更改。根据上述教导,许多修改和变更是可能的。选出和描述的各个实施例的目的是为了更好地解释本发明的原理和其实际应用,因而使本领域技术人员能够更好利用本发明各个实施例和适合预期特定用途的各种变更。
此外,本发明的范围并不局限于说明书中所述的过程、机器、制造、物质组分、构件、方法和步骤的具体实施例。所属领域的一般技术人员可从本发明中轻易地了解,可根据本发明使用现有的或即将开发出的,具有与本文所描述的相应实施例实质相同的功能,或能够取得与所述实施例实质相同的结果的过程、机器、制造、物质组分、构件、方法或步骤。相应地,所附权利要求范围旨在包括这些流程,机器,制造,物质组分,构件,方法,及步骤。
根据本发明的实施例如此处所述。虽然本发明已经在特定实施例中进行了描述,但是应理解,本发明不应该被解释为这些实施例的限制,而是根据以下权利要求书进行解释。
- 还没有人留言评论。精彩留言会获得点赞!