一种基于多重预训练的深层神经网络训练方法与流程
本发明属于深层神经网络技术领域,尤其涉及一种基于多重预训练的深层神经网络训练方法,
背景技术:
深层神经网络被广泛应用于图像识别、语音识别、自然语言处理等领域,目前对深层神经网络的训练方法是通过单一模型进行预训练,得到具有一定特性的网络权重初值,然后用反向传播算法来训练网络。由于不同的预训练模型具有不同的特性,因此在实际应用过程中需要尝试不同的预训练模型,然后综合比较各个模型所得到初始网络的性能,最终确定理想的预训练模型。
然而,有一些问题对深层神经网络权值的初始值的要求是复合的,即要求深层神经网络权值的初始值具有多重特性,而不仅仅是单一的特性。
例如,授权发明专利CN201210594536将SVM的训练方法引入到神经网络的训练方法中,提出OIN/SVM混合模型来替代反向传播算法在训练神经网络过程中的作用。而本发明保留了反向传播算法,同时在反向传播算法开始之前,利用多重预训练的方法,为神经网络找到一个合理的初始值。
技术实现要素:
发明目的:本发明将多重预训练的思路引入到深层神经网络的训练过程中,使得深层神经网络权值的初始值具有较好的特性,进而使得后续的反向传播训练算法能够得到性能更好的模型。
本发明立足于解决这一类问题,提出用不同的预训练模型来确定深层神经网络权值的初始值,使深层神经网络权值的初始值具有不同模型的特点,从而更好地解决这一类问题。
技术方案:本发明公开了一种基于多重预训练的深层神经网络训练方法,包括如下步骤:
步骤1,随机选取神经网络的参数;
步骤2,用受限玻尔兹曼机对神经网络的参数进行逐层预训练;
步骤3,用去噪自编码器对神经网络的参数进行逐层预训练;
步骤4,用反向传播算法对神经网络的参数进行调整。
步骤1中,随机选取神经网络输入层和第一隐层之间的权值矩阵W、输入变量偏置b和隐变量偏置c。
步骤2包括如下步骤:
步骤2-1,输入权值矩阵W、输入变量偏置b和隐变量偏置c,随机选择M个训练样本(M的典型值取10),将这M个样本按行排列,形成一个M列的矩阵,记为x;
步骤2-2,计算sigm(Wx+b),sigm表示用西格玛函数逐一作用到向量Wx+b的每个元素上,西格玛函数的表达式为:
步骤2-3,以sigm(Wx+b)中的每一个元素为二项分布取1的概率,对每一个二项分布进行采样,得到隐变量h;
步骤2-4,计算sigm(WTh+c);
步骤2-5,以sigm(WTh+c)中的每一个元素为二项分布取1的概率,对每一个二项分布进行采样,得到重构的可见变量x’;
步骤2-6,计算sigm(Wx’+b);
步骤2-7,将权值矩阵W更新为W+∈(hxT-sigm(Wx’+b)x'T),
将输入变量偏置b更新为b+∈(h-sigm(Wx’+b)),
将隐变量偏置c更新为c+∈(x-x'),∈为学习步长(∈的典型值取0.01);
步骤2-8:重复步骤2-1~步骤2-7直到所有的样本都被选取过;
步骤2-9:重复步骤2-1~步骤2-8直到达到最大迭代次数,得到受限玻尔兹曼机预训练后的权值矩阵W、输入变量偏置b和隐变量偏置c。
步骤3包括如下步骤:
步骤3-1,在步骤2得到的权值矩阵W、输入变量偏置b和隐变量偏置c的基础上,随机选择M个训练样本(M的典型值取10),将这M个样本按行排列,形成一个M列的矩阵,记为x;
步骤3-2,对于每个样本,随机选取20%的元素设置为0,得到污染后的样本,记为x’;
步骤3-3,计算h=sigm(Wx’+b);
