一种跨语言话题检测方法及系统与流程
本发明涉及跨语言话题检测技术领域,尤其涉及一种基于可比语料库的跨语言话题检测方法和系统。
背景技术:
跨语言话题检测的研究有助于不同国家和民族的人们能够实行知识共享,增强各个国家和民族地区网络信息安全,推进我国民族地区经济文化发展,促进民族团结,为构建“和谐社会”和“科学发展”的社会环境提供重要的条件支撑。
目前,跨语言话题检测主要有基于机器翻译、双语词典、双语平行语料库三种方法。对于基于机器翻译和词典的跨语言检测方法,由于每种语言都有自身的特征,在从源语言到目标语言翻译的过程中,会出现语义上的偏差,并产生噪声,从而改变源语言新闻报道所表达的意思,影响文本和话题相似度计算的准确度。因此翻译策略并不能在根本上提升跨语言话题检测的性能。基于平行语料库的跨语言话题检测方法主要面临的困难是平行语料难以获取且资源匮乏。
技术实现要素:
本发明的目的在于,解决现有的跨语言话题检测技术存在的上述问题,提供了一种跨语言的话题检测方法及系统,通过词向量扩充语言的关键词来提高跨语言文档相似度计算的准确率,通过基于LDA的话题模型构建,利用跨语言话题对齐实现了跨语言话题检测。
为了实现上述目的,一方面,本发明提供了一种跨语言话题检测方法,该方法包括以下步骤:
通过计算第一语言和第二语言的相似度来构建第一语言和第二语言的可比语料库;基于第一语言和第二语言的可比语料库分别构建第一语言话题模型和第二语言话题模型;在第一语言话题模型和第二语言话题模型生成的文档-话题概率分布的基础上通过相似度判定,以确定第一语言话题和第二语言话题的对齐,从而实现跨语言话题检测。
另一方面,本发明提供一种跨语言话题检测系统,具体包括:
第一生成模块,用于构建第一语言和第二语言的可比语料库;
第二生成模块,基于第一语言和第二语言的可比语料库分别构建第一语言话题模型和第二语言话题模型;
检测模块,用于在第一语言话题模型和第二语言话题模型生成的文档-话题概率分布的基础上通过相似度判定,以确定第一语言话题和第二语言话题的对齐,从而实现跨语言话题检测。
本发明提供的一种跨语言话题检测方法及系统,提高了跨语言文档相似度计算的准确率,通过基于LDA的话题模型构建,利用跨语言话题对齐实现了跨语言话题检测。
附图说明
图1为本发明实施例提供的一种跨语言话题检测方法流程示意图;
图2为本发明实施例提供的一种跨语言话题检测系统结构示意图;
图3为图1所示跨语言话题检测方法流程中涉及藏语和汉语的网络页面;
图4为图1所示跨语言话题检测方法流程中构建藏语LDA话题模型和汉语LDA话题模型的示意图,其中LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构,本实施例中的话题即为LDA中的主题;
图5为图1所示跨语言话题检测方法流程中通过吉布斯抽样法对LDA话题模型进行参数估计的示意图;
图6为图1所示跨语言话题检测方法流程中藏语话题和汉语话题的对齐过程示意图;
图7为本发明实施例提供的跨语言话题检测系统结构示意图。
具体实施方式
下面通过附图和实施例,对本发明的技术方案作进一步的详细描述。
本发明实施例提供了一种跨语言话题检测方法及系统,以提高跨语言文档相似度计算的准确率,通过基于LDA的话题模型构建,利用跨语言话题对齐实现了跨语言话题检测。
以下结合图1和图7对本发明实施例提供的跨语言话题检测方法进行详细阐述:
如图1所示,该方法包括步骤101-103:
步骤101,构建第一语言和第二语言的可比语料库,本实施例中,第一语言以藏语为例,第二语言以汉语为例。
(1)藏汉词典构建
如图3所示,利用网络爬虫,从维基百科中包含汉语链接的藏语网页中获取藏语和汉语对应的实体对;
从网络上下载藏汉词典,通过分割、替换获取实体对,并与利用网络爬虫从维基百科中获取的实体对一起构成新的藏汉词典。
(2)新闻语料获取
利用网络爬虫从新闻网站抓取藏语和汉语的新闻文档,包括新闻标题、时间、内容三部分。过滤掉内容较少的文档,从而获得初始的双语语料。
对初始的双语语料进行数据预处理,具体包括步骤:
分词:藏语分词使用国家语言资源监测与研究中心少数民族语言分中心开发的分词工具,汉语分词使用中科院计算所的自动分词软件ICTCLAS;
去除无意义的词:按照藏语和汉语停用词表中的词语分别将藏语、汉语新闻语料中无意义的词、符号、标点及乱码等去掉。
词性选择:选择长度至少为两个字的名词、动词;
汉语文档还需要进行繁体转简体、数字和字母等全角转半角。
(3)藏汉文本相似度计算
①特征项的选择
选择藏语和汉语文档的特征项并构建词向量,以计算藏语和汉语文档的相似度,具体包括步骤:
设D为语料中的文档总数,Di为包含词语i的文档数。按照公式(1)计算得到预处理后的双语语料的中每一个词的权重值IDF。
将一篇新闻文本中的词语按照出现的位置分为三类:在标题和正文中都存在的词、只存在于标题中的词和只存在于正文中的词。对网络新闻来说,标题具有举足轻重的作用,因此标题中的词应有较高的权重,将这三类词的权重依次设置为2、1.5和1。根据公式(2)中词的位置不同赋予不同的重要性,得到新的权重IDF′。
设TF为某一词语在一篇文本里出现的次数,按公式(3)计算出词i的最终权重Wi。
Wi=TF*IDF′ (3)
对一篇预处理后的文档中的词的权重进行排序,选择权重较高的词作为关键词,关键词为藏语和汉语文档的第一特征项。
对关键词进行词向量的语义距离计算,能够获得与此关键词距离的最近的几个词,作为对关键词的语义扩展,从而作为文本相似度计算的第二特征项。
选取藏语和汉语新闻文档的第三特征项,具体包括步骤:
将藏语和汉语新闻文档中涉及时间、数字或其他字符串作为辅助特征,加入到文档的特征项中,可以增加跨语言相似文本的匹配度。由于藏语分词时直接将阿拉伯数字分成独立的词,而汉语分词时表示时间的阿拉伯数字后通常带有年、月、日等单位,表示数量的阿拉伯数字后通常带有亿、万、千等单位。为了减少由于分词粒度带来的偏差,将有这样特征的汉语词中的阿拉伯数字和其后的单位分割开,只留下阿拉伯数字。
②词向量的获取
词向量的获取过程如下:
从预处理后的初始双语语料中读入词汇;
统计词频,初始化词向量,放入哈希表中;
构建哈夫曼树,得到每个词汇的哈夫曼树中的路径;
从初始的双语语料中读入一行语句,去除停用词,获得该行语句中每一个中心词的上下文,词向量求和Xw。获得中心词的路径,使用路径上所有节点的目标函数对Xw的偏导数的和优化中心词词向量,优化中心向量的具体步骤如下:
优化词向量公式要计算δ(Xwθ),为了简便运算,本实施例采用一种近似计算的方法。激励函数sigmoid函数δ(x)在x=0处变化剧烈,向两边趋于平缓,当x>6和x<-6时函数就基本不变。
