基于文本数据库的检索方法及系统与流程
本发明涉及数据库技术领域,尤其是涉及一种基于文本数据库的检索方法及系统。
背景技术:
对于一些需要使用数据库但是又不方便通过数据库软件来存取数据的场合,比如对于游戏的客户端软件,它往往拥有大量的配置文件,但是在客户端中想要使用数据库往往面临着一些麻烦,比如需要在客户端内嵌入数据库文件,对嵌入的数据库文件需要加密,数据文本也需要加密等等。此时使用有纯文本组成的文本数据库往往要方便很多,但是对于文本数据库的读写操作相较于应用数据库软件而言就显得很繁杂了,此时就需要一套对于文本数据库的读写方式。本专利描述的是一种处理多个文本数据库文件的数据载入读取方法。
文本数据库存储在本地文件夹中,如果需要查找文本中的某一数值,则每次都临时到对应文件中去查找,那么效率上是不理想的,不能满足实际需求;倘若把文本的内容都存储在内存中,并且能够以一种比较简便快捷的方式迅速查找到所需的值,但如果存储方法不理想,往往得不偿失。而且对于大批量的文件,倘若每一个文件都去编写一个配套的读取函数,那工作量是惊人的,并且不利于后期的维护。
技术实现要素:
本发明所要解决的技术问题是:提供一种基于文本数据库的检索方案,可提高文件查询效率,且降低工作量。
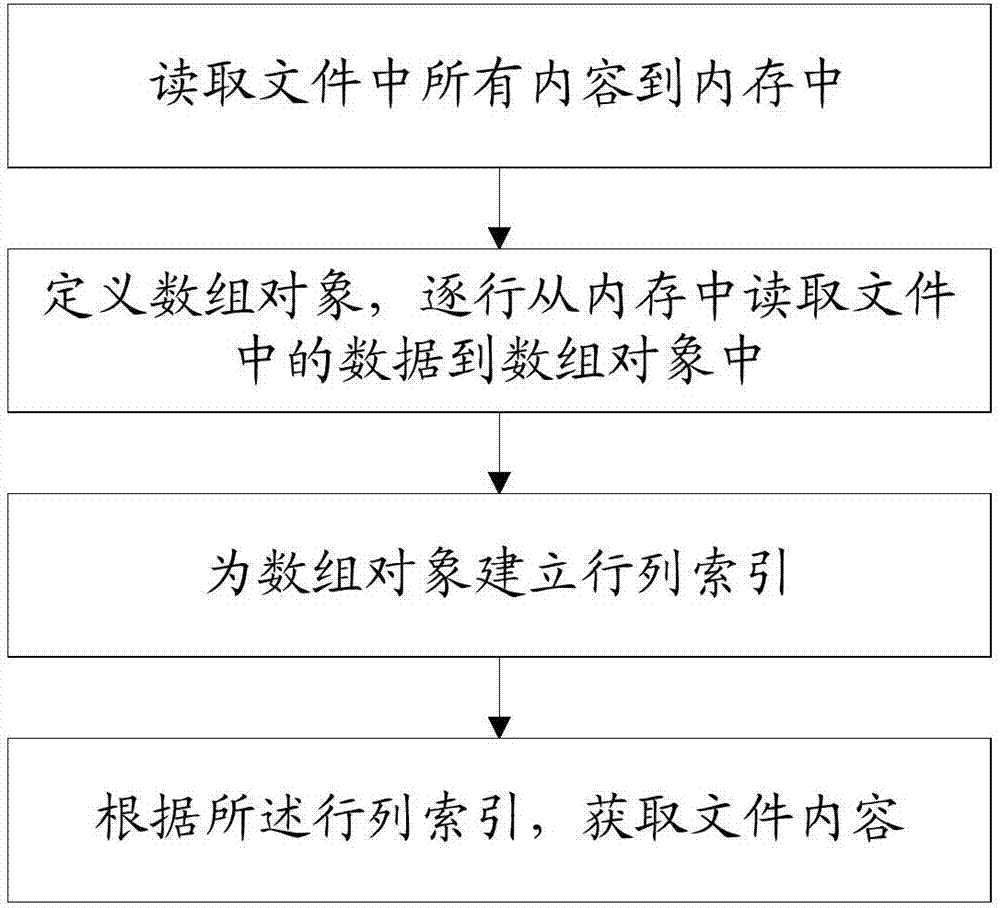
为了解决上述技术问题,本发明采用的技术方案为:提供一种基于文本数据库的检索方法,包括:
读取文件中所有内容到内存中;
定义数组对象,逐行从内存中读取文件中的数据到数组对象中;
为数组对象建立行列索引;
根据所述行列索引,获取文件内容。
为解决上述问题,本发明还提供一种基于文本数据库的检索系统,包括:
读取模块,用于读取文件中所有内容到内存中;
定义模块,用于定义数组对象,逐行从内存中读取文件中的数据到数组对象中;
索引模块,用于为数组对象建立行列索引;
查询模块,用于根据所述行列索引,获取文件内容。
本发明的有益效果在于:区别于现有技术,本发明通过读取文件内容到内存中,并定义数组对象,从内存中读取数据到数组对象中,建立行列索引后,根据该索引,可快速获取文件内容。通过上述方式,本发明可以提高检索效率,并降低工作量,节约人力。
附图说明
图1为本发明方法实施例一的流程示意图;
图2为本发明系统实施例二的结构示意图。
具体实施方式
为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。
本发明最关键的构思在于:为所有文件建立行列索引,并根据索引进一步检索所需的内容。
本发明主要是提供一种处理多个文本数据库文件的数据载入读取方案,请参照图1,本发明实施例一提供一种基于文本数据库的检索方法,包括:
s1:读取文件中所有内容到内存中;
s2:定义数组对象,逐行从内存中读取文件中的数据到数组对象中;
s3:为数组对象建立行列索引;
s4:根据所述行列索引,获取文件内容。
