基于人名的邮箱地址推荐方法及系统与流程
本发明涉及网络信息技术领域,特别涉及一种基于人名的邮箱地址推荐方法及系统。
背景技术:
随着互联网的发展,用户的联系方式已经不再局限于电话号码、传真地址、通信地址等等。电子邮箱作为新兴的一种联系方式,承担着信息沟通的重要作用。大部分企业以及个人都会使用电子邮箱进行沟通和业务往来。在CNNIC(China Internet Network Information Center,中国互联网络信息中心)发布的一系列关于全国互联网发展的统计报告中指出,截至2015年12月在接入互联网的企业中89.0%在过去一年使用过互联网收发电子邮件,而普通用户则中有2.45亿使用电子邮件。因此准确高效的获得用户的邮箱地址,将具有广泛的应用价值。特别是在学术研究领域,由于研究者中电子邮件的使用率更高,因此在进行专家推荐、专家联系等方面更有价值。电子邮箱地址的提取是信息抽取方向的一个着眼点,是数据挖掘研究的基础问题。
目前已有一些邮箱地址搜索系统能够使用,其基本原理都是通过网络爬虫进行多层搜索,将获取到的疑似邮箱地址直接返回给用户交给用户判断,如Email Hunter,EmailBreaker,Volia Norbert等等。这类方法得到的结果充斥着大量无关、错误的信息,且运行时间很长,效率低下,准确率和搜索速度都难以满足实际需求。另外,Tang等人在2010年提出了先找个人主页再利用机器学习方法提取邮箱地址,这种方法也存在两个缺点:一是查找主页可能存在误差进而导致邮箱地址的不正确;二是主页中也可能包含其他混淆的邮箱地址或者不包含地址。
技术实现要素:
本发明旨在至少在一定程度上解决上述相关技术中的技术问题之一。
为此,本发明的一个目的在于提出一种基于人名的邮箱地址推荐方法,该方法能够根据待搜索人的信息向用户推荐待搜索人的邮箱,具有效率高、准确度高的优点。
本发明的另一个目的在于提出一种基于人名的邮箱地址推荐系统。
为了实现上述目的,本发明第一方面的实施例提出了一种基于人名的邮箱地址推荐方法,包括:以待搜索人的信息和邮箱作为关键词,通过搜索引擎进行搜索,得到对应于待搜索人的搜索结果页面;对所述对应于待搜索人的搜索结果页面中的条目结构进行分析,并将符合邮箱地址格式的地址作为待搜索人的候选邮箱地址;对所述待搜索人的候选邮箱地址进行格式规范,并去除所述待搜索人的候选邮箱地址中的无效地址;以及对所述待搜索人的候选邮箱地址中剩余的邮箱地址进行特征抽取以得到特征向量,并将所述特征向量输入预先构造的SVM分类模型中进行分类鉴别,并将被判定为正例的邮箱地址作为待搜索人的邮箱地址推荐给用户。
根据本发明实施例的基于人名的邮箱地址推荐方法,基于搜索引擎得到的搜索结果页面,通过减少搜索深度大大提高了运行速度,同时结合待搜索人的关键特征及搜索中获取的其他信息对候选邮箱地址以特定方法进行评估和判断,筛选出匹配待搜索人的邮箱地址,并推荐给用户。即该方法能够根据待搜索人的信息向用户推荐待搜索人的邮箱,具有效率高、准确度高的优点。
另外,根据本发明上述实施例的基于人名的邮箱地址推荐方法还可以具有如下附加的技术特征:
在一些示例中,所述SVM分类模型的构造方法包括以下步骤:以搜索人的信息和邮箱作为关键词,通过搜索引擎进行搜索,得到对应于搜索人的搜索结果页面;对所述对应于搜索人的搜索结果页面中的条目结构进行分析,并将符合邮箱地址格式的地址作为搜索人的候选邮箱地址;对所述搜索人的候选邮箱地址进行特征抽取,并根据得到的特征数据及预设的训练数据集进行SVM训练,以得到SVM分类模型,其中,所述预设的训练数据集中包括已经标注过真伪的邮箱地址。
