一种基于零空间投影的近红外光谱预处理方法与流程
本发明涉及近红外光谱技术领域,具体涉及一种基于零空间投影的近红外光谱预处理方法。
背景技术:
近红外光谱能够表征待测物中的多种含氢基团信息,具有采样方便、无损伤、无污染、能够在线检测等优点,非常适合用于各种复杂混合物的检测。近红外光谱检测技术目前已广泛应用于制药、烟草、石油化工及农业等领域。
近年来,近红外光谱技术结合多元校正技术,如偏最小二乘算法(Partial Least Squares,PLS)等进行定量分析越来越普遍,然而,在实际应用中,在模型建立之后,由于时间间隔的原因,测试样本与训练样本的状态可能不一致。例如,测试温度,湿度(水分),光谱基线漂移等不一致。当测试样本中的干扰程度不在训练样本包含的范围之内时,其模型不能很好的应对这些新的干扰,导致预测精度降低。
常用的近红外光谱预处理技术主要有求导(一阶导数谱,二阶导数谱),多元散射校正(Multiplicative scatter correction,MSC)(参见文献H.Martens,S.A.Jensen,and P.Geladi,“Multivariate linearity transformations for near infrared reflectance spectroscopy,”in Proc.Nordic Symp.Applied Statistics,1983,pp.205–234.)和标准正态变量校正(Standard normal variate,SNV)(参见文献R.J.Barnes,M.S.Dhanoa,and S.J.Lister,“Standard normal variate transformation and de-trending of near-infrared diffuse reflectance spectra,”Applied spectroscopy,vol.43,no.5,pp.772–777,1989.)等。
这些方法都假设光谱干扰项可由一常数项a和一乘性项b组成,通过对两种干扰项进行消除来达到校正目的。例如,一阶导数谱可以消除常数性的基线漂移,二阶导数谱在一阶导数之上,还可以消除乘性项的基线漂移。MSC和SNV分别通过估计近红外光谱中的干扰项a和b,从而对其进行校正。
现有的预处理方法的缺点主要是:在校正中没有考虑实际的干扰因素及其幅度,当测试样本的干扰项幅度超出训练样本范围时,会导致模型对新样本的预测精度降低。
现有的预处理方法只针对近红外光谱,没有考虑到建模对象的信息,预处理对建模对象的影响是未知的,可能出现由于预处理不当导致的预测效果不理想,甚至预测偏差超出设定阈值的现象。
技术实现要素:
本发明提供了一种基于零空间投影的近红外光谱预处理方法,在建模之前,对训练样本和后续预测样本进行零空间的正交投影,消除干扰因素,提高建模结果的鲁棒性,降低模型的维护频率。
一种基于零空间投影的近红外光谱预处理方法,包括:
步骤1,采集训练样本的近红外光谱以及感兴趣成分的化学值;
步骤2,依据训练样本化学值由小到大的顺序,对近红外光谱进行排序;
步骤3,除化学值最大和化学值最小的训练样本外,对其余训练样本,利用相邻两个训练样本的化学值,计算拟合权重;
步骤4,除化学值最大和化学值最小的训练样本外,对其余训练样本,利用拟合权重生成虚拟近红外光谱;
步骤5,除化学值最大和化学值最小的训练样本外,对其余训练样本,用真实近红外光谱减去虚拟近红外光谱,得到差谱,所有差谱构成差谱矩阵;
