一种基于主动学习解决商品冷启动问题的推荐方法与流程
本发明涉及推荐系统领域,具体涉及一种基于主动学习解决商品冷启动问题的推荐方法。
背景技术:
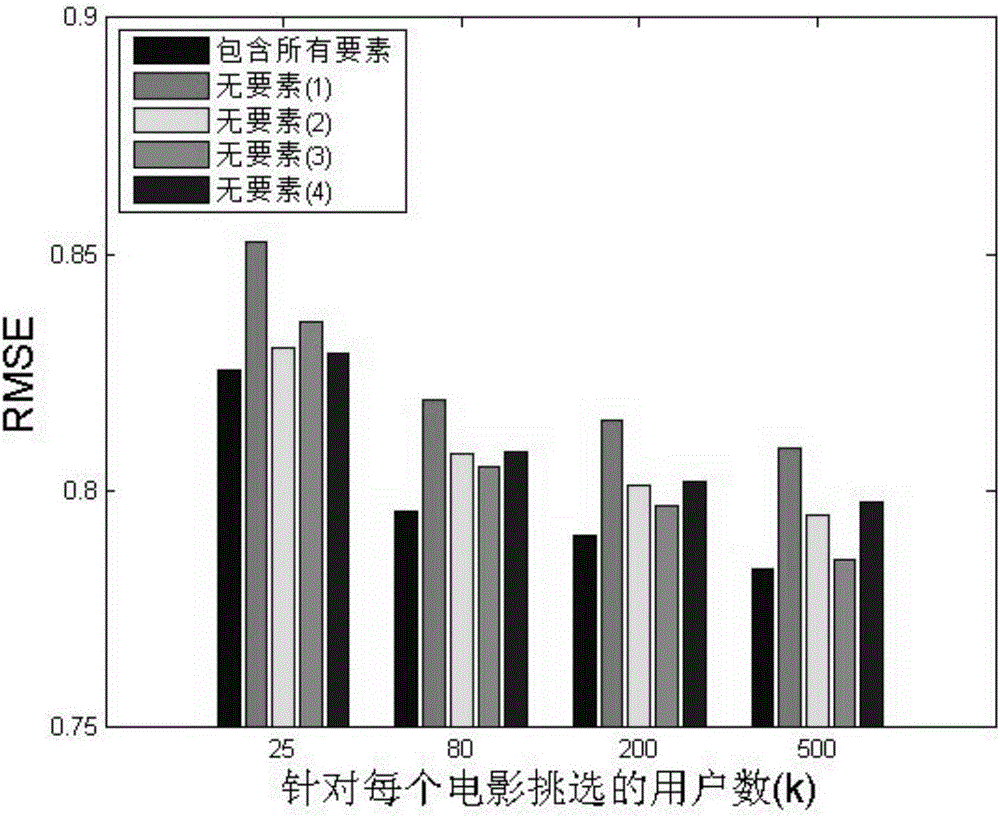
:互联网多媒体的快速发展产生了大量的信息,这一方面满足了用户对信息的需求,但另一方面,用户难以从大量信息中获取到有用的内容(信息过载),因此也降低了用户对信息的使用效率。推荐系统是解决信息过载问题的一个很有用的方法。它通过分析用户的历史行为等数据来预测用户的信息需求,从而将用户可能需要的信息直接推荐给用户。目前推荐系统已广泛应用于商品、电影、音乐、新闻等领域的推荐应用中。在这些应用中,用户对新商品(新的电影,新的音乐,新的新闻等)的了解较少,因此如何有效地将新商品推荐给用户是一个很有挑战的问题,这就是所谓的商品冷启动问题。传统解决商品冷启动问题的方法大致可以分为两类:基于内容的推荐算法和基于主动学习思想的推荐算法。基于内容的推荐算法根据商品在属性上的相似性来对新商品进行推荐,比如,一个用户购买了和某新商品相似的商品,则将该新商品推荐给该用户;基于主动学习思想的推荐算法首先挑选一些用户对新商品进行评分,然后根据这些用户的反馈来预测其他用户对新商品的喜好程度。基于内容的推荐算法利用商品属性的相似信息进行推荐,但属性相似的商品可能会有较大的品质差异,从而造成错误的推荐。比如,电影Taken3和电影Taken的编剧和很多演员是一样的,因此从属性上看它们是相似的,但IMDB网站上用户对Taken的评分很高,而对Taken3的评分不高,因此将Taken3推荐给喜欢Taken的用户很可能是个错误的推荐。传统基于主动学习思想的推荐算法并没有利用商品的属性信息来挑选用户,但实际上,商品的属性信息能让我们对新商品有一定的了解,从而提升用户挑选策略的有效性。技术实现要素:针对上述解决商品冷启动问题中传统方法存在的不足,本发明提供了一种基于主动学习解决商品冷启动问题的推荐方法,通过分析历史评分数据和商品的属性信息,合理地挑选用户对新商品进行评分,根据反馈得到的评分数据,加深对新商品的理解,从而准确地预测未挑选用户对新商品的喜好程度。一种基于主动学习解决商品冷启动问题的推荐方法,包括:步骤1,构建用户对商品的评分模型,通过用户对商品的历史评分数据和商品的属性特征对该模型进行预训练;步骤2,对于一个新商品,使用步骤1的评分模型估计出不同用户对该商品是否会评分,以及评多少分;步骤3,根据步骤2的结果,挑选用户对新商品进行评分,得到新商品上的评分数据;步骤4,利用新商品的评分数据对步骤1的评分模型进行再训练;步骤5,利用再训练的评分模型预测未挑选用户对新商品的评分,并根据该评分进行商品推荐。作为优选,步骤1中使用libFM构建如下3个模型:模型1,用于仅根据某商品的属性,预测每个用户是否会对该商品评分。用户ID和商品的属性作为特征,如果评分,则标签为1,如果不评分,则标签为0;模型2,用于仅根据某商品的属性,预测每个用户会对该商品评多少分。用户ID和商品的属性作为特征,标签为评分的数值。模型3,用于根据某商品的ID以及该商品的属性,预测每个用户会对该商品评多少分。用户ID、商品ID和商品的属性作为特征,标签为评分的数值。作为优选,步骤2中,利用步骤1构建的模型1预测每个用户是否会对新商品评分,利用步骤1构建的模型2预测每个用户对新商品评多少分。作为优选,步骤3中,挑选用户基于以下四个要素:要素1,被挑选的用户中每个用户对新商品的评分概率;要素2,被挑选的用户中任两个用户对新商品的评分的差异;要素3,被挑选的用户中每个用户对新商品的客观性评分的能力;要素4,被挑选的用户和未挑选的用户之间的相似度。