智造行业中一种新的语义相似度求解方法与流程
本发明涉及语义网络技术领域,具体涉及一种新的语义相关度求解方法。
背景技术:
21世纪以来,全球互联网进入了一个高速发展的新时期,各种新技术不断涌现。作为联系计算机与人之间重要的自然语言处理技术也快速发展中。传统的语义相关度计算方法大致分为两类:基于语义词典的语义相关度计算方法以及基于语料库的语义相关度计算方法;语义相关度计算是自然语言处理领域非常重要的一项技术,它的用途很广泛,是自然语言处理领域一项基础性的研究工作。例如要识别“这个苹果很好吃”,通过语料库检索得到相似的翻译有“这个梨子很好吃”、“这个人很好吃”。这里涉及一个歧义问题,前一个“好”的意思是很好,读音为三声,后一个“好”为四声,所以第一个翻译更合适。为了消除词语歧义问题,本发明提出了智造行业中一种新的语义相似度求解方法。
技术实现要素:
针对于词语中的歧义问题,本发明提出了智造行业中一种新的语义相似度求解方法。
为了解决上述问题,本发明是通过以下技术方案实现的:
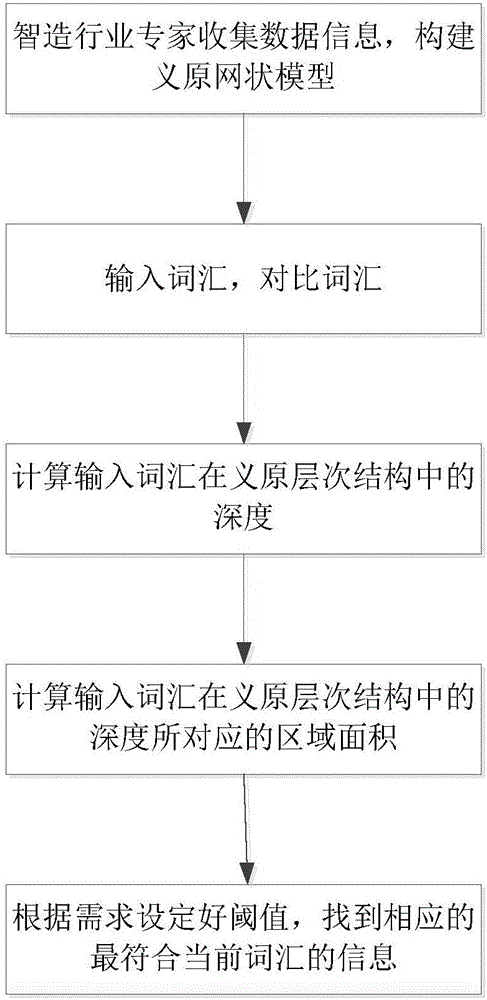
步骤1:根据权重比重,构建智造中相关行业的网状模型。权重大,则深度浅,反之,亦然。
步骤2:此网状模型中有相关属性类,相关属性类对应的义原层次结构以及解释义原,根据输入对比网状模型中词源。
步骤3:根据义原深度距离,确定词语的相似度。
步骤4:根据义原的区域面积,确定词语的相似度。
步骤5:综合考虑义原深度距离、义原区域面积,来更准确判断词语间的相似度。
步骤6:正确检索到用户需要的信息。
本发明的有益效果是:
1、比较传统的语义分析方法,此计算得出的精确度更高。
2、在消除歧义方面有更好的效果。
3、更符合用户需求。
附图说明
图1智造行业中一种新的语义相似度求解方法的结构流程图。
具体实施方式
为解决词语歧义问题,结合图1对本发明进行了详细说明,其具体实施步骤如下:
步骤1:根据权重比重,构建智造中相关行业的网状模型。权重大,则深度浅,反之,亦然。
本网状模型设计由智造行业专家进行数据收集来确定。
步骤2:此网状模型中有相关属性类,相关属性类对应的义原层次结构以及解释义原,根据输入对比网状模型中词源。
步骤3:根据义原深度距离,确定词语的相似度。其具体计算过程如下:
根据此网状模型,选出符合输入的属性类,即义原层次结构。根据输入词汇在义原层次结构中出现的概率P,确定输入的义原S1在层次结构中的深度为为
P=max(P1,P2,…,Pn)
P1,P2,…,Pn分别为每个义原中输入词汇出现的概率,类中义原的个数为n个。
Nj为在第j个义原中出现的次数,V为第j个义原中根据输入词语划分模块的总个数。
由Pj值来确定输入词汇在此网状模型中的深度值DJ。dj与相似度成反比,这里给定一个调节因子α。
即dj=αH(Pj)
步骤4:根据义原的区域面积,确定词语的相似度。其具体计算过程如下:
根据步骤3中的深度dj对应的第j个义原,可以知道此义原的区域面积S。
S=n(解释义原)/β
上式n(解释义原)为第j义原对应的解释义原个数,β为相关区域面积的一个调节因子。
步骤5:综合考虑义原深度距离、义原区域面积,来更准确判断词语间的相似度。其具体计算过程如下:
为了满足其在智造行业中的搜索需求,专家制定了一个具体阈值,相似度必须顺序满足下式两条件,即找到了最佳理解含义,即
(1)dj=αH(Pj)<dC
(2)S>C
上式dc为用户自定义的一个层状网状模型深度,C为用户自定义的一个相关区域度面积。
当深度越小,权重就越大,说明越符合本智造行业领域。同时相关度面积越大,所含信息量就越大。
注明α+β=1,α、β分别对义原深度距离、义原区域面积进行权重划分。
步骤6:正确检索到用户需要的信息。
- 还没有人留言评论。精彩留言会获得点赞!