步骤6,对差谱矩阵进行主成分分析,选取表征总体95%以上的投影向量,记为P;
步骤7,将训练样本矩阵在P的正交方向进行投影,得到Xp;
步骤8,对Xp和相对应的感兴趣成分的化学值Y,利用偏最小二乘算法建模;
步骤9,对待测样本Xnew,在P的正交方向进行投影,将投影结果代入步骤8所建模型中,得到预测物质的含量。
本发明针对给定物质的定量建模问题,构造建模光谱基于该物质含量的零空间,该零空间表征了训练样本中的干扰因素,例如温度,湿度(水分),基线漂移等。建模之前,对训练样本和后续测试样本进行该零空间的正交投影,以消除这些干扰因素。在训练样本和测试样本干扰因素不一致的情况下,通过零空间投影可以显著消除两者差异,从而提高模型的鲁棒性,降低维护频率。
步骤1中的训练样本感兴趣成分的测量采用国际标准,或者国内标准,或者其他成熟的化学方法测量得到。感兴趣的成分如:总糖含量,烟碱含量等。
作为优选,步骤3中,利用下式计算拟合权重:
式中,yi-1 yi yi+1分别为第i-1,i,i+1个训练样本的感兴趣成分的化学值,i=2...N-1。
作为优选,步骤4中,第i个样本的虚拟近红外光谱的计算公式如下:
zi=wxi-1+(1-w)xi+1
其中,xi-1 xi+1分别表示第i-1个和第i+1个训练样本的真实近红外光谱,w为拟合权重。
作为优选,步骤5中的差谱矩阵为:E=[e2;e3;...;eN-1],ei=xi-zi。
本发明提供的基于零空间投影的近红外光谱预处理方法,在预处理过程中,考虑了与建模对象无关的信息(干扰因素),预先在光谱中对这些干扰因素进行正交投影,以消除这些干扰因素。由于消除的是整个干扰因素的零空间,因此,在测试样本受干扰幅度与训练样本不一致的情况下,仍然可以通过投影对其进行消除,从而使利用投影后光谱建立的模型可以长久适用,降低模型的维护频率和成本。
附图说明
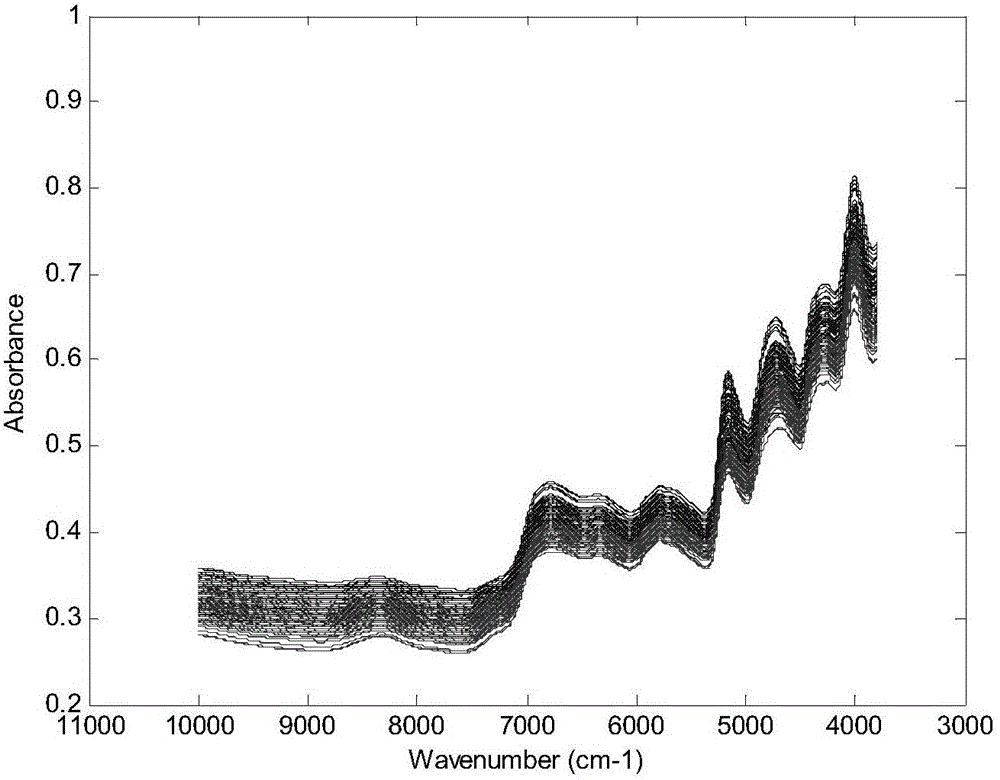
图1a为训练集和测试集的原始近红外光谱;
图1b为测试集光谱在训练集光谱中的PCA投影;
图2a为训练集和测试集的二阶导数谱;
图2b为测试集二阶导数谱在训练集二级导数谱中的PCA投影;
图3a为训练集和测试集经标准校正后的光谱;
图3b为测试集经标准校正后的光谱在训练集经标准校正后的光谱中的PCA投影;
图4a为训练集和测试集经零空间投影后的光谱;
图4b为测试集经零空间投影后的光谱在训练集经零空间投影后的光谱中的PCA投影。
具体实施方式
下面结合附图,对本发明基于零空间投影的近红外光谱预处理方法做详细描述。
一种基于零空间投影的近红外光谱预处理方法,包括:
步骤1,利用近红外光谱采集训练样本的近红外光谱数据,同时利用其它方法测量训练样本中感兴趣成分的含量。近红外光谱数据已2维矩阵形式存储,矩阵的行列分别代表训练样本的数量以及光谱维数。
步骤2,对步骤1中的获取的感兴趣成分的含量值(即化学值),将含量值按升序排序,同时,将光谱按同样的方式排序,以保证光谱与化学值的一一对应。
步骤3,除化学值最大和化学值最小的训练样本外,对其余训练样本,利用相邻两个训练样本的化学值以及下式计算拟合权重:
式中,yi-1 yi yi+1分别为第i-1,i,i+1个训练样本的感兴趣成分的化学值,i=2...N-1。
步骤4,除化学值最大和化学值最小的训练样本外,对其余训练样本,利用拟合权重生成虚拟近红外光谱。
第i个样本的虚拟近红外光谱的计算公式如下:
zi=wxi-1+(1-w)xi+1
