一种GPU中用于分支处理的寄存器文件结构的制作方法
本发明涉及通用GPU计算领域,特别是涉及一种GPU中用于分支处理的寄存器文件结构。
背景技术:
随着集成电路技术的不断发展及集成度的不断提高,GPU的计算能力得到了不断的增强。当代的GPU已经不仅仅局限于处理图形应用,还能应用于通用计算领域,并且具有广阔的前景。为了使GPU能够更高效的执行通用计算,需要对GPU的微架构做进一步的优化。
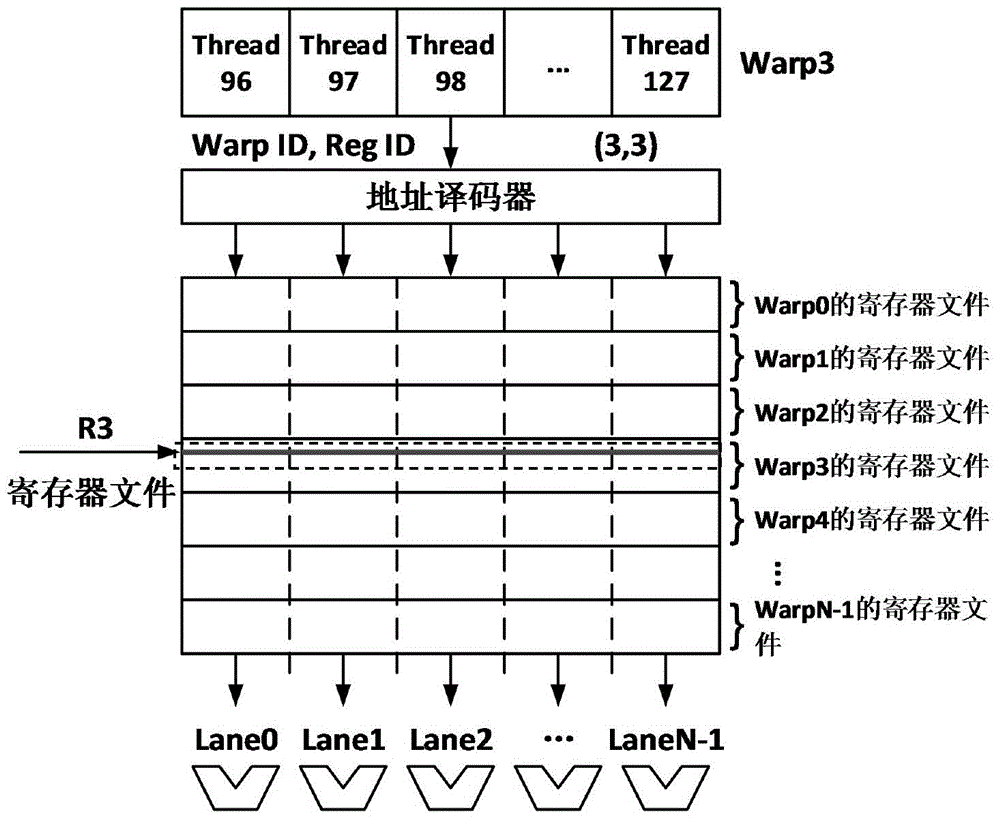
当代的GPU以单指令流多线程流(Single-Instruction Multiple-Thread,SIMT)的方式在单指令流多数据流(Single-InstructionMultiple-Data,SIMD)的硬件流水线上执行。在这种执行模式中,线程被硬件组织成线程束(warp)。线程束中的每一个线程都对应一个SIMD通道,并且线程束中的线程,每一个线程都能拥有自己独立的指令控制流(例如作为Warp3的各个线程Thread96,Thread97,Thread98,…...Thread127选择(Warp ID,Reg ID)对应的寄存器(例如R3)中的Warp3的寄存器文件进行同时访问,如图1所示。多个线程束组成一个线程块(block),线程块的大小由程序员设定。
然而,当程序中有条件分支出现的时候,线程束中的线程可能会选择不同的路径(如路径A-F、路径A-B-C,D-E-G),如图2所示。GPU通过SIMD通道屏蔽的方法来串行执行每一条路径,并且为每一个线程束分配一个栈来维护每一条路径的信息,如图3所示。图3中的栈是图2中线程束W0的路径信息。栈的一个条目由三个域构成,其中PC表示W0(Wrap0的简写)要执行的下一条指令的地址,RPC表示分支程序流的汇合点,如图2中的E和G,Active Mask表示的是线程束中跳转到该路径的有效线程。GPU根据每一个线程束的Active Mask来判断当前路径中应该执行哪些线程。
当W0发生条件分支的时候(图2中的A点),GPU首先将汇合点的地址(G)写入栈顶(此时栈顶为条目①)的PC域,然后再向栈里弹入两个条目,即条目②和条目③,代表分支后的两条路径F和B。每个条目分别记录各自路径的PC,RPC以及Active Mask,然后GPU首先执行栈顶的条目所代表的路径B。随后B又发生条件分支,此时GPU将条目③的PC域改为分支汇合点E,并且弹入条目④和条目⑤分别代表路径C和D。GPU首先执行路径D,当栈顶的PC等于RPC的时候,表示当前执行的路径下一条指令将到达汇合点,此时需要将条目⑤弹出,从而可以执行下一条路径,即路径C。当程序再次到达汇合点时,将条目④弹出,执行路径E,GPU按照上述执行方式运行一直到程序结束。这种方式虽然保证了程序流的正确性,并且能够在程序到达汇合点之后恢复条件分支之前线程束中线程的并行度,却不能在执行分支路径的时候增加线程束中有效线程的个数,导致SMID利用率和性能的下降。
技术实现要素:
基于上述现有技术,本发明提出了一种GPU中用于分支处理的寄存器文件结构,为了在执行分支路径时增加线程束中有效线程的个数,提高线程并行度和SIMD硬件利用率,改善性能,可以将同一个线程块的不同线程束中执行同一路径的所有线程进行压缩,使这些线程能够在同一个线程束中运行。而为了使压缩效率最大化,需要解除线程束中线程与SIMD通道的一一对应关系,使得位于任意通道的线程都能够被压缩到同一个线程束中,并且在访问寄存器文件的时候不会产生额外的访问冲突。
本发明公开了一种GPU中用于分支处理的寄存器文件结构,该寄存器文件结构中,把寄存器文件按照行平均分成N个bank,N是GPU中一个SM所能容纳的最多的线程束的个数;对于寄存器文件中寄存器的分配方法遵循以下约束条件:
