结合用户情感表达方式的中文情感新词识别方法和系统与流程
本发明实施例涉及计算机科学
技术领域:
,尤其是涉及一种结合用户情感表达方式的中文情感新词识别方法和系统。
背景技术:
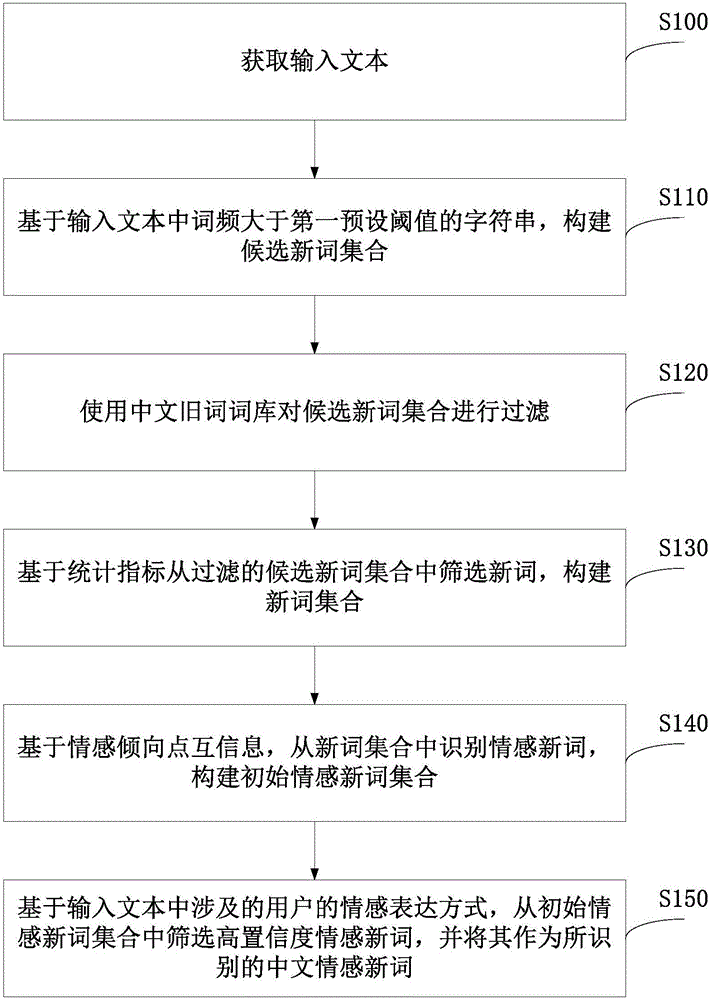
:作为情感词库的基本组成元素,情感词是大多数文本情感分析方法的基础。随着Web2.0技术的普及,社会媒体中用于表达情感的新词不断产生,自动识别这些情感新词对情感词库构建以及文本情感分析具有重要意义。如今,互联网上的海量社会媒体文本在给情感新词识别工作带来数据支持的同时也提出了严峻的技术挑战。以往的中文情感新词识别工作可以分为两类:其中一类工作通过句子中情感词的上下文识别新情感词,代表性工作包括:Wang等("ABootstrappingMethodforExtractingSentimentWordsUsingDegreeAdverbPatterns,"in2012InternationalConferencesonComputerScience&ServiceSystem(CSSS),2012,pp.2173-2176)将传统情感词的前后词汇作为匹配新情感词的上下文模板,并采用Bootstrapping策略不断产生新的情感词及上下文模板;另一类工作以新词发现为基础,通过筛选新词集合中的情感词实现情感新词识别,代表性工作包括:桑等("基于广义Jaccard系数的微博情感新词判定,"山东大学学报(理学版),2015,50(07),pp.71-75)基于现有分词工具识别新词,根据左右邻接词对新词以及传统情感词进行特征表示,并通过广义Jaccard系数计算新词与传统情感词的特征向量相似度,进而从新词集合中筛选情感新词。其中,上述第二类工作大多通过定义统计指标挖掘文本中的新词,相关统计指标包括:点互信息("UnknownChinesewordextractionbasedonvarietyofoverlappingstrings,"InformationProcessing&Management,2013,49(2),pp.497-512)、邻接熵("Chinesewordsegmentationbasedoncontextualentropy,"Proceedingsofthe17thAsianPacificconferenceonlanguage,informationandcomputation,2003,pp.152-158)、构词能力及灵活度("微博新词发现及情感倾向判断分析,"山东大学学报(理学版),2015,50(01),pp.20-25)等;在新词发现的基础上,相关工作根据新词与传统情感词在文本中的共现情况或上下文相似性识别其中的情感词,如:基于“情感倾向点互信息(SOPMI)”识别情感词("Thumbsuporthumbsdown?:semanticorientationappliedtounsupervisedclassificationofreviews,"Proceedingsofthe40thannualmeetingonassociationforcomputationallinguistics,2002,pp.417-424)。以往中文情感新词识别方法主要存在以下不足:(1)大量方法在中文分词结果的基础上识别情感新词,因而难以识别分词工具无法正确切分的词;(2)基于新词发现的方法可能将新词发现阶段的错误传递到后续的情感词识别任务中,导致该类方法精度偏低;(3)现有方法仅利用词的上下文文本信息识别情感新词,忽略了词背后的用户情感表达方式等信息。有鉴于此,特提出本发明。技术实现要素:本发明实施例的主要目的在于提供一种结合用户情感表达方式的中文情感新词识别方法,其至少部分地解决了如何提高情感新词识别的精度和灵活度的技术问题。此外,还提供一种结合用户情感表达方式的中文情感新词识别系统。为了实现上述目的,根据本发明的一个方面,提供了以下技术方案:一种结合用户情感表达方式的中文情感新词识别方法,所述方法至少包括:获取输入文本;基于所述输入文本中词频大于第一预设阈值的字符串,构建候选新词集合;使用中文旧词词库对所述候选新词集合进行过滤;基于统计指标从过滤的候选新词集合中筛选新词,构建新词集合;其中,所述统计指标为构词能力、点互信息、灵活度和邻接熵;基于情感倾向点互信息,从所述新词集合中识别情感新词,构建初始情感新词集合;基于所述输入文本中涉及的用户的情感表达方式,从所述初始情感新词集合中筛选高置信度情感新词,并将其作为所识别的中文情感新词。