作为优选,步骤3中,挑选用户对新商品进行评分,得到新商品上的评分数据,是根据求解以下目标函数计算:maxqαΣm=1|U|q(m)p(m)+βΣm=1|U|Σn=1|U|q(m)q(n)D(m,n)-γΣm=1|U|q(m)o(m)+σΣm=1|U|Σn=1|U|q(m)(1-q(n))S(m,n)s.t.q(m)∈{0,1},∀mandΣm=1|U|q(m)=k,---(1)]]>式中,U是所有的用户集合;|U|是用户总数,k是预先设定的需要挑选的用户数;m,n是用户索引;q是待求解的向量,q(m)是向量q的第m个元素,q(n)是向量q的第n个元素;α,β,γ和σ是不同项的权重;p(m):第m个用户um对新商品inew的评分概率;D(m,n):第m个用户um和第n个用户un对新商品inew评分的差异;o(m):第m个用户um对新商品inew生成客观性评分的能力;S(m,n):第m个用户um和第n个用户un的相似度。目标函数(1)中的每一项对应于挑选用户筛选标准的一个要素,具体如下:挑选用户第一项所考虑的要素是用户对新商品的评分概率,即要素1。我们定义向量p,向量中的第m个元素p(m)表示利用模型1预测第m个用户um对新商品inew的评分概率,该评分概率p(m)定义为:p(m)=willing_score(um,inew),um∈U(2)式中,um表示U中的第m个用户,inew表示新商品;willing_score(um,inew)是模型1预测用户um会对新商品inew评分的概率。通过求解目标函数(1),p(m)越大时,用户um越有可能被挑选。该要素的直观理解为:用户对新商品进行评分的概率越大,我们越倾向于挑选这些用户。因为这些用户更愿意对新商品进行评分,有较好的用户体验。同时,我们能得到更多的评分数据用于对评分模型进行再训练。挑选用户第二项所考虑的要素是用户对新商品的评分的差异,即要素2。我们定义矩阵D,矩阵中的每个元素D(m,n)表示第m个用户um和第n个用户un的评分差异,该评分差异D(m,n)定义为:D(m,n)=|Pr(um,inew)-Pr(un,inew)|12,um∈U,un∈U---(3)]]>式中:un表示U中的第n个用户,Pr(um,inew)是模型2预测用户um对新商品inew的评分数值,Pr(un,inew)是模型2预测用户un对新商品inew的评分数值。通过求解目标函数(1),D(m,n)越大时,用户um和用户un越有可能被同时挑选。该要素的直观理解为:我们倾向于挑选评分多样化的用户。相比于单一化的评分数据,多样化的评分数据能提供更多的信息量。另外,基于这些评分数据所训练的评分模型也不会偏向于某个评分区域。挑选用户第三项所考虑的要素是用户对新商品进行客观性评分的能力,即要素3。我们定义向量o,向量o中的第m个元素o(m)体现了第m个用户um生成客观性评分的能力,该客观性评分能力o(m)定义为:o(m)=1log|I(um)|1|I(um)|Σir∈I(um)(R(m,r)-R(r)‾)2,um∈U,ir∈I---(4)]]>式中:I是所有的商品集合,r是商品索引,ir表示I中的第r个商品,I(um)是用户um评过分的商品集合,R(m,r)是用户um对商品ir的评分数值,是商品ir上所有评分的均值。通过求解目标函数(1),o(m)越大时,用户um越有可能被挑选。该要素的直观理解为:我们倾向于挑选能生成客观性评分的用户。因为这些用户的评分更能体现商品本身的质量。挑选用户第四项所考虑的要素是用户之间的相似度。