一种抓取网站数据的方法和装置与流程
本发明涉及计算机及其软件技术领域,特别涉及一种抓取网站数据的方法和装置。
背景技术:
网络爬虫(又被称为网页蜘蛛,网络机器人)是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。网页的抓取策略可以分为深度优先、广度优先和最佳优先三种,同时在网页权重判定有专门的算法,例如pagerank,即网页排名,又称网页级别、google左侧排名或佩奇排名,是google创始人拉里·佩奇和谢尔盖·布林于1997年构建早期的搜索系统原型时提出的链接分析算法,自从google在商业上获得空前的成功后,该算法也成为其他搜索引擎和学术界十分关注的计算模型。
目前,很多重要的链接分析算法都是在pagerank算法基础上衍生出来的。pagerank算法是google用于用来标识网页的等级/重要性的一种方法,是google用来衡量一个网站的好坏的唯一标准。在揉合了诸如title标识和keywords标识等所有其它因素之后,google通过pagerank来调整结果,使那些更具“等级/重要性”的网页在搜索结果中的网站排名获得提升,从而提高搜索结果的相关性和质量。pagerank算法得到的级别从0到10级,10级为满分。pr值越高说明该网页越受欢迎(越重要),那么该网页被抓取的概率也就越高。例如:一个pr值为1的网站表明这个网站不太具有流行度,而pr值为7到10则表明这个网站非常受欢迎(或者说极其重要)。一般pr值达到4,就算是一个不错的网站了。google把自己的网站的pr值定到10,这说明google这个网站是非常受欢迎的,也可以说这个网站非常重要。
现有的网络爬虫在抓取网页时都会用到pagerank算法,就是按照算法来计算网页重要性,只要网页的pr值满足要求,就会对网站的数据进行抓取,在一定程度上增加了网络爬虫的工作负载,同时也因庞大的网站数据浪费了客户的时间,进一步降低了客户的使用体验。
技术实现要素:
有鉴于此,本发明提供一种抓取网站数据的方法和装置,能够根据网站的代码质量对网站进行抓取,从而过滤掉一些代码质量差的网站,从而减少了网络爬虫的工作负载,进而也避免了客户在进行搜索的时候无需在一些代码质量不高的网站浪费时间,也在一定程度上提高了用户的使用体验。
为实现上述目的,根据本发明的一个方面,提供了一种抓取网站数据的方法。
本发明的抓取网站数据的方法包括:获取网站的网页,确定该网页的代码质量;根据所述网页的代码质量确定所述网站的抓取概率;根据所述网站的抓取概率抓取所述网站的数据。
可选地,所述确定该网页的代码质量的步骤包括:先根据如下的一种或几种方式确定各方式对应的得分:使用冗余代码检查工具确定该网页的冗余代码得分,统计重复关键词得到该网页的重复度得分,检查网页的引用库版本确定该网页的引用库版本得分,使用代码检查工具确定该网页的javascript代码质量得分,使用css代码静态检查工具确定该网页的css质量得分,统计html标签中不推荐使用的标签的个数得到该网页的标签得分;然后将所述得分之和作为该网页的代码质量。
可选地,所述网站的网页包括该网站首页以及设定数目的该网站 的二级页面;根据所述网页的代码质量确定所述网站的抓取概率的步骤包括:根据如下公式计算网页的质量平均分:网页的质量平均分=(网站的首页的代码质量分+网站的二级页面的代码质量分)/(1+网站的二级页面的数目);根据如下公式计算该网站的抓取概率,网站的抓取概率=(设定分数范围的最大值-网页的质量平均分)/设定分数范围的最大值。
可选地,根据所述网站的抓取概率抓取所述网站的数据的步骤包括:首先确定所述网站的抓取概率不小于预设的抓取概率的下限值,然后抓取所述网站的数据。