根据本发明的另一个方面,还提供了一种结合用户情感表达方式的中文情感新词识别系统,所述系统至少包括:获取单元,用于获取输入文本;第一构建单元,用于基于所述输入文本中词频大于第一预设阈值的字符串,构建候选新词集合;过滤单元,用于使用中文旧词词库对所述候选新词集合进行过滤;第二构建单元,用于基于统计指标从过滤的候选新词集合中筛选新词,构建新词集合;其中,所述统计指标为构词能力、点互信息、灵活度和邻接熵;第三构建单元,用于基于情感倾向点互信息,从所述新词集合中识别情感新词,构建初始情感新词集合;筛选单元,用于基于所述输入文本中涉及的用户的情感表达方式,从所述初始情感新词集合中筛选高置信度情感新词,并将其作为所识别的中文情感新词。与现有技术相比,上述技术方案至少具有以下有益效果:本发明实施例通过预设词频阈值构建候选新词集合,然后使用中文旧词词库对候选新词集合进行过滤;之后基于统计指标从过滤的候选新词集合中筛选新词,构建新词集合。从字、词内部和词外部三个层次共同发现新词,在此基础上,基于情感倾向点互信息确定初始情感新词;最后基于所述输入文本中涉及的用户的情感表达方式,从所述初始情感新词集合中筛选高置信度情感新词,并将其作为所识别的中文情感新词,提高了情感新词识别的效果。所以,本发明实施例能够根据实际需要确定输出的情感新词集合的大小,具有灵活度较高的技术效果。当然,实施本发明的任一产品不一定需要同时实现以上所述的所有优点。本发明的其它特征和优点将在随后的说明书中阐述,并且,至少部分地从说明书中变得显而易见,或者通过实施本发明而被了解。本发明的目的和其它优点可通过在所写的说明书、权利要求书以及附图中所特别指出的方法来实现和获得。附图说明附图作为本发明的一部分,用来提供对本发明的进一步的理解,本发明的示意性实施例及其说明用于解释本发明,但不构成对本发明的不当限定。显然,下面描述中的附图仅仅是一些实施例,对于本领域普通技术人员来说,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。在附图中:图1为根据一示例性实施例示出的结合用户情感表达方式的中文情感新词识别方法的流程示意图;图2为根据一示例性实施例示出的结合用户情感表达方式的中文情感新词识别系统的结构示意图。这些附图和文字描述并不旨在以任何方式限制本发明的构思范围,而是通过参考特定实施例为本领域技术人员说明本发明的概念。具体实施方式下面结合附图以及具体实施例对本发明实施例解决的技术问题、所采用的技术方案以及实现的技术效果进行清楚、完整的描述。显然,所描述的实施例仅仅是本申请的一部分实施例,并不是全部实施例。基于本申请中的实施例,本领域普通技术人员在不付出创造性劳动的前提下,所获的所有其它等同或明显变型的实施例均落在本发明的保护范围内。本发明实施例可以按照权利要求中限定和涵盖的多种不同方式来具体化。需要说明的是,在下面的描述中,为了方便理解,给出了许多具体细节。但是很明显,本发明的实现可以没有这些具体细节。需要说明的是,在没有明确限定或不冲突的情况下,本发明中的各个实施例及其中的技术特征可以相互组合而形成技术方案。本发明实施例提供一种结合用户情感表达方式的中文情感新词识别方法。如图1所示,该方法至少可以包括步骤S100至步骤S150。S100:获取输入文本。其中,输入文本即为文本语料。S110:基于输入文本中词频大于第一预设阈值的字符串,构建候选新词集合。从文本语料中提取词频大于预设阈值的N-Gram,构建候选新词集合。其中,N-Gram表示文本语料中连续N个字符组成的字符串;N取正整数。优选地,N-Gram由中英文字符或数字组成。为此,对于每个文本,可以采用正则表达式提取其中的连续中英文字符及数字,在此基础上采用滑动窗口方式生成N-Gram集合。所采用的正则表达式为:“[a-zA-Z0-9\u4e00-\u9fa5]+”。以句子“精彩花絮提前曝光!”为例,从该句子中提取的2-Gram所构建的候选新词集合为{“精彩”,“彩花”,“花絮”,“絮提”,“提前”,“前曝”,“曝光”,“光!”}。S120:使用中文旧词词库对候选新词集合进行过滤。其中,中文旧词词库是指尽可能涵盖现有中文词汇的中文词典的集合。例如,中文旧词词库可以是大连理工大学情感词库、知网词库、COAE2014评测提供的旧词词库、CSDN中文分词词库等。本发明实施例通过中文旧词词库,排除旧词,过滤出候选新词集合,由此可以提升新词发现的精度。S130:基于统计指标从过滤的候选新词集合中筛选新词,构建新词集合;其中,统计指标为构词能力、点互信息、灵活度和邻接熵。