首先构建评分矩阵R,每个用户都是R的一个行向量,然后定义相似度矩阵S,矩阵中的每个元素S(m,n)是第m个用户um和第n个用户un的相似度,该相似度S(m,n)定义为:S(m,n)=Sim(R(m,:),R(n,:))ifm≠n0ifm=n---(5)]]>式中:R(m,:)和R(n,:)是通过评分矩阵R所表示的第m个用户和第n个用户的向量,Sim()是两个向量间的相似度函数。通过求解目标函数(1),S(m,n)越大时,用户um和用户un中越有可能一个被挑选,而另一个未被挑选。该要素的直观理解为:我们倾向于使挑选的用户和未挑选的用户相似。这样,挑选的用户对新商品的评分更能体现未挑选的用户对该商品的喜好程度。q(m)取值只能为0或1,通过求解目标函数(1)后,若q(m)=1则表示第m个用户被挑选;若q(m)=0,则表示第m个用户未被挑选。让挑选的用户对新商品进行评分,得到新商品上的评分数据。作为优选,步骤4中,将步骤3中反馈得到的评分数据加入步骤1中的模型3进行再训练,得到模型4。作为优选,步骤5中,利用步骤4的模型4预测未挑选用户对新商品的评分。本发明具有的有益效果是:(1)提供了一种新颖的解决推荐系统中商品冷启动问题的策略。使用主动学习的思想来解决商品冷启动问题,基于4个要素精心挑选部分用户对新商品评分。这些用户的反馈能更好地反映其他用户对新商品的喜好程度。(2)同时考虑每个用户的用户体验。在主动学习阶段,所挑选的用户比较乐意去对新商品评分。在预测阶段,模型能很好地预测未挑选的用户对新商品的喜好程度。这样,所挑选的用户(在主动学习阶段)和未挑选的用户(在预测阶段)都有较好的用户体验。(3)用户挑选策略具有公平性。如果经常挑选某个用户去对新商品评分,则该用户会不耐烦,从而极大地降低用户体验。我们的挑选策略是个性化的,即对于不同的新商品,所挑选的用户不同,这在一定程度上能保证挑选策略的公平性。(4)充分利用有限的用户资源。不同新商品具有不确定性,受关注程度不同。不确定性大的新商品需要得到更多的了解,以减少不确定性;了解受关注程度低的新商品意义不大。因此,通过分析新商品的属性,挑选更多的用户去对不确定性大、受关注程度高的新商品进行评分。附图说明图1表示本发明中基于主动学习解决商品冷启动问题的推荐方法的流程图。图2表示本发明实施例提出的4个要素和挑选的用户数对预测阶段预测准确率的影响。图3表示本发明实施例中根据新电影的不确定性、受关注程度合理配置用户资源的有效性的结果。具体实施方式下面将结合附图并以Movielens-IMDB数据集为例对本发明作进一步的详细说明。Movielens-IMDB数据集是一个电影数据集,包含用户对电影的历史评分数据和电影的属性数据(比如导演,演员等)。表1是该数据集的统计信息。我们随机挑选其中8000部电影,用这些电影的属性和评分数据来训练模型,从而预测剩余1998部电影的评分。前8000部电影的数据称为训练集,后1998部电影的数据称为测试集。表1如图1所示,基于主动学习解决商品冷启动问题的推荐方法包括主动学习阶段和预测阶段。主动学习阶段包括步骤1至步骤4,预测阶段包括步骤5。具体的步骤如下:步骤1,用libFM工具构建3个模型。模型1用于预测每个用户在只考虑电影属性时是否会对电影评分。所有的评分数据作为正样例,随机采样相等数量(5154925个)的未评分数据作为负样例。特征是用户ID和电影的属性,特征维度为用户数与电影的总属性数之和,某用户ID或电影属性出现则相应特征为1,否则为0。正样例的标签为1,负样例的标签为0。模型2用于预测每个用户在只考虑电影属性时会对电影评多少分。所有的评分数据是训练数据。