(1)当应用程序中的每一个线程束所需要的寄存器的个数大于或等于每个bank中所包括的行数时,将寄存器文件中的寄存器连续地平均分配给每一个线程束;
(2)当应用程序中的每一个线程束所需要的寄存器的个数小于每个bank中所包括的行数时,此时每一个线程束独占一个bank;
其中,线程束在访问寄存器文件的时候,其中的每一个线程都会产生一个访问请求,仲裁器将针对同一个bank的访问请求进行合并并且根据其中被访问的每个bank的线程束索引、线程索引以及寄存器索引,生成相应的访问地址及控制信号;每一个访问请求根据生成的访问地址和控制信号读出bank中的一行的寄存器数据,再用crossbar将这一行中有效的数据路由到相应的SIMD通道上面;如果线程束中该SIMD通道所对应的线程无效,则对应的crossbar的输出端口的输出为零;对应同一SIMD通道的所有的crossbar的输出中至多有一个数据是有效的;最后,将各个crossbar的与SIMD通道相对应的输出端口进行“或”操作,过滤出其中的有效数据,输入到SIMD通道上面;线程任意的更换SIMD通道而且压缩后形成的线程束在访问寄存器文件的时候不会产生访问冲突。
所述控制信号利用分支指令信息的栈结构实现维护,所述栈结构使用两个buffer0和Buffer1来存储最新遇到的分支信息;Buffer0用来存储线程在非提前调度状态下遇到分支后的信息,Buffer1用来存储线程在提前调度状态下遇到分支后的信息;一个线程块中的所有线程束共享一个栈,并且栈中增加线程束计数器来记录还没有到达分支或者汇合点的线程束的个数;当线程束到达分支或者汇合点时,WCnt减一。如果WCnt变成零,则表示线程块中所有的线程束全部到达分支或者汇合点。
实验结果显示,该方法能够有效的提高SIMD硬件利用率和性能。GPU的基本架构下的SIMD硬件利用率和采用该寄存器文件之后的压缩机制的硬件利用率对比如附图-7所示,性能对比如附图-8所示。对GPU架构进行修改后,硬件利用率最高能提升3.1倍,平均(OA)的硬件利用率由62.7%提高到85.9%。而性能最高能够提升2.3倍,平均(HM)能够提升8.4%。
附图说明
图1为GPU中寄存器文件结构图;
图2为分支程序控制流示意图;
图3为维护跳转路径信息的栈结构示意图;
图4为改进后的寄存器文件结构图;
图5为对改进后的寄存器文件结构的程序执行流程图;
图6为改进后的维护分支指令信息的栈结构示意图;
图7为本发明的改进寄存器架构与基本机构的SIMD通道硬件利用率效果比较图;
图8为本发明的改进寄存器架构与基本机构的归一化性能比较图;
图9为控制信号的产生逻辑图。
具体实施方式
下面将结合附图对本发明的具体实施方式进行详细描述,这些实施方式若存在示例性的内容,不应解释成对本发明的限制。
为了在执行分支路径时增加线程束中有效线程的个数,提高线程并行度和SIMD硬件利用率,改善性能,可以将同一个线程块的不同线程束中执行同一路径的所有线程进行压缩,使这些线程能够在同一个线程束中运行。而为了使压缩效率最大化,需要解除线程束中线程与SIMD通道的一一对应关系,使得位于任意通道的线程都能够被压缩到同一个线程束中,并且在访问寄存器文件的时候不会产生额外的访问冲突。
为了实现线程的任意压缩,需要重新设计寄存器文件结构,改进后的寄存器文件结构如图4所示。在该寄存器文件结构中,把寄存器文件按照行平均分成N个bank。N是GPU中一个Streaming Multiprocessor(SM,流多处理器)所能容纳的最多的线程束的个数。对于寄存器文件中寄存器的分配方法,有如下约束:
(1)当应用程序中的每一个线程束所需要的寄存器的个数大于或等于每个bank中所包括的行数时,将寄存器文件中的寄存器连续地平均分配给每一个线程束;
(2)当应用程序中的每一个线程束所需要的寄存器的个数小于每个bank中所包括的行数时,此时每一个线程束独占一个bank。
