空气质量预报方法与流程
本发明涉及数值分析技术领域,适用于大气环境分析领域,特别涉及一种空气质量预报方法。
背景技术:
随着工业化进程的发展,空气污染成为越来越严重的一个问题。城市区域是空气污染最常发生的地区,分布于珠江三角洲、四川盆地、长江三角洲、京津冀、东北平原地区的都市化城市和重工业城市空气污染的状况比其他地区更为严重。目前城市空气质量问题已受到普遍关注,其形成机理、影响、控制途径及预报预测系统的建立与发展已成为亟需解决的问题。
目前,城市空气质量多通过统计学预报法和数值预报法进行预报。统计学预报法是分析空气污染出现时的大尺度天气系统活动规律,分析中低空大气温度、相对湿度和风速等气象要素和污染物的统计学关系。该方法简单方便,但由于气象条件、气溶胶浓度、谱分布、化学成分的关系非常复杂,建立准确度较高的统计预报方程难度较大,且这种方法需要同期城市污染物和气象监测资料,预报成本较高。
数值预报法则是通过空气质量数值预报模式计算污染物浓度分布和变化规律。该方法虽具有完善的理论基础,但预报过程难度大且计算量。以美国环保局(epa)为代表,从1970年至今已开发了三代空气质量模型。第三代空气质量模式,通称为models-3,该类模式拟将所有的大气问题均考虑进模式之中,可以有效地进行较为全面的空气质量控制策略的评估。目前类似的比较常用的空气质量模式还有:eurad模式、adom模式、radm模式、uam模式、stem模式等,这些模式各有特色,各有其优缺点。前三种主要用于酸雨问题的研究,而后几种用于大气光化学和气溶胶二次污染的模拟。虽然各模式的动力框架结构不一,但所采取的化学反应机理主要是cbm-iv、radmii、以及saprc等。
国内空气质量预报根据其应用于环境决策和环境研究的目标、污染物的排放特征和污染物在大气中的相互作用、形成和转化的特点,对模型的参数和功能作修订和改进,也发展形成了具有适应区域特点的各种尺度多模型体系。第一代模型主要是高斯烟流模型,国 内第二代模式有城市尺度的空气质量预报模式(如中国科学院大气物理研究所hrdm)及区域尺度污染物欧拉输送模式(如中国科学院大气物理研究所raqm、南京大学区域酸沉降模式regadm等)。目前国内模式发展也进入第三代,以一个大气的概念,建构了从全球尺度、区域尺度及套网格的大气环境模式系列,有南京大学的区域大气环境模式系统(regaems)、中国科学院大气物理研究所的嵌套网格空气质量预报系统(naqpms[10])、中国科学院大气物理研究所全球环境大气输送模式等。
上述空气质量预报模型依赖各种排放源清单能够从全球或区域尺度进行大范围的空气质量模拟预报。每个模型根据不同的大气物理化学机理从不同角度反应了大气成分的变化,但是没有一个模型能全面包括所有的大气物化反应机理。在现有技术中,虽然采用了多模式集合预报的方法,但该方法只可针对较大范围尺度的区域(如全球)或是中等范围尺度的区域(如亚洲、中国东北地区等)进行预报,预报精度较低,并且预报过程中计算量大,耗时多。
技术实现要素:
为了解决上述问题,本发明的目的在于提供一种空气质量预报方法,对空气中一种或多种气体或颗粒物的含量进行预报,包括以下步骤、:
步骤一:采集待预报地区的历史环境数据,并将历史环境数据依次输入两个或两个以上空气质量预报模型中,分别得到两个或两个以上历史空气质量预测数据;
步骤二:将两个或两个以上历史空气质量预测数据以实际观测数据为参考数据进行修正,计算出各空气质量预报模型在最终集合计算结果中所占权重值;
步骤三:采集待预测地区的当前环境数据,并将当前环境数据依次输入两个或两个以上空气质量预报模型中,分别得到两个或两个以上初始预测数据;
步骤四:根据权重值对初始预测数据进行修正,得到最终预报数据。
