一种基于用户评价信息的商品舆情分析方法及系统与流程
本发明涉及数据挖掘和舆情分析技术,具体涉及一种基于用户评价信息的商品舆情分析方法及系统。
背景技术:
近年来电子商务发展迅速,人们越来越依赖于诸如京东、天猫、淘宝等电商平台进行购物。在这些电商平台上,用户不仅可以详细地了解商品信息,还可以通过已购买用户的评价,进一步了解商品的使用效果。另一方面,由于商家较难收集消费者对线下销售产品的评价信息,因此分析电商平台上用户对产品的评价信息是了解商品舆情的重要途径,对商家和用户均具有很高价值。
例如:以下为从京东商城获取的某品牌电视机的用户评价数据:
电视屏幕还不错,自带芒果tv太坑,好看的全要vip,并不是智能机,还是选智能机好。
电视功能不好,但是便宜,不能装软件。
没有服务人员联系我。
价格很便宜,声音像是电梯里电视那种小喇叭声,没法听。上门安装底座居然也要收50元。最倒霉的是底座不稳,一碰就倒了,一倒屏幕就碎了,打电话客服说换屏比换电视贵,所以也没法修了。2400块钱看了不到3星期就废了,很不开心!
电视像素不理想,外形还可以吧。
……
通过对评价数据进行分析,我们发现产品的如下特征:屏幕还不错、功能不好、价格便宜、底座不稳、像素不理想、外形还可以等。这样的舆情信息,一方面可以帮助用户快速了解商品的优劣;另一方面则能够帮助商家快速准确地发现自己产品和服务的问题,并根据与竞争对手产品的比较,发现自己的优势与不足,进而有针对性的改善产品、服务的质量,提升企业核心竞争力。
因此本申请有必要提出一种基于用户评价信息的商品舆情分析方法及系统。
技术实现要素:
本发明所要解决的技术问题是:提出一种基于用户评价信息的商品舆情分析方法及系统,快速有效的发现消费者对所购商品的情感,并在此基础上进行商品舆情分析。
本发明解决其技术问题所采用的技术方案是:一种基于用户评价信息的商品舆情分析系统,包括爬虫模块、数据预处理模块、情感分析模块、词典构造模块和可视化模块;
所述爬虫模块,用于对电子商务平台进行数据爬取,获得商品的基本信息及用户对商品的评价数据,并进行分类写入评价文本数据库中;
所述数据预处理模块,用于对商品的评价数据进行预处理,生成可供进一步分析的特征向量;
所述情感分析模块,用于提取特征向量中的典型特征,分析用户对典型特征的情感和对产品的总体情绪;
所述词典构造模块,用于对分词词库进行收集和融合以形成分词词典,从而供数据预处理模块进行分词和标注词性;还用于构建情感词典,从而供情感分析模块标注极性;
可视化模块,用于在Web端对情感分析模块的分析结果进行可视化展示。
作为进一步优化,所述爬虫模块对电子商务平台进行数据爬取,获得商品的基本信息及用户对商品的评价数据包括:
爬虫模块从指定的种子站点开始,以宽度优先模式从互联网爬取网页,针对每一个爬取到的网页,分析页面源代码,并进行解析,获取网页内相关的信息:产品特征和用户评价。
作为进一步优化,所述数据预处理模块对商品的评价数据进行预处理,生成可供进一步分析的特征向量,包括:
数据预处理模块首先基于分词词典对用户的评价数据进行分词处理,在分词结果的基础上,采用关联规则挖掘算法Apriori在评价文本数据库中发现高频名词及名词词组,并将其视为典型特征;对于包含典型特征的评价文本,数据预处理模块在去除该文本中的停用词后,发现文本中离名词或名词词组最近的形容词,进而生成形如[特征,观点]的特征向量。
作为进一步优化,所述情感分析模块提取特征向量中的典型特征,分析用户对典型特征的情感和对产品的总体情绪,包括:
对于特征向量中的每一个元素,情感分析模块在情感词典内寻找与典型特征及其观点相对应的极性,并将[评论,特征,观点,极性]写入数据库;
情感分析模块从评价数据库内选择部分数据作为训练数据集,采用支持向量机的方法对总体情感进行分类:
首先,对训练数据集进行标记,并对其中的形容词进行词频统计,提取出现频率较高的形容词作为样本特征;然后,将每个训练样本进行转换,将其转换为如下格式:<标记>特征1:个数特征2:个数……特征n:个数,其中<标记>取值为positive或negtive;最后,将转换后的训练数据输入到LIBSVM库中进行分类训练;训练出的分类结果随后被应用到实际数据中,帮助分析用户评价文本的总体情感。
作为进一步优化,所述可视化模块在Web端对情感分析模块的分析结果进行可视化展示,展示内容包括:产品的好评/差评率;正面及负面典型特征,并返回与特征相关的原始评论;帮助用户选择不同品牌及该品牌下的产品。
此外,本发明的另一目的还在于提出一种基于用户评价信息的商品舆情分析方法,其包括以下步骤:
a.对电子商务平台进行数据爬取,获得商品的基本信息及用户对商品的评价数据,并进行分类写入评价文本数据库中;
b.对商品的评价数据进行预处理,生成可供进一步分析的特征向量;
c.提取特征向量中的典型特征,分析用户对典型特征的情感和对产品的总体情绪;
d.在Web端对情感分析模块的分析结果进行可视化展示。
作为进一步优化,步骤a中,所述对电子商务平台进行数据爬取,获得商品的基本信息及用户对商品的评价数据的方法是:
爬虫模块从指定的种子站点开始,以宽度优先模式从互联网爬取网页,针对每一个爬取到的网页,分析页面源代码,并进行解析,获取网页内相关的信息:产品特征和用户评价。
作为进一步优化,步骤b中,所述对商品的评价数据进行预处理,生成可供进一步分析的特征向量的方法包括:
数据预处理模块首先基于分词词典对用户的评价数据进行分词处理,在分词结果的基础上,采用关联规则挖掘算法Apriori在评价文本数据库中发现高频名词及名词词组,并将其视为典型特征;对于包含典型特征的评价文本,数据预处理模块在去除该文本中的停用词后,发现文本中离名词或名词词组最近的形容词,进而生成形如[特征,观点]的特征向量。
作为进一步优化,步骤c中,所述提取特征向量中的典型特征,分析用户对典型特征的情感和对产品的总体情绪的方法包括:
对于特征向量中的每一个元素,情感分析模块在情感词典内寻找与典型特征及其观点相对应的极性,并将[评论,特征,观点,极性]写入数据库;
情感分析模块从评价数据库内选择部分数据作为训练数据集,采用支持向量机的方法对总体情感进行分类:
首先,对训练数据集进行标记,并对其中的形容词进行词频统计,提取出现频率较高的形容词作为样本特征;然后,将每个训练样本进行转换,将其转换为如下格式:<标记>特征1:个数特征2:个数……特征n:个数,其中<标记>取值为positive或negtive;最后,将转换后的训练数据输入到LIBSVM库中进行分类训练;训练出的分类结果随后被应用到实际数据中,帮助分析用户评价文本的总体情感。
作为进一步优化,步骤d中,在Web端对情感分析模块的分析结果进行可视化展示时,所述展示内容包括:
产品的好评/差评率;正面及负面典型特征,并返回与特征相关的原始评论;帮助用户选择不同品牌及该品牌下的产品。
本发明的有益效果是:利用爬虫模块获取电商平台上商品的用户评价数据,经过数据预处理,再结合所构建的情感词典对评价数据进行情感分析,得到商品的典型特征以及每条评价的整体极性,通过可视化模块,展示个用户和商家,以帮助用户快速了解商品的优劣,帮助商家快速准确地发现自己产品和服务的问题,并根据与竞争对手产品的比较,发现自己的优势与不足,进而有针对性的改善产品、服务的质量,提升企业核心竞争力。
附图说明
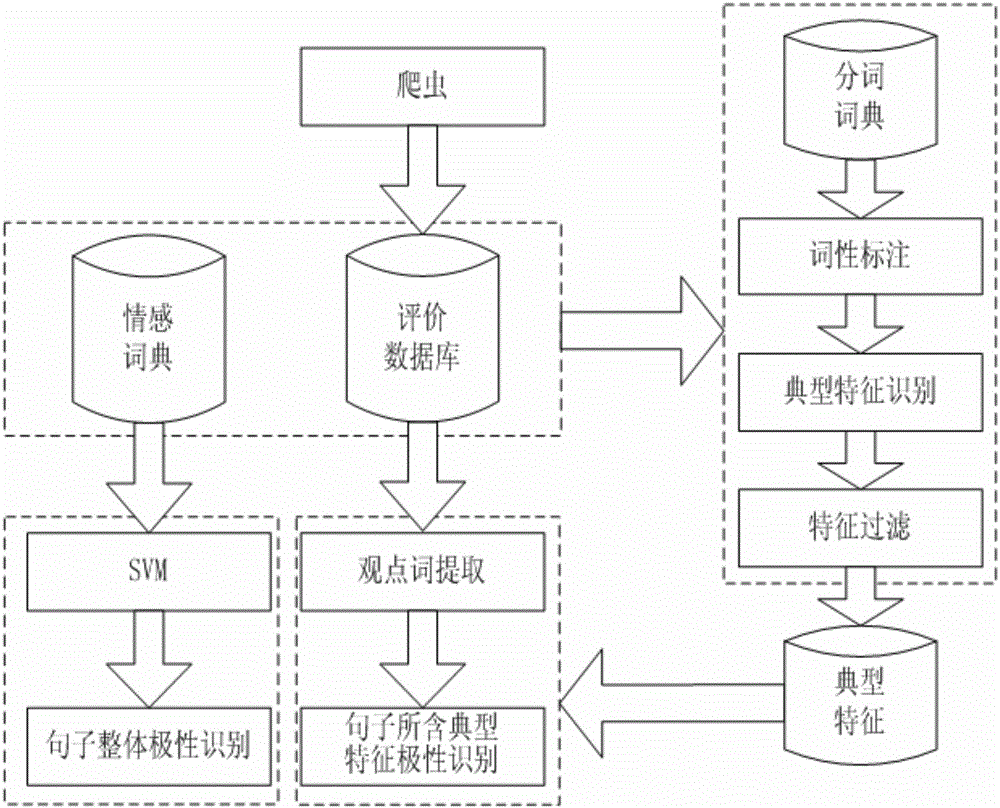
图1为基于用户评价信息的商品舆情分析系统结构框图;
图2为基于用户评价信息的商品舆情分析流程简图。
具体实施方式
如图1所示,本发明中基于用户评价信息的商品舆情分析系统包括:
(一)爬虫模块(Crawler Module,简称CM)
