音乐数据推荐方法与系统与流程
本发明涉及数据推荐技术领域,特别是涉及音乐数据推荐方法与系统。
背景技术:
目前,为了满足人们的生活需求,越来越多的人需要长时间驾驶汽车。例如长途客货运司机、城市公交车司机等。长途驾驶汽车一方面消耗大量体力,另一方面消耗人的精神力,容易使人感觉到疲劳、心情烦躁。
针对上述情况,目前汽车中一般都搭载有娱乐系统,可以在闲暇之余自动推荐一些音乐数据,让驾驶者保持愉悦的心情。
一般的娱乐系统是被动响应用户选择的播放音乐数据,或者是基于历史记录数据推荐音乐数据。而驾驶者在实际驾驶过程中可能由于路况、周围环境等因素会处于不同的心情状态,若简单采用基于历史数据推荐音乐数据是无法实现准确推荐适合当前场景音乐数据。
技术实现要素:
基于此,有必要针对一般音乐数据推荐方法无法准确推荐适合当前场景音乐数据的问题,提供一种能够准确推荐适合当前场景音乐数据的方法与系统。
一种音乐数据推荐方法,包括步骤:
采集汽车周围环境数据以及汽车行驶状态数据;
根据汽车周围环境数据以及汽车行驶状态数据,从预设音乐数据库中选择匹配的音乐数据;
推送查找到的音乐数据。
一种音乐数据推荐系统,包括:
数据采集模块,用于采集汽车周围环境数据以及汽车行驶状态数据;
匹配模块,用于根据汽车周围环境数据以及汽车行驶状态数据,从预设音乐数据库中选择匹配的音乐数据;
推送模块,用于推送查找到的音乐数据。
本发明音乐数据推荐方法与系统,采集汽车周围环境数据以及汽车行驶状态数据,根据汽车周围环境数据以及汽车行驶状态数据,从预设音乐数据库中选择匹配的音乐数据,推送查找到的音乐数据。整个过程,考虑汽车周围环境数据和汽车行驶状态数据,基于这些应用环境的数据从预设音乐数据中查找并推荐适合当前场景音乐数据。
附图说明
图1为本发明音乐数据推荐方法第一个实施例的流程示意图;
图2为本发明音乐数据推荐方法第二个实施例的流程示意图;
图3为本发明音乐数据推荐系统第一个实施例的结构示意图;
图4为本发明音乐数据推荐系统第二个实施例的结构示意图。
具体实施方式
如图1所示,一种音乐数据推荐方法,包括步骤:
S200:采集汽车周围环境数据以及汽车行驶状态数据。
汽车周围环境和汽车行驶状态数据可以通过OBD(On-Board Diagnostic,车载诊断系统)采集模块获取汽车ECU(Electronic Control Unit,行车电脑)的数据和安装于汽车上的传感器来实现。具体来说,汽车周围环境数据可以包括温度和湿度,汽车行驶状态数据可以包括汽车速度与加速度等数据。温度和湿度会影响驾驶员的心情,例如当温度较高且湿度较高时(夏天刚下过雨出太阳或将要下雨时)驾驶员会感觉异常闷热,内心会比较烦躁,这时需要推荐让驾驶员内心平静的音乐数据,如轻音乐等,当温度较低时(冬天)驾驶员会感觉到寒冷,内心会感觉到孤单、无聊,这时需要推荐欢快热闹的音乐数据。汽车速度与加速度同样会影响驾驶员的心情,当车辆速度较低,且频繁加速减速(加速度次数多)时,表明目前处于一个比较拥堵的情况,这时同样需要推荐让驾驶员内心平静的音乐数据。在实际应用中,温度数据可以通过安装于汽车的温度传感器采集,湿度可以通过安装于汽车的湿度传感器采集,速度和加速度可以通过插在汽车OBD接口上的OBD采集。非必要的,可以对这些在OBD上采集到的数据缓存至终端设备,另外还可以通过车辆诊断系统读取车辆故障信息、路程、车辆状况以及燃气里程等。这样可以额外为用户提供维修保养、保险期满提醒、道路救援服务以及为用户提供维修、保险期满提醒以及道路救援服务等服务。
S400:根据汽车周围环境数据以及汽车行驶状态数据,从预设音乐数据库中选择匹配的音乐数据。