本发明所涉及的空气预报方法简单实用,可针对较小范围的区域(如城市、区县等)进行预报,预报精度高,且计算过程简单,方便采样。
进一步地,历史环境数据包括第一历史排放数据、历史第一地形数据以及历史气象数据。
优选地,当前环境数据包括第一当前排放数据、当前第一地形数据以及当前气象数据。
进一步地,在步骤一中,增加采集历史第二地形数据,并将历史气象数据与历史第二地形数据分别与两个或两个以上空气质量预报模型得到的基于历史第一地形数据的历史 空气质量预测数据进行计算,分别得到两个或两个以上基于历史第二地形数据的初始预测数据。
优选地,步骤三中,增加采集当前第二地形数据,并将当前气象数据与当前第二地形数据分别与两个或两个以上空气质量预报模型得到的基于当前第一地形数据的当前空气质量预测数据进行计算,分别得到两个或两个以上基于当前第二地形数据的初始预测数据。
进一步地,在步骤一中,将历史第二地形数据,历史气象数据以及第二历史排放数据一起依次输入到两个或两个以上空气质量预报模型中,以嵌套计算的方式进行运算,分别得到两个或两个以上历史空气质量预测数据。
优选地,在步骤一中,以历史第二地形数据、历史人口分布数据和/或历史工厂分布数据对历史空气质量预测数据进行重采样运算,得到基于历史第一地形数据的历史空气质量预测数据。
进一步地,在步骤三中,将当前第二地形数据、当前气象数据以及第二当前排放数据一起依次输入两个或两个以上空气质量预报模型中,以嵌套计算的方式进行运算,分别得到两个或两个以上基于当前第二地形数据的初始预测数据。
优选地,在步骤三中,以当前第二地形数据、人口分布数据和/或工厂分布数据对历史空气质量预测数据进行重采样运算,得到基于当前第二地形数据的初始预测数据。
进一步地,空气质量预报模型为三个。
优选地,空气质量预报方法主要对空气中pm2.5、pm10、二氧化硫、二氧化氮、一氧化碳、臭氧中一种或多种的含量进行预报。
如上,本发明所涉及的空气质量预报方法预报过程简单,采样方便,且预报精确度高,还可改善因排放源数据缺乏造成的城市尺度空气质量预报精度较差的问题。
附图说明
图1为本发明空气质量预报方法的流程图。
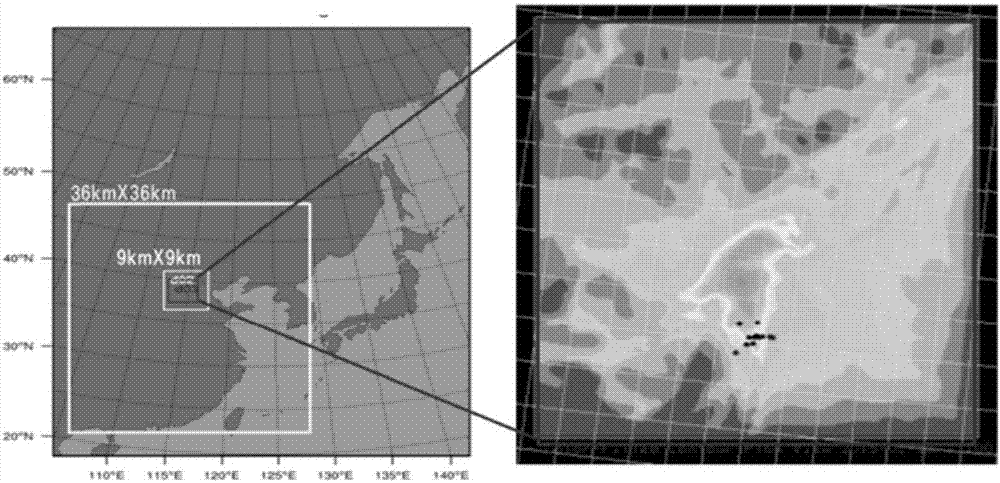
图2为空气预报分析区域示例图;
图3(a)为pm10含量预报结果示例图;
图3(b)为二氧化硫含量预报结果示例图;
图3(c)为二氧化氮含量预报结果示例图;
图3(d)为臭氧含量预报结果示例图;
图3(e)为一氧化碳含量预报结果示例图;
图3(f)为pm2.5含量预报结果示例图。
具体实施方式
具体来说,本发明所涉及的空气质量预报方法是一种基于数据同化方法和待预测地区环境数据的多模式空气质量预报方法。
以下由特定的具体实施例说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其他优点及功效。虽然本发明的描述将结合较佳实施例一起介绍,但这并不代表此发明的特征仅限于该实施方式。恰恰相反,结合实施方式作发明介绍的目的是为了覆盖基于本发明的权利要求而有可能延伸出的其它选择或改造。为了提供对本发明的深度了解,以下描述中将包含许多具体的细节。本发明也可以不使用这些细节实施。此外,为了避免混乱或模糊本发明的重点,有些具体细节将在描述中被省略。
另外,在以下的说明中所使用的“上”、“下”、“左”、“右”、“顶”、“底”,不应理解为对本发明的限制。
如图1所示,本发明提供一种空气质量预报方法,对空气中一种或多种污染物含量进行预报,在本发明的空气质量预报方法主要对空气中pm2.5、pm10、二氧化硫、二氧化氮、一氧化碳、臭氧中一种或多种的含量进行预报,包括以下步骤:
步骤一:采集待预报地区的历史环境数据,并将历史环境数据依次输入两个或两个以上空气质量预报模型中,分别得到两个或两个以上历史空气质量预测数据;
步骤二:将两个或两个以上历史空气质量预测数据以实际观测数据为参考数据进行修正,计算出各空气质量预报模型在最终集合计算结果中所占权重值;
步骤三:采集待预测地区的当前环境数据,并将当前环境数据依次输入两个或两个以上空气质量预报模型中,分别得到两个或两个以上初始预测数据;
步骤四:根据权重值对初始预测数据进行修正,得到最终预报数据。
在本发明中,历史环境数据优选包括第一历史排放数据、历史第一地形数据以及历史气象数据;当前环境数据优选包括当前排放数据、当前第一地形数据以及当前气象数据。
在步骤一中,首先采集第一历史排放数据、历史第一地形数据以及历史气象数据,利用两个或两个以上空气质量预报模型对待预报地区进行历史时段的空气质量预报,得到历史空气质量预测数据。
进一步地,待预测地区优选为城市,为了使计算所得结果更为精确,在步骤一中,增 加采集历史第二地形数据,并将历史气象数据与历史第二地形数据分别与两个或两个以上空气质量预报模型得到的基于历史第一地形数据的历史空气质量预测数据进行计算,分别得到两个或两个以上基于第二历史地形数据的历史空气质量预测数据,具体来说,即增加采集历史第二地形数据,并将历史环境数据与历史第二地形数据与基于第一地形数据的历史空气质量预测数据进行如下方式之一的操作:
方式一:采集历史第二地形数据以及待预报城市区域所对应的第二历史排放数据,并将历史第二地形数据、历史气象数据以及第二历史排放数据一起依次输入两个或两个以上空气质量预报模型中,以嵌套计算的方式分别得到两个或两个以上基于第二历史地形数据的空气质量预测数据;在该方式中,对第二历史排放数据的测量精度要求较高,以获得较为精确的计算结果。
方式二:由于在实际操作中,高精度的第二历史排放数据往往较难获得,因此,在本发明中,针对实际上缺乏高精度的第二历史排放源数据的大多数城市区域的情况,利用方式一中基于第二历史排放数据的多层嵌套计算可用基于人口分布数据和/或工厂分布数据的重采样计算替代,用以提高城市区域预报的精度。即利用历史第二地形数据,以及待预报地区的人口分布数据和/或工厂分布数据对基于历史第一地形数据计算得到的历史空气质量预测数据进行重采样运算,得到基于第二地形数据的空气质量预测数据。
在步骤二中,将步骤一中所得到的历史空气质量预测数据与已采集的实际观测数据进行比对,以实际观测数据为参考对历史空气质量预测数据进行数据同化,对历史空气质量预测数据进行修正,得到修正后的历史空气质量预测数据和误差值;再分别计算各个空气质量预报模型所得到的数据与实际观测数据的相关性,并根据相关系数计算出各空气质量预报模型在最终集合计算结果中所占权重值。
在步骤三中,采集待预测地区的当前环境数据,即第一当前排放数据、当前第一地形数据以及当前气象数据,利用多个空气质量预报模式进行未来时段的预报,并利用前述计算得到的权重进行加权集成计算得到最终的集合预报结果。
进一步地,在步骤三中,待预测地区优选为城市,为了使计算所得结果更为精确,增加采集当前第二地形数据,并将当前气象数据与当前第二地形数据分别与两个或两个以上空气质量预报模型得到的基于当前第一地形数据的当前空气质量预测数据进行计算,分别得到两个或两个以上基于当前第二地形数据的初始预测数据,具体来说,即增加采集当前第二地形数据,并将当前气象数据与当前第二地形数据与基于当前第一地形数据的当前空气质量预测数据进行如下方式之一的操作:
方式一:采集当前第二地形数据以及待预报城市区域所对应的第二当前排放数据,并将当前第二地形数据、当前气象数据以及第二当前排放数据一起依次输入两个或两个以上空气质量预报模型中,以嵌套计算的方式分别得到两个或两个以上基于第二地形数据的空气质量预测数据;在该方式中,对第二当前排放数据的测量精度要求较高,以获得较为精确的计算结果。
方式二:进一步地,由于在实际操作中,高精度的第二当前排放数据往往较难获得,因此,在本发明中,针对实际上缺乏高精度的第二当前排放源数据的大多数城市区域的情况,利用方式一中基于第二当前排放数据的多层嵌套计算可用基于人口分布数据和/或工厂分布数据的重采样计算替代,用以提高城市区域预报的精度。即利用当前第二地形数据,以及待预报地区的人口分布数据和/或工厂分布数据对基于历史第一地形数据计算得到的历史空气质量预测数据进行重采样运算,得到基于当前第二地形数据的空气质量预测数据。
其中,当前/历史第二地形数据和第二当前/历史排放数据的分辨率高于当前/历史第一地形数据和第一当前/历史排放数据的分辨率,也就是说,当前/历史第一地形数据和第一当前/历史排放数据的每一个值覆盖的空间范围较大,当前/历史第二地形数据和第二当前/历史排放数据的每一个值覆盖的空间范围较小。
进一步地,在本发明中,基于当前第二地形数据、人口分布数据和/或工厂分布数据的重采样计算方式如下:
计算待预测城市区域范围内的当前第二地形数据平均值a、人口分布数据平均值p、工厂分布数据平均值f,按下式计算城市范围内的当前第二地形数据、人口分布数据,工厂分布数据每个网格的权重w:
其中a,p,f为各类数据每个网格的实际值。
将基于历史第一地形数据的历史空气质量预测数据中的每个值按下式重采样得到基于历史第二地形数据的预测数据中的多个值:
其中,v1是基于历史第一地形数据的预测数据的值,v2是基于历史第二地形数据的预测数据的值,n为每个v1的网格对应的v2的网格数量,wi为n个网格中第i个的权重。
因此,本发明所涉及的空气质量预报方法能利用多种空气质量预报模型的侧重于不同的空气物理化学变化机理的优点,改善传统算术平均集成方法所忽略的各模型精度不同的 问题,同时对于数据缺乏的地区能够较大程度的提高区域模拟的精度。更进一步地,在本发明中,空气质量预报模型优选为三个:气象研究预报-区域建模分析系统(weatherresearch&forecast-communitymodelingandanalysissystem,下文简称wrf-cmaq)、化学物质含量预报模型(weatherresearchforecastcoupledwithchemistry,下文简称wrf-chem)、综合空气质量扩展模型(comprehensiveairqualitymodelwithextensions,下文简称camx)。在本发明中,可以根据实际所需预报的污染物种类,选择上述模型中的一个或多个进行计算。
进一步地,在本发明中,还可以采用其他各种模型替代上述模型,如wrf-chem模型可用mm5/rams/arps等模型进行替代;wrf-chem/camx模型可用aermod/adms/uam等模型进行替代。其中,mm5(mesoscalemodel5)为中尺度预报模型、rams(regionalatmospheremodelingsystem)为区域大气建模系统、arps(advancedregionalpredictionsystem)为区域预测系统、aermod(ams/eparegulatorymodel)为大气模拟预测管理模型、adms(atmosphericdiffusionmodelsystem)为大气扩散模型系统、uam(urbanatmospheremodel)为城市大气模型。
但本发明并不局限于此,还可以用其他各种模型对上述模型进行替代,以获得所需的空气污染物含量。