本步骤结合字、词内部和词外部三个层次的统计指标(也即新词发现统计指标),从多个维度综合评价候选新词是新词的可能性。其中,字层次的新词发现统计指标为构词能力;词内部层次的新词发现统计指标为点互信息;词外部层次的新词发现统计指标包括灵活度和邻接熵。本发明实施例通过构词能力、点互信息、灵活度和邻接熵这四项统计指标从候选新词集合中进一步筛选新词。其中,构词能力用来衡量某个字的成词能力。构词能力是指单字符在文本语料中作为词的一部分出现的次数与其总出现次数之比,其计算前需要对语料进行中文分词。构词能力通过以下公式计算:其中,WFP(c)为单字c的构词能力,f(c)为单字c在文本语料中的出现次数;f(words|c)为包含单字c的词在文本语料中的出现次数。对于候选新词t,其构词能力定义为组成词t的所有字符的最小构词能力,即:其中,CharSet(t)为词t对应的字符集合。候选新词的构词能力越高,表明其内部的各个字符越有可能作为词的组成部分出现。因此,该词是新词的可能性也越大。点互信息从共现的角度衡量词内部各字符之间相互关联的紧密程度。点互信息是指词的出现概率除以词中各字符出现概率之积的对数值,其计算公式如下:其中,PMI(t)表示词t的点互信息;N表示语料规模;n表示词t的长度;f(t)表示词t在文本语料中的出现次数;CharSequence(t)表示词t的字符序列,f(c)表示字符c在文本语料中的出现次数。候选新词的点互信息越大,表明其内部各个字符越经常作为一个整体出现,因此该词是新词的可能性也越大。灵活度用来衡量某个词与其他词搭配使用的灵活程度。灵活度是指与词相邻的不同字符数目,可以细分为左灵活度和右灵活度。为了防止经常作为词尾的单字出现在新词首部,并防止经常作为词首的单字出现在新词尾部,本发明实施例计算左灵活度时将其除以词首字的后缀率,计算右灵活度时将其除以词中最后一个字的前缀率。具体计算方式如下:其中,FlexibilityL(t)和FlexibilityR(t)分别表示词t的左灵活度和右灵活度;NL(c|t)和NR(c|t)分别表示文本语料中出现在词t左边和右边的不同字符数目;suf(c)和pre(c)分别表示字符c的后缀率和前缀率;f(word1=c)和f(wordn=c)分别表示文本语料中字符c作为词首和词尾的出现次数;f(c)表示字符c在文本语料中的总出现次数。本发明实施例将候选新词的灵活度Flexibility(t)定义为该词的左灵活度与右灵活度的较小值,即:Flexibility(t)=min(FlexibilityL(t),FlexibilityR(t))。候选新词的灵活度越高,表明其越经常与不同字符共同出现。因此,该词是新词的可能性也越大。邻接熵用来衡量与某个词搭配使用的其他词的分布情况。邻接熵是指与词相邻的字符的分布的熵,可以细分为左邻接熵和右邻接熵。可以根据以下公式来计算左邻接熵和右邻接熵:其中,AdjacencyEntropyL(t)和AdjacencyEntropyR(t)分别表示词t的左邻接熵和右邻接熵;LeftCharSet(t)和RightCharSet(t)分别表示与词t左相邻和右相邻的字符集合;f(c,t)表示字符c作为词t的左邻居出现的次数;f(t,c)是字符c作为词t的右邻居出现的次数;f(t)是词t的出现次数。本发明实施例将候选新词的邻接熵AdjacencyEntropy(t)定义为该词的左邻接熵与右邻接熵的较小值,即:AdjacencyEntropy(t)=min(AdjacencyEntropyL(t),AdjacencyEntropyR(t))。候选新词的邻接熵越大,表明其周围字符的分布越均匀,因此该词是新词的可能性也就越大。对于候选新词集合中的各候选新词,其各项新词发现统计指标的取值越大,则该词是新词的概率也越大。本发明实施例计算出所有候选新词的构词能力、点互信息、灵活度和邻接熵之后,采用设置阈值的方式来筛选新词。选取所述构词能力大于等于第二预设阈值、所述点互信息大于等于第三预设阈值、所述灵活度大于等于第四预设阈值且所述邻接熵大于等于第五预设阈值的候选新词,构建所述新词集合。假设候选新词t的构词能力为WFP(t)、点互信息为PMI(t)、灵活度为Flexibility(t)、邻接熵为AdjacencyEntropy(t)。若候选新词t同时满足如下所有条件:WFP(t)≥θWFP、PMI(t)≥θPMI、Flexibility(t)≥θFlexibility、AdjacencyEntropy(t)≥θAdj,则认为词t是新词,将其加入新词集合中。