将值域区间[-6,6]均等分为1000等份,剖分节点分别记为x0,x1,x2,…,xk,…,x1000,分别计算sigmoid函数在每个xk处的值,并存储在表格中,当获得一个词的上下文词向量之和x时:
当x<=-6时,δ(x)=0
当x>=6时,δ(x)=1
当-6<x<6时,δ(x)≈δ(xk),xk为距离x最近的等份点,直接查表就可获得δ(xk);
统计已训练词汇数目,大于10000时更新学习率,具体包括:
在神经网络中,较小的学习率可以保证收敛性,但会导致收敛的速度太慢;较大的学习率虽然可以使学习速度变快,但可能导致振荡或发散,所以在训练过程中要“动态优化”学习率。学习率初始值设为0.025,每当训练完10000个词对学习率进行一次调整,调整的公式为:
wordCountActual为已经处理过的词数量,trainWordsCount为词典中总的词数量;
最后,保存词向量。
③词语语义距离计算
获取词向量后,对关键词进行词向量的语义距离计算,具体包括步骤:
首先加载存储词向量的二进制文件。将文件中词向量读入到哈希表中。在加载过程中,为了后续词义距离计算的方便,对词语的每个向量做了除以它向量长度的计算,计算公式如下:
采用余弦值法计算词语与词语之间的语义距离,即:
假设词语A的向量表示为(Va1,Va2,…,Van),词语B的向量表示为(Vb1,Vb2,…,Vbn),则词语A和词语B的语义计算公式为:
在模型加载过程中,程序处理已经完成了对向量距离的除运算,所以上述公式的计算转化为:
根据计算结果选取与关键词距离最近的几个词。
④候选匹配文本的选择
对于一篇藏语新闻文本,需要选定与其进行相似度计算的汉语新闻文本。由于一件新闻报道的藏语和汉语版本发布的时间不是完全一一对应的,通常汉语的报道要早于藏语的报道,通过比较新闻文本的时间,将时间差限定在一个范围内,以此来选定藏语新闻文本的候选匹配汉语文本,避免进行大量没必要的计算。
⑤构建藏汉可比新闻文档
利用已选取的第一特征项、第二特征项和第三特征项,将每一篇藏语和汉语新闻文档都分别用空间向量的形式表示:
Ti=(tw1,tw2,…,twx)Cj=(cw1,cw2,…,cwy)
利用Dice系数计算藏语文本Ti和汉语文本Cj的相似度:
其中,c为两篇文本Ti和Cj的所共同含有的特征项的权重之和,即直接匹配的字符串和通过藏汉词典匹配的藏语和汉语翻译对。a和b分别为文本特征词语的权重之和。
文本的相似度完成以后,根据计算的相似度值与人工设定的阈值进行比较,大于阈值就认为是相似的,由此构建出m对藏汉可比新闻文档。
步骤102,根据可比语料库分别构建第一语言话题模型和第二语言模型;
具体地,本实施例基于藏语和汉语的可比语料库分别构建藏语LDA话题模型和汉语LDA话题模型(如图4所示)。
图4为图1所示跨语言话题检测方法流程中构建藏语LDA话题模型和汉语LDA话题模型的示意图:
图中KT、KC分别为藏语和汉语话题个数,M为藏汉可比新闻文本对的数量,分别是藏语和汉语的第m个文档的词语总数,NT、NC分别为藏语和汉语文档的词语总数,分别是藏语和汉语每个文档下话题的多项分布的Dirichlet先验参数,是每个话题下词的多项分布的Dirichlet先验参数,分别是藏语第m个文档中第nT个词的话题和汉语第m个文档中第nC个词的话题,分别是藏语第m个文档中的第nT个词语和汉语第m个文档中第nC个词语,分别是藏语第m个文档下的话题分布向量和汉语第m个文档下的话题分布向量,它们分别是KT、KC维向量。分别表示藏语第kT个话题下词的分布向量和汉语第kC个话题下词的分布向量,它们分别是NT、NC维向量。