在本发明中,在获得将对两个或两个以上历史空气质量预测数据后,以实际观测数据为参考数据进行修正所采用的方法为数据同化的方法。数据同化是分析处理随空间和时间分布的观测资料为数值预报提供初始场的一个过程,具体包括两层基本涵义:合理利用各种不同精度的非常规观测资料,把它们与常规观测资料融合为有机的整体,为数值预报提供更好的初始场,并综合利用不同时间段所采集的观测资料,将这些资料中所包含的时间演变信息转化为要素场的空间分布状况。数据同化从最初的逐步订正法,最优插值法,到现在的变分同化和集合卡尔曼滤波已经有多种同化方法。具体来说:
初步预报值定义为背景场xb,最终修正后的目标值为分析场xa,观测值构成观测场yo1)三维变分同化中,
xa=xb+(b-1+htr-1h)-1htr-1(yo-h(x))
其中,x,y变量为矩阵,h(x)为前向算子,形如y=h(x),是分析变量到观测变量的一个计算函数,最简单的为插值函数,即:
t为矩阵转置运算;r为观测误差协方差矩阵;b为背景误差协方差矩阵。
建立目标函数如下:
jb和jo表示对背景场和观测场的拟合程度。j(x)对x的梯度函数为::
通过迭代法求
2)集合最优插值同化中,
xa=xb+w(yo-h(xb))
其中,
w=bht(htbh+r)-1
更进一步,在本发明中,在计算各空气质量预报模型所得出结果的权重时,相关或相关系数是用于反映变量之间相关关系密切程度的统计指标,相关及相关系数可通过如下方法确定:
其中,x,y分别为观测值集合,和与观测值位置时刻一致的同化后的分析值集合。
对应的基于相关系数的权重确定方案按下式确定,其中,c1、c2、c3分别代表三个模型所计算出的数值,w1、w2、w3分别代表三个数值的权重:
w1=c1/(c1+c2+c3)
w2=c2/(c1+c2+c3)
w3=c3/(c1+c2+c3)
基于上述计算方法,本发明的空气质量预报方法可以细化为如下步骤:
1、利用历史时段的数据进行预报和同化,求取多模式集合所需权重:
a)将历史气象数据,历史排放源数据和历史第一地形数据分别输入所选三个空气质量预报模式wrf-cmaq,wrf-chem,wrf-camx中,计算得到初始大尺 度低分辨率的历史空气质量预测数据。
b)利用较为精确的排放源数据,历史第二地形数据和历史空气质量预测数据进行嵌套计算,得到三个模式的初始城市尺度高分辨率空气质量预报结果。
c)如果缺乏较为精确的排放源数据,则采用历史第二地形数据,人口分布数据和/或工厂分布数据对初始低分辨率的历史空气质量预测数据进行重采样计算,首先计算权重,再按下式重采样得到城市尺度高分辨率空气质量预报结果。
d)采用三维变分同化方法,对城市尺度预报结果和历史空气质量预测数据进行同化,得到修正后的城市空气质量预报结果和误差项。
e)计算三个修正后城市空气质量预报结果和观测数据的相关性,并计算对应三个模式的权重。
2、利用当前时段的数据对未来时段的空气质量进行预报:
a)将当前气象分析数据,当前排放源数据和当前第一地形数据分别输入所选三个空气质量预报模式wrf-cmaq,wrf-chem,wrf-camx中,计算得到初始大尺度低分辨率初始预测数据。
b)利用较为精细的当前排放源数据,当前第二地形数据和当前空气质量预测数据进行嵌套计算,得到三个模式的初始城市尺度高分辨率空气质量预报结果。
c)如果缺乏较为精细的当前排放源数据,则可采用当前第二地形数据,当前人口分布数据和/或工厂分布数据对初始低分辨率预测数据进行重采样计算,在计算权重后,得到当前城市尺度高分辨率空气质量预报结果。
3、将得到的三个当前城市尺度高分辨率空气质量预测数据按照历史空气质量预测数据计算得到的集成权重值进行集合加权计算,得到最终的空气质量预报结果。