其中,θWFP、θPMI、θFlexibility和θAdj分别为构词能力、点互信息、灵活度和邻接熵的最低阈值,取值由具体实施方式确定。具体地,新词发现统计指标的阈值可以设置如下:构词能力阈值θWFP=0.1、点互信息阈值θPMI=-2、灵活度阈值θFlexibility=20、邻接熵阈值θAdj=1.5。S140:基于情感倾向点互信息,从新词集合中识别情感新词,构建初始情感新词集合。在输入文本中会同时存在中文情感新词与传统情感词,通过计算所有情感新词与传统情感词的“情感倾向点互信息(SOPMI)”,以该指标为参考从新词集合中识别中文情感新词,来构建初始情感新词集合。“情感倾向点互信息”是指新词与正向传统情感词的点互信息之和减去新词与负向传统情感词的点互信息之和。其中,正向与负向传统情感词来自于传统情感词库,其由实际应用中的具体实施方式确定。新词与某个传统情感词的点互信息是指新词与该传统情感词共同出现于一篇文本中的概率除以各自出现概率之积的对数值。可以根据以下公式计算得到:其中,SOPMI(t)表示词t的“情感倾向点互信息”;PMI(t,w)表示词t与词w之间的点互信息;PosSet表示正向传统情感词集合;NegSet表示负向传统情感词集合;N表示语料规模;f(t,w)表示词t和词w共同出现于一个文本中的次数;f(t)和f(w)分别表示词t和词w在文本语料中的出现次数。对于新词集合中的新词t,若其“情感倾向点互信息”取值为正,则表示该词是正向情感词;若其“情感倾向点互信息”取值为负,则表示该词是负向情感词。本发明实施例通过计算所有新词的“情感倾向点互信息(SOPMI)”,采用设置阈值的方式识别新词集合中的情感新词。选取情感倾向点互信息的绝对值大于等于第六预设阈值的新词,构建初始情感新词集合。具体地,假设新词t的“情感倾向点互信息”取值为SOPMI(t),若其满足|SOPMI(t)|≥θSOPMI,则将新词t加入初始情感新词集合中。其中,θSOPMI为“情感倾向点互信息”的最低阈值,其取值由具体实施方式确定。优选地,θSOPMI=0.1。新词t的“情感倾向点互信息”绝对值越大,表明该词表达的情感强度就越强,因此该词是情感词的可能性也就越大。S150:基于输入文本中涉及的用户的情感表达方式,从初始情感新词集合中筛选高置信度情感新词,并将其作为所识别的中文情感新词。其中,情感表达方式包括情感表达显著性和情感表达强度。本步骤从用户的情感表达显著性和情感表达强度这两方面考虑用户的情感表达方式。通过引入用户的情感表达方式识别初始情感新词中的高置信度情感新词。具体地,从情感表达显著性和情感表达强度这两个维度对用户进行分组,进而根据用户分组信息以及用户的用词情况对初始情感新词进行评分,在此基础上筛选高置信度情感新词。本步骤具体还可以包括:S151:基于情感表达显著性,将所述输入文本中涉及的用户划分为情感表达外显组、情感表达内敛组和其他组。其中,用户的情感表达显著性反映用户是否倾向于采用醒目、清晰的情感表达方式。由于情感新词往往高度凝练、形象并且吸引人的眼球,长度较短却可以表达多个传统情感词才能共同表达的情感,因此情感表达方式较为显著的用户更可能大量使用情感新词。鉴于社会媒体中用户发布的大多数文本都包含情感,并且文本的长度越短,其情感表达越醒目、清晰,因此本发明实施例基于用户所发布文本的平均长度来衡量其情感表达显著性。S151具体可以包括:S1511:统计用户的平均文本长度。S1512:可以根据以下公式计算用户u的情感表达显著性:其中,AvgLen(u)表示所统计的用户的平均文本长度;MaxLen表示预先定义的最大文本长度,其取值可根据实际应用情况来确定。优选地,MaxLen设置为140。S1513:将用户u的情感表达显著性与预设阈值进行比较。S1514:如果用户的情感表达显著性大于等于第七预设阈值,则执行S1515;否则,执行S1518。S1515:将用户划分为情感表达外显组。S1516:如果用户的情感表达显著性小于等于第八预设阈值,则执行S1517;否则,执行S1518。S1517:将用户划分为情感表达内敛组。S1518:将用户划分为其他组。具体地,若用户u的情感表达显著性saliency(u)≥θSaliencyMin,则用户u属于情感表达外显组GHighSaliency;若用户u的情感表达显著性saliency(u)≤θSaliencyMax,则用户u属于情感表达内敛组GLowSaliency;否则,用户u属于其他组GOther。其中,θSaliencyMax和θSaliencyMin分别为情感表达显著性的最大、最小阈值,其取值可根据实际情况确定。