预设音乐数据库是预先构建的数据库,在这个数据库中可以存储大量音乐数据,我们基于步骤S200采集的环境数据和行驶状态数据,在该数据库中查找匹配当前应用环境的音乐数据。具体来说,预设音乐数据库中还可以存储有应用环境类别与音乐数据对应关系列表,例如可以将不同的温度、湿度、车辆速度以及加速度分别划设为不同类别,不同类型预先对应不同音乐数据从而构建上述对应关系列表,再将该对应关系列表存储至预设音乐数据库内,非必要的,关于这个类别划分以及数据分析可以采用大数据分析方法并结合历史经验数据获得。
另外,在其中一个实施例中,可以是根据汽车周围环境数据以及汽车行驶状态数据,采用上下文感知推荐系统,并基于高斯过程的模型从预设音乐数据库中选择匹配的音乐数据。
一般推荐系统模型基本为“用户—项目”的二维推荐系统,即“用户*项目=评级等级(推荐等级)”,在本实施例采用上下文感知推荐系统,将上述一般的推荐系统模型扩展为包含多种上下文信息的多维评分效用模型,即“用户*项目*上下文信息=评价等级(推荐等级)”其中上下文信息可以包含多维度的信息,即,直接整合上下文信息与用户—项目的关系,三者俩俩之间直接进行交互(强耦)可以得到随机变量集合。高斯过程指的是一组随机变量的集合,这个集合里面的任意有限个随机变量都服从联合高斯分布。基于高斯过程的模型的结果即可从预设音乐数据库中获得评分等级最高的音乐数据,即获得匹配的音乐数据。为了提高模型的准确率,需要用到OBD采集到ECU的历史数据作为历史数据集,也解决推荐算法存在的冷启动的问题。
S600:推送查找到的音乐数据。
将获得的音乐数据推送至驾驶者随身携带的智能终端(智能手机),播放该音乐数据给驾驶者带来愉悦的心情。非必要的,在播放音乐的同时,还可以获取虚拟场景数据,将虚拟场景数据推送至增强现实装置(AR),这样用户可以处于虚拟场景中享受美妙的音乐,带来良好的用户体验。
本发明音乐数据推荐方法,采集汽车周围环境数据以及汽车行驶状态数据,根据汽车周围环境数据以及汽车行驶状态数据,从预设音乐数据库中选择匹配的音乐数据,推送查找到的音乐数据。整个过程,考虑汽车周围环境数据和汽车行驶状态数据,基于这些应用环境的数据从预设音乐数据中查找并推荐适合当前场景音乐数据。
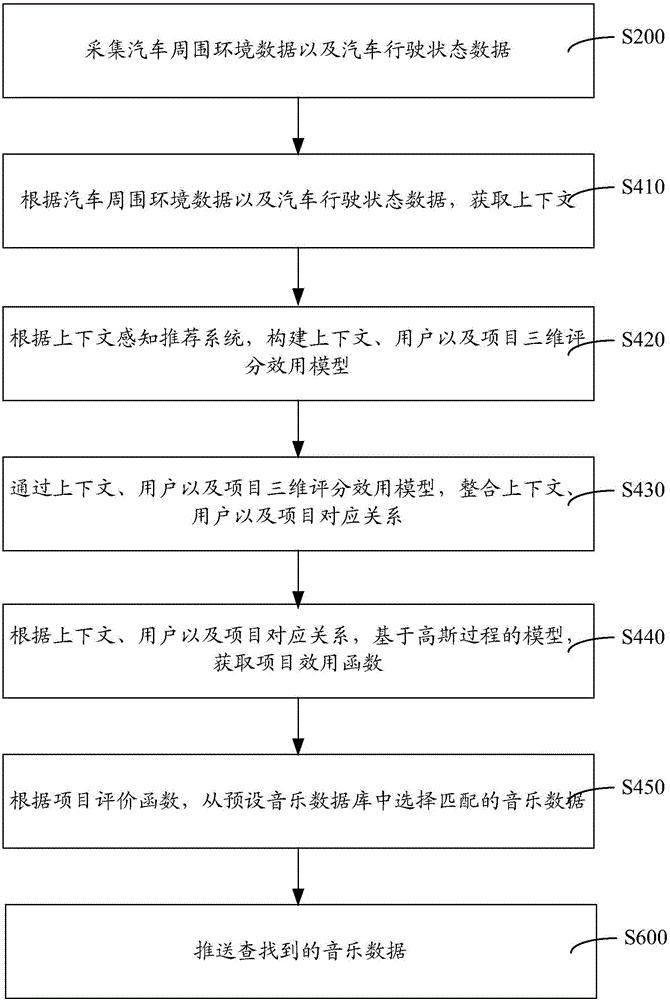
如图2所示,在其中一个实施例中,步骤S400包括:
S410:根据汽车周围环境数据以及汽车行驶状态数据,获取上下文。
上下文是用于描述实体状态的任何信息。具体来说,在这里,实体状态是指步骤S200中获得的汽车周围环境数据以及汽车行驶状态数据,更进一步来说,这里的实体状态包括温度、湿度、速度和加速度等与用户和项目之间交互相关的客体。因为用户对项目(音乐数据)的偏好顺序往往与上下文有关系。这些信息可以包括温度、湿度、速度和加速度等与用户和应用程序之间交互相关的客体(包括用户与应用程序本身)。因为用户对项目的偏好顺序往往与上下文有关系。
S420:根据上下文感知推荐系统,构建上下文、用户以及项目三维评分效用模型。
具体来说,项目是指待推荐的音乐数据,例如当待推荐的音乐数据为“中国心”歌曲时,项目即为歌曲“中国心”。在这里采用上下文感知推荐系统,构建如“用户*项目*上下文信息=评价等级”的包含多种上下文信息的三维评分效用模型。
S430:通过上下文、用户以及项目三维评分效用模型,整合上下文、用户以及项目对应关系。
直接整合上下文信息与用户—项目的关系,三者俩俩之间直接进行交互(强耦合),整合获得上下文、用户以及项目对应关系。
S440:根据上下文、用户以及项目对应关系,基于高斯过程的模型,获取项目效用函数。