具体地,本发明是通过c++语言实现,并在步骤s1之前,将所有文件都看成是只具有行列属性的一张表。应当说明的是,这是本发明在具体应用中的一个抽象,所有文件都可以进行这种抽象。文本数据库可以被视为将一个数据库内的一张表的数据拷贝出来,然后存在.txt或者excel等文件中,文件内容仍然可以视为一张表,但是如果要对表进行检索,利用sql就无法实现了,只能通过文件操作来进行。随后对于这张表构造一个模板类class,class中提供打开文件并将文件的内容按行列属性存储在内存中的方法。方法具体实现过程如下:
1、打开文件,将文件内的所有内容读到内存中;
2、定义一个数组对象,保存文件的第一行数据(如第一行是列名,不是真实数据)。声明vector<char*>(即存储空间大小可变的数组对象)对象col,声明vector<vector<char*>>(可以看成是存储空间可变的二维数组对象,每一行都是一个col对象,分n列)对象line,将内存中的数据逐字段读到col中,读进去的过程中需要检查列值,若出现为空的列,用0表示,这么做的目的是在可变长数组容器中,值的存储是并列的,若出现空的值,会跳过这个值然后读取下一个值,跳过的值不计数,这样就会出现列数不对应的情况。待遇到换行符时代表一行读取完毕,此时将col的内容存入line的尾部保存下来,然后清空col中的内容后继续将新的一行数据读到col中,依次循环直到全部读取完毕,这样处理,使得源文件的行和列的顺序不会改变;
3、为line中的数据建立行列索引(纯文本文件没有索引概念),行索引的建立方式为:为每张表(即每个文件)人为定义一个集合,集合内包含表的若干属性值,这个集合被看成是对应表的主键值,然后每一行都提取主键值与对应的行号进行组合成一个元素,再定义一个映射关系,映射关系通过主键进行查找,返回此主键值所对应的行号,以此来定位已知主键值的一行数据所在行号,然后在line中查找对应行号的数据,以获得该行所有数据,查找对应行号的方法是根据数组自带的下标来获取;列索引的建立方式为:每个文件的第一行固定为该表各列的属性名,以属性名和对应的列号为组合,存入一个对象中,查找的时候通过属性名为查找条件,得到该属性所在的列号。行列索引的存在可以帮助程序快速定位到指定行列上。
例如:学生表.txt内容如下:
则先将整个表的数据读入内存,然后将第一行(列名)存入数组colname中,从第二行开始至末尾都是有效数据。把第二行整行数据从内存中读出来按列(相邻两列间有特殊符号分隔,对应编码是’\t’)检查处理好空值(比如上表第四行的性别,那就用0表示)后存入到数组col中(数组可以理解成一排连续的格子。这里再解释下下标,假设对于第二行数据存入col后,对col[0]取值得到的就是张三,col[1]就得到“3”,col[4]得到“汉”,这个0、1、4就是下标),再将col的内容存入二维数组line中,然后清空col的内容,再将下一行的数据处理好后存入col中,这样一直循环到把全部有效数据都存到了line中,此时加入我获取line[0],得到的就是一个以“张三312男汉”为内容的数组,获取line[0][0]即第0行第0列数据,也就是“张三”。