特征是用户ID和电影的属性,特征维度为用户数与电影的总属性数之和,某用户ID或电影属性出现则相应特征为1,否则为0。评分数值为相应的标签。模型3用于预测每个用户在同时考虑电影ID及电影属性时会对电影评多少分。所有的评分数据是训练数据。特征是用户ID、电影ID和电影的属性,特征维度为用户数、电影数与电影的总属性数之和,某用户ID、电影ID或电影属性出现则相应特征为1,否则为0。评分数值为相应的标签。步骤2,对于一个新电影,利用步骤1构建的模型1和模型2估计出每个用户对该电影是否会评分,以及评多少分。对于某个特定的用户,将模型1和模型2中该用户ID和相应电影属性对应的特征赋值为1,其他特征赋值为0,预测相应的标签,共需要作2(2个模型)*|U|(|U|为用户数)次预测。用模型1预测每个用户对新电影是否会评分,可以形式化地定义如下:willingscore(um,inow),um∈U式中,各符号的定义同公式(2)。用模型2预测每个用户对新电影会评多少分,可以形式化地定义如下:式中,各符号的定义同公式(3)。步骤3,挑选用户对新电影进行评分,得到新电影上的评分数据。步骤3-1,分别构建向量p,o和矩阵D,S。其中,p为1*N(N为用户数)的向量,向量p中的第m个元素p(m)表示利用模型1预测第m个用户um对新电影inew评分的概率,即:D为|U|*|U|的矩阵(|U|为用户数),矩阵D中的每个元素D(m,n)表示第m个用户um和第n个用户un的评分的差异,定义为:D(m,n)=|Pr(um,inew)-Pr(un,inew)|12,um∈U,un∈U---(3)]]>o为1*|U|(|U|为用户数)的向量,向量o中的第m个元素o(m)表示第m个用户um生成客观性评分的能力,定义为:o(m)=1log|I(um)|1|I(um)|Σir∈I(um)(R(m,r)-R(r)‾)2,um∈U,ir∈I---(4)]]>S为|U|*|U|的矩阵(|U|为用户数),矩阵S中的每个元素S(m,n)表示第m个用户um和第n个用户un的相似度,定义为:S(m,n)=Sim(R(m,:),R(n,:))ifm≠n0ifm=n---(5)]]>步骤3-2,通过构建的向量p,o和矩阵D,S来构造目标函数并进行求解,从而挑选出用户对新电影进行评分。其中,目标函数定义为:maxqαΣm=1|U|q(m)p(m)+βΣm=1|U|Σn=1|U|q(m)q(n)D(m,n)-γΣm=1|U|q(m)o(m)+σΣm=1|U|Σn=1|U|q(m)(1-q(n))S(m,n),---(1)]]>s.t.q(m)∈{0,1},∀mandΣm=1|U|q(m)=k]]>实验中,设置α=1,β=0.3,γ=0.1,σ=0.1。对于k,进行以下两种类型的实验:一种类型是,每个新电影挑选的用户数设定值一样(该种类型方法记为FMFC),取k=25。另一种类型是,不同新电影挑选的用户数设定值不一样(该种类型方法记为FMFC-DB)。FMFC-DB能充分利用有限的用户资源,挑选更多的用户去对不确定性大、重要的电影进行评分。具体地,FMFC-DB通过如下方式对不同新电影分配挑选的用户数。首先,定义第s部新电影new_items的受欢迎程度popular(new_items):popular(new_items)=1|U|Σumwilling_score(um,new_items),s∈{1,2,......l}---(6)]]>式中,l为新电影总数,s为新电影的索引,new_items为第s部新电影,willing_score(um,new_items)是模型1预测用户um会对电影new_items评分的概率,|U|是用户总数,其他符号的定义同目标函数(1)。