基于高斯过程的模型,建立一种非线性的矩阵分解方法——高斯过程分解机,使用线性组合对用户—项目—上下文的隐因子进行交互。具体来说,上述交互过程具体包括如下步骤:首先,基于潜在因子模型方法,将所述用户、项目以及上下文表述为潜在的d维特征向量Vi,Vj,Vc1,Vc2,...,VcM,其中,i为用户,j为项目,c上下文条件,M为所述上下文条件的个数;之后,将潜在的d维特征向量Vi,Vj,Vc1,Vc2,...,VcM平铺转化为上下文、用户以及项目的D维特征向量t(j,c)=[ViT,VjT,Vc1T,Vc2T...VcMT]T,c=(c1,c2,...,cM),其中,D=(M+1)d,T为向量计算方法;最后,获取以用户为中心,用户i在上下文条件c的情况下对项目j的效用函数fi(t(j,c))。
S450:根据项目效用函数,从预设音乐数据库中选择匹配的音乐数据。
根据步骤S440中获得的项目效用函数,计算每个项目的评价结果,在选取评价结果最优的音乐数据作为匹配的音乐数据。例如根据步骤S440中的项目效用函数,计算得到当前应用环境下播放“中国心”歌曲这个项目评分为A,得计算得到当前应用环境下播放相声视频这个项目评分为B,当A高于B时,将选择“中国心”歌曲为音乐数据,当B高于A时,将选取该相声视频为匹配的音乐数据。更具体来说,我们可以针对评价结果进行优先级排序,选取优先级最高的项目为匹配的音乐数据。
为更进一步详细解释上述步骤S440的实现过程,下面将采用严谨数学公式方式,介绍在其中一个实施例中,步骤S440包括的内容。
基于高斯过程的模型,建立了一种非线性的矩阵分解方法——高斯过程分解机,使用线性组合对用户—项目—上下文的隐因子进行交互。向用户推荐手机上的APP(Application,应用程序)中,用户集U={user1,user2,user3,..},手机APP的集合V={A1,A2,A3,...},用户当前的上下文为温度、湿度、速度和加速度等多维度的信息,因此我们可以使用C1,C2,C3,C4等来分别表示上下文信息,例如C1={10°,20°,30°},C2={40%,60%,80%},C3={40m/s,60m/s,80m/s},C4={10m/s2,20m/s2,30m/s2}。观察样例可以用多元组表示为U*V*C*R,例如:(user1,A1,(10°,40%,40m/s,10m/s2),4),(user2,A3,(30°,80%,60m/s,20m/s2),11),其中,上述两个集合中最后一位数4和11分别为数字评分结果。基于潜在因子模型的方法,首先分别将用户,项目,上下文表述为潜在的d维特征向量Vi,Vj,Vc1,Vc2,...,VcM。将(项目,上下文)平铺转化为D维特征向量,
D=(M+1)d,t(j,c)=[ViT,VjT,Vc1T,Vc2T...VcMT]T,c=(c1,c2,...,cM)
T为向量计算方法,以将观测向量函数t(j,c)从行向量变为列向量。以用户为中心,用户i在上下文条件为c的情况下对项目j的评价表达为(效用函数):fi(t(j,c))。
高斯过程指的是一组随机变量的集合,这个集合里面的任意有限个随机变量都服从联合高斯分布。高斯分布完全由均值μ和协方差X决定,而高斯过程(GP)完全由均值函数m(x)和协方差函数k(x,x′;θ)决定。比如,是一个具有N个向量的集合,实值函数满足多维高斯分布p(f|X)=N(f;m,k)那么称f(x)是一个高斯过程,f(x)~GP(m(x),k(x,x′;θ)),其中,为均值函数,Kn,n=k(xn,xn,;θ)K为协方差函数,径向基核函数为:在高斯过程分解机(GPFM)中,令xi表示用户i的所有的隐因子表达的观测向量t(j,c),yi表示相应的效用值,则f↓i(x)服从高斯过程,即