优选地,θSaliencyMax=0.071,θSaliencyMin=0.857。上述分组规则的形式化表述如下:IFsaliency(u)≥θSaliencyMinTHENu∈GHighSaliencyIFsaliency(u)≤θSaliencyMaxTHENu∈GLowSaliencyIFsaliency(u)≤θSaliencyMinANDsaliency(u)≥θSaliencyMaxTHENu∈GOtherS152:基于情感表达强度,将输入文本中涉及的用户划分为高强度情感组和中低强度情感组。用户的情感表达强度反映用户是否经常表达高强度情感。由于情感新词往往情感强度较高且与传统情感词相比更容易吸引阅读者目光,因此频繁表达高强度情感的用户更可能大量使用情感新词。鉴于社会媒体中用户的情感表达特点,本发明实施例基于统计用户的连续感叹号使用比例、连续问号使用比例和连续波浪号使用比例来衡量用户的情感表达强度。其中,用户的连续感叹号使用比例、连续问号使用比例和连续波浪号使用比例分别指用户发布的所有文本中包含连续两个及以上中英文感叹号(“!”,“!”)、问号(“?”,“?”)和波浪号(“~”,“~”)的比例。用户u的情感表达强度定义如下:其中,%!+(u)表示用户u的连续感叹号使用比例;%?+(u)表示用户u的连续问号使用比例;%~+(u)表示用户u的连续波浪号使用比例。若用户u的情感表达强度strength(u)≥θStrengthMin,则用户u属于高强度情感组GHighStrength;否则用户u属于中低强度情感组GLowStrength。其中,θStrengthMin为情感表达强度最小阈值,其取值可根据实际应用情况来确定。优选地,θStrengthMin=0.15上述分组规则的形式化表述如下:IFstrength(u)≥θStrengthMinTHENu∈GHighStrengthIFstrength(u)<θStrengthMinTHENu∈GLowStrength。S153:统计输入文本中涉及的用户使用候选新词的次数。本步骤中,可以基于文本语料统计文本语料中涉及到的作者(也即用户)使用情感新词的次数。S154:基于情感表达外显组、情感表达内敛组、其他组、高强度情感组和中低强度情感组以及用户使用所述候选新词的次数,计算初始情感新词集合中各词的情感表达显著性得分和情感表达强度得分。可以根据以下公式计算情感表达显著性得分和情感表达强度得分:其中,Scoresaliency(t)和Scorestrength(t)分别表示候选新词t的情感表达显著性得分和情感表达强度得分;GHighSaliency表示情感表达外显组;GLowSaliency表示情感表达内敛组;GHighStrength表示高强度情感组;GLowStrength表示中低强度情感组;UTMap(u,t)表示用户u使用词t的次数;α1、β1、α2、β2表示权重因子,其取值可以具体的实际应用情况来确定。优选地,α1=β1=α2=1,β2=0。S155:根据情感表达显著性得分和情感表达强度得分,从初始情感新词集合中筛选高置信度情感新词。具体地,本步骤可以包括:S1552:从初始情感新词集合中分别提取情感表达显著性得分与情感表达强度得分大于0的情感新词。S1554:按照情感表达显著性得分与情感表达强度得分从高到低,对提取出的初始情感新词进行排序。S1556:分别选取得分最高的前k个初始情感新词构成基于情感表达显著性的情感新词集合和基于情感表达强度的情感新词集合;其中,k取正整数,k的取值可根据实际情况来确定。优选地,k=1000。S1558:对基于情感表达显著性的情感新词集合和基于情感表达强度的情感新词集合取交集,得到高置信度情感新词。在对基于情感表达显著性提取的情感新词集合TermSetsaliency和基于情感表达强度提取的情感新词集合TermSetstrength取交集,得到的是高置信度情感新词集合。将该高置信度情感新词集合作为最终识别出来的中文情感新词集合。下面以一优选实施例进一步详细地说明本发明实施例的技术方案。本优选实施例不应视为对本发明保护范围的不当限定。以新浪微博用户发布的微博作为输入文本(也即文本语料)。输入文本由560684条包含传统情感词或情感新词的微博文本组成,其中,共282787条微博包含不重复的5340个情感新词。本发明实施例将“大连理工大学情感词库”作为传统情感词库,并将“COAE2014评测”中“任务三:微博情感新词发现与判定”提供的情感新词列表作为情感新词识别的标准答案。S200:从文本语料中提取所有由中英文字符和数字组成的N-Gram。优选地,2≤N≤10。