一种软件隐私泄露行为的定量分析方法及装置与流程
本发明实施例涉及计算机技术领域,具体涉及一种软件隐私泄露行为的定量分析方法及装置。
背景技术:
针对软件隐私泄露问题,近年来的工作主要依据两种思路:一种基于模糊测试的方法,对于软件输入输出数据进行比对分析;另一种基于恶意软件行为分析技术,对于软件的内部功能进行分析。
基于模糊测试方法是比对输入输出数据来验证软件是否泄漏隐私的方法。这种方法将软件的内部工作过程视为一个黑盒,不去了解其内部结构和通信协议,仅关注软件的输入数据和向外部网络输出的数据之间的关系。该方法通过构造特定的隐私数据,观察其输出数据是否含有输入的隐私数据,从而发现软件是否含有隐私泄露行为。虽然基于输出输出数据比对的黑盒模糊测试方法能够快速准确的分析出某些特定格式的隐私数据泄露行为,但是这类方法也存在一些固有的问题:由于无法获知目标软件的内部实现细节和源码,此类方法很难收集采用了加密连接的软件所传输的明文信息,这阻碍了对于软件输出数据内容的鉴别,使得输入输出数据的比对也变得很困难;网络数据流中和多条数据流之间的消息重组,会导致软件输出数据和输入数据的匹配误报率大大提升;经过针对性设计的软件可以改变隐私数据在网络输出数据流中序列结构,使之具有随机化的长度和顺序,将真实的隐私数据隐藏于噪音数据之中,会导致软件的检测率大幅下降。
恶意软件行为建模与分析是近年来备受关注的重要研究问题,已有不少的成熟的理论模型和分析方法,但是不同的方法都具有各自适 用性和局限性,具体到软件隐私泄露行为分析这个新的热点问题上还存在一些尚未解决的问题。
在实现本发明实施例的过程中,发明人发现现有的软件隐私泄露行为的分析方法未针对目标软件的具体特性进行定量分析,从而导致软件隐私泄露行为分析不够严谨。
技术实现要素:
由于现有的软件隐私泄露行为的分析方法未针对目标软件的具体特性进行定量分析,而导致软件隐私泄露行为分析不够严谨的问题,本发明提出一种软件隐私泄露行为的定量分析方法及装置。
第一方面,本发明实施例提出一种软件隐私泄露行为的定量分析方法,包括:
根据目标软件的属性值,构建软件隐私泄露行为模型;
计算所述软件隐私泄露行为模型中每条行为路径发生隐私泄露的概率,并根据所述每条行为路径发生隐私泄露的概率,计算得到所述目标软件隐私泄露的可能性;
若判断获知所述隐私泄露可能性大于预设值,则根据每条行为路径发生隐私泄露的概率,计算得到每条行为路径发生隐私泄露的严重性,并根据所述每条行为路径发生隐私泄露的严重性,计算得到所述目标软件隐私泄露的严重性。
优选地,还包括:
计算所述软件隐私泄露行为模型中的部分完成泄露路径的数量,所述部分完成泄露路径为所述软件隐私泄露行为模型中包括源位置或判决位置的行为路径;
根据所述数量,计算所述目标软件隐私泄露的操纵性。
优选地,还包括:
根据目标行为路径,计算所述目标软件隐私泄露的隐秘性,所述目标行为路径为所述软件隐私泄露行为模型中至少包括一个源位置的行为路径。
优选地,还包括:
根据每个目标软件隐私泄露的可能性、严重性、操纵性和隐秘性,建立候选指标矩阵;
根据所述候选指标矩阵,计算得到每个目标软件隐私泄露的整体泄露度。
优选地,所述根据所述候选指标矩阵,计算得到每个目标软件隐私泄露的整体泄露度,进一步包括:
根据所述候选指标矩阵,计算得到所述候选指标矩阵的相关系数矩阵;
计算所述相关系数矩阵的特征值和特征向量,并根据所述特征值和特征向量,计算得到候选主成分;
根据所述候选主成分,计算得到每个目标软件隐私泄露的整体泄露度。
第二方面,本发明实施例还提出一种软件隐私泄露行为的定量分析装置,包括:
模型构建模块,用于根据目标软件的属性值,构建软件隐私泄露行为模型;
可能性计算模块,用于计算所述软件隐私泄露行为模型中每条行为路径发生隐私泄露的概率,并根据所述每条行为路径发生隐私泄露的概率,计算得到所述目标软件隐私泄露的可能性;
严重性计算模块,用于若判断获知所述隐私泄露可能性大于预设值,则根据每条行为路径发生隐私泄露的概率,计算得到每条行为路径发生隐私泄露的严重性,并根据所述每条行为路径发生隐私泄露的严重性,计算得到所述目标软件隐私泄露的严重性。
优选地,还包括:
操纵性计算模块,用于计算所述软件隐私泄露行为模型中的部分完成泄露路径的数量,所述部分完成泄露路径为所述软件隐私泄露行为模型中包括源位置或判决位置的行为路径;并根据所述数量,计算所述目标软件隐私泄露的操纵性。
优选地,还包括:
隐秘性计算模块,用于根据目标行为路径,计算所述目标软件隐私泄露的隐秘性,所述目标行为路径为所述软件隐私泄露行为模型中至少包括一个源位置的行为路径。
优选地,还包括:
矩阵建立模块,用于根据每个目标软件隐私泄露的可能性、严重性、操纵性和隐秘性,建立候选指标矩阵;
整体泄露度计算模块,用于根据所述候选指标矩阵,计算得到每个目标软件隐私泄露的整体泄露度。
优选地,所述整体泄露度计算模块进一步包括:
相关系数矩阵计算单元,用于根据所述候选指标矩阵,计算得到所述候选指标矩阵的相关系数矩阵;
主成分计算单元,用于计算所述相关系数矩阵的特征值和特征向量,并根据所述特征值和特征向量,计算得到候选主成分;
整体泄露度计算单元,用于根据所述候选主成分,计算得到每个目标软件隐私泄露的整体泄露度。
由上述技术方案可知,本发明实施例通过目标软件的属性值构建软件隐私泄露行为模型,并进一步计算目标软件隐私泄露的可能性和严重性,使得软件隐私泄露行为的分析结合了严谨的数学运算,其定量分析结果更为严谨和准确。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些图获得其他的附图。
图1为本发明一实施例提供的一种软件隐私泄露行为的定量分析方法的流程示意图;
图2为本发明一实施例提供的一种软件隐私泄露行为的定量分析装置的结构示意图。
具体实施方式
下面结合附图,对发明的具体实施方式作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
图1示出了本发明一实施例提供的一种软件隐私泄露行为的定量分析方法的流程示意图,包括:
S101、根据目标软件的属性值,构建软件隐私泄露行为模型;
其中,隐私泄露行为可以被定义为如下的四元组:
PL(pctg,pcont,pproc,pdest)
pctg,pcont,pproc pdest这四个属性值和单个隐私的属性值对应,PL中的四个值是对于整个目标软件而言的,它刻画了该软件的整体隐私泄露行为。
这个四元组的计算是依据两方面的数据,一方面是全局PPN本身的静态结构,包括模块的组合方式、位置、变迁和弧上的变量设置;另一方面是模型运行以后,代表隐私泄露实例的令牌的最终属性值。
S102、计算所述软件隐私泄露行为模型中每条行为路径发生隐私泄露的概率,并根据所述每条行为路径发生隐私泄露的概率,计算得到所述目标软件隐私泄露的可能性;
其中,可能性是下述定量指标的计算基础,它是对于软件中是否存在泄漏行为的概率的衡量,映射到行为路径上,就是行为路径实际构成隐私泄露路径的概率。假设σpath1是路径集BPS中的一条行为路径,它包含n1个变迁和n1+1个位置,这些变迁的权重是wti,1≤i≤n1,那么该路径的可能性如下计算:
如果整个BPS中共有N条行为路径,那么所有路径的平均可能性就是该行为路径集对应的软件行为的隐私泄露可能性,计算公式如下:
在上式中,每一条路径的变迁权重越高,它是泄露路径的概率越高,这样的高概率泄露路径在路径集中含有的越多,则整个行为路径集的泄露可能性越大。这样的规则构成了计算其它指标的基础。
S103、若判断获知所述隐私泄露可能性大于预设值,则根据每条行为路径发生隐私泄露的概率,计算得到每条行为路径发生隐私泄露的严重性,并根据所述每条行为路径发生隐私泄露的严重性,计算得到所述目标软件隐私泄露的严重性。
其中,在确定了隐私泄露行为发生的可能性以后,尤其是可能性较高的时候,需要对于该行为可能造成的后续影响进行评估,也就是严重性这个指标的意义所在。计算严重性的时候,需要用到模块的严重性权重,以及行为路径的模块内子路径。首先,需要计算每一条行为路径单独的严重性指标,假设该路径经过m个PPN模块,那么其路径严重性计算如下:
然后,将所有的完整隐私路径的严重性基于其路径发生可能性进行平均,我们就可以得到整个软件行为的严重性:
其中NL是BPS中所有完整泄露路径的总数。
严重性是衡量泄露行为的一项综合和直观的指标,更高的严重性意味着该行为可能造成更多的实际损失。这本来是很难量化的指标,因为对于严重性的测量涉及很多的因素,比如泄露数据的类型、实际内容和泄露后的去向等等。而且在不同的场景下,用户对于损失的定义也是不同的,比如,在商业服务器上,系统信息型数据的泄露会让攻击者有针对性的寻找服务器的漏洞,这种情况下系统信息型隐私数据的泄露严重性就高于其它的类别;而在个人电脑上,动态生成的隐私数据诸如账户密码等会直接影响用户的经济利益,此类别的泄露严重性就更大。因此,在具体计算的时候必须根据实际情况来定义各种类别的隐私数据的相关模块的权重值。
所述软件隐私泄露行为模型又称为隐私Petri网(Privacy Petri Net,PPN)。Petri网是对离散并行系统的数学表示,是一种适合于描述异步并发现象的系统模型,它既有严格的数学定义,又有直观的图形表示,既有丰富的系统描述手段和系统行为分析技术,又为计算机科学提供坚实的概念基础,已有理论证明,Petri网的模拟能力与图灵机(Turing Machine)等价,研究领域趋向认为Petri网是所有流程定义语言之母。PPN是一种高级Petri网模型,结合并扩展了已有的一些高级Petri网模型的特点,例如着色Petri网,随机Petri网等,加入了建模隐私泄露行为的一些特有模型元素、相关算法和判定规则。
PPN有三个方面的主要特点:首先,PPN具有形式化的定义,为精准的描述目标软件的行为提供的数学基础,是PPN赖以定义各种 行为属性的基础;其次,PPN具有简洁精炼的图形化表示原语,能够提供直观易懂的软件行为表达方式,并且基于这些图形原语,定义了特殊的图形结构,依据这种结构可以分析、判定和评估软件行为的各种特性与相关指标;最后,PPN还采用了高度模块化的建模方法,通过扩展和组合已有的模块,可以快速的构建新的全局模型。总之,利用PPN可以构造出具有各种类型的具有隐私泄露行为的模型,为后续的分析提供模型基础。
本实施例通过目标软件的属性值构建软件隐私泄露行为模型,并进一步计算目标软件隐私泄露的可能性和严重性,使得软件隐私泄露行为的分析结合了严谨的数学运算,其定量分析结果更为严谨和准确。
进一步地,在上述方法实施例的基础上,所述方法还包括:
S104、计算所述软件隐私泄露行为模型中的部分完成泄露路径的数量,所述部分完成泄露路径为所述软件隐私泄露行为模型中包括源位置或判决位置的行为路径;并根据所述数量,计算所述目标软件隐私泄露的操纵性。
