基于分布式存储的关联信息索引系统及其建立与使用方法与流程
本发明属于计算机分布式数据库技术领域,具体涉及一种基于分布式存储的关联信息索引方法,为一种用于提高方法分布式数据库中关联信息查询效率的方法。
背景技术:
随着互联网的发展和应用,人类社会产生了越来越多的数据信息。为了存储这些海量数据,分布式数据库应运而生。一般数据库为了提高查询效率,往往对数据库中的元组部分属性创建索引。这种方法,对于费海量的数据查询十分高效。由于分布式数据库中存有海量数据,因此当数据增长到一定规模时,使用索引查询数据也十分缓慢,难以达到预期效果。对于一些特定应用,在数据库中查询关联元组信息,这种情况将将更加耗时和低效。如果存在一种基于分布式存储的关联信息索引方法,那么在处理这种问题时,将会大大提高查询效率。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供一种基于分布式存储的关联信息索引系统及其建立与使用方法,提高在分布式数据库中查询关联信息的效率;它基于现有的数据库索引技术,提供一种策略,当在量的分布式海数据库中进行关联信息查询时,会大幅提高查询效率。
技术方案:为实现上述目的,本发明采用的技术方案为:
一种基于分布式存储的关联信息索引系统,分布式数据库中所有元组按照关联性划分成若干分类组,设置二级索引系统进行查找定位,其中,
一级索引为:每一个分类组设置一个索引,即为分类组索引;
二级索引为:一个分类组中的一个元祖的索引,即为分类组元组索引。
进一步的,二级索引存放一个分类组中的一组具有关联的元组信息,表示为A1(a11,a12,...,a1k),A2(a21,a22,...,a2m),...An(an1,an2,...,anl),其中,Ai是一个二级索引组,存放所述二级索引;
一级索引存放所述二级索引组的索引信息,表示为I(f(A1),f(A2),...,f(An)),其中,I是一个一级索引组,存放所述一级索引。
一种基于分布式存储的关联信息索引的建立方法,具体包括如下步骤:
步骤一、遍历分布式数据库中所有元组;
步骤二、使用算法处理所述元组,将具有关联的元组划分到一个分类组中,形成若干分类组;
步骤三、为一个分类组中的具有关联的一个元组根据其属性创建一组索引,即为二级索引;建立一个二级索引组,存放此分类组中的所有二级索引;
步骤四、为所述每一个二级索引组创建一个索引,即为一级索引;建立一个一级索引组,存放所有一级索引。
进一步的,所述步骤二中使用关联规则算法模型处理所述元组,对所有元组的数据进行关联、分类。
进一步的,所述关联规则算法模型的方法中进行阈值设定,包括关联规则中的置信度和支持度。
一种基于分布式存储的关联信息索引的使用方法,采用关键词查询关联元组信息,具体步骤包括:
1.查询所述关键词所在的一级索引,再从一级索引中去查找所有满足条件的二级索引;
2.确定了二级索引之后,直接到所述分布式数据库中去查找所有关联的元组信息;
3.输出结果。
有益效果:本发明提供的基于分布式存储的关联信息索引系统及其建立与使用方法,优点主要有:
1.使用高效的关联规则算法。高效的关联规则算法可以很好地将有强关联的元组信息关联到一起,方便之后为具有关联的元组创建索引;
2.通过创建二级索引提高查询效率。将具有强关联的元组关联到一起,然后为他们创建索引。并对每个组创建一个唯一标识的索引。相当于创建一个二级索引,这就大大提高了分布式数据库的查询效率。
3.实现了关联规则和创建索引的实时更新。系统会在不受外界干扰的条件下,根据关联规则设定的阈值,实时更新关联后的元组信息和索引信息。这样用户在查询分布式数据库关联元组信息时,就能根据实时信息,提高查询的效率。
附图说明
图1为创建索引整体流程图;
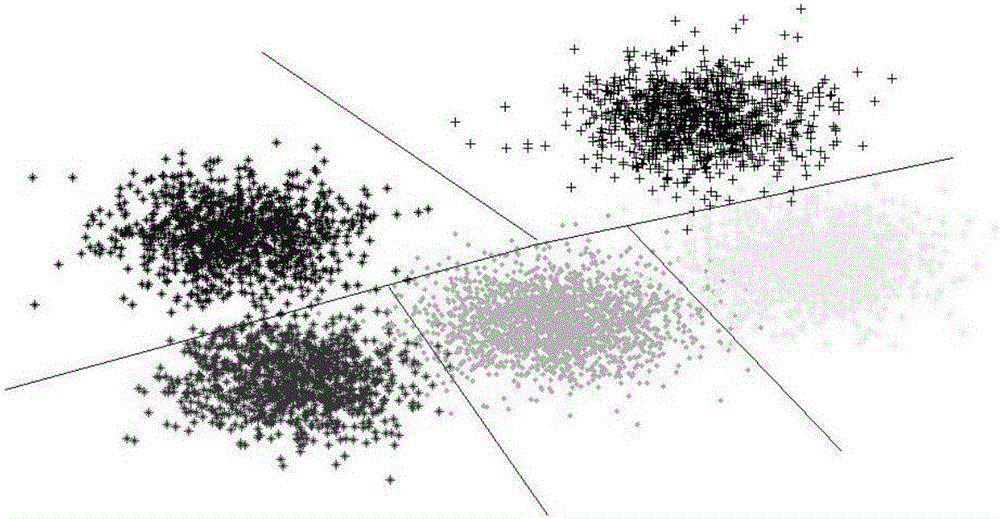
图2为分类结果图;
图3为建立索引流程图;
图4为查询流程图;
图5为一级索引和二级索引之间的逻辑关系;
图6为本发明实施例检索时效对比示意图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
一种基于分布式存储的关联信息索引系统,分布式数据库中所有元组按照关联性划分成若干分类组,设置二级索引系统进行查找定位,其中,
一级索引为:每一个分类组设置一个索引,即为分类组索引;
二级索引为:一个分类组中的一个元祖的索引,即为分类组元组索引。