下面通过两具体实施例对本发明进行详细说明:
第一实施例:
数据源采用美国国家环境预报中心(下文简称ncep)提供的全球地理数据库,全球基础排放源数据,历史和即时的全球预报系统(下文简称gfs)气象场数据。实验所面向的区域为华北某城市范围,在3km分辨率尺度下由50*50的格网覆盖,图2显示了在嵌套计 算方式下各层所对应的范围。分析时间为2015年12月5日,预报时间为12月6日00时至9日00时,总计72小时。历史数据采用12月1日至12月5日共120小时的数据。
步骤1:输入地理数据,36km全球排放源数据和1-5日的gfs气象数据至wrf-cmaq,wrf-chem,wrf-camx三种模式中,计算初始无嵌套预报结果,得到36km格网分析结果。统计pm2.5,pm10,no2,so2,o3,co六种主要污染物。
步骤2:以嵌套计算方式处理1-5日36km分析结果,即修改三个模型中的嵌套计算方式,并输入嵌套计算后两层所需9km和3km北京区域详细排放源数据,处理得到3km分析结果。
步骤3:将1-5日3km污染物预报结果和地面观测站数据输入三维变分数据同化计算模型,计算得到同化后的三种模式的3km污染物数据。
步骤4:计算同化后三种模式3km污染物数据与地面观测数据的相关系数,分别为:0.782,0.634,0.699。并以三个相关系数,确定三个模型对应的权重值分别为:0.370,0.300,0.330.
步骤5:输入地理数据,36km全球排放源数据和6-8日的gfs气象分析数据计算三个模式的未来时段预报结果,格网大小36km。
步骤6:以嵌套方式计算6-8日3km分析结果。
步骤7:以步骤4得到的权重为系数,计算集合预报的最终结果。
步骤8,输出空气中各污染物/颗粒物浓度结果(如图3(a)至图3(f)所示)。
第二实施例:
步骤1:输入地理数据,36km全球排放源数据和1-5日的gfs气象数据至wrf-cmaq,wrf-chem,wrf-camx三种模式中,计算初始无嵌套预报结果,得到36km格网分析结果。统计pm2.5,pm10,no2,so2,o3,co六种主要污染物。
步骤2:以重采样方式处理1-5日36km分析结果。
步骤2-1:以3km分辨率的北京城区地形高度数据,人口分布数据,工厂分布数据计算重采样权重值。
步骤2-2:以3km重采样权重值为依据对36km分析结果对应区域进行重采样。
步骤3:将1-5日3km污染物预报结果和地面观测站数据输入三维变分数据同化计算模型,计算得到同化后的三种模式的3km污染物数据。
步骤4:计算同化后三种模式3km污染物数据与地面观测数据的相关系数,分别为: 0.754,0.579,0.649。并以三个相关系数,确定三个模型对应的权重值:0.382,0.291,0.327
步骤5:输入地理数据,3km全球排放源数据和6-8日的gfs气象数据计算三个模式的预报结果。
步骤6:以重采样方式计算6-8日3km分析结果。
步骤7:以步骤4得到的权重为系数,计算集合预报的最终结果。
步骤8,输出颗粒物浓度结果。
综上,本发明所涉及的空气质量预报方法通过数据同化后的精度和相关性分析来评估多个空气质量预报模式在最终集合预报结果中的贡献度,并且利用城市地形数据,人口经济数据与雾霾产生的相关性来提高初始预报的分辨率,并从而解决精细排放源数据难以获取的问题。此外,本发明经过数据同化辅助提供多模式集合预报的结果精度得到提高,还可在在显著降低数据获取成本的同时提高城市级别空气预报的精度,值得进行广泛推广应用。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!