其中,操纵性是评估目标软件被其它软件操纵或者和其它软件协作完成隐私泄露行为的指标。某些软件只完成了部分的隐私泄露行为,其行为路径的也包含了很多部分完成的泄露路径,因此这样的路径集平均可能性会比较低。但是,这样软件并不能简单的被认为没有问题,他们可能成为其它的软件的工具和组件。现阶段出现了不少的多进程协作型的恶意软件,其工作模式就是利用这些完成部分功能的软件。比如,某软件把自己的功能分解成若干个部分,然后为每个部分单独创建进程,这些进行依次工作,将隐私数据当作“接力棒”传递出去;还有一种情况,某软件充当监工的角色,将工作分配给若干的进程完成,自己在幕后只负责指挥和控制。因此,操纵性的计算可以依据其完成的部分泄露行为的数量来进行,映射到行为路径上就是 部分完成的泄露路径。我们将至少包含了一个源位置或者一个判决位置的路径都定义为部分完成泄露路径。因此,操纵性可以如下计算:
其中NPL是部分完成的泄露路径的总数。
操纵性弥补了严重性对于泄露行为评估的不足,适用于某些较为复杂的泄露行为。我们对于操纵性的计算方式虽然将实际情况进行了简化,但是仍然保留了部分完成这个最为重要概念。尽管高操纵性并不表示该软件会直接对隐私数据造成泄露,但然后值得引起用户的注意。
对于隐私泄露型恶意软件,在定性分析得出结果以后,用户只要直接的查杀就能够很好的解决问题,但是,对于应用软件中可能存在的隐私泄露行为,无法替用户做出决定,毕竟用户主要是为了使用软件的正常功能,而且对于所界定的隐私泄露行为,用户也有自己的理解和选择。所以有必要给出更为详细和多方面的定量分析结果,为用户提供参考的依据和比较的标准,也为软件隐私泄露行为给出一个客观的评价体系。
进一步地,在上述方法实施例的基础上,所述方法还包括:
S105、根据目标行为路径,计算所述目标软件隐私泄露的隐秘性,所述目标行为路径为所述软件隐私泄露行为模型中至少包括一个源位置的行为路径。
其中,隐秘性指标是对于上述三个指标的补充,上述三个指标计算的都是软件通过行为路径直接表现出来的结果,但现在的软件往往采用了特殊的技术避免被监控和分析,这些技术在恶意软件中已经被广泛使用,渐渐的在应用程序中也能看到,比如加壳,混淆,隐藏等等,这都增加了软件隐私泄露行为的另一个指标——隐秘性。该指标衡量了隐私泄露软件的生存性以及持续泄露隐私数据的能力。
增加隐秘性的技术很多也很复杂,为了统一的衡量这个指标,采用了和行为路径有关的方式,将相邻触发的变迁之间的额外的系统调用数量作为计算的依据。不论是什么样的隐秘性技术,都会引入额外的操作,这些操作越复杂,引入的额外调用越多,隐秘性就越强。但是我们还是限定至少要先触发后续为源位置的变迁,否则无法构成泄露路径,而且大部分的调用都将被视为隐秘性相关的调用,这样会引起误报。
假设BPS中共有N条包含了至少一个源位置行为路径,行为路径σpathi,1≤i≤N总长度为ni,1≤i≤N,其后的调用序列中无法与变迁相关的系统调用数量为nei,则软件行为的隐私泄露隐秘性为:
由于隐秘技术的使用,隐秘性高的软件的行为路径集往往表现出大量的不完整路径,但是这和计算操纵性时涉及的不完整路径是有本质区别的,其真实的行为很可能缺失包含完整的泄露路径,因此高隐秘性的软件更需要额外的重视和进一步的分析,否则很可能长时间的驻留于用户主机中造成更大的危害。
进一步地,在上述方法实施例的基础上,所述方法还包括:
S106、根据每个目标软件隐私泄露的可能性、严重性、操纵性和隐秘性,建立候选指标矩阵;
S107、根据所述候选指标矩阵,计算得到每个目标软件隐私泄露的整体泄露度。