S202:过滤词频小于10的词以及中文旧词词库中已有的词,得到包含631117个词的候选新词集合。其中,中文旧词词库为大连理工大学情感词库、知网词库、COAE2014评测提供的旧词词库、CSDN中文分词词库。候选新词集合中的部分词及对应词频如下所示:表一:S204:利用Ansj工具对文本语料进行中文分词。S206:基于文本语料计算候选新词集合中所有词的构词能力、点互信息、灵活度和邻接熵。候选新词集合中部分词的上述四项新词发现统计指标取值如下表:表二:词构词能力点互信息灵活度邻接熵嗨森0.423.2736.751.63躺枪0.243.3670.172.72狗血0.740.78145.573.35hold住0.599.6695.853.03即送0.30-1.5439.352.99熬制0.79-0.4321.842.41吃姜0.24-0.8736.002.15跟它0.10-1.81178.741.59盖被0.05-0.8066.721.60熟的0.02-1.38571.381.63看花0.50-3.4969.502.15真能0.48-4.3485.483.23出成绩0.671.2213.501.86香精油0.830.4216.471.75给姐0.670.0149.440.08纹产0.84-0.7130.350.64S208:从候选新词集合中过滤构词能力大于等于0.1、点互信息大于等于-2、灵活度大于等于20且邻接熵大于等于1.5的词,构建新词集合。从表二可以看出,“盖被”和“熟的”这两个候选新词由于其中包含的“它”和“被”这两个字较少与其他字构成词,导致构词能力较低而会被过滤掉。“看花”和“真能”这两个候选新词由于其内部各字之间的相互联系不够紧密,导致点互信息较小而会被过滤掉。“出成绩”和“香精油”这两个候选新词由于其左右相邻的不同字较少,导致灵活度较低而会被过滤掉;“给姐”和“纹产”这两个候选新词由于其左右相邻的字的分布较不平衡,导致邻接熵较小而会被过滤掉;其余八个候选新词:“嗨森”、“躺枪”、“狗血”、“hold住”、“即送”、“熬制”、“吃姜”、“跟它”均未被过滤,因此将这八个候选新词加入新词集合中。最终得到的新词集合共包含15767个词。S210:计算新词集合中各新词的情感倾向点互信息。例如,部分新词的“情感倾向点互信息”取值如下:表三:新词SOPMI新词SOPMI嗨森20.91即送29.60躺枪29.36熬制32.86狗血4.68吃姜0.0hold住29.94跟它0.0S212:从新词集合中过滤出情感倾向点互信息的绝对值大于等于0.1的词,构建初始情感新词集合。从表三可以看出,“吃姜”和“跟它”这两个词由于情感倾向性较弱而会被过滤掉;其余六个词则加入初始情感新词集合中。最终得到的初始情感新词集合共包含15319个词。S214:基于文本语料,统计微博用户的如下写作信息:平均文本长度AvgLen(u)、连续感叹号使用比例%!+(u)、连续问号使用比例%?+(u)和连续波浪号使用比例%~+(u)以及用户使用情感新词的次数,其中不考虑发布微博总量小于10的用户。示例地,部分用户的上述写作信息如下(其中第一部分表示微博用户id):S216:设置最大文本长度为140,计算微博用户的情感表达显著性。S218:设置情感表达显著性的最大阈值、最小阈值分别为0.071、0.857,并基于该阈值对微博用户进行分组。在上面列出的5个用户中,用户“1851551315”和“2206696934”属于情感表达外显组;用户“3469725254”属于情感表达内敛组;用户“2815862634”和“2004121323”属于其他组。S220:基于微博用户的连续感叹号、问号和波浪号使用比例,计算微博用户的情感表达强度。S222:设置情感表达强度最小阈值为0.15,将微博用户划分为高强度情感组和中低强度情感组。示例地,在上面列出的5个用户中,用户“1851551315”和“2004121323”属于高强度情感组;用户“2206696934”、“3469725254”和“2815862634”均属于中低强度情感组。经过如上所述的用户情感表达方式分组,情感表达外显组中共包含870个用户,情感表达内敛组中共包含15个用户;其他组中共包含4827个用户;高强度情感组中共包含968个用户,中低强度情感组中共包含4744个用户。S224:基于情感表达外显组、情感表达内敛组、其他组、高强度情感组和中低强度情感组,并根据微博用户使用情感新词的次数,计算初始情感新词集合中所有词的情感表达显著性得分和情感表达强度得分。其中,权重因子设置为:α1=β1=α2=1,β2=0。