基于增量式分区策略的MapReduce数据均衡方法与流程
本发明属于MapReduce编程领域,具体涉及一种基于增量式分区策略的MapReduce数据均衡方法。
背景技术:
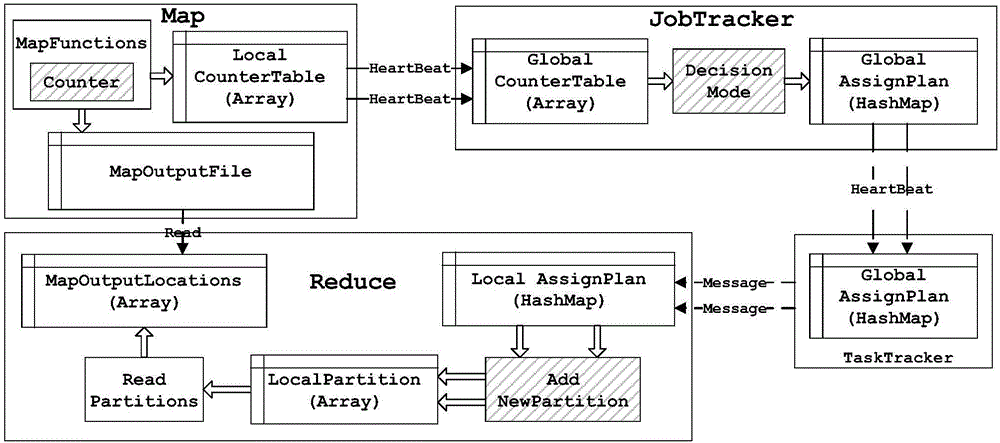
:MapReduce编程模型包含两个阶段,即Map阶段和Reduce阶段。在Map阶段,每一个Mapper从本地HDFS上加载splits进行处理,输出为<key,value>对形式,产生的数据用hash函数分配到不同的partition,每一个partition对应着一个Reducer,一旦Map完成,Hadoop开始将数据shuffle到对应的Reducer,在一般情况下,hash方法能够确保每一个Reducer能够接受到均衡数量的partition,然而,由于partition存在数据倾斜的可能,所以不能保证各个Reducer的负载均衡。技术实现要素:要解决的技术问题为了有效避免数据倾斜造成的负载不均衡这一问题,本发明提出一种基于增量式分区策略的MapReduce数据均衡方法,提出一种更高效的方法有着巨大的现实需求。技术方案一种基于增量式分区策略的MapReduce数据均衡方法,其特征在于步骤如下:步骤1:确定一系列的决策点,在每一个决策点t使用优化的马尔科夫决策模型(S,A,P,Rat(st,st+1),γ)对在Map端产生的N个微分区进行自动分区,其中N>M,M为Reducer个数;决策点的确定:以第一个Mapper完成时刻为第一个决策点,运行到最后一个Mapper的α时刻为最后一个决策点,中间的决策点采用等分原则;所述的马尔科夫决策模型(S,A,P,Rat(st,st+1),γ):S是状态的有限集,A是行动的有限集,行动是自动选择前k个微分区,P是状态转换概率的集合,γ是代表现在和将来报酬拥有不同的重要性的折扣因素,为报酬函数;其中W是微分区的总量,是在决策点t已分配的微分区的总量,N是微分区的总个数,是在决策点t以后未分配的微分区的总个数;步骤2:采用LPT算法对步骤1中的分区进行分配,将并行代价的目标函数的作为LPT算法的输出:所述的并行代价的目标函数:minmaxj{Ljf}]]>s.t.(1)---∀1≤i≤h,Σ1≤j≤Mxij=1(2)---∀1≤i≤M,Lj=Lj+Σi(xij·eic)]]>其中,Lj为给第j个Reducer分配的初始负载,为第j个Reducer被分配微分区后的负载,h为在决策点t之前未被分配的微分区总个数,xij为Pu中的微分区到Reducer的映射,Pu为在决策点t之前未被分配的微分区集合,如果第i个微分区被分配到第j个Reducer则xij=1,否则xij=0;指在Pu中第i个微分区预估的数量,指被分配到第j个Reducer上的微分区的总量。90%≤α≤100%。有益效果本发明提出的一种基于增量式分区策略的MapReduce数据均衡方法,具体为首先在Map端产生多于Reducer个数的微分区,微分区的负载统计被持续收集并且发送给决策者,在每一个决策点,优化的马尔科夫模型在未被分配的微分区中自动进行分区选择,然后利用分配算法将选中的微分区分配到各Reducer上;依照此方法,经过多次分区选择和分配,最终在执行Reduce函数前,将所有微分区分配到Reduce端,该方法使得数据划分更加均衡,有效避免了数据倾斜所带来的负载不均衡问题。