根据本发明的另一个方面,提供了一种抓取网站数据的装置。
本发明的抓取网站数据的装置包括:获取模块,用于获取网站的网页,然后确定该网页的代码质量;确定模块,用于根据所述网页的代码质量确定所述网站的抓取概率;抓取模块,用于根据所述网站的抓取概率抓取所述网站的数据。
可选地,所述获取模块还用于:首先根据如下的一种或几种方式确定各方式对应的得分:使用冗余代码检查工具确定该网页的冗余代码得分,统计重复关键词得到该网页的重复度得分,检查网页的引用库版本确定该网页的引用库版本得分,使用代码检查工具确定该网页的javascript代码质量得分,使用css代码静态检查工具确定该网页的css质量得分,统计html标签中不推荐使用的标签的个数得到该网页的标签得分;然后将所述得分之和作为该网页的代码质量。
可选地,所述网站的网页包括该网站首页以及设定数目的该网站的二级页面;所述确定模块还用于:根据如下公式计算网页的质量平均分:网页的质量平均分=(网站的首页的代码质量分+网站的二级页面的代码质量分)/(1+网站的二级页面的数目);根据如下公式计算 该网站的抓取概率,网站的抓取概率=(设定分数范围的最大值-网页的质量平均分)/设定分数范围的最大值。
可选地,所述抓取模块还用于首先确定所述网站的抓取概率不小于预设的抓取概率的下限值,然后抓取所述网站的数据。
根据本发明的又一个方面,提供了一种抓取网站数据的装置。
本发明的抓取网站数据的装置,包括:存储器和处理器,其中,所述存储器存储指令;所述处理器执行所述指令,用于:获取网站的网页,确定该网页的代码质量;根据所述网页的代码质量确定所述网站的抓取概率;根据所述网站的抓取概率抓取所述网站的数据。
可选地,所述处理器还用于:先根据如下的一种或几种方式确定各方式对应的得分:使用冗余代码检查工具确定该网页的冗余代码得分,统计重复关键词得到该网页的重复度得分,检查网页的引用库版本确定该网页的引用库版本得分,使用代码检查工具确定该网页的javascript代码质量得分,使用css代码静态检查工具确定该网页的css质量得分,统计html标签中不推荐使用的标签的个数得到该网页的标签得分;然后将所述得分之和作为该网页的代码质量。
可选地,所述网站的网页包括该网站首页以及设定数目的该网站的二级页面;所述处理器还用于:根据如下公式计算网页的质量平均分:网页的质量平均分=(网站的首页的代码质量分+网站的二级页面的代码质量分)/(1+网站的二级页面的数目);根据如下公式计算该网站的抓取概率,网站的抓取概率=(设定分数范围的最大值-网页的质量平均分)/设定分数范围的最大值。
根据本发明的技术方案,由于是从网站的代码质量的角度进行分析得到的该网站的抓取概率,因而能够过滤掉一些代码质量差的网站, 从而减少了网络爬虫的工作负载,进而也避免了客户在进行搜索的时候无需在一些代码质量不高的网站浪费时间,也在一定程度上提高了用户的使用体验。
附图说明
附图用于更好地理解本发明,不构成对本发明的不当限定。其中:
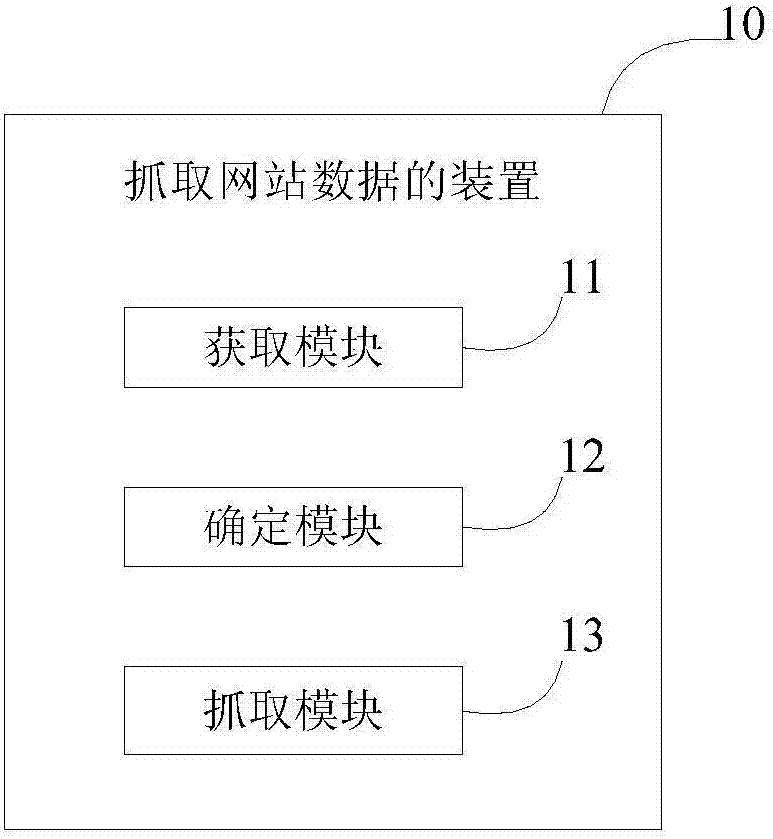
图1是根据本发明实施例的一种抓取网站数据的装置的示意图;
图2是根据本发明实施例的一种抓取网站数据的方法的示意图;
图3是根据本发明实施例的另一种抓取网站数据的装置的示意图。
具体实施方式
以下结合附图对本发明的示范性实施例做出说明,其中包括本发明实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本发明的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。