一级索引就是分类组的索引,我们称之为分类组索引;二级索引就是这个分类组中的一个元祖的索引,我们称之为分类组元组索引。
二级索引存放一个分类组中的一组具有关联的元组信息,表示为A1(a11,a12,...,a1k),A2(a21,a22,...,a2m),...An(an1,an2,...,anl),其中,Ai是一个二级索引组,存放二级索引,即为存放一组有关联的分类组元组索引信息;
一级索引存放二级索引组的索引信息,表示为I(f(A1),f(A2),...,f(An)),其中,I是一个一级索引组,存放一级索引。
上述的一种基于分布式存储的关联信息索引的建立方法,具体包括如下步骤:
步骤一、遍历分布式数据库中所有元组;
步骤二、使用关联规则算法模型处理元组,将具有关联的元组划分到一个分类中,形成若干分类组;关联规则算法模型的方法中进行阈值设定,包括关联规则中的置信度和支持度;
步骤三、为一个分类组中的具有关联的一个元组属性创建一组索引,这些索引就是即为二级索引;讲这些二级索引存放在一个数组中,也就是二级索引组,存放此分类组中的所有二级索引;
为同一个分类组中具有关联的元组属性建立一个二级索引组,所有同一分类的元组属性的索引都包含在这个组内,这样形成若干个二级索引组,假设有N个分类,那么就形成N个二级索引组,这些索引被称之二级索引。
步骤四、为这N个二级索引组中的每一个二级索引组再各自创建一个索引,即为一级索引;这些一级索引被存放在一个新的数组内,即为一级索引组,存放所有一级索引。
上述的一种基于分布式存储的关联信息索引的使用方法,采用关键词查询关联元组信息,具体步骤包括:
1.查询关键词所在的一级索引,再从一级索引中去查找所有满足条件的二级索引;
2.确定了二级索引之后,直接到分布式数据库中去查找所有关联的元组信息;
3.输出结果。
查询时,首先查询一级索引,在一级索引中确定要继续查找的二级索引。一级索引和二级索引之间的关系如图5所示。
本发明中,使用了二级索引来提高检索的效率。使用二级索引,可以大大加快对数据的找查与定位。二级索引中的一级索引存放具有关联的元组的索引入口的索引信息,二级索引存放一组具有关联的元组信息。查询时,会首先定位到一级索引的位置,一级索引相当于提供入口信息,然后再在该索引下继续查找符合条件的关联索引信息。
本发明中,为了提高关联程度,专门使用了关联规则算法,并通过实验设定阈值以期达到比较好的效果。阈值主要是指关联规则中的置信度和支持度。由于分布式数据库中的数据规模在不断增加,为了取得很好的效果,我们需要不断通过实验,更改阈值,使得关联效果最好。置信度和支持度往往根据经验设定,具体说来就是在数据量不同时,进行试验,通过实验得到一组比较理想的置信度和支持度,由于数据库中的数据一直在变化,因此这两个值理论上也是在不断发生变化的,因此,需要经常做实验,动态地设置置信度和支持度。
如图1所示是本发明中的整体流程图。首先从数据库中读取所有数据,然后,对这些数据使用关联规则算法,将具有强关联的所有元组放划分到一个类别中,之后为同一个类别中的所有元组的属性创建索引,这些索引就是二级索引。将这些二级索引都存放在一个数组中,称之为二级索引组。这样,有几个类别理论上就应该有几个二级索引组。之后,在为每一个二级索引组各自创建一个索引,称之为一级索引,把这些一级索引存放在一个新的数组中,称之为一级索引组。
如图2所示,是使用关联规则之后的结果图。对数据库中的所有元组使用关联规则算法,将具有强关联的元组信息进行关联。有关联的元组信息存放到一个类别中,图2就是将部分结果以图的形式体现。
如图3所示是建立索引流程图。它详细描述了在关联之后如何建立索引的过程。首先获得所有关联的元组信息,对每一组具有关联的元组创建一组索引,以供查询关联元组。然后为每一个索引组创建一个索引,可以唯一标识这个索引组。这样就可以减少在分布式数据库中检索的时间,大大提高效率。
图4是查询流程图。首先由用户输入关键词,然后系统会去查找该关键词对应的索引组,从索引组中找到所有与之关联的元组信息的索引。再通过索引去查询数据,将结果输出。
实施例
我们的数据库中目前有190435条用户注册信息数据,这些注册信息数据包含了他们的个人描述和自己定义的标签,我们有一个需求,输入一个情感类的字符串,比如勇敢,得到所有倾向勇敢的用户的信息。我们一共做了10组实验,分别输入不同情感类的词汇,对比使用本发明前后程序检索的效率。结果如图6所示。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!