该定义的直观理解是,对某新电影评分的用户越多,则该电影的受欢迎程度就越高。其次,定义第s部新电影new_items的争议性controversial(new_items):controversial(new_items)=1|U|Σum∈U(Pr(um,new_items)-Pr(new_items)‾)2,s∈{1,2,......l}---(7)]]>式中,Pr(um,new_items)是模型2预测用户um对电影new_items的评分数值,为预测的所有用户对新电影new_items评分的平均值,U是所有的用户集合,其他符号的定义同公式(17)。该定义的直观理解是,用户对某新电影评分的方差越大,则该电影的争议性就越大。然后,定义新电影的一个预算得分:budget_score(new_items)=popular(new_items)+λ·controversial(new_items)(8)式中,popular(new_items)和controversial(new_items)的定义同公式(6)(7),λ用于调节受欢迎程度和争议性的权重,经实验验证,λ取值为0.78时推荐效果最好。最后,给第s部新电影分配的挑选用户数k(s)为:k(s)=budget_score(new_items)Σt=1lbudget_score(new_itemt)·ktotal,s∈{1,2,......l}---(9)]]>式中,ktotal为总共要挑选的用户次数,本发明设定ktotal=25*l,t为新电影的索引,new_itemt为第t部新电影,其他符号的定义同公式(6)(7)(8)。根据以上公式得到每部电影要挑选的用户数。通过优化目标函数(1)来挑选用户对新电影进行评分,并得到新电影的评分数据。步骤4,利用步骤3得到的新电影的评分数据,对步骤1构建的模型3进行再训练。利用步骤1中模型3的参数作为初始参数,使用libFM工具对电影的历史评分数据和步骤3得到的新电影的评分数据进行训练,得到再训练后的模型(模型4)。步骤5,利用步骤4再训练得到的模型4预测未挑选用户对新电影的评分,并根据该评分进行电影推荐。使用如下4个评价标准证明本发明方法的有效性:其中,PFR(percentageoffeedbackratings)表示评分请求的反馈率,PFR的分母是发送的总评分请求个数(数值上等于挑选的总用户次数ktotal),分子是实际上得到反馈的评分个数。该数值是小于1的,因为存在一部分被挑选的用户没有对新电影进行评分。PFR越高,则表示主动学习阶段所挑选的用户更乐于对新电影进行评分,这些用户的用户体验也越好。同理,AST(AverageSelectingTimes)表示平均每个用户接收到的评分请求个数,AST的分母是接收评分请求的不同用户数(一个用户可能接收多次评分请求,但用户数只算一个),分子是发送的总评分请求个数。AST越高,则表示主动学习阶段经常挑选相同的用户去对不同的新电影评分,这些用户会不耐烦,从而产生不好的用户体验。RMSE(RootMeanSquareError)表示用户评分的均方根误差,MAE(MeanAbsoluteError)表示用户评分的平均绝对误差。RMSE和MAE都是针对预测阶段,用于评价未挑选用户对新电影评分的预测准确率。其中,Rtest是Movielens-IMDB的测试集中有评分的{用户,电影}配对集合,R(um,inew)是该测试集中用户um对新电影inew的真实评分,是用户um对新电影inew的预测评分,其他符号同目标函数(1)。