使用数据库复制的分布式工作流的制作方法
分布式工作流包括在分布式系统中的不同节点上执行的一系列的步骤。节点可以驻留在相同数据中心中或驻留在多个数据中心中。图1是分布式工作流的示例。工作流的一些步骤被期望执行在节点1上,其他步骤被期望执行在要么节点2要么节点3上。节点1、2、3可以在本地数据中心中或分布在多个数据中心之间。
技术实现要素:
在一个方面中,一种方法包括:在节点处确定工作流步骤是否具有不满意的依赖性;如果工作流步骤具有不满意的依赖性,则在节点处将工作流步骤的状态设置为阻塞状态;如果工作流步骤不具有不满意的依赖性,则执行工作流步骤;如果在执行工作流步骤之后,取消工作流步骤,则在节点处将工作流步骤的状态设置为取消状态;如果在执行工作流步骤之后,成功地执行工作流步骤,则在节点处将工作流步骤的状态设置为成功状态;如果在执行工作流步骤之后,未成功地执行工作流步骤,则在节点处将工作流步骤的状态设置为错误状态;如果成功地执行工作流步骤,则在节点处将工作流的状态设置为成功状态;以及使用数据库复制向其他节点通知工作流步骤的状态和工作流的状态。
在另一方面中,一种装置包括电子硬件电路装置,其被配置为在节点处确定工作流步骤是否具有不满意的依赖性;如果工作流步骤具有不满意的依赖性,则在节点处将工作流步骤的状态设置为阻塞状态;如果工作流步骤不具有不满意的依赖性,则执行工作流步骤;如果在执行工作流步骤之后,取消工作流步骤,则在节点处将工作流步骤的状态设置为取消状态;如果在执行工作流步骤之后,成功地执行工作流步骤,则在节点处将工作流步骤的状态设置为成功状态;如果在执行工作流步骤之后,未成功地执行工作流步骤,则在节点处将工作流步骤的状态设置为错误状态;如果成功地执行工作流步骤,则在节点处将工作流的状态设置为成功状态;以及使用数据库复制向其他节点通知工作流步骤的状态和工作流的状态。
在另一方面中,一种制品包括存储计算机可执行指令的非暂态计算机可读介质,所述指令使得机器在节点处确定工作流步骤是否具有不满意的依赖性;如果工作流步骤具有不满意的依赖性,则在节点处将工作流步骤的状态设置为阻塞状态;如果工作流步骤不具有不满意的依赖性,则执行工作流步骤;如果在执行工作流步骤之后,取消工作流步骤,则在节点处将工作流步骤的状态设置为取消状态;如果在执行工作流步骤之后,成功地执行工作流步骤,则在节点处将工作流步骤的状态设置为成功状态;如果在执行工作流步骤之后,未成功地执行工作流步骤,则在节点处将工作流步骤的状态设置为错误状态;如果成功地执行工作流步骤,则在节点处将工作流的状态设置为成功状态;以及使用数据库复制向其他节点通知工作流步骤的状态和工作流的状态。
附图说明
图1是分布在节点上的工作流的框图。
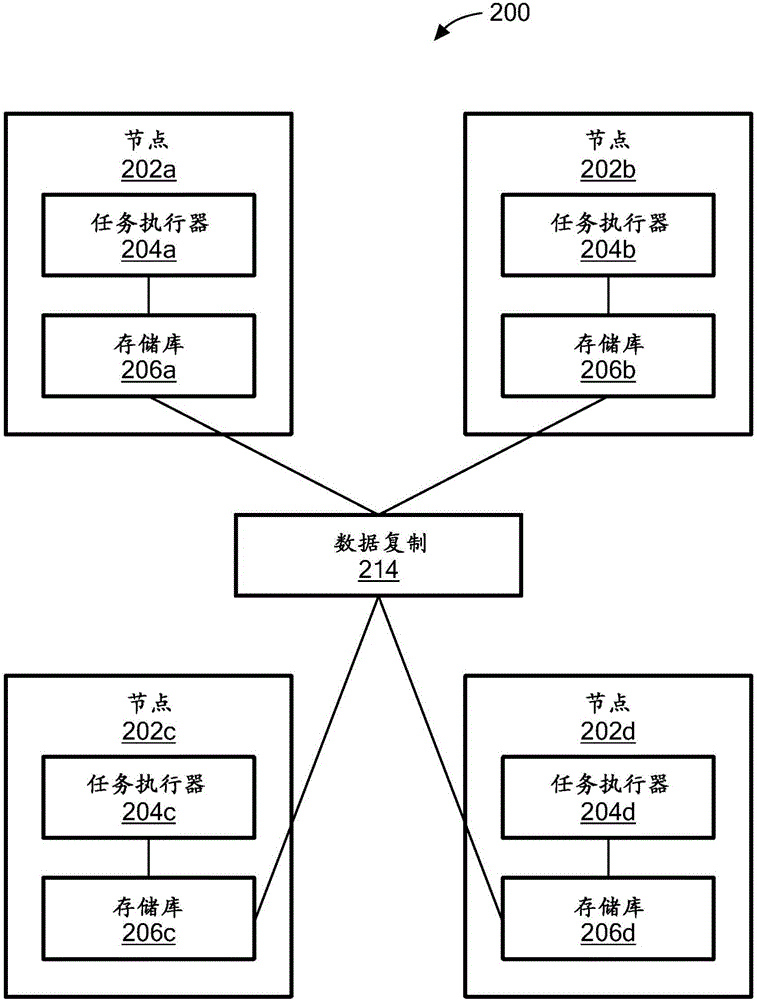
图2是工作流协调系统的示例的框图。
图3是另一工作流协调系统的示例的框图。
图4是针对工作流的状态流程图的框图。
图5是用于执行由分布式节点所使用的工作流的过程的示例的流程图。
图6是在其上可以实现图5的过程的部分中的任一部分的计算机。
具体实施方式
在本文中描述了通过数据库复制(例如,主动/主动数据库复制)提供分布式工作流协调的技术。
参考图2,工作流协调系统200是执行相同站点(例如,在相同数据中心中)处的分布式节点上的工作流的系统的示例。工作流协调系统200包括节点(例如,节点202a、节点202b、节点202c和节点202d)和数据库复制214。节点202a-202d包括相应地任务执行器204a-204d和相应的存储库206a-206d。任务执行器(例如,任务执行器204a-204d)执行工作流的一个或多个工作流步骤。