图1是根据本发明实施例的一种抓取网站数据的装置的示意图。如图1所示,本发明实施例的抓取网站数据的装置10主要包括获取模块11、确定模块12、以及抓取模块13;获取模块11用于获取网站的网页,然后确定该网页的代码质量;确定模块12用于根据所述网页的代码质量确定所述网站的抓取概率;抓取模块13用于根据所述网站的抓取概率抓取所述网站的数据;其中,网站的网页包括该网站首页以及设定数目的该网站的二级页面。
本发明实施例的抓取网站数据的装置10的获取模块11还可用于:首先根据如下的一种或几种方式确定各方式对应的得分:使用冗余代码检查工具确定该网页的冗余代码得分,统计重复关键词得到该网页的重复度得分,检查网页的引用库版本确定该网页的引用库版本得分,使用代码检查工具确定该网页的javascript代码质量得分,使用css 代码静态检查工具确定该网页的css质量得分;统计html标签中不推荐使用的标签的个数得到该网页的标签得分;然后将所述得分之和作为该网页的代码质量。
本发明实施例的抓取网站数据的装置10的确定模块12还可用于:根据如下公式计算网页的质量平均分:网页的质量平均分=(网站的首页的代码质量分+网站的二级页面的代码质量分)/(1+网站的二级页面的数目);根据如下公式计算该网站的抓取概率,网站的抓取概率=(设定分数范围的最大值-网页的质量平均分)/设定分数范围的最大值。
本发明实施例的抓取网站数据的装置10的抓取模块13还可用于首先确定所述网站的抓取概率不小于预设的抓取概率的下限值,然后抓取所述网站的数据。
图2是根据本发明实施例的一种抓取网站数据的方法的示意图。如图2所示,该方法的执行主体为图1中所提到的抓取网站数据的装置10,该方法主要包括步骤s20至s22。
步骤s20:获取网站的网页,确定该网页的代码质量。在该步骤中,首先获取网站的网页,然后根据如下的一种或几种方式确定各方式对应的得分:
使用冗余代码检查工具确定该网页的冗余代码得分;此处所提到的冗余代码指的是在网页的代码中不必要的代码段,冗余代码可以通过重复代码检查工具simian、codestyle或findbug等插件来对网页的冗余代码进行检查,从而得到网页的冗余代码得分;例如,可以设定每多n行冗余代码,则该网页的冗余代码得分加1分;其中,n≥1。
统计重复关键词得到该网页的重复度得分;meta标签是针对网页的描述,通常比较差的网页,都会为了让搜索引擎收录,而将页面描述metacontent中加入很多重复关键词,因而可以通过统计页面描述 metacontent中关键词的重复次数确定该网页的重复度得分;例如,可以设定一个关键词每重复n次,该网页的重复度得分加1分;其中n≥3。
检查网页的引用库版本确定该网页的引用库版本得分;例如,可以通过检查网页的引用库的版本号确定该网页所引用的版本库是否低于设定的引用版本库,如果低于设定的引用版本库,则该网页的引用版本得分加1分;如果不低于设定的引用版本库,则该网页的引用版本得分不变;同时,将该网页的引用版本与预先保存的稳定版本库进行对比,如果该网页的引用版本不属于所述稳定版本库中的一个,则该网页的引用版本库得分再加1分;否则,该网页的引用版本库得分不变。
使用代码检查工具确定该网页的代码质量得分;此处所提到的代码质量即指的是代码中所存在的问题,可以通过jscs等代码检查工具检查网站javascript代码所存在的问题的个数,从而确定该网页的代码质量;例如,设定通过代码检查工具确定该网页代码的问题个数,如果问题个数大于设定的问题个数的上限值,则该网页的代码质量得分加1分;否则,该网页的代码质量不变。
使用css代码静态检查工具确定该网页的css质量得分;网页的css质量可以通过检查该网页代码中使用的标签确定该网页的css质量得分;例如,检查该网页代码中使用css不推荐的标签的次数,如每使用<tr></tr>一次,则该网页的css质量得分加1分;同时检查css写在独立的标签里的次数,每检查到写在独立的标签里的n次,则该网页的css质量得分加1分;否则,该网页的css质量得分不变;其中,n≥1。