步骤3-4,计算误差e=||x-sigm(WTh+c)||2;
步骤3-5,将权值矩阵W更新为
将输入变量偏置b更新为
将隐变量偏置c更新为其中表示e关于参数θ(θ可以是W、b或者c)的偏导数;
步骤3-6,重复步骤3-1~步骤3-5,直到所有的样本都被选取过;
步骤3-7,重复步骤3-1~步骤3-6直到达到最大迭代次数。
步骤4包括以下步骤:
步骤4-1,在步骤3得到的各层权值矩阵W、输入变量偏置b和隐变量偏置c的基础上,随机选择M个训练样本(M的典型值取10),将这M个样本按行排列,形成一个M列的矩阵,记为x,根据神经网络的计算公式,逐层计算各层神经网络节点的取值;
步骤4-2,根据反向传播公式,计算输出误差关于各层神经网络参数的梯度;
步骤4-3,选取学习步长∈(典型值为0.01),根据步骤4-2求取的梯度,对各层神经网络的参数进行更新。
所述方法通过受限玻尔兹曼机和去噪自编码器对深层神经网络进行预训练。受限玻尔兹曼机和去噪自编码器都是针对双层网络提出的预训练模型,即基于这两种模型的深层神经网络预训练过程都是逐层进行的。
所述方法首先用受限玻尔兹曼机对网络进行逐层的预训练,即视相邻两层神经网络为一个受限玻尔兹曼机;然后用去噪自编码器对网络进行逐层的预训练,即视相邻两层神经网络为一个去噪自编码器,算法框架如图1所示。
所述方法在预训练受限玻尔兹曼机时采取的是对比散度算法,在实际的优化过程中,梯度是共享的,即之前优化步骤的梯度会影响当前优化步骤中的梯度。
所述算法在预训练受限玻尔兹曼机时采取的优化函数是
其中v和h分别是受限玻尔兹曼机输入层和隐层节点的取值,W、b和c分别是两层之间的连接权值和偏置量。
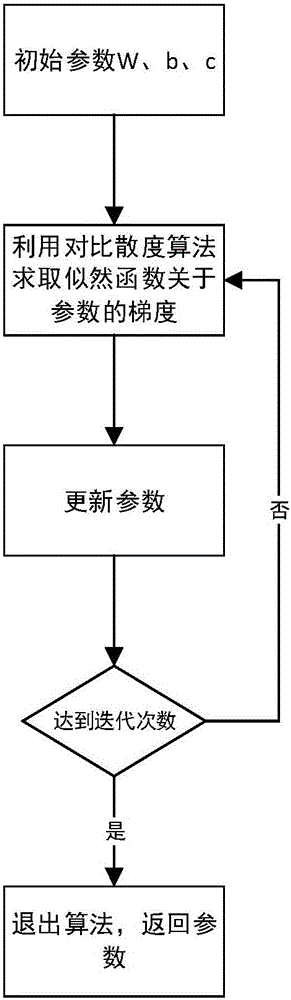
所述算法在预训练受限玻尔兹曼机时的学习步长是0.01,每次处理的样本个数是10个(即M取值为10),预训练的迭代优化步数为100步,实验表明,这样一组参数得到的模型性能比较好,算法流程如图2所示。
所述算法在预训练去噪自编码器时采用的污染策略是随机选择一定比例的节点并将这些节点的值赋为0。
所述算法在预训练去噪自编码器时采取的优化函数是
其中sigm表示sigmoid函数,是污染后的输入,v是干净的输入。优化目标是污染的信号经过去噪自编码器编码和解码之后得到的恢复信号与原始信号之间的平方误差。
所述算法在预训练去噪自编码器时污染比例为20%,学习步长是0.01,每次处理的样本个数是10个,预训练的迭代优化步数为100步,实验表明,这样一组参数得到的模型性能比较好,算法流程如图3所示。
所述算法在预训练深层神经网络时先逐层用受限玻尔兹曼机进行预训练,接着逐层用去噪自编码器进行预训练,最后用反向传播算法对网络的参数进行调整。
本发明提出的算法框架可以扩展至任意逐层的预训练模型,比如自编码器、收缩自编码器等,所述算法均可进行统一处理,并使得最终得到的预训练之后的网络具有这些模型的特性。
本发明还公开了一种根据前文所述方法的计算机手写字符识别中的应用,包括如下步骤:
第一步A:将数据划分为训练集(包含50000张手写字符图片)、验证集(包含10000张手写字符图片)和测试集(包含10000张手写字符图片);
第一步B:统一验证集中图片的尺寸为24像素*24像素;
第二步A:随机选取输入层和第一隐层之间的权值矩阵W(1)、输入变量偏置b(1)和隐变量偏置c(1);
第二步B:从训练集中选取10个样本作为输入变量,用对比散度算法,采取本发明中约定的参数对输入层和第一隐层之间的权值矩阵、输入变量偏置和隐变量偏置进行优化;