线程束在访问寄存器文件的时候,其中的每一个线程都会产生一个访问请求。图4中的仲裁器(Arbitrator)负责将针对同一个bank的访问请求进行合并并且根据其中被访问的每个bank的线程束索引、线程索引以及寄存器索引,生成相应的访问地址及控制信号。每一个访问请求根据生成的访问地址和控制信号读出bank中的一行的寄存器数据,再用crossbar(交叉开关)将这一行中有效的数据路由到相应的SIMD通道上面。如果线程束中该SIMD通道所对应的线程无效,则对应的crossbar的输出端口的输出为零。因此对应同一SIMD通道的所有的crossbar的输出中至少有一个数据是有效的。最后,将各个crossbar的与SIMD通道相对应的输出端口进行“或”操作,过滤出其中的有效数据,输入到SIMD通道上面。这种寄存器文件结构在进行线程压缩时能够带来两种特点,即:
1)对应同一SIMD通道的线程能够同时访问多个寄存器文件;
2)位于同一线程束的线程产生相同的访问请求。
这样,线程就可以任意的更换SIMD通道而且压缩后形成的线程束在访问寄存器文件的时候不会产生访问冲突。下面以图4为例来说明压缩后的线程束访问寄存器文件的过程。
图4中,线程束的宽度为32个线程,因此线程0(Thread 0)和线程32(Thread 32)原本位于同一通道中(通道0),线程33(Thread 33)对应通道1,线程66(Thread 66)则对应通道2。该线程束在访问寄存器的时候,首先由仲裁器ARBITRATOR将各个线程分配到他们所对应的bank上面,即线程0(Thread 0)和线程32(Thread 32)访问Bank 0,线程33(Thread 33)访问Bank 1,线程66访问Bank 2(Thread 66)。然后根据访问地址读出这些访问请求在各自的bank中所需要的那一行寄存器数据,Bank 0的输出中只有对应SIMD通道0的数据是有效的,Bank 1的输出中对应SIMD通道0和通道1的数据是有效的,而Bank 2的输出中对应SIMD通道2的数据是有效的。然后Bank 0的有效输出数据被crossbar通过控制信号路由到SIMD通道0上,Bank 1的有效输出数据被路由到SIMD通道1和通道2上,Bank 2的有效输出数据被路由到SIMD通道31上。
基于这种寄存器文件结构,一个SIMD通道能够获得寄存器文件中的任何一个数据,从而使一个由对应任意通道的线程构成的线程束能够在访问寄存器文件的时候不产生任何访问冲突。
当有32(线程束的宽度)个线程执行完分支指令的时候,这32个线程就可以形成一个新的线程束,而这个线程束就可以提前于线程块中的其他线程被调度了。因此可以将执行完分支指令的线程放入一个缓冲区,当这个缓冲区中的有效线程数达到32时或者所有的线程都已完成分支指令时,由这些线程形成的新的线程束就可以被调度了。
一个被调度的线程束除非遇到了新的条件分支指令,或者到达控制流的汇合点才会被停止运行。本发明用1bit的提前调度位来标识一个线程束是不是被提前调度。当一个线程束被提前调度的时候,该位被置为1。当所有的线程都完成分支指令的时候,提前调度的线程束的提前调度位被置为0。如果其他线程还没有完成分支指令而提前调度的线程又到达一个分支指令,这些线程就不能被提前调度了,起分支信息会被存到另一个缓冲区中。
当最后一个线程束完成分支指令,并且没有新的线程执行已经被提前执行的路径,这时候会有三种特殊情况:
(1)所有提前调度的线程都已经到达一个新的分支。在这种情况下,新分支中的一条路径所对应的线程将会被压缩并且调度压缩所形成的线程束。此时这些线程束被标识为非提前调度。
(2)所有提前调度的线程都已经到达控制流的汇合点。这时清除该路径的信息,将下一路径所对应的线程进行压缩并调度。