因此,所有f↓i(x)的先验分布为
实际观测值yiz是具有高斯噪声的,因此可建模为服从高斯分布
p(yiz|fi(xz),σi)=N(y;fi(xz),σi2)
因此完整的所有观测量的似然函数为
在上述的过程中,我们一直将高斯过程的均值函数假设为0。考虑到实际生活中,不同的用户的评分松弛度有一定的偏向,因此在效用函数中加入偏置量
因此,将fi的先验分布中的均值加上偏置量后
模型求解和训练:使用联合分布概率求解边缘概率分布
p(y|X,Xbias,θ,σ)=p(y|f,σ)p(y|X,Xbias,θ)
分别代入y和f的概率分布得p(y|X,Xbias,θ,σ),然后求对数后,得-log p(y)。优化变量为U={X,Xbias,θ,σ}。使用随机梯度下降法进行训练,最小化函数-log p(y)
U(n+1)=Un+Δn@Δn=hΔ(n-1)ad log N(yi,mi,Kyi)/(dUn)
使用高斯过程回归(GSR)进行预测分布,给定一个测试的观察量的隐因子向量x*=t(j*,c*),则其预测效用函数fi(x*)一定满足p(f(x*)i|Xi,θi,yi)=N(μ*,s*)。
如图3所示,一种音乐数据推荐系统,包括:
数据采集模块200,用于采集汽车周围环境数据以及汽车行驶状态数据;
匹配模块400,用于根据汽车周围环境数据以及汽车行驶状态数据,从预设音乐数据库中选择匹配的音乐数据;
推送模块600,用于推送查找到的音乐数据。
本发明音乐数据推荐系统,数据采集模块200采集汽车周围环境数据以及汽车行驶状态数据,匹配模块400根据汽车周围环境数据以及汽车行驶状态数据,从预设音乐数据库中选择匹配的音乐数据,推送模块600推送查找到的音乐数据。整个过程,考虑汽车周围环境数据和汽车行驶状态数据,基于这些应用环境的数据从预设音乐数据中查找并推荐适合当前场景音乐数据。
在其中一个实施例中,匹配模块400具体用于根据汽车周围环境数据以及汽车行驶状态数据,采用上下文感知推荐系统,并基于高斯过程的模型从预设音乐数据库中选择匹配的音乐数据。
如图4所示,在其中一个实施例中,匹配模块400包括:
上下文获取单元410,用于根据汽车周围环境数据以及汽车行驶状态数据,获取上下文。
模型构建单元420,用于根据上下文感知推荐系统,构建上下文、用户以及项目三维评分效用模型。
整合单元430,用于通过上下文、用户以及项目三维评分效用模型,整合上下文、用户以及项目对应关系。
评价函数获取单元440,用于根据上下文、用户以及项目对应关系,基于高斯过程的模型,获取项目效用函数。
匹配单元450,用于根据项目效用函数,从预设音乐数据库中选择匹配的音乐数据。
在其中一个实施例中,评价函数获取单元440包括:
第一特征向量获取单元,用于基于潜在因子模型方法,将所述用户、项目以及上下文表述为潜在的d维特征向量Vi,Vj,Vc1,Vc2,...,VcM,其中,i为用户,j为项目,c上下文条件,M为所述上下文条件的个数。
第二特征向量获取单元,用于将潜在的d维特征向量Vi,Vj,Vc1,Vc2,...,VcM平铺转化为上下文、用户以及项目的D维特征向量t(j,c)=[ViT,VjT,Vc1T,Vc2T...VcMT]T,c=(c1,c2,...,cM),其中,D=(M+1)d。
函数获取单元,用于获取以用户为中心,用户i在上下文条件c的情况下对项目j的效用函数。
在其中一个实施例中,汽车周围环境数据包括温度和湿度,汽车行驶状态数据包括速度和加速度。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!