第二步C:重复第二步B,直到所有的训练样本都被选中过;
第二步D:根据神经网络的计算公式,利用输入变量,权值矩阵W(1)和输入变量偏置b(1)来计算第一隐层的变量的值,作为第一隐层和第二隐层构成的受限玻尔兹曼机的输入;
第三步:重复第二步的过程,优化第一隐层和第二隐层之间的权值矩阵W(2)、输入变量偏置b(2)和隐变量偏置c(2);
第四步:重复第二步的过程,优化第二隐层和第三隐层之间的权值矩阵W(3)、输入变量偏置b(3)和隐变量偏置c(3);
第五步A:从训练集中选取10个样本作为输入变量,以W(1)、b(1)和c(1)为初始值,根据去噪自编码器的优化函数和本发明所约定的参数,得到更新后的参数和
第五步B:重复第五步A,直到所有的训练样本都被选中过;
第五步C:根据神经网络的计算公式,利用输入变量,更新后的权值矩阵和更新后的输入变量偏置来计算第一隐层的变量的值,作为第一隐层和第二隐层构成的受限玻尔兹曼机的输入;
第六步:重复第五步的过程,更新第一隐层和第二隐层之间的权值矩阵输入变量偏置和隐变量偏置
第七步:重复第五步的过程,更新第二隐层和第三隐层之间的权值矩阵输入变量偏置和隐变量偏置
第八步:以和为初始值,随机选择第三隐层和输出层之间的参数W(4)和b(4),用反向传播算法对神经网络进行优化。
第九步:在验证集上测试优化后的神经网络的性能是否达到性能要求,如果没有,则重复第二~第八步。
有益效果:本发明与现有技术相比有如下优点:
1.本发明提出了新的预训练算法框架,综合利用了不同预训练模型的特性,使得预训练的结果具有不同模型的特性,从而具有更好的性能。在本方法中,神经网络被多种模型进行多重预训练,从而使得神经网络的参数初始值具有不同模型的特性,从而达到更好的训练效果。
2.支持收缩自编码器等其他逐层预训练模型的综合运用。
3.测试结果表明,选择合适的预训练策略可以提高模型的性能。
附图说明
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
图1是本发明演示模型的训练过程。
图2是受限玻尔兹曼机的预训练过程。
图3是去噪自编码器的预训练过程。
图4是演示模型的结构。
具体实施方式
如图2所示,预训练受限玻尔兹曼机的算法。
初始化W、b和c(对于第一次预训练的模型而言,参数是随机初始化的,其他情况下参数选择上次预训练的结果),选取学习步长∈=0.01,设置迭代次数N=100,设置同时处理的样本数M=10。
第一步A:依次选择M个样本,记为x;
第一步B:计算sigm(Wx+b);
第一步C:以sigm(Wx+b)中的每一个元素为取1的概率,对每一个二项分布进行采样,得到隐变量h;
第一步D:计算sigm(WTh+c);
第一步E:以sigm(WTh+c)中的每一个元素为取1的概率,对每一个二项分布进行采样,得到重构的可见变量x’;
第一步F:计算sigm(Wx’+b);
第一步G:更新W←W+∈(hxT-sigm(Wx’+b)x'T)、b←b+∈(h-sigm(Wx’+b))、c←c+∈(x-x')。
第二步:重复第一步直到所有的样本都被选取过。
第三步:重复第一步和第二步100次。
如图3所示,预训练去噪自编码器的算法。
初始化W、b和c(对于第一次预训练的模型而言,参数是随机初始化的,其他情况下参数选择上次预训练的结果),选取学习步长∈=0.01,设置迭代次数N=100,设置同时处理的样本数M=10,设置污染的比例为20%。