藏语LDA话题模型和汉语LDA话题模型的生成过程如下:
设置话题的数量KT、KC;
设置先验参数本实施例中设为50/KT,设为50/KC,设为0.01;
对藏语文档的KT个话题,根据Dirichlet分布计算每个潜在话题下词语的分布概率向量对汉语文档的KC个话题,根据Dirichlet分布计算每个潜在话题下词语的分布概率向量
对于之前获取的藏语和汉语新闻文本可比对,
(1)分别计算文档中话题的分布概率向量
(2)针对藏语文本所包含的每一个词nt,从话题的分布概率向量的多项式分布中为其分配一个潜在话题在此话题的多项式分布中,选择特征词
(3)针对汉语文本所包含的每一个词nc,从话题的分布概率向量的多项式分布中为其分配一个潜在话题在此话题的多项式分布中,选择特征词
重复步骤(1)、(2)和(3),直到算法结束。
图5为图1所示跨语言话题检测方法流程中通过吉布斯抽样法对LDA话题模型进行参数估计的示意图。
本实施例采用吉布斯抽样法(Gibbs sampling)对LDA模型进行参数估计。Gibbs sampling是生成马尔科夫链的一种方法,生成的马尔科夫链可以用来做蒙特卡洛仿真,从而求得一个较复杂的多元分布。它是马尔科夫链蒙特卡洛(Markov-Chain Monte Carlo,MCMC)算法的一种简单实现,主要思想是构造出收敛于目标概率分布函数的马尔科夫链,并且从中抽取最接近目标概率的样本。
初始时,随机给文档中的每个词语分派一个话题z(0),然后统计每个话题z下词w出现的次数以及每篇文档m下话题z中的词出现的数量,每一轮计算p(zi|z-i,d,w)。
其中,t为文档中第i个词,zi为第i个词所对应的话题,为话题k中出现词语v的词数,为文档m中出现话题z的次数,V为词语的总数,K为话题的总数。
排除对当前词语的话题分配,依照其他全部词的话题分配,来估计当前词被分配各个话题的概率。在获得当前词语属于全部话题z的概率分布后,根据这个概率分布为该词语分派一个新的话题z(1)。然后用同样的方法不断更新下一个词语的话题,直到每篇文档下话题分布和每个话题下词语的分布收敛,算法停止,输出待估计的参数和最后第m篇文档中第n个词语的话题zm,n也同时得出。
设置迭代次数,本实施例中参数α和β分别设为50/K、0.01。根据公式10计算产生话题-词汇概率分布即出现在话题k中的词语v的概率。
其中,为话题k中词语v出现的次数,βv=0.01。
针对文档集中每篇文档,根据公式11计算文档的文档-话题分布概率θm,k,即文档m中话题k所占的概率。
其中,为文档m中话题k出现的次数,αk=50/K。
步骤103,在话题模型生成的文档-话题概率分布的基础上通过话题的相似度判定,以确定第一语言和第二语言对齐。
具体地,如图6所示,在构建出LDA话题模型后,在生成的话题-文档概率分布中,每一个话题在每一篇文档中都会以一定的概率出现。因此,对每个话题来说,可以表示成文档上的空间向量。通过向量之间的相似度来衡量藏汉话题的相关性,将藏汉话题对齐。
对于藏语话题ti和汉语话题tj,计算两者的相关性的步骤如下:
将通过文档相似度计算构建出的m对藏汉可比新闻文档,作为索引文档集;