在一些示例中,所述特征数据包括:1)所述搜索人的last name占地址前缀的比例;2)除所述last name外的搜索人的姓名占地址前缀的比例;3)所述搜索人的姓名的各部分首字母占候选地址前缀的比例;4)当前地址在所述搜索人的候选邮箱地址中出现的次数占所述搜索人的候选邮箱地址总数的比例;5)当前地址的域名在所述搜索人的候选邮箱地址域名集合中出现的次数占所述搜索人的候选邮箱地址域名总数的比例;6)所述搜索人的last name是否包含于相关搜索条目的标题中;7)所述搜索人的last name是否包含于相关搜索条目的摘要中;8)所述搜索人所在的机构名称是否包含于相关搜索条目的标题中;9)所述搜索人所在的机构名称是否包含于相关搜索条目的摘要中。
在一些示例中,所述待搜索人的信息包括:待搜索人的姓名和/或待搜索人所在的机构名称。
在一些示例中,所述搜索人的信息包括:搜索人的姓名和/或搜索人所在的机构名称。
为了实现上述目的,本发明第二方面的实施例还提出了一种基于人名的邮箱地址推荐系统,包括:搜索模块,所述搜索模块用于将待搜索人的信息和邮箱作为关键词,通过搜索引擎进行搜索,得到对应于待搜索人的搜索结果页面;分析模块,所述分析模块用于对所述对应于待搜索人的搜索结果页面中的条目结构进行分析,并将符合邮箱地址格式的地址作为待搜索人的候选邮箱地址;预处理模块,所述预处理模块用于对所述待搜索人的候选邮箱地址进行格式规范,并去除所述待搜索人的候选邮箱地址中的无效地址;以及推荐模块,所述推荐模块用于对所述待搜索人的候选邮箱地址中剩余的邮箱地址进行特征抽取以得到特征向量,并将所述特征向量输入预先构造的SVM分类模型中进行分类鉴别,并将被判定为正例的邮箱地址作为待搜索人的邮箱地址推荐给用户。
根据本发明实施例的基于人名的邮箱地址推荐系统,基于搜索引擎得到的搜索结果页面,通过减少搜索深度大大提高了运行速度,同时结合待搜索人的关键特征及搜索中获取的其他信息对候选邮箱地址以特定方法进行评估和判断,筛选出匹配待搜索人的邮箱地址,并推荐给用户。即该系统能够根据待搜索人的信息向用户推荐待搜索人的邮箱,具有效率高、准确度高的优点。
另外,根据本发明上述实施例的基于人名的邮箱地址推荐系统还可以具有如下附加的技术特征:
在一些示例中,所述SVM分类模型的构造过程包括:以搜索人的信息和邮箱作为关键词,通过搜索引擎进行搜索,得到对应于搜索人的搜索结果页面;对所述对应于搜索人的搜索结果页面中的条目结构进行分析,并将符合邮箱地址格式的地址作为搜索人的候选邮箱地址;对所述搜索人的候选邮箱地址进行特征抽取,并根据得到的特征数据及预设的训练数据集进行SVM训练,以得到SVM分类模型,其中,所述预设的训练数据集中包括已经标注过真伪的邮箱地址。
在一些示例中,所述特征数据包括:1)所述搜索人的last name占地址前缀的比例;2)除所述last name外的搜索人的姓名占地址前缀的比例;3)所述搜索人的姓名的各部分首字母占候选地址前缀的比例;4)当前地址在所述搜索人的候选邮箱地址中出现的次数占所述搜索人的候选邮箱地址总数的比例;5)当前地址的域名在所述搜索人的候选邮箱地址域名集合中出现的次数占所述搜索人的候选邮箱地址域名总数的比例;6)所述搜索人的last name是否包含于相关搜索条目的标题中;7)所述搜索人的last name是否包含于相关搜索条目的摘要中;8)所述搜索人所在的机构名称是否包含于相关搜索条目的标题中;9)所述搜索人所在的机构名称是否包含于相关搜索条目的摘要中。