RMSE、MAE越低,则表示预测阶段未挑选用户对新电影评分的预测准确率越高。表2是本实施例方法(包括提及的FMFC与FMFC-DB)与其他传统算法HBR(Hybrid-basedRecommendation,即混合推荐法)、FM(FactorizationMachineswithoutActiveLearning,即传统因子分解机推荐法)、FMRS(FactorizationMachineswithRandomSampling,即随机采样的因子分解机推荐法)、FMPS(FactorizationMachineswithPopularSampling,即流行度采样的因子分解机推荐法)、FMCS(FactorizationMachineswithCoverageSampling,即覆盖率采样的因子分解机推荐法)、FMES(FactorizationMachineswithExplorationSampling,即探索采样的因子分解机推荐法)在上述4个评价标准上的实验结果。由表2可知,本实施例的RMSE、MAE低于所有传统算法,表示在预测阶段本实施例有较好的预测准确率。本实施例的PFR高于所有传统算法,说明本实施例不仅在预测阶段具有较好的预测准确率,而且在主动学习阶段,挑选的用户大部分都乐于对新电影进行评分,这些用户因此也有较佳的用户体验。本实施例的AST低于大部分传统算法,但高于FMRS(FMRS在主动学习阶段随机挑选用户对新电影评分,其他过程和本实例一样),这是容易理解的,因为FMRS在主动学习阶段随机挑选用户,使得每个用户被挑选的概率相同,所以从公平性的角度来说FMRS是最好的。另外,HBR和FM是基于内容的推荐算法,没有主动学习过程,因此,表2中这两种算法没有PFR和AST。表2RMSEMAEPFR(%)ASTHBR0.87310.6696xxFM1.030.7769xxFMRS0.91770.72765.219.99FMPS0.84620.650326.061998FMCS0.84480.648927.501998FMES0.90880.69996.401998FMFC0.82550.631628.98128.41FMFC-DB0.81930.626129.49107.19图2表示本发明实施例提出的4个筛选要素和挑选的用户数对预测阶段预测准确率(RMSE)的影响。其中,“包含所有要素”,“无要素(1)”,“无要素(2)”,“无要素(3)”,“无要素(4)”分别自左向右对应使用全部筛选要素,缺少筛选要素1,缺少筛选要素2,缺少筛选要素3和缺少筛选要素4的实验结果,x轴表示挑选的用户数,y轴表示RMSE的结果。从图2可以看出,4个筛选要素都能提升预测阶段的预测准确率,从而证明了4个筛选要素的高有效性。增加挑选的用户数也能提升预测准确率,这是容易理解的,因为挑选的用户数越多,我们对新电影的了解就越多,从而能更好地预测其他未挑选用户对该电影的喜好程度。图3表示本发明实施例中根据新电影的不确定性、受关注程度合理配置用户资源的有效性的结果,主要指本实例提出的FMFC和FMFC-DB用RMSE和PFR作为评价标准时的实验结果。其中,x轴表示所有电影总共要挑选的用户次数(即ktotal)。从图3可以看出,在ktotal取不同值时,FMFC-DB都比FMFC的效果更好。这表明本发明提出的根据新电影的不确定性,受关注程度来合理配置用户资源是有效的。以上所述仅为本发明的实施举例,并不用于限制本发明,凡在本发明精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1