其中,xi-1 xi+1分别表示第i-1个和第i+1个训练样本的真实近红外光谱,w为拟合权重。
步骤5,生成零空间。除化学值最大和化学值最小的训练样本外,对其余训练样本,用真实近红外光谱减去虚拟近红外光谱,得到差谱,所有差谱构成差谱矩阵,差谱矩阵为:E=[e2;e3;...;eN-1],ei=xi-zi。
步骤6,对差谱矩阵进行主成分分析,选取表征总体95%以上的投影向量,记为投影矩阵P。
步骤7,将训练样本矩阵X在P的正交方向进行投影,得到Xp;Xp=X(I-PP'),P’为投影矩阵P的转置。
步骤8,对Xp和相对应的感兴趣成分的化学值Y,利用偏最小二乘算法建模;
步骤9,对待测样本Xnew,在P的正交方向进行投影,Xnewp=Xnew(I-PP'),将投影结果Xnewp代入步骤8所建模型中,得到预测物质的含量。
本发明提供的方法与现有技术(未经预处理的原始数据建模,导数方法(一阶导数谱,二阶导数谱)、标准正态校正SNV)进行对比,通过预测集建模精度来说明本发明的有效性。
样品制备与实验设计:选取云南、湖南、湖北、山东、福建、河南等不同省份的2014年的复烤片烟111个作为训练样本。将片烟烟叶入切丝机切丝,将切好后的烟丝置于烘箱中,在40℃下干燥4h,用旋风磨(FOSS)磨碎过40目筛(泰勒制),密封平衡1d后,每个样本分为两份:一份进行近红外光谱测量,另一份利用流动分析仪按国标检测方法测得烟叶样本的总糖含量。过30天后,另取不同省份的2013年的复烤片烟57个作为测试样本,采用同样的方式进行近红外光谱和化学值采集。
图1a展示了未经预处理的训练集光谱(深色)与测试集光谱(浅色),图1b展示了测试集光谱在训练集光谱中的投影。由图中可以看出,在较长的时间间隔下,训练集光谱与测试集光谱的形态出现了一定的差异,直观而言,测试集光谱的吸收值较训练集光谱低。在PCA投影中可以发现同样的现象,即训练集光谱与测试集光谱的二维投影并不在同一区域内。
图2a展示了进行二阶导数运算的训练集光谱(深色)与测试集光谱(浅色),图2b展示了测试集光谱在训练集光谱中的投影(注意到训练集光谱在投影中非常集中)。由图中可以看出,二阶导数谱在光谱中可以消除低次项的光谱差异,但是,在投影中可以看出,二阶导运算未消除预测样本与训练样本的差异。
图3a展示了进行标准正交校正预处理后的训练集光谱(深色)与测试集光谱(浅色),图3b展示了测试集光谱在训练集光谱中的投影。由图中可以看出,标准正交校正预处理后的测试集光谱投影涵盖在训练集光谱投影的范围之内,然而,其分布与训练集光谱的投影并不一致,因此,在后期的预测中,仍会出现预测不精确的问题。
图4a展示了本发明提出的基于零空间投影预处理的训练集光谱(深色)与测试集光谱(红色),图4b展示了测试集光谱在训练集光谱中的投影。由图中可以看出,本发明方法预处理后的测试集光谱投影与训练集光谱投影的分布较为相似。这表明,虽然训练集和测试集光谱的干扰程度并不一致,但是通过构造干扰项的零空间,可以涵盖已有的干扰因素,从而降低由于采样时间导致的温度,湿度,基线漂移等因素对光谱的影响。
本发明方法与其他方法在烟叶总糖化学值模型预测效果对比,如表1所示。
表1
表1中:RMSEC:训练集根均方误差,RMSECV:训练集交叉验证根均方误差(计算方法采用5折交叉验证),RMSEP:测试集根均方误差。
由表1可以看出,本发明采用构造零空间的方法,用零空间的方式表征与研究成分无关的因素,通过投影的方式将整个干扰空间完全消除,从而提高模型的鲁棒性,提高对新样本的预测精度。
- 还没有人留言评论。精彩留言会获得点赞!