一种关联热词的统计方法与流程
本发明涉及互联网技术领域,尤其涉及一种关联热词的统计方法。
背景技术:
热词即热门词汇。热词作为一种词汇现象,反映了一个国家、一个地区在一个时期人们普遍关注的问题和事物,具有时代特征,也反映了一个时期的热点话题及民生问题。随着云时代的来临,数据分析统计在决策过程中起到越来越重要的作用。为了能在大数据量的文本中发现当前的热点,特别是在突发事件处理中,如果热点事情发生了,相关热点词汇数据就会大量增加,及时的发现相关的热词,就可以发现突发事件,及时处理。
在热词的统计分析过程中往往会用到文本分词,其属于自然语言处理技术范畴,对于一句话,人可以通过自己的知识来明白哪些是词,哪些不是词,但要让计算机也能理解,其处理过程就是分词算法。目前常见的中文分词项目有word分词,SCWS,FudanNLP,ICTCLAS,HTTPCWS,CC-CEDICT,IK,Paoding,MMSEG4J,盘古分词。
停用词是停用一些在文本中广泛出现,但是对分析没有意义,或者意义很小的词。避免这些词因为较高的词频,而排在热词榜的前列,更有代表性的词反而排在后面的问题。
现有做法中,对文本进行分词,去除停用词后直接进行词频统计,输出词频最高的词作为热词。该方法只是单纯对词频进行统计,没有对统计的文本进行筛选,找出的热词相关性较差。
此外还通过人工直接添加或者计算机整理后人工识别的技术,维护一套热词库,通过直接对文本进行匹配查找,最后输出词频数。其不能有效识别新出现的热词,需要人工把新词加入热词表之后才会有该热词的统计信息。
技术实现要素:
本发明的目的是为了克服现有技术的缺陷,提供一种关联热词的统计方法,从而可以通过短语来控制进行热词分析的文本范围,避免无关文本的词频干扰,使用更灵活方便,同时通过同义词库的替换,增加了对文本范围的筛选的合理性,避免遗漏了有效文本。
为实现上述目的,本发明提供了一种关联热词的统计方法,该方法包括以下步骤:
S1根据需要统计的时间周期范围从数据源获取文本数据;
S2输入需要进行热词分析的短语;
S3对短语输入分词处理模块,拆分成词组;
S4对文本数据输入分词处理模块,输出文本词组;
S5短语词组中的词与同义词库进行匹配,如果有同义词,则新增短语词组的拷贝,把同义词替换原词后作为新增同义短语词组;
S6同义短语词组与文本词组进行相似度计算,找出符合要求的文本词组;
S7对符合要求的文本词组进行词频统计,从高到低输出词组。
进一步地,S4中分词处理模块的处理方法为:
把文本根据分词计算方法,拆分成词;
根据词性,过滤掉副词,助词,标点符号等无意义的词;
词组与停用词库进行对比,去除停用词库包含的词;
输出分词词组。
进一步地,S6中相似度的计算方法为:
a.按顺序取出一个文本词组;
b.取出一个同义短语词组,对短语词组与文本词组进行匹配计算,判断文本词组中是否包含该同义词组的所有词,或者含有的词的个数/同义词词组的个数>相似度百分比系数,如果满足条件则认为这个文本词组是满足相似度条件;
c.如果满足条件则把词组加入满足词组队列,重复步骤a;否则继续下一个同义短语词组,直到全部短语词组都处理完,再重复步骤a。
进一步地,还能够通过预先训练好分类器,对文本进行分类,找出需要的分类后,再进行词频统计,输出热词。
本发明技术方案带来的有益效果:
本发明能针对给定的短语对文本进行相似度符合判断,找出有关联的文本,然后再进行热词统计,从而能够通过短语控制热词分析的文本范围,避免无关文本的词频干扰,得出的词与短语的关联性较高。而且通过短语来查找对应的热词,也更灵活方便,不需要对配置进行修改,也不需要预先人工预先训练分类器。
此外,通过同义词库的替换,把具有相同含义的词也纳入统计范围,增加了对文本范围的筛选的合理性,避免遗漏了有效文本,增加了覆盖率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
图1是本发明的文本数据来源流程图;
图2是本发明的方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在对海量文本进行热词分析时,一般的热词分析只是对词频进行统计,没有对统计范围进行限定。本方法是根据预先给定的短语,查找相符合的文本,然后再进行词频统计,有效的去除了一些非关联热词的干扰。但是如果单纯的进行词的比较,因为中文的博大精深,相同的含义,可以用不同的词来表达。因此增加了同义词词库,通过同义词的替换,可以把具有相同含义的词,也纳入统计范围,增加了对文本范围的筛选的合理性,避免遗漏了符合条件的文本。
如图1所示为本发明的文本数据来源流程图。为了从大量文本中找到自己关心的热词,本发明采用了对文本根据输入短语进行预筛选,根据筛选结果再进行热词分析的计算方法。文本的数据来源可能是数据库,文本文件,录音文件转换的文本,OCR纸质文件后转换出的文本文件。
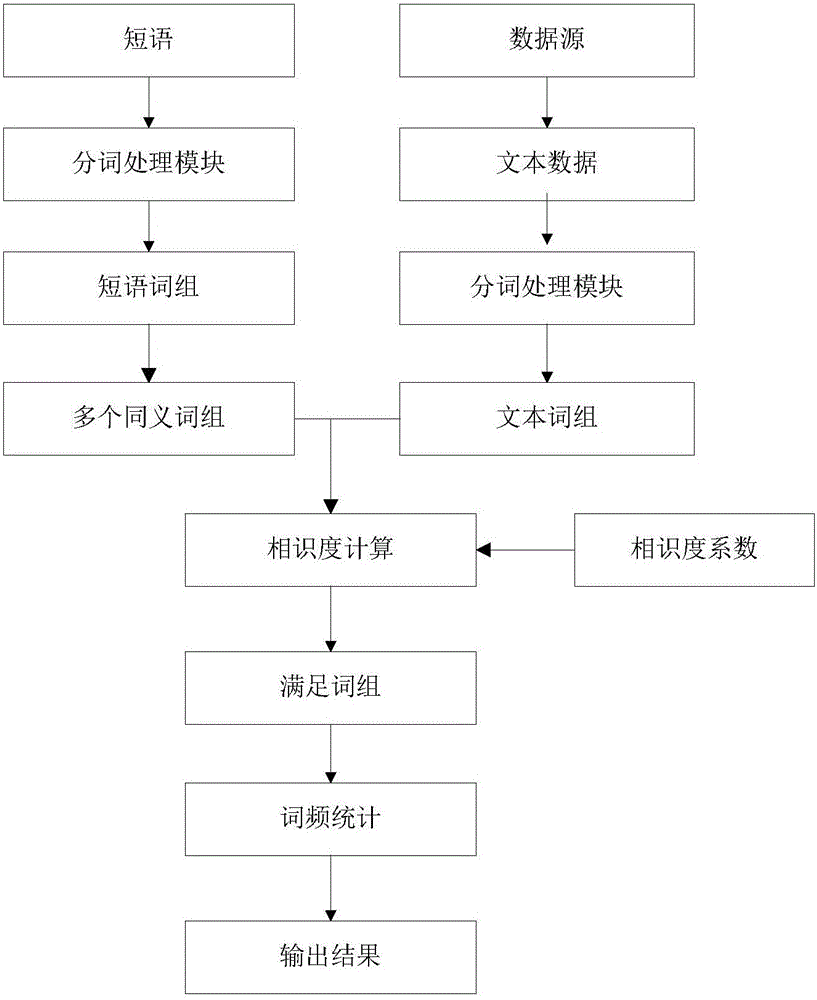
本发明的一种关联热词的统计方法,其方法流程如图2所示:
S1根据需要统计的时间周期范围从数据源获取文本数据。
S2输入需要进行热词分析的短语。
S3对短语输入分词处理模块,拆分成词组。
S4对文本数据输入分词处理模块,输出文本词组。
S5短语词组中的词与同义词库进行匹配,如果有同义词,则新增短语词组的拷贝,把同义词替换原词后作为新增同义短语词组。
S6同义短语词组与文本词组进行相似度计算,找出符合要求的文本词组。
S7对符合要求的文本词组进行词频统计,从高到低输出词组。
其中S4分词处理模块的详细步骤如下:
S4.1把文本根据分词计算方法,拆分成词。
S4.2根据词性,过滤掉副词,助词,标点符号等无意义的词。
S4.3词组与停用词库进行对比,去除停用词库包含的词。
S4.4输出分词词组。
其中S6相似度的详细计算步骤如下:
S6.1按顺序取出一个文本词组。
S6.2取出一个同义短语词组,对短语词组与文本词组进行匹配计算,判断文本词组中是否包含该同义词组的所有词,或者含有的词的个数/同义词词组的个数>相似度百分比系数。如果满足条件则认为这个文本词组是满足相似度条件。
S6.3如果满足条件则把词组加入满足词组队列,重复S6.1;否则继续下一个同义短语词组,直到全部短语词组都处理完,再重复步骤S6.1。
此外,还能够通过预先训练好分类器,对文本进行分类后,找出需要的分类后,再进行词频统计,输出热词。但是分类器需要先训练,而且需要有一定量的训练文本才可以进行训练,训练文本一般也是通过人工判断来产生的。
以上对本发明实施例进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!