CM的主要工作流程如下:(1)从指定的种子站点(起始网站)开始,以宽度优先的模式,从互联网爬取网页;(2)针对每一个爬取到的网页,分析页面源代码,并进行解析,进行获取网页内相关的信息,如产品特征,用户评价等;(3)将有关信息分类写入数据库。
(二)数据预处理模块(Data Preprocessing Module,简称DPM)
(1)DPM首先对用户的评价文本进行分词处理。分词采用了中科院研发的中文分词算法及工具包;(2)在分词结果的基础上,DPM采用关联规则挖掘算法Apriori在评价文本库中发现高频名词及名词词组,并将其视为典型特征;(3)对于包含典型特征的评价文本,DPM在去除该文本中的停用词后,发现文本中离名词(或名词词组)最近的形容词,并生成形如[特征(名词),观点(形容词)]的一组特征向量,如:例一中的[屏幕,不错]、[功能,不好]、[价格,便宜]、[底座,不稳]、[像素,不理想]、[外形,还可以]。
(三)情感分析模块(Sentiment Analysis Module,简称SAM)
对于待分析的特征向量,SAM结合情感词典逐一对特征向量中的每一个典型特征进行极性标注。考虑到中文环境下,极性不仅取决于形容词,同时也和与之关联的名词有关,例如[水平,高]和[价格,高]虽然都有形容词“高”,然而极性却截然相反。因此对于特征向量中的每一个元素,SAM在情感词典内寻找与典型特征及其观点相对应的极性,并将[评论,特征,观点,极性]写入数据库。
此外,SAM从评价数据库内选择部分数据作为训练数据集,采用支持向量机(SupportVector Machine,简称SVM)的方法对总体情感进行分类,分类计算采用了LIBSVM库。具体的实现步骤如下:首先,对训练数据集进行标记,并对其中的形容词进行词频统计,提取出现频率较高的形容词作为样本特征。其次,将每个训练样本进行转换,将其转换为如下格式:<标记>特征1:个数特征2:个数……特征n:个数(<标记>取值为positive或negtive)。最后,将转换后的训练数据输入到LIBSVM中进行分类训练。训练出的分类结果随后被应用到实际数据中,帮助分析用户评价文本的总体情感。
(四)词典构造模块(Dictionary Building Module,简称DBM)
为了提高分词效果,我们收集了多个词库,并将它们进行融合,形成了较为全面的词库,用于分词和标注词性。此外,我们还以[特征,观点]为对象,构建了情感词典,以正确标注极性(正面(positive)或负面(negative))。
(五)可视化模块(Visualization Module,简称VM)
VM将分析结果在Web端进行展现,主要可视内容包括(1)产品的好评/差评率;(2)正面(positive)及负面(negative)典型特征,并返回与特征相关的原始评论;(3)帮助用户选择不同品牌及该品牌下的产品。
a.对电子商务平台进行数据爬取,获得商品的基本信息及用户对商品的评价数据,并进行分类写入评价文本数据库中;
b.对商品的评价数据进行预处理,生成可供进一步分析的特征向量;
c.提取特征向量中的典型特征,分析用户对典型特征的情感和对产品的总体情绪;
d.在Web端对情感分析模块的分析结果进行可视化展示。
图2示意了本发明基于用户评价信息的商品舆情分析方法,其包括:
1、爬虫模块对电子商务平台进行数据爬取,获得商品的基本信息及用户对商品的评价数据,并进行分类写入评价文本数据库中;
2、数据预处理模块基于分词词典对用户的评价数据进行分词处理,对分词结果进行词性标注、典型特征识别和特征过滤,进而形成特征向量;
3、情感分析模块提取特征向量中的典型特征,结合情感词典基于支持向量机(简称SVM)的方法对总体情感进行分类,分析用户对典型特征的情感和对产品的总体情绪;
4、在Web端对情感分析模块的分析结果进行可视化展示。
- 还没有人留言评论。精彩留言会获得点赞!