在一些示例中,所述待搜索人的信息包括:待搜索人的姓名和/或待搜索人所在的机构名称。
在一些示例中,所述搜索人的信息包括:搜索人的姓名和/或搜索人所在的机构名称。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1是根据本发明实施例的基于人名的邮箱地址推荐方法的流程图;
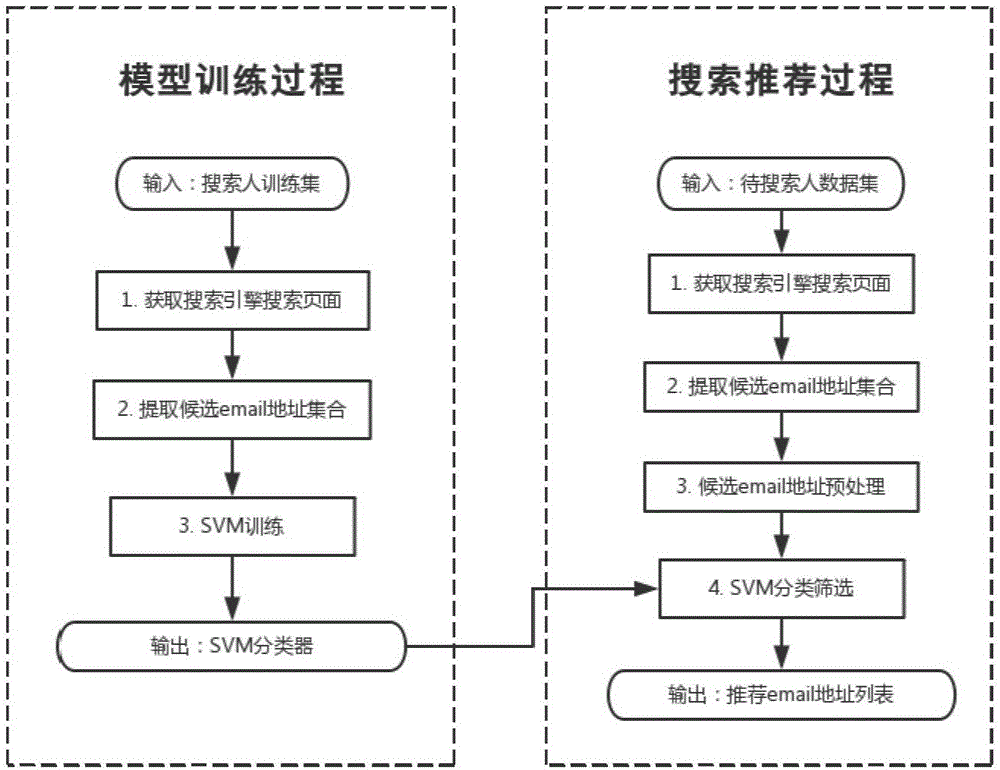
图2是本发明一个实施例的基于人名的邮箱地址推荐方法的整体流程图;
图3是本发明一个具体实施例的获取的待搜索人的搜索结果页面示意图;以及
图4是本发明实施例的基于人名的邮箱地址推荐系统的结构框图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
以下结合附图描述根据本发明实施例的基于人名的邮箱地址推荐方法及系统。
图1是根据本发明一个实施例的基于人名的邮箱地址推荐方法的流程图。图2是根据本发明一个实施例的基于人名的邮箱地址推荐方法的整体流程图。如图1所示,并结合图2,该方法包括以下步骤:
步骤S1:以待搜索人的信息和邮箱作为关键词,通过搜索引擎进行搜索,得到对应于待搜索人的搜索结果页面。其中,待搜索人的信息包括:待搜索人的姓名和/或待搜索人所在的机构名称。更为具体地,待搜索人的姓名和待搜索人所在的机构名称以英文或拼音的形式展示。则在步骤S1中,例如,将“待搜索人姓名+email”作为关键词输入搜索引擎(例如Google搜索),在搜索引擎返回的结果中获取第一页作为待搜索人的搜索结果页面。
步骤S2:对对应于待搜索人的搜索结果页面中的条目结构进行分析,并将符合邮箱地址格式的地址作为待搜索人的候选邮箱地址。
步骤S3:对待搜索人的候选邮箱地址进行格式规范,并去除待搜索人的候选邮箱地址中的无效地址。
步骤S4:对待搜索人的候选邮箱地址中剩余的邮箱地址进行特征抽取以得到特征向量,并将特征向量输入预先构造的SVM分类模型中进行分类鉴别,得到预测标注,并将被判定为正例的邮箱地址作为待搜索人的邮箱地址推荐给用户。
其中,特征抽取过程中的特征定义为:
1)待搜索人的last name占地址前缀的比例;
2)除last name外的待搜索人的姓名占地址前缀的比例;
3)待搜索人的姓名的各部分首字母占候选地址前缀的比例;
4)当前地址在待搜索人的候选邮箱地址中出现的次数占待搜索人的候选邮箱地址总数的比例;
5)当前地址的域名在待搜索人的候选邮箱地址域名集合中出现的次数占待搜索人的候选邮箱地址域名总数的比例;
6)待搜索人的last name是否包含于相关搜索条目的标题中;
7)待搜索人的last name是否包含于相关搜索条目的摘要中;
8)待搜索人所在的机构名称是否包含于相关搜索条目的标题中;
9)待搜索人所在的机构名称是否包含于相关搜索条目的摘要中。
其中,在本发明的一个实施例中,上述的SVM分类模型的构造方法包括以下步骤:
步骤1:以搜索人的信息和邮箱作为关键词,通过搜索引擎进行搜索,得到对应于搜索人的搜索结果页面。其中,搜索人的信息包括搜索人的姓名和/或搜索人所在的机构名称。更为具体地,搜索人的姓名和搜索人所在的机构名称以英文或拼音的行驶展示。则在步骤1中,例如在搜索引擎中输入“搜索人姓名+email”,以获取对应于搜索人的搜索结果页面。