对于藏语话题ti,将映射到索引文档集上,得到ti的向量表示(di1,di2,di3,…,dim),则ti的索引向量为
对于汉语话题,将映射到索引文档集上,得到tj的向量表示(d'j1,d'j2,d'j3,…,'djm,)则tj的索引向量为
得到ti和tj的索引向量后,采用以下四种常用的相似度计算方法来计算向量和的相关性,每种方法只保留最大的相似度。
①余弦相似度,利用向量的余弦夹角来计算相似度,余弦值越大,相关性越大。余弦距离注重的是两个向量在方向上的差异,对绝对的数值不敏感,适用于长度不一的文本之间的相似性比较。
②欧氏距离,用来描述空间中两个点的常规距离。计算的值越小,两点之间的距离就越近,相似度就越大。与余弦距离相比,欧氏距离体现的是向量在数值特征上的绝对差异,因此适用于长度差异不大的文本之间的相似性比较。
③Hellinger距离,度量两个分布之间差异的一种方法。由于话题可以表示成离散的概率分布,因此,Hel l inger距离可以用来计算话题之间的相似度。计算值越大,话题之间的差异度就越大,相似度就越小;计算值越小,话题之间的相似度就越大。
④KL距离(Kullback-Leibler Divergence),也叫做相对熵(Relative Entropy),是基于信息论提出的。因为和是相同维度上的分布,因此可以用KL距离来衡量两个话题的相关性。藏语话题和汉语话题之间相似度的差异,可以通过在一个信息空间的两个话题的概率分布的差异来度量。两个概率分布P和Q,P到Q的KL距离为:
DKL(P||Q)=P*log(P/Q) (15)
Q到P的KL距离为:
DKL(Q||P)=Q*log(Q/P) (16)
由于KL距离是非对称的,而事实上,藏语话题ti到汉语话题tj的距离与tj到ti的距离是相等的。因此,我们使用对称的KL距离来计算话题的距离:
将公式代入
整理得
基于以上四种方法对结果进行投票,如果第n种方法methodn计算出藏语话题ti和汉语话题tj的相似度最大,投票值为1,否则投票值为0,记为Vote(methodn,ti,tj)∈{1,0},当投票结果Votes(ti,tj)≥3时为有效投票,否则,为无效投票。当投票无效时,通过计算的准确率来选择有优越性的方法为最终的投票结果。
本发明实施例提供的一种跨语言话题检测方法,提高了跨语言文档相似度计算的准确率,通过基于LDA的话题模型构建,利用跨语言话题对齐实现了跨语言话题检测。
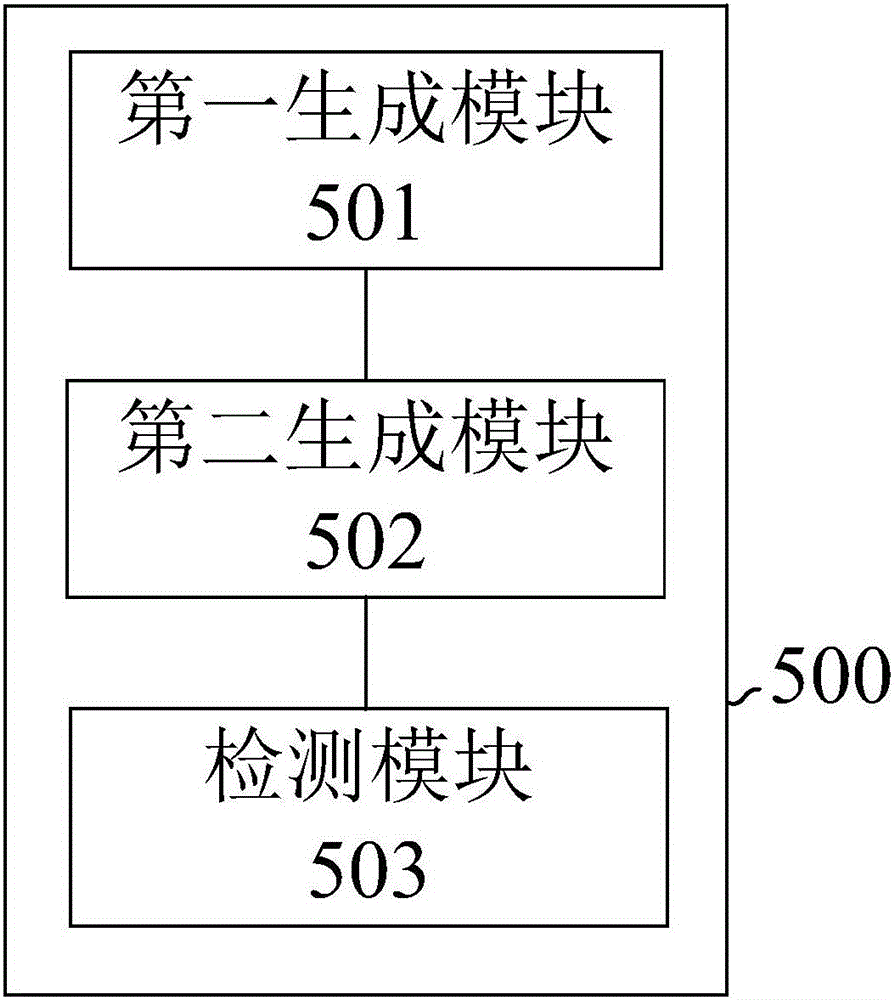
图2为本发明实施例提供的一种跨语言话题检测系统的结构图。该跨语言话题检测系统500包括第一生成模块501、第二生成模块502和检测模块503。
第一生成模块501用于构建第一语言和第二语言的可比语料库;
第二生成模块502基于第一语言和第二语言的可比语料库分别构建第一语言话题模型和第二语言话题模型;
检测模块503用于在第一语言话题模型和第二语言话题模型生成的文档-话题概率分布的基础上通过相似度判定,以确定第一语言话题和第二语言话题的对齐,从而实现跨语言话题检测。
本发明实施例提供的一种跨语言话题检测系统提高了跨语言文档相似度计算的准确率,通过基于LDA的话题模型构建,利用跨语言话题对齐实现了跨语言话题检测。
以上的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!