第一步A:依次选择M个样本,记为x;
第一步B:对于每个样本,随机选取20%的元素设置为0,得到污染后的样本,记为x’;
第一步C:计算h=sigm(Wx’+b);
第一步D:计算误差e=||x-sigm(WTh+c)||2;
第一步E:更新
第二步:重复第一步直到所有的样本都被选取过。
第三步:重复第一步和第二步100次。
如图1所示,演示模型的训练算法。
第一步:用受限玻尔兹曼机模型预训练,得到W(1)、b(1)和c(1)。
第二步:用受限玻尔兹曼机模型预训练,得到W(2)、b(2)和c(2)。
第三步:用受限玻尔兹曼机模型预训练,得到W(3)、b(3)和c(3)。
第四步:用去噪自编码器模型预训练,得到和
第五步:用去噪自编码器模型预训练,得到和
第六步:用去噪自编码器模型预训练,得到和
第七步:随机选取W(4)和b(4),以W(4)和b(4)为参数的初始值,利用反向传播算法对演示模型进行训练。
实施例
下面以三隐层神经网络为例介绍本发明在手写字符识别系统中的应用,网络结构如图4所示。
第一步A:将数据划分为训练集(包含50000张手写字符图片)、验证集(包含10000张手写字符图片)和测试集(包含10000张手写字符图片);
第一步B:统一图片的尺寸为24像素*24像素;
第二步A:随机选取输入层和第一隐层之间的权值矩阵W(1)、输入变量偏置b(1)和隐变量偏置c(1);
第二步B:从训练集中选取10个样本作为输入变量,用对比散度算法,采取本发明中约定的参数对输入层和第一隐层之间的权值矩阵、输入变量偏置和隐变量偏置进行优化;
第二步C:重复第二步B,直到所有的训练样本都被选中过;
第二步D:根据神经网络的计算公式,利用输入变量,权值矩阵W(1)和输入变量偏置b(1)来计算第一隐层的变量的值,作为第一隐层和第二隐层构成的受限玻尔兹曼机的输入;
第三步:重复第二步的过程,优化第一隐层和第二隐层之间的权值矩阵W(2)、输入变量偏置b(2)和隐变量偏置c(2);
第四步:重复第二步的过程,优化第二隐层和第三隐层之间的权值矩阵W(3)、输入变量偏置b(3)和隐变量偏置c(3);
第五步A:从训练集中选取10个样本作为输入变量,以W(1)、b(1)和c(1)为初始值,根据去噪自编码器的优化函数和本发明所约定的参数,得到更新后的参数和
第五步B:重复第五步A,直到所有的训练样本都被选中过;
第五步C:根据神经网络的计算公式,利用输入变量,更新后的权值矩阵和更新后的输入变量偏置来计算第一隐层的变量的值,作为第一隐层和第二隐层构成的受限玻尔兹曼机的输入;
第六步:重复第五步的过程,更新第一隐层和第二隐层之间的权值矩阵输入变量偏置和隐变量偏置
第七步:重复第五步的过程,更新第二隐层和第三隐层之间的权值矩阵输入变量偏置和隐变量偏置
第八步:以和为初始值,随机选择第三隐层和输出层之间的参数W(4)和b(4),用反向传播算法对神经网络进行优化。
第九步:在验证集上测试优化后的神经网络的性能是否达到性能要求,如果没有,则重复第二~第八步。本发明被应用到手写字符识别的应用中。在这一应用中,用于训练的图片为50000张,用于验证和测试的各10000张。本发明得到的神经网络在正确率上比用单一模型来进行预训练的神经网络提高了3%。
本发明提供了一种基于多重预训练的深层神经网络训练方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!