步骤2:提取候选email(邮箱)地址集合。即对对应于搜索人的搜索结果页面中的条目结构进行分析,并将符合邮箱地址格式的地址作为搜索人的候选邮箱地址。
步骤3:对搜索人的候选邮箱地址进行特征抽取,并根据得到的特征数据及预设的训练数据集进行SVM训练,以得到SVM分类模型,其中,预设的训练数据集中包括已经标注过真伪的邮箱地址。即根据得到的特征数据及预设的训练数据集中候选邮箱地址的标注进行SVM训练,得到SVM分类模型,从而完成前期的模型训练过程。需要说明的是,在具体实施过程中,此过程自需要线下运行一次,产生的SVM分类模型可被搜索推荐系统多次使用,因此模型训练过程不需要重复运行。
其中,上述的特征数据包括:
1)搜索人的last name占地址前缀的比例;
2)除last name外的搜索人的姓名占地址前缀的比例;
3)搜索人的姓名的各部分首字母占候选地址前缀的比例;
4)当前地址在搜索人的候选邮箱地址中出现的次数占搜索人的候选邮箱地址总数的比例;
5)当前地址的域名在搜索人的候选邮箱地址域名集合中出现的次数占搜索人的候选邮箱地址域名总数的比例;
6)搜索人的last name是否包含于相关搜索条目的标题中;
7)搜索人的last name是否包含于相关搜索条目的摘要中;
8)搜索人所在的机构名称是否包含于相关搜索条目的标题中;
9)搜索人所在的机构名称是否包含于相关搜索条目的摘要中。
为了便于更好地理解本发明上述实施例的基于人名的邮箱地址推荐方法,以下结合图3,以具体实施例来对该方法进行详细描述。
在本实施例中,以Peer Bork作为待搜索人的姓名,则基于人名的邮箱地址推荐方包括以下步骤:
步骤A:获取搜索引擎搜索结果页面。
具体地,以人名+“email”作为搜索关键词,获取待搜索人的搜索结果页面。例如,以“Peer Bork email”作为搜索关键词,以Google搜索引擎为例,获取待搜索人的搜索结果页面,即Google搜索引擎根据搜索关键词返回的搜索结果的第一页,部分结果如图3所示。
步骤B:分析搜索结果页面,抽取候选邮箱地址。
具体地,例如使用正则表达式对搜索结果页面进行遍历匹配,抽取出搜索结果页面中所有符合email地址格式的候选邮箱地址。例如,在如图3所示的搜索结果页面中,使用python正则表达式:'(([a-z0-9-]+)(\.|dot|\.)?)+(@|at)(([a-z0-9\-]+)(\.|dot|\.))+([a-z]+)'可以抽取出4个候选地址:onferences@vib.be、email@embl.de、peer.bork@embl.de以及bork@embl.de。
步骤C:候选邮箱地址预处理。
具体地,对候选email地址进行规范格式、筛去无效地址等预处理。例如:将特殊格式的'@'符号(如“[at]”)转化成规范的'@'字符;筛去前缀为"email"、"lastname"等特殊关键词的无效地址。
步骤D:进行SVM分类筛选。
对所有候选email地址进行特征抽取,再用SVM分类模型根据特征向量判断email地址的有效性。具体过程简述如下:
假设email地址格式形如:prefix@domain,其中prefix表示邮箱前缀,domain代表邮箱域名,两者以'@'符号隔开。由于email地址不区分大小写,因此以下涉及的所有文本均经过小写转化处理。其中,email地址的特征具体定义如下:
(1)搜索人的姓氏占地址前缀的比例f1;
f1=地址前缀中姓氏的长度/地址前缀总长度,
例如:在示例中,待搜索人的姓氏是'Bork',长度为4。在候选地址onferences@vib.be中,前缀onferences不直接包含'bork',因此f1=0/10=0.0;而在候选地址peer.bork@embl.de中,f1=4/8=0.5;
(2)除姓氏以外的搜索人名字占地址前缀的比例f2;
f2代表前缀中包含的所有除姓氏以外的名字部分的总长度除以地址前缀总长度得到的比例。
(3)搜索人姓名的各部分首字母占候选地址前缀的比例f3;
f3代表前缀中包含的所有名字部分的首字母数量除以地址前缀总长度得到的比例。在计算过程中,通过从前缀中删除已统计首字母的方法,排除各首字母位置重叠的情况。
(4)当前地址在整个候选地址集合中出现的次数占候选地址总数的比例f4;
(5)当前地址的域名在整个候选地址域名集合中出现的次数占候选地址域名总数的比例f5;
(6)搜索人的姓是否包含于相关搜索条目的标题中f6:
例如:在示例中,待搜索人的姓氏是'Bork'。在搜索结果页面的第一条结果标题“Peer Bork-EMBL”中包含'Bork',此时f6=1,而在第三条结果标题“
Heidelberg:Faculty”中不包含'Bork',此时f6=0。
(7)搜索人的last name是否包含于相关搜索条目的摘要中f7;
(8)搜索人的所在机构名称是否包含于相关搜索条目的标题中f8;
(9)搜索人的所在单位名称是否包含于相关搜索条目的摘要中f9。
然后,对每个候选email地址进行上述特征向量的抽取,通过SVM分类模型进行分类鉴别,舍弃被判定为负例的候选地址,将所有正例(即分类器判断有效的候选地址)整理成最终的推荐email地址。
综上,本发明实施例的基于人名的邮箱地址推荐方法主要原理概述为:通过对搜索引擎返回的搜索结果页面分析得到候选email地址,再对候选地址进行特征提取,并通过机器学习的方法评估其是否与待搜索人匹配。在从Google等引擎得到的搜索结果页面中隐含着大量相关信息。例如:所有候选email地址的域名分布情况、搜索引擎条目的来源、搜索引擎条目的主题与搜索人的相关度等等。本发明实施例的方法通过信息抽取、机器学习等方法,寻找搜索结果中冗余信息之间的联系,以这些信息为基础加强邮箱有效性评估的可信度。这也是本专利准确率高于普通方法的保证。同时,本发明运用以搜索引擎直接作为知识库的方法,与基于海量数据抓取或深层搜索的传统方法相比大大提高了运行速度,节省了程序运行需要的空间资源。
根据本发明实施例的基于人名的邮箱地址推荐方法,基于搜索引擎得到的搜索结果页面,通过减少搜索深度大大提高了运行速度,同时结合待搜索人的关键特征及搜索中获取的其他信息对候选邮箱地址以特定方法进行评估和判断,筛选出匹配待搜索人的邮箱地址,并推荐给用户。即该方法能够根据待搜索人的信息向用户推荐待搜索人的邮箱,具有效率高、准确度高的优点。
本发明的进一步实施例还提供了一种基于人名的邮箱地址推荐系统。
图4是根据本发明一个实施例的基于人名的邮箱地址推荐系统的结构框图。如图4所示,该系统100包括:搜索模块110、分析模块120、预处理模块130和推荐模块140。
其中,搜索模块110用于将待搜索人的信息和邮箱作为关键词,通过搜索引擎进行搜索,得到对应于待搜索人的搜索结果页面。其中,待搜索人的信息包括:待搜索人的姓名和/或待搜索人所在的机构名称。