示例地,部分初始情感新词的情感表达显著性得分和情感表达强度得分如下:S226:分别基于情感表达显著性得分和情感表达强度得分,从高到低对初始情感新词集合中的所有词进行排序,得到情感表达显著性得分列表和情感表达强度得分列表。S228:从情感表达显著性得分列表和情感表达强度得分列表中各取前1000个词,分别构造基于情感表达显著性和强度的高置信度情感新词集合。S230:对基于情感表达显著性的高置信度情感新词集合和基于情感表达强度的高置信度情感新词集合取交集,得到最终的高置信度情感新词集合,将该集合作为中文情感新词识别的输出结果。最终得到的部分高置信度中文情感新词如下:嗨森躺枪狗血hold住……在实际使用中,为防止其识别出的情感新词数量过少,将经过词频与词性过滤的分词结果加入中文情感新词识别结果中,即:取二者的并集作为最终的输出结果。具体地,用分词工具对输入文本(也即文本语料)进行分词,然后用中文旧词词库对分词后的结果进行初步过滤。之后再过滤词频小于10的词以及以下词性的词:人名、地名、团体机构名、其他专有名词、方位词、时间词、名动词、副词、代词、数词、量词、介词、连词、拟声词,最后将未被过滤出的词加入到步骤S230的结果中,共同作为中文情感新词识别的最终结果。下面给出本发明实施例与现有技术对比的结果:表四:其中,精度为识别出的情感新词中正确情感新词所占的比例;召回率为识别出的正确情感新词占所有情感新词的比例;F1值为精度和召回率的简单调和平均数。综上所述,本发明实施例具有如下优点:(1)基于多种新词发现统计指标,从字、词内部和词外部三个层次共同发现新词,在此基础上确定初始情感新词,能够有效提高情感新词识别的效果。(2)通过分析用户的情感表达方式以及用户对初始情感新词的使用情况筛选高置信度情感新词,能够进一步提高情感新词识别的精度。(3)根据用户的情感表达方式分组对识别出的情感新词进行评分并排序,能够根据实际需要确定输出的情感新词集合大小,灵活度较高。(4)各个统计指标以及用户情感表达方式指标的计算均可并行处理,适合面向海量社会媒体文本的情感新词识别。本实施例中虽然将各个步骤按照上述先后次序的方式进行了描述,但是本领域技术人员可以理解,为了实现本实施例的效果,不同的步骤之间不必按照这样的次序执行,其可以同时(并行)执行或以颠倒的次序执行,这些简单的变化都在本发明的保护范围之内。基于与方法实施例相同的技术构思,还提供一种结合用户情感表达方式的中文情感新词识别系统。该系统可以执行上述方法。如图2所示,该系统20至少可以包括:获取单元21、第一构建单元22、过滤单元23、第二构建单元24、第三构建单元25和筛选单元26。其中,获取单元21用于获取输入文本。第一构建单元22用于基于输入文本中词频大于第一预设阈值的字符串,构建候选新词集合。过滤单元23用于使用中文旧词词库对候选新词集合进行过滤。第二构建单元24用于基于统计指标从过滤的候选新词集合中筛选新词,构建新词集合;其中,统计指标为构词能力、点互信息、灵活度和邻接熵。第三构建单元25用于基于情感倾向点互信息,从新词集合中识别情感新词,构建初始情感新词集合。筛选单元26用于基于输入文本中涉及的用户的情感表达方式,从初始情感新词集合中筛选高置信度情感新词,并将其作为所识别的中文情感新词。在上述实施例中,第一构建单元22从由获取单元21获取的输入文本中提取词频大于第一预设阈值的字符串来构建候选新词集合。其中,字符串可以由中英文字符或数字组成。过滤单元23可以利用大连理工大学情感词库、知网词库、COAE2014评测提供的旧词词库、CSDN中文分词词库等中文旧词词库来对候选新词集合进行过滤。第二构建单元24可以结合字、词内部和词外部三个层次的新词发现统计指标(即构词能力、点互信息、灵活度和邻接熵)来对过滤的候选新词集合进行筛选,以构建新词集合。第三构建单元25在构建初始情感新词集合中所利用的情感倾向点互信息为:新词与正向传统情感词的点互信息之和减去新词与负向传统情感词的点互信息之和。其中,正向与负向传统情感词来自于传统情感词库,其由实际应用中的具体实施方式确定。新词与某个传统情感词的点互信息是指新词与该传统情感词共同出现于一篇文本中的概率除以各自出现概率之积的对数值。第三构建单元25选取情感倾向点互信息的绝对值大于等于第六预设阈值的新词,来构建初始情感新词集合。筛选单元26利用包括情感表达显著性和情感表达强度的用户情感表达方式从初始情感新词集合中筛选高置信度情感新词。具体地就是,筛选单元26从情感表达显著性和情感表达强度这两个维度对用户进行分组,进而根据用户分组信息以及用户的用词情况对初始情感新词进行评分,在此基础上筛选高置信度情感新词。