本实施例提供的软件隐私泄露行为的定量分析方法的评价指标主要包括四个方面:可能性(possibility),严重性(severity),操纵性(manipulability)和隐秘性(crypticity)。可能性是其他三个指标的基础,表示软件包含隐私泄露行为的概率。对于高可能性的软件,我们会进一步关注其造成严重后果的能力,这个性质我们称为严重 性。对于低可能性的软件,我们会考虑其是否具有和其他软件协作完成泄露行为,或者被其他软件利用实施泄露行为,这种性质我们称为操纵性。此外,还有一个值得关注的属性,就是软件的实际行为和表面上被追踪和观察到的不同,恶意的行为被隐藏在正常行为下面,这种性质我们称为隐秘性。通过这些不同侧面的性质,可以很好的刻画出软件行为的立体观感,为用户理解我们的分析结果和后续操作提供依据。
最后还有给出一个整体的指标,称之为整体泄露度(OD,Overall Degree),这个指标是通过特定算法消除了四个指标之间的重复关联性而得出的,它作为一个综合的指标,能够为不同软件之间隐私泄露行为提供直接比较的参数,也能够给予用户对于该软件隐私泄露行为总体程度的直观理解。
行为路径作为PPN主要的输出结果,行为路径构成的集合BPS代表了软件的行为。在定量分析中,我们同样使用行为路径作为主要的依据,不过我们需要额外添加一些重要的参数和新的处理方法。
设σpath1=inst1.proc=p1t1p2…pn-1tn-1pn是一条行为路径,我们首先给该路径上的每一个变迁分配权重w,该权重是根据此变迁在当前路径中的重要性设定的,变迁ti的权重记作:
wti∈(0,1),1≤i≤n-1
该权重的初始值是来自于对于已知隐私泄露型恶意软件的统计结果,越高的权重值表示此变迁在已知恶意软件的泄露路径中出现和被成功触发的概率越大。这个值主要用于计算泄露行为的可能性。
然后,我们将整个行为路径依据其覆盖的模块划分为若干个部分。假设行为路径σpath1经过m个模块,覆盖每个模块中的变迁数量为ki(1≤i≤m),那么该路径可以表示为模块间的子路径σi(1≤i≤m)的连接,如下所示:
σpath1=σ1σ2…σm,其中σi=p1t1p2t2…pkitkipki+1
接下来,再次引入一个权重,该权重是分配给每一个子路径的,记作:
wσi,1≤i≤m
该权重表示的是该子路径所在的模块相关的泄露行为,表示该行为可能造成的后续影响的严重程度。我们赋予各个模块的该参数主要是体现他们的严重性的差异和顺序,假设现在共有k个预定义的PPN模块,我们先按照其严重程度进行排序,然后程度最轻的设置为1,最重的设置为k,这个值主要是用来计算严重性和操作性。
上述四个指标分别描述了隐私泄露行为的不同方面的特性,他们彼此之间也是存在着相关影响的潜在联系的。可能性是支配其它三个指标的核心指标,严重性和操纵性在行为路径总数确定的情况下此消彼长,隐秘性对于其它三个指标有着不确定的影响。接下来我们将深入分析这些相互关系。
可能性是评估其它指标的基础指标。更高的可能性意味着更大的路径行为发生概率这个因子在其它指标的计算公式中都是作为乘子出现的,在数值上直接影响它们的计算结果,呈现较为标准的正相关关系。
可能性与其它指标的关系所表示的实际意义是比较容易理解的。只有隐私泄露行为有更大的几率发生,该行为在同样的路径严重性权重下,最终的后续结果的期望——整体行为性才会更高;由部分完成的泄露路径决定的操纵型也类似,在泄露行为能够发生的情况下,才能够被其它程序操纵组合完成泄露行为;在采用同样的隐秘技术的情况下,被隐藏的泄露路径的发生可能性越大,隐秘的结果更具威胁,这是造成可能性和隐秘性正相关的主要原因。