附图说明图1增量式分区的处理流程图图2增量式分区在Hadoop系统上的实现图具体实施方式现结合实施例、附图对本发明作进一步描述:本发明提出了基于增量式分区策略的MapReduce数据均衡方法,增量式分区的处理流程见图1,解决其技术问题所采用的技术方案包括以下内容:1.并行代价目标函数Hadoop负载均衡的最终目标是优化并行时的表现,为了实现这一目标,增量式分区策略需要考虑数据Shuffle和Reducer之间负载均衡的代价,假设Map端产生N个微分区,Reducer个数为M个,决策点数量为K个,可以表示为{T1,...,TK}。增量式分区策略包括一系列的行动。在每一个决策点选择出一些未分配的微分区而后再分配给相应的Reducer,最终,N个微分区将全部分配到Reducer端并且每一个微分区只被分配一次。并行代价的目标函数为:minmaxj(f1(Rj)+Σi(aij×f2(Si)))---(1)]]>Si表示第i个微分区的大小,aij表示微分区到Reducer的映射,aij=1表示第i个微分区被分配到第j个Reducer,否则aij=0,Rj表示第j个Reducer,f2()表示微分区的计算代价。在本发明中,我们用微分区的大小来表示其计算代价。为了减小并行代价,本发明采取如下的分区选择和分区分配方法。2.分区选择给定一系列的决策点和一个微分区集合P,分区选择就是在每一个决策点从P中选择一个子集,用以准备将其中的微分区分配到对应的Reducer。本发明基于马尔科夫决策模型提出一种优化模型用以实现自动分区选择。标准的马尔科夫决策模型是一个五元组(S,A,P,R,γ),S是状态的有限集,A是行动的有限集,P是状态转换概率的集合,R是状态转换报酬,γ是代表现在和将来报酬拥有不同的重要性的折扣因素。(1)报酬函数选择一个微分区进而将其分配后可以使其立即开始Shuffle,但是也减小了以后均衡调整的机会,因此,我们综合考虑两个冲突的因素后定义如下的报酬函数:Rat(st,st+1)=WctW·NutN---(2)]]>W是微分区的总量,是在决策点t已分配的微分区的总量,N是微分区的总个数,是在决策点t以后未分配的微分区的总个数。在等式(2)中,第一部分对应着在决策点t已分配的微分区在所有微分区中占的数量比,它用来衡量能否尽早Shuffle;第二部分代表在决策点t后未分配的微分区在所有微分区中占的个数比,它用来衡量还可以负载均衡的机会。在决策点t已分配的微分区更多将导致增大减小。值得指出的是在某一决策点无论是没有微分区被分配还是全部的微分区被分配都将导致最小报酬是0。(2)决策点的确定决策点的确定问题即为微分区的选择与分配时机确定问题,微分区分配过早会导致可以负载均衡的机会更小,分配过晚会延迟Shuffle时间。本发明定义第一个Mapper完成时刻为第一个决策点,用户可定义一个变量α(90%≤α≤100%),定义运行到最后一个Mapper的α时刻为最后一个决策点,中间的决策点采用等分原则。如此既能增大负载均衡机会又减少了Shuffle时间的延迟。(3)优化的马尔科夫决策模型优化的马尔科夫决策模型中在每一个决策点的行动是自动选择前个k微分区,如此可获得最大报酬,以下是证明过程:假设在一个最佳的解决方法SL1中,在决策点ti的行动是选择了一个微分区集合Pti,其中Pti不是最大的,在决策点ti有一个未分配的微分区p,p的大小比在Pti中的微分区p'大,假设在SL1中p'在决策点tj被选择,解决方法SL2和SL1除了在决策点ti选择了p'和在决策点tj选择了p之外行动都是相同的。