本领域技术人员可以理解,上述结合用户情感表达方式的中文情感新词识别系统还包括一些其他公知结构,例如处理器、存储器等,为了不必要地模糊本公开的实施例,这些公知的结构在图2中未示出。应该理解,图2中的获取单元21、第一构建单元22、过滤单元23、第二构建单元24、第三构建单元25和筛选单元26的数量仅仅是示意性的。根据实现需要,它们可以具有任意的数量。需要说明的是:上述实施例提供的结合用户情感表达方式的中文情感新词识别系统在进行中文情感新词识别时,仅以上述各功能模块的划分进行举例说明,在实际应用中,可以根据需要而将上述功能分配由不同的功能模块来完成,即将系统的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。上述系统实施例可以用于执行上述方法实施例,其技术原理、所解决的技术问题及产生的技术效果相似,所属
技术领域:
的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。应指出的是,上面分别对本发明的系统实施例和方法实施例进行了描述,但是对一个实施例描述的细节也可应用于另一个实施例。对于本发明实施例中涉及的模块、步骤的名称,仅仅是为了区分各个模块或者步骤,不视为对本发明的不当限定。本领域技术人员应该理解:本发明实施例中的模块或者步骤还可以再分解或者组合。例如上述实施例的模块可以合并为一个模块,也可以进一步拆分成多个子模块。以上对本发明实施例所提供的技术方案进行了详细的介绍。虽然本文应用了具体的个例对本发明的原理和实施方式进行了阐述,但是,上述实施例的说明仅适用于帮助理解本发明实施例的原理;同时,对于本领域技术人员来说,依据本发明实施例,在具体实施方式以及应用范围之内均会做出改变。需要说明的是,本文中涉及到的流程图或框图不仅仅局限于本文所示的形式,其还可以进行划分和/或组合。附图中的标记和文字只是为了更清楚地说明本发明,不视为对本发明保护范围的不当限定。术语“包括”、“包含”或者任何其它类似用语旨在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备/装置不仅包括那些要素,而且还包括没有明确列出的其它要素,或者还包括这些过程、方法、物品或者设备/装置所固有的要素。术语第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。应注意,本文中所述的“实施例”意味着:结合实施例描述的技术特征、结构或者特性包括在本发明的至少一个实施例中。本发明的各个步骤可以用通用的计算装置来实现,例如,它们可以集中在单个的计算装置上,例如:个人计算机、服务器计算机、手持设备或便携式设备、平板型设备或者多处理器装置,也可以分布在多个计算装置所组成的网络上,它们可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。因此,本发明不限于任何特定的硬件和软件或者其结合。本发明提供的方法可以使用可编程逻辑器件来实现,也可以实施为计算机程序软件或程序模块(其包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件或数据结构等等),例如根据本发明的实施例可以是一种计算机程序产品。所述计算机程序产品包括计算机可读存储介质,该介质上包含计算机程序逻辑或代码部分,用于实现所述方法。所述计算机可读存储介质可以是被安装在计算机中的内置介质或者可以从计算机主体上拆卸下来的可移动介质(例如:采用热插拔技术的存储设备)。所述内置介质包括但不限于可重写的非易失性存储器,例如:RAM、ROM、快闪存储器和硬盘。所述可移动介质包括但不限于:光存储介质(例如:CD-ROM和DVD)、磁光存储介质(例如:MO)、磁存储介质(例如:磁带或移动硬盘)、具有内置的可重写非易失性存储器的媒体(例如:存储卡)和具有内置ROM的媒体(例如:ROM盒)。虽然本文说明了大量的具体细节。但是,应该能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实施例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。本发明并不限于上述实施方式,在不背离本发明实质内容的情况下,本领域普通技术人员可以想到的任何变形、改进或替换均落入本发明的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1