(3)所有提前调度的线程都已经到达一条栅栏同步指令并且下一条指令不是控制流的汇合点。在这种情况下,清除栅栏同步,提前调度位置0,继续调度这些线程。
以图2中的控制流为例,来说明该方法的执行流程。图2中,程序在A发生分支,分成路径B和F,两条路径在D汇合。路径B又分成C和D,并且在E汇合。其执行流程图如图5所示。
在图5中,假设程序执行过程中发生了3次cache缺失,并且cache缺失(Miss Cash)时需要3个周期获取数据。W2在周期c-3遇到了一次cache缺失。当分支指令A1被W1在周期c-5执行完毕之后,一个由线程0,2,4,5组成的新线程束(W0)就能够被调度了。在周期c-6,由于cache缺失,W2仍然处于挂起状态。然而,新形成的W0能都被提前调度去执行分支指令B0来隐藏cache缺失所造成的延迟。W0的分支信息被存储在一个缓冲区中,并且W0的线程不能再被提前压缩。当W2执行完指令A1,所有的线程都通过了分支指令,线程束的提前调度位都被清除。在路径B上,通过压缩一共产生了2个线程束,一个是在周期c-5提前压缩形成的W0,另一个是在周期c-7形成的W1。
为了支持提前调度机制的功能,需要对维护分支指令信息的栈结构进行改进,如图6所示。改进后的栈结构中使用两个buffer(Buffer0和Buffer1)来存储最新遇到的分支信息。Buffer0用来存储线程在非提前调度状态下遇到分支后的信息,Buffer1用来存储线程在提前调度状态下遇到分支后的信息。由于是将同一个线程块中的线程进行压缩,所以现在一个线程块中的所有线程束共享一个栈,并且栈中增加线程束计数器(WCnt)来记录还没有到达分支或者汇合点的线程束的个数。当线程束到达分支或者汇合点时,WCnt减一。如果WCnt变成零,则表示线程块中所有的线程束全部到达分支或者汇合点。
如图9所示,为仲裁器产生控制信号来控制一个crossbar的一个输出端口的输出的逻辑。一个线程束中的线程编号(tid_0,tid_1,tid_2,tid_3,……tid_31)进入warp-id检测单元,首先除以线程束的宽度(32)来获得warp-id,然后用产生的warp-id与当前的bank对应的warp-id进行同或操作,然后再将32个同或结果进行或操作,产生的信号为bank使能信号。如果输出为1,则表示这个warp中有访问这个bank的线程,需要将bank开启,并根据寄存器地址访问相应的数据。图9中的逻辑流程所示为crossbar1的第一个输出端口的举例,即图4中的C(1,0),因此具体说明描述如下:
将tid_0对32取模操作,得到tid_0在线程束内部的偏移量,并且将上述tid_0产生的同或结果作为选通信号,来选通多路选择器M0。M0的输入分别为tid_0取模的结果和111111。如果M0的选通信号为1,则输出tid_0的取模结果,反之则输出111111。M1的输入信号为从bank中读出的32组数据和0,共33个输入,其选通信号为M0的6位输出。当M0的输出为111111时,选通0;如果不为111111,则根据选通信号的数值输出相应位置的数据。
当线程束到达一个分支的时候,硬件首先检查一下这些线程束是不是提前调度的线程束。如果是,相应的分支信息就会更新到Buffer0中。否则,则更新到Buffer1中。在更新之前,需要删除PC值等于RPC的路径。当一条路径当中的有效线程数大于或者等于32时,这些线程将会被发送到压缩单元(compaction unit)进行压缩。图中的异或单元(XOR)用来过滤将要进行压缩的有效线程。当一个分支被所有的线程都执行完毕时,将Buffer0中的信息更新到block-wide stack中。如果此时Buffer1不为空,则将Buffer1的信息复制到Buffer0中。否则,清空Buffer1。
- 还没有人留言评论。精彩留言会获得点赞!