统计html标签中不推荐使用的标签的个数得到该网页的标签得分;很多html标签中包括不推荐的标签,所以可以通过将html标签与预先保存的不推荐使用的标签库进行对比得到该网页的标签得分,如 果使用不推荐使用的标签,则该网页的标签得分加1分;否则,该网页的标签得分不变。
再将上述各个得分之和作为该网页的代码质量。
步骤s21:根据所述网页的代码质量确定所述网站的抓取概率。在步骤s20中所提到的网页包括该网站首页以及设定数目的该网站的二级页面。通过步骤s20抓取网站数据的装置10确定了所抓取的网站首页以及该网站二级网页的质量;进而通过根据如下公式计算网页的质量平均分:网页的质量平均分=(网站的首页的代码质量分+网站的二级页面的代码质量分)/(1+网站的二级页面的数目),最后根据如下公式计算该网站的抓取概率,网站的抓取概率=(设定分数范围的最大值-网页的质量平均分)/设定分数范围的最大值。例如,设定分数范围的最大值为100,如果该网站的网页的质量平均分为50分,那么可以计算得到该网站的抓取概率为0.5;如果该网站的网页的质量平均分为20,则计算得到的该网站的抓取概率为0.8,也就是说一个网站的网页的质量平均分越低,则该网站的抓取概率也就越大。
步骤s22:根据所述网站的抓取概率抓取所述网站的数据。在该步骤中,抓取网站数据的装置10根据步骤s21所得到的网站的抓取概率抓取网站的数据;例如,可以设定如果所需抓取的网站的概率小于设定的抓取概率的下限值,则该网站将不会被抓取;设定抓取概率的下限值为0.4,如果步骤s21中得到的网站的抓取概率为0.35,则该网站不会被抓取。
根据本发明实施例的技术方案,由于是从网站的代码质量的角度进行分析得到的该网站的抓取概率,因而能够过滤掉一些代码质量差的网站,从而减少了网络爬虫的工作负载,进而也避免了客户在进行搜索的时候无需在一些代码质量不高的网站浪费时间,也在一定程度上提高了用户的使用体验。
图3是根据本发明实施例的另一种抓取网站数据的装置的示意图。如图3所示,本发明的抓取网站数据的装置30主要包括存储器31和处理器32;其中,所述存储器31存储指令;所述处理器32执行所述指令,用于:获取网站的网页,确定该网页的代码质量;根据所述网页的代码质量确定所述网站的抓取概率;根据所述网站的抓取概率抓取所述网站的数据;其中,所述网站的网页包括该网站首页以及设定数目的该网站的二级页面
本发明的抓取网站数据的装置30的处理器32还可用于:先根据如下的一种或几种方式确定各方式对应的得分:使用冗余代码检查工具确定该网页的冗余代码得分,统计重复关键词得到该网页的重复度得分,检查网页的引用库版本确定该网页的引用库版本得分,使用代码检查工具确定该网页的javascript代码质量得分,使用css代码静态检查工具确定该网页的css质量得分,统计html标签中不推荐使用的标签的个数得到该网页的标签得分;然后将所述得分之和作为该网页的代码质量。
本发明的抓取网站数据的装置30的处理器32还可用于:根据如下公式计算网页的质量平均分:网页的质量平均分=(网站的首页的代码质量分+网站的二级页面的代码质量分)/(1+网站的二级页面的数目);根据如下公式计算该网站的抓取概率,网站的抓取概率=(设定分数范围的最大值-网页的质量平均分)/设定分数范围的最大值。
上述具体实施方式,并不构成对本发明保护范围的限制。本领域技术人员应该明白的是,取决于设计要求和其他因素,可以发生各种各样的修改、组合、子组合和替代。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!