存储库(例如,存储库206a-206d)存储工作流定义和状态(如由其状态所指示的)。在工作流协调系统200执行工作流之前,定义工作流。工作流定义/状态被序列化(serialize)到数据库复制214。完整工作流定义包括工作流数据结构(对象)和一组工作流步骤数据结构(对象)。在一个示例中,工作流数据结构包括以下字段:统一资源标识符(URI)ID(唯一数据库ID);字符串orchControllerName(工作流名称);字符串任务ID;字符串状态(指示工作流是否成功);所完成的布尔。在一个示例中,工作流步骤数据结构包括以下字段:URI ID(针对该步骤的唯一数据库ID);URI工作流ID;URI依赖性;字符串执行方法;字符串回滚方法(当工作流失败时指向待执行的方法的指针);字符串状态;日期开始时间;和日期结束时间。
数据库复制214是主动/主动数据库复制。数据库复制214是允许节点共享工作流元数据和状态的主动/主动复制。数据库复制214包括以下特征。
第一,由于任何节点可以发起写请求,因而在节点的仲裁集上成功地完成写之后,数据库复制214返回成功状态。“仲裁集”意指集群的大多数节点。例如,在图2中,集群包括节点202a-202d,并且当写在节点中的任何3个上成功时,满足仲裁集。
第二,对于任何读请求而言,数据库复制214试图读取仲裁集节点并且在合并来自仲裁集节点的结果之后返回成功。第三,少数节点故障不影响整个系统200的可用性。第四,每个节点拥有数据库副本。如果大多数节点是工作/运行的,则数据库复制214是可使用的。
在一个特定示例中,数据库复制214是与APACHE ZOOKEEPER集成的APACHE CASSANDRA。
参考图3,工作流协调系统300是执行不同站点上的分布式节点上的工作流(例如,使用不同的数据中心)的系统的示例。工作流协调系统300包括节点(例如,节点302、节点302b、节点302c、节点302d、节点302e和节点302f)和数据库复制314。节点302a-302f分布地包括任务执行器304a-304f并且分布地包括存储库306a-306f。节点302a、302c、302e在第一站点310a处,并且节点302b、302d、302f在第二站点310b处。数据库复制314与数据库复制214基本上相同。
参考图4,状态流程图400描绘了工作流或工作流步骤可能处于的状态。工作流或工作流步骤可以处于以下状态之一。创建状态404指示工作流/工作流步骤被定义并且被添加到数据库。排队状态406指示任务执行器没有资源运行工作流/工作流步骤并且在队列中是未决(pending)的。阻塞状态410指示任务执行器具有资源执行工作流/工作流步骤,但是任务执行器由一些外部依赖性阻塞。执行状态416指示任务执行器正在执行工作流/工作流步骤。取消状态424指示当工作流/工作流步骤正在执行时,工作流/工作流步骤由终端用户取消。成功状态428指示工作流/工作流步骤成功地完成。错误状态432指示工作流/工作流步骤执行失败。
参考图5,过程500是由用于处理工作流的节点所执行的过程的示例。在通过每个节点执行过程500之前,基于工作流数据结构和工作流步骤数据结构,定义工作流。在工作流数据结构和工作流步骤数据结构推送到一个节点之后,使用数据库复制将工作流数据结构和工作流步骤数据结构复制到工作流协调系统中的所有节点。复制方法可以是同步或异步的。
过程500选择工作流(502)并且从所选择的工作流选择工作流步骤(506)。过程500确定工作流步骤是否具有不满意的依赖性(512)。如果工作流步骤具有不满意的依赖性,则过程500将工作流步骤设置为阻塞状态(514)。复制数据库214更新其他节点。如果工作流步骤不具有不满意的依赖性,则过程500将工作流步骤设置为执行步骤(516)。复制数据库214更新其他节点。
过程500执行工作流步骤(520)。过程500确定工作流步骤是否已经由用户(524)取消,并且如果工作流已经由用户取消,则过程500将工作流步骤的状态设置为取消(528)。复制数据库214更新其他节点。