分析模块120用于对对应于待搜索人的搜索结果页面中的条目结构进行分析,并将符合邮箱地址格式的地址作为待搜索人的候选邮箱地址。
预处理模块130用于对待搜索人的候选邮箱地址进行格式规范,并去除待搜索人的候选邮箱地址中的无效地址。
推荐模块140用于对待搜索人的候选邮箱地址中剩余的邮箱地址进行特征抽取以得到特征向量,并将特征向量输入预先构造的SVM分类模型中进行分类鉴别,得到预测标注,并将被判定为正例的邮箱地址作为待搜索人的邮箱地址推荐给用户。
其中,特征抽取过程中的特征定义为:
1)待搜索人的last name占地址前缀的比例;
2)除last name外的待搜索人的姓名占地址前缀的比例;
3)待搜索人的姓名的各部分首字母占候选地址前缀的比例;
4)当前地址在待搜索人的候选邮箱地址中出现的次数占待搜索人的候选邮箱地址总数的比例;
5)当前地址的域名在待搜索人的候选邮箱地址域名集合中出现的次数占待搜索人的候选邮箱地址域名总数的比例;
6)待搜索人的last name是否包含于相关搜索条目的标题中;
7)待搜索人的last name是否包含于相关搜索条目的摘要中;
8)待搜索人所在的机构名称是否包含于相关搜索条目的标题中;
9)待搜索人所在的机构名称是否包含于相关搜索条目的摘要中。
其中,在本发明的一个实施例中,上述的SVM分类模型的构造过程包括:以搜索人的信息和邮箱作为关键词,通过搜索引擎进行搜索,得到对应于搜索人的搜索结果页面;对对应于搜索人的搜索结果页面中的条目结构进行分析,并将符合邮箱地址格式的地址作为搜索人的候选邮箱地址;对搜索人的候选邮箱地址进行特征抽取,并根据得到的特征数据及预设的训练数据集进行SVM训练,以得到SVM分类模型,其中,预设的训练数据集中包括已经标注过真伪的邮箱地址。
其中,搜索人的信息包括:搜索人的姓名和/或搜索人所在的机构名称。
其中,上述的特征数据包括:1)搜索人的last name占地址前缀的比例;
2)除last name外的搜索人的姓名占地址前缀的比例;
3)搜索人的姓名的各部分首字母占候选地址前缀的比例;
4)当前地址在搜索人的候选邮箱地址中出现的次数占搜索人的候选邮箱地址总数的比例;
5)当前地址的域名在搜索人的候选邮箱地址域名集合中出现的次数占搜索人的候选邮箱地址域名总数的比例;
6)搜索人的last name是否包含于相关搜索条目的标题中;
7)搜索人的last name是否包含于相关搜索条目的摘要中;
8)搜索人所在的机构名称是否包含于相关搜索条目的标题中;
9)搜索人所在的机构名称是否包含于相关搜索条目的摘要中。
需要说明的是,本发明实施例的基于人名的邮箱地址推荐系统的具体实现方式与本发明实施例的基于人名的邮箱地址推荐方法的具体实现方式类似,具体请参见方法部分的描述,为了减少冗余,此处不做赘述。
综上,根据本发明实施例的基于人名的邮箱地址推荐系统,基于搜索引擎得到的搜索结果页面,通过减少搜索深度大大提高了运行速度,同时结合待搜索人的关键特征及搜索中获取的其他信息对候选邮箱地址以特定方法进行评估和判断,筛选出匹配待搜索人的邮箱地址,并推荐给用户。即该系统能够根据待搜索人的信息向用户推荐待搜索人的邮箱,具有效率高、准确度高的优点。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!