严重性和操纵性具有类型含义和计算方法,主要的区别在于两种所依据的行为路径,前者是完整的泄露路径后者是部分完成的泄露路径,因此在其它情况相同的情况下,两种路径在行为路径集中的比例 决定了两个值的关系。通常情况下,两个值和总和是固定值,按两种路径的数量此消彼长。
由于严重性和操纵性分别描述的是软件直接表现出来的后续结果和潜在的威胁,因此,为了完整的评估隐私泄露行为,这两个指标是非常重要的。
隐秘性是较为特殊的指标,它描述的是未被实际追踪到了软件隐私泄露行为。该指标虽然不直接从数值上影响其它指标,但是在实际分析的过程中,它的间接影响通常是比较明显的。在其它条件基本相同的情况下,它会减少其它指标的数值,这是因为实际的行为路径被隐藏和掩盖了,这些路径相关的指标值无法计算在内。因此,即使软件的其它指标都比较低,如果隐秘性较高,该软件存在泄漏行为的几率也是比较大的。
更进一步地,在上述方法实施例的基础上,S108进一步包括:
S1071、根据所述候选指标矩阵,计算得到所述候选指标矩阵的相关系数矩阵;
S1072、计算所述相关系数矩阵的特征值和特征向量,并根据所述特征值和特征向量,计算得到候选主成分;
S1073、根据所述候选主成分,计算得到每个目标软件隐私泄露的整体泄露度。
四个单项指标给出了泄露行为在不同侧面的特性,彼此之间也有着密切的关系,为了给出能够在不同软件之间直接比较的综合指标,我们还需要将这四个指标进一步融合起来。接下来,我们将介绍对于这个问题的处理——整体泄露度(OD,overall privacy leak degree),这一衡量软件隐私泄露行为的综合指标。
计算不同软件之间可比较的整体泄露度的问题可以被抽象成为一个多属性决策问题(Multiple Attribute Decision Making,MADM)。 多属性决策问题是对于存在多个属性的候选项进行排序和选择的问题。关于OD计算的MADM问题可以如下表示:
假设有n个候选项A1,A2,…,An,分别表示n个待分析的软件,每个候选项有4个属性值P,S,M,C,分别表示前文提到的4个指标。那么我们可以得到候选项/指标矩阵M:
该矩阵中,每行表示一种指标,每列表示一个候选项。每个元素表示第i个软件的第j个指标的得分mij。x1到x4是代表一行元素的变量,O1,O2,...,On是与一列元素相关的变量,表示最终的泄露度OD。
OD值的计算方法我们称之为PLEAS算法(Privacy Leak ovErall quAntitative analysiS)。该算法是基于解决MADM较为常用的主成分分析法(principal component analysis,PCA)实现的。PCA方法可以有效区别出多个属性之间的相似性和相异性,并且尽可能的减少属性合成后的信息损失,是一种适用于解决我们面临的隐私泄露度计算问题的有效方法。
PLEAS算法的主要流程如下:
(1)将所有待分析软件作为候选项,它们的的四个分项指标作为元素按照上式中的结构组成矩阵M。然后将所有数据归一化,得到归一化的元素值和变量值具体计算方法如下:
其中
(2)计算矩阵M的相关系数矩阵R=rij(4×4):
(3)由矩阵R的特征值和特征向量生成候选主成分。假设特征值为λ1≥λ2≥λ3≥λ4≥0,相关的特征向量为u1,u2,u3,u4,其中ui=[u1i,u2i,u3i,u4i]T,那么得到CPC如下:
(4)从候选主成分中选出需要的个数。一般来说,总数不超过原来的变量总数。选择的标准是依据候选主成分的信息量占比bi,特征值最大的第一个主成分信息量最大,后续的依次减小,bi的计算主要依据特征值,方法如下:
(5)然后通过bi计算累计信息量占比ap:
逐渐增大p的值使ap接近1,通常超过0.9即可,这时的p个候选主成分就是我们最终需要的主成分。
(6)按照选定的主成分计算每个候选项的最终总体评分:
最后得到的Oi的值就是软件的整体泄露度OD。经过计算后,OD值越高的整体泄露度越大。
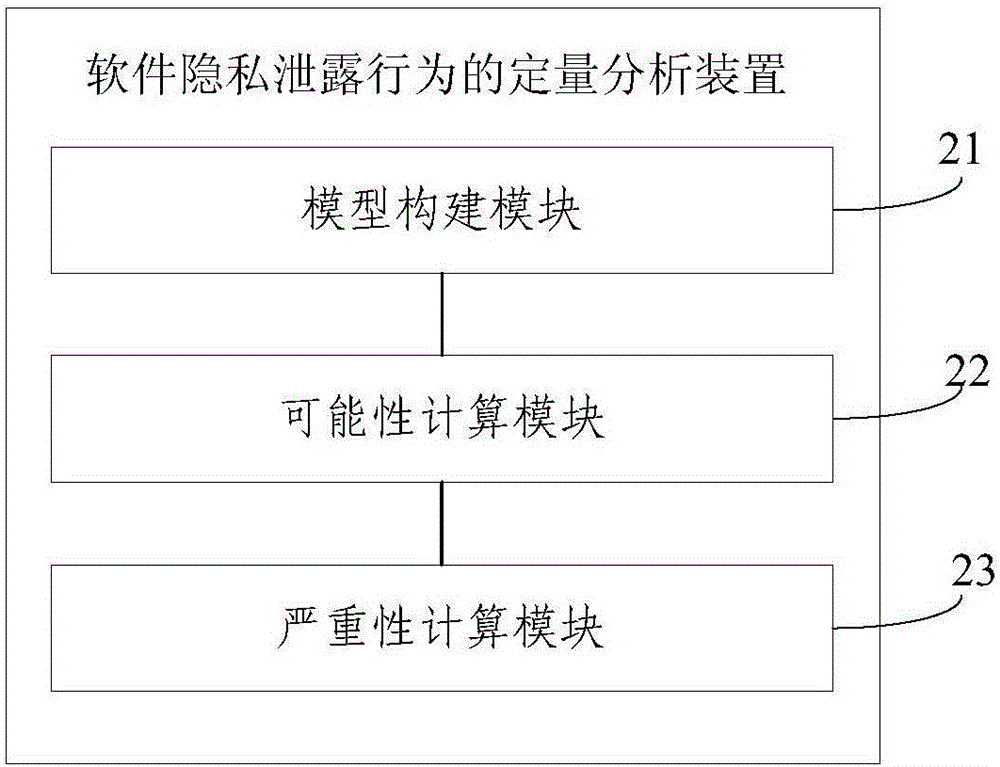
图2示出了本发明一实施例提供的一种软件隐私泄露行为的定量分析装置的结构示意图,所述装置包括:模型构建模块21、可能性计算模块22和严重性计算模块23,其中,
所述模型构建模块21用于根据目标软件的属性值,构建软件隐私泄露行为模型;
所述可能性计算模块22用于计算所述软件隐私泄露行为模型中每条行为路径发生隐私泄露的概率,并根据所述每条行为路径发生隐私泄露的概率,计算得到所述目标软件隐私泄露的可能性;
所述严重性计算模块23用于若判断获知所述隐私泄露可能性大于预设值,则根据每条行为路径发生隐私泄露的概率,计算得到每条行为路径发生隐私泄露的严重性,并根据所述每条行为路径发生隐私泄露的严重性,计算得到所述目标软件隐私泄露的严重性。
具体地,所述模型构建模块21根据目标软件的属性值,构建软件隐私泄露行为模型;所述可能性计算模块22计算所述软件隐私泄露行为模型中每条行为路径发生隐私泄露的概率,并根据所述每条行为路径发生隐私泄露的概率,计算得到所述目标软件隐私泄露的可能性;所述严重性计算模块23若判断获知所述隐私泄露可能性大于预设值,则根据每条行为路径发生隐私泄露的概率,计算得到每条行为路径发生隐私泄露的严重性,并根据所述每条行为路径发生隐私泄露的严重性,计算得到所述目标软件隐私泄露的严重性。
本实施例通过目标软件的属性值构建软件隐私泄露行为模型,并进一步计算目标软件隐私泄露的可能性和严重性,使得软件隐私泄露行为的分析结合了严谨的数学运算,其定量分析结果更为严谨和准确。
进一步地,在上述装置实施例的基础上,所述装置还包括:
操纵性计算模块24,用于计算所述软件隐私泄露行为模型中的部分完成泄露路径的数量,所述部分完成泄露路径为所述软件隐私泄露行为模型中包括源位置或判决位置的行为路径;并根据所述数量,计算所述目标软件隐私泄露的操纵性。
进一步地,在上述装置实施例的基础上,所述装置还包括:
隐秘性计算模块25,用于根据目标行为路径,计算所述目标软件隐私泄露的隐秘性,所述目标行为路径为所述软件隐私泄露行为模型中至少包括一个源位置的行为路径。
进一步地,在上述装置实施例的基础上,所述装置还包括:
矩阵建立模块26,用于根据每个目标软件隐私泄露的可能性、严重性、操纵性和隐秘性,建立候选指标矩阵;
整体泄露度计算模块27,用于根据所述候选指标矩阵,计算得到每个目标软件隐私泄露的整体泄露度。
更进一步地,在上述装置实施例的基础上,所述整体泄露度计算模块27进一步包括:
相关系数矩阵计算单元271,用于根据所述候选指标矩阵,计算得到所述候选指标矩阵的相关系数矩阵;
主成分计算单元272,用于计算所述相关系数矩阵的特征值和特征向量,并根据所述特征值和特征向量,计算得到候选主成分;
整体泄露度计算单元273,用于根据所述候选主成分,计算得到每个目标软件隐私泄露的整体泄露度。
本实施例所述的软件隐私泄露行为的定量分析装置可以用于执行上述方法实施例,其原理和技术效果类似,此处不再赘述。
本发明的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
- 还没有人留言评论。精彩留言会获得点赞!