如果工作流步骤尚未由用户取消,则过程500确定工作流步骤的执行是否是成功的,并且如果工作流步骤的执行不是成功的,则过程500将工作流步骤状态设置为错误(536)。复制数据库214更新其他节点。
如果工作流步骤的执行是成功的,则过程500将工作流步骤状态设置为成功状态(542)。复制数据库214更新其他节点。
在处理块514、536和542之后,过程500是否存在附加的步骤(546),并且如果存在附加的步骤,则过程500转到下一工作流步骤(548)。
如果不存在附加的步骤,则过程500将工作流状态设置为成功状态(550)。复制数据库214更新其他节点。
参考图6,计算机600包括处理器602、易失性存储器604、非易失性存储器606(例如,硬盘)和用户接口(UI)608(例如,图形用户接口、鼠标、键盘、显示器、触摸屏等)。非易失性存储器606存储计算机指令、操作系统616和数据618。在一个示例中,计算机指令612从易失性存储器604当中由处理器602执行,以执行本文所描述的过程中的全部过程或一部分过程(例如,过程500)。
本文所描述的过程(例如,过程500)不限于供图6的硬件和软件使用;其可以适用于任何计算或处理环境中和任何类型的机器或能够运行计算机程序的机器的集合。可以以硬件、软件或二者的组合实现本文所描述的过程。本文所描述的过程可以实现在执行在可编程计算机/机器上的计算机程序中,所述计算机/机器各自包括处理器、非暂态机器可读介质或由处理器(包括易失性存储器和非易失性存储器和/或存储元件)可读的其他制造品、至少一个输入设备和一个或多个输出设备。程序代码可以适于使用输入设备所输入的数据以执行本文所描述的过程并且生成输出信息。
系统可以至少部分经由计算机程序产品实现(例如,在非暂态机器可读存储介质,诸如例如非暂态计算机可读介质中),以由数据处理装置(例如,可编程处理器、计算机或多个计算机)执行或控制数据处理装置的操作。每个这样的程序可以以高级程序编程语言或面向对象编程语言实现以与计算机系统通信。然而,可以以汇编语言或机器语言实现程序。语言可以是编译语言或解释语言并且其可以以任何形式部署,包括作为单独程序或作为模块、组件、子例程或适于在计算环境中使用的其他单元。计算机程序可以被部署为一个站点处的一个计算机上或多个计算机上或跨多个地点分布并且通过通信网络相互连接的多个计算机上。计算机程序可以存储在由通用可编程计算机或专用可编程计算机可读的非暂态机器可读介质上,以用于当非暂态机器可读介质由计算机读取时,对计算机进行配置和操作以执行本文所描述的过程。例如,本文所描述的过程还可以被实现为配置有计算机程序的非暂态机器可读存储介质,其中,当计算机程序被执行时,计算机程序中的指令使得计算机根据过程进行操作。非暂态机器可读介质可以包括但不限于硬盘驱动器、光盘、闪速存储器、非易失性存储器、易失性存储器、磁软盘等,但不是包括暂态信号本身。
本文所描述的示例不限于所描述的特定示例。例如,过程500不限于图5的特定处理顺序。相反,图5中的处理块中的任一个可以根据需要重新排序、组合或移除、并行或串行执行以实现上文所阐述的结果。
与实现系统相关联的处理块(例如,在过程500中)可以由执行一个或多个计算机程序的一个或多个可编程处理器执行以执行系统的功能。系统的全部或一部分可以被实现为专用逻辑电路(例如,FPGA(现场可编程门阵列)和/或ASIC(专用集成电路))。系统的全部或一部分可以使用电子硬件电路实现,其包括电子设备,诸如例如以下中的至少一个:处理器、存储器、可编程逻辑设备或逻辑门。
本文所描述的不同的实施例的元件可以组合以形成上文未特别地阐述的其他实施例。还可以分离地或以任何适合的子组合提供单个实施例的上下文中所描述的各种元件。在本文中未特别描述的其他实施例也在所附权利要求的范围内。
- 还没有人留言评论。精彩留言会获得点赞!