接下来建立索引:行索引:假设定义姓名+年龄组成主键,那么索引的内容第一行就是(张三,3)=1,第二行就是(李四,4)=2;列索引:内容就是:姓名=1、年级=2…民族=5。
比如要查找5年级王五的性别,先通过5年级和王五定位行号为3,然后再定位性别为第四列,那么获取line[2][3](下标从0开始)就是所需值了。
应用本发明后,从效率方面看:数据存储在内存中,需要查询哪个数据可以借助行列索引快速得到。
建立索引只需要获取主键属性,这个在建立表文件的时候一般都需要设定主键,所以基本上不需要特别去获取,只需要为每个文件定义好一个主键的类型就好了,然而为每个文件去编写一个配套的读取函数所需要的工作量就比这个大多了。
line是在内存中的,一般会作为文件数据库的数据,大都不会出现比较长 的内容(比如一个字段里是一篇文章或者其他的很多内容的数据),适用场合一般都倾向于文件字段多,但是值内容不是很多的数据,这种数据一个也才几十k,一百个也不过几m大小。
从工作量方面看:将所需要的方法都定义在了通用模板类中,免去了为每个表文件编写一个读取查询函数的困扰,节约了人力。
如图2所示,本发明实施例二提供一种基于文本数据库的检索系统100,包括:
读取模块110,用于读取文件中所有内容到内存中;
定义模块120,用于定义数组对象,逐行从内存中读取文件中的数据到数组对象中;
索引模块130,用于为数组对象建立行列索引;
查询模块140,用于根据所述行列索引,获取文件内容。
其中,在实施之前,还需要将文件抽象成具有行列属性的表,因此所述系统100还包括:
抽象模块101,用于将文件抽象成具有行列属性的表;
构造模块102,用于为所述表构造模板。
其中,所述定义模块120具体用于:
定义数组对象,包括存储空间大小可变的数组对象col及line;
将所述表的第一行数据作为列名,并保存;
从第二行开始,从内存中逐字段读取所述表中的数据到数组对象col中,直至一行完毕;
保存数组对象col内容到数组对象line尾部后,清空col中内容;
进入下一行,重复执行步骤“从内存中逐字段读取所述表中的数据到数组对象col中,直至一行完毕”直至全部读取内存中内容。
在上述读取过程中,检测列值是否为空;
若是,则忽略所述空列值,并不作计数;
反之,则继续读取后续字段,直至读取一行完毕。
所述索引模块130具体用于:
建立行索引,具体地:
为所述表定义集合,对应所述表的主键值,包括所述表的若干属性值;
逐行提取主键值及对应的行号,以组合成元素,并定义对应的映射关系;
建立列索引,具体地:
定义所述表的第一行数据为属性名;
组合属性名及对应列号,并存入数组对象col中。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!