通过我们定义的报酬函数我们可以得到:Ri,j(SL1)Ri,j(SL2)=Wc1i·Nu1i+Yj-i·Wc1j·Nu1jWc2i·Nu2i+Yj-i·Wc2j·Nu2j---(3)]]>Ri,j(SL1)指在解决方法SL1中在决策点ti和tj实现的总报酬,指在解决方法SL1中在决策点ti已分配的微分区的总量,指在解决方法SL1中在决策点ti后还未分配的微分区的个数,其中和还可以得出因此Ri,j(SL1)<Ri,j(SL2)。因为在除了ti和tj之外的其他任意一个决策点,SL1和SL2实现了相同的报酬,因此SL2的总报酬大于SL1。因此,在每一个决策点自动选择前k个微分区可获得最大报酬。3.分区分配分区分配的主要目标是确保各个Reducer计算的负载均衡。因此,我们可以将在决策点t分区分配的问题表示为装箱最优化问题。假设给第i个Reducer分配的初始负载为Li,在决策点t之前未被分配的微分区总个数为h,用集合表示为Pu,使用变量xij去指代Pu中的微分区到Reducer的映射,如果第i个微分区被分配到第j个Reducer则xij=1,否则xij=0。则最优化问题可表示为minmaxj{Ljf}---(4)]]>s.t.(1)---∀1≤i≤h,Σ1≤j≤Mxij=1(2)---∀1≤i≤M,Lj=Lj+Σi(xij·eic)]]>指在Pu中第i个微分区预估的数量,指被分配到第j个Reducer上的微分区的总量。我们用传统的LPT(LargestProcessingTimefirst)算法来实现分区分配,LPT算法的输出即为并行代价目标函数的解,如此我们可以实现并行代价的最小化。该方法在Hadoop系统上的具体实现见附图2。以下为在Hadoop上实现该方法的具体步骤:1.Counter模块在各个Mapper的运行线程中加入Counter模块,并将Counter的统计结果放入Table_LocalCounter中。微分区的个数决定了Table_LocalCounter的大小,并且在同一个任务中微分区的个数是不变的,因此可以用一维数组来实现,并且将Table_LocalCounter驻留在内存中。2.DecisionModel模块在JobTracker类中新添DecisionModel模块,以添加微分区的选择和分配功能。所有任务的Table_LocalCounter汇总后存入Table_GlobalCounter,在结构体Plan_GlobalAssign中添加分区分配计划。每次决策完成后,需要将Plan_GlobalAssign的更新增加到下次的Heartbeat通信中,如此Reducer节点可以实时的接收到分配计划。3.AddNewPartition模块Reducr在对Heartbeat解析以后,可将属于自己的分区信息获取到,对于原MapReduce架构,只需要各Reducer在MapOutputLocation中添加自己的信息,并开始等待Mapper的完成。在增量式分区策略中,由于Reducer的输入来源是多个分区,因此,需要增加AddNewPartition模块,将分区信息渐进地增加到LocalPartition中,然后进行微分区信息和分区的存储路径的转换并存放到MapOutputLocation中,该模块不仅可以实现Reducer初始化时的多分区分配,而且可以完成在Reducer读取数据过程中的增量